基于熵重要測度權(quán)重粗糙集的阿爾法多層凝聚入侵分類
2016-09-26 07:30:35王興柱顏君彪曾慶懷
計算機(jī)應(yīng)用與軟件 2016年3期
王興柱 顏君彪 曾慶懷
1(湖南文理學(xué)院芙蓉學(xué)院 湖南 常德 415000)2(湖南文理學(xué)院現(xiàn)代教育技術(shù)中心 湖南 常德 415000)
?
基于熵重要測度權(quán)重粗糙集的阿爾法多層凝聚入侵分類
王興柱1顏君彪1曾慶懷2
1(湖南文理學(xué)院芙蓉學(xué)院湖南 常德 415000)2(湖南文理學(xué)院現(xiàn)代教育技術(shù)中心湖南 常德 415000)
針對入侵檢測數(shù)據(jù)量大,而文獻(xiàn)[1]提出的α核心集的多層凝聚算法計算復(fù)雜度過高,影響實際應(yīng)用的問題,提出一種基于熵重要測度權(quán)重粗糙集的α核心集多層凝聚入侵分類算法。首先,基于熵重要測度權(quán)重方法利用粗糙集對入侵檢測數(shù)據(jù)進(jìn)行預(yù)處理和屬性約簡,降低數(shù)據(jù)維數(shù)防止算法陷入“維數(shù)陷阱”;其次,用熵重要測度權(quán)重距離代替阿爾法多層凝聚算法的歐式距離計算個體相似度,并實現(xiàn)粗糙集輸出數(shù)據(jù)與阿爾法多層凝聚算法的有效對接。通過實驗表明,基于熵重要測度權(quán)重粗糙集的α核心集多層凝聚入侵分類算法能夠更加有效對KDDCUP99標(biāo)準(zhǔn)數(shù)據(jù)庫進(jìn)行檢測分類。
熵重要測度權(quán)重粗糙集多層凝聚入侵檢測
0 引 言
入侵檢測系統(tǒng)(IDS)是對網(wǎng)絡(luò)中入侵行為進(jìn)行檢測的自動系統(tǒng),作為入侵安全防范的前提已在許多安全系統(tǒng)中得到廣泛應(yīng)用[1,2]。二十一世紀(jì),網(wǎng)絡(luò)逐漸成為獲取資訊最常用的工具之一,人們對于網(wǎng)絡(luò)的依賴程度也逐漸增加。如何構(gòu)建高效的入侵攻擊防御系統(tǒng),對于保障信息安全、維持正常生產(chǎn)、生活秩序意義非凡[3]。
為進(jìn)一步提高入侵檢測算法的整體性能,許多學(xué)者致力于入侵檢測算法方面的研究。文獻(xiàn)[4]基于SVM算法在非線性識別中的特點,提出一種SVM入侵檢測算法,去除了機(jī)器學(xué)習(xí)算法的局限性。文獻(xiàn)[5]基于神經(jīng)網(wǎng)絡(luò)在非線性逼近方面的優(yōu)勢,對特征提取后的入侵攻擊行為進(jìn)行檢測。文獻(xiàn)[6]基于k-Means算法來降低訓(xùn)練樣本量,提高其學(xué)習(xí)性能和計算效率,通過反向傳播學(xué)習(xí)機(jī)制對入侵攻擊進(jìn)行檢測。文獻(xiàn)[7]基于CACC對算法進(jìn)行離散化,以此提高數(shù)據(jù)表達(dá)能力,然后基于樸素貝葉斯和k-Means聚類進(jìn)行入侵估計檢測等。
1 多層凝聚算法
學(xué)者馬儒寧在文獻(xiàn)[1]中闡述了一種新的基于α核心集指標(biāo)的分層次聚類方法(MULCA),稱之為多層凝聚算法。有關(guān)定義如下:
定義1該定義根據(jù)高斯距離概念,給出(入侵)數(shù)據(jù)xi與xj間的相似性形式如下:
(1)
式中,σ=σ0d,d為數(shù)據(jù)集的直徑。
定義2文獻(xiàn)[1]采用α核心集概念,此處給出多層凝聚算法的首要核心集概念。如果對于任意數(shù)據(jù)集X中的任何一點x*都滿足式(2)所述的要求:
(2)
則稱任意點x*為任意數(shù)據(jù)集X的首要核心點。
定義3α個依次首要核心點可定義形式如下:
(3)

定義4數(shù)據(jù)集X的α核心凝聚矩陣可由式(4)獲得:
(4)
從定義4給出的凝聚矩陣計算公式可以看出,該矩陣PX~Xα能夠反映出數(shù)據(jù)集X與其α核心集Xα的相關(guān)程度。
定義5Xα的加權(quán)相似性矩陣形式如下:
(5)
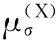
根據(jù)定義5,可依次定義得到原數(shù)據(jù)集X,在凝聚粗化分層過程中,每一層提取結(jié)果的α核心集的相似性加權(quán)矩陣,形式可定義如下:
(6)
根據(jù)定義1-定義5,可獲得文獻(xiàn)[1]提出的多層凝聚算法的兩階段計算(粗化與細(xì)化)過程步驟,如圖1所示。
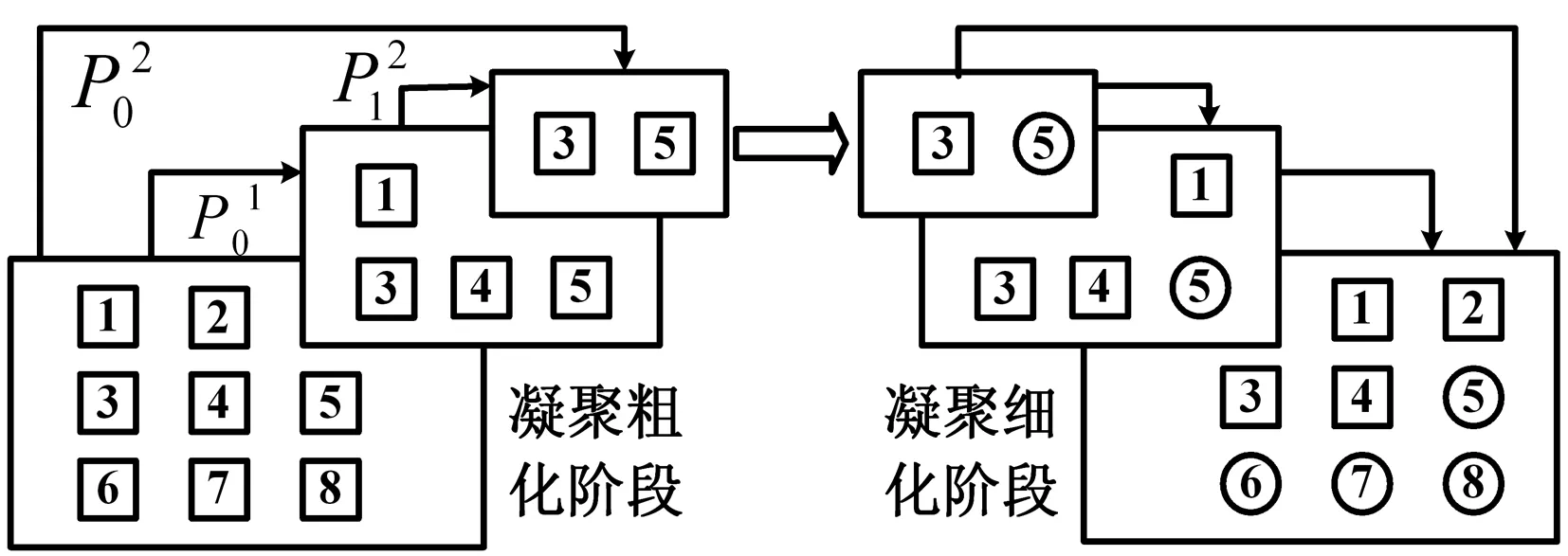
圖1 多層凝聚算法過程
2 粗糙集熵屬性約簡
MULCA算法由于牽涉到凝聚粗化和凝聚細(xì)化兩個階段,導(dǎo)致算法計算復(fù)雜度的提高,特別是針對如入侵檢測系統(tǒng)這種大數(shù)據(jù)量的分類問題時,如何降低算法的計算復(fù)雜度關(guān)乎算法的實際應(yīng)用價值。下面將借助粗糙集熵屬性約簡來對分類數(shù)據(jù)進(jìn)行預(yù)處理,以期達(dá)到降低算法計算復(fù)雜度,提高分類精度的目的[8,9]。
定義6(等價關(guān)系族)假設(shè)P、Q在集合U中為等價的,Q的P正域可表述為:
(7)

(8)

Gain(A)=I(S1,…,Sm)-E(A)
(9)

sig(C)=rP(C)-rP-Q(C)
(10)
定義9(熵測度權(quán)重距離)假設(shè)有K個屬性,則對于其屬性j∈K,其重要性權(quán)值可根據(jù)定義8表述如下:
(11)
則熵測度權(quán)重距離可定義如下:
(12)
利用該熵測度權(quán)重距離可以對冗余屬性進(jìn)行刪減,從而可以有效地降低計算數(shù)據(jù)量,并可仿真算法陷入“維度陷阱”,粗糙集熵屬性約簡步驟如下:
步驟1輸入n個對象的數(shù)據(jù)庫,及輸出簇的數(shù)量k;
步驟2數(shù)據(jù)初始化,令γΦ=0,Φ→red;
步驟3對任意屬性ai∈A-red,計算重要測度:
sig(ai,red,D)=γred∪a(D)-γred(D)
(13)
步驟4選擇最重要測度的屬性ak,滿足下式:
sig(ak,red,D)=max(sig(ai,red,D))
(14)
步驟5若sig(ak,red,D)>0,則更新red集合:red∪ak→red,否則返回步驟4;
步驟6利用上述得到的K維數(shù)據(jù)庫根據(jù)定義9計算red集中的個體屬性權(quán)重ωj;
步驟7任意k個屬性對象作為簇中心;
式中,Wx表示相x的質(zhì)量分?jǐn)?shù),Ix為積分強(qiáng)度,KxA和KiA可以在JCPDS(Joint Committee on Powder Diffraction Standards,粉末衍射標(biāo)準(zhǔn)聯(lián)合委員會)的PDF卡片中得到.
步驟8循環(huán)執(zhí)行下列步驟:
(1) 根據(jù)簇對象均值,將對象劃歸到類似簇中;
(2) 更新簇均值和簇中對象均值;
(3) 計算熵測度權(quán)重距離d(xk,ci),直到d(xk,ci)值穩(wěn)定為止;
步驟9輸出red、屬性簇及d(xk,ci)。
3 改進(jìn)MULCA算法的入侵檢測
多層凝聚算法由于獨特的算法結(jié)構(gòu)導(dǎo)致算法的計算復(fù)雜度增加,因此,對于大數(shù)據(jù)量的入侵?jǐn)?shù)據(jù)檢測,降低數(shù)據(jù)冗余對于算法的實際應(yīng)用意義非凡[10]。第1、2節(jié)著重介紹了α核心集的多層凝聚算法以及粗糙集熵屬性約簡的有關(guān)定義和算法步驟,本節(jié)主要思想是基于粗糙集熵屬性約簡的數(shù)據(jù)預(yù)處理并結(jié)合α核心集的多層凝聚算法實現(xiàn)入侵?jǐn)?shù)據(jù)的有效檢測。基于改進(jìn)MULCA算法的入侵?jǐn)?shù)據(jù)檢測算法框架如圖2所示。

圖2 入侵檢測算法過程
基于改進(jìn)MULCA算法的入侵?jǐn)?shù)據(jù)檢測步驟如下:
步驟1輸入待分類的入侵?jǐn)?shù)據(jù)集X及所需要聚類的個數(shù)K;
步驟3利用熵測度權(quán)重距離d(xi,xj)取代定義1相似度定義,令μ(xi,xj)=d(xi,xj),利用粗糙集熵屬性約簡后的數(shù)據(jù)集作為多層凝聚算法的輸入數(shù)據(jù)集X′;

步驟5參照第1節(jié)有關(guān)定義執(zhí)行細(xì)化過程,對數(shù)據(jù)集進(jìn)行分類,輸出最終的入侵?jǐn)?shù)據(jù)分類結(jié)果C={C1,C2,…,Cm}。
4 仿真實驗與分析
4.1算法測試
仿真對比實驗,選取文獻(xiàn)[11]PROCLUS算法、文獻(xiàn)[12]EWKM算法、文獻(xiàn)[13]FWKM算法和文獻(xiàn)[14]FCS四種算法作為對比算法。本文對比實驗采用文獻(xiàn)[11]使用的數(shù)據(jù)合成方法進(jìn)行實驗數(shù)據(jù)生成。


表1 仿真數(shù)據(jù)集實驗參數(shù)
由表2對比結(jié)果可以看出,RSMULCA算法在四種對比測試數(shù)據(jù)上的識別精度式中最高。作為對比算法在某些數(shù)據(jù)集上識別精度接近于RSMULCA算法,如FCS算法在數(shù)據(jù)集DB1和DB4上的聚類識別精度,在個別數(shù)據(jù)集上其算法性能受制于參數(shù)影響,如在數(shù)據(jù)集DB2上,α=2.1上FCS算法的識別精度為0.9582,但是當(dāng)α=3.0時,識別精度降為0.8846,在其他數(shù)據(jù)集上參數(shù)依賴程度不大。從表2對比數(shù)據(jù)中可看出,PROCLUS、EWKM和FWKM三種算法也有不同程度的參數(shù)依賴性,相比RSMULCA算法對實驗的自適應(yīng)能力要強(qiáng)于對比算法。

表2 聚類識別精度對比
因為PROCLUS算法是基于數(shù)據(jù)抽樣的,仿真過程中算法每次運行結(jié)果都不同。EWKM、FWKM和FCS算法不會出現(xiàn)此情況。對于同一實驗數(shù)據(jù),5種算法各運行20次取平均性能。
下面主要測試算法聚類時間及數(shù)據(jù)點數(shù)、維數(shù)和簇數(shù)三個參數(shù)對RSMULCA算法運行時間的影響程度,仿真結(jié)果如圖3所示。
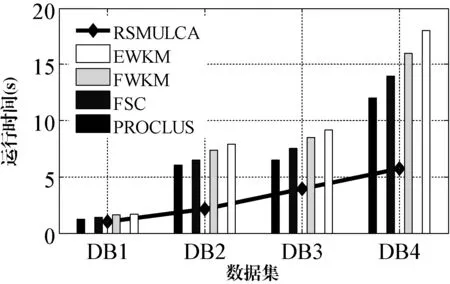
圖3 運行時間對比結(jié)果
圖3給出幾種對比算法的運行時間對比情況,從中可以看出,RSMULCA算法在運行時間上要優(yōu)于所采用的對比算法,主要原因是RSMULCA算法采用粗糙集熵屬性約簡算法有助于降低分類數(shù)據(jù)的計算數(shù)據(jù)量。其他幾種算法運行時間情況是:PROCLUS優(yōu)于FCS算法,兩者優(yōu)于EWKM和FWKM算法,而FWKM要優(yōu)于EWKM算法,主要原因是EWKM算法參數(shù)確定需要較復(fù)雜的計算步驟。
4.2入侵檢測實驗分析
在以往入侵分類算法的文獻(xiàn)報道中,KDDCUP99數(shù)據(jù)庫[15,16]是常用到的實驗對象,為了方便與相關(guān)文獻(xiàn)算法的對比,這里依然沿用其他文獻(xiàn)的做法,以KDDCUP99數(shù)據(jù)庫作為實驗對象。該數(shù)據(jù)庫最具有代表性的主要有4種網(wǎng)絡(luò)入侵?jǐn)?shù)據(jù):DOS、Probe、U2R和U2L。這四種類型網(wǎng)絡(luò)入侵?jǐn)?shù)據(jù)信息如表3所示。

表3 測試數(shù)據(jù)選取數(shù)量
在對入侵檢測算法進(jìn)行評價時,常用到的評價指標(biāo)主要有檢測率和錯檢率。所謂檢測率指的是算法檢測出的入侵?jǐn)?shù)據(jù)個數(shù)與入侵?jǐn)?shù)據(jù)總數(shù)的比值;錯檢率指的是被誤報為入侵的正常數(shù)據(jù)數(shù)量與正常數(shù)據(jù)總數(shù)的比值。對于表3選取的測試數(shù)據(jù)集,分別選取RSMULCA算法、PIDE[10]算法和KTID算法[15]的入侵檢測分類結(jié)果進(jìn)行比較如表4所示。

表4 分類結(jié)果對比(%)
檢測率如式(15)所示,錯檢率如式(16)所示[13]:

(15)

(16)
表4所示分別為RSMULCA、PIDE和KTID三種算法在標(biāo)準(zhǔn)測試數(shù)據(jù)庫上,根據(jù)式(15)、式(16)的實驗對比數(shù)據(jù)。從該對比數(shù)據(jù)可以看出,在DOS、U2R、U2L和Probe四種數(shù)據(jù)分類中,RSMULCA算法在檢測率和錯檢率上的識別性能均要比PIDE和KTID算法更優(yōu)異。PIDE與KTID相比,前者在U2L和U2R兩種網(wǎng)絡(luò)入侵?jǐn)?shù)據(jù)上的識別效果要優(yōu)于KTID算法。在錯檢率方面,PIDE算法在U2L和DOS兩種入侵?jǐn)?shù)據(jù)上的識別效果要優(yōu)于KTID算法。總體上,PIDE入侵檢測算法和KTID入侵檢測算法的性能各有千秋。通過數(shù)據(jù)對比可以得到這樣的結(jié)論,本文所提RSMULCA入侵檢測算法是可行的,能夠有效地提高入侵檢測的識別率,降低錯檢率。
為進(jìn)一步驗證RSMULCA算法的入侵?jǐn)?shù)據(jù)識別性能優(yōu)勢,分別選取MULCA和UMID[17]兩種算法進(jìn)行對比。標(biāo)準(zhǔn)測試數(shù)據(jù)庫仍選用KDDCUP99,入侵?jǐn)?shù)據(jù)數(shù)量如表3所示,仿真對比結(jié)果如圖4、圖5所示。

圖4 三種算法的檢測率對比

圖5 三種算法的錯測率對比
圖4給出RSMULCA、MULCA和UMID三種算法的檢測率對比結(jié)果。可以看出,RSMULCA算法在DOS、U2R、U2L和Probe四種入侵?jǐn)?shù)據(jù)上的檢測準(zhǔn)確率性能均要比MULCA和UMID兩種對比算法優(yōu)秀。而后兩種算法,在DOS和U2R兩種入侵方式中,MULCA算法的入侵?jǐn)?shù)據(jù)檢測率優(yōu)于UMID算法,在U2L和Probe兩種入侵方式中,UMID算法的入侵?jǐn)?shù)據(jù)檢測率優(yōu)于MULCA算法。圖5給出RSMULCA、MULCA和UMID三種算法的錯檢率對比結(jié)果。可以看出,RSMULCA算法在四種入侵?jǐn)?shù)據(jù)上的檢測錯誤率要低于另外兩種對比算法,其中在U2R、Probe和U2L三種攻擊方式中MULCA算法的入侵?jǐn)?shù)據(jù)錯檢率要高于UMID算法。綜上所述,實驗結(jié)果表明RSMULCA算法對入侵?jǐn)?shù)據(jù)檢測是可行和高效的。
5 結(jié) 語
從提高入侵檢測系統(tǒng)對新的入侵?jǐn)?shù)據(jù)檢出率的角度,結(jié)合文獻(xiàn)[1]提出的α核心集的多層凝聚算法設(shè)計了無監(jiān)督的入侵檢測分類系統(tǒng),并且為了解決多層凝聚算法計算復(fù)雜度過高的問題,采用基于熵重要測度權(quán)重粗糙集對入侵?jǐn)?shù)據(jù)進(jìn)行預(yù)處理,并和多層凝聚算法實現(xiàn)有效對接,降低數(shù)據(jù)維數(shù)防止“維數(shù)陷阱”,提高了分類的準(zhǔn)確率。
[1] 馬儒寧,王秀麗,丁軍娣.多層核心集凝聚算法[J].軟件學(xué)報,2013,24(3):490-505.
[2]ChiragM,DhirenP,BhaveshB.Asurveyofintrusiondetectiontechniquesincloud[J].JournalofNetworkandComputerApplications,2013,36(1):42-57.
[3]FaraounKM,BoukelifA.InternationalJournalofComputationalIntelligence[J].NeuralNetworksLearningImprovementusingtheClusteringAlgorithmtoDetectNetworkIntrusions,2007,3(2):161-168.
[4]BoppanaRV,SuX.OntheEffectivenessofMonitoringforIntrusionDetectioninMobileAdHocNetworks[J].IEEETransactionsonMobileComputing,2011,10(8):1162-1174.
[5]MaLC,MinY,PeiQQ.ADynamicIntrusionDetectionMechanismBasedonSmartAgentsinDistributedCognitiveRadioNetworks[J].GeneticandEvolutionaryComputing,2014,238(2):283-290.
[6] 楊雅輝,黃海珍,沈晴霓.基于增量式GHSOM神經(jīng)網(wǎng)絡(luò)模型的入侵檢測研究[J].計算機(jī)學(xué)報,2014,37(5):1216-1224.
[7]ValenzuelaJ,WangJH,BissingerN.Real-timeintrusiondetectioninpowersystemoperations[J].IEEETransactionsonPowerSystems,2013,28(2):1052-1062.
[8]AnilKB,BipanT,JayashriR.OptimizationofSensorArrayinElectronicNose:ARoughSet-BasedApproach[J].IEEESensorsJournal,2011,11(11):3001-3008.
[9] 唐繼勇,宋華,孫浩.基于粗糙集理論與核匹配追蹤的入侵檢測[J].計算機(jī)應(yīng)用,2010,30(5):1202-1205.
[10]FungCJ,ZhangJ,BoutabaR.EffectiveAcquaintanceManagementbasedonBayesianLearningforDistributedIntrusionDetectionNetworks[J].IEEETransactionsonNetworkandServiceManagement,2012,9(3):320-332.
[11]AggarwalCC,ProcopiucC,WolfJL.Fastalgorithmforprojectedclustering[C]//Proc.oftheACM.SIGMOD.NewYork:ACMPress,1999:61-71.
[12]JingL,NgMK,HuangJZ.Anentropyweightingk-meansalgorithmforsubspaceclusteringofhighdimensinoalsparesedata[J].IEEETransonKnowledgeandDataEngineering,2007,19(8):1-16.
[13]HnangJZ,NgMK,RongH.Automatedvariableweightingink-meanstypeclustering[J].IEEETransonPatternAnalysisandMachineIntelligence,2005,27(5):657-668.
[14]GaoG,WuJ,YangZ.Afuzzysubspaceclusteringalgorithmforclusteringhighdimensionaldata[J].LectureNotesinComputerScience,2006,24(3):271-278.
[15]MengYX,LiWJ.Towardsadaptivecharacterfrequency-basedexclusivesignaturematchingschemeanditsapplicationsindistributedintrusiondetection[J].ComputerNetworks,2013,57(17):3630-3640.
[16]HassanzadehA,XuZY,RaduS.PRIDE:PracticalIntrusionDetectioninResourceConstrainedWirelessMeshNetworks[J].InformationandCommunicationsSecurity,2013,23(3):213-228.
[17]ShakshukiEM,SheltamiTR.EAACK—ASecureIntrusion-DetectionSystemforMANETs[J].IEEETransactionsonIndustrialElectronics,2013,60(3):1089-1098.
INTRUSIONCLASSIFICATIONFORALPHAMULTILEVELAGGREGATIONBASEDONROUGHSETWITHENTROPYIMPORTANTMEASUREMENTWEIGHT
WangXingzhu1YanJunbiao1ZengQinghuai2
1(Furong College,Hunan University of Arts and Science,Changde 415000,Hunan,China)2(Modern Educational Technology Center,Hunan University of Arts and Science,Changde 415000,Hunan,China)
Intrusiondetectionhaslargedataamount,andthemultilevelaggregationclusteringalgorithmofαcore-setpresentedbyliterature[1]hastoohighcomputationalcomplexity,whichaffectsthepracticalapplication.Aimingatthisproblem,weproposedanintrusionclassificationalgorithmforαcore-setmultilevelaggregationclustering,whichisbasedonroughsetwithentropyimportantmeasurementweight.First,basedonentropyimportantmeasurementweightmethoditusestheroughsettocarryoutpretreatmentandattributereductiononintrusiondetectiondata,andtodecreasedatadimensionforpreventingthealgorithmfromfallinginto"dimensiontrap";Secondly,itreplacestheEuclideandistanceofalphamultilevelaggregationclusteringalgorithmwithentropyimportantmeasurementweightdistancetocomputetheindividualsimilarity,andimplementstheeffectivedockingofoutputdataofroughsetandalphamultilevelaggregationclusteringalgorithm;Finally,itwasdemonstratedthroughexperimentsthattheproposedalgorithmcouldmoreeffectivelydothedetectionandclassificationonKDDCUP99standarddatabase.
EntropyImportantmeasurementWeightRoughsetMultilevelaggregationclusteringIntrusiondetection
2014-11-23。湖南省自然科學(xué)基金項目(14JJ2124)。王興柱,副教授,主研領(lǐng)域:網(wǎng)絡(luò)與信息安全,現(xiàn)代教育技術(shù)。顏君彪,教授。曾慶懷,副教授。
TP311
ADOI:10.3969/j.issn.1000-386x.2016.03.075
猜你喜歡
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
數(shù)學(xué)小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2019年4期)2019-05-20 10:06:32
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
海峽科技與產(chǎn)業(yè)(2016年3期)2016-05-17 04:32:12
山東青年(2016年1期)2016-02-28 14:25:25
當(dāng)代修辭學(xué)(2014年3期)2014-01-21 02:30:44
