基于編輯距離的無序詞表的對齊和定位
2016-09-26 11:28:56趙志靖
智能計算機與應用 2016年4期
趙志靖


摘要:語言調查采集到的數據存在相當程度的差異,需要進行二次加工。本文基于編輯距離算法實現從語言和方言詞匯大數據中的詞匯相似匹配及數據的對齊和定位。通過對達讓語數據進行的三次實驗發現,在做距離計算時,以詞算而不是以詞加括號內注釋的整體去算的方式在保證抽取詞匯召回率的基礎上準確率會顯著提升。實驗結果表明,基于編輯距離的數據抽取方法是可行的,具有較好的檢索效果。
關鍵詞:編輯距離;相似度
中圖分類號:TP391 文獻標識碼:A
Abstract: The data of languages collected from field research have considerable differences,they need for secondary process.This paper implements the match and extraction of vocabulary similarity from the big data of language and dialect vocabulary based on levenshtein distance algorithm.Through the three experiments made by using the data of Darang, the research finds that the way of counting words rather than words and comments in brackets as a whole increases the precision rate dramatically on the basis of ensuring extraction vocabulary recall rate when the levenshtein distances are computed. The experimental results show that it is feasible to extract data based on levenshtein distance, the aboved method has better retrieval effect.
Keywords: Levenshtein Distance;similarity
引言
中國語言研究中,經歷了60余年大規模數據的采集,形成約數千種語言和方言詞匯大數據。不過這些數據因調查理念、調查目的、調查方式、調查領域、調查詞表等不同而存在不同程度的差異,需要進行二次加工處理,這批寶貴資源對語言工程和語言文化建設具有重要價值。本文目標提出對采集的語言數據二次加工,建設統一格式詞表,便于后續的語言科學研究。也就是說語言調查采集到的數據是無序的,且數量不等,本文擬建設統一格式詞表,該詞表包括1 329個詞匯,并且這些詞匯是按照順序排列的,然后又從數千種語言詞匯大數據中,每種語言都抽取意義相同1 329個詞匯,如果沒有找到,則以空表示,這就涉及到數據的定位,由于這1 329個詞匯是按照順序排列的,所以還涉及到數據的對齊,最后將每種語言按順序排好的1 329個詞匯保存為獨立的Excel文件,供語言分析研究使用。本文的難點在于如何從數千種語言詞匯數據中盡可能準確地找到這1 329個詞匯。
1 中國語言和方言數據現狀
半個多世紀以來,我國開展過數次規模不等的語言和方言調查。1956年,根據國務院指示開展了漢語和民族語言普查,共普查了1 849個縣市的漢語方言,并組成7個民族調查隊,調查了主要民族地區的語言。這次語言普查,對于推廣普通話和漢語規范化,對于少數民族文字的改革與創制,對于民族身份的認定等都起了重要作用。1999年,教育部、國家語委等11部(委)聯合開展了中國語言文字使用情況調查,調查采用入戶問卷的調查方式,涉及全國1 063個縣(市、區),直接被調查對象47萬多人。這次調查獲得了我國語言文字使用的一些基本數據,為當今的語言決策提供了重要支撐。除了這2次大的語言調查之外,我國學者還持續進行了漢語方言、民族語言、海外華語的調查研究,取得了許多重要成果。
在推廣普通話的同時,社會的語言資源保護意識逐漸加強,方言文化保護受到社會各界的關注。國家語委積極推進中國語言資源有聲數據庫建設,江蘇庫數據調查工作完成并通過國家驗收,成為全國首個建成并開通的省級語言資源庫,上海、北京、遼寧、廣西等省區市有聲數據庫建設工作取得成效,山東、河北、福建等省有聲數據庫建設工作啟動。“中華經典資源庫”啟動了首期建設工作[1]。
但是語言生活異常豐富復雜且與時而變,半個多世紀以來所進行的各種語言調查,或因調查理念、調查目的、調查方式(包括調查技術)、調查領域等限制,采集到的數據存在相當程度的差異,需要進行大規模統籌建設。用現代信息技術大規模處理中國語言數據,建成中國語言資源數據庫,對我國語言生活規劃和語言科學研究將產生極其重要的影響。
2 基于編輯距離的數據對齊和定位技術
2.1 編輯距離
編輯距離算法是俄羅斯的Vladimir Levenshtein在1965年最先提出來的[2]。Levenshtein提出的編輯距離算法允許使用插入、刪除和替換3種編輯操作方式,用這3種編輯操作方式計算得到的編輯距離叫Levenshtein Distance。[3]
編輯距離用于衡量2個序列的相似度,即兩者之間有多近似或有多大區別。在自然語言處理中被衡量的序列就是單詞或字符串。2個單詞之間的編輯距離越小,其相似度就越高。如果設2個字符串分別為源字符串s和目標字符串t,從字符串s到t的編輯距離是指:只使用刪除、插入或替換3種操作,需要最少多少步可以將s變成t,即“將源字符串s變換為目標字符串t所需要的最少的刪除、插入或替換操作的次數”[4]。舉例如下。
1)如果s=“computer”,t=“computer”,那么編輯距離D(s,t)=0,因為s與t完全相同,不需要變換。
2)如果s=“sport”,t=“sort”,那么編輯距離D(s,t)=1,因為將s變換為t只需一次編輯操作(刪除字母“p”)。
3)如果s=“sensible”,t=“sensitive”,其編輯距離D(s,t)=3,因為將s變成t至少需要三步(第一步插入“t”,第二步把“b”替換成“i”,第三步把“l”替換成“v”)。
編輯距離D(s,t)的計算方法如下所述。假設Dij=D(s1…si,t1…tj),0≤i≤m,0≤j≤n,m和n分別表示源字符串s和目標字符串t的長度,Dij表示從s1…si到t1…tj的編輯距離,那么(m+1)×(n+1)階矩陣Dij可通過公式(1)計算得到。
公式(1)包含刪除、插入和替換三種操作。該算法是從兩個字符串的左邊開始比較,記錄已經比較過的編輯距離,然后進一步得到下一個字符位置時的編輯距離。矩陣Dij能夠通過從D00逐行逐列計算獲取,最終Dmn表示D(s,t)的值,即源字符串s和目標字符串t的編輯距離。
編輯距離算法最初用于拼寫檢查,計算將錯誤的拼寫形式轉換成正確的拼寫形式最少需要多少次操作[5]。現在,編輯距離算法不僅用于拼寫檢查,還在如剽竊檢測、重名或近似名查詢、重復內容檢查、生物學上的DNA分析、計算機輔助翻譯需要的相似譯文文本查找、數據清洗等領域中得到了很好的應用[6-7]。
2.2 統一格式詞表數據對齊和定位的實現過程
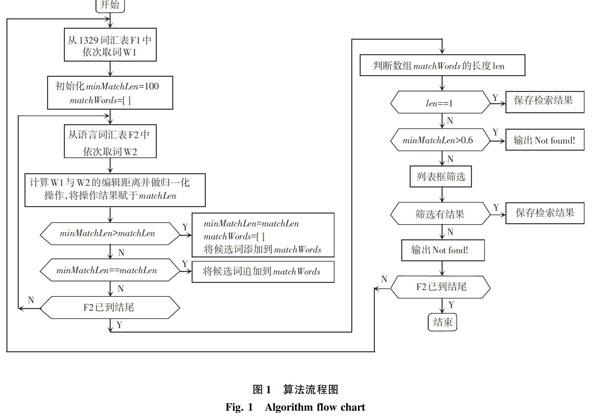
統一格式詞表是指從數千種語言詞匯大數據中,每種語言都抽取意義相同的詞匯(本文是1 329個詞匯),然后將所有語言的1329詞匯按統一順序和格式排列,供語言分析研究使用。統一格式詞表數據和語言詞匯數據保存在Excel中。數據的對齊和定位算法流程如圖1所示。
首先,從1329詞匯表F1中取詞W1,然后從語言詞匯大數據F2中依次取詞W2,計算W1與W2之間的編輯距離。實際操作中,所謂的W1和W2可能還需要做細化處理,因為1329詞匯數據和語言詞匯數據保存在Excel中,數據是以類似一條記錄的形式保存的,不是以單個詞的形式保存的。比如,1329詞匯表Excel文件中“雹子,冰雹”這條記錄,在程序處理過程中,會將“雹子”和“冰雹”分別取出去做編輯距離計算,而不是以“雹子,冰雹”整體去做編輯距離計算。語言詞匯數據Excel文件中的記錄也是這樣處理的。如此經過編輯距離計算之后,研究擇取其中的最小值進入下一步的處理中。將1329詞匯表中的每個詞匯,采用編輯距離算法,和語言詞匯表的所有數據進行相似匹配,并計算編輯距離,將距離最小的和等于最小距離的值作為匹配結果保存到matchWords數組中。如果matchWords的長度為1,則說明只有一條匹配結果,然后將該結果輸出保存;如果matchWords的長度為大于1,則說明匹配到相似數據較多,需要進一步處理。
由于應用中詞匯的長度相差較大時,詞匯長度對最終的計算結果影響較大,因此,有必要對編輯距離值進行歸一化操作。本文基于取比較詞匯的最大長度做歸一化。也就是說,matchLen和最小距離值minMatchLen都是歸一化后的值。
本文的算法中,將最小距離minMatchLen閾值設置為0.6,因為經過對輸出結果的勘察,我們發現,最小距離值超過0.6的匹配結果,其正確率基本為0。也就是說,具體只對小于0.6的結果做進一步處理,超過0.6就認為沒找到,自動輸出“Not found!”。超過0.6的檢索結果舉例如表1所示。實驗舉例用詞匯來自達讓語,見本文第四部分,下同,不再贅述。
2.3 詞匯的自動抽取及后加工
如前所述,matchWords的長度為1,自動抽取并輸出匹配結果;如果matchWords的長度大于1,詞匯比較距離超過0.6的自動輸出“Not found!”,詞匯比較距離小于0.6的則需要進行后加工,即人工判斷,后期篩選。即雖然抽取詞匯的過程是自動的,但是篩選出盡可能正確的詞匯仍需要人工判斷。在此,以“洞,窟窿”、“巖石”舉例做如下說明,具體如表2、表3所示。
表2和表3中加粗斜體的為篩選結果。由表可知,表2可篩選出正確的匹配詞;表3篩選不出匹配詞,程序自動輸出“Not found!”。同時表2說明,最小距離值為0并不一定只有一個候選詞,仍需進一步篩選。
本文用輸入對話框的動態列表菜單來顯示候選詞匯,如果候選詞匯數目比較大會影響美觀,所以本文選用下拉列表框,其高度固定,寬度根據內容自動擴展,點擊列表框右邊的倒立小三角可顯示帶滾動條的下拉列表,內容可多可少。如果有多個候選詞,就會按匹配到的先后順序進行排列并顯示給用戶。程序運行過程中,列表選擇輸入對話框是自動彈出的,用戶只需在正確詞上面單擊鼠標右鍵,然后點下“OK”按鈕即可;如果候選詞列表中沒有找到正確的匹配詞,則點下“Cancel”按鈕,程序自動輸出“Not found!”。這就完成了詞匯篩選的過程。圖2和圖3是詞匯篩選界面功能實例圖。
圖2是程序在檢索“洞,窟窿”時,由于有多個匹配結果,所以程序運行過程中跳出對話框進行篩選;圖3顯示,“窟窿(衣服上的窟窿)”應該是正確的匹配結果,而不是其他項。鼠標選擇正確項之后按“OK”按鈕,由此正確的匹配結果就得到了保存。
3 實驗設計與數據分析
3.1 實驗語料
本文所用實驗語料是田野調查采集的達讓語數據,共有數據記錄2660條,其片段截取如圖4所示。
3.2 實驗過程
本文第三部分的程序實現說明都是基于該實驗語料。
為了使得距離值能夠切實反映詞匯之間的差異,程序在處理過程中會忽略語言數據中括號內的內容。也就是說,在做距離計算時,以詞算而不是以詞加括號內注釋的整體去算。這一點通過實驗結果可以得到印證。
利用提供的達讓語數據,研究展開了三次實驗。
第一次實驗:做距離計算時,語言數據是以詞加括號內注釋的整體去算的,且后期未做篩選加工處理。未召回的詞數目為174,檢索成功的詞數目為664。
第二次實驗:做距離計算時,語言數據中括號內注釋部分被刪除了,且后期未做篩選加工處理。未召回的詞數目為39,檢索成功的詞數目為990。
第三次實驗:做距離計算時,語言數據中括號內注釋部分被刪除了,且后期做了篩選加工處理。未召回的詞數目為152,檢索成功的詞數目為1092。
實驗結果用準確率P(Precision)、召回率R(Recall)來表示。3次實驗結果如表4所示。
3.3 實驗數據分析
從實驗一結果來看,語言數據如果是以詞加括號內注釋的整體去算,會增加詞匯的長度,從而無形中加大了編輯距離的值,使得召回率和準確率降低,且均將低于其他2個實驗,尤其是準確率大大降低;從實驗二結果來看,由于將語言數據中括號內注釋部分刪除了,召回率和準確率都提高了,尤其是準確率有了明顯提升;實驗三在實驗二的基礎上做了后期篩選加工處理,由于加入了篩選操作,召回率略微下降,但比實驗一的召回率仍然偏高,最重要的卻是,實驗三的準確率有了改觀與增益。這符合數據處理的正常思維。從實驗結果的整體上來看,統一格式詞表的數據提取用編輯距離算法可以得到研發,但抽取需要將語言數據中括號內注釋部分刪除,使得要比較的詞匯的長度差小一些,且抽取結果也需要后期篩選處理。
4 結束語
編輯距離是計算和量化分析詞匯相似度的一種重要依據。根據編輯距離可實現從數千種語言詞匯大數據中檢索/抽取詞匯。但是同時也看到,本文只研究了抽取過程的自動化,由于后加工階段需要進行篩選加工處理,會增加時間復雜度,在計算時間上,編輯距離算法還需進一步優化,或者將編輯距離算法和其他算法結合起來推進實施優化處理。
參考文獻:
[1]李宇明.論中國語言資源有聲數據庫的建設[J].中國語文,2010,(4):356-363.
[2]LEVENSHTEIN V I. Binary codes capable of correcting deletions, insertions and reversals[J].Doklady Akademii Nauk SSSR,1965,163(4):845-848.
[3]MANNING C D,RAGHAVAN P,SCHUTZE H. Introduction to information retrieval[M].Cambridge: Cambridge University Press,2008:58-60.
[4]馬立東.編輯距離算法及其在英語易混詞自動抽取中的應用[J].智能計算機與應用,2013,3(1):47-51.
[5]Allison L. Dynamic Programming Algorithm(DPA) for Edit-Distance[EB/OL].[2015-07-10].http://www.allisons.org/ll/AlgDS/Dynamic/Edit/.
[6]米成剛,楊雅婷,周喜,等.基于字符串相似度的維吾爾語中漢語借詞識別[J].中文信息學報,2013,27(5):173-178,190.
[7]瑪依熱·依布拉音,米吉提·阿不里米提,艾斯卡爾·艾木都拉.基于最小編輯距離的維語詞語檢錯與糾錯研究[J].中文信息學報,2008,22(3):110-114.
猜你喜歡
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
中華胰腺病雜志(2021年1期)2021-02-26 11:28:36
山東醫藥(2020年34期)2020-12-09 01:22:24
文苑(2020年4期)2020-05-30 12:35:30
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
中華胰腺病雜志(2019年4期)2019-08-29 08:52:20
小學生作文(中高年級適用)(2018年3期)2018-04-18 01:24:47
華北電力大學學報(社會科學版)(2016年4期)2016-12-01 03:59:30
發明與創新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
