三維自由面流動模擬中GPU并行計算技術
2016-10-12 06:54:46李海州唐振遠萬德成
海洋工程 2016年5期
李海州,唐振遠,萬德成
(1.上海交通大學 船舶海洋與建筑工程學院 海洋工程國家重點實驗室,上海 200240;2.高新船舶與深海開發裝備協同創新中心,上海 200240)
三維自由面流動模擬中GPU并行計算技術
李海州1,2,唐振遠1,2,萬德成1,2
(1.上海交通大學 船舶海洋與建筑工程學院 海洋工程國家重點實驗室,上海 200240;2.高新船舶與深海開發裝備協同創新中心,上海 200240)
MPS(Moving Particle Semi-implicit)法能夠有效地處理潰壩、晃蕩等自由面大變形流動問題。在三維MPS方法中,粒子數量的急劇增加會導致其計算效率的降低并限制其在大規模流動問題中的應用。基于自主開發的MPS求解器MLParticle-SJTU,本文對求解過程中耗時最多的鄰居粒子搜尋和泊松方程求解兩個模塊采用了GPU并行加速,詳細探討了CPU+GPU策略。以三維晃蕩和三維潰壩這兩種典型的自由面大變形流動為例,比較了CPU+GPU相對于MLParticle-SJTU串行求解時的加速情況,結果表明CPU+GPU在鄰居粒子和泊松方程這兩個模塊中的加速比最高能達到十倍左右。此外,采用CPU+GPU并行能夠較準確地模擬潰壩、晃蕩等自由面大變形問題。
MLParticle-SJTU求解器;鄰居粒子搜索;GPU并行技術;稀疏矩陣求解;潰壩;晃蕩
Abstract:MPS (Moving Particle Semi-implicit) is very suitable to deal with free surfaces flows of large deformation such as dam-breaking and sloshing flows.However,the computational efficiency of the MPS method becomes a bottle neck for large-scale engineering applications with the increase of the number of particles,especially for 3D flow problems.Based on our in-house solver MLParticle-SJTU,the present work applies GPU technique in searching for neighboring particles and solving pressure Poisson equation,which are two most time-consuming parts in the MPS.The acceleration performance is analyzed according to 3D sloshing and 3D dam breaking flows.The results show that a speedup up to 10x can be achieved by CPU+GPU acceleration compared to that by only one CPU.
Keywords:MLParticle-SJTU solver; neighbor list search; GPU parallel computation; sparse linear equation; sloshing;dam-breaking wave
無網格粒子法MPS(Moving Particle Semi-implicit)[1-3]能夠有效地處理自由面大變形流動問題,如晃蕩、潰壩等。盡管如此,當該方法應用到三維流動問題時,粒子數和計算量會急劇的增加,基于傳統的CPU串行計算已經很難滿足工程應用的需要。因此,如何有效地提高MPS方法在三維問題中的計算效率就顯得尤為重要。
近些年來,已有學者在嘗試著通過多CPU并行計算來提高MPS方法的計算效率。Ikari 和 Gotoh[4]分析了粒子分解法和區域分解法兩種并行策略的優缺點,結果顯示區域分解法能夠獲得較好的并行效率;Gotoh 等[5]開發了一個三維 MPS 并行求解器,采用MPI實現進程間通信,研究了三維破波問題,并分析了不同迭代方法的并行效率。Iribe等[6]介紹了一種基于粒子分解法的并行 MPS 方法,為了減少因粒子分解帶來的進程間通信量,作者采取了優化措施,如對粒子重新編號、提前生成緩沖區粒子列表,這些做法提高了并行效率,最后計算了波浪在海岸的演化問題。張雨新等[7]基于MPI并行庫和動態負載平衡技術開發了粒子法并行求解器MLParticle-SJTU,數值測試表明該求解器能夠獲得較好的加速比。上述研究表明CPU并行確實能夠有效地提高計算效率。一般地,隨著核數的增加,計算效率有增大的趨勢。因此,如果能夠有效利用足夠多核數進行并行計算的話,可能會得到非常可觀的計算效率。
另外,一種擁有非常多核數的處理器引起了大家的注意,即GPU(圖形處理器)。為了處理大規模的圖像數據,GPU在硬件結構、指令流程和浮點數計算能力等方面做了大量的優化。同時,GPU的計算核心數也遠遠高于CPU,比如一塊消費級顯卡就擁有數百乃至上千個計算核心。而以上這些特性也奠定了GPU擁有強大并行計算能力的基礎。因此,現在也有不少人開始考慮如何充分利用GPU的并行能力。
在粒子法領域,關于GPU并行的工作最早見諸于一種提出較早的無網格粒子法SPH(Smoothed Particle Hydrodynamics)中。Harada等[8]以及Zhang等[9]最早將GPU技術應用到無網格粒子法SPH。隨后GPU在SPH上的應用逐漸增多。Crespo等[10]對SPH理論及某些關鍵問題的不同處理方式進行了綜述,并比較了SPH方法在CPU和GPU上實現的異同。計算結果表明,在使用單塊GPU進行百萬級別粒子數的模擬時,較單核CPU能獲得兩個數量級的加速比。Dominguez等[11]研究了CPU-GPU計算平臺的優化問題。對于CPU端,提出了將計算域劃分為更小的Cell單元以及利用OpenMP等優化措施。對于GPU端,則提出了最大化并行率、減少全局內存訪問等優化策略。相較于SPH而言,GPU在MPS中的應用就相對較少。其中,Hori 等[12]采用 CUDA (Compute Unified Device Architecture) 庫開發了基于 GPU加速的二維MPS并行程序,獲得了數倍到十多倍的加速比;朱小松[13]針對晃蕩問題研究了MPS的GPU并行計算及其優化分析。這些應用大多是集中在二維問題上,三維應用所開展的工作還比較少。
本文的主要目標是基于課題組自主研發的CPU并行求解器MLParticle-SJTU[14-20],研究如何利用GPU并行技術來提高三維MPS的計算效率。其中,求解器MLParticle-SJTU是基于改進的MPS方法,利用C++語言和MPI并行庫自主開發的,目前該求解器已經應用到液艙晃蕩[15-18]、潰壩[19,20]等問題。針對MPS方法中最耗時的求解部分:鄰居粒子搜尋和泊松方程求解,本文詳細地討論了GPU并行技術分別在這兩部分中的加速策略。由于CPU上的算法并不能直接應用到GPU上,本文采用對原有CPU計算程序的部分模塊進行GPU化的方法來研究GPU并行技術在三維MPS中的應用。為了與CPU并行以及全GPU并行相區別,本文將MPS中部分模塊GPU化的方法稱之為CPU+GPU并行。最后,本文將通過對三維晃蕩問題和三維潰壩問題的仿真模擬來驗證CPU+GPU并行在三維MPS方法中的可行性和有效性。
1 CPU+GPU并行模型
1.1GPU計算架構
GPU(Graphics Processing Unit),即圖形處理器,最初主要用于圖形處理的加速,隨著技術的不斷革新,目前GPU已發展成為一種高度并行化、多線程、多核的處理器,具有非常大的計算吞吐量和相當高的存儲器帶寬。如圖1[21]所示,GPU相較于CPU劃分了更多的執行單元(ALU),即更多的計算核心,從而能并發執行相當多數量的線程,而這也正是GPU擁有強大并行計算能力的原因所在,也即GPU是專為計算密集型、高度并行化的計算而設計。
1.2CPU+GPU執行方式
從上節可以看到,GPU的硬件結構決定了GPU可以進行高效率的并行計算。但是,要充分利用其并行性能,則需要一個簡單、有效的操作平臺,本文的CPU+GPU工作是基于NVIDIA公司推出的軟件加硬件操作平臺CUDA(Compute Unified Device Architecture,通用并行計算架構)來進行開發的。在CUDA模型中,CPU被稱為主機(Host),而GPU被稱為設備端(Device)。一個典型的CPU+GPU混合計算的工作流程如圖2所示。在執行任務時,先由主機端程序開辟任務所需的內存或顯存,然后將主機端數據拷入顯存中,設備端接收到主機端的執行指令后執行相應的任務要求,執行結束后,將執行結果傳遞給主機端,主機端釋放開辟的內存或顯存,執行結束。
在主機端,程序的執行和只有CPU情況下的運行模式是一樣的,可串行可并行。本文的計算中,主機端的程序都是串行進行的。

圖1 GPU與CPU相比分配了更多的晶體管用于數據處理[21]Fig.1 The GPU devotes more transistors to data processing[21]

圖2 CPU+GPU執行模式Fig.2 The execution mode of CPU+GPU
在設備端,程序是以線程為基本單位來運行的。而線程間則是以Thread、Block、Grid的三維組織層次來執行的。其中,每個Block由若干個Thread組成一維、二維、三維的形式,而Block則以一維、二維、三維的形式組成Grid。在計算時,計算任務將分配到相應的流多處理器(Stream Multiprocessors,SM)中,而流多處理器又將任務分配到Grid中,如此向下傳遞,最終到達Tread執行任務。任務完成后,則將計算結果返回,最終回到主機端。
總的來說,CPU+GPU的運行模式就是由CPU端提供GPU端計算所需要的初始數據,而當GPU端計算完成之后,就將結果傳輸回CPU端,從而構成一次CPU+GPU計算。
2 MPS的CPU+GPU并行方案
2.1MPS串行時間開銷分析
本文分析MPS計算程序MLParticle-SJTU串行時各模塊的CPU時間開銷,并找出耗時最大的模塊。求解器采用了改進的MPS方法[14-20],該方法將原始MPS方法中需要的兩次鄰居粒子搜尋降低到了一次,這在一定程度上優化了MPS的計算效率。圖3(a)是原始的MPS計算流程,圖3(b)給出了改進的MPS計算流程。
本文在linux平臺下選取了一個三維潰壩(潰壩尺寸與后文中的潰壩算例相同)作為時間開銷分析的測試算例,統計了100個時間步長的計算時間,并分析各部分的時間比例。統計結果如表1所示。

表1 MPS各部分時間占比情況Tab.1 The distribution of running time of MPS
從表1可以看到,PartB和PartD所占的時間比例最大,其余部分則幾乎可以忽略。其中,PartD所占用時間比例高達82.74%,而其對應的部分為泊松方程求解模塊。PartB對應占比11.33%則位居第二,并遠遠高于剩下的部分。其中鄰居粒子搜尋是整個PartB的核心,其耗時占PartB的50%左右(表中沒有列出)。從上述分析結果可以看到,在三維MPS計算中,鄰居粒子搜尋和泊松方程的求解是制約計算效率的關鍵因素。因此,本文研究CPU+GPU并行加速在PartB和泊松方程求解中的加速策略。

圖3 MPS計算流程Fig.3 The flow chart of MPS
2.2PartB的并行化方案
2.2.1 粒子搜尋的基本思路
PartB包含了建立鄰居粒子對的三個步驟:鄰居粒子搜尋、核函數計算、更新粒子對信息。其中核函數計算和更新粒子對信息實現起來比較容易,且步驟單一,所以不需要特別討論。而PartB中的鄰居粒子搜尋則是一個相對較復雜的問題,本文將對該問題進行詳細討論。
目前,普遍采用的粒子搜尋方法有CLL(cell-linked list)和VL(Verlet list)兩種[ 23],其基本思想都是將粒子搜索域劃分成一個個很小的單元,從而縮小搜索范圍,提高搜索效率。由于原始的CPU程序采用的是CLL方法,也就是要構建鏈表保存所有的鄰居粒子對,因此,本文的GPU端也要采用與之相適應的搜尋方法。

圖4 鄰居粒子搜尋范圍Fig.4 The schematic diagram of neighbour searching
鄰居粒子搜尋共分為兩部分,首先要把所有粒子分配到背景單元中,這個可以通過對某一指定坐標點來計算所有粒子的相對坐標來實現;其次,利用分配好的背景單元來搜尋鄰居粒子,以三維情況為例,每個粒子的搜尋范圍應該如圖4所示。可以看到,每個粒子只搜尋了一半的范圍(單獨來看的話,三維問題應該是上中下共三層27個單元都是潛在鄰居粒子單元),這是因為在GPU上每個粒子的鄰居粒子搜索操作均由一個對應的線程來完成,因此如果每個粒子都搜尋所有的鄰居粒子,那么將會導致最后的鄰居粒子列表重復。因為鄰居粒子對是成對出現的,i粒子是j粒子的鄰居粒子,那么j也是i的鄰居粒子,所以如果都進行完全搜尋的話,將會造成鄰居粒子對重復。
在對這一過程進行并行化的時候,還有一個值得注意的問題就是鄰居粒子對的存儲問題。圖5給出了串行和并行程序中,鄰居粒子對的存儲情況。串行時需要預先估算一個最大的鄰居粒子數來分配粒子對的存儲空間。在并行處理時,由于每個線程都要進行粒子搜尋,所以要為每一個線程都分配存儲空間,這就要求對每個線程估算一個最大的粒子數上限。而這個最大粒子數上限則和具體問題以及計算粒子數等相關,為了保險起見,該最大粒子數必須預留足夠的空間,因此需要取足夠大的值,這無疑會增加內存的消耗量。此外,由于在GPU端完成粒子搜尋后需要將數據傳回CPU端,之前分配過大的數據存儲空間則會造成數據傳輸時間增大,這也將一定程度上制約GPU的加速效果。
2.2.2 粒子搜尋中的優化措施
1) 合并保存兩種作用域的鄰居粒子。在MPS方法中,存在著兩種粒子作用域的離散:一種是散度和梯度的離散,其作用域取為2.1倍的初始粒子間距;另一種則是拉普拉斯算子的離散,其作用域取為4.0倍的初始粒子間距[1]。由于第一種作用域內的鄰居粒子必定屬于第二種鄰居粒子,因此只需要考慮拉普拉斯算子作用域情況下鄰居粒子的情況來分配存儲空間。
2) 數據傳輸優化。在GPU完成計算后需要把數據傳回CPU端。當傳輸的數據量很大時,有限的傳輸速度就成為了瓶頸。在CUDA存儲模型中,提供了一種稱為鎖頁內存的模式,使用該內存后將在CPU內存中分配出專門用于與GPU存儲進行數據傳輸而不參與其它CPU任務的空間,并允許GPU進行DMA(直接內存訪問)。因此,使用鎖頁內存能夠有效提高數據傳輸。
3)提取鄰居粒子對的優化。如圖5所示,CPU+GPU并行計算后的數據分布與串行的數據分布是不一樣的。因此,需要將GPU并行計算得到的結果重新拼接為串行時的情況,也即拼接所有鄰居粒子為一個連續的內存。在這個過程中,對于并行產生的零散結果進行拼接時,盡量使用整段內存copy拼接要比遍歷插入效率高很多。

圖5 串行與并行中粒子對存儲情況Fig.5 The storage of particle pairs in serial and parallel compatations
2.3泊松方程求解的并行化方案
在MPS方法中,流體是不可壓的,其壓力是通過對壓力泊松方程的求解得到的。本文所采用的改進的MPS方法[22]中,壓力泊松方程的表達式為:
<2Pn+1>i=(1-γ)
(1)
式中:γ是一個系數,取值范圍為0~1,Lee等[22]建議取值為0.01≤γ≤0.05。
通過對上式進行離散,最終會得到一個關于壓力的稀疏矩陣。而對該矩陣的求解則耗費了絕大部分的計算時間。因此,如何高效地求解稀疏矩陣是提高MPS方法計算效率的關鍵點。
2.3.1 稀疏矩陣的存儲
非零元素的個數遠遠小于元素總數的矩陣被稱為稀疏矩陣。一般來說,一個N階矩陣需要使用N*N的數組來存放,由于零元素并不參與計算,但是數量又很多,這無疑會增加很多不必要的存儲開銷。因此,對于稀疏矩陣需要使用壓縮存儲,這不僅可以節省存儲空間,同時也可以節省計算時間。但使用何種壓縮格式,則需要結合具體問題和實現難易度進行考慮。
本文采用了CSR(行壓縮)的存儲格式。該格式需要三類數據來表達:數值,列號以及行偏移。數值和列號與完全存儲時的情況一致,表示對應元素的值及其列號,行偏移則表示某一行的第一個非零元素在values里面的起始偏移位置。假設有如下稀疏矩陣:

如果采用zero-based索引的話,該矩陣的CSR存儲可表示為:

2.3.2 矩陣求解
稀疏矩陣的求解是科學和工程計算中經常遇到的問題,因此,關于稀疏矩陣求解的研究也取得了很多進展。其中,向量乘法運算(SpMV)是一個關鍵操作,特別是使用迭代法求解時,矩陣向量的乘法運算對計算效率的影響尤為突出。而在GPU平臺上實現稀疏矩陣向量乘法運算則更具有挑戰性。這主要是因為稀疏矩陣存儲格式對GPU訪存的影響,非零元素的隨機分布可以導致線程之間的計算負載不均衡。

圖6 CPU+GPU并行方案圖示 Fig.6 The schematic diagram of CPU+GPU
在CUDA的官方庫中有一些成熟的線性代數庫,最終使用CULA線性代數庫來求解稀疏矩陣。CULA[24]是一個用GPU開發的線性代數求解工具集,能夠求解稀疏矩陣和稠密矩陣,并能達到很可觀的加速比。對于稀疏矩陣,CULA提供了各種常用的迭代方法,比如共軛梯度(CG)、雙共軛梯度(BICG)、穩定雙共軛梯度(BICGSTAB)等。本文計算所采用的迭代方法為穩定雙共軛梯度法(BICGSTAB),這種解法在效率、精度以及穩定性上都有較好的表現。
2.4MPS的CPU+GPU并行方案小結
通過對MLParticle-SJTU求解器中各部分計算時間的分析得知,PartB(鄰居粒子搜尋、核函數計算、粒子對列表構建)與PartD(稀疏矩陣系數生成與稀疏矩陣求解)耗時最多。本文詳細討論了這兩個最耗時部分在GPU上的加速策略。圖6描述了將這兩個模塊進行部分GPU化后整個MPS求解的計算流程。
3 計算與分析
以三維晃蕩問題和三維潰壩問題為研究對象,驗證CPU+GPU加速的可靠性與效率問題。其中,對于潰壩算例本文詳細分析了CPU+GPU相對于單CPU串行時的加速情況。本節中兩個算例所采用的計算平臺均為高性能集群,該計算節點的配置為Intel(R) Xeon(R) CPU E5-2680 v2 @ 2.80GHz,十核心;內存64G;K40 M顯卡,顯存12G,具有2 880個CUDA計算核心。需要指出的是,后文中MLParticle-SJTU計算結果是指單線程串行計算結果,CPU+GPU計算結果則是指CPU串行加GPU并行(鄰居粒子搜尋模塊和泊松方程求解模塊)的計算結果。
3.1三維潰壩模擬
本文計算所采用的潰壩模型如圖7所示,水柱位于液艙的右側,初始時刻在擋板的約束下處于靜平衡狀態,從t=0 s時刻開始自由運動。水柱前面有一個方形障礙物,為了記錄水柱的演化過程,在x=0.992 m,z=0 m處設置了一個水面高度探測器H1,記錄該位置處水面高度隨時間變化曲線。在計算中,總共使用了1 015 793個粒子來模型化該算例,其中652 212為水粒子,其余為邊界粒子,粒子初始間距為0.01 m。
圖8給出了H1位置處水面高度隨時間變化曲線,計算終止在t=4 s,其中實驗結果來自文獻[25]。從圖中可以看到,在t=0.4 s左右,水柱前緣到達H1,此后H1位置處水面迅速上升,在t=1.8 s左右,水面出現一個較大的峰值,這是由于障礙物后面返回的水體經過H1。對比可以看到,數值計算給出的峰值與實驗值有一點差別,但水面的整體變化趨勢和實驗結果是比較接近的。需要說明的是,該算例的流動現象是非常復雜的,自由面變形十分劇烈,對于這樣的流動問題,數值和實驗的完全吻合是十分困難的,盡管如此,整體上看,MLParticle-SJTU和CPU+GPU得到的計算結果與實驗結果基本一致。

圖7 潰壩的幾何尺寸(單位:m)Fig.7 Geometry definition of Dam breaking(unit: m)

圖8 H1位置處水面高度隨時變化曲線Fig.8 The varying curve of elevating head at H1
3.2計算效率分析
對上節中的潰壩算例分別取五種不同的粒子間距來計算分析,具體參數如表2所示。此外,分析計算效率時采用的是計算中間100步的平均值。

表2 不同粒子間距及其對應的粒子數Tab.2 Varied particle spaces and corresponding particle number
3.2.1 鄰居粒子加速情況
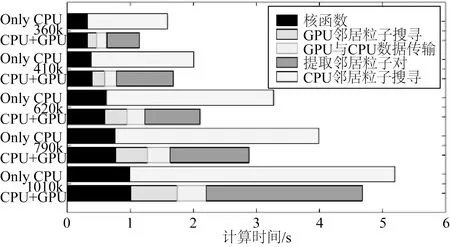
圖9 不同粒子數下PartB各部分計算時間的分布變化 Fig.9 Time distribution of varied particle numbers in PartB
圖9描述了PartB模塊在MLParticle-SJTU與CPU+GPU模式下,五種不同粒子間距的時間分布情況。從整體上來說PartB的GPU+CPU加速效果并不明顯,這是因為隨著GPU加速的應用,鄰居粒子搜尋在PartB中所占的比例相對較小,而隨之產生的數據傳輸、提取鄰居粒子對等額外操作所消耗的時間卻占了較大比重。如果單獨來比較GPU+CPU加速的鄰居粒子搜尋和CPU串行時的鄰居粒子搜尋,則可以發現采用GPU+CPU時有5~10倍的加速比。而諸如數據傳輸,特別是提取鄰居粒子對這些額外操作耗費如此多的時間,主要是因為保存粒子信息的數組太大。比如,當粒子數為1 010 k時,拉普拉斯作用域內的鄰居粒子對為101 447 855左右,而所需分配的顯存大小為4 600 MB左右,如此龐大的數據量需要相當多的數據拷貝時間。同時,如此大的粒子對數也需要非常多的計算時間來提取鄰居粒子對。但實際上,數據拷貝是對連續內存進行整段復制,因此這個效率相對還是較高的。而提取鄰居粒子對則是對分散的數據(N個線程會產生N段數據,在GPU并行中,線程數一般是稍大于粒子數的,因此數據很分散)進行串行重排,因而相對來說耗時也要大許多。總之,數據傳輸以及粒子重排這些額外操作大大降低了加速效果。另外,核函數沒有采用GPU加速也是考慮到這樣做會進一步增加數據傳輸量。
由此可見,雖然GPU加速在鄰居粒子搜尋中能提高數倍的計算效率,但CPU+GPU這種部分GPU化所產生的額外操作大大降低了加速效果。為了充分利用GPU加速可以采用如下改進措施:建立鄰居粒子對信息時,可以將粒子間距稍微大于作用間距的粒子對也進行保存,而在需要使用鄰居粒子對時則進一步檢查是否是真正的鄰居粒子。通過這種方法,可以對粒子對信息進行復用,只需在一定計算步數之后才更新鄰居粒子對信息,從而減少數據傳輸以及串行重排的次數,具體算法可以參考Koshizuka[1]文章中的附錄A。
3.2.2 泊松方程求解的加速情況
在MLParticle-SJTU串行計算時,泊松方程求解所占時間比例高達80%以上,因此有效的加速泊松方程求解對提高計算效率有相當大的意義。圖10是五種不同粒子數下,使用GPU加速后泊松方程求解所對應的加速比。可以看到,加速比在6x~11x左右,隨著粒子數的增多,加速比也有增大的趨勢。此外,為了保證結果具有可比性,CPU+GPU與MLParticle-SJTU對稀疏矩陣求解的迭代精度是相當的。 值得一提的是,GPU計算時間是包括數據傳輸的。雖然需要交換的數據量不小,但是由于是整段內存拷貝傳輸,影響相對較小。
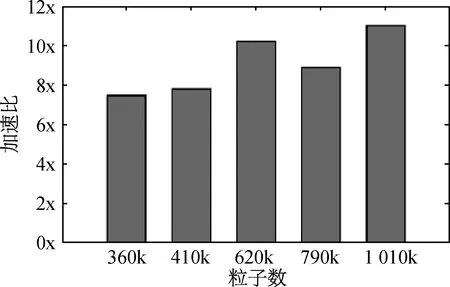
圖10 不同粒子數下CPU+GPU與MLParticle-SJTU泊松方程求解計算時間的分布Fig.10 Time distribution of varied particle numbers of CPU+GPU and MLParticle-SJTU

圖11 不同粒子數下CPU+GPU與MLParticle-SJTU 計算時間分布Fig.11 Time distribution of varied particle numbers of CPU+GPU and MLParticle-SJTU
3.2.3 GPU加速后的整體情況
在分析了PartB和泊松方程求解這些局部的加速情況后,有必要來看看整體時間分布的變化。在對五組數據進行分析后發現,時間占比較大的仍然是PartB和稀疏矩陣的求解,而其它部分所占時間則很少。為了方便起見,將PartB和稀疏矩陣求解之外的其它模塊所耗時間合在了Others中進行比較分析。從圖11中可以看到:1) 采用CPU并行技術能提高MPS的計算效率;2) 使用GPU加速后,PartB所占的比例增大到了30%左右,這是因為稀疏矩陣的求解時間大大減少了,PartB沒有太大的改進,在加速后的時間占比中反而明顯的增加了。
3.3晃蕩算例
液艙的模型尺寸如圖12所示,其中長L=0.79 m,高H=0.48 m,寬W=0.48 m。水深d=0.144 m,對應的充水率為30%。壓力監測點在液艙右側壁面自由面附近,距離液艙底部0.12 m。粒子總數達到了604 k,其中流體粒子422 k,其余為邊界粒子。粒子的初始間距為0.005 m,時間步長為0.001 5 s,重力加速度g=9.81 m/s,水的密度為1 000 kg/m3。液艙的外部激勵方程為:
x=-Acos(ωt)
(2)
式中:A為激勵幅值,取0.057 5 m;ω為外部激勵的圓頻率,取4.49 rad/s。
圖13給出了流動達到劇烈變化時,兩個不同時刻的自由面形狀。可以看到在流體到達右邊頂部以及隨后流體與右側頂部沖擊時,CPU+GPU和MLParticle-SJTU計算結果與實驗所示的自由面形狀都吻合良好。其中,實驗數據源于Chang等[26]。
圖14描述了MLParticle-SJTU和CPU+GPU給出的壓力曲線能夠較好的和實驗相吻合。一次拍擊有兩個壓力峰值,第一個壓力峰值的產生是由于液體水平運動對側壁撞擊造成的,此后液體沿著艙壁向上運動,并在重力的作用下開始下落,從而對底部流體產生第二次拍擊。
圖15描述了晃蕩算例的加速情況。其中,鄰居粒子搜尋部分,CPU+GPU相較于MLParticle-SJTU有11.6x的加速比,但是由于數據傳輸和粒子重排所消耗的時間較多,導致PartB部分的加速只有1.4x;而在泊松方程求解這一塊,加速比則有9.2x;最后,總體上的加速比則為3.2x。可以看到,晃蕩算例所表現出的加速情況與潰壩算例中的結果是相當一致的。

圖12 晃蕩模型尺寸 Fig.12 Geometry definition of sloshing

圖13 不同時刻粒子輪廓比較Fig.13 Comparison of free surface snapshots at different time

圖14 P點拍擊壓力變化曲線對比Fig.14 The varying curve of impact pressure at point P
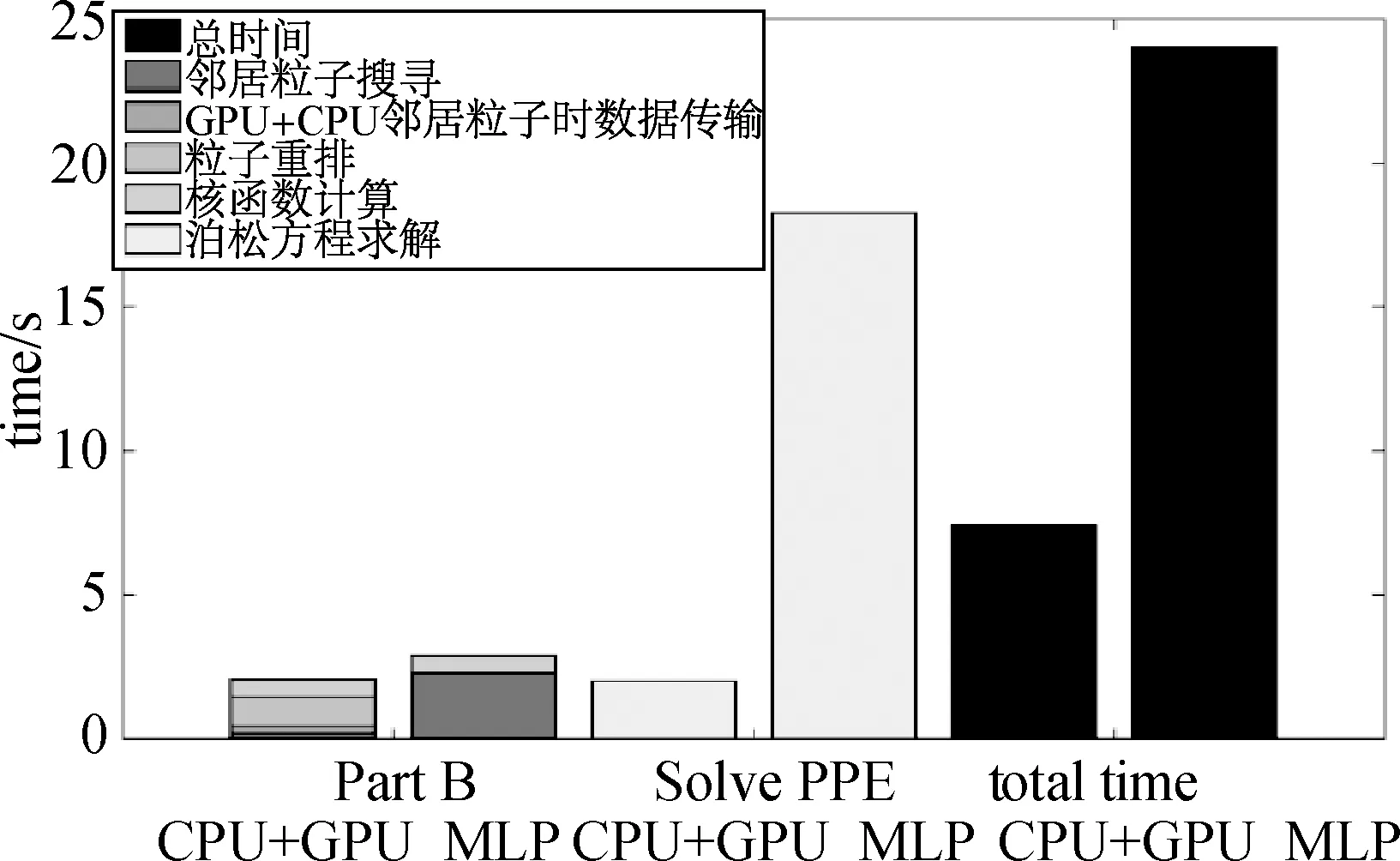
圖15 晃蕩算例加速情況(MLP即 MLparticle-SJTU)Fig.15 Time distribution of sloshing case (MLP is short for MLParticle-SJTU)
4 結 語
本文以CPU+GPU為計算平臺,研究了GPU并行計算技術在三維MPS方法中的應用,并對晃蕩、潰壩等典型自由面問題進行了數值模擬。通過計算結果與實驗值比較,驗證了CPU+GPU并行計算方式在求解水動力學問題中的可靠性與適用性。通過比較CPU+GPU與MLParticle-SJTU的計算時間,可以看到單步CPU+GPU能提高MPS的并行效率。在潰壩流動問題中,泊松方程求解的加速比最高可達11.0x。由此可見,CPU+GPU并行加速能夠有效地提高三維MPS方法的計算效率。
在對MLParticle-SJTU中兩個時間占比最大的模塊,PartB和泊松方程的求解進行GPU加速后可以發現:雖然泊松方程的求解得到了較好的加速,但是PartB加速后的粒子重排與數據傳輸這些額外操作顯著地增加了時間消耗,使得PartB的加速不明顯,因而導致PartB在加速后的時間占比中顯著增大,在一定程度上影響了整體的加速情況。如果要解決這個問題,可以考慮的途徑有:1)對粒子信息進行復用,充分挖掘鄰居粒子鏈表法這種存儲模式的優點;2)考慮實現MPS的全GPU化,從而不再產生這些額外操作。
從整體上來說,CPU+GPU這種并行加速方式可以有效提高MPS的計算效率。但是由于在部分GPU化時會存在與原有程序進行拼接而產生額外的操作,有時這些額外的操作會降低整體的加速比。比如PartB中的鄰居粒子搜尋就說明了額外操作會大大影響整體加速比。因此,在目前部分GPU化的基礎上,將所有計算全部交由GPU處理,并根據GPU的特點充分地利用GPU的加速潛力。
[1] KOSHIZUKA S,NOBE A,OKA Y.Numerical analysis of breaking waves using the moving particle semi-implicit method[J].International Journal for Numerical Methods in Fluids,1998,26(7):751-769.
[2] 張雨新,萬德成.用 MPS 方法數值模擬低充水液艙的晃蕩 [J].水動力學研究與進展,2012,27(1):100-107.(ZHANG Y X,WAN D C.Numerical simulation of liquid sloshing in low-filling tank by MPS[J].Chinese Journal of Hydrodynamics,2012,27(1):100-107.(in Chinese))
[3] ZHANG Y X,TANG Z Y,WAN D C.A parallel MPS method for 3D dam break flows[C]//Proceedings of the 8th Int.Workshop on Ship Hydro.2013:135-139.
[4] IKARI H,GOTOH H.Parallelization of MPS method for 3D wave analysis[C]// Proceedings of the 8th International Conference on Hydro-science and Engineering (ICHE).2008.
[5] GOTOH H,KHAYYER A,Ikari H,et al.Refined reproduction of a plunging breaking wave and resultant splash-up by 3D-CMPS method[C]//Proceedings of the Nineteenth International Offshore and Polar Engineering Conference.International Society of Offshore and Polar Engineers,2009:518-524.
[6] IRIBE T,FUJISAWA T,KOSHIZUKA S.Reduction of communication in parallel computing of particle method for flow simulation of seaside areas[J].Coastal Engineering Journal,2010,52(04):287-304.
[7] ZHANG Y X,YANG Y Q,TANG Z Y,et al.Parallel MPS method for three-dimensional liquid sloshing[C]// Proceedings of the Twenty-fourth International Ocean and Polar Engineering Conference.International Society of Offshore and Polar Engineers,2014:257-264.
[8] HARADA T,KOSHIZUKA S,KAWAGUCHI Y.Smoothed particle hydrodynamics on GPUs[C]// Proceedings of the Computer Graphics International.2007:63-70.
[9] ZHANG Y X,SOLETHALER B,PAJAROLA R.GPU accelerated SPH particle simulation and rendering[C]// Proceedings of the ACM SIGGRAPH 2007 Posters.ACM,2007.
[10] CRESPO A J C,DOMINGUEZ J M,BARREIRO A,et al.GPUs,a new tool of acceleration in CFD:efficiency and reliability on smoothed particle hydrodynamics methods[J].PLoS One,2011,6(6):e20685.
[11] DOMíNGUEZ J M,CRESPO A J C,Gómez-Gesteira M.Optimization strategies for CPU and GPU implementations of a smoothed particle hydrodynamics method[J].Computer Physics Communications,2013,184(3):617-627.
[12] HORI C,GOTOH H,IKARI H,et al.GPU-acceleration for moving particle semi-implicit method[J].Computers & Fluids,2011,51(1):174-183.
[13] 朱小松.粒子法的并行加速及在液體晃蕩研究中的應用 [D].大連:大連理工大學,2011.(ZHU X S.Parallel acceleration of particle method and its application on the study of liquid sloshing [D].Dalian :Dalian University of Technology.(in Chinese))
[14] TANG Z Y,WAN D C.Numerical simulation of impinging jet flows by modified MPS method[J].Engineering Computations,2015,32(4):1 153-1 171.
[15] ZHANG Y X,WAN D C,TAKANORI H.Comparative study of MPS method and level-set method for sloshing flows[J].Journal of Hydrodynamics,Ser.B,2014,26(4):577-585.
[16] 張雨新,萬德成,日野孝則.MPS方法數值模擬液艙晃蕩問題[J].海洋工程,2014,32(4):24-32.(ZHANG Y X,WAN D C,HINO T.Application of MPS method in liquid sloshing[J].The Ocean Engineering,2014,32(4):24-32.(in Chinese))[17] 楊亞強,唐振遠,萬德成.基于MPS方法模擬帶水平隔板的液艙晃蕩[J].水動力學研究與進展,2015,30(2):146-153.(YANG Y Q,TANG Z Y,WAN D C.Numerical study on liquid sloshing in horizontal baffled tank by MPS method[J].Chinese Journal of Hydrodynamics,2015,30(2):146-153.(in Chinese))
[18] 張雨新,萬德成.MPS方法在二維液艙晃蕩中的應用[J].復旦學報:自然科學版,2013,52(5):618-626.(ZHANG Y X,WAN D C.Application of MPS method for 2D liquid sloshing[J].Journal of Fudan Univesity,Natural Science,2013,52(5):618-626.(in Chinese))
[19] 張馳,張雨新,萬德成.SPH方法和MPS方法模擬潰壩問題的比較分析[J].水動力學研究與進展,2011,26(6):736-746.(ZHANG C,ZHANG Y X,WAN D C.Comparative study of SPH and MPS methods for numerical simulations of dam breaking problems[J].Chinese Journal of Hydrodynamics,2011,26(6):736-746.(in Chinese))
[20] 張雨新,萬德成.MPS 方法在三維潰壩問題中的應用[J].中國科學物理學力學天文學,2011,41(2):140-154.(ZHANG Y X,WAN D C.Application of MPS in 3D dam breaking flows[J].Scientia Sinica Physica,Mechanica & Asstronomica,2011,41(2):140-154.(in Chinese))
[21] CUDA_C_Programming_Guide[R].NVIDIA,CUDA Toolkit Doc,2015.
[22] LEE B H,PARK J C,KIM M H,et al.Step-by-step improvement of MPS method in simulating violent free-surface motions and impact-loads[J].Computer Methods in Applied Mechanics and Engineering,2011,200(9):1 113-1 125.
[23] DOMINGUEZ J M,CRESPO A J C,GóMEZ-GESTEIRA M,et al.Neighbour lists in smoothed particle hydrodynamics[J].International Journal for Numerical Methods in Fluids,2011,67(12):2 026-2 042.
[24] CULA (GPU-Accelerated LAPACK)[ED/OL].http://www.culatools.com/.
[25] KLEEFSMAN K,FEKKEN G,VELDMAN AEP,et al.A volume-of-fluid based simulation method for wave impact problems[J].Journal of Computational Physics,2005,206(1):363-393.
[26] SONG Y K,CHANG K A,RYU Y,et al.Experimental study on flow kinematics and impact pressure in liquid sloshing[J].Experiments in Fluids,2013,54(9):1-20.
Application of GPU acceleration techniques in 3D violent free surface flows
LI Haizhou1,2,TANG Zhenyuan1,2,WAN Decheng1,2
(1.State Key Laboratory of Ocean Engineering,School of Naval Architecture,Ocean and Civil Engineering,Shanghai Jiao Tong University,Shanghai 200240,China; 2.Collaborative Innovation Center for Advanced Ship and Deep-Sea Exploration,Shanghai 200240,China)
O353
A
10.16483/j.issn.1005-9865.2016.05.003
萬德成。 E-mail:dcwan@sjtu.edu.cn
1005-9865(2016)05-0020-10
2015-10-26
國家自然科學基金資助項目(51379125,51490675,11432009,51579145,11272120);長江學者獎勵計劃(T2014099);上海東方學者崗位跟蹤計劃(2013022);工信部數值水池創新專項VIV/VIM項目(2016-23/09)
李海洲(1991-),男,碩士,主要從事GPU并行技術在無網格粒子法中的應用。E-mail:dxlhz@foxmail.com
猜你喜歡
甘肅教育(2020年14期)2020-09-11 07:57:42
中學生數理化(高中版.高考數學)(2020年5期)2020-06-02 09:19:08
兒童故事畫報(2019年5期)2019-05-26 14:26:14
商周刊(2017年9期)2017-08-22 02:57:49
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
時代英語·高二(2015年1期)2015-03-16 00:08:11
中國衛生(2014年11期)2014-11-12 13:11:32
