自適應觀測權重的目標跟蹤算法*
2016-10-12 02:38:57劉行,陳瑩
計算機與生活 2016年7期
關鍵詞:模型
劉 行,陳 瑩
江南大學 輕工過程先進控制教育部重點實驗室,江蘇 無錫 214122
自適應觀測權重的目標跟蹤算法*
劉行,陳瑩+
江南大學 輕工過程先進控制教育部重點實驗室,江蘇 無錫 214122
LIU Xing,CHEN Ying.Target tracking algorithm based on adaptive observation weight.Journal of Frontiers of Computer Science and Technology,2016,10(7):1010-1020.
針對視覺跟蹤在復雜場景中跟蹤精度較低和魯棒性較差的問題,在貝葉斯框架下提出了一種自適應觀測權重的目標跟蹤算法。通過視覺跟蹤中的線性表示模型構建出一種加權觀測模型;提出一種基于迭代加權的模型優化算法,利用在線更新的自適應權重矩陣消除觀測離群值對跟蹤有效性的影響;最后,采用有效的似然評估函數實現對目標準確、魯棒的跟蹤。實驗結果表明,該算法在跟蹤精度和魯棒性方面都優于現有的一些跟蹤算法。
視覺跟蹤;線性表示;在線更新;離群值;自適應權重矩陣
1 引言
目標跟蹤技術作為計算機視覺領域的重要課題已廣泛運用于人機交互、視頻監控、智能交通、航空航天等諸多領域。目前,雖然視覺跟蹤領域已經產生一些比較優秀的跟蹤算法[1-4],但是在實際場景中由于存在光照變化、部分遮擋、低分辨率、目標形體變化及突然運動等諸多因素的干擾,設計出魯棒、高效的跟蹤算法仍然是一個具有挑戰性的難題。
視覺跟蹤領域已經提出的跟蹤算法大體分為兩類:判別式算法[5-7]和產生式算法[1,8-9]。判別式算法將目標跟蹤看成一個二分類問題,從背景中區分出感興趣的前景目標。產生式算法通過搜索與目標模型相似度最高的候選目標區域來進行跟蹤。在產生式跟蹤器中,基于線性表示模型的跟蹤算法引起了廣泛重視,出現了一些不錯的跟蹤算法[1,10-11],其中最突出的算法是Ross等人提出的IVT(incremental visual tracking)跟蹤器[1]。IVT在貝葉斯推理框架中通過PCA(principal component analysis)子空間對目標進行線性表示和在線增量學習的方式對子空間進行更新,取得了較好的跟蹤效果,但由于IVT跟蹤器將誤差項看成是高斯分布的,構建出的模型對由部分遮擋、突然運動等干擾因素引起的離群值(離群值是指一組數據中與其他數值相比差異較大的數值)非常敏感,因此對于部分遮擋和突然運動等非常不魯棒。為解決跟蹤器對離群值的敏感性問題,Mei等人[12]利用目標模板和瑣碎模板重構候選目標,提出了L1跟蹤器,通過稀疏表示解決L1最小化問題去估計真實目標位置,但是存在L1最小化耗時非常嚴重的問題。Bao等人[13]提出了一種加速的近端梯度下降法進一步緩解L1最小化問題,但是在復雜場景中跟蹤效果仍然不理想。Wang等人在文獻[9]中提出了一種軟閾值跟蹤算法,將誤差項看成是高斯-拉普拉斯分布,取得了一定的效果,但在具有眾多干擾項的場景中仍存在跟蹤精度較低和魯棒性較差的問題。Wang等人[14]將正常值看成是高斯分布,離群值看成是均勻分布,提出了概率離群模型的跟蹤算法,但這種對于離群值的處理仍然不夠理想,還是會在一些復雜場景中出現跟蹤漂移等問題。Xiao等人將L2范數用于視覺跟蹤領域提出了L2跟蹤器[15-16],利用Square模板[17]去構建誤差項,取得了一定的效果,但在強烈光照、部分遮擋等因素同時干擾時容易漂移和跟蹤失敗,并且魯棒性較低。由于上述跟蹤器大多將誤差項看成是高斯分布或拉普拉斯分布,在沒有眾多干擾因素下是滿足的,然而在實際中,特別是存在遮擋,目標突然運動等干擾時,誤差項的分布是遠離高斯或拉普拉斯分布的,就會對離群值非常敏感,造成跟蹤算法失效。
針對當前跟蹤算法對離群值敏感,導致在復雜場景中跟蹤有效性和穩定性較低的問題,提出了一種自適應觀測權重的目標跟蹤算法(adaptive observation weighted tracking,AOWT)。算法未對觀測誤差作概率分布假設,而是通過重寫誤差項,利用線性表示模型[1]構建出一種加權觀測模型,然后建立一種基于迭代加權的模型優化算法求解該模型,并且通過不斷在線更新的自適應權重矩陣緩解并消除離群值對跟蹤有效性的影響,進而建立似然評估函數精確、魯棒地跟蹤目標。
2 目標跟蹤框架
視覺跟蹤的兩個核心部分就是運動模型和觀測模型。本文在貝葉斯推理框架[1]下進行目標跟蹤,跟蹤框架流程圖如圖1所示。
圖1中,首先由運動模型產生候選樣本狀態,然后通過觀測模型評估運動模型產生的候選狀態,得到最佳的候選狀態后,通過增量PCA方法[1]更新觀測模型,進行下一幀跟蹤,最終實現對目標準確有效的跟蹤。其中運動模型和觀測模型的定義過程如下。
給定目標在第t幀的觀測向量Zt={z1,z2,…,zn},n是觀測向量的維數,觀測向量Zt是指在當前幀目標圖像周圍提取的候選目標圖像塊;,是第t幀目標的位置變量,其中xit表示第i個樣本的位置狀態。然后可以通過式(1)最大后驗估計法得到最優的目標位置。

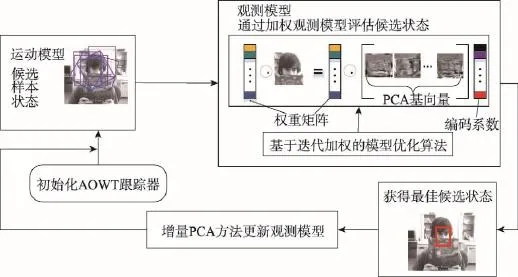
Fig.1 Flowchart of tracking framework圖1 跟蹤框架流程圖
通過貝葉斯推理框架可以遞歸地求出后驗概率p(Xt|Zt),如式(2)所示:
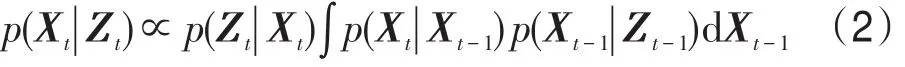
式中,p(Xt|Xt-1)表示連續兩幀之間的運動模型;p(Zt|Xt)是跟蹤系統中的觀測模型,也叫觀測似然函數。
本文采用IVT[1]中6個仿射參數的方法來描述目標的運動模型,通過該模型產生候選樣本狀態,表示第i個樣本在第t幀的目標狀態量。其中是目標中心在x方向和y方向的平移量;表示旋轉角;表示尺度變化量;表示高寬比;表示傾斜角。然后通過高斯分布來建模運動模型,如式(3)所示:
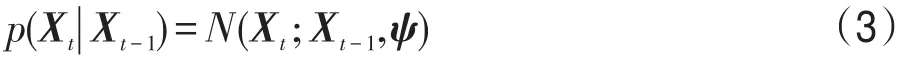
其中,N表示高斯分布;ψ是對角協方差矩陣,ψ中的元素由仿射參數的方差構成[1]。
觀測模型在跟蹤系統中有著重要的作用,往往對跟蹤的有效性和魯棒性有很大影響,本文提出一種加權觀測模型來評估候選樣本,得出最準確穩定的候選狀態,利用增量PCA方法[1]更新觀測模型,最終提出一種自適應觀測權重的目標跟蹤算法。
3 自適應觀測權重的目標跟蹤
首先通過問題分析提出本文的基本思想,然后具體介紹構建加權觀測模型的過程,進而提出基于迭代加權的模型優化算法去求解觀測模型。
3.1問題分析
由線性表示模型[1]可知,在第t幀目標的觀測向量集Zt可以表示為:

上式就是通過A和βt對Zt進行編碼。其中Zt是n維的觀測向量;βt∈Rq×1是q維的編碼系數向量;A=[a1,a2,…,aq]∈Rn×q是由若干幀跟蹤結果構成的圖像子空間的PCA基向量矩陣;e是編碼誤差項。
由于離群值像素通常發生在目標被遮擋或低分辨率的區域,相當于Zt中包含了離群值像素,而A仍然是根據前若干幀跟蹤結果的圖像子空間得到的,顯然此時的編碼誤差e=Zt-Aβt會明顯增大,如果不對離群值進行處理,就會造成編碼的失效與不穩定,進而導致跟蹤失敗。目前大多數跟蹤器[9,14,18-19]都將誤差分布看成高斯或拉普拉斯分布構建出觀測模型,這樣的模型對跟蹤過程中出現的離群值(通常是由遮擋、低分辨、突然運動等引起的)非常敏感。為了解決編碼過程中對離群值敏感的問題,本文的基本思想是沒有直接將誤差項看成是高斯或拉普拉斯分布,而是通過重寫誤差項,建立一個與各數據點(像素點)有關的權重矩陣來構建出一種加權觀測模型。該權重矩陣滿足對編碼誤差大的點(離群值點)給予較小的權重,誤差較小的點給予較大的權重(權重矩陣作用示意圖如圖2所示),然后提出一種基于迭代加權的模型優化算法,通過反復迭代以改進權重系數,消除離群值對編碼有效性的影響,最終得到最佳的編碼系數βt。
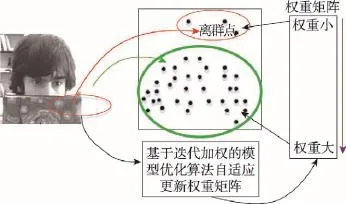
Fig.2 Weight matrix effect schematic圖2 權重矩陣作用示意圖
3.2加權觀測模型
為了建立加權觀測模型,可由式(4)重寫誤差項為:
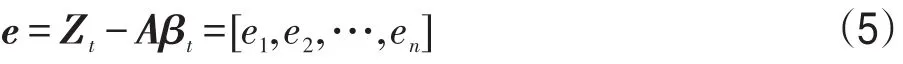
其中,e的元素為ei=zi-aiβt,i=1,2,…,n。
假設e1,e2,…,en是獨立同分布的,并且它們的概率密度函數為gθ(ei),θ是表示特征分布的參數集,可得該估計量的似然函數如式(6)所示:
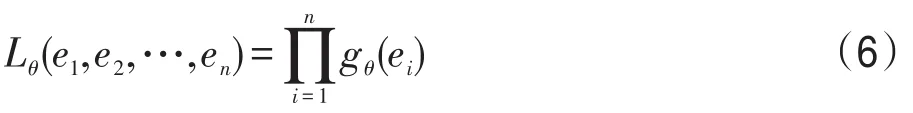
最大似然估計的目的是最大化式(6),等同于最小化式(7):
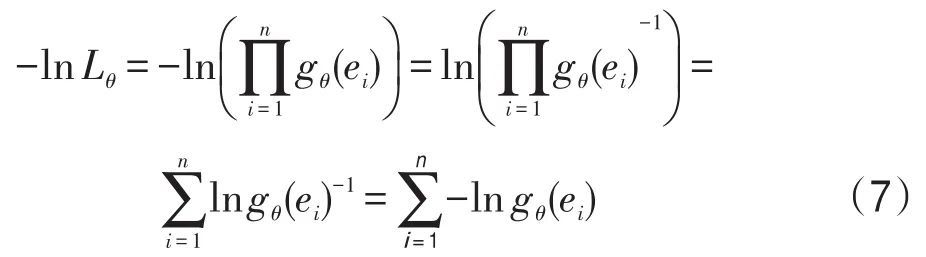
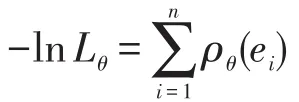
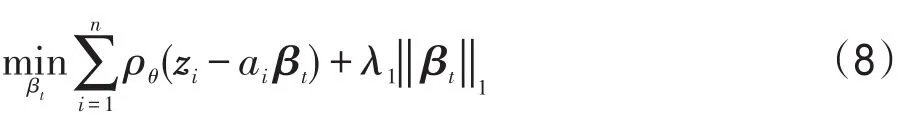
通常情況下,可假設誤差項的概率密度函數gθ(ei)是對稱的,且當|ei|<|ej|時gθ(ei)
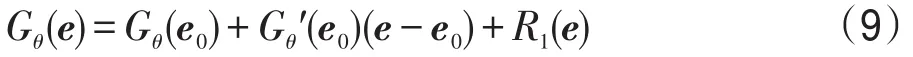
其中,Gθ′(e0)是Gθ(e)的一階導數Gθ′(e)在e0處的函數值,Gθ′(e0)=[ρθ′(e0,1);ρθ′(e0,2);…;ρθ′(e0,n)],e0,i是e0的第i個元素;R1(e)是高階殘余項。
在編碼過程中,為了使最小化更容易,一般要求Gθ(e)是凸函數,故這里可以將 R1(e)近似為 R1(e)≈(e-e0)W(e-e0)/2[20]。因為e中的元素是獨立的,并且沒有ei與ej(i≠j)的交叉項,所以W是一個對角矩陣。由 ρθ(ei)的性質可知,Gθ(e)在e=0時取得極小值,令Gθ′(0)=0可得W的對角元素Wi,i如式(10)所示:
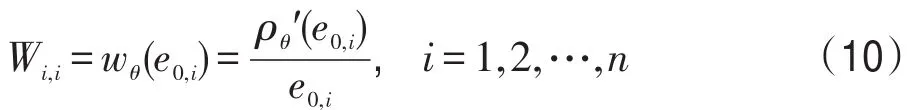
由 ρθ(ei)的性質可知,ρθ′(e0,i)與e0,i有相同的符號,則Wi,i是大于0的標量。由文獻[20]可知,式(9)可以被重寫為式(11):

b是和e0有關的一個常量,又因為e=Zt-Aβt,所以式(8)可以近似為式(12):
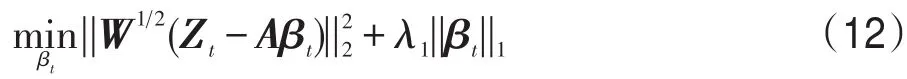
其中,||?||2表示L2范數;W是一個對角矩陣,作用于測試圖像的每一個像素。直觀上,在跟蹤過程中,為了緩解在編碼Zt時由于部分遮擋、突然運動等造成的離群值像素對編碼有效性的影響,此時應該給離群值像素賦予很小的權重值,即Wi,i的值很小,這樣就會減少離群值對跟蹤的影響。考慮到文獻[21]中的logistic函數具有這樣的性質,故可定義權重函數wθ(ei):
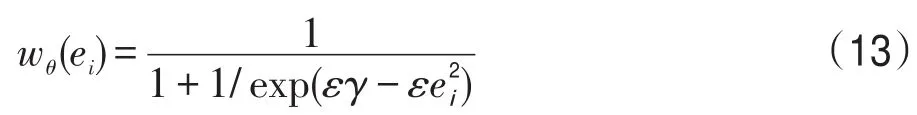
其中,ε和γ是大于0的常量,ε控制從1到0的下降率,γ控制分界點的位置,當誤差的平方大于γ時,權重值減小到0.5。
由3.1節的分析已經知道存在離群值像素的地方會導致編碼誤差ei過大,即當式(13)中的ei較大時,會使得exp(εγ-εei2)較小,從而導致式(13)的分母1+1/exp(εγ-εei2)較大,此時wθ(ei)就會取得較小值,因此該權重函數的定義保證了離群值像素處賦予小的權重值。同理,當編碼誤差ei偏小時,通過式(13)會賦予大的權重值,這樣就保證了編碼誤差不同處的像素被賦予合適的權重值,達到了自適應更新觀測權重的目的。在3.3節具體的優化算法中利用相鄰迭代權重比的約束會進一步提高自適應能力。為了使跟蹤對于離群值更加魯棒,在實際算法中將ε 和γ都定義為與編碼誤差有關的常量,定義如下:

式中,Γa是Γ=[e12,e22,…,en2]經過升序排列之后得到的;h=?λ2n?,λ2∈(0,1],?λ2n?表示取不超過λ2n的最大整數。定義ε的值為ε=λ3/γ,其中λ3是大于0的常量,本文取λ3=8。
3.3基于迭代加權的模型優化算法
3.3.1迭代加權模型優化算法的提出
本節通過基于迭代加權的模型優化算法求解觀測模型,在迭代過程中通過式(13)來自適應更新權重矩陣W,消除離群值對跟蹤有效性和魯棒性的影響。直接采用L1-Ls[22]來計算式(12)非常耗時,因為式(12)是L1正則約束的最小化問題,由于L1正則化的目標函數在0處是不可導的,所以導致求解最小化比較復雜耗時。考慮到L2正則化的目標函數是一個二次函數,在0處是可導的,可以直接通過二次函數的導數為0來計算最小化問題,這樣就會大大節省計算時間。又因為L2正則約束與L1相比唯一的區別是L2的稀疏性比L1要弱,在文獻[23]中已經證明了稀疏性并不是影響編碼效果的本質原因,并且利用L2范數代替L1范數進行編碼求解取得與之前一樣甚至更好的效果,因為L2范數能防止模型的過擬合問題。故式(12)可以通過L2正則約束來求解最小化問題(下文實驗結果的定量分析中用AOWT(L1)表示利用L1-Ls來計算式(12)的AOWT算法,AOWT(L2)表示通過L2最小化來計算式(12)的AOWT算法),可設L2正則化二次函數為式(15):
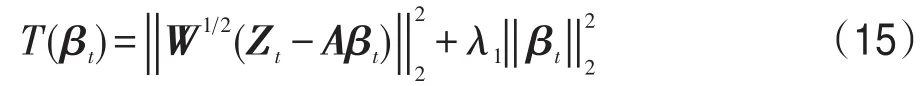

因為T(βt)是一個凸函數,所以令T(βt)的導數T′(βt)=0可以得到每次迭代最優的為:

基于迭代加權的模型優化算法流程如下所示。
算法1基于迭代加權的模型優化算法
輸入:Zt,Zt_mean,A,其中Zt_mean為Zt的均值向量。
輸出:βt。
(1)第一次迭代k=1,k表示迭代次數。
(2)計算誤差e(k)=Zt-Zt(k),且令Zt(1)=Zt_mean,其中Zt(k)表示第k次迭代的重構觀測向量。
(3)計算第k次迭代的權重wθ(ei(k)):
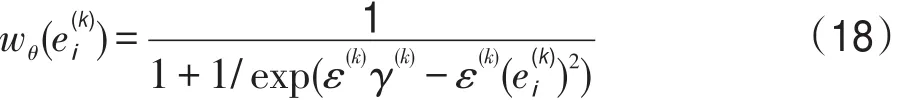
其中ε(k)、γ(k)表示第k次迭代的ε和γ。
(7)重復步驟(2)~(6),直到連續5次迭代滿足
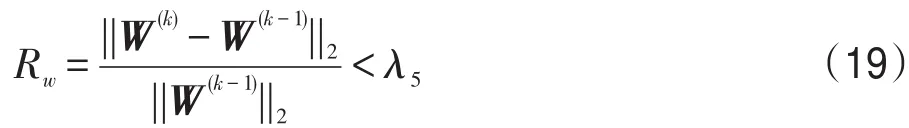
或滿足k=kmax。其中λ5是大于0任意小的常量,本文取λ5=0.01;kmax表示最大迭代次數,本文取kmax=10。
通過上述基于迭代加權的模型優化算法得到輸出的βt,根據文獻[12]可定義似然評估函數如式(20)所示:
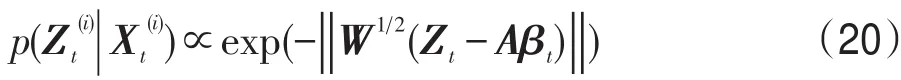
最后采用增量PCA方法[1]對本文提出的AOWT跟蹤器的觀測模型進行在線更新。
3.3.2算法的收斂性分析
式(17)是式(8)的局部近似解,上述模型優化算法的每一次迭代都會使得式(8)的目標函數值減小,由于式(8)的非負稀疏約束,故隨著迭代的不斷進行,算法將會達到收斂[20]。
在具體優化算法中,如算法1中步驟(7)所示,當相鄰迭代的權重差異比Rw連續5次迭代均小于一個大于0任意小的常量時,認為算法達到收斂,迭代停止。
3.3.3算法的復雜度分析
4 實驗結果及性能分析
4.1實驗裝置與評價標準
實驗仿真均在Matlab R2010b,Window8.1系統,Pentium?Dual-Core CPU處理器,3.20 GHz主頻和4 GB內存的計算機環境下編程實現。為了驗證本文算法的有效性,將本文提出的AOWT跟蹤器與IVT跟蹤器[1]、L2RLS跟蹤器[16]、KCF跟蹤器[3]、RPT跟蹤器[24]在8個富有挑戰性的視頻序列中做了對比實驗,AOWT與IVT、L2RLS采用的抽樣粒子數均為600。
本文采用文獻[25]中評估跟蹤算法性能的兩個重要指標,平均中心位置誤差(average center location error,ACLE)和重疊精度(overlap precision,OP)來衡量跟蹤算法的有效性。其中ACLE表示跟蹤算法估計的目標中心位置與手動標記的ground-truth之間的平均歐式距離。OP表示跟蹤算法標記的跟蹤框與文獻[25]中手動標記的跟蹤框之間的重疊度SAOR超過一定閾值th(th∈[0,1])的幀數相對于視頻序列總幀數的百分比(實驗均采用與文獻[24]中相同的閾值th=0.5)。重疊度的定義為:

其中,rt表示跟蹤邊界框的區域;rg表示ground-truth中標準跟蹤邊界框的區域;area表示求區域的面積。
4.2實驗結果與分析
4.2.1定性分析
所有跟蹤器的跟蹤結果對比圖如圖3所示。本文提出的AOWT跟蹤器的跟蹤框采用紅色實線標記,IVT跟蹤器采用藍色點劃線標記,L2RLS跟蹤器采用綠色虛線標記,KCF跟蹤器采用黑色點線標記,RPT跟蹤器采用黃色點劃線標記但線寬比IVT的線寬粗。
(1)尺度變化和光照變化
在Singer1序列中,剛開始各算法都能較好跟蹤,在98幀由于有著強烈的光照變化,除了AOWT跟蹤器和L2RLS跟蹤器能準確跟蹤目標以外,其他跟蹤器都已跟蹤漂移,隨著尺度的不斷變化,最后只有AOWT能一直穩定跟蹤目標。在DavidIndoorNew序列中,目標從黑暗的環境中慢慢走向光亮的地方,197幀時L2RLS跟蹤器出現了輕微的跟蹤漂移,其他算法均能較好跟蹤,在496幀時,由于同時伴有尺度和摘戴眼鏡等干擾,L2RLS出現很大程度的跟蹤漂移,RPT尺度變化失敗,最后只有AOWT、IVT、KCF能較準確地跟蹤目標。在Caviar1中待跟蹤目標漸漸地遠離攝像機,尺度越來越小,可以看出KCF不能適應這樣的尺度變化,到193幀時目標被其他行人遮擋,IVT出現跟蹤漂移,最后只有AOWT和L2RLS能很好地處理目標的尺度變化,并保持有效的跟蹤。
(2)嚴重遮擋和目標旋轉
在Faceocc2序列中,在前幾十幀的時候,各跟蹤器都能基本保持良好跟蹤,164幀中目標被書本遮擋,IVT出現了漂移,其他跟蹤器都能準確跟蹤,但到423幀時,目標被書本遮擋,同時伴隨著頭部旋轉,只有AOWT仍能很好地適應旋轉變化,其他算法都已跟蹤漂移。在Caviar2序列中,剛開始待跟蹤目標沒有被其他行人遮擋時各算法均能較好跟蹤,192幀時目標被遮擋,KCF和RPT出現了漂移,其他算法可以保持跟蹤,到485幀時,L2RLS算法已經基本失效,IVT算法也錯誤跟蹤到旁邊的其他行人上,只有AOWT跟蹤器仍能良好跟蹤目標。在Caviar3序列中,開始的時候目標沒有什么較大的干擾,各跟蹤器都能比較準確地跟蹤目標,71幀時當目標從左邊走向右邊,先是被穿紅色衣服的行人嚴重遮擋,然后又被穿黑色衣服的行人遮擋,兩次嚴重遮擋之后,只有AOWT算法能準確穩定地跟蹤目標,其他算法都已經漂移甚至失敗。

Fig.3 Tracking results comparison of different algorithms圖3 各算法跟蹤結果對比圖
(3)運動模糊、形體變化和攝像機抖動
在Owl序列中,剛開始的時候沒有出現攝像機抖動,待跟蹤目標比較清晰,各跟蹤器都能較好跟蹤;到46幀時,由于嚴重的攝像機抖動導致目標變得很模糊,除了AOWT,其他算法都出現了不同程度的跟蹤漂移現象;383幀時攝像機抖動得更加劇烈,目標嚴重模糊,此時其他跟蹤器都已跟蹤失敗,只有本文提出的AOWT跟蹤器仍能準確地跟蹤,一直到最后,AOWT都保持著準確穩定的跟蹤。在Face序列中,125幀時IVT和RPT出現跟蹤漂移,伴隨著攝像機長時間抖動,到305幀時KCF算法也偏移了目標,最后只有AOWT跟蹤器和L2RLS跟蹤器能較好地跟蹤目標。
由以上可以看出,本文提出的AOWT跟蹤器一直保持準確跟蹤,而其他跟蹤器大部分都會出現跟蹤漂移,可見本文算法的性能優于其他算法。
4.2.2定量分析
(1)各算法的平均中心位置誤差(ACLE)和重疊精度(OP)
如表1和表2所示,中心位置誤差(center location error,CLE)曲線圖如圖4所示。其中,AOWT(L1)表示直接采用L1-Ls[22]工具包來計算式(12)的AOWT算法,AOWT(L2)表示利用L2最小化,通過式(17)來求解式(12)的AOWT算法。從表格和曲線圖可以看出,AOWT算法在跟蹤過程中平均中心位置誤差小,重疊精度高,可見本文提出的AOWT算法在有效性和魯棒性方面都優于其他算法。因為AOWT(L1)算法與AOWT(L2)算法唯一的區別僅僅在于計算式(12)的方法不同,所以它們的ACLE和OP基本差不多,主要體現在跟蹤速度上的不同。
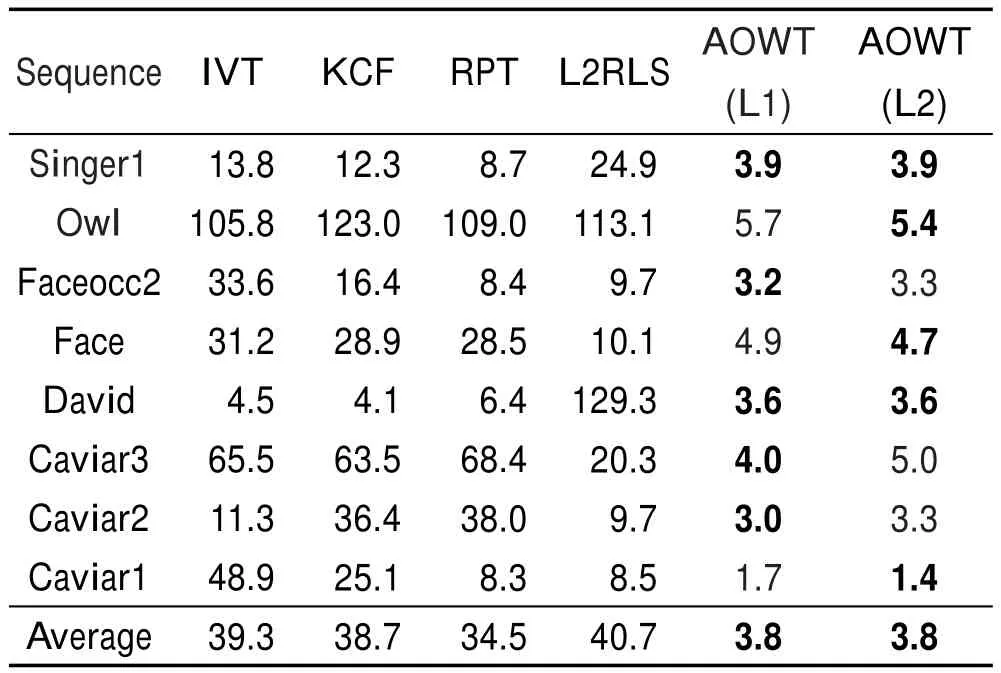
Table 1 Average center location error of different algorithms表1 跟蹤算法的平均中心位置誤差pixel
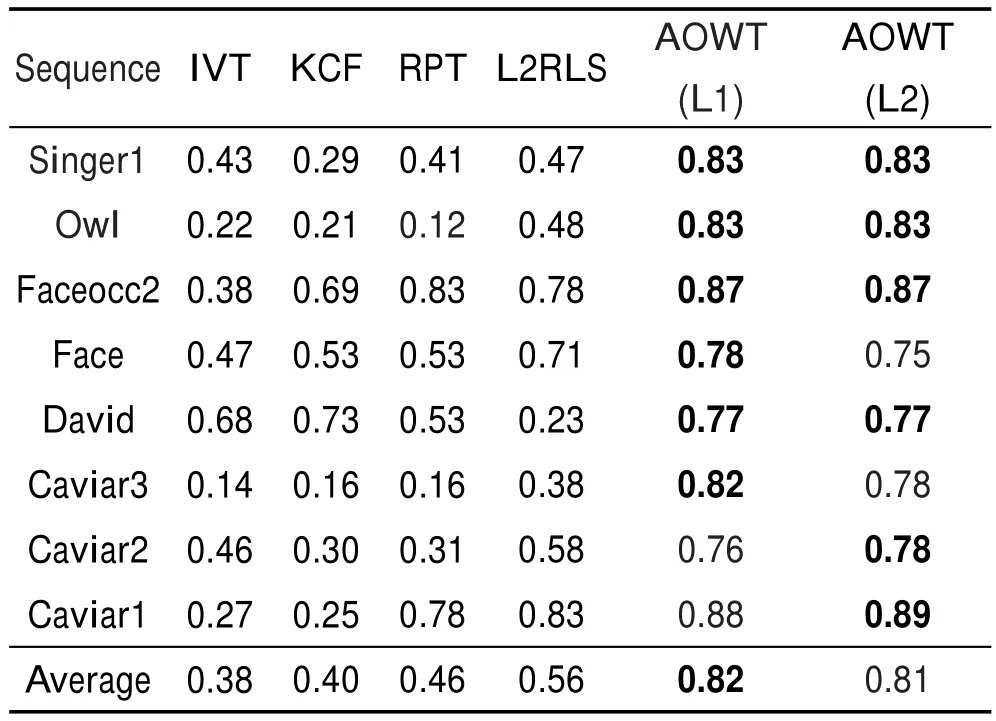
Table 2 Overlap precistion of different algorithms表2 跟蹤算法的重疊精度
(2)跟蹤速度分析
各跟蹤器在不同視頻序列中的跟蹤速度如表3所示。首先從表3中可以明顯看出,直接利用L1-Ls[22]工具包求解的AOWT算法(AOWT(L1))的跟蹤速度比采用L2最小化求解的AOWT算法(AOWT(L2))的跟蹤速度慢很多。另外,從表3中可見,KCF的速度最快,其次是IVT和AOWT(L2),KCF本身就是致力于高速的研究,利用循環結構通過離散傅里葉變換計算分類器的響應,減少了時間的消耗,但KCF的跟蹤精度和魯棒性明顯不如本文提出的AOWT(L2)跟蹤器。AOWT(L2)的跟蹤速度比IVT慢一點,但跟蹤精度卻大大提升了,而其他算法的跟蹤速度比AOWT(L2)都要慢。
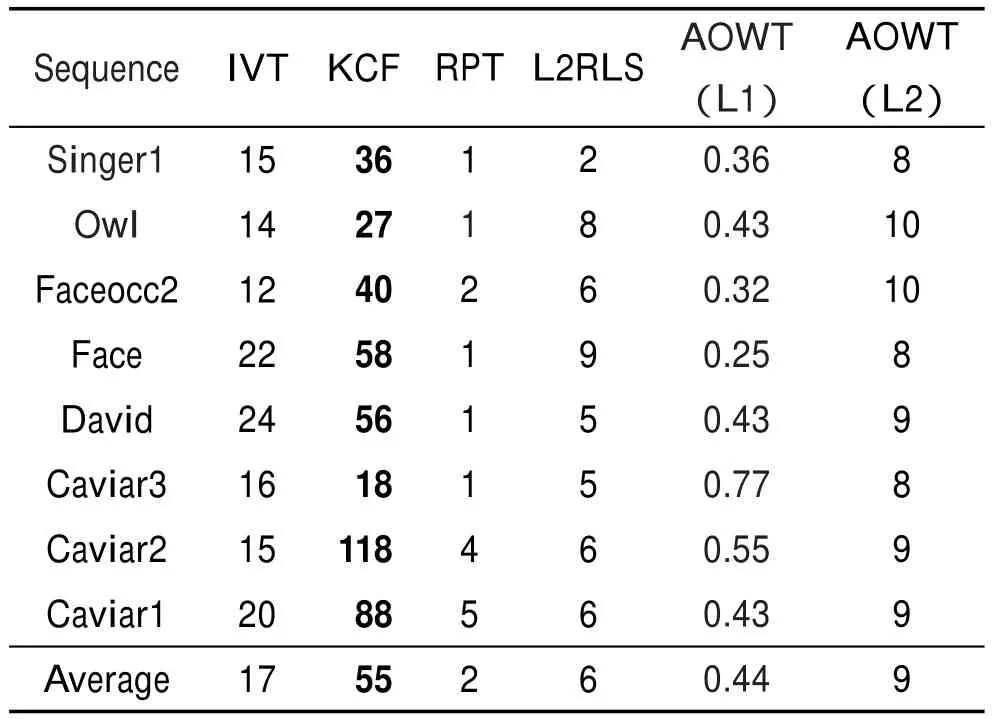
Table 3 Speed comparison of different trackers表3 各跟蹤器的速度比較 f/s
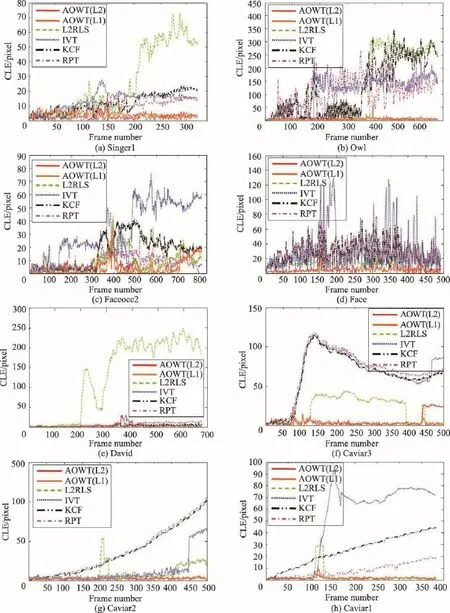
Fig.4 Center location error of different algorithms圖4 各算法的中心位置誤差圖
5 結束語
本文提出了一種自適應觀測權重的目標跟蹤算法,通過線性表示模型構建出一種加權觀測模型;然后建立一種基于迭代加權的模型優化算法計算該模型,通過在線更新的自適應權重矩陣消除離群值對跟蹤有效性的影響,最后建立似然評估函數實現對目標精確的跟蹤。實驗結果證明了AOWT跟蹤器的有效性和魯棒性。此外,本文算法仍然存在需要完善的地方,未來的工作主要致力于進一步提高觀測模型的魯棒性以及算法的優化問題,使得跟蹤算法的精度更高,速度更快。
[1]Ross D A,Lim J,Lin R S,et al.Incremental learning for robust visual tracking[J].International Journal of Computer Vision,2008,77(1/3):125-141.
[2]Kalal Z,Mikolajczyk K,Matas J.Tracking-learning-detection[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2012,34(7):1409-1422.
[3]Henriques J F,Caseiro R,Martins P,et al.High-speed tracking with kernelized correlation filters[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2015,37(3): 583-596.
[4]Zhang Kaihua,Zhang Lei,Liu Qingshan,et al.Fast visual tracking via dense spatio-temporal context learning[M].[S.l.]: Springer International Publishing,2014:127-141.
[5]Grabner H,Bischof H.On-line boosting and vision[C]//Proceedings of the 2006 IEEE Computer Society Conference on Computer Vision and Pattern Recognition,New York, USA,Jun 17-22,2006.Piscataway,USA:IEEE,2006,1:260-267.
[6]Henriques J F,Rui C,Martins P,et al.Exploiting the circulant structure of tracking-by-detection with kernels[C]// LNCS 7575:Proceedings of the 12th European Conference on Computer Vision,Florence,Italy,Octr 7-13,2012.Berlin,Heidelberg:Springer,2012:702-715.
[7]Hare S,Saffari A,Torr P H S.Struck:structured output tracking with kernels[C]//Proceedings of the 2011 IEEE International Conference on Computer Vision,Barcelona, Spain,Nov 6-13,2011.Piscataway,USA:IEEE,2011:263-270.
[8]Mei Xue,Ling Haibin.Robust visual tracking and vehicle classification via sparse representation[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2011, 33(11):2259-2272.
[9]Wang Dong,Lu Huchuan,Yang M H.Least soft-threshold squares tracking[C]//Proceedings of the 2013 IEEE Conference on Computer Vision and Pattern Recognition,Portland,USA,Jun 23-28,2013.Piscataway,USA:IEEE, 2013:2371-2378.
[10]Zhang Tianzhu,Ghanem B,Liu Si,et al.Robust visual tracking via multi-task sparse learning[C]//Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition,Providence,USA,Jun 16-21,2012.Piscataway,USA:IEEE,2012:2042-2049.
[11]Wang Dong,Lu Huchuan,Yang M H.Online object tracking with sparse prototypes[J].IEEE Transactions on Image Processing,2013,22(1):314-325.
[12]Mei Xue,Ling Haibin.Robust visual tracking using ?1 minimization[C]//Proceedings of the 2009 IEEE 12th International Conference on Computer Vision,Kyoto,Japan,Sep 29-Oct 2,2009.Piscataway,USA:IEEE,2009:1436-1443.
[13]Bao Chenglong,Wu Yi,Ling Haibin,et al.Real time robust L1 tracker using accelerated proximal gradient approach [C]//Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition,Providence,USA,Jun 16-21,2012.Piscataway,USA:IEEE,2012:1830-1837.
[14]Wang Dong,Lu Huchuan.Visual tracking via probability continuous outlier model[C]//Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus,USA,Jun 23-28,2014.Piscataway,USA:IEEE, 2014:3478-3485.
[15]Xiao Ziyang,Lu Huchuan,Wang Dong.Object tracking with L2-RLS[C]//Proceedings of the 2012 21st International Conference on Pattern Recognition,Tsukuba,Japan,Nov 11-15,2012.Piscataway,USA:IEEE,2012:1351-1354.
[16]Xiao Ziyang,Lu Huchuan,Wang Dong.L2-RLS-based object tracking[J].IEEE Transactions on Circuits and Systems for Video Technology,2014,24(8):1301-1309.
[17]Shi Qinfeng,Eriksson A,van den Hengel A,et al.Is face recognition really a compressive sensing problem?[C]//Proceedings of the 2011 IEEE Conference on Computer Vision and Pattern Recognition,Providence,USA,Jun 20-25, 2011.Piscataway,USA:IEEE,2011:553-560.
[18]Li Xi,Hu Weiming,Zhang Zhongfei,et al.Visual trackingvia incremental log-Euclidean Riemannian subspace learning [C]//Proceedings of the 2008 IEEE Conference on Computer Vision and Pattern Recognition,Anchorage,USA,Jun 23-28,2008.Piscataway,USA:IEEE,2008:1-8.
[19]Hu Weiming,Li Xi,Zhang Xiaoqin,et al.Incremental tensor subspace learning and its applications to foreground segmentation and tracking[J].International Journal of Computer Vision,2011,91(3):303-327.
[20]Yang Meng,Zhang Lei,Yang Jian,et al.Robust sparse coding for face recognition[C]//Proceedings of the 2011 IEEE Conference on Computer Vision and Pattern Recognition,Providence,USA,Jun 20-25,2011.Piscataway,USA:IEEE,2011: 625-632.
[21]Zhang Jian,Jin Rong,Yang Yiming,et al.Modified logistic regression:an approximation to SVM and its applications in large-scale text categorization[C]//Proceedings of the 20th International Conference on Machine Learning,Washington,USA,Aug 21-24,2003:888-895.
[22]Kim S J,Koh K,Lustig M,et al.An interior-point method for large-scale l1-regularized least squares[J].IEEE Journal of Selected Topics in Signal Processing,2007,1(4):606-617.
[23]Zhang Lei,Yang Meng,Feng Xiangchu.Sparse representation or collaborative representation:which helps face recognition?[C]//Proceedings of the 2011 International Conference on Computer Vision,Barcelona,Spain,Nov 6-13,2011. Piscataway,USA:IEEE,2011:471-478.
[24]Li Yang,Zhu Jianke,Hoi S C H.Reliable patch trackers:robust visual tracking by exploiting reliable patches[C]//Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition,Boston,USA,Jun 7-12,2015.Piscataway,USA:IEEE,2015:353-361.
[25]Wu Yi,Lim J,Yang M H.Online object tracking:a benchmark[C]//Proceedings of the 2013 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Portland,USA,Jun 23-28,2013.Piscataway,USA:IEEE, 2013:2411-2418.

LIU Xing was born in 1990.He is an M.S.candidate at Jiangnan University.His research interest is visual target tracking.
劉行(1990—),男,安徽池州人,江南大學物聯網工程學院碩士研究生,主要研究領域為視覺目標跟蹤。

CHEN Ying was born in 1976.She received the Ph.D.degree from Xi?an Jiaotong University in 2005.Now she is a professor and M.S.supervisor at Jiangnan University,and the member of CCF.Her research interests include computer vision and pattern recognition.
陳瑩(1976—),女,浙江麗水人,2005年于西安交通大學獲得博士學位,現為江南大學物聯網工程學院教授、碩士生導師,CCF會員,主要研究領域為計算機視覺,模式識別。
Target TrackingAlgorithm Based onAdaptive Observation Weight*
LIU Xing,CHEN Ying+
Key Laboratory of Advanced Process Control for Light Industry,Ministry of Education,Jiangnan University,Wuxi, Jiangsu 214122,China +Corresponding author:E-mail:chenying@jiangnan.edu.cn
To solve the problems of poor robustness and low effectiveness of visual tracking in complex scenes,this paper proposes a target tracking algorithm based on adaptive observation weight in Bayesian framework.Firstly,a weighted observation model is established via linear visual tracking representation.Then an iterative optimization algorithm is put forward to adaptively update the weight matrix to eliminate negative influences of observation outliers. Finally,effective likelihood evaluation function is adopted to capture the target accurately.The experimental results show that the proposed algorithm outperforms other state-of-the-art tracking algorithms in tracking accuracy and robustness.
visual tracking;linear representation;on-line updating;outliers;adaptive weight matrix
2015-10,Accepted 2015-12.
10.3778/j.issn.1673-9418.1510079
A
TP391
*The National Natural Science Foundation of China under Grant Nos.61104213,61573168(國家自然科學基金);the Prospective Joint Research Foundation of Jiangsu Province under Grant No.BY2015019-15(江蘇省產學研前瞻性聯合研究項目).
CNKI網絡優先出版:2015-12-22,http://www.cnki.net/kcms/detail/11.5602.TP.20151222.1017.002.html
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
