為科學服務的大數據*
2016-10-18 02:03:50郭毅可于思淼王世才倫敦帝國理工學院數據科學研究所倫敦SW72AZ英國
中國科學院院刊 2016年6期
郭毅可 潘 為 于思淼 吳 超 王世才倫敦帝國理工學院數據科學研究所 倫敦 SW7 2AZ, 英國
為科學服務的大數據*
郭毅可潘為于思淼吳超王世才
倫敦帝國理工學院數據科學研究所倫敦SW7 2AZ, 英國

數據驅動的科研活動已蔚為大觀,然而厘清關于數據研究的基本問題仍是數據科學的首要任務。文章根據倫敦帝國理工學院建設數據科學研究院的經驗,將數據科學聚焦于交叉研究上,討論從數據整合與理解,到數據感知與交互,再到數據學習與認知,最后到數據交換與經濟的完整鏈條,并結合開展的科研實踐工作,分析了其中的基本研究問題。
大數據,數據科學,數據驅動的科學研究
1 研究背景
微軟研究院以 Jim Gray 曾經對科學研究方法的歷史作了一個精辟的總結[1]:幾百年前,科學研究是完全通過實驗來觀察自然、理解自然;到了近代數百年,科學才開始注重理論研究,通過建模和抽象來總結揭示自然的規律;近幾十年來,計算機的廣泛使用,使得計算模擬成了科學研究的一個重要手段。到了今天,計算技術已經完全普適化。科學儀器已經成為高通量數據采集的工具,由模擬和儀器采集的數據經過計算機的處理分析形成信息和知識。數據驅動已成為今天科學研究的新的方法。
如今,海量數據源源不斷地被產生出來。科學家和工程師通過對數據的觀察、整合、分析和解釋,不斷創造知識,推動著科學技術的進步和社會的發展。在這種背景下,在中國乃至世界各地,各類以數據為驅動或以數據科學為目標的研究單位如雨后春筍般涌現,在可預見的未來,數據驅動的科學研究必將得到蓬勃發展,蔚為大觀。然而,在目前的探索階段,厘清關于數據科學的基本問題仍然是首要任務,例如數據科學應該研究什么?它與傳統計算機研究和統計分析到底有什么區別?它在學科交叉中應該扮演什么角色?本文根據倫敦帝國理工學院建設數據研究院(Data Science Institute)的實際經驗,提出對如何建設一個支持以數據作為驅動為己任的數據研究院的見解,試圖從我們的研究脈絡中尋找共性問題,拋磚引玉,希望能在更廣大范圍內引起對這些基本問題的思考和討論。
倫敦帝國理工學院是一所專注于科學技術、醫學和商學的世界頂級名校。從事的科學研究和數據緊密相關:從個人醫療數據到科學實驗數據,從公共數據到商業數據。這樣一個大學必須有一個數據研究所作為支撐學校數據驅動研究的科研機構。于 2014 年 4 月成立,其建所宗旨是:“研究先進的大數據管理和分析技術,并以此來促進數據驅動的科學研究及技術發展,造福人類社會。”它把自己的任務定義為:(1)作為學校交叉學科發展的樞紐,組織并推進以大數據為基礎的多學科合作;(2)培養新一代有創新能力的數據科學家;(3)為學校的數據驅動的科學研究提供技術與設施的支持;(4)作為學校對外合作的窗口,與全世界工業界及學術界廣泛開展大數據科研合作;(5)向政府、公共管理機構及全社會提供有關大數據的政策與技術咨詢。
研究所自成立以來,秉承其宗旨,在上述 5 個方向上做出了許多努力,取得了令人矚目的成果,得到了學界和社會的廣泛關注和肯定,很多研究成果產生了國際影響力。因此,習近平主席 2015 年對英國進行國事訪問期間專門參觀了數據科學研究所,聽取了一些研究成果匯報,包括:和浙江大學合作的對中國人口遷移的分析;和維也納國際應用系統分析研究所、美國大氣研究中心和上海大學合作有關“一帶一路”戰略國際影響力分析;和英國國家基因組計劃、歐盟創新制藥計劃合作的有關精準醫學的合作研究;以及和上海地鐵在交通監測和預測方面的合作。習近平主席認為用大數據做交叉學科研究很有意義,和實際應用相結合是個好方向。習近平主席對我們的這些工作表示贊賞,肯定了研究所對大數據研究方向的思考和策略,使研究所倍受鼓舞。
2 數據驅動的交叉科學研究
科學技術的偉大進步往往需要多學科的交叉融合,數據科學的交叉同樣會驅動產生重大的科學發現。而且我們認為數據科學無法作為獨立學科存在,必須和特定領域結合在一起;如不對交叉學科的領域知識有深入的理解,而設計脫離實際的數據分析方法是很難有發展前途的。
以目前熱門的“精準醫療”為例,其涉及到生理學、分子生物學、藥理學、化學、營養學、環境學、生物物理學等眾多學科,很多學科在各自的領域對相關問題已經有了很長的研究歷史,然而只有當交叉出現,特別是針對生物醫學的大數據分析方法和工具出現之后,結合患者生活環境、生物信息、臨床和藥物等各種數據,實現精準醫療才有可能。
由此可見,數據科學是一個組合體,它在明確的應用目標下,驅動和連接各種學科,形成有機統一。把數據科學作為統計學和計算機科學的分支應用,把機器學習和大數據管理技術等數據科學的具體技術作為數據科學的主要內涵的思路與做法,未免是太狹隘了。
進而言之, 數據科學的許多方法也來自于不同領域的科學研究,以今天非常流行的深度學習技術為例,它的許多進步是基于神經生物學和信號處理技術的研究。從數據驅動的領域科學研究中獲取養料和動力,是數據科學研究的一個重要途徑。
數據科學有自己的學科內涵,即基于數據的獲取,清理、建模、分析等方法,從這個角度說,數據科學與數學及計算機科學一脈相承;它也有自己的外延,即面向各種應用問題,從這個角度說,數據科學又是各個交叉科學的載體。在后文中,我們將結合數據科學的內涵,即其研究問題,以及外延,即其應用領域,談談我們的理解。
3 倫敦帝國理工學院數據科學研究所研究方向
數據科學研究是一條完整的鏈條,由 4 個關鍵的環節串聯在一起。我們將這 4 個環節定義為數據整合與理解(Data Integration and Understanding)、數據感知與交互(Data Sensing and Interaction)、數據學習與認知(Data Learning and Cognition)、數據交換與經濟(Data Exchange and Economy)。倫敦帝國理工學院數據科學研究所在這 4 個方面同時開展研究,并且將幾方面的研究緊密地整合到一起。下面具體地闡釋每部分的研究內容。
3.1 數據整合與理解
一份數據,從采集到分析,需要經歷一系列的處理、理解和整合,這部分的工作,毫不夸張地說,可以占到整個數據研究工作量的80%。
(1)在數據整合與理解方面,數據集成是大數據研究的關鍵。眾所周知,數據的多樣性和復雜性往往使得無法將所有數據進行整合,并為領域內的所有研究人員所共同使用。很多擁有相同實驗目的的結果數據無法相互兼容。例如,在生命科學領域,在利用mRNA分析基因表達的過程中,基因芯片產生的表達程度數據通常用CEL格式存取,而如果使用mRNA測序技術則會產生大量基因序列的原始片段。兩種數據都可以通過各自的計算方法得到基因表達的程度,但數據的格式天差地別,專業的分析人員也需要借助多種不同的技術分析匯總其中的結果,讓計算機對此做出統一正確的理解可以說是困難重重。隨著信息需求不斷發展和增長,數據一體化的需求也不斷增長。適當的標準化方法可以有效幫助數據的集成,標準化方法往往取決于數據集和特定領域的慣例,標準分數和T-統計量是轉換醫學研究中常用的標準化方法。
(2)現有的數據集成技術, 如本體論,語義W eb 可以起到關鍵的作用。這些現有語義框架和技術可以被用來建立各種數據之間的聯系,并通過已有的映射關系拓展并建立新的聯系。例如,對于醫療數據,可以通過預定義的、映射一致的本體森林模型來為臨床數據和分子分析數據提供一個更加統一的數據表示,每一棵子樹都表示一個研究項目,通過拓展子樹節點之間的語義關系建立聯系,獲得新的語義知識。新的知識可以是擁有相同或相似病理特征的人的集合,或是治愈某種疾病的治療方法的集合。
(3)對數據標注,整理和ETL( Extract,Transform,Load)自動化的研究是大數據研究的重要課題。
ETL,用來描述將數據從來源端經過提取(extract)、轉換(transform)、加載(load)至目的端的過程,也是對數據集成各個過程的集成和自動化過程[2]。ETL 通過提取和轉換完成數據清洗、標準化和語義建模的過程,使原始數據轉換成人、機都能理解的有效信息。ETL 的核心在于減少繁復的數據預處理中的人工干預,自動化完成數據整合的各個步驟。其難點在于通過人工智能的方法對原始數據進行自動化標注,并利用語義分析的方法將被標注的對象加入語義網絡。
(4)對于數據的標準化和統一化,質量控制是關鍵技術。在標準化的過程中,需要特別重視數據質量控制。仍以 mRNA 分析基因表達為例,相對于基因芯片產生的少量高質量數據,mRNA 測序技術產生基因序列數據量較大,但可靠性較差。通常的基因表達分析結果中都需要加注每個基因序列片段分析結果的質量,對于質量較差的片段,通常的分析中一般不予采用。
我們主持的“歐洲轉化醫學信息與知識管理服務”(European Translational Information & Know ledge Managem ent Services,eTRIKS)項目就是以數據標準化和質量控制為目標的一個典型的數據質量工程。eTRIKS是由歐洲創新藥物計劃(Innovative M edicines Initiative)發起的 5 年科研總經費達 2 300 萬歐元的研發項目,由世界 12 大制藥廠參與,旨在建設基于云計算的全歐洲范圍內的醫學研究標準大數據平臺,成為歐盟醫學臨床研究的大數據標準。由全球性非盈利性組織 tranSMART 基金會主導開發的知識管理平臺是 eTRIKS 平臺的核心系統。它以系統級的方法來解決數據集成和理解的問題,其具體架構如圖 1 所示。
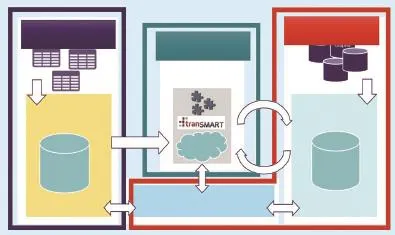
圖1 歐洲轉化醫學信息與知識管理服務(eTRIKS)項目技術框架圖
此平臺上的研究主要包括生物信息數據聯邦、高效數據存儲架構設計以及相關數據索引技術。生物信息數據聯邦主要用于解決生物信息的多元化帶來的異構信息抽象和整合等問題,使得各種數據源可以依據其自身特點,以各自特有的模式進行低成本、高效率存儲和處理。例如,基因芯片所產生的數據主要存儲在 CEL 格式的元信息矩陣和數據信息矩陣中,高通量測序數據結果多存儲在 FASTA 或 FASTQ 文件中,而單核苷酸多態性統計數據多以關系型數據庫模型存儲。一個復雜的病理研究通常需要綜合多種來源的各種信息共同計算,而數據聯邦通過抽象和整合這些多元數據,使得這種基于混合數據結構的高效海量數據計算成為可能。
在考慮多種信息集中處理的同時,我們也關注于對各類數據存儲結構的優化[3,4],通過引入先進的存儲技術提高數據的存取效率。例如,數據科學中心設計實現的 CGC 索引(Collaborating Global Clustering Index)是針對遺傳信息的高效數據存儲和檢索方法。
3.2 數據感知與交互
隨著傳感器技術及其產業的發展,傳感網絡大規模地被應用于收集不同領域的數據[5],其進一步所帶來的普適感測促進了物聯網這個新興領域的發展[6],帶來了廣闊的未來潛在應用,包括產品追蹤、智慧環境、社會感知、智能設備、災害預測等等[7]。 面對感知大數據,如何構建針對物聯網的通用高性能數據處理平臺,及研究針對物聯網和大數據感測的高性能數據管理方法成為關鍵。
在這方面,數據科學研究所提出了“認知感知”的方法論,認為感知數據的作用在于建立、驗證和糾正模型。一旦一個目標感知對象被建模之后,其模型預測將與感知數據進行比對,如果模型正確,則無需進一步數據采集和模型修正;如果模型失效,說明目標對象出現新的行為或原模型粗糙,這時才需要進一步采集數據并修正模型。這種方法被叫做“認知感知”是因為它契合智能生物感知世界的方法,智能生物包括人類能在有限認知計算資源的限制下實現與動態環境的均衡,其目標可以說是優化自由能量(Free energy)或最小化驚奇(M inimize surprise)[8]。基于這種認識,我們在感知系統中,將認知定義為優化主觀認知分布和客觀分布之間 KL 距離的建模行為,而感知行為被看做是減小此 KL 距離與實際 KL 距離的措施。為了實現這種感知和認知,我們解決了兩方面的問題:如何調整模型和模型空間來適應感知對象的變化;如何減少感知維度。
感知之后的數據除了分析建模之外,一個重要的研究方法是數據可視化。數據可視化是研究如何將數據以形象化的方式展現出來的一門科學。它主要專注于分析,以連貫和簡短的形式把大量的信息展現出來,而抽取何種數據進行形象化的抽象,本身就蘊含了對數據如何應用的科學思維。在大數據背景下,大規模的多維的數據正在被快速地產生和積累。如何更有效地探索數據、理解數據以及表達數據成為一項重要的研究課題。
通過圖形化地表達數據,人可以利用自身復雜的視覺系統直接參與到數據探索和交流的過程中。這使得很多復雜的數據可以更有效地被分析和理解。數據可視化成為數據科學的重要組成部分的主要原因有兩個:第一,由于人類視覺系統十分擅長模式識別,通過圖形可視化數據以及相關的分析結果,可以更容易更準確地理解數據中的有效信息。第二,數據可視化技術可以很大程度地幫助人們交流和傳播大數據所蘊含的有效信息和重要發現。
由此可見,可視化不是數據分析的結果,而是數據分析的過程。如何建立一個能支持發現科學直觀的可視化環境是非常重要的,在這方面我們做了大量的工作,建立了全球最大的數據可視化設施“全球數據觀察站”(圖 2),幾十個電腦屏幕組成的動態數據圖像準確銜接,其背后蘊含的是并行運算、多項目管理、編程,以及對數據的深刻理解。在數據觀察站中實現了各種實時交互的可視化應用,比如全球比特幣交易的實時數據可視化,個性化醫療系統可視化,上海地鐵運行分析的數據可視化等,實時處理和展示隨時間變化的各種類型的數據。

圖2 數據可視化平臺及應用
我們所處理的數據源不再是靜態的,它會隨著數據的實時變化進行即時接受、處理并更新可視化數據。這種方式的數據可視化可以幫助人們觀察到最新的即時數據并理解其對舊數據產生的影響。可交互的數據可視化分析可以讓人利用可視化信息與系統進行交互,并在此過程中進一步得到相關信息提取和挖掘的結果。在這個交互過程中,人可以在充分理解數據可視化信息的基礎上,根據不同的目的主動探索和發現所需要的數據結果。這可以極大地提升數據探索和挖掘的效率。
與此同時,人在與數據可視化進行交互的過程中也可以產生新的數據。這些數據可以被收集和分析,以學習人與系統交互的具體情況。例如,在數據觀察站我們可以利用眼動追蹤設備來實時記錄人眼在屏幕上注視點的位置。這些位置點形成的熱點圖可以清晰地展示出人對于數據可視化最關注的部分。這些數據可以幫助我們設計和創造出更有效的或者更吸引人的數據可視化系統。同時,人的眼動情況也提供了一種新的與系統交互的途徑。系統可以通過探測人關注點的具體位置進行實時更新,例如展示額外信息等。新的交互方式毫無疑問會對人與數據可視化系統的交互產生積極的影響。
3.3 數據學習與認知
研究所進行數據學習與認知研究是從實際出發,為了應用服務的機器學習。沒有應用背景的數據科學研究會缺乏影響力,沒有對數據科學理論的扎實研究也做不出好的應用。我們關注的實際問題包括功能核磁共振或者腦電圖推斷有效連接(effective connectivity)腦網絡;基于微流控技術得到的蛋白質熒光表達推斷基因網絡結構; 印度西北部平原地下水水位趨勢變化預測;中國省會城市交通網絡車輛速度和流量的預測;計量經濟學中經濟變量的因果性推斷。這些科學問題都是由數據驅動的研究,而這些問題中的數據都可以用時間序列來描述。時間序列模型的主要目的是對系統的物理本質有洞察力的解釋和根據已有的歷史數據對未來進行預測。
基于貝葉斯理論和數據同化理論,我們團隊致力于開發貝葉斯學習引擎(Bayesian Learning Engine)進行時間序列數據建模 。貝葉斯學習引擎由兩部分構成:大數據建模(Data Modelling)引擎和大數據同化(Data Assimilation)引擎。數據建模和數據同化用來做模型篩選的思想可以總結為同化學習理論(Assim ilated Learning)。
大數據建模引擎基于貝葉斯理論構建,其實現分為如下步驟:(1)確定數據的似然函數。(2)選取適當的模型結構。一方面由于所研究的科學問題所在領域的特點不同,選取的模型結構往往具有很大的差別,而且往往是非線性的。比如在生化網絡和基因網絡中,模型中方程必須要遵循化學反應動力學原理,也就是模型的形式只能用多項式和有理函數來描述;比如在描述天氣系統、生態系統的混沌震蕩系統中,模型也往往是具有多項式形式;而在描述電力系統、通訊網絡系統時,模型一般具有三角函數形式;在腦網絡的動力因果模型(Dynam ic Causal M odel)描述中[8],函數的形式限制于一階和二階多項式形式。即便是具備了一定的領域知識,由于非線性函數形式的無窮性,模型空間維數仍然極高。另一方面,如果系統具有高維的狀態變量,比如基因網絡中的基因數目,那么情形會更加嚴重,模型選擇將面臨很大的挑戰。(3)根據先驗知識和系統的特點構造先驗概率,用于刻畫模型中隱藏變量的不確定程度。而這個不確定程度往往由超參數刻畫。值得注意的是,超參數的個數往往小于或者等于候選模型中的隱含變量個數。
接下來我們對后驗概率積分獲得邊緣似然函數,通過對其分析,一個令人喜悅的發現是對于不同的先驗概率構造,我們只需求解一系列的平滑函數加變權重L1范數規則化優化問題[9]。而這類優化問題的集中化解法或者分布式解法已經被廣泛地研究,基于不同的分布式計算平臺與計算架構,比如 MapReduce、Hadoop、Spark/ Shark 可以比較直觀地實現并行化。
除此之外,模型選擇依然面臨著其他問題。首先,這類優化問題的一個問題是對規則參數的調試,不同的規則參數下會得到不同的模型。另外,如果起始選擇了不同的候選模型,最后優化得到的模型往往更加不唯一。而且模型選擇原則,比如赤池信息量準則(AIC)和貝葉斯信息量準側(BIC)往往相差不大,導致模型很難區分。
數據同化技術[10]可以對數據引擎得到的模型集合進行在線篩選。它能幫助一個動態模型不斷地將觀測數據的有用信息反饋進入原有的模型中,一方面能改良無法觀測的物理量,從而不斷地把模型的(預測)輸出逼近現實,另一方面可以不斷地修正模型,在線做出模型選擇。
3.4 數據交換與經濟
大數據時代的到來,不僅僅意味著更多數據被收集和被處理,更為重要的是,數據實實在在成為改變個人和社會的力量。眾多案例[11-13]已向我們展示了大數據的應用價值,然而一個技術要深刻地推進社會發展,它需要從具有應用價值發展為具有“應用+經濟”的雙重價值。
從經濟價值的眼光來看大數據,我們可以看到所謂的“數據”在整條價值鏈上處在起點的位置。數據從一開始作為原材料,到最后成為產品提供給用戶,其中經歷了一系列的加工和增值過程,包括清理[14]、語義化[15]、融合[16]、分析[17]、建模[18]、知識提取[19]、應用[20]、分發[21]等關鍵步驟,如同一個工業產品,從原材料到最終產品形態再到市場,是一個復雜的價值鏈,需要精巧的協同工作。而在目前大部分的大數據研究中,關注點還在于這些具體過程的技術基礎,我們相信隨著整個大數據生態環境的建立,每個步驟背后的經濟因素將成為最大的推動力量。
要推動從數據到數據產品的價值鏈,有很多關鍵的經濟問題需要考慮,其中一個核心的問題是數據作為資產的定價問題。數據與其他原材料在4個方面有很大不同:(1)數據的使用不會帶來數據的消耗,它的開發不是排他的,甚至反而是利他的;(2)聚合后的數據比單獨的數據更有價值,也應該具有更高的價格;(3)同樣種類的數據,不同來源的數據具有不同的價值,這點在醫療數據中尤為突出;(4)同樣的數據在不同的使用者看來,也是價值各異。在這些特殊的條件中,如何對數據資產定價是一個很難的問題,我們認為采用一種基于市場協商的價格或許更為現實可行。
有了定價,還需要交易。目前很多概念仍需考察,例如交易是代表了數據所有權的轉移?還是僅僅出讓了使用權?數據作為一種容易復制和分發的資產,如何控制其再交易?另外一方面,定價和交易的問題同樣存在于整個數據價值鏈上,例如對數據產品如何定價?目前基于app的交易模式是否是最合理的?
解決這些核心問題,有利于找到適合大數據產品和大數據經濟的商業模式。目前很多商業模式初現雛形,例如基于眾包的數據收集和基于用戶數據收集的精確廣告等。然而很多商業模式其經濟模型曖昧不明,在數據定價、用戶隱私等方面缺乏明晰思考和監管。總體來說,整個價值鏈上的商業模式尚處起步,大有研究和發展空間。
由大數據經濟推動的各個參與者(數據提供者、加工者、產品開發者、發布商、用戶等)最終會形成一個生態環境。一個好的生態環境會促進各個參與者的效益和效率,并提高從技術到效能再到效益的轉化。目前此生態環境初見雛形,但在很多方面缺乏體系支持。以隱私為例,目前在用戶和數據收集者之間缺乏一個有效的隱私保護機制。針對這個問題,我們提出了一種新的移動隱私保護模型(Pay-by-Data,PbD模型[22]),用于控制以下這類常見問題:在目前的機制下,手機應用可以在用戶不知情或無力控制的情況下,獲取用戶大量移動端數據。在 PbD 模型中,定義了一種新的應用價格,即數據;并建立了一種新的開發者與用戶之間的關系,使得用戶可以對他們的數據有更強的控制。模型讓用戶知道他們哪些數據被收集,而這些用戶數據的使用也被顯式地告知用戶,并通過新的粒度更低的認證機制來控制。此模型同時使得用戶可以從數據交易中獲得獎勵。這種顯式的數據-服務交換使得我們可以建立一種以市場機制為調節手段的數據定價和交易方法。在過去的兩年中,我們團隊完成了 PbD 的計算模型并完成了其原型系統,包括 PbD 市場、數據交易價格、PbD 開發 SDK和一個定制的 PbD Android 操作系統。
其他的支持體系包括法律、知識產權等方面,其中一個有意思的方向是科學領域的數據知識產權,或者說數據出版。這個問題涉及到科學數據如何被開發利用,尤其是在學界之外的開發利用。這其中同樣有經濟模型的問題,例如科研經費如何對數據獲取、處理和發布進行支持,以及如何建立對數據科學家的聲譽和激勵,從而在科學數據領域形成良好生態。我們在此領域做了一些初步工作,進行了一個大規模的數據出版調查,并出版了第一期的數據出版調查報告,調查圍繞數據出版話題,側重從數據出版動機、數據出版方式、數據出版運營模式以及數據出版質量評價 4 大維度出發,來了解世界范圍內科學研究領域科學家對于科學數據出版相關內容的看法和態度,并針對數據出版的意義價值及其操作層面的諸多問題予以探討,以期全面了解數據出版發展現狀,并試圖探索推進數據出版事業未來發展、為促進科學數據交流共享提供積極建議。
4 結語
大數據為人類社會提供了又一次新的資源機遇,其具有已有自然資源所不具備的許多特征。如它的超可再生性——數據的使用本身并不消耗數據,相反,還會產生新的數據;它的非競爭性使用—— 一方對數據的占有并不限制其他人對這份數據的擁有。這些特征使得數據資源的使用不僅可以像其他的自然資源一樣產生能量與財富,而且可以完全改變人類的社會組織結構和行為方式。所以,對數據科學研究必須站在社會發展、新的經濟模式、新的工業體系、新的創新產品、新的生活方式以及新的科學研究的方法等宏觀角度來進行系統化的科學研究。
1 Hey T, Tansley S, Tolle K, et al. The fourth paradigm: dataintensive scientific discovery. General Collection, 2009, 317(8): 1. 2 Vassiliadis Panos. A survey o f Extract-transform-Load technology. International Journal of Data Warehousing and M ining, 2009, 5(3): 1-27.
3 Wang S, Pandis I, Wu C, et al. High dimensional Biological data retrieval optim ization w ith NoSQL technology. BMC Genom ics,2014, 15 (8): 1.
4 Wang S, Pandis I, Johnson D, Emam, et al. Optim ising parallel R correlation matrix calculations on gene expression data using MapReduce. BMC Bioinformatics, 2014, 15 (1): 351.
5 Zhu T, Xiao S, Zhang Q, et al. Emergent Technologies in Big Data Sensing: A Survey. International Journal of Distributed Sensor Networks 2015, 2015: 1-13.
6 Zaslavsky A, Perera C, Georgakopoulos D. Sensing as a Service and Big Data. Proc. Int. Conf. Adv. Cloud Com put.Doi: arXiv:1301.0159.
7 Aggarwal C C, Ashish N, Sheth A. The Internet of Thinys :A Surrey from the Data Centric Perspectire, Managing and Mining Sensor Data. 383-428 (2014). Doi:10.1007/978-1-4614-6309-2_12.
8 Friston K J, Harrison L W. Dynam ic causal m odelling. Neuroimage, 2010,5 (4): 1273-1302.
9 Pan W, Yuan Y, Goncalves J, et al. A sparse bayesian approach to the identification o f non linear state-space system s. IEEE Transaction on Automatic Control, 2015, 61 (1): 1.
10 Evensen G. Data assim ilation: the ensemb le Kalman filter. Springer Science & Business Media, 2009.
11 Ahnn J H. Big data com puting for the personalization of services and its applicaiton to speech recognition. International Symposium on Big Data Computing, London, 2015.
12 Manyika J, Chui M, Brown B, et al. Big data: The next frontier for innovation, com petition, and productivity. Analytics, 2011.
13 Andrew M A, Erik B., et al. Big data: the management revolution. Harvard Business Review, 2012, 90 (10): 60-67.
14 Rahm E, Hong H D. Data cleaning: Problem s and current approaches. IEEE Data Engineerhy Bulletin. 2000, 23 (23): 3-13.
15 Auer S, Bizerc, Kobilaror G, et al. Dbpedia: A nucleus for a web of open data. The Semantic web. Springer Berlin Heidelberg,2007, 4825: 722-735.
16 Hall D L, James L. An introduction to multisensor data fusion. Proceedings of the IEEE, 1997, 85 (1): 6-23.
17 Trnka A. Big data analysis.European Journal of Science and Theology, 2014, 10 (1): 143-148.
18 Wu X D, Zhu X, Wu G Q, et al. Data m ining w ith big data. IEEE Transactions on Know ledge and Data Engineering, 2014, 26 (1):97-107.
19 Chen H, Chiang R HL, Storey V C, Business Intelligence and Analytics: From Big Data to Big Impact. M IS quarterly 2012, 36(4): 1165-1188.
20 M urdoch T B, Detsky A S. The inevitable application of big data to health care. Jama the Journal of American M ediael Association. 2013, 309 (13): 1351-1352.
21 Naim i A I, Westreich D J. Big data: A revolution that w ill transform how we live, w ork, and think. In formation Commwnicotion & Society, 2013, 17 (1): 181-183..
22 Wu C, Guo Y K. Enhanced user data privacy w ith pay-by-data model. 2013 IEEE International Conference on Big Data, 2013:53-57.
郭毅可英國帝國理工學院計算系教授,帝國理工學院數據科學研究所所長。1985年畢業于清華大學計算機系,獲工學學士學位。1993年在英國帝國理工學院獲得計算機博士學位,博士期間研究方向為計算邏輯及陳述性語言編程,其畢業論文獲1994年英國帝國理工學院最佳博士畢業論文。2002年被聘為帝國理工學院計算機系終身正職教授,在當時是英國最年輕的教授之一。其主要研究領域包括大數據管理與分析、分布式數據挖掘、網格計算、云計算、傳感器網絡及生物信息學等。1999年創立了帝國理工計算系的第一個派生公司InforSense,并于1999年至2008任該公司首席執行官。InforSense有限公司于2009年6月為國際知名科學數據管理公司英國IDBS公司并購,迄今他一直擔任IDBS公司首任首席創新官。2012出任全球性非盈利性組織tranSMART基金會的首席技術官。2011年至2013年擔任清華大學信息科學與技術國家實驗室講席教授。2012年成為首批上海市千人計劃入選者、上海特聘專家,并為北京市人民政府“海外人才工作顧問”。現任上海市產業研究院大數據首席科學家,中科院深圳先進技術院健康大數據中心主任,及上海大學計算機學院院長。E-mail: y.guo@imperial.ac.uk
Yike GuoProfessor of Computing Science in the Department of Computing at Imperial College London. He is the founding Director of the Data Science Institute at Imperial College, as well as leading the Discovery Science Group in the department. Professor Guo also holds the position of CTO of the tranSMART Foundation, a global open source community using and developing data sharing and analytics technology for translational medicine. Professor Guo received a first-class honours degree in Computing Science from Tsinghua University, China, in 1985 and received his PhD in Com putational Logic from Im perial College in 1993 under the supervision of Professor John Darlington. He founded InforSense, a software company for life science and health care data analysis, and served as CEO for several years before the company's merger w ith IDBS, a global advanced R&D software provider, in 2009. He has been working on technology and platforms for scientific data analysis since the m id-1990s, where his research focuses on know ledge discovery, data m ining and large-scale data management. He has contributed to numerous major research projects including: the UK EPSRC platform project, Discovery Net; the Wellcome Trust-funded Biological A tlas of Insulin Resistance (BAIR); and the European Comm ission U-BIOPRED project. He is currently the Principal Investigator of the European Innovative Medicines Initiative (IM I) eTRIKS project, a €23M project that is building a cloud-based informatics platform, in which tranSMART is a core com ponent for clinico-genom ic medical research, and co-Investigator of Digital City Exchange, a £5.9M research programme exploring ways to digitally link utilities and services w ithin smart cities. Professor Guo has published over 200 articles, papers and reports. Projects he has contributed to have been internationally recognised, including w inning the “Most Innovative Data Intensive Application Award” at the Supercomputing 2002 conference for Discovery Net and the Bio-IT World “Best Practices Award for U-BIOPRED in 2014. He is a Senior Member of the IEEE and is a Fellow of the British Computer Society. E-mail: y.guo@imperial.ac.uk
Big Data for Better Science
Guo YikePan WeiYu Sim iaoWu ChaoWang Shicai
(Data Science Institute, Imperial College London, London SW7 2AZ, UK)
Data driven scientific research has now gain great prosperity. However, we believe that the principle task of data science is to understand the basic problems w ithin data research. In this paper, based on our experience in building the Data Science Institute in Imperial College London, we consider data science as the core of interdisciplinary research, and discuss the whole pipeline of data science research,including data integration and understanding, data sensing and interaction, data learning and cognition, and data exchange and economy. We discuss these basic scientific problems based on our practices in practice. We hope the work presented in this paper can bring thinking and discussion in a larger scale.
big data, data science, data-driven scientific research
10.16418/j.issn.1000-3045.2016.06.002
*修改稿收到日期:2016 年 5月19日
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
世界科學技術-中醫藥現代化(2022年3期)2022-08-22 00:32:50
云南化工(2021年8期)2021-12-21 06:37:54
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
海洋信息技術與應用(2020年1期)2020-06-11 12:43:56
數學物理學報(2020年2期)2020-06-02 11:29:24
傳媒評論(2019年4期)2019-07-13 05:49:14
小小藝術家(2019年6期)2019-06-24 17:39:44
光學精密工程(2016年6期)2016-11-07 09:07:19
今古傳奇·故事版(2016年15期)2016-09-07 06:57:32
