基于位置服務上的信息發布/訂閱數據建模研究
2016-10-26 00:52:44張素智徐家興魏萍萍
現代計算機 2016年23期
張素智,徐家興,魏萍萍
(鄭州輕工業學院計算機與通信工程學院,鄭州450002)
基于位置服務上的信息發布/訂閱數據建模研究
張素智,徐家興,魏萍萍
(鄭州輕工業學院計算機與通信工程學院,鄭州450002)
目前,基于內容、主題在線發布/訂閱系統的數據建模和匹配算法缺乏面向LBS的支持,因此提出基于LBS服務的信息發布/訂閱數據建模。在該建模中,用戶只需要訂閱感興趣的信息,就能夠在當前所在位置接收訂閱信息,這有效地解決現有的發布/訂閱系統中數據匹配的冗余和低精度的問題。通過仿真實驗,將數據模型應用于城市信息發布平臺系統中。測試結果表明,該模型提高準確度,減少數據冗余,適合大規模發布/訂閱應用需求。
查詢處理;索引;信息發布;位置定位
0 引言
隨著互聯網的迅速發展和普及,特別是隨著移動計算、網格計算、云計算等新的網絡計算模式的興起,分布式應用系統的范圍和規模都發生了很大變化,分布式計算已成為構建大型信息發布系統的主流技術。這就需要一個更加機動的通信和互動機制,以反映系統中動態的和松散耦合等特點,并發布/訂閱模型使功能上能夠滿足上述要求,這種機制受到越來越多科學家的關注。典型的發布/訂閱系統的基本模型,如圖1所示,其中包括發布、訂閱和事件代理。

圖1 發布/訂閱模型
1 數據建模
LBS發布/訂閱數據模型包括:概念模型、發布事件模型,和訂閱事件[1]模型。
1.1概念模型
在城市信息發布平臺中,使用本體建立一個概念模型。本體[2]是一個特定于域的概念,是概念之間的關系和概念定義關系應該遵循的約束條件。概念模型[3]清楚地定義一個字段的約束以及它們之間的應遵循的關系等。發布內容的事件必須滿足限制的概念和關系,即內容必須定義在一個概念模型中,必須有存在概念模型中定義的事件;當事件模型接收到一個事件,它必須接觸事件內容和概念模型,并進行解決;用戶發布訂閱必須滿足定義和概念模型的約束。因此,概念模型是整個系統的基礎,并發揮著重要的作用。
定義1:一個概念模型可以使用six-tuples O=(C、P、CR、PR、X、L):
(1)C表示一組概念類的應用程序域,每個實體屬于一個或多個類。例如在基于網絡圖的信息發布平臺中,類層次結構之間的關系如圖2所示。
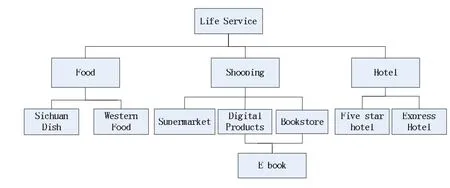
圖2 類和信息平臺的關系
(2)P表示一組屬性。每個類都有一個或多個屬性。基于網絡圖的在城市信息發布平臺,例如,一些屬性之間的關系如圖3所示。
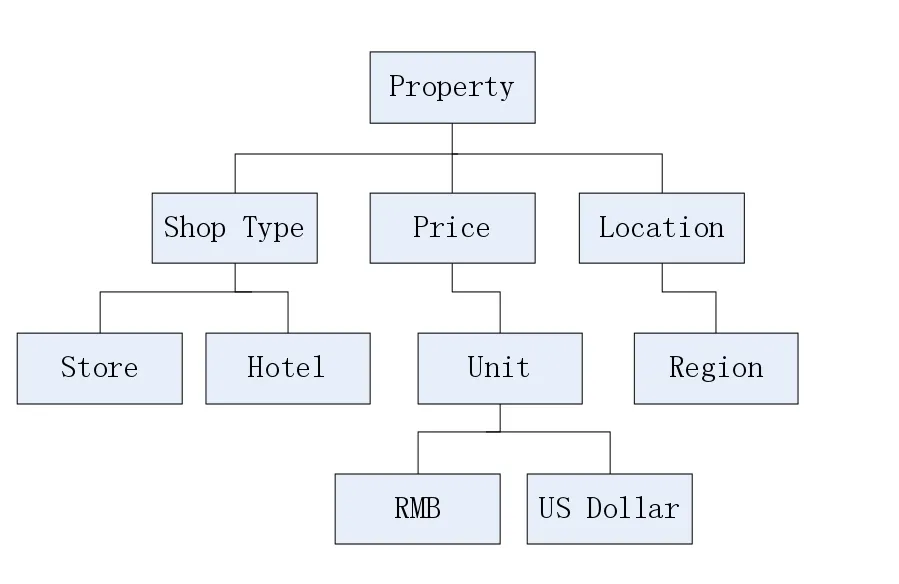
圖3 屬性和關系的信息平臺
(3)CR是一組概念之間的關系,RP是一組相關的更多屬性。概念及其屬性關系主要是繼承、相交、平行等。
(4)X代表一組約束之間的概念和屬性,描述為每個類允許哪些屬性存在,屬性的屬性值為空,是什么類型的信息等。
(5)L表示一組區域信息,包括一些地理區域,它的大小并不是固定的,但是根據相關性劃分。每個消息都有相應的位置信息。
這是一個訂閱條件,和一個實體類B,A到B的子類或間接父類,那么這兩個可以匹配。同樣,如果P1屬性訂閱和事件數據的屬性P2和P1,P2的子類或間接父類,這兩個也可以匹配。例如,某人的訂閱條件shopType=“餐館、茶館”,在一個事件數據shopType=“餐館、茶館”,那么事件和訂閱條件相匹配。
1.2事件模型
城市信息發布平臺使用RDF語言[4]來描述事件模型,與triple-tulles(主題、屬性、對象)的形式表達每個triple-tulle稱為語句的事實。其中,主題是說對資源URI引用,屬性代表屬性URI引用,對象代表價值或URI引用,或者文字值。商家發布信息,并將改變概念模型到事件模型,最后統一到RDF格式。最后,事件服務代理將發送一個RDF-formatted事件到所有相匹配的用戶,這在一定程度上,解決異構結構的問題。
定義2:使用RDF eight-tuples事件模型:
(1)V代表一個組中的所有節點的事件模型圖。節點包括URI引用節點,文本節點,或者一個空白的節點。
(2)A代表一個弧的所有事件模型圖,和弧是URI引用。
(3)LV表示一組標簽中的所有節點事件模型。
(4)LA表示一組標簽所有弧事件模型。
(5)θ表示一組映射函數從節點到節點的標簽,即vθ-LV。
(6) 表示一組電弧弧標簽的所有映射函數,即v -LV。
(7)X表示一組約束事件模型。
(8)L表示一組區域信息的概念。
圖4顯示了我們,在城市的信息發布平臺,李寧專賣店,東風5號公路附近賣籃球鞋,他們的價格是1000至2000元人民幣。商家發布的信息,事件模型統一格式的事件模型。
1.3訂閱模式
用戶的訂閱[5]是由幾個”和“操作的“報表模式”。模式每個語句描述的事件發表聲明,并且每個訂閱可以表示為一系列的5個元素。
定義3:訂閱聲明為5個元素(主體、客體、價值、過濾器(主題)、過濾器(對象)),主體和客體提供訂閱的主題和對象的語句,它可以表示為一個特定的值,或者也可以使用變量來表示,每個變量”?”作為前綴,如?l,?2,等等。弧連接到主體和客體的屬性代表,其中每個屬性代表一個類型。
過濾器(主題)和過濾器(對象)代表頂點,綁定可以是空的。在事件圖中,每個頂點都有一個特定的值,但是在訂閱圖中,我們允許的對象和對象都之間是約束和不受約束的變量,它可以在事件中的匹配任何值,約束變量只能匹配約束的值。過濾器可以被表示為一個約束(?x,op,v)?x是一個變量,op是運營商,v代表一個變量值。例如,(?1>100)描述這個變量節點只能有一個匹配的值大于100的節點圖。過濾操作符作為一元運算符,即:>、<、=、≥≤,≠,和∈。
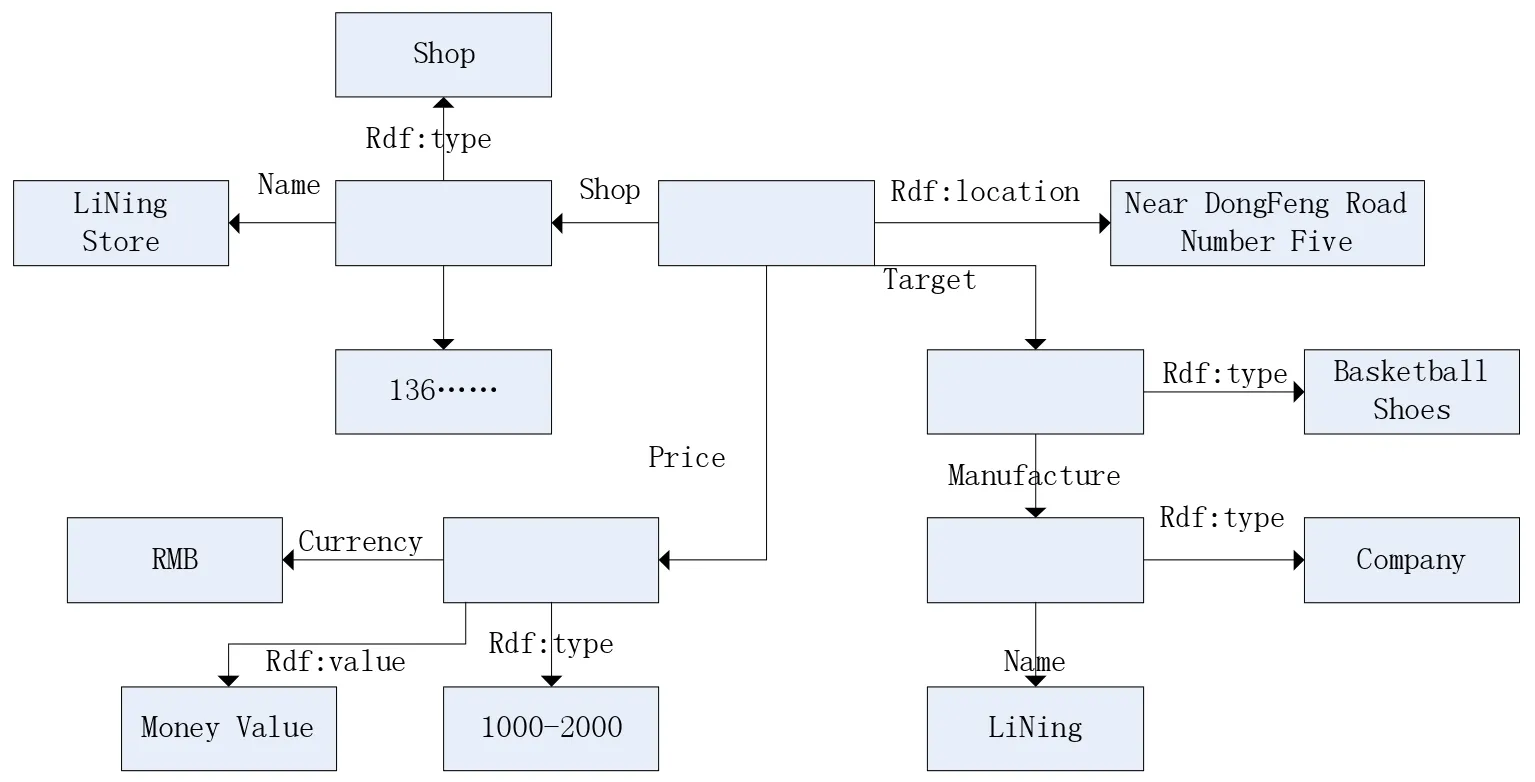
圖4 示例事件模型圖
如果一個人現在在鄭州輕工業大學附近(東風路5號)想買一雙李寧的籃球鞋,它的價格在1000~2000元之間,對應的訂閱聲明可以被描述為:
(_R,rdf:位置?1、null(?1、∈的東風5號路附近)
(_R目標?2、null(?2='籃球鞋'))
(_R、名稱?3、null(?3=“LiNing”))
(_R、價格?4、null(?4><1000~2000))
每個訂閱事件可以表示為一個訂閱圖,如圖5所示:
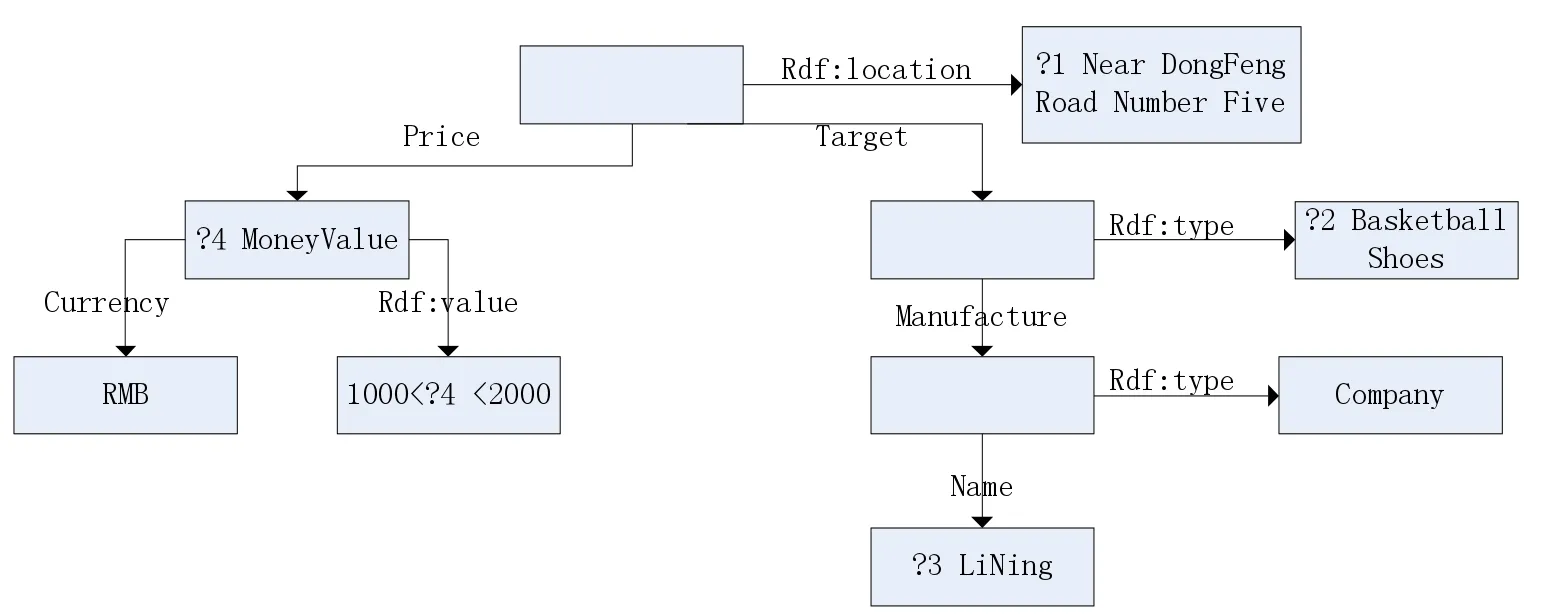
圖5 訂閱模型圖的例子
2 模型應用
2.1匹配算法
匹配算法的實質是給定一個訂閱集S和發布事件P,找到滿足訂閱集S的所有發布事件集合的過程,暴力匹配方法匹配[6]算法是最典型的方法,它會將所有的發布事件的元素P組與訂閱信息匹配,匹配算法需要每個屬性來比較,這樣用戶等待時間太長,并且會產生大量的重復匹配,大大減少匹配的效率。為了解決匹配效率低下等問題,結合基于LBS的信息數據模型[7],設計多個屬性索引的快速匹配算法。算法描述如下:
(1)建立一個索引表的訂閱集,過濾器的過濾條件下(主題)和過濾器(對象)在相應的分類和排序,即每個訂閱報表需要分類和排序操作。如果運算符“>”和“>=”,按照升序排序;如果它是“<”和“<=”,在降序排列。當一個序列中的值滿足要求,之后的一切屬性的值對應值來滿足需求,價值不符合上述標準將不再找到匹配,這可以極大地減少匹配。
步驟2:根據操作符的類型,事件模型屬性設置匹配約束,發現和綁定在一個位置,其屬性權重增加,附近的位置信息,找到匹配的位置。使用Haversin算法:
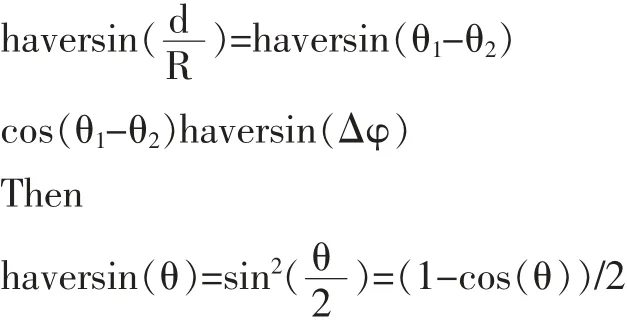
地球的半徑R,理想的平均6371公里;代表兩個緯度,θ1θ2代表兩個經度不同;Δφ代表經度差異,讓θ1= θ2then Δφ=rcsin(sin(d/2R))/cosθ弧度轉換:dlng= Δφ*180/π,讓Δφ=0,Δθ=d/R弧度轉換得:dlat= Δθ*180/π。最后,我們可以得到4點:左上角:(lat+dlat,lng-dlng),右上角:(lat+dlat,lng+dlng),左下角:(latdlat,lng-dlng),右下角:(lat dlat,lng+dlng)。
(3)根據操作符尋找匹配,如果“=”操作符,則直接匹配模型的產權約束,否則覆蓋的集合中的原有操作符,包括匹配的屬性,將滿足需求訂閱信息收集到臨時TempList集合,然后在臨時集合templist中的第二屬性作為第一屬性匹配方法匹配,重復第三步依次類推,直到這一事件模型的所有屬性完全匹配。
(4)臨時返回結果集TempList,其中結果之一是匹配成功的訂閱消息。
2.2實驗結果
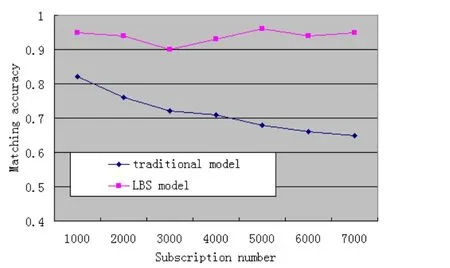
圖6 不同的數據模型來匹配精度的影響
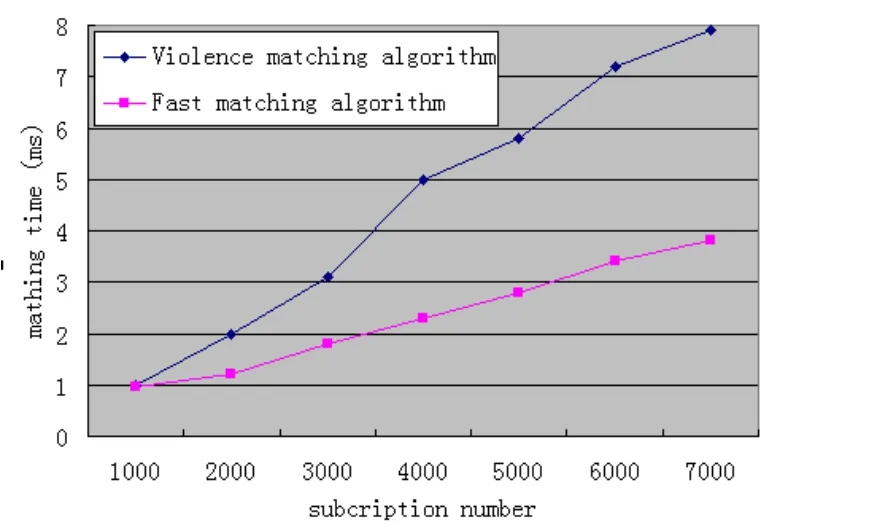
圖7 訂閱數量匹配速度的影響
實驗I:測試不同的數據模型來匹配精度的影響,如圖6。
結果表明,傳統在訂閱模式匹配的準確性隨著訂閱數量增多不斷減少,并且在相同訂閱數量的情況下,基于LBS的訂閱系統在準確度上一直占有優勢,該圖表明,滿足用戶需求的結果所占的比例越來越少;基于LBS的準確發布訂閱模型匹配的變化不明顯,且精度更高,更接近用戶需求。隨著需求的不斷增長,新的訂閱模型更利于滿足用戶的訂購。
實驗II:測試的影響訂閱的數量匹配速度,如圖7。
結果表明,傳統的算法隨著訂閱數量的增多,消耗時間越來越長,與多屬性索引匹配算法相比較,在最初訂閱數量少時,還擁有較好的匹配效率,當訂閱數量過多時,新算法明顯優于傳統的算法。由于提出的算法支持排序、適應多屬性索引、選擇連續、減少比較次數,從而減少了匹配時間,提高了匹配效率,因此多屬性索引匹配算法更適合于大量的訂閱過程。
3 結語
近年來,隨著計算機網絡技術的迅速發展,特別是移動網絡,發布/訂閱模型[8]逐漸增多并得到廣泛應用。模型的關鍵是如何實現信息和訂閱之間的匹配效率。相對于基于主題/內容的發布/訂閱系統模型,我們提出一個新的基于LBS發布/訂閱模型數據模型。它使用邏輯算子的特點來實現精確、快速和高效的匹配,因此基于LBS的定位系統更適用于大規模分布式發布-訂閱系統。總之,實驗表明數據模型匹配的準確性比其他方法有更大的進步。
[1]Jiangang Ma,Tao Huang.Underlying Techniques for Large-Scale Distributed Computing Oriented Publish/Subscribe System[J].Jiangang Ma.Beijing:Journal of Software,2006:134-147.
[2]Jing An.Design of Information Service System Based on LBS[C].Jing An.Zhejiang:Digital Technology and Application,2014:164.
[3]Xi-wei Feng,Jian-hua Wang,Yao Feng,Pei-guang Lin.Semantic Web-Based Matching Algorithm for Publish/Subscribe System[J]. Xiwei Feng.Beijing:Journal of University of Science and Technology Beijing,2013:544-550.
[4]Xiao Zheng,Jun-zhou Luo,Jiu-xin Cao,Ai-bo Song.A Publish Subscribe Based Information Dissemination Model for QoS of Web Services[J].Xiao Zheng.Beijing:Journal of Computer Research and Development,2010:56-69.
[5]Guo-yan Xu,Zhi-jian Wang,Xiao-fang Li.Research on Publish/Subscribe Model Based on Web Services[J].Guoyan Xu.Nanjing:Microelectronics&Computer,2009:29-60.
[6]Zhi-wen Zou,Qiao Li.Subscription Partition Based Multi Index Parallel Matching Algorithm[J].Zhiwen Zou.Jiangsu:Journal of Huazhong University of Science and Technology(Natural Science Edition),2013(S2).
[7]Yong-feng Li,Hui-lin Wang.Indexing and Filtering Metadata for Content Based Publish/subscribe System[J].Yongfeng Li.Beijing:Computer engineering and design,2013:10-32.
[8]Qiang Zhang,Jian-hua Li.Real-Time Performance Analysis of Information Sharing Based on a Publish/Subscribe Model[J].Qiang Zhang.Beijing:Military Operations Research and Systems Engineering,2013:33-35.
Research on Data Modeling of Information Publish/Subscribe Based on LBS
ZHANG Su-zhi,XU Jia-xing,WEI Ping-ping
(School of Computer and Communication Engineering,Zhengzhou University of Light Industry,Zhengzhou 450002)
At present,the content-based,theme-based publish/subscribe system currently has short of supporting LBS in data modeling and matching algorithm,so proposes a data modeling of information publish/subscribe based on LBS,and applies the traditional pattern of the publish/subscribe to LBS in the information service.In the model,users only need to subscribe your interested information,and then receive subscription information near your current location,and effectively solve the existing publish/subscribe system in the data matching redundancy and low accuracy of the results.Through simulation experiment,the data modeling is applied to the city information publishing platform system.The test results show that the model has a great improvement in the accuracy of matching results and reduces the data redundancy,which is suitable for large scale publish/subscribe application requirements.
Query Processing;Index;Information Release;Position Location
國家自然科學基金青年科學基金項目(No.61201447)
1007-1423(2016)23-0027-05DOI:10.3969/j.issn.1007-1423.2016.23.007
張素智(1965-),男,教授,博士,研究方向為Web數據庫、分布式計算和異構系統集成
徐家興(1990-),男,碩士研究生,研究方向為數據挖掘與集成
魏萍萍(1990-),女,碩士研究生,研究方向為數據挖掘與集成
2016-05-24
2016-08-10
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
中華手工(2017年2期)2017-06-06 23:00:31
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
中外會展(2014年4期)2014-11-27 07:46:46
中學數學雜志(初中版)(2006年1期)2006-12-29 00:00:00
建筑創作(2001年3期)2001-08-22 18:48:14
祝您健康(1987年3期)1987-12-30 09:52:32
