基于改進的SVM方法的異常檢測研究
2016-11-07 09:44:20張輝劉成
網絡與信息安全學報 2016年8期
張輝,劉成
(1. 新疆公安廳特別偵察隊,新疆 烏魯木齊 830000;2. 國家計算機網絡應急技術處理協調中心,北京 100029)
基于改進的SVM方法的異常檢測研究
張輝1,劉成2
(1. 新疆公安廳特別偵察隊,新疆 烏魯木齊 830000;2. 國家計算機網絡應急技術處理協調中心,北京 100029)
利用非參數檢驗的方法提取出對分類結果影響顯著的特征變量,提出一種改進的SVM多分類方法(D-SVM),其融合了判別分析,可以解決樣本不均衡導致的分類不準確和誤報率高的問題。將多分類問題處理成一個個二分類問題,D-SVM既可以保持SVM較好的分類準確性,同時又可以不受樣本不均衡的影響,具有較低的誤報率。將D-SVM應用到KDD99數據集,結果表明,該方法具有較高的分類準確性和較低的誤報率。
異常檢測;非參數檢驗;SVM分類;樣本不均衡;判別分析
1 引言
計算機技術和互聯網的發展極大地促進了網絡與企業、個人生活的融合。據中國互聯網信息中心《第37次中國互聯網絡發展狀況統計報告》顯示,截至2015年12月,全國使用計算機辦公的企業比例為95.2%,涉及供應鏈、營銷、財務和人力資源等方面;與此同時,網絡購物和網絡社交等已成為人們生活必不可少的一部分。隨著“互聯網+”的逐漸深入,網絡的作用會更加突出,網絡安全問題也將會變得十分嚴峻,并成為制約網絡發展的因素。入侵檢測在網絡安全中有重要的作用,它可以實時地監測、阻止來自網絡外部和內部的入侵,保護網絡免受攻擊,造成損失。入侵檢測方法可以分為2類[1]:誤用檢測(misuse detection)和異常檢測(anomaly detection)。誤用檢測只能檢測已知的攻擊,而異常檢測卻可以檢測新的、未知的攻擊。異常檢測已成為入侵檢測領域的主要研究對象[2,3],因此,本文以異常檢測為主要研究內容。
異常檢測的實質是分類問題,即如何將數據分為正常和異常2類。相關研究領域已有很多研究成果。異常檢測的研究方法主要有基于統計的方法、基于數據挖掘的方法和基于機器學習的方法這幾類[4]。基于統計的方法其核心內容就是利用統計方法設定閾值[5,6]或概率[7,8],對于未知的連接或數據分組,檢驗其是否在設定的閾值或概率范圍內,從而判定是否為入侵或攻擊。基于數據挖掘的方法是以數據為中心,利用數據挖掘的相關技術和算法,找出審計數據或流量數據中存在的規律,從而發現入侵行為[9]。基于數據挖掘的檢測方法主要有基于離群點的挖掘方法、基于分類的檢測方法、基于聚類的檢測方法和基于關聯分析的檢測方法[10,11]。基于機器學習的方法主要有神經網絡、遺傳算法、隱馬爾可夫模型和支持向量機(SVM)等[12]。
在這些方法中,SVM具有比較好的檢測效果[13,14]。SVM是在統計學習理論的基礎上,充分考慮了結構風險最小化,通過學習得到一個使分類間隔最大化的超平面,從而將不同的類分別開來。同時,SVM具有良好的泛化能力,已經被廣泛應用到人臉識別、數據挖掘、入侵檢測等領域,并取得良好的分類效果。本文選取SVM作為入侵檢測方法,可以達到比較好的檢測效果。但SVM方法對訓練樣本有一定的要求,如果訓練不足,可能會導致SVM分類效果和進度達不到要求。因此,本文在SVM方法的基礎上引進判別分析的思想,提出一種改進的SVM多分類方法(D-SVM),該方法不僅能夠保留SVM較好的分類效果,還能解決由于訓練樣本較少而對SVM產生的影響。同時,本文還提出一種非參數變量篩選的方法,選出對分類結果有顯著作用的特征或變量,從而達到降維和提高分類效果的作用。將本文提出的方法應用到KDD99數據集,結果表明,本文提出的方法具有高的分類精度。
2 方法介紹
2.1 SVM方法介紹
SVM的核心思想就是將樣本映射到一個高維空間,并在高維空間中線性可分。再通過在高維空間構造一個超平面來達到分類的目的。SVM一般用在解決二分類問題上,具有良好的效果;對于多分類問題,SVM分類效果較差。為了使SVM在處理多分類問題時也能達到較好的分類效果,本文采用二叉樹分類思想,首先將多分類問題處理成二分類問題,再進行逐步迭代,直至將所有的類都分開。
2.2 距離判別法
判別分析可以不受樣本不均衡問題的影響,分類效果比較理想且穩健。距離判別的核心思想就是通過計算待判樣本到已知類中心的距離,再比較距離的大小,樣本到哪個類中心的距離最小,則該樣本就判定屬于哪一類。距離判別法具有簡單高效的特點,它通過計算距離,直觀地將樣本歸類。在某些方法失效的情況下,距離判別仍具有比較穩健的分類效果。距離判別的定義可以表示為
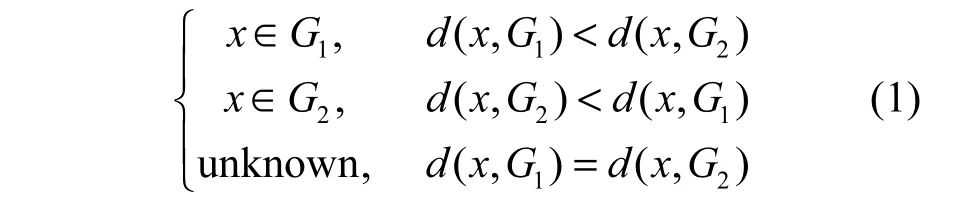
其中,G1,G2表示類1和類2;d(x,G1)和d(x,G2)表示x 到類1和類2的距離。在計算距離時一般選用馬氏距離。相比于歐氏距離,馬氏距離不僅能夠消除變量間量綱的影響,還能消除多維變量間多重相關性的影響。
3 數據處理
3.1 KDD99數據集介紹
KDD99數據集是1998年美國國防部高級規劃署在MIT林肯實驗室進行的一項入侵檢測評估項目。通過模擬真實網絡環境,仿真各種用戶類型、各種不同的網絡流量和攻擊手段。收集了9周時間的TCPdump數據。隨后來自哥倫比亞大學的Sal Stolfo 教授和來自北卡羅萊納州立大學的 Wenke Lee 教授對以上數據進行特征分析和數據預處理,形成了一個新的數據集,使其只包含網絡流量數據。該數據集被用于1999年舉行的KDD CUP競賽中,成為著名的KDD99數據集。KDD99數據集是公認的入侵檢測的Benchmark數據集。
KDD數據集分為全部數據集(kddcup.data.gz,18M)和10%數據集(kddcup.data_10_percent.gz,2.1M)。本文以10%數據集為分析對象。
10%數據集包含494 021條記錄,每條記錄由41個特征變量和類別標簽表示,其中,34個是連續型變量,7個是名義型變量;包含5類數據:Normal(97 278條)、DoS攻擊(391 458條)、Probe攻擊(4 107條)、U2R攻擊(52)和R2L攻擊(1 126條)。本文主要使用34個連續型數值變量作為研究的特征變量。
3.2 非參數檢驗變量篩選
變量篩選的目的是選出對分類結果有顯著影響的特征變量,從而可以達到降維,提高效率的作用。不同于已有的變量綜合的方法,如PCA,本文提出一種利用非參數檢驗篩選變量的方法。
Kolmogorov-Smirnov兩樣本分布檢驗,從樣本經驗分布出發,利用大樣本性質檢驗2個樣本是否來自于同一個總體。假定樣本來自F(x)分布,樣本來自)分布,則Kolmogorov-Smirnov檢驗如式(2)所示。
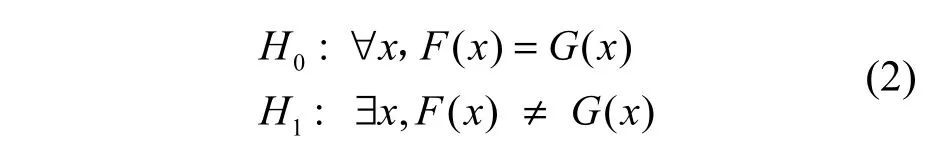

Kolmogorov-Smirnov檢驗已經運用到許多方面[15~17],在本文中,利用Kolmogorov-Smirnov檢驗方法檢驗正常樣本與入侵或攻擊樣本在哪些特征變量上分布具有顯著的差異,選出檢驗顯著的特征變量作為研究的變量。與PCA等變量綜合的方法不同,本文提出的非參數檢驗變量篩選的方法可以直接選出正常樣本與入侵或攻擊樣本在統計上有顯著差異的變量,刪除不顯著的變量,消除冗余信息和不顯著變量信息對分類的干擾,比變量綜合的方法更簡便、有效。
4 實驗結果及分析
4.1 Kolmogorov-Smirnov檢驗變量選擇
為了研究的簡便,本文以KDD99數據集的10%數據集為研究對象,且只選取34個連續型變量和標簽變量作為研究的特征變量。因此,得到了一個494 021×35的數據表,其中表的每一行表示一條記錄,前34列表示選取的34個特征變量(數值型),第35列是標簽,表示每一條記錄所屬的類別(Normal,DoS,Probe,R2L,U2R)。將10%數據集分為正常、入侵或攻擊2類,分別記為類N和類A,其中,類N中樣本數為97 278,占19.6%;類A中樣本數為396 743,占80.4%。運用Kolmogorov-Smirnov方法檢驗類N和類A在哪些變量上的分布不存在顯著差異,結果如表1所示。

表1 KS檢驗不顯著特征變量
從表1中可以看出這14個特征變量在類N和類A上表現并無顯著差異。因此,可以認為這些特征變量對分類結果沒有顯著影響。最終得到了一個494 021×21的數據表。
4.2 正常與異常行為分類
對于入侵檢測,首先關心的是將正常行為和異常行為分開,這是評價研究方法的關鍵指標。首先利用SVM分類方法構建第一級分類器將正常行為樣本與異常行為樣本分開。
在數據集中按比例隨機選取5 000個正常樣本,20 000個異常樣本作為訓練集。按照同樣的方式選取10 000個正常樣本和40 000個異常樣本作為測試集。獨立重復進行5次實驗,結果如表2所示。

表2 5次獨立實驗平均結果
從表2中可以看出,SVM可以有效地將正常和異常樣本分隔開,分類效果比較理想。正常行為和異常行為的分類準確率分別達到99.92%和98.32%,整體分類正確率達到99.59%。說明第一級分類可以以較高準確率(99.92%)識別入侵或攻擊行為,為入侵行為的進一步分類奠定了基礎。
4.3 異常行為具體攻擊類別分類
4.3.1 R2L、U2R與DoS、Probe分類
使用KDD99數據集研究多分類文獻中,關于R2L和U2R的分類效果都不理想,原因在于這2類攻擊樣本太少,導致訓練不足。考慮到數據集中R2L和U2R樣本數較少,將這2類攻擊合為一類攻擊,記作R&U;DoS和Probe當作一類,記作D or P。利用SVM分類,結果如表3所示。

表3 R&U和D or P的平均誤報率(5次獨立實驗)
從表3中可以看出,即使使用二分類SVM方法,R&U的誤報率仍然很高,達到44%,SVM方法對于R&U的分類效果很差。
為了解決R&U誤報率高的問題,隨機選取5 000個正常樣本,求出樣本中心。按比例分別隨機選取40 400個D or P樣本和100個R&U樣本,分別計算這2類樣本到正常樣本中心的馬氏距離。這2類的馬氏距離分布如圖1所示。
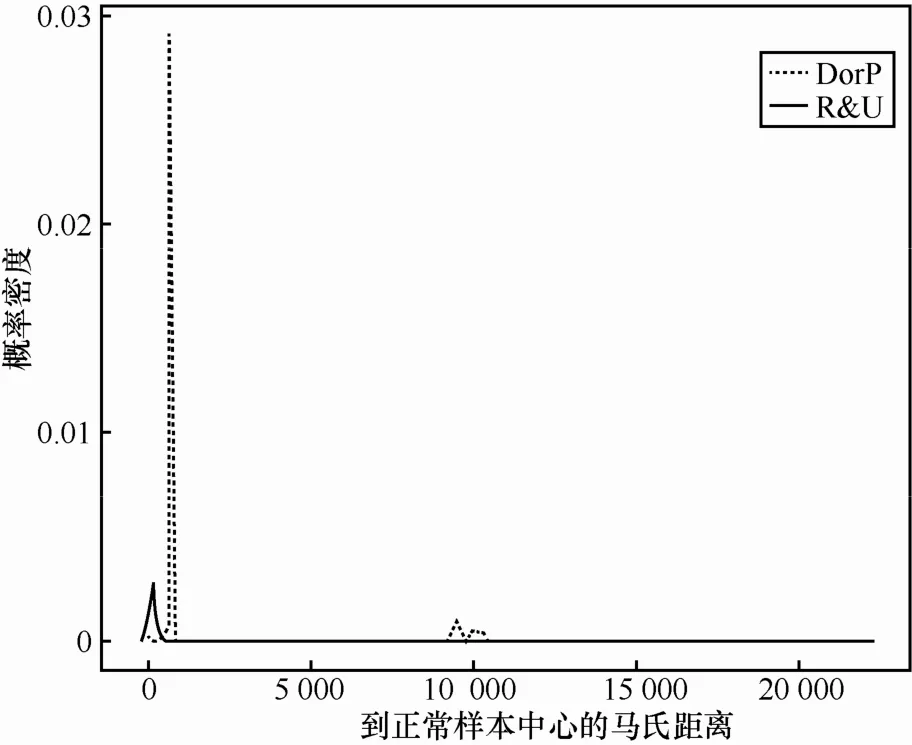
圖1 R&U和D or P到正常樣本類中心馬氏距離分布
從圖1中可以清楚地看到R&U和D or P這2類到正常樣本中心的馬氏距離具有明顯的位置差異,說明這2類到正常樣本中心的馬氏距離顯著不同。因此,可以用距離判別方法構建第二級分類器將這2類分開。
隨機選取5 000正常樣本,計算每一個樣本到中心的馬氏距離的均值和方差,分別用MN和VN表示。隨機選取40 400個D or P樣本和100個R&U樣本,組成待分類樣本記作Test,分別計算Test中每一個樣本到正常樣本中心的馬氏距離,用集合MdTest表示。計算MdTest中每個元素到正常樣本中心的偏差程度,用w表示,如式(4)所示。

為了確定w的最優取值,令w從0到4依次取值。每次增加0.1,得到R&U的誤報率如圖2所示。
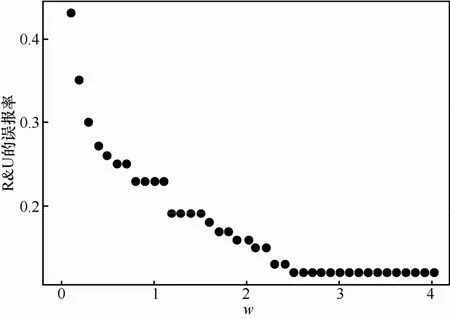
圖2 R&U誤報率與w變化關系
如圖2所示,R&U的誤報率隨著w的增加,呈現逐步下降的趨勢,兩者之間表現出負相關關系。此外,隨著w的增加,D or P的誤報率逐漸上升,R&U與D or P整體分類準確率呈下降趨勢,為了平衡R&U誤報率和整體分類準確率,本文選取圖2中R&U的第3個平穩點作為w的最優取值(w=1.2)。
為了測試距離判別方法的分類效果,按照上文方法進行5次獨立重復實驗,結果如表4所示。
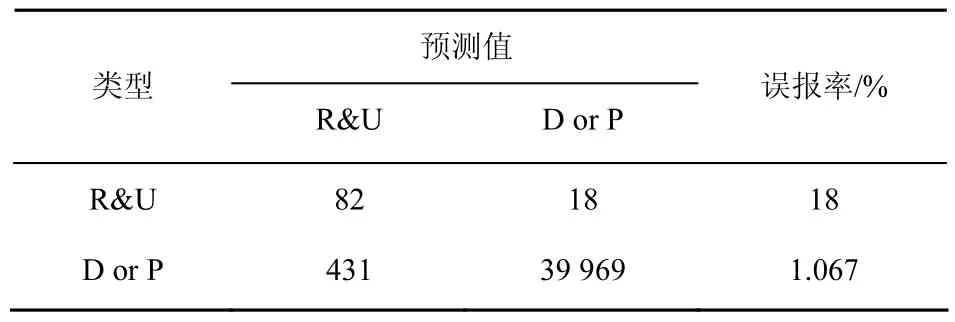
表4 R&U與D or P平均誤報率
對比表3和表4可以看出,相比于SVM方法,距離判別不僅能夠大幅度降低R&U的誤報率,同時,分類正確率較SVM降低得也比較小(R&U的誤報率降低59.09%,而檢測正確率才只下降0.97%),可以認為兩者的分類正確性沒有顯著差別。由此可見,距離判別方法較SVM方法在R&U與D or P分類問題上表現更好。
4.3.2 DoS與Probe分類
類R&U和類D or P充分分開后,再使用SVM構建第三級分類器,對DoS和Probe判別分類,分類結果如表5所示。

表5 DoS和Probe分類結果(5次平均結果)
表5的分類結果表明,SVM方法可以有效地將DoS和Probe分開,具有較高的分類準確率(DoS為99.95%,Probe為98.96%)和正確率(99.94%)。
以上結果表明,采用三級分類器構建的SVM多分類方法,即D-SVM方法,既能保持SVM分類的優勢,同時又能解決由于訓練樣本不足導致分類效果不理想的問題。
4.4 結果比較
為了比較D-SVM方法與其他方法的分類效果,選取了PCA-Logit[18]、CANN[19],結果如表6所示。。
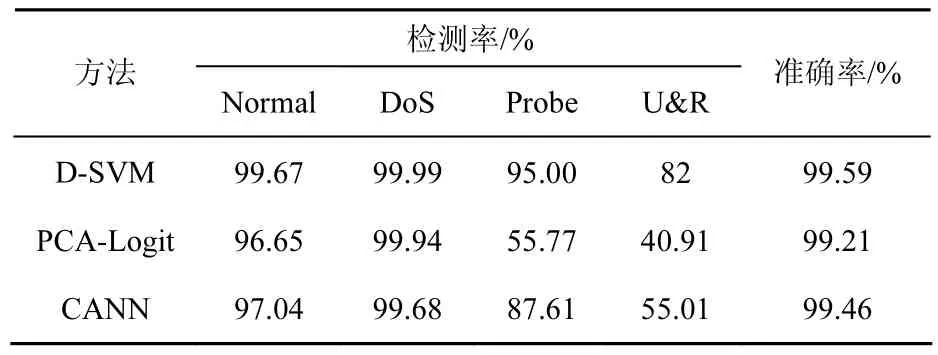
表6 D-SVM與PCA-Logit、CANN分類結果比較
通過表6可以看出,本文提出的D-SVM方法相比于其他2種方法具有一定的優勢,具有較高的整體分類準確率(accuracy)和檢測率(DR)。在整體分類準確率指標上,D-SVM略高于其他2種方法;但在檢測率指標上,D-SVM具有顯著的優勢,尤其體現在U2R和R2L的檢測率上,D-SVM方法的U&R檢測率達到82%,遠遠高于其他2種方法,從而說明,即使在樣本不均衡的情況下,D-SVM較其他2種方法仍然能夠更加準確地識別出U2R和R2L 2類攻擊。因此,與其他2種方法相比,D-SVM具有較高的分類準確率和檢測率;同時還可以較少地受到來自不均衡問題的影響,具有穩健性。
5 結束語
本文基于SVM方法,提出一種綜合判別分析的多分類方法—— D-SVM。通過構建一個三級分類器,實現了正常行為與入侵行為的準確分類以及入侵行為所屬類別分類的功能。第一級分類器利用SVM方法將正常和異常行為分開;第二級分類器利用距離判別分析方法將類R&U和類D or P分開;第三級分類器再利用SVM方法將DoS和Probe分開。并用非參數檢驗的方法選取對分類結果具有顯著影響的特征變量,從而實現降維和提高檢測效率的作用。KDD99數據集的實驗結果表明,本文提出的方法具有較高的分類準確率和較低的誤報率,并克服了由于樣本不均衡導致的訓練不足、分類結果不理想的缺點。
[1] LEE W, STOLFO S J, MOK K W. A data mining framework for building intrusion detection models[C]//The IEEE Symposium on Security and Privacy. c1999: 120-132.
[2] VERWOERD T, HUNT R. Intrusion detection techniques and approaches[J]. Computer Communications, 2002, 25(15): 1356- 1365.
[3] ENDORF C F, SCHULTZ E, MELLANDER J. Intrusion detection & prevention[M]. McGraw-Hill Osborne Media, 2004.
[4] LIAO H J, LIN C H R, LIN Y C, et al. Intrusion detection system: a comprehensive review[J]. Journal of Network and Computer Applications, 2013, 36(1): 16-24.
[5] SHYU M L, CHEN S C, SARINNAPAKORN K, et al. A novel anomaly detection scheme based on principal component classifier[R]. Coral Gables Department of Electrical and Computer Engineering of Miami University, 2003.
[6] JAMDAGNI A, TAN Z, HE X, et al. Repids: a multi tier real-time payload-based intrusion detection system[J]. Computer Networks,2013, 57(3): 811-824.
[7] 胡志鵬, 魏立線, 申軍偉, 等. 基于核Fisher判別分析的無線傳感器網絡入侵檢測算法[J]. 傳感技術學報, 2012(2): 246-250. HU Z P, WEI L X, SHEN J W, et al. An intrusion detection algorithm for wsn based on kernel Fisher discriminant[J]. Chinese Journal of Sensors and Actuators, 2012(2): 246-250.
[8] MOK M S, SOHN S Y, JU Y H. Random effects logistic regression model for anomaly detection[J]. Expert Systems with Applications,2010, 37(10): 7162-7166.
[9] 郭春. 基于數據挖掘的網絡入侵檢測關鍵技術研究[D]. 北京:北京郵電大學, 2014. GUO C. Research on key technologies of network intrusion detection based on data mining[D]. Beijing: Beijing University of Posts and Telecommunications, 2014.
[10] LEE W, STOLFO S J, MOK K W. Adaptive intrusion detection: a data mining approach[J]. Artificial Intelligence Review, 2000, 14(6):533-567.
[11] HWANG T S, LEE T J, LEE Y J. A three-tier IDS via data mining approach[C]//The 3rd Annual ACM Workshop on Mining Network Data. c2007: 1-6.
[12] AN W, LIANG M. A new intrusion detection method based on SVM with minimum within class scatter[J]. Security and Communication Networks, 2013, 6(9): 1064-1074.
[13] MUKKAMALA S, JANOSKI G, SUNG A. Intrusion detection using neural networks and support vector machines[C]//The 2002 International Joint Conference on Neural Networks(IJCNN'02)c2002: 1702-1707.
[14] GAN X S, DUANMU J S, WANG J F, et al. Anomaly intrusion detection based on PLS feature extraction and core vector machine[J]. Knowledge-Based Systems, 2013, (40): 1-6.
[15] 葉鋼, 余丹, 李重文, 等. 一種基于Kolmogorov-Smirnov檢驗的缺陷定位方法[J]. 計算機研究與發展, 2013(4): 686-699. YE G, YU D, LI C W, et al. Fault localization based on Kolmogorov-Smirnov testing model[J]. Journal of Computer Research and Development, 2013(4): 686-699.
[16] 從飛云, 陳進, 董廣明. 基于AR模型的Kolmogorov-Smirnov檢驗性能退化及預測研究[J]. 振動與沖擊, 2012(10): 79-82. CONG F Y, CHEN J, DONG G M. Performance degradation assessment by Kolmogorov-Smirnov test and prognosis based on AR model[J]. Journal of Vibration and Shock, 2012(10): 79-82.
[17] 陳敏. 門限自回歸模型條件異方差的Kolmogorov-Smirnov檢驗[J]. 應用數學學報, 2002(4): 577-590. CHEN M. A Kolmogorov-Smirnov test of conditional heteroscedasticity for threshold autoregressive models[J]. Acta Mathematicae Applicatae Sinica, 2002(4): 577-590.
[18] 李蕊. 基于PCA和LOGIT模型的網絡入侵檢測方法[J]. 成都信息工程學院學報, 2014(3): 261-267. LI R. A network intrusion detection method based on PCA and LOGIT model[J]. Journal of Chengdu University of Information Technology, 2014(3): 261-267.
[19] LIN W C, KE S W, TSAI C F. CANN: an intrusion detection system based on combining cluster centers and nearest neighbors[J]. Knowledge-based systems, 2015, 7(8): 13-21.

張輝(1979-),女,河南鎮平人,碩士,新疆公安廳特別偵察隊技術八級工程師,主要研究方向為網絡與信息安全、網絡偵察技術。

劉成(1985-),男,湖南邵陽人,博士,國家計算機網絡應急技術處理協調中心高級工程師,主要研究方向為網絡與信息安全、網絡攻防技術。
Anomaly intrusion detection based on modified SVM
ZHANG Hui1, LIU Cheng2
(1. Special Reconnaissance Team of Xinjiang Public Security Bureau, Urumpi 830000, China;2. National Computer Network Emergency Response Technical Team/Coordination Center of China, Beijing 100029, China)
A modified SVM multi-classification algorithm integrated with discriminant analysis (D-SVM) was proposed, which could solve the problem of low detection accuracy and high false alarm rate caused by unbalanced datasets. For a multi-classification problem could be divided into several binary classification problems, D-SVM could not only have the virtue of high detection accuracy, but also have a low false alarm rate even confronted with unbalanced datasets. Experiments based on KDD99 dataset verify the feasibility and validity of the integrated approach. Results show that when confronted with multi-classification problems, D-SVM could achieve a high detection accuracy and low false alarm rate even when SVM alone fails because of the unbalanced datasets.
anomaly detection, non-parametric test, SVM classifier, unbalanced datasets, discriminant analysis
TP309/TP274
A
10.11959/j.issn.2096-109x.2016.00092
2016-06-11;
2016-07-23。通信作者:劉成,lc@cert.org.cn
猜你喜歡
中老年保健(2021年12期)2021-11-30 02:58:01
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
攝影之友(影像視覺)(2019年2期)2019-03-05 08:27:14
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
中華詩詞(2018年11期)2018-03-26 06:41:34
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
