壓水堆控制棒導向筒的質量預測研究
2016-11-08 11:11:15楊家榮
上海電氣技術 2016年2期
許 偉, 楊家榮
上海電氣集團股份有限公司 中央研究院 上海 200070
?
壓水堆控制棒導向筒的質量預測研究
許偉,楊家榮
上海電氣集團股份有限公司 中央研究院 上海200070
作為壓水堆核電站核心設備堆內構件的關鍵組件,控制棒導向筒的質量管控一直是制造企業重點關注的問題。為了提高導向筒的產品質量,統計分析了導向筒質量的歷史數據分布情況,采用相關性分析方法找出了影響導向筒質量的關鍵因素,并基于智能化建模方法,構建了導向筒摩擦力的質量預測模型,為保障導向筒質量的穩定性奠定了基礎。
控制棒導向筒; 質量預測; 相關性分析; 神經網絡
堆內構件是壓水堆核電站的關鍵設備[1-2]。如圖1所示,堆內構件由壓力容器內除燃料組件及其相關部件、堆芯測量儀表及壓力容器材料輻照監督管之外的所有其它結構件構成,控制棒導向筒是堆內構件的主要部件之一,為控制棒組件的運動提供定位和導向,使控制棒能夠精準地進出燃料組件,控制燃料組件的反應速率。控制棒導向筒的精密加工和焊接是堆內構件制造國產化的關鍵技術之一[3],它由34個零部件經過繁多的生產工序后裝配而成,如圖2所示。控制棒導向筒中上、下部導向筒裝配時的摩擦力性能指標是評價堆內構件產品質量的一個關鍵參數。百萬千瓦級壓水堆核電站每個機組有61套控制棒導向筒組件,安裝在倒帽形的上部性堆內構件上。摩擦力試驗主要用于測試一組24根吸收棒從上至下通過導向筒上部導向板、中部導向板、下部導向板、特殊導向板及連續導向段組件時的摩擦力[4]。因此,導向筒各零部件的加工、裝配質量都影響著整個導向筒的質量[5]。然而,如何從眾多的生產環節中找出影響導向筒質量的關鍵因素,進而預測導向筒產品的質量,最終保證產品質量的穩定,始終是生產制造企業面臨的巨大挑戰。
以某企業生產的控制棒導向筒為對象,統計分析導向筒摩擦力歷史數據,對各生產工序與摩擦力的相關性進行分析,分別采用不同的方法建立了控制棒導向筒摩擦力預測模型。模型具有較高的預測準確性,為控制棒導向筒質量的有效管控奠定了基礎。
1 導向筒產品質量的分布
通過人工記錄并錄入計算機的方式,共收集了該企業342套控制棒導向筒的摩擦力數據。繪制這些數據的分布曲線,如圖3所示。統計各種摩擦力值出現的頻率,如圖4所示。
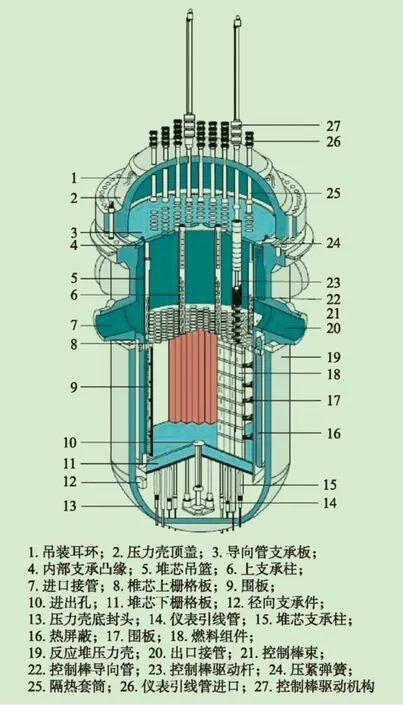
圖1 壓水堆核電站堆內構件結構
由圖3、圖4可知,控制棒導向筒的質量基本符合正態分布,且加工工藝及流程控制較好,使產品的整體摩擦力較設計要求的90N有很大裕量,但仍存在產品的質量波動(如摩擦力為31.5N和34N時),影響質量的穩定性。產品的整體質量較高,勢必造成制造、管理成本增加,因此需要對產品波動情況進行預測,并且應對關鍵工序(零件)與非關鍵工序(零件)的重視程度加以區別對待,平衡整個工藝線路的成本和投入。
2 工序的相關性分析
控制棒導向筒的制造過程是典型的復雜多工序過程,各工序之間具有相關性,上道工序對下道工序的影響始終存在。每道工序的綜合質量既包括工序本身加工的固有質量,又包括上道工序的影響,而且各工序對導向筒摩擦力的影響程度也有所區別。因此,導向筒質量波動來源的辨識是非常復雜的,很難直接發現真正的質量波動源分布在哪些工序中。前期,總結分析出導向筒制造過程中133個工序變量對摩擦力有一定影響,采用相關系數法計算133個工序變量與摩擦力之間的相關程度。

圖2 控制棒導向筒示意圖

圖3 摩擦力數據分布

圖4 摩擦力概率曲線
判斷兩變量是否相關,一般主要看兩方面,即顯著水平與相關系數。顯著水平稱為P值,是判斷相關性時首要考慮的內容。若相關程度不顯著,即使相關系數再高,也只能是偶然因素引起的。一般P值小于0.05即認為顯著。相關系數通常稱為R值,在確認指標顯著的情況下,根據相關系數的高低判斷變量間的相關程度。相關系數是衡量變量之間相關性的特定指標,R值的大小反映兩個變量相關的密切程度。相關系數取值范圍在[-1,1]之間,越接近±1,相關程度越高;越接近0,相關程度越低。相關系數大于0,說明兩個變量正相關,即兩個變量增減變化方向一致;相關系數小于0,說明兩個變量負相關,即兩個變量增減變化方向相反;相關系數等于1,兩個變量完全線性相關;相關系數等于0,兩個變量無直接關系,即不相關。
目前衡量變量間相關程度的系數有皮爾遜系數、斯皮爾曼系數和肯德爾系數三種[6],三者各有一定的適用條件。皮爾遜相關也稱為積差相關,適用于三種情況: ① 兩變量之間是線性關系,都是連續數據;② 兩變量的總體是正態分布,或接近正態的單峰分布;③ 兩變量的觀測值是成對的,每對觀測值之間相互獨立。斯皮爾曼相關系數使用單調函數來描述變量間的相關性,當其中一個變量可以表示為另一個變量的較好的單調函數時(即兩個變量的變化趨勢相同),兩個變量之間的相關系數可以達到+1或-1。斯皮爾曼相關系數只要求兩變量的觀測值是成對的。肯德爾相關系數是一個用來測量兩個隨機變量相關性的統計值,它使用計算而得的相關系數去檢驗兩個隨機變量的統計依賴性。肯德爾相關系數與斯皮爾曼相關系數對數據條件的要求相同。
由于導向筒的摩擦力數據與各工序變量之間的相關程度不明確,因此考慮分別采用以上三種相關系數方法獲得各工序變量與摩擦力的相關系數R值和顯著水平P值,然后選擇由三種相關系數方法得到的R值和P值中均能滿足P<0.05且R>0.15的工序變量作為摩擦力質量的主要影響因素。由皮爾遜、斯皮爾曼和肯德爾相關系數法依次得到40、30和53個工序變量滿足P<0.05且R>0.15,最終選取同時滿足P<0.05且R>0.15的28個變量作為影響導向筒摩擦力的關鍵變量,見表1。
3 導向筒的摩擦力質量預測
對于制造控制棒導向筒這樣的多工序生產過程而言,提高產品質量的核心是減小產品生產過程中出現的波動,而減小質量波動的基本策略是確定主要的波動源,并采取相應的措施[7]。最終導向筒摩擦力質量是之前所有工序的制造質量共同影響后的綜合積累。因此,在確定了影響摩擦力質量的28個關鍵因素之后,即可采取方法,根據已知的關鍵因素數據對未來的摩擦力質量進行預測,判斷摩擦力的變化趨勢。
目前已經出現了很多智能化的建模方法用于描述變量間的復雜非線性關系,如人工神經網絡、支持向量機、極限學習機等。人工神經網絡(Artificial Neural Network, ANN)[8]是在現代神經生物學研究基礎上提出的一種模擬人腦信息處理過程以反映人腦神經網絡特性的計算結構,它是一個高度非線性的網絡系統,具有多層結構,每層結構中包含多個彼此連接的人工神經元(節點)。單個神經元不能處理復雜的問題,只有當大量神經元組成龐大的神經網絡后,才能表現出在處理復雜信息方面的強大能力。支持向量機(Support Vector Machines, SVM)[9]是在統計學習理論的基礎上發展起來的一種新型機器學習方法,基于結構風險最小化原理(Structural Risk Minimization, SRM)產生。與傳統的基于經驗風險最小化原理(Empirical Risk Minimization, ERM)方法(如神經網絡)相比,支持向量機的拓撲結構簡單,適用于解決小樣本、非線性復雜問題。支持向量機能夠根據有限的樣本數據在模型復雜性和學習能力之間維持一個平衡,有助于獲得較好的外推能力,這就有別于基于ERM的神經網絡因過學習而導致預測效果不佳的問題。極限學習機(Extreme Learning Machine, ELM)[10]是近期提出的一種新的單隱層前向神經網絡學習方法,這種學習方法在保證網絡具有良好泛化性能的同時,極大提高了前向神經網絡的學習速度,且避免了梯度下降學習方法的許多問題,如局部極小、迭代次數過多、性能指標及學習率的確定困難等。
選定人工神經網絡、支持向量機和極限學習機三種方法分別構建導向筒摩擦力質量預測模型。將342組導向筒質量的樣本數據分為250組訓練樣本和92組測試樣本,其中訓練樣本用于導向筒質量預測模型的建立,測試樣本用來驗證所建立模型的有效性。三個模型的訓練和測試結果與實際摩擦力值的比較曲線依次如圖5~6、圖7~8及圖9~10所示。由此可知,三個模型的輸出與實際摩擦力值比較接近,表明模型的擬合能力較好。
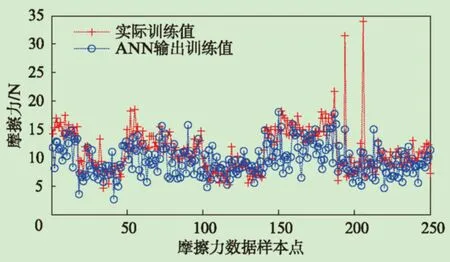
圖5 神經網絡預測訓練數據的摩擦力

圖6 神經網絡預測測試數據的摩擦力

圖7 支持向量機預測訓練數據的摩擦力

圖8 支持向量機預測測試數據的摩擦力
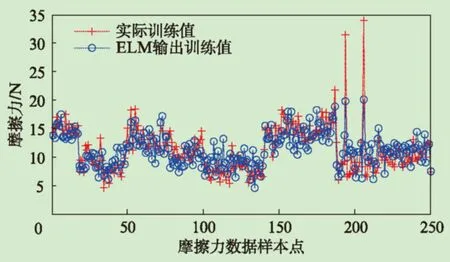
圖9 極限學習機預測訓練數據的摩擦力

圖10 極限學習機預測測試數據的摩擦力
為了進一步說明三個模型的性能,比較模型的訓練、測試誤差(均方誤差、絕對誤差、相對誤差)及建模耗時。由表2可知,三種摩擦力質量預測模型的精度接近,其中ELM的耗時最少,三者均能預測導向筒的摩擦力。由于三種方法在每次建模時模型精度大小存在一定的隨機性,因此考慮選擇三個模型輸出結果的平均值作為摩擦力質量的預測值。
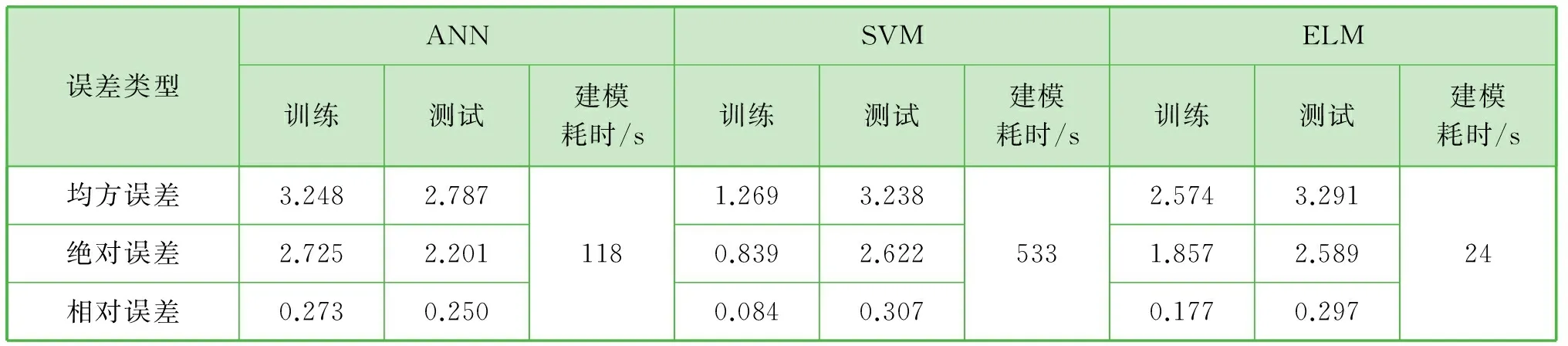
表2 三種摩擦力質量預測模型的預測誤差和運算時間對比
基于以上結果和分析可知,由三種方法建立的導向筒摩擦力質量預測模型適用于摩擦力質量的預測,可為摩擦力變化趨勢的判斷及摩擦力波動源的反向定位提供有力的支撐。
4 結束語
針對壓水堆核電站控制棒導向筒的質量管控問題,收集了導向筒制造過程的質量數據,統計了導向筒摩擦力的分布情況,分析了導向筒的質量穩定性。采用相關性分析方法,找出了與導向筒摩擦力質量密切相關的關鍵影響因素。運用先進的智能建模方法,構建了導向筒摩擦力質量預測模型,基本達到了質量預測的要求,為導向筒質量的進一步控制和管理打下了堅實的基礎。
[1] 孫德意,宋浩亮,許俊斌.從世界核電站發展趨勢看我國核電發展現狀[J].上海電氣技術,2011,4(2): 40-46.
[2] 楊平漢.壓水堆控制棒驅動機構結構設計與制造[J].裝備機械,2014(2): 20-26.
[3] 吳小康.壓水堆核電廠堆內構件制造的質量監督[J].核動力工程,2011,32(1): 16-19.
[4] 周潔.嶺澳二期核電工程控制棒導向筒設備制造的工藝研究及風險控制[J].裝備機械,2013(3): 60-64.
[5] 俞欣,謝紅.核反應堆控制棒導向筒連續段的焊接變形控制[J].裝備機械,2014(4): 16-19.
[6] TAHATA K, MIYAMOTO N, TOMIZAWA S. Decomposition of Independence Using Pearson, Kendall and Spearman’s Correlations and Association Model for Two-way Classifications[J]. Far East J. Theoretical Statistics, 2008,25(2): 273-283.
[7] 戴敏.多工序制造過程質量分析方法與信息集成技術研究[D].南京: 東南大學,2006.
[8] RUMELHART D E, MCCLELLAND J L, PDP Reseach Group. Parallel Distributed Processing: Explorations in the Microstructure of Cognition[M].Cambridge: the MIT Press, 1986.
[9] CORTES C, VAPNIK V. Support-vector Networks[J]. Machine Learning, 1995,20(3): 273-297.
[10] HUANG G B. Learning Capability and Storage Capacity of Two-hidden-layer Feedforward Networks[J]. IEEE Transaction on Neural Network, 2003,14(2): 274-281.
As a key reactor component within PWR nuclear power station, quality control of the guiding cylinder for control rod has been a major issue to be concerned by manufacturing enterprises. In order to improve the quality of the guide cylinder, statistical analysis on the distribution of historical quality data of the guiding cylinder had been conducted. Relevance analysis was adopted to identify the key factors affecting the quality of the guiding cylinder, and quality prediction model for the friction of guiding cylinder was built based on intelligent modeling method, all these measures will establish the foundation to ensure the stable quality of the guiding cylinder.
Guiding Cylinder for Control Rod; Prediction of Quality; Relevance Analysis; Neural Network

上海電氣技術2016,9(2)
2015年12月
許偉(1985—),男,博士,工程師,主要從事制造過程智能化、工業數據分析等工作,
E-mail: xuweisec@126.com
TM623;TL372+.3
A
1674-540X(2016)00-031-06
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·八年級物理人教版(2021年12期)2021-12-31 03:23:08
中學生數理化·中考版(2020年10期)2020-11-27 01:59:48
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
中國生殖健康(2019年2期)2019-08-23 08:12:08
產品可靠性報告(2017年7期)2017-09-05 09:49:12
光學精密工程(2016年6期)2016-11-07 09:07:19
汽車觀察(2016年3期)2016-02-28 13:16:26
核科學與工程(2015年4期)2015-09-26 11:59:03
