面向QEMU的分布式塊存儲系統的設計與實現
2016-11-09 08:22:00張滬濱李小勇
微型電腦應用 2016年4期
關鍵詞:一致性
張滬濱,李小勇
?
面向QEMU的分布式塊存儲系統的設計與實現
張滬濱,李小勇
計算系統虛擬化是當前的主流趨勢,然而為虛擬機磁盤提供存儲的現有后端系統常直接沿襲分布式文件系統的設計,導致一系列虛擬磁盤I/O場景下不必要的開銷。提出的COMET系統,是一個面向QEMU的分布式塊存儲系統。它基于Proactor模式,針對虛擬磁盤I/O特性揚棄文件系統的語義并在數據讀寫與一致性等方面采用精簡合理的設計,盡可能縮短I/O路徑,在具備線性擴展能力、高可用性的同時,實現了寫時復制的磁盤快照和寫時復制的磁盤克隆等創新功能。測試數據表明,COMET在部分I/O場景下擁有足以媲美乃至超越成熟開源系統的性能。
QEMU;塊存儲;分布式;快照;克隆
0 引言
虛擬化是云環境下服務器聚合和彈性資源管理的關鍵使能技術。近年來,諸如PLE、EPT、SR-IOV等新一代硬件加速技術的成功應用和改進[1]使虛擬機對CPU、內存、網卡的訪問效率足以匹敵相同硬件環境下的物理機;而虛擬機磁盤I/O的性能,雖然借由virtio半虛擬化驅動[2]等技術在前端進行了大量優化,但仍隨后端存儲具體實現的不同,呈現出巨大的靈活性與提升空間。
目前,虛擬塊設備(VBDs)是為虛擬機提供塊存儲的主流解決方案[3,4]。該方案中,將虛擬磁盤作為一個抽象的文件存儲在DAS、SAN、NAS或提供塊設備接口的分布式文件系統中。然而,DAS不易擴展,SAN的性能依賴于高價的Fibre-Channel協議專用硬件且擴展性有限,NAS缺乏高可用配置容易形成單點故障且后期的擴展成本高,它們都無法滿足云規模的IaaS服務場景。分布式文件系統的根本設計目的是面向文件,而非面向虛擬磁盤文件,使用分布式文件系統存儲虛擬磁盤文件并提供塊設備接口雖然充分利用了分布式文件系統本身的可擴展性、高可用性等優點,但也同時強制引入文件系統的諸多復雜語義,導致了虛擬磁盤I/O場景下的不必要開銷。例如,一般分布式文件系統中,用戶位于云運營商管轄范圍之外。對于多用戶共享同一文件的場景,必須統一使用鎖或租約等同步機制;對于多用戶各自獨占文件的場景,必須結合元數據進行相應的訪問控制機制;對于一致性場景,也必須在站在多用戶的角度進行復雜設計實現而產生較大的開銷……在虛擬磁盤I/O場景下,虛擬磁盤的直接用戶是位于云運營商管轄范圍之內的虛擬機,每個虛擬機對自身的磁盤獨占使用,互不干擾,相對于分布式文件系統,在提供的語義、鎖機制、元數據管理、一致性等諸多方面都能夠得到巨大的簡化。
基于此,本論文提出并實現專用于為IaaS虛擬機提供塊存儲的COMET分布式塊存儲系統。它提供針對虛擬磁盤I/O場景的最小化語義,避免了不必要的性能損耗。它基于無中心架構,不會出現單點故障并且具備線性擴展能力。它采取雙副本和強一致性,為高可用性提供保障。此外,COMET實現了寫時復制的磁盤快照和寫時復制的磁盤克隆等創新功能。
本論文其余部分組織如下:第1部分闡述近年來為虛擬機提供后端磁盤存儲的相關研究,第2部分詳述系統設計,第3部分進行性能測試與對比,第4部分為總結和展望。
1 相關工作
論文MOBBS: A Multi-tier Block Storage Systemfor Virtual Machines using Object-based Storage[5]使用HDD和SSD的混合介質為虛擬機提供后端存儲,并提出了Hybrid Pool技術對不同介質的設備進行有效利用。
論文PIOD: A Parallel I/O Dispatch Model Based on Lustre File System for Virtual Machine Storage[6]基于Lustre并行分布式文件系統,通過OST_Queue技術將I/O請求按照對應物理磁盤位置分批提交,減少磁頭抖動提高性能。
開源分布式文件系統Ceph[7]通過librbd為虛擬機提供塊存儲,后者導出了創建卷、克隆卷、創建快照、快照回滾、讀寫數據等一系列API。然而,Ceph在塊存儲方面表現出的擴展速度慢、集群不穩定等現象常被人們所詬病。
開源分布式對象存儲系統Sheepdog以輕量級的代碼為虛擬機提供塊存儲。Sheepdog采用多副本模式,以Zookeeper或corosync進行管理集群,也支持日志和糾刪碼。
開源系統OpenStack與Cinder結合使用可以達到提供塊存儲的目的[8],其中,OpenStack是存儲資源的提供者,而Cinder是分布式塊存儲的API框架,Cinder主要與OpenStack中的Nova交互,通過軟件定義方式,向上層提供塊存儲視圖。
Amazon是虛擬機IaaS云服務的首要運營商之一,其中虛擬機后端存儲由Amazon EBS提供。Amazon EBS 主要提供兩種虛擬磁盤卷:能夠激增至數百IOPS的標準卷和支持4000IOPS的預配置IOPS卷,并允許對虛擬磁盤卷隨時進行創建、刪除、遷移、快照等操作。Amazon EBS憑借其強大的彈性服務成為業界翹楚,然而其技術細節并無公開資料供檢索。
2 系統設計與實現
2.1 總體架構
COMET主要涉及3個層次,如圖1所示:

圖1 系統架構總圖
虛擬機集群、服務器集群和物理磁盤群,服務器集群和物理磁盤群構成COMET分布式塊存儲系統的主體,每個服務器掛載不定量的多個物理磁盤。圖1給出了包含虛擬機集群在內的系統架構總圖。
虛擬磁盤在COMET中以4M分割,每個4M塊稱為一個Chunk,每個Chunk作為服務器上的一個文件存儲于物理磁盤中,多個Chunk散布于不同的物理磁盤乃至不同服務器上,對同一虛擬磁盤的讀寫可以通過多個底層物理磁盤的協作來提高效率。
出于可用性考慮,服務器集群由兩個隔離域組成,該兩域位于不同機房,以降低同時掉電等事故的概率。每個隔離域中包含多臺服務器,支持服務器的動態加入和移出。每個Chunk有兩個副本,分別位于隔離域A和隔離域B中,雙副本和隔離域對客戶機透明而對QEMU不透明,這里通過改進的一致性哈希算法實現Chunk的定位。COMET采取去中心架構,徹底避免了單點故障,具備線性擴展能力。
2.2 QEMU端I/O設計
本論文選用了支持KVM[9]與virtio的高性能開源Hypervisor QEMU[10]作為客戶機與物理機的中間層。為構建完整的I/O路徑,必須成功建立自客戶機應用層到COMET后端存儲的I/O回路。這一步的關鍵是,在貫穿客戶機與宿主機的復雜I/O棧中,確定合適的層次將接收到的I/O指令移接至COMET存儲,并在成功執行指令后將I/O數據或完成狀態回送至該層。為性能計,必須保證總I/O路徑盡可能短。
用宿主機本地磁盤為客戶機虛擬磁盤存下的I/O路徑圖,如圖2所示:
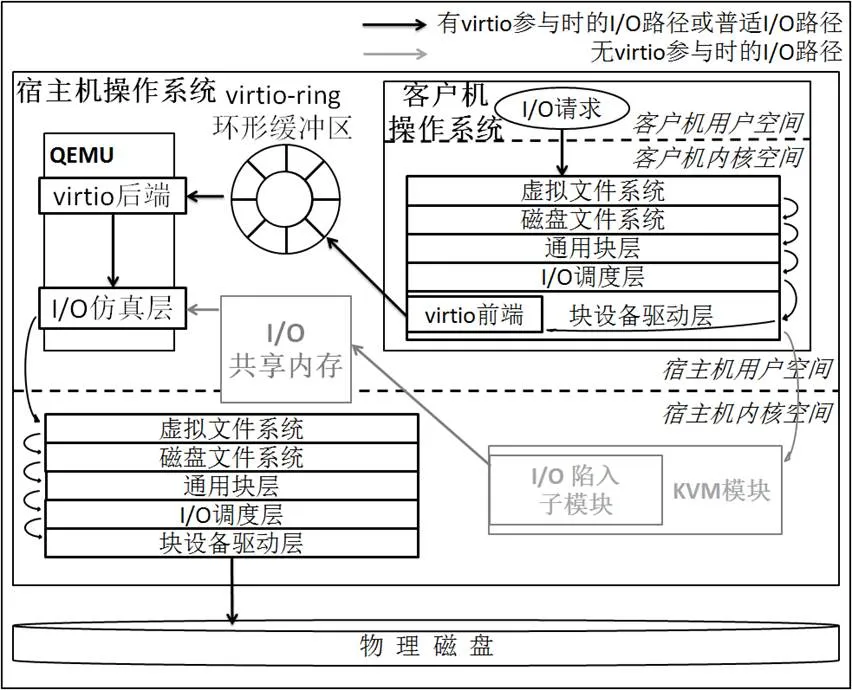
圖2 I/O路徑示例圖
其中只畫出I/O指令的下發路線,I/O數據或狀態的回送路線與之互逆。啟用virtio時,位于客戶機操作系統的virtio前端和QEMU中的virtio后端里應外合,自客戶機用戶空間下達的讀寫指令傳送到塊設備驅動層時被virtio前端截獲,經由virtio-ring環形緩沖區傳至virtio后端,進而抵達QEMU中的I/O仿真層。圖2場景下,I/O仿真層代碼通過相應系統調用讀寫位于宿主機本地磁盤上為客戶機磁盤提供存儲的文件,最終讀寫物理磁盤。不啟用virtio時,客戶機I/O指令到達塊設備驅動層后,繼續向客戶機視角下的底層磁盤設備傳送,進而被宿主機KVM模塊的I/O陷入子模塊截獲,通過共享內存頁的方式輸送給QEMU中的I/O仿真層,后續過程與啟用virtio的情形相同。對比知,virtio的存在,繞過了傳統的KVM的I/O陷入方式,不僅減少了CPU通過VM entry、VM exit在根模式與非根模式之間切換的次數[11],而且減少了宿主機在用戶空間和內核空間切換的次數,極大地提高了效率。
基于此,在客戶機的內部的I/O棧里進行I/O指令的接收和I/O路徑的移接相當于放棄了virtio對虛擬機I/O的優化效應,并不合理;而在宿主機的內核I/O棧里這樣做則會導致I/O路徑過長,同樣不合理。COMET最終采用的方案為:在距離virtio后端最近的I/O仿真層實現并添加新的代碼塊,將接收到的I/O指令解析后提交給后端的分布式存儲,并根據后端存儲返回的I/O數據或狀態在該層提交給QEMU,構成I/O回路。
2.3 數據一致性
分布式文件系統中,對一致性的實現必須考慮位于多個物理節點的多個用戶共享同一文件情形下的多副本一致性,其實現往往需要借助Paxos[12]等成熟協議。而虛擬磁盤I/O場景下,同一虛擬磁盤的唯一用戶為位于同一物理節點上的客戶機,使問題得到了巨大簡化。COMET針對虛擬磁盤I/O場景實現了雙副本的強一致性。
COMET為每一個Chunk維護一個版本號信息,QEMU端維護著對應虛擬磁盤全部Chunk的版本信息(以1TB虛擬磁盤為例,占用內存空間為1M)。讀操作不改變版本號,寫操作使版本號增1,無論讀寫,COMET在回執中攜帶相應Chunk的版本號以供QEMU端對照。對于寫操作,QEMU端等待兩個副本所在服務器都回執寫成功后才向客戶機報告寫成功(故障導致超時的情形下允許以單個副本的寫成功標識成功),同時更新本地維護的Chunk版本號;對于首次讀操作,QEMU端向兩個副本分別索要版本號,若一致,則任選其一拉取數據;若不一致,則觸發修復事件,先使用高版本Chunk覆蓋低版本Chunk,再讀出數據。對于后續讀操作,QEMU任選一個副本進行交互。
為說明故障場景下的強一致性,不妨假設客戶機A在對某Chunk進行讀寫,Chunk的兩個副本為甲和乙。一個典型的過流程為:

① A首次讀Chunk②乙所在服務器宕機③ A無法與乙所在服務器建立連接,轉而與甲副本交互④ A寫甲副本,甲副本版本號更新,A更新自己維護的對應Chunk的版本號⑤ 乙所在服務器重啟⑥ A讀到乙副本,發現返回的版本號與維護的Chunk版本號不同,觸發修復事件⑦乙副本被修復⑧A讀到最新數據⑨后續讀寫注:若第⑥步未發生,則COMET后臺修復進程會對低版本乙進行發現,仍觸發修復,之后A再讀乙將直接得到新版本的數據。
在分布式文件系統中,則無法采用該方法,這是因為,分布式文件系統中多用戶位于多個物理節點,即便令其在本地維護Chunk的版本號,在文件共享情形下,所維護的版本號無法及時更新,從而在不同用戶間產生分歧。以位于不同物理節點的用戶A、B讀同一Chunk的甲、乙副本為例,一個可能的流程為:

① A首次讀Chunk②B首次讀Chunk③乙所在服務器宕機④ A無法與乙所在服務器建立連接,轉而與甲副本交互⑤ A寫甲副本,甲副本版本號更新,A更新自己維護的對應Chunk的版本號,B不知道A對Chunk進行了寫操作,未更新本地維護的Chunk的版本號⑥乙所在服務器重啟⑦ B讀到乙副本,發現返回的版本號與維護的Chunk版本號相同,認為讀操作成功,從而B讀到舊數據,強一致性被破壞
可見,COMET強一致性的實現是針對虛擬磁盤I/O場景的精簡實現,該實現避免了分布式文件系統中強一致性對應的復雜設計所帶來的開銷,提高了性能。
2.4 快照與克隆
COMET系統實現寫時復制的磁盤快照和寫時復制的磁盤克隆的創新功能。COMET中一個Chunk在讀、寫、快照等混合請求下的事件時序圖,如圖3所示:

圖3 快照時序圖
COMET中,所有客戶機的虛擬磁盤都基于一個事先建立好的根磁盤快照,稱為S0。建立一個虛擬機的過程即將該虛擬機的物理存儲導向S0,除此之外不需要做任何事情。對S0的首次寫會導致創建真正的客戶機Chunk,稱為C。數據寫入C而不影響S0。后續讀寫都在C上執行。
COMET結合時間戳(實際上是以時間戳為主體結合遞增數字字串的可區分字符串)來輔助快照的管理。對于拍攝快照請求,系統只是記錄請求時間戳,在后續發生寫操作時,才真正創建快照Chunk并維護其Chunk時間戳。圖3中t1時刻由寫操作觸發所創建的St1,同時作為S1和S2的快照Chunk。對于讀請求,直接在當前Chunk執行。對于寫請求,需結合時間戳檢查之前是否有未處理的快照請求(即該請求并無與之對應的新建快照Chunk),若存在,則新建快照Chunk,否則直接寫入。對于快照讀取請求,若存在未處理的快照請求,則保存當前Chunk為快照Chunk,否則自所讀取快照的請求時間戳向后,定位至最近的快照Chunk,同時清理當前Chunk。對于快照刪除請求,若存在未處理的快照請求,則保存當前Chunk為快照Chunk,以圖3中刪除S1為例,繼而,先找到位于S1請求時間戳之后的最近快照Chunk St1,再自St1向前回溯至最近的快照Chunk(這里為S0),若兩個快照Chunk之間除待刪除快照外還存在其他快照(這里為S2),則只刪除S1的維護信息,不刪除快照Chunk;若兩個快照Chunk之間只有待刪除快照且其對應快照Chunk不是當前Chunk,則真正刪除快照Chunk。COMET根據時間戳找尋快照Chunk的過程中是以快照鏈為外沿進行的。舉例而言,在圖3基礎上,若先讀取快照S1再經歷讀寫并產生快照S4,雖然全局范圍內,自S4請求時間戳向前的最近快照Chunk為St2,然而St2(對于S3)和S4分屬不同的快照鏈,故對COMET而言,S4請求時間戳之前的最近快照為位于S4快照鏈上的St1。
基于該實現,克隆客戶機類相當于為當前Chunk拍攝快照,而舊客戶機和新客戶機成為該快照下的兩個分支,由于磁盤快照本身幾乎不消耗時間,故而磁盤克隆也可以瞬時完成。
3 讀寫性能測試
3.1 測試環境
硬件方面,本測試使用3臺配有Intel(R) Xeon(R) CPU E5506系列4核處理器、16G內存、7200轉1TB SATA盤的服務器。服務器之間使用Intel X520-SR1 10Gbps網卡、高速網線、DELL N4032萬兆以太網交換機互連。其中,服務器A作虛擬機節點,服務器B、C除引導盤外分別掛載八塊磁盤,用作后端存儲節點。
軟件方面,3臺服務器均安裝基于Linux-2.6.32內核的CentOS6.6,A上采用針對COMET添加了I/O仿真層代碼的qemu-2.3.0作Hypervisor,并啟用kvm和kvm-intel模塊,為虛擬機分配4GB內存。
3.2測試方案
本論文分別測試基于COMET與成熟開源分布式對象存儲系統Sheepdog的前端虛擬機I/O性能并進行對比,其中COMET和Sheepdog均采用雙副本。具體測試涵蓋 {1~512線程} × {4K~4M讀寫塊} × {順序讀寫, 隨機讀寫} 的全部情形。測試工具為Fio,測試方法為在虛擬機上安裝Fio并執行語句:
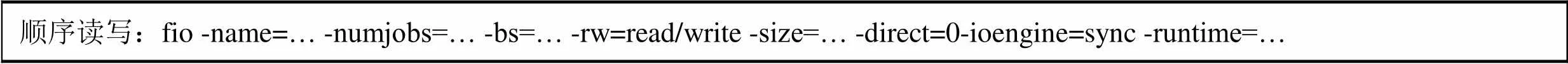
順序讀寫:fio -name=… -numjobs=… -bs=… -rw=read/write -size=… -direct=0-ioengine=sync -runtime=…
隨機讀寫:fio-name=… -numjobs=… -bs=…-rw=randread/randwrite -size=… -direct=1 -ioengine=libaio -iodepth=8 -runtime=…
3.3 主要結果
限于篇幅,這里選用較有代表性的128KB塊大小多線程順序讀寫和4KB塊大小多線程隨機讀寫的測試數據進行闡述。COMET和Sheepdog的性能對比如圖4所示:
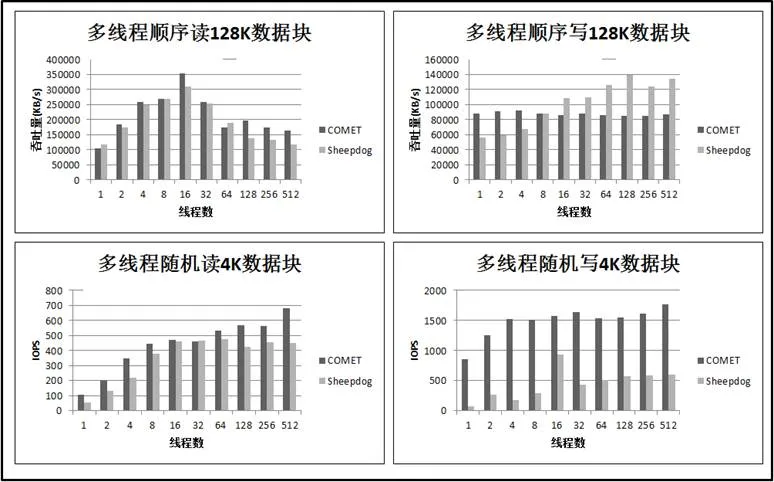
圖4 多線程讀寫性能對比
其中,COMET順序讀性能比Sheepdog略高,隨機讀性能高出Sheepdog較多,隨機寫性能明顯高于Sheepdog且比Sheepdog穩定,這不僅得益于針對性的設計,也得益于系統內部高并發架構的實現與異步IO的成功使用。
對于順序寫,COMET在多于16線程的情形下明顯低于Sheepdog。這是因為Sheepdog在其QEMU端驅動和后端存儲之間維護了寫緩存,該緩存的命中減少了交付后端的寫請求個數從而提高性能。COMET尚未實現緩存機制,然而考慮到寫緩存會降低系統可靠性,擬只實現讀緩存。
4 總結
COMET系統的創新性在于:1)針對虛擬磁盤I/O場景揚棄了文件系統的語義,在數據讀寫和一致性等方面采用了精簡合理的設計;2)實現了寫時復制的磁盤快照和寫時復制的磁盤克隆等創新功能。
COMET的不足在于尚未實現緩存機制(為可靠性計,擬只實現讀緩存),性能上仍存在優化空間。就業界現狀而言,除內存緩存外,使用大容量SSD的為分布式系統提供緩存也已成為技術熱點。在后續工作中,COMET系統將構建基于內存與SSD的多層讀緩存,力求性能上的進一步階躍。
參考文獻:
[1] Dong Y, Zheng Z, Zhang X, et al. Improving virtualization performance and scalability with advanced hardware accelerations[C]//Workload Characterization (IISWC), 2010 IEEE International Symposium on. IEEE, 2010: 1-10.
[2] Russell R. virtio: towards a de-facto standard for virtual I/O devices[J]. ACM SIGOPS Operating Systems Review, 2008, 42(5): 95-103.
[3] Tarasov V, Hildebrand D, Kuenning G, et al. Virtual machine workloads: the case for new benchmarks for NAS[C]//FAST. 2013: 307-320.
[4] Tarasov V, Jain D, Hildebrand D, et al. Improving I/O performance using virtual disk introspection[C]//Proceedings of the 5th USENIX conference on Hot Topics in Storage and File Systems. USENIX Association, 2013: 11-11.
[5] Ma S, Chen H, Lu H, et al. MOBBS: A Multi-tier Block Storage Systemfor Virtual Machines usingObject-based Storage[C]//High Performance andCommunications (HPCC), 16th International Conference on. IEEE, 2014: 272-275.
[6] Lei Z, Zhou Z, Hu B, et al. PIOD: A Parallel I/O Dispatch Model Based on Lustre File System for Virtual Machine Storage[C]//Cloud and Service Computing (CSC), 2013 International Conference on. IEEE, 2013: 30-35.
[7] Weil S A, Brandt S A, Miller E L, et al. Ceph: A scalable, high-performance distributed file system[C]//Proceedings of the 7th symposium on Operating systems design and implementation. USENIX Association, 2006: 307-320.
[8] Rosado T, Bernardino J. An overview of openstack architecture[C]//Proceedings of the 18th International Database Engineering & Applications Symposium. ACM, 2014: 366-367.
[9] Ali S. Virtualization with KVM[M]//Practical Linux Infrastructure. Apress, 2015: 53-80.
[10] Huynh K, Hajnoczi S. KVM/QEMU storage stack performance discussion[C]//Linux Plumbers Conference. 2010.
[11] Uhlig R, Neiger G, Rodgers D, et al. Intel virtualization technology[J]. Computer, 2005, 38(5): 48-56.
[12] Zhao W. Fast Paxos Made Easy: Theory and Implementation[J]. International Journal of Distributed Systems and Technologies (IJDST), 2015, 6(1): 15-33.
Design and Implementation of Distributed Block Storage for QEMU
Zhang Hubin, Li Xiaoyong
(College of Information Security, Shanghai Jiaotong University, Shanghai 200240, China)
Virtualization of computing system has become a main trend. However,currentbackend storage implementationsfor virtual machine disks usuallyreference directly from distributed file system, resulting in a series of unnecessary overhead in virtual disk I/O scenarios.The COMET system presented by this paper is a distributed block storage systems for QEMU. Based on Proactor mode, COMET abandons the semantics of the file system, takes reasonable design in data access as well as consistency and maintains a minized I/O path for virtual disk I/O scenarios. Withlinear scalability, high availability, COMET implemented innovative features such as write-on-copy disk snapshot and write-on-copyclone.Results show that COMET has a performance comparable to or even betterthan mature open source systems in certain I/O scenarios.
QEMU; Block Storage; Distributed System;Snapshot; Clone
1007-757X(2016)04-0054-04
TP311
A
(2015.09.06)
張滬濱(1990-),男,上海交通大學,信息安全工程學院,碩士,研究方向:操作系統、網絡、存儲、分布式,上海,200240
李小勇(1972-),男,上海交通大學,信息安全工程學院,副教授、博士,研究方向:操作系統、網絡、存儲、分布式,上海,200240
猜你喜歡
遼寧教育(2022年19期)2022-11-18 07:20:42
公民與法治(2022年5期)2022-07-29 00:47:28
汽車實用技術(2022年9期)2022-05-20 05:51:26
教學考試(高考物理)(2021年5期)2021-11-08 10:31:22
歷史教學問題(2021年4期)2021-11-05 07:02:34
中醫眼耳鼻喉雜志(2021年1期)2021-07-22 07:38:14
裝備制造技術(2020年11期)2021-01-26 00:39:12
中國公共安全(2017年11期)2017-02-06 05:28:08
電測與儀表(2016年7期)2016-04-12 00:22:18
燕山大學學報(2015年4期)2015-12-25 02:19:49
