一種基于FPGA的頻域脈沖壓縮處理器的實現
2016-11-17 08:32:33顧峰,戴健
艦船電子對抗 2016年4期
顧 峰,戴 健
(中國船舶重工集團公司第723研究所,揚州 225001)
?
一種基于FPGA的頻域脈沖壓縮處理器的實現
顧 峰,戴 健
(中國船舶重工集團公司第723研究所,揚州 225001)
針對某搜索雷達波束個數多、碼型種類多的特點,設計了一種基于現場現場可編程門陣列(FPGA)的頻域脈沖壓縮處理模塊。其中的快速傅里葉變換(FFT)/逆快速傅里葉變換(IFFT)使用流結構,同時為了減少量化誤差的影響,FFT采用塊浮點運算。模塊使用外部雙倍速率(DDR)同步動態隨機存儲器(SDRAM)緩存脈壓前的數字波束形成(DBF)數據、脈沖壓縮系數。文章還對正斜率和負斜率調頻信號所對應脈壓系數的關系進行了推導,結果使得脈壓系數的存儲空間減少了一半。
現場現場可編程門陣列;脈沖壓縮;快速傅里葉變換;塊浮點;頻域
0 引 言
脈沖壓縮技術在現代雷達中被廣泛采用。脈沖壓縮雷達發射時采用寬脈沖調制信號以提高發射的平均功率,保證足夠大的作用距離;而接收時采用相應的脈沖壓縮算法獲得窄脈沖,以提高距離分辨率。脈壓技術較好地解決了雷達作用距離與距離分辨率之間的矛盾,而且壓縮是對已知信號做處理,所以脈壓技術抗干擾能力也較強[1]。
近年來隨著高性能現場可編程門陣列(FPGA)的出現,由于其具有高度并行性處理、流水線處理、低功耗等優勢,使用FPGA進行雷達信號處理成為一種普遍現象。此外,FPGA有豐富的IP核,這些知識產權核可以大大簡化FPGA的設計,加速設計速度,縮短研發周期。
本文針對某搜索雷達波束個數多、碼型種類多的特點,設計了一種基于FPGA的頻域脈沖壓縮處理器,該處理器具有設計靈活,調試方便,可擴展性強的特點。
1 脈沖壓縮處理技術
數字脈沖壓縮的實現方式有2種: 一是時域卷積法;二是頻域乘積法。
時域脈沖壓縮的過程是通過對接收信號s(n)與匹配濾波器脈沖響應h(n)求卷積的方法實現的:
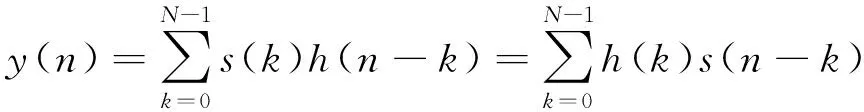
(1)
式中:N為匹配濾波器沖激長度。
根據匹配濾波理論:
(2)
即匹配濾波器是輸入信號的共軛鏡像。
由傅里葉變換的性質可知,時域卷積相當于頻域相乘,因此,式(1)可以采用快速傅里葉變換(FFT)及反變換(IFFT)在頻域內實現。用公式表示為:
y(n)=IFFT[S(W)*H(W)]=
IFFT[FFT(s(n))*FFT(h(n))]
(3)
一般情況下,對于大時寬帶寬積信號,用頻域脈壓較好;對于小時寬帶寬積信號,用時域脈壓較好[2]。本文中脈沖壓縮處理器即是基于頻域法實現的,其原理框圖如圖1所示。

圖1 頻域脈壓原理圖
2 系統硬件平臺
該脈沖壓縮處理器用于某相控陣搜索雷達的信號處理部分。該雷達在陣面上完成數字波束形成(DBF),通過光纖將DBF數據發送給信號處理機,要求在信號處理機中完成脈沖壓縮、動目標檢測等處理,并將處理結果發送給PowerPC進行數據處理。其硬件結構如圖2所示。

圖2 硬件平臺示意圖
系統的硬件主要由光電轉換模塊、雙倍速率(DDR)同步動態隨機存儲器(SDRAM)存儲器、FPGA、PowerPC組成。DBF分機通過2根光纖將DBF數據發送給信號處理分機,傳輸協議為Aurora幀格式。1個PRT的數據組成1幀數據,1幀數據由固定長度的處理模式參數(包含DBF數據長度、波束數、碼型、處理模式等信息)和可變長度的DBF數據組成。該雷達在1個脈沖重復時間(PRT)內同時形成16個波束,波束的數據率為10 MHz,數據位寬為32 bit,雷達根據工作模式的不同,使用不同的PRT及不同的碼型,一個PRT內(一個波束的)DBF數據的長度最大為7 500個。
16個波束的DBF數據的帶寬為5 120 Mbps(16·10 MHz·32 bit),本系統傳輸DBF數據的光纖為2根,每根的波特率為4 Gbps,考慮到8b10b編碼及Aurora協議的效率,該光纖通道也是能滿足DBF數據傳輸要求的。光電轉換模塊使用的是武漢永力公司的TLD850M10GR,該光模塊最大支持6.25 Gbps的傳輸波特率。
由于該雷達的DBF數據以及碼型較多,但FPGA的片內存儲資源有限,且FPGA需完成較多的信號處理任務,設計使用外部DDR來緩存脈壓前的DBF數據、脈壓系數等,考慮到DBF數據的速率為5 120 Mbps及DDR訪問的效率0.8(為保險起見,按0.8考慮,實際測試約為0.89),外部DDR緩存的訪問速度至少為12.5 Gbps(5 120 Mbps·2·1.25)。在本設計中,DDR芯片選用Micron公司的MT41J128M16HA-125T,該芯片的數據位寬為16 bit,存儲容量為256 MB(128 MHz·16 bit)。該芯片的最大數據速率可以達到1 600 MT/s,即讀寫速度可以達到25.6 Gbps(1.6 GHz·16 bit),可以滿足應用。
FPGA是信號處理分機的主要芯片,DBF數據接收、DDR控制器以及脈沖壓縮模塊等均在FPGA中實現,根據處理資源的評估,FPGA芯片選用Xilinx公司的xc7v485t。FPGA的功能示意圖如圖3所示。上電后,PowerPC將各碼型的脈壓系數通過串行高速輸入輸出(SRIO)發送給FPGA,FPGA將其寫入DDR的相應空間中,同時PowerPC在FPGA中建立不同碼型所對應的脈壓系數,存放在DDR地址空間的索引表。FPGA將接收到的DBF數據寫入DDR中,一幀數據接收完后,FPGA先從DDR中讀取該幀數據的工作參數,根據工作參數中的碼型信息,從脈壓系數的地址索引表獲取對應的脈壓系數存放地址空間,然后從DDR的相應空間中加載脈壓系數到片內存儲空間;順序從DDR中讀取波束0~波束15的DBF數據到脈壓模塊,完成16個波束的脈沖壓縮處理,再將處理結果送入后面的處理模塊繼續進行其他的處理。DBF數據的接收緩存和其脈沖壓縮處理是并行進行的,即對當前接收到的DBF數據幀緩存的同時,可以對之前已緩存的DBF數據幀進行脈壓處理。下面重點介紹脈沖壓縮處理模塊的設計,關于數據緩存部分的DDR控制器及其直接存儲器存取(DMA)控制器的設計可參考文獻[4]。

圖3 FPGA的功能示意圖
3 脈壓模塊的設計
3.1 FFT結構的選擇
從圖1容易看出,脈沖壓縮模塊所占用資源幾乎都為傅里葉變換(FFT)/逆傅里葉變換(IFFT)所占用,應盡量減少脈沖壓縮模塊中FFT所占用的資源(片內塊隨機存取存儲器(BRAM)存儲資源、DSP48運算單元)。Xilinx公司提供了快速傅里葉變換IP核,可通過控制配置端口的信號來實時設置FFT變換長度,設置FFT運算或IFFT運算,這在很大程度上為設計提供了便利。該IP核提供3種結構選擇[3]:
(1) 基-2,突發I/O。這種結構采用單個基-2蝶形單元對輸入數據進行變換,運算消耗的時間最長,資源消耗最少。
(2) 基-4,突發I/O。這種結構采用單個基-4蝶形單元對輸入數據進行變換,并利用BRAM來存儲旋轉因子,運算消耗的時間較長,資源消耗較少。
(3) 流水線型,數據流水I/O。這種結構將若干基-2蝶形單元級聯起來,使得數據的輸入、計算、輸出可以流水進行,從而可以達到很高的處理速度,但資源消耗較大。
在本設計中,FFT的工作頻率為200 MHz,通過仿真可知,在該工作頻率下,2個基-2的FFT(1個FFT、1個IFFT)可在1個PRT內完成1個波束的脈沖壓縮運算,16個波束的脈沖壓縮需要32個基-2的FFT;1個基-4的FFT(FFT和IFFT復用1個IP核)可在1個PRT內完成1個波束的脈沖壓縮運算,16個波束的脈沖壓縮需要16個基-4的FFT;2個流水線型FFT(1個FFT、1個IFFT)可在1/18的PRT內完成1個波束的脈沖壓縮處理,16個波束可復用該脈壓模塊,即16個波束的脈沖壓縮只需要2個流水線型的FFT。
考慮到最長PRT的DBF數據長度及碼型寬度,FFT的長度選擇為8 192點。當然,隨著PRT的減小,可通過FFT的配置端口相應減少FFT的變換長度。使用不同結構的FFT完成16個波束的脈沖壓縮所占用資源如表1所示。

表1 脈壓模塊占用資源
從表1可知,流水型的FFT占用資源最少,因此選擇了該結構,16個波束的DBF數據共用1個脈沖壓縮模塊,順序對每個波束的DBF數據進行處理,為此,需要使用DDR緩存脈壓前的16個波束的DBF數據。
3.2 脈壓系數
脈壓系數H(W)即為匹配濾波器脈沖響應h(n)的傅里葉變換。一般情況下,為了節省處理時間和處理資源,脈壓系數都是事先算好,存儲在片內的存儲空間(如只讀存儲器(ROM))中。由于該雷達碼型較多,有多種脈寬的線性調頻、非線性調頻的發射波形,如將其對應的脈壓系數都存儲在FPGA的片內存儲空間,將會占用很多的存儲空間,為了節省寶貴的片內存儲空間,上電后,PowerPC將各碼型的脈壓系數發送給FPGA,FPGA將其寫入DDR的相應空間中。脈壓處理之前,FPGA首先將當前碼型所對應的脈壓系數從DDR中讀取并寫入片內的BRAM中;FFT輸出時,順序從BRAM中讀取脈壓系數,并將其與FFT輸出數據相乘的結果作為IFFT的輸入。
在本設備中發射波形為正斜率調頻信號,由于混頻器高低本振的原因,在14.5 GHz頻率以下接收波形為正斜率,在14.5 GHz以上接收波形為負斜率,為此,每種碼型需有2套脈壓系數(正斜率和負斜率),但通過計算可知,負斜率的脈壓系數可通過簡單的變換正斜率的脈壓系數獲得。
負斜率的脈壓系數H-(W)為其脈沖響應的h-(n)的傅里葉變化:
(4)
式中:N為FFT點數。



real[H+(-W)]-j·imag[H+(-W)]
(5)
若將式(5)乘以j的結果作為脈壓系數,則其脈壓結果為原脈壓結果乘以j,這對脈壓的性能指標沒有任何影響。即脈壓系數可表示為:
H-(W)={real[H+(-W)]-j·imag[H+(-W)]}·j=imag[H+(-W)]+j·real[H+(-W)]
(6)
因此,負斜率的脈壓系數的實部為正斜率脈壓系數的虛部的鏡像,負斜率脈壓系數的虛部為正斜率脈壓系數實部的鏡像。這使得負斜率的脈壓系數不需要存儲,只需簡單地對正斜率的脈壓系數進行鏡像處理即可獲得,鏡像處理在FPGA中是容易實現的。當接收波形為正斜率時,存儲脈壓系數的BRAM的讀取地址順序為0~FFTN_1(FFTN_1為FFT點數減1);當接收波形為負斜率時,存儲脈壓系數的BRAM的讀取地址順序為FFTN_1~0。使用該方法對負斜率的回波進行脈壓處理的仿真結果如圖4所示(所仿真回波為線性調頻(LFM)信號,帶寬為5 MHz,時寬為10 μs,脈壓系數使用海明窗加權)。
3.3 塊浮點數據格式及其定點化
在數字信號處理系統中,數據表示格式可分為定點制、浮點制和塊浮點制,它們在實現時對系統資源的要求不同,工作速度也不同,有著不同的適用范圍[5]。
定點表示法使用最多,簡單且速度快,但動態范圍有限,需要用合適的溢出控制規則(如定比例法)適當壓縮輸入信號的動態范圍,但這樣會降低輸出信號的信噪比。浮點表示法的優點是動態范圍大,可避免溢出,能在很大的動態范圍內達到很高的信噪比,主要缺點是系統實現復雜,硬件需求量大,成本和功耗高,而且速度較慢。
塊浮點表示法是定點法和浮點法的結合,兼有以上2種表示法的某些優點。這種制式,1組數具有1個共同的指數,這個指數是這組數中最大的那個數的指數。由于塊浮點法只用1個單一的指數表示1組數的指數,因而節約了存儲器,簡化了系統。其主要優點是:大動態范圍、低截斷(或舍入)噪聲。從芯片實現角度上看,塊浮點表示法能夠在保證較高的信號處理質量前提下,資源占用與定點算法相當。這種表示法對于要運算的數比較多、數值相近的情況特別適用,尤其適用于實現快速傅里葉變換算法。本脈壓模塊中的FFT核可選擇塊浮點表示法,考慮到塊浮點表示法的優點,我們選擇了該表示法。
從式(3)容易看出,脈壓后數據的塊指數PC_EXP為FFT運算后數據的塊指數FFT_EXP加上IFFT運算后數據的塊指數IFFT_EXP(如圖3所示)。由于脈壓后的處理都為定點運算,所以塊浮點表示法的脈壓后數據需轉換為定點表示法的脈壓后數據。

圖4 正負斜率LFM脈壓仿真
根據FFT的設置,塊浮點的脈壓后數據的尾數為24 bit,指數為6 bit,根據設計,脈壓后的定點數據的位寬為32 bit。定點化的目的是使最大的脈壓后定點數據的有效數據位寬為32 bit,由于脈壓系統為線性系統,脈壓前數據的幅度最大時,脈壓后數據的幅度也最大,為此設計了如下的定點化流程:在某一碼型下,模擬一幀幅度最大的脈壓前DBF數據,通過仿真,可得出此時脈壓后塊浮點數據的塊指數,該塊指數的值減去8記為該碼型的定點化指數。在實際工作時,根據脈壓后塊浮點數據的塊指數與該定點化指數的差值,對脈壓后塊浮點數據的24 bit的尾數進行相應的移位,如指數差值為正,脈壓后塊浮點數據的尾數左移相應的位數(移位數為指數差值的絕對值);如指數差值為負,右移相應的位數(移位數為指數差值的絕對值)。容易理解,當脈壓前的數據為最大時,脈壓后的塊浮點數據的24 bit的尾數需左移8位,此時得到的32 bit的定點數據的有效數據位寬為32 bit。不同碼型對應的定點化指數不一樣,需分別仿真確定。上電后,PowerPC將不同碼型對應的定點化指數加載到FPGA中,在對塊浮點數據定點化時,根據碼型信息查找對應的定點化指數。
4 脈沖壓縮模塊的測試
使用超高速集成電路硬件描述語言(VHDL)編寫FPGA程序,完成綜合與實現后,利用ModelSim仿真軟件對脈沖壓縮模塊進行布局布線后仿真,此時的仿真已基本接近真實情況。仿真信號同圖4中負斜率LFM信號,仿真波形如圖5所示,橫坐標為運行時間,縱坐標為幅度。從圖4和圖5可以看出波形一致,表明軟件設計正確,運行正常。
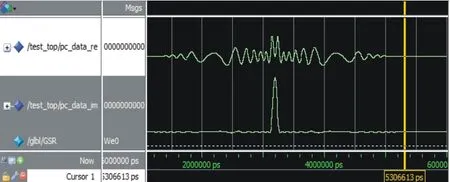
圖5 脈壓模塊的Modelsim仿真
5 結束語
脈壓實現有時域法或頻域法。頻域法里的FFT有多種不同的實現結構,沒有哪一種方法是最好的,工程應用時需根據具體的運算量來選擇實現方法,以達到較好的性價比。本文針對某型搜索雷達設計了一種頻域脈沖壓縮處理模塊,其中的FFT采用流水線型,該模塊在占用資源較少的情況下,能完成16個波束的脈沖壓縮處理,且其中的塊浮點算法減小了定點算法中的截斷誤差對脈壓輸出信噪比的影響。在FPGA軟件不變的情況下,通過PowerPC加載不同碼型的脈壓系數及其定點化指數,可實現不同碼型的脈沖壓縮處理,具有較好的靈活性。
[1] 吳太亮,劉崢.基于FPGA的時域脈沖壓縮器研究[J].制導與引信,2007,28(4):45-50.
[2] 賀知明,黃巍,向敬成.數字脈壓時域與頻域處理方法的對比研究[J].電子科技大學學報,2002,31(2):120-124.
[3] Xilinx Company.Data Sheet.Fast Fourier Transform V9.0[R].San Jose,USA:Xilinx Company,2015.
[4] 顧峰.基于DMA傳輸方式方式的SDRAM控制器的設計與實現[J].艦船電子對抗,2009,32(2):108-111.
[5] 馬翠梅,陳禾,章菲菲.脈沖壓縮定點處理的量化噪聲分析[J].北京理工大學學報,2013,33(9):965-969.
Realization of A Pulse Compression Processor in Frequency Domain Based on FPGA
GU Feng,DAI Jian
(The 723 Institute of CSIC,Yangzhou 225001,China)
Aiming at the characteristics of multiple beams and multiple code types,this paper designs a pulse compression processing module in frequency domain based on field programmable gate array (FPGA).The fast fourier transform (FFT) and inverse FFT (IFFT) in the compressor use streaming structure,and block float operation is adopted in FFT for reducing the influence of quantization error.The module uses digital beam forming (DBF) data and pulse compression coefficient before external double data rate (DDR) synchronous dynamic random access memory (SDRAM) buffer memory pulse compression.The relationship of corresponding pulse compression coefficients between positive frequency modulation (FM) signal and negative FM signal is also deduced,which can reduce a half of memory space for pulse compression coefficient.
field programmable gate array;pulse compression;fast Fourier transform;block float;frequency domain
2016-01-11
TN957.5
A
CN32-1413(2016)04-0105-05
10.16426/j.cnki.jcdzdk.2016.04.023
