基于信息融合的網頁文本聚類距離選擇方法
2016-11-25 05:38:12張少宏李繼巧羅嘉怡謝冬青
廣州大學學報(自然科學版) 2016年1期
張少宏,李繼巧,羅嘉怡,謝冬青,王 婧
(1.廣州大學計算機科學與教育軟件學院,廣東 廣州 510006;2.廣州圖書館,廣東 廣州 510623)
基于信息融合的網頁文本聚類距離選擇方法
張少宏1,李繼巧1,羅嘉怡1,謝冬青1,王 婧2
(1.廣州大學計算機科學與教育軟件學院,廣東 廣州 510006;2.廣州圖書館,廣東 廣州 510623)
在當前信息化的年代里,文本數據在高速的增長,人們獲取有用的信息猶如大海撈針.文本聚類作為文本挖掘的基礎技術,發揮了很重要的作用.由于缺乏預先定義的類和類標號的訓練實例,如何選擇合適的數據相似度是文本聚類的關鍵問題.文章為此提出一種新的衡量文本相似度的方法Adaptive Metric Selection(AMS).文章通過抓取網頁內容,為聚類提供數據來源,分詞和向量化是必要的轉化,利用特征提取的方法獲取特征項,并用Isomap進行降維,最后利用自適應選擇方法AMS對數據進行相似度衡量再進行聚類分析.實驗結果表明,AMS明顯優于從多種相似度獨立進行聚類的平均結果.
數據挖掘;特征提取;聚類融合
本文針對聚類知識提取和聚類評價的若干問題進行研究,討論如何在盡可能包含聚類先驗知識的情況下抽象出聚類知識,并從知識中尋找盡可能多的聚類結構信息,用一種自適應度量方法
在無監督學習中,由于缺乏已知類別的樣本數據,數據的相似度衡量方法歷來備受重視并得到深入的研究.在監督學習中,學習的目標是學習者從輸入到輸出的映射關系,其中輸出的正確值已經由指導者提供.然而,在無監督學習中,卻沒有這樣的指導者.另一方面,在無監督聚類應用中基于集成的技術已經吸引許多計算機領域的精英團體的高度興趣[1-18].
具體而言,無監督集成框架,通常被稱為聚類融合或一致聚類[1,4],能根據多個不同的獨立聚類結果生成一個一致的結果.獨立聚類結果能通過不同的透視方法,例如,通過不同的數據樣本子集[3-4],不同的數據特征子集[2-3]或不同的聚類算法[1,19]得到.一旦獨立分區創建,可以用于互協矩陣的方法[1,3,5]或者以圖分割方法[1-2]推導出一致聚類結果.在第一類聚類融合的方法,重組矩陣是根據各個獨立的分區,這些獨立分區的第(i,J)個矩陣標志項中,第i個數據點和第J個數據點是否屬于分區內的同一集合來生成的.然后,把所有的重組矩陣總結起來得出一個一致矩陣.這樣一來這個矩陣能充當一個成對的相似矩陣,一個一致的結果能用恰當的聚類算法或圖像分割算法被提取.特別地,每一個一致矩陣的項都是所有重組矩陣的相應的項的均值.這樣一個一致矩陣能被看對比其他相似度度量方法獨立進行聚類的平均結果,進而評價聚類的好壞.
1 數據預處理
1.1 網頁抓取
筆者使用網絡爬蟲技術抓取5種類型的網頁,分別是教育類(edu)、財經類(finance)、健康類(health)、體育類(sports)和軍事類(war),每個類別300篇文章,存到.txt文件中.因為計算機并不具備人腦的理解能力.在對文本進行預處理時,需要對文本內容進行分詞處理,去除停用詞,將其表示成計算機能夠理解和計算的模型.
1.2 分詞處理
與英文不同,在中文文本中,詞與詞之間沒有用空格來分隔,界限不明顯,導致計算機的處理存在較大難度.因此,需要將中文句子拆分為一個個單獨的詞.
筆者使用ICTCLAS分詞系統(又名NLPIR漢語分詞系統)對文本進行處理.其基本思想是:對句子進行原子切分,然后進行較為粗糙的N-最短路徑切分,找到前N個較為符合要求的切分結果,生成二元分詞表,最后得到分詞結果[20].
分詞前后的對照見圖1和圖2.
圖1 分詞前的例子Fig.1 Example before the split
1.3 去除停用詞
停用詞是指詞頻過高且沒有實質意義的詞,或詞頻很低且不能代表文本主題的詞[21].一般地,過濾停用詞可以構造停用詞表,通過跟讀入的文本分詞進行對比,若該詞在停用詞表出現就去除.而且,為了后續程序容易處理,詞與詞之間采用空行來分隔.
1.4 計算TF-IDF
傳統的數據均以結構化的形式而被處理,因此,在滿足復雜性能夠接受的情況下,需要合理的標示文本.
TF-IDF是在1988年由SALTON提出的實現單詞權重最為有效的方法.其中,TF稱為詞頻;IDF是逆文檔頻率,其大小與一個詞的常見程度成反比:如果一個詞越常見,則權重越小[22].將這2個值相乘,就得到了一個詞的TF-IDF值.
(1)計算詞頻(TF)

(2)計算逆文檔頻率(IDF)
逆文檔頻率(IDF)=

(3)計算TF-IDF
IF-IDF=詞頻(IF)×逆文檔頻率(IDF).
1.5 特征選擇方法
對特征集中的所有特征計算評分值,得到一個評估分值(又稱權值),對其從大到小排序,提取預定數目的最優特征作為提取結果的特征子集,稱為特征提取[23].在文本聚類中幾種常見的文本監督特征算法包括MI、IG、CHI和WLLR.
假設整個文檔集中有N篇文檔,其中M篇是教育類的,以下有4個觀察值可以使用,即類別和文檔數的4種組合(見表1).
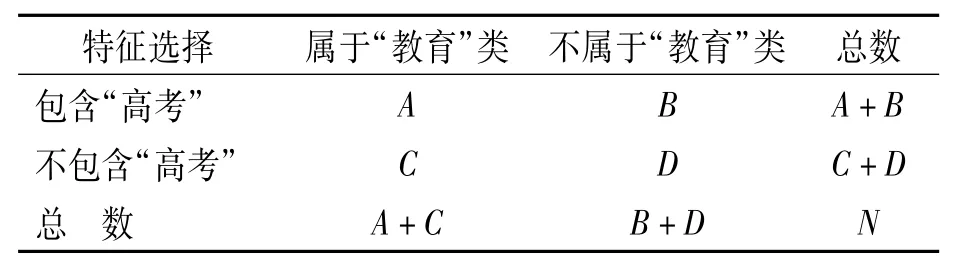
表1 類別和文檔的組合Table 1 The combination of categories and document
1.5.1 互信息法MI(Mutual Information)
互信息法用于衡量特征詞與文檔類別直接的信息量.它是根據特征詞條t與類別C之間的相關程度來度量特征詞條與類別的相關度的,在某個特定的類別中出現的頻率高,而在其他的類別中出現的頻率較低的詞條與該類別的互信息值較大[24].
計算公式:
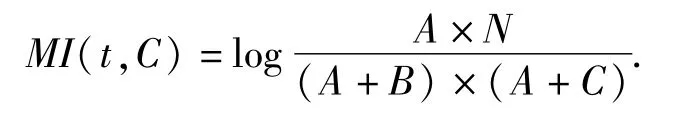
它不僅能夠反映2個變量之間的線性相關性,而且能夠反映變量之間的非線性相關性[24].
1.5.2 信息增益法IG(Information Gain)
在信息增益中,衡量標準是看特征能夠為分類系統帶來多少信息,帶來的信息越多,特征就越重要[25].假如有一個特征t,整個系統中某些文本有t和整個系統中沒有t時的信息量是不同的,而前后的相差部分就是特征t的信息量,即信息增益.
它表示的是包含所有特征時系統的信息量,也叫熵.計算公式:
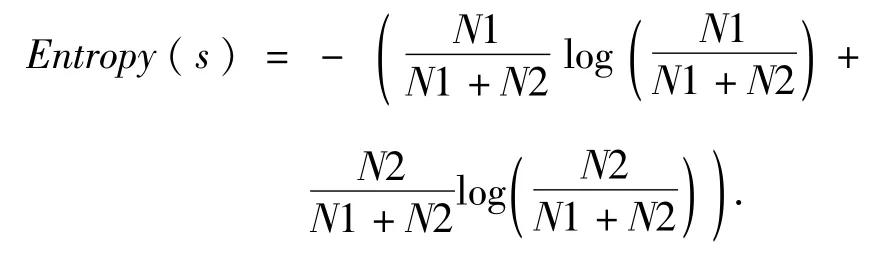
其中,N1表示正類文檔數,數值等于A+C,N2表示負類文檔數,數值等于B+D.N1+N2表示總文檔數N.
系統中不包含t的信息量,叫做條件熵.
歸納起來,每個詞的信息增益計算為
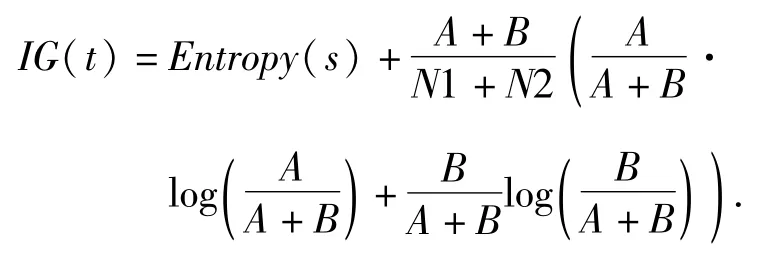
信息增益的缺點在于,它只考慮到特征對系統的貢獻,而沒有關注到具體的類別[26].雖然能夠獲得整個文檔集中的特征詞,但是不能區分不同類別間的特征詞的權重.
1.5.3 卡方檢驗CHI(Chi-square)
卡方檢驗的主要思想:根據實際值與理論值的偏差來確定理論是否正確[27].偏離程度決定卡方值的大小,卡方值越大,越不符合,偏差越小,卡方值就越小,越趨于符合,若量值完全相等時,卡方值就為0,表明理論值完全符合.計算公式:
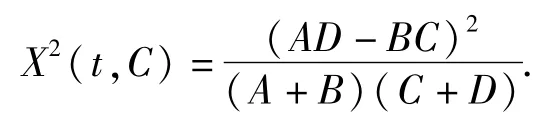
而不足在于“低頻詞缺陷”,即不管在文檔中出現的次數,而單純考慮是否出現.
1.5.4 加權對數概率比WLLR(Weighted Log Likelihood Ration)WLLR特征選擇方法的定義如下:
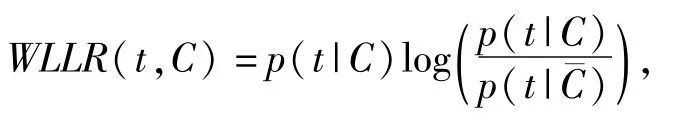
其中,p(t|C)表示文檔中出現特征詞t時屬于類C的概率,p(t|Cˉ)表示特征詞t不屬于C類的概率.
計算公式:
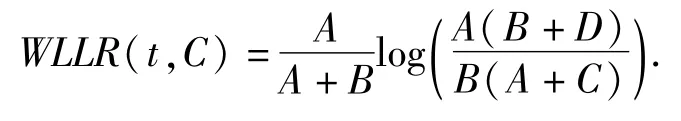
總之,這些特征選擇方法各有優缺.一般而言,CHI、IG的性能明顯優于MI;而CHI、IG 2者之間的性能大體相當,都能夠過濾掉80%以上的特征項.
2 基于一致近似性的聚類自適應評價指標選擇
2.1 傳統的聚類分析方法
聚類就是給出一堆原始數據,根據數據對象之間的相似度將數據分成相應的類或簇,類或簇是數據對象的集合.同一個類或簇中的對象應該具有很高的相似度,而不同簇中的對象則高度相異[28].
傳統的聚類方法主要分成5大類:劃分方法、層次方法、基于密度的方法、基于網格的方法和基于模型的方法[29].
劃分方法中,最著名和最常用的劃分方法是k均值(又叫k-means算法),k中心點和它們的變種[30].
層次聚類方法將數據對象組成一棵聚類樹,將這棵樹進行層次的分解.根據層次分解是以自底向上(合并)還是自頂向下(分裂)方式,層次聚類方法可以進一步分為凝聚的和分裂的.一般分為2種類型:凝聚層次聚類和分裂層次聚類[30].
基于密度的聚類方法以數據集在空間分布上的稠密程度為依據進行聚類,無需預先設定簇的數量,因此,特別適合于對未知內容的數據集進行聚類.密度聚類方法可以發現任意形狀的簇,克服了那些基于對象之間距離的聚類算法只能發現球狀簇的缺點,并且可以過濾孤立點數據或離群點這些“噪聲”[30].
2.2 文本相似度衡量
與分類不同的是,聚類是根據一定的相似性定義來劃分數據的,因此,需要考慮到聚類時所采用的相似性度量.
本文表示文本的形式是基于向量空間模型的,即一個向量代表一個文檔,特征詞的權重作為向量的元素.將文檔表示成向量空間模型的形式,有利于對文本進行相似度的衡量.
首先,本文的對象是一篇篇.txt文檔,也就是比較1 500*1 500個對象的相似度.相似度的衡量通常有2種度量方式:距離度量和相似度度量.
假設要比較數據點集x和y的差異,它們都包含了D個維的特征,即
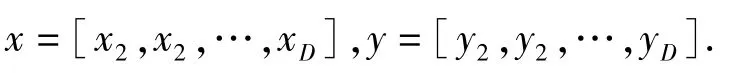
距離度量用于衡量個體在空間上存在的距離,越遠說明個體間的差異越大.常用方法是歐幾里得距離和曼哈頓距離.
(1)歐幾里得距離.它衡量的是多維空間中各個點之間的絕對距離[31],公式為
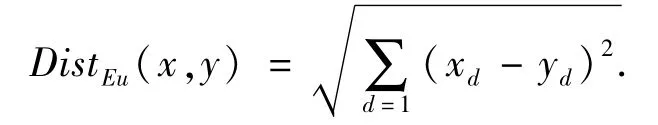
(2)曼哈頓距離.是將多個維度上的距離進行求和后的結果[31].
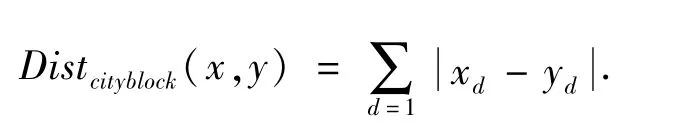
相似度度量,不同于距離度量,它的值越小代表個體間差異越大,越不相似[32].常用的是向量空間余弦相似度和相關距離.
(3)向量空間余弦相似度.它利用向量空間中2個向量夾角的余弦值作為衡量2個個體間的差異大小,相比于距離度量,它更加注重2個向量在方向上的差異,而不是在距離或長度上[33].
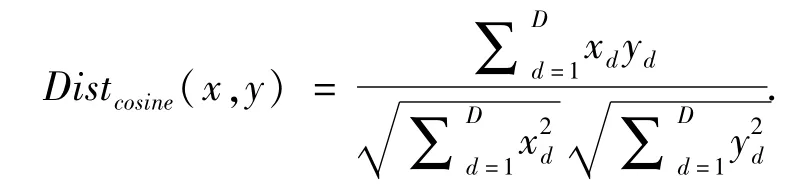
(4)相關距離.相關系數ρxy是衡量x與y相關程度的一種方法.相關系數的絕對值越大,表明x與y相關度越高.相關距離的定義則為

2.3 自適應選擇方法文本相似度衡量
筆者利用了一種新的相似度衡量方法,叫做Adaptive Metric Selection(AMS),來比較文本的相似度.它是基于劃分方法k均值算法的基礎上的,采用了一致密切關系來衡量聚類算法的自適應指標選擇問題.
k均值算法的基本步驟:給出n個數據對象,從中任意選取k個對象,每個對象都作為一個簇的初始聚類中心.對剩余的n-k個對象,分配到離它最近(最相似)的簇中.然后重新計算每個(有變化)簇的均值(中心對象),更新聚類中心.這個過程不斷重復,直到準則函數收斂或者到達某個終止條件[34].
以下給出k均值過程的概述:
算法:k均值
輸入:①k:簇的數目;②D:包含n個對象的數據集
輸出:k個簇的集合方法:①從D中任意選擇k個對象作為初始
簇中心;
②repeat根據簇中對象的均值,將每個對象(再)指派到最相似的簇;
更新簇均值,計算每個簇中對象的均值;
③until簇中心不再發生變化對于各種不同的數據集都使用統一的度量指標是不太合理的.因此在本文中使用一種稱為自適應指標的聚類融合方法AMS.
給出一個擁有N個數據點{x1,x2,…,xN}的數據集X,把數據集X分成K個互不相交的簇{A1,A2,…,Ak},一個N×N的Co-association Matrix(M),即互協矩陣,它的構造公式如下所示:
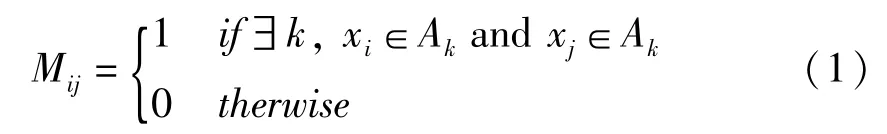
利用多個已經被計算出來的N×N的互協矩陣M,求出它們的均值,構造出相應的Consensus Matrix(M),即一致矩陣.
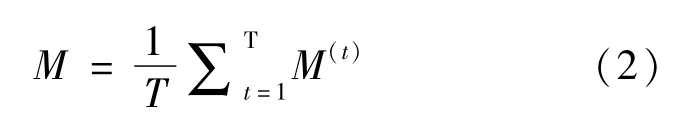
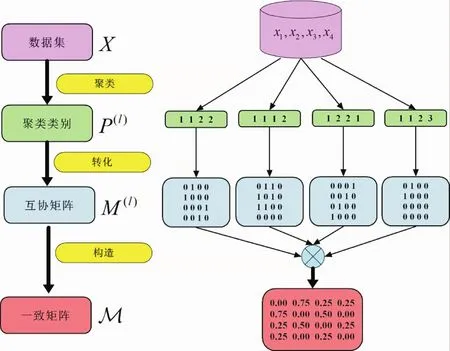
圖3 一致矩陣的構造流程圖Fig.3 The flow chart of the structure of the consistent matrix
利用降維后的數據,經過k均值算法得到5個簇,使得1 500篇文章都被分到5個類別中的任意一個.利用這些聚類類別,通過轉化把向量矢量轉變為矩陣的形式,得到互協矩陣Mv,最后求出互協矩陣的均值融合成一個一致矩陣這個Μ在整個實驗中起到一個參考矩陣的作用.
先算出4個待用參數a,b,c,d.
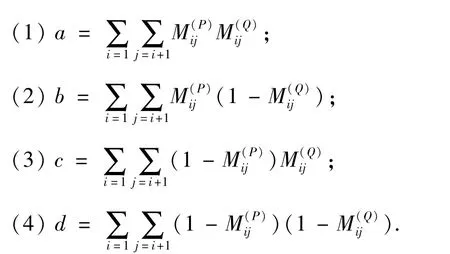
然后利用4個參數計算出SS.

自適應度量選擇AMS權值是由以下所有實驗各指標中的一致矩陣和互協矩陣Mv之間計算出一致性的.如下所示:

根據自適應度量選擇權值從高到低排序出一個指標列表.用公式(3)選出AMS的最好結果并保存下來.

式中表示A(t*)是SS函數中,會產生最大輸出的那個參數t.比如有一個函數f(t),t可能的取值范圍是{0,1,2},f(t=0)=29,f(t=1)=31,f(t=3)=2.那么y=argmax f(t)=1,也就是t等于1時,f(t)有最大的值.
3 AMS算法的實驗開展
3.1 AMS實驗前期準備工作
實驗環境在MyEclipse10,Matlab7.0環境下進行,實驗語料位抓取1 500篇網頁正文文本.
(1)數據集:5個特征方法分別經過Isomap降維算法降維后,分別得到1 500*20的矩陣.
(3)k均值的評價指標:4種相似度衡量方法,即①歐幾里得距離;②曼哈頓(或城市塊)距離;③向量空間余弦相似度;④相關距離.
(4)評估方法:在聚類中,常用作為聚類效果評估的2種指標:①調整后的芮氏指標Adjusted Rand Index(ARI);②標準化互信息Normalized Mutual Information(NMI).
3.2 實驗結果及分析
3.2.1 文本樣本數據在5種不同文本特征衡量方法下的相似度
對5種文本特征選擇方法畫出對應的1 500 *1 500的相似矩陣(見圖4),以觀察它們的聚類性能.第i行第J列的交叉點表示第i個網頁和第J個網頁的相似程度,而每個方格代表一個類別.比如第1行第4個方格表示第1類(教育類)和第4類(體育類)的相似度.

圖4 文本樣本數據在5種不同文本特征衡量方法下的相似度矩陣Fig.4 The similarity matrix of text sample data in 5 different text features
通常,相同的類別之間應該盡可能相似(灰度越深),而不同類別之間則越不相似越好(灰度越淡).反映在上面幾幅圖中就是,相同類別對應的是大矩陣中向下對角線的5個小矩陣;不同的類別對應的是非向下對角線的其它20個小矩陣.理想情況是,相同類別下的小矩陣越黑越好,表示類別間文本越相似.然而事實并沒有達到預期的結果.圖4中,WLLR中的第4類明顯和所有5個類的相似度很低(包括自身).這表明,單一的特征選擇方法還是存在較大的缺陷.
3.2.2 文本樣本數據在5種不同文本特征衡量方法下的相似度
筆者使用2個評價指標NMI和ARI比較自適應選擇度量方法AMS和單獨使用4種不同相似度衡量方法(歐幾里得距離、曼哈頓距離、向量空間余弦相似度和相關距離)進行聚類后的性能,如圖5所示.圖5中的2個子圖中,縱坐標分別表示對應的2種不同聚類性能衡量標準NMI和ARI.從圖5可見,使用AMS選擇自適應的文本相似度衡量后的聚類效果明顯優于單獨使用4種不同的相似度衡量方法.筆者也使用實驗驗證參數選擇對AMS算法的影響.AMS只依賴一個參數,即聚類個數T.驗證T在不同選擇情況下AMS的性能:T=40,80,120,160,200.在圖6中比較使用AMS選擇自適應的文本相似度衡量方法和單獨使用4種不同相似度衡量方法的平均結果的性能.圖6中的2個子圖中,橫坐標表示選擇不同的聚類個數T=40,80,120,160,200,縱坐標分別表示對應的2種不同聚類性能衡量標準NMI和ARI.從圖6可見,AMS選擇的自適應文本相似度衡量方法在不同T的情況下都優于比較對象.
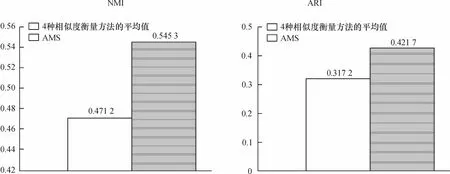
圖5 AMS和4種相似度衡量方法的平均值在文本相似度衡量方面的差異Fig.5 Performance comparison between AMS and the average of four individual similarity measures
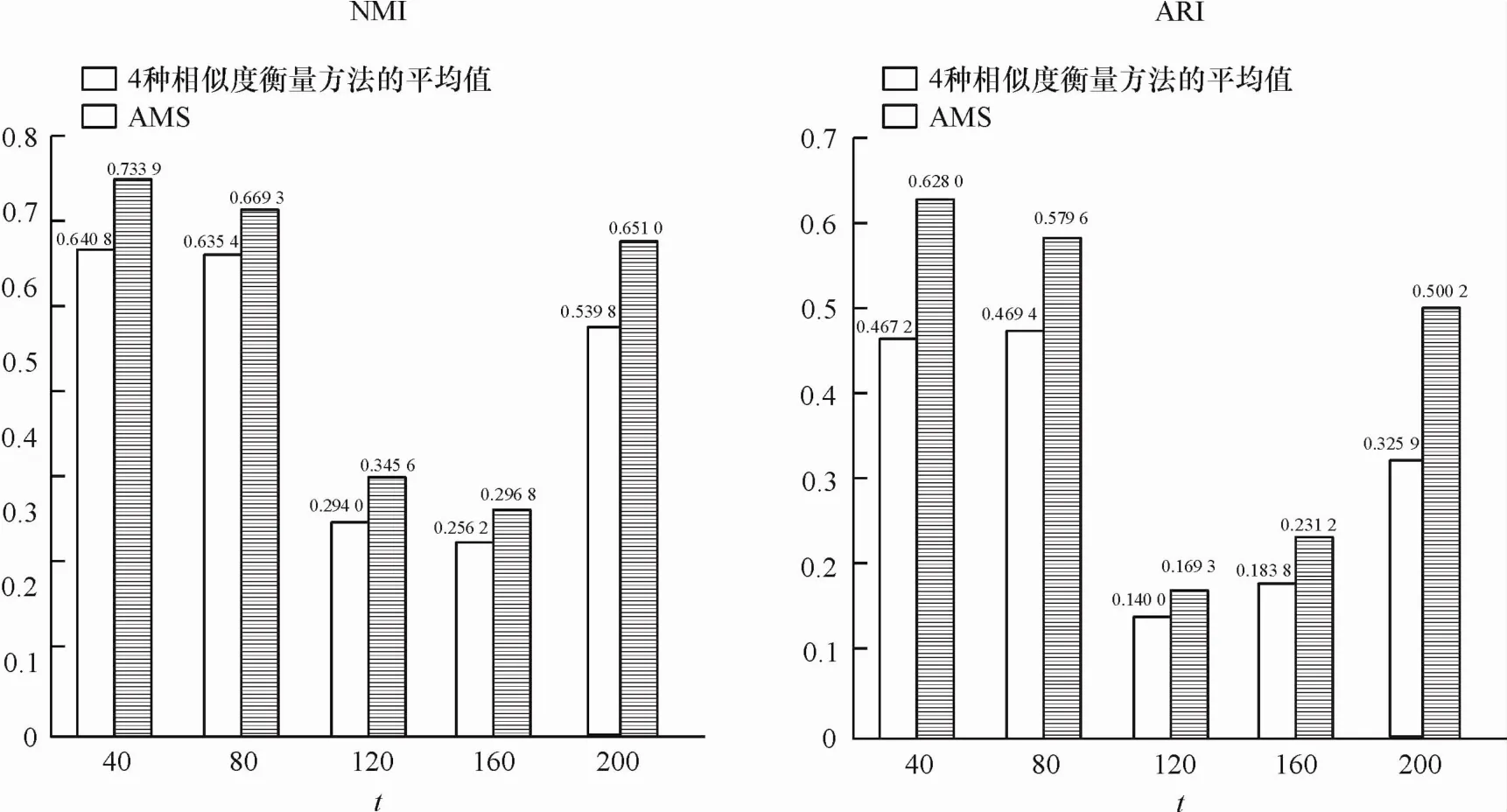
圖6 在不同聚類個數T下基于AMS選擇的相似度和單獨選擇相似度衡量方法的平均值的聚類性能比較Fig.6 Performance comparison between AMS and the average of four individual similarity measures with different numbers of clustering solutions t
結合圖5和圖6發現,不論是整體結果分析,還是細分T,自適應選擇度量方法AMS的聚類效果都超過了4種相似度衡量方法的平均值.這也從側面反映了使用不同的評估方法對判定結果的重要性.
筆者提出的方法是把多個聚類解決方案作為參考信息并且使用SS方法來進行評估以達成一致性.得益于從一個聚類融合的一致密切關系,自適應選擇方法AMS獲得顯著的改進,明顯高于4種相似度衡量方法的平均水平.而且,AMS只需要依賴一個參數——聚類融合解決方案數T.這也大大簡化實驗的工作量.另外,通過圖6可以觀察到,對于不同的聚類融合解決方案數T,本文提出的方法均明顯高于4種相似度衡量方法的平均水平,這說明本文的方法有較好的魯棒性,并不依賴于具體參數.
4 結 論
對網頁文本聚類問題,本文提出基于信息融合的自適應指標選擇方法Adaptive Metric Selection(AMS),并對比了4種距離/相似度方法和AMS在衡量文本相似度方面的差異.在衡量文本相似度中,自適應指標選擇AMS相對于4種距離/相似度度量有著比較好的聚類效果.
[1] STREHL A,GHOSH J.Cluster ensembles-a knowledge reuse framework for combining multiple partitions[J].J Mach Learn Res,2002,3:583-617.
[2] FERN X Z,BRODLEY C E.Solving cluster ensemble problems by bipartite graph partitioning[C]∥Proceed 21 Intern Conf Mach Learn,2004:69.
[3] FERN X,LIN W.Cluster ensemble selection[C]∥Proc SIAM Int Conf Data Min(SDM),2008:787-797.
[4] MONTI S,TAMAYO P,MESIROV J,et al.Consensus clustering:a resampling-based method for class discovery and visualization of gene expression microarray data[J].Mach Learn,2003,52(1):91-118.
[5] FRED A,JAIN A K.Combining multiple clusterings using evidence accumulation[J].IEEE Trans Pattern Anal Mach Intell,2005,27(6):835-850.
[6] KUNCHEVA L I,VETROV D.Evaluation of stability of k-means cluster ensembles with respect to random initialization[J].IEEE Trans Pattern Anal Mach Intell,2006,28(11):1798-1808.
[7] AYAD H,KAMEL M S.Cumulative voting consensus method for partitions with variable number of clusters[J].IEEE Trans Pattern Anal Mach Intell,2008,30(1):160-173.
[8] AZIMI J,FERN X.Adaptive cluster ensemble selection[C]//Proceed 21st Intern Jont Confer Artif Intell,2009:992-997.
[9] WU O,HU W,MAYBANK S J,et al.Efficient clustering aggregation based on data fragments[J].IEEE Trans Syst,Man,Cybern B,Cybern,2012,42(3):913-926.
[10]IAM-ON N,BOONGOEN T,GARRETT S.Lce:A link-based cluster ensemble method for improved gene expression data analysis[J].Bioin-Format,2010,26(12):1513-1519.
[11]IAM-ON N,BOONGOEN T,GARRETT S,et al.A link-based approach to the cluster ensemble problem[J].IEEE Trans Pattern Anal Mach Intell,2011,33(12):2396-2409.
[12]WANG T.Ca-tree:A hierarchical structure for efficient and scalable coassociation-based cluster ensembles[J].IEEE Trans Syst Man Cybern B Cybern,2011,41(3):686-698.
[13]ZHANG S,WONG H S.Arimp:A generalized adjusted rand index for cluster ensembles[C]∥Istanbul,Turkey 20th Internat Conf Pattern Recog(ICPR 2010),2010:778-781.
[14]ZHANG S,WONG H S,SHEN Y.Generalized adjusted rand indices for cluster ensembles[J].Pattern Recog,2012,45(6):2214-2226.
[15]ZHANG S,WONG H,SHEN Y,et al.A new unsupervised feature ranking method for gene expression data based on consensus affinity[J].IEEE/ACM Trans Comput Biol Bioinf,2012,9(4):1257-1263.
[16]ZHANG S,WONG H S,SHEN W J,et al.Aors:Affinity-based outlier ranking score[C]∥Neural Netw(IJCNN),2014 Intern Joint Conf IEEE,2014:1020-1027.
[17]TOPCHY A P,JAIN A K,PUNCH W F.Clustering ensembles:Models of consensus and weak partitions[J].IEEE Trans Pattern Anal Mach Intell,2005,27(12):1866-1881.
[18]YU Z,WONG H,WANG H.Graph-based consensus clustering for class discovery from gene expression data[J].Bioinformatics,2007,23(21):2888.
[19]GIONIS A,MANNILA H,TSAPARAS P.Clustering aggregation[J].ACM Trans Knowl Disc Data(TKDD),2007,1(1):4.
[20]劉群,張華平,俞鴻魁,等.基于層疊隱馬模型的漢語詞法分析[J].計算機研究與發展,2004(8):1421-1429.LIU Q,ZHANG H P,YU H K,et al.Based on layered hidden Markov model of Chinese lexical analysis[J].Comput Res Devel,2004(8):1421-1429.
[21]劉七.基于Web文本內容的信息過濾系統的研究與設計[D].南京:南京理工大學,2004.LIU Q.Research and design of information filtering system based on Web text content[D].Nanjing:Nanjing University of Science and Technology,2004.
[22]盧志翔,蒙麗莉.文本分類中特征項權重算法的改進[J].柳州師專學報,2011(4):128-131.LU Z X,MENG L L.The improvement of feature weight algorithm in text classification[J].J Liuzhou Teach Coll,2011(4):128-131.
[23]楊帆,孫強.從Web網頁上獲取一價事件常識的方法[J].科學技術與工程,2010(25):6300-6304.YANG F,SUN Q.A method for obtaining knowledge from the Web Webpage event[J].Sci Tech Eng,2010(25):6300-6304.
[24]鄧彩鳳.中文文本分類中互信息特征選擇方法研究[D].重慶:西南大學,2011.DENG C F.Research on feature selection method in Chinese Text Categorization[D].Chongqing:Southwestern University,2011.
[25]彭湘華.基于相關性的癌癥特征選擇及分類算法研究[D].長沙:湖南大學,2012.PENG X H.Research on correlation based feature selection and classification algorithm for cancer[D].Changsha:Hunan University,2012.
[26]田偉.XML文檔分類方法的研究及其應用[D].沈陽:大連理工大學,2009.TIAN W.Research and application of XML document classification method[D].Shenyang:Dalian University of Technology,2009.
[27]王垚堯.基于機器學習的經濟行業分類方法研究[D].哈爾濱:哈爾濱工業大學,2011.WANG Y Y.Research based on classification method of economic sectors based on machine learning[D].Harbin:Harbin Institute of Technology,2011.
[28]韓家煒.數據挖掘概念與技術[M].北京:機械工業出版社,2001.HAN J W.Concept and technology of data mining[M].Beijing:Machinery Industry Press,2001.
[29]毛國君.數據挖掘原理與算法[M].北京:清華大學出版社,2005.MAO G J.Principle and algorithm of data mining[M].Beijing:Tsinghua University Press,2005.
[30]TENENBAUM J B,DE SILVA V,LANGFORD J C.A global geometric framework for nonlinear dimensionality reduction[J].Science,2000,290(5500):2319-2323.
[31]馬永軍,方廷健.基于支持向量機和距離度量的紋理分類[J].中國圖像圖形學報,2002,7(11):1151-1155.MA Y J,FANG T J.Texture classification based on support vector machine and distance measurement[J].Chin J Imag Graph,2002,7(11):1151-1155.
[32]劉寶生,閆莉萍,周東華.幾種經典相似性度量的比較研究[J].計算機應用技術,2006(11):1-3.LIU B S,YAN L P,ZHOU D H.Comparison of several classical similarity measures[J].Comput Appl Tech,2006(11):1-3.
[33]MONTI S,TAMAYO P,MESIROV J,et al.Consensus clustering:A resampling-based method for class discovery and visualization of gene expression microarray data[J].Mach Learn,2003,52(1):91-118.
[34]FERN X,LIN W.Cluster ensemble selection[C]∥Proc SIAM Int Conf Data Min(SDM),2008:787-797.
M etric selection for web text clustering based on information ensembles
ZHANG Shao-hong1,LI Ji-qiao1,LUO Jia-yi1,XIE Dong-qing1,WANG Jing2
(1.School of Computer Science and Educational Software,Guangzhou University,Guangzhou 510006,China;2.Guangzhou Library,Guangzhou 510623,China)
In the current information age,text data grows at a high speed,and it is very hard for people to get useful information from huge data,which is like looking for a needle in a haystack.As the basic method in text mining,text clustering plays a very important role.Without predefined training set,it is one of the most important questions in text mining to select the suitable metric for different text data.Thus,in this thesis,we propose one novel Adaptive Metric Selection(AMS)method.The pipeline of our working includes:①crawling the webpage content to prepare the data source for clustering;②transforming the content to separate words and then to a vector form;③Extracting features;④Reducing dimension using Isomap;and⑤Using an adaptive selection method AMS to evaluate data similarity.K means is used as the basic clustering algorithm,and we use two popular clustering quality measures to evaluate the final results:①Adjusted Rand Index(ARI),and②Normalized Mutual Information(NMI).Simulation results show the effectiveness of our proposed methods compared to the averaged results of different metrics.
data mining;feature extraction;clustering ensembles
TP 181
A
1671-4229(2016)01-0080-10做是一個相似矩陣,并且,這樣一個最終的聚類結果能用任意能直接在距離矩陣或相似矩陣上運算的聚類算法獲得.基于包含Single Link(SL),Average Link(AL)or Complete Link(CL)的凝聚層次聚類算法的聚類融合方法就是有代表性熱門方法.第二類聚類融合方法生成一種基于樣本、集合、分區之間的關聯的代表性圖像,其中這種關聯是源于獨立聚類結果.在這一類方法中,典型的結果包括Cluster-based Similarity Partitioning Algorithm(CSPA)[19],Meta-CLustering Algorithm(MCLA)[19]和Hybrid Bipartite Graph Formulation algorithm(HBGF)[19].聚類融合方法生成更多較獨立聚類結果更穩定且精確的結果.一般需要處理2種相似度衡量:①樣本數據之間的相似度衡量方法,通常稱為相似度或者距離.樣本相似度或距離的選擇,會直接影響無監督學習算法的學習結果.②無監督學習得到的樣本類別和樣本類別參考值之間的相似度,通常成為聚類質量的衡量方法.聚類質量衡量方法的選擇,是正確衡量聚類結果的基礎.
【責任編輯:陳 鋼】
2015-12-21;
2015-12-30
張少宏(1969-),男,副教授,博士.E-mail:zimzsh@qq.com
猜你喜歡
甘肅教育(2020年8期)2020-06-11 06:10:02
制造技術與機床(2019年10期)2019-10-26 02:48:08
兒童故事畫報(2019年5期)2019-05-26 14:26:14
電子制作(2018年18期)2018-11-14 01:48:06
Coco薇(2016年2期)2016-03-22 02:42:52
小學教學參考(2015年20期)2016-01-15 08:44:38
人間(2015年20期)2016-01-04 12:47:10
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
