離線瞬態社會網絡中的多用戶位置鄰近預測
2016-11-25 03:42:42廖國瓊王汀利鄧琨萬常選
計算機研究與發展 2016年11期
關鍵詞:用戶
廖國瓊王汀利鄧 琨萬常選
1(江西財經大學信息管理學院 南昌 330013)2(江西省高校數據與知識工程重點實驗室(江西財經大學) 南昌 330013) (liaoguoqiong@163.com)
?
離線瞬態社會網絡中的多用戶位置鄰近預測
廖國瓊1,2王汀利1鄧 琨1,2萬常選1,2
1(江西財經大學信息管理學院 南昌 330013)2(江西省高校數據與知識工程重點實驗室(江西財經大學) 南昌 330013) (liaoguoqiong@163.com)
離線瞬態社會網絡(offline ephemeral social network, OffESN)是一種在特定時間通過參加特定事件臨時組建的新型社會網絡.隨著移動智能終端的普及和短距離通信技術(如藍牙、RFID技術等)的發展,該類型網絡得到工業界和學術界越來越多的關注.位置鄰近(location proximity)關系是指用戶在離線網絡中的相遇關系.針對位置鄰近關系的動態變化性及持續時間短等特征,主要研究離線瞬態社會網絡中多用戶鄰近關系預測問題.首先,給出離線瞬態社會網絡中的相關概念及問題定義;然后,設計多用戶鄰近關系預測總體框架,包括網絡片段收集、疊加網絡構建、網絡過濾及極大緊密子圖發現等步驟.由于多鄰近關系的數量及每個鄰近關系中用戶的數量不能事先確定,基于分裂思想提出了一種極大緊密子圖挖掘策略,以預測多用戶位置鄰近關系.該挖掘算法是以加權邊介數為網絡分裂依據,以聚集密度為分裂結束條件.在2個真實數據集上完成了實驗,驗證了所提出預測策略的可行性及效率.
社會網絡;瞬態社會網絡;位置鄰近;極大緊密子圖;鏈接預測
近年來,隨著Internet技術的快速發展,在線社會網絡(online social networks),如Facebook,Linkin,Twitter,QQ等已成為人們即時通信、分享消息及交友的方便快捷平臺[1].與此同時,隨著移動智能終端的普及和短距離通信技術(如藍牙、RFID等)的快速發展,離線瞬態社會網絡(offline ephe-meral social network, OffESN)開始得到越來越多的關注[2-6].
OffESN是人們在特定時間通過參加特定事件(如參加學術會議、博覽會等[4])臨時組建的社會網絡.不同于在線社會網絡中相對穩定的朋友關系(friendship),OffESN中的社會關系主要是通過藍牙、RFID等短距離通信技術收集到的位置鄰近(location proximity)關系[3],即用戶相遇關系.不同于基于位置社會網絡(location-based social network, LBSN),OffESN更多關注的是用戶是否相遇,而不關心用戶在何處相遇.OffESN中的位置鄰近關系主要具有4個特征:
1) 面對面接觸(face-to-face contact).不同于在線社會網絡,OffESN中的位置鄰近關系是通過離線的面對面接觸形成.
2) 事件驅動(event-driven).OffESN主要包含2類事件:預定事件(prescheduled events)和自發事件(spontaneous events)[6].位置鄰近關系是伴隨著這些事件的開始而產生、事件的結束而消失.
3) 動態性.OffESN中的位置鄰近關系是動態變化的,即用戶的相遇關系隨時間的變化而變化.
4) 持續時間短.OffESN中事件的持續時間通常較短.例如,在由參加學術會議形成的OffESN中,預定事件(如主題報告或分組討論)的持續時間一般為0.5~1 h, 而自發事件的持續時間通常在0.5 h之內.
在離線瞬態社會網絡中,一群人常常聚集在一起參加活動或交流.例如在參加學術會議時,幾個人可能結伴一起去聽學術報告,也可能聚集在一起討論感興趣的話題.因此,分析OffESN中多個用戶之間的鄰近關系,對進一步揭示該類型網絡的特征具有重要意義.同時,由于短距離通信技術的局限,如信號不穩定、信號遮擋及電量不足等原因,可能會導致一些位置鄰近關系未被探測到,預測多用戶鄰近關系可用于幫助發現缺失的位置鄰近關系.
鏈接預測(link prediction)是社會網絡分析的重要研究方向之一,最早由Liben-Nowell和Kleinberg提出[7],其任務是利用網絡中的已知信息預測未來可能發生的鏈接.鏈接預測在實際應用中具有重要意義,如推薦商品、發現缺失鏈接、識別錯誤鏈接等,得到了研究者的廣泛關注.目前在線社會網絡鏈接預測取得了較多研究成果,主要有基于相似性度量[7-9]、基于分類模型[10-11]、基于概率關系模型[12-14],基于時間序列模型[15-16]等方法.
針對OffESN的鏈接預測研究已開始得到學者們的關注.文獻[4]基于學術會議數據集的分析結果及社會關系理論對OffESN的特征進行了分析,并利用因子圖模型預測用戶兩兩之間的地理巧遇.文獻[5]通過分析OffESN鏈接預測的影響因素,基于位置鄰近概念提出了新鄰近關系和重復鄰近關系預測策略.然而,這些方法只能預測OffESN中用戶兩兩之間的位置鄰近關系.由于OffESN缺乏用戶偏好以及用戶對事件的評論信息,文獻[6]提出了一種潛在網絡融合模型(latent network fusion)進行用戶潛在偏好分析,通過預測用戶興趣進行事件推薦.該模型只能預測用戶與事件之間的鏈接.
與上述預測兩兩之間是否可能產生鏈接不同,多用戶鄰近關系預測是預測多個用戶在未來是否可能相遇,已有鏈接預測策略不能直接應用于多用戶鄰近關系預測.就筆者所知,目前尚無文獻對OffESN中的多用戶鄰近關系進行預測,其主要挑戰包括:
1) 如何衡量OffESN中多個用戶的緊密程度;
2) 在給定時刻,發生的多用戶鄰近關系數量及參與每個鄰近關系的用戶數量事先不確定;
3) 多用戶鄰近關系持續時間較短,且隨時間的變化而發生變化.
1 問題定義
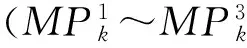
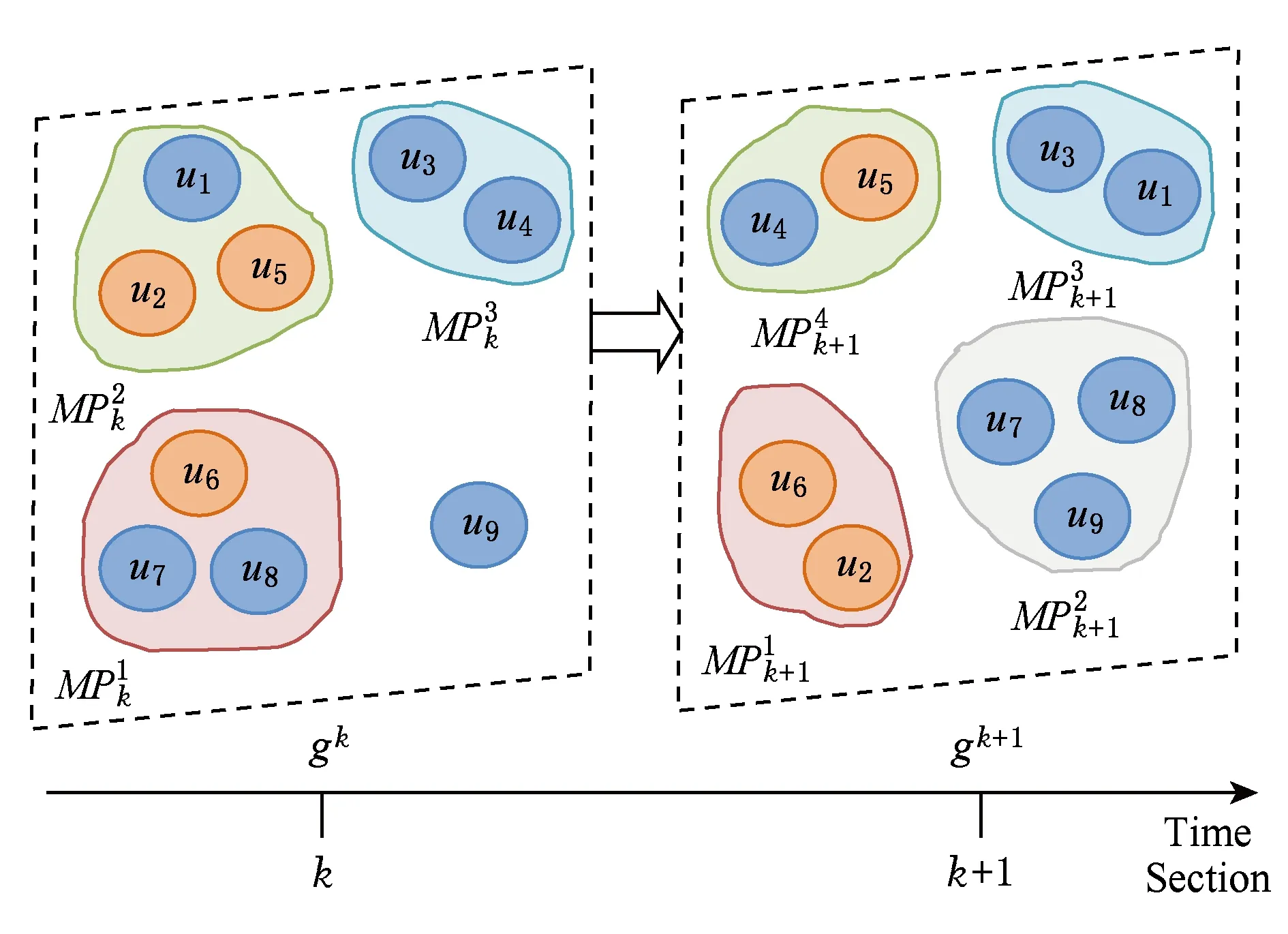
Fig. 1 An example of multi-user location proximity.圖1 多用戶位置鄰近關系示例
定義1. 多用戶位置鄰近.在任意時間段,如果探測到N(N≥2)個用戶兩兩相遇(相互鄰近時間超過指定時間閾值),則稱這N個用戶在該時間段發生多用戶位置鄰近.
我們將OffESN按時間段建模成不同的網絡片段(network fragment).
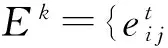
假設(時間依賴性): 若2個用戶在時刻t相遇,則他們在時刻t+1很可能再次相遇.
ACM SIGCOMM國際學術會議于2009-08-17—2009-08-21在西班牙巴塞羅那召開.會議組織方通過藍牙設備收集了76位參會代表會議召開期間的位置鄰近數據[17].我們探測到的所有兩兩位置鄰近關系按天劃分為0~4共5個時間段.
圖2為第1~4個時間段中的鄰近關系對前一個時間段的時間依賴性.其中,Independent表示在上一個時間段未發生位置鄰近的用戶在下一個時間段發生位置鄰近的比例,Dependent表示上一個時間段發生位置鄰近的用戶在下一個時間段仍然鄰近的比例.
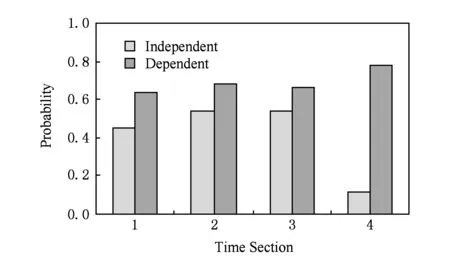
Fig. 2 Time dependency of location proximity.圖2 位置鄰近關系的時間依賴性
從圖2可以看出,在不同的時間段,Dependent值都高于Independent,驗證了如果用戶在上一個時間段發生位置鄰近則他們在當前時間段發生位置鄰近的可能性較高,即位置鄰近行為具有時間依賴性.于是,利用用戶的歷史鄰近信息,將多個連續網絡片段進行疊加,形成1個保存歷史鄰近關系的完整網絡.
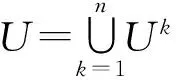
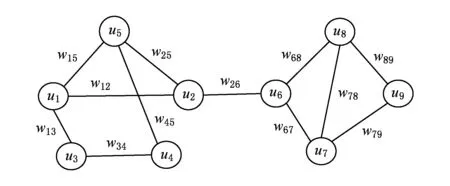
Fig. 3 An example of overlay network.圖3 疊加網絡示例
(1)
為滿足位置鄰近關系的時間依賴特征,式(1)引入了衰減思想,以保證距離當前時間較近的鄰近關系對疊加網絡的權重影響較大.
圖3為圖1的疊加網絡實例.由于疊加網絡為無向圖,故wi j=wj i.
密度(density)是用來衡量社會網絡中不同結點之間聚集程度的重要指標之一.我們利用該指標度量疊加網絡中子圖的聚集程度.
定義4. 聚集密度.若S為疊加網絡G中的任意一子圖,|US|和|ES|分別為S擁有的結點數和鏈接數,dens(S)為S的聚集密度,則有:
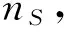
(2)
其中,nS=(|US|×(|US|-1))/2,表示S中的最大鏈接數.
根據聚集密度,可提取疊加網絡中聚集程度較為緊密的最大子圖,稱之為極大緊密子圖(maximal close subgraph).
定義5. 極大緊密子圖.設ε為給定聚集密度閾值,S為G中的任意子圖且|US|≥2,若稱S為極大緊密子圖,當且僅當2個條件同時滿足:
1)den(S)≥ε;
2) 對于任意v∈U且v?S,e={ev u|u∈S},den(S∪(v,e))<ε成立,即在S中加入新結點v及其相連的邊e后,所形成子圖的聚集密度小于ε.
因此,極大緊密子圖中包含了聚集關系較為密切的結點.
根據觀察,在學術會議離線網絡中,多個用戶發生位置鄰近的可能性主要有:1)共同去參加感興趣的學術報告或分組討論;2)新舊朋友聚在一起聊天交流、喝咖啡或用餐.因此,相對于研究興趣不相同的會議代表,研究興趣相同的代表發生位置鄰近的頻率較高且時間較長.同樣,相對于非朋友關系的代表,具有朋友關系的代表發生位置鄰近的頻率較高且時間較長.因此,總體上,具有相同研究興趣的代表和具有朋友關系的代表更易于在疊加網絡中形成極大緊密子圖.因此,我們可推測:存在于一個極大緊密子圖的會議代表在未來發生位置鄰近的可能性較大,即可將離線瞬態社會網絡中的多用戶鄰近預測問題轉化為從疊加網絡中挖掘極大緊密子圖問題.
本研究的預測策略為:在當前疊加網絡中,屬于一個極大緊密子圖中的用戶將在下一個時間段可能發生位置鄰近.
定義6. 多用戶鄰近預測.G是由n個連續網絡片段{g1,g2,…,gn}形成的疊加網絡.若S為G中的極大緊密子圖,則預測S中的用戶在第n+1個網絡片段gn+1中將發生位置鄰近.
2 預測總體框架
根據上述定義,首先給出多用戶鄰近預測的總體框架,如圖4所示:
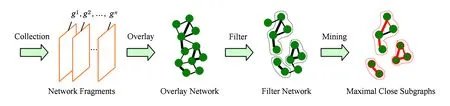
Fig. 4 The overall framework of multi-user proximity prediction.圖4 多用戶鄰近關系預測總體框架
從圖4可以看出,多用戶位置鄰近關系預測包括4個步驟:
步驟1. 收集網絡片段.首先,將短距離通信設備探測到的相遇關系按給定時間段進行劃分;然后,對每個劃分進行統計,生成網絡片段g1,g2,…,gn,其中每個片段包括用戶集、鄰近邊集及權重集.
步驟2. 網絡疊加.將g1,g2,…,gn中的用戶集和鄰近關系集進行疊加,并按照式(1)計算每條邊的疊加權重,從而得到疊加網絡G.
步驟3. 網絡過濾.由于疊加網絡中存在噪聲鄰近邊,因此根據邊權重閾值過濾G中的噪聲關系.
步驟4. 極大緊密子圖發現.對過濾后得到的每個獨立網絡子圖,計算其聚集密度,判斷其是否為極大緊密子圖.若是,則預測該子圖中的用戶在下一個時間片段發生位置鄰近;若不是,則對子圖進行分裂,直到剩余結點為孤立結點.
3 構建疊加網絡
疊加網絡是進行預測的基礎,在挖掘最大緊密子圖之前,需要構建疊加網絡.
OffESN中的位置鄰近信息隨著時間的增長不斷增加.在預測開始時,我們選取前n個網絡片段進行疊加網絡初始化.初始化過程如算法1所示:
算法1. 疊加網絡初始化.
輸入:{g1,g2,…,gn};
輸出:疊加網絡G=(U,E,W).
①k=1;
②U=?,E=?;
③ for eachuiinUk(k=1,2,…,n)
④U=ui∪U; /*合并結點集*/
⑤ end for
⑥ for eachei jinEk(k=1,2,…,n)
⑦E=ei j∪E; /*合并邊集*/
⑧ end for
⑨ for eachei j∈Edo
⑩ setwi j=0; /*初始化邊的權重*/

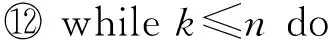

衰減公式計算*/


初始化之后,每次只需將新時間片段產生的邊及結點添加到疊加網絡中,同時更新邊的權重,以獲得最新疊加網絡.
4 極大緊密子圖發現
本研究擬通過發現極大緊密子圖來判斷網絡中多用戶是否位置鄰近.但是,由于事先無法知道不同時刻疊加網絡中極大緊密子圖數量及每個子圖中的用戶數量,因此擬采用基于分裂的思想發現極大緊密子圖.
GN算法[18]是一種分裂型的社區發現算法.該算法根據網絡中社區內部高內聚、社區之間低內聚的特點,逐步去除社區之間的邊,以得到相對內聚的社區結構.該算法按邊介數大小隨機刪除邊進行網絡結構分裂,無需在執行算法之前指定子圖目標個數及規模.但是,利用GN算法不能直接用于極大緊密子圖提取,其原因主要有:
1) GN算法是為靜態無權圖設計,它是將邊介數作為網絡分裂的依據,而未考慮邊的權重、圖的結構和權重的動態變化;
2) 該算法是為社區發現而設計,網絡分裂終止條件為社區模塊度Q,未考慮離線瞬態社會網絡中疊加網絡特征.
針對以上問題及OffESN特征,我們在進行網絡分裂時做了3點擴充:
1) 為支持OffESN的動態特征,實時更新疊加網絡中的結點、邊及權重;
2) 利用加權邊介數代替邊介數作為網絡分裂的依據,即每次選取加權邊介數最大的邊刪除;
3) 利用聚集密度作為網絡分裂的終止條件,即當分裂子圖的聚集密度大于閾值時停止分裂.
4.1 加權邊介數
邊介數(edge betweenness,EB)是用來衡量邊在網絡中重要性程度的度量指標,它表示網絡中所有最短路徑中經過一條邊的路徑數目占最短路徑總數的比例.邊介數值較高的邊,它們最有可能占據連接不同子網絡的“橋”位置[18].例如,圖3中邊e26具有較高的邊介數,因為它連接了分別由用戶1~5和用戶6~9組成的2個子網絡.
定義7. 邊介數.邊介數為網絡中所有最短路徑中經過一條邊的路徑數量占全部最短路徑數量的比例.設EB(ei j)為邊ei j的邊介數,其計算為
(3)
其中,σ(s,t)為從結點s到結點t的最短路徑數量,σ(s,t|ei j)為從結點s到結點t經過邊ei j的最短路徑數.
由于疊加網絡中的鄰近關系具有權重,故其為無向有權圖.為保證重要的邊(具有較高權重的邊)不被輕易刪除,于是提出加權邊介數(weighted edge betweenness,WEB)概念.
定義8. 加權邊介數.加權邊介數為一條邊的邊介數與該邊權重的比值.設WEB(ei j)為ei j的加權邊介數,其計算為

(4)
4.2 極大緊密子圖發現算法
由于短距離通信技術的不穩定性,可能存在噪聲數據,故在進行挖掘極大緊密子圖之前,需先去除疊加網絡中權重小于指定閾值的邊,然后再進行分裂.算法2是極大緊密子圖發現算法描述.
算法2. 極大緊密子圖發現算法.
輸入:疊加網絡G=(U,E,W)、邊權重閾值θ.
① for eachei jinEdo /*網絡過濾*/
② ifwi j<θ
③delete(ei j,G); /*刪除權重小于權重閾值θ的邊*/
④ end if
⑤ end for
⑥split(G). /*網絡分裂*/
網絡分裂函數split(G)是極大緊密子圖發現算法的核心.當網絡聚集密度小于閾值ε時,則去除加權邊介數最大的邊,將網絡分裂為2個子網絡.當網絡只有1個結點或其聚集密度大于閾值ε時,則停止分裂.算法3為網絡分裂算法.
算法3. 網絡分裂算法split(G).
輸入:待分裂的網絡G=(U,E,W);
輸出:極大緊密子圖集合.
① if |U|=1
②remove(G);
③ end if
④dens(G)=|EG|/nG; /*計算G的聚集密度*/
⑤ ifdens(G)>ε
⑥ returnG;
⑦ else
⑧ for eachei jinEdo
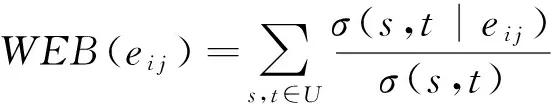
⑩ end for
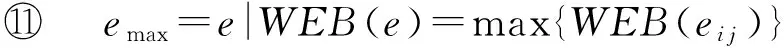

極大緊密子圖發現算法的核心是計算邊的加權邊介數.設圖中結點數為n,邊數為m,則計算單條邊加權邊介數的時間復雜度為O(mn).因此,在最差情況下,對于具有m條邊的圖而言,極大緊密子圖發現算法的時間復雜度為O(m2n).
5 實驗及結果分析
5.1 實驗準備
本實驗采用的2個數據集sigcomm 2009[17]和mobility 2011[19]均來自CRAWDAD網站.我們分別從這2個數據集中提取12 153和1 339條鄰近關系記錄.2個數據集均以天為時間段進行網絡片段劃分,并以位置鄰近的頻率數作為邊權重.
本實驗所選擇的性能評價指標為預測準確率(precision rate,PR)和召回率(recall rate,RR).設X為預測的多用戶鄰近關系數,Y為在第n+1個網絡片段中實際多用戶鄰近關系數,Z為X中實際包含的多用戶鄰近關系數,則有:PR=ZX;RR=ZY.
本文所提出的多用戶鄰近關系預測策略(記為MPP)是基于分裂思想進行極大緊密子圖提取.由于尚未見離線瞬態社會網絡多用戶鄰近預測算法,故擬選擇采用相似的分裂思想進行社區發現的GN算法及Radicchi算法[20]進行比較.與GN算法不同的是,Radicchi算法引入了邊聚集系數進行網絡分裂,減低了算法的時間復雜度,但當網絡中三角環數量較少時準確率會下降.對于社區發現算法,我們預測位于相同社區中的多個用戶在下一個時刻可能相遇.
本實驗的硬件環境為處理器Intel?Xeon?CPU E5645@2.40 GHz、內存4 GB,操作系統為Windows 7.
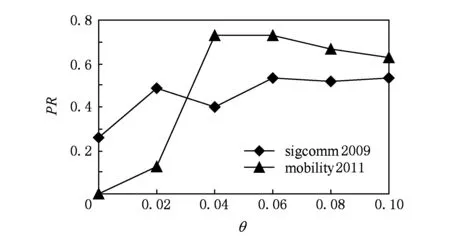
Fig. 5 Influence of the weight threshold on precision rates.圖5 權重閾值對準確率的影響
5.2 實驗結果及分析
實驗1. 邊權重閾值對準確率和召回率的影響.
圖5顯示了不同邊權重閾值θ下(固定ε=0.6)多用戶鄰近關系預測結果.可以看出,當邊權重閾值較小時,2個數據集精確度都不高.從sigcomm 2009數據集的結果可以看出,當θ從0.04增加到0.10時,準確率略微上升后基本保持不變;當θ從0.06增加到0.10時,mobility 2011數據集的精確度整體變化不大.圖6為召回率變化情況,總體趨勢與圖5相同.
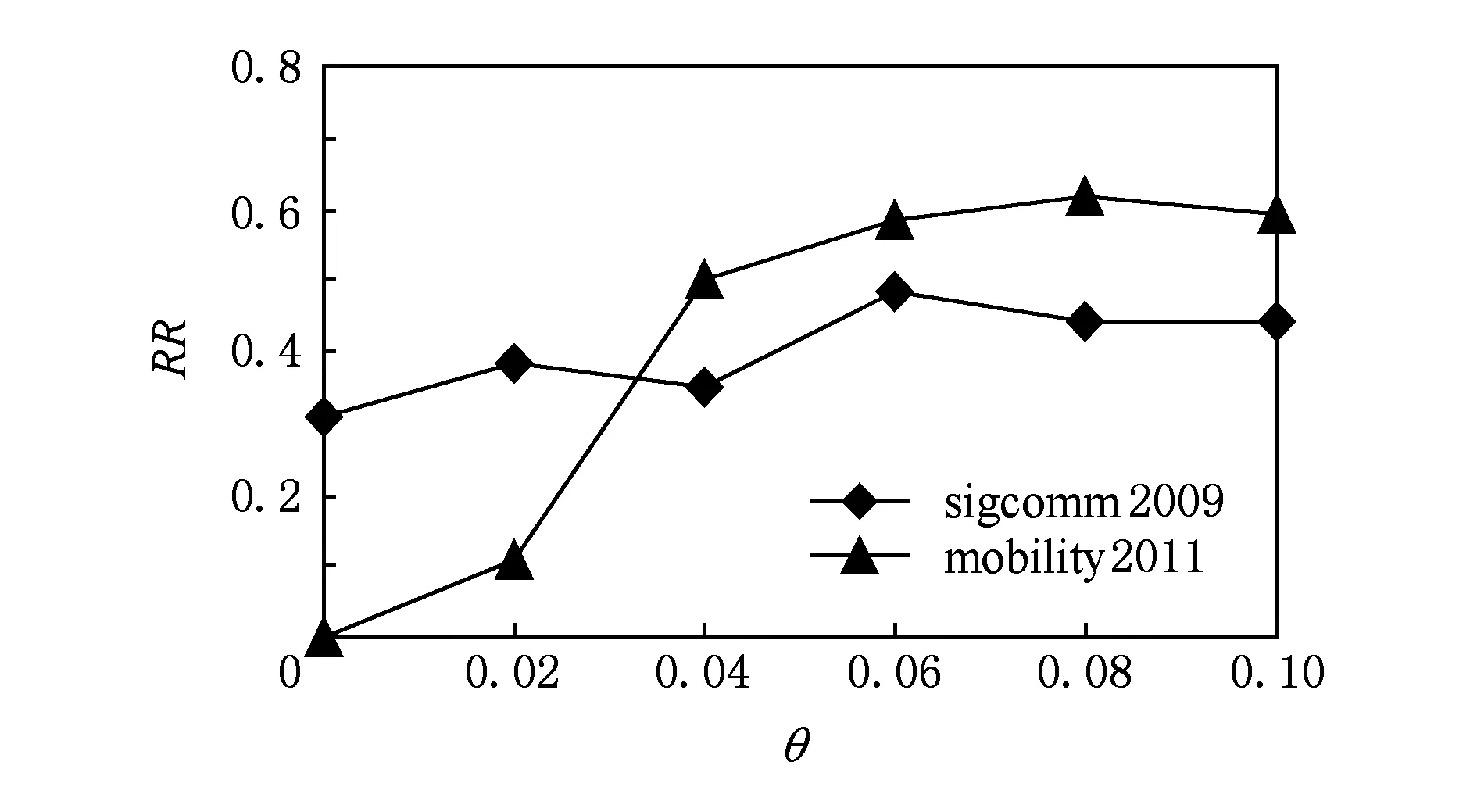
Fig. 6 Influence of the weight threshold on recall rates.圖6 權重閾值對召回率的影響
實驗2. 聚集密度閾值對準確率和召回率的影響.
圖7和圖8展示了在不同聚集密度閾值ε下(固定θ=0.06)預測準確率和召回率的變化情況.
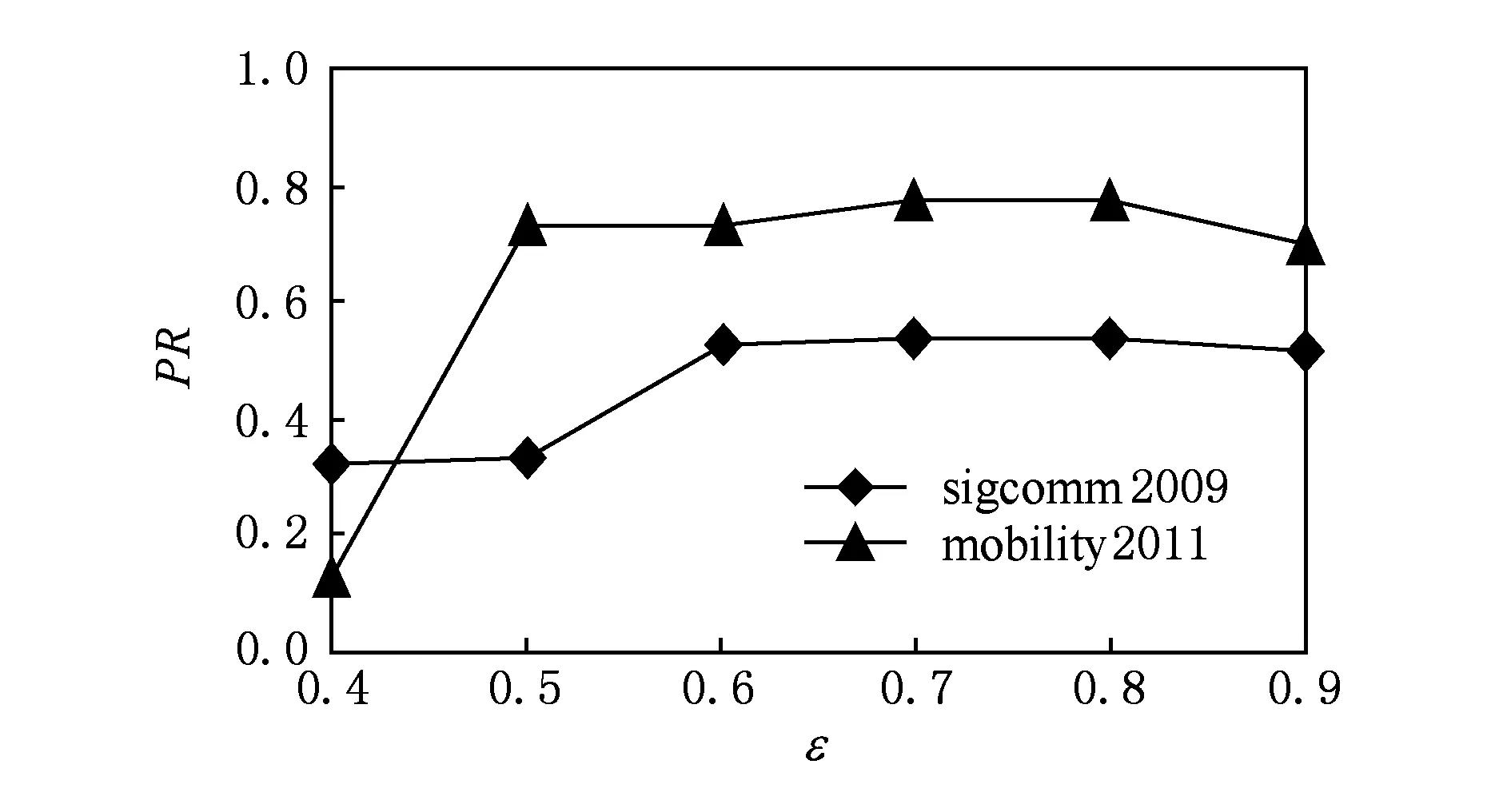
Fig. 7 Influence of the density threshold on precision rates.圖7 聚集密度閾值對準確率的影響
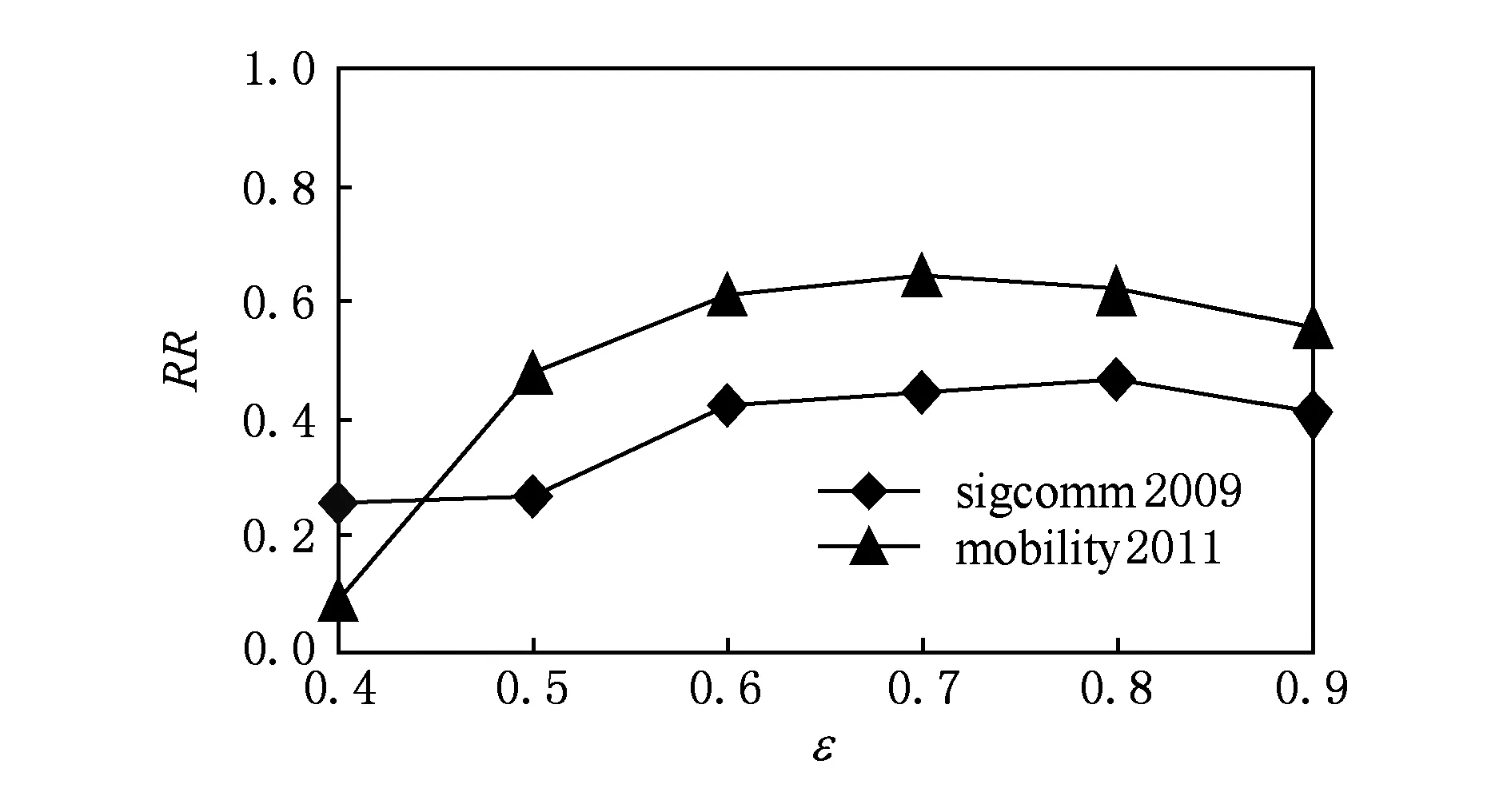
Fig. 8 Influence of the density threshold on recall rates.圖8 聚集密度閾值對召回率的影響
從圖7和圖8可以看出,當ε從0.4變化到0.6時,2個數據集的準確率和召回率都呈上升趨勢;而當ε達到 0.6時,2個指標的變化不大.這是由于當ε較大時,極大緊密子圖規模相對較小,指標值變化相對固定.
實驗3. 加權邊介數對準確率和召回率的影響.
圖9和圖10展示了固定θ=0.06,ε=0.6時,分別利用加權邊介數(WEB)和普通邊介數(EB)作為分裂依據時的準確率和召回率比較.可以看出,采用加權邊介數的準確率和召回率均高于采用普通邊介數的準確率和召回率,其原因是加權邊介數考慮了邊的權重,避免了鄰近關系較為緊密的邊被刪除.
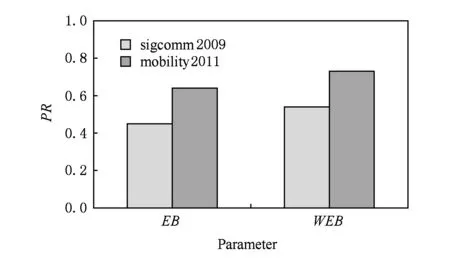
Fig. 9 Influence of edge betweennesses on precision >rates.圖9 邊介數對準確率的影響

Fig. 10 Influence of edge betweennesses on recall rates.圖10 邊介數對召回率的影響
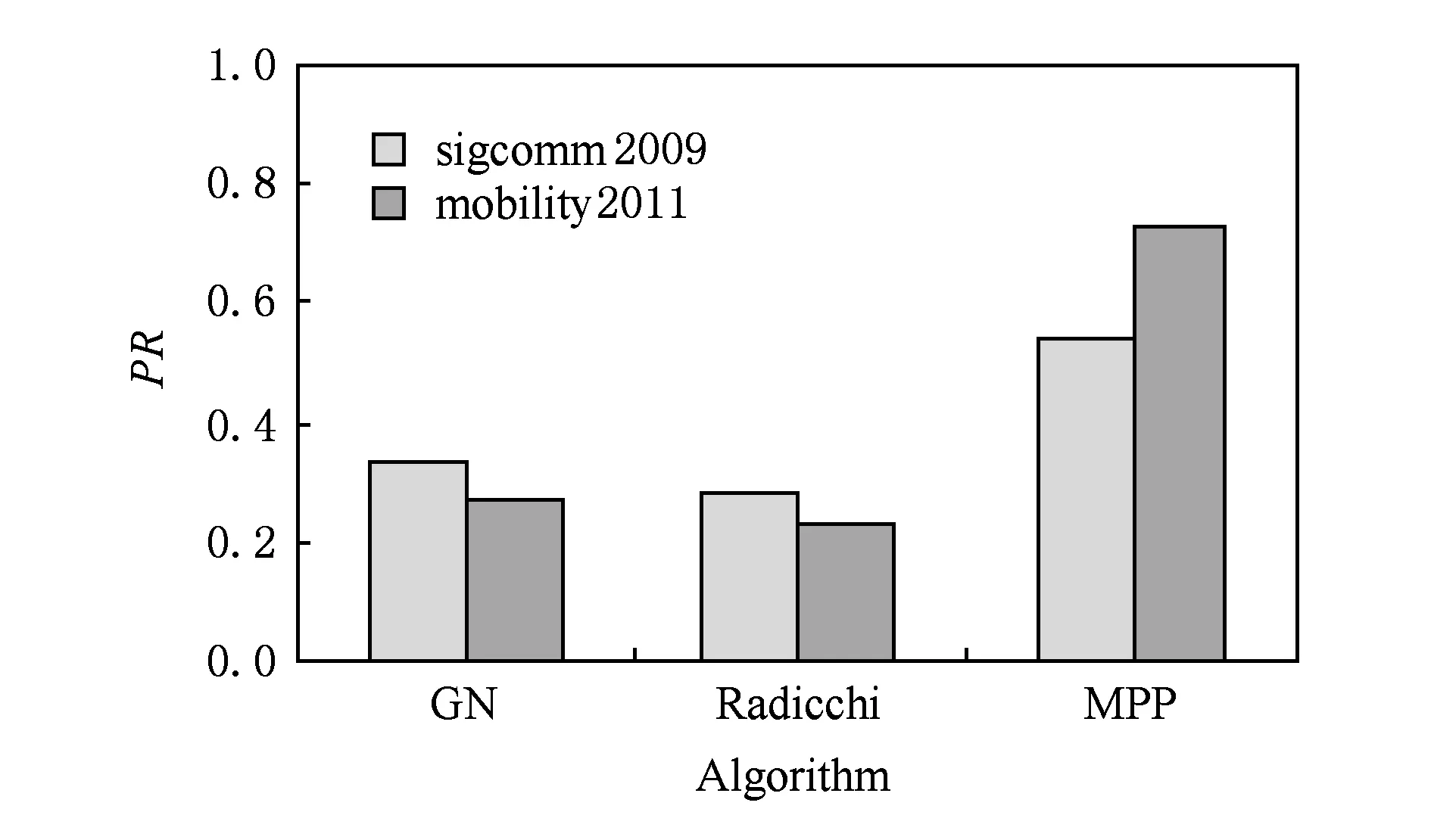
Fig. 11 Precision rate comparison of different algorithms.圖11 不同算法準確率比較
實驗4. 比較不同算法對準確率和召回率的影響.
圖11和圖12分別是3種算法預測的準確率和召回率的比較結果,其中固定θ=0.06,ε=0.6.
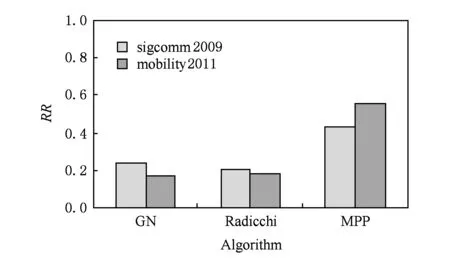
Fig. 12 Recall rate comparison of different algorithms.圖12 不同算法召回率比較
可以看出,MPP算法的準確率和召回率都高于GN算法和Radicchi算法.在學術會議的離線網絡中,每次同時發生位置鄰近的用戶數通常不多(常常幾個人碰面在一起交流和討論);而社區發現算法發現的社區規模往往較大,不易發現規模比較小的多用戶位置鄰近,故它們的準確率和召回率都比MPP算法低.
實驗5. 分析不同算法的挖掘時間開銷.
圖13是3種算法的挖掘時間開銷比較結果.可以看出,MPP算法所需時間開銷小于GN算法,其原因是GN算法計算分裂終止判斷條件——模塊度的時間開銷高于MPP算法計算聚集密度的開銷.但是,由于Radicchi算法只需計算局部邊聚集系數作為分裂條件,故其所需時間最少.
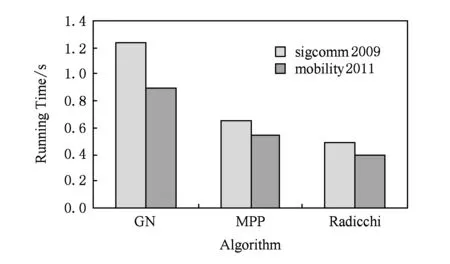
Fig. 13 Time overhead comparison of different algorithms.圖13 不同算法的時間開銷比較
6 結 論
本文針對離線瞬態社會網絡中的多用戶鄰近關系預測問題展開研究,主要創新之處在于考慮了離線瞬態社會網絡特征,提出了極大緊密子圖概念及其挖掘策略,能有效地解決多鄰近關系數及規模不確定問題.全文主要工作總結如下:
1) 設計了離線瞬態社會網絡中多用戶鄰近關系預測的總體框架;
2) 考慮到用戶鄰近關系的強度不同,提出了采用加權邊介數作為網絡分裂依據,以避免重要邊不被刪除;
3) 提出了基于分裂思想的極大緊密子圖提取算法;
4) 在真實數據集上進行了性能測試,測試結果驗證了所提出算法的可行性.
在后續的研究中,我們將進一步研究離線瞬態社會網絡的特征,以期發現更多特征指標及更有效的算法幫助提高預測的準確率.
[1]Kong Xiangnan, Zhang Jiawei, Yu P S. Inferring anchor links across multiple heterogeneous social networks[C] //Proc of the 22nd ACM Int Conf on Information & Knowledge Management (CIKM 2013). New York: ACM, 2013: 179-188
[2]Chin A, Wang Hao, Xu Bin, et al. Connecting people in the workplace through ephemeral social networks[C] //Proc of the 3rd IEEE Int Conf on Privacy, Security, Risk and Trust and Social Computing. Piscataway, NJ: IEEE, 2011: 527-530
[3]Chin A, Zhang Daqing. Ephemeral social networks[M] //Mobile Social Networking. Berlin: Springer, 2014: 25-64
[4]Zhuang Honglei, Chin A, Wu Sen, et al. Inferring geographic coincidence in ephemeral social networks[M] //Machine Learning and Knowledge Discovery in Databases. Berlin: Springer, 2012: 613-628
[5]Scholz C, Atzmueller M, Stumme G. On the predictability of human contacts: Influence factors and the strength of stronger ties[C] //Proc of the 4th IEEE Int Conf on Privacy, Security, Risk and Trust and Social Computing. Piscataway, NJ: IEEE, 2012: 312-321
[6]Liao Guoqiong, Zhao Yuchen, Xie Sihong, et al. An effective latent networks fusion based model for event recommendation in offline ephemeral social networks[C] //Proc of the 22nd ACM Int Conf on Information & Knowledge Management(CIKM 2013). New York: ACM, 2013: 1655-1660
[7]Liben-Nowell D, Kleinberg J. The link-prediction problem for social networks[J]. Journal of the American Society for Information Science and Technology, 2007, 58(7): 1019-1031
[8]Lichtenwalter R N, Lussier J T, Chawla N V. New perspectives and methods in link prediction[C] //Proc of the 16th ACM SIGKDD Int Conf on Knowledge Discovery and Data Mining (KDD 2010). New York: ACM, 2010: 243-252
[9]Bliss C A, Frank M R, Danforth C M, et al. An evolutionary algorithm approach to link prediction in dynamic social networks[J]. Journal of Computational Science, 2014, 5(5): 750-764
[10]Hasan M A, Chaoji V, Salem S, et al. Link prediction using supervised learning[C] //Proc of the 6th SIAM Int Conf on Data Mining: Workshop on Link Analysis, Counter-terrorism and Security. Philadelphia, PA: SIAM, 2006: 531-540
[11]Benchettara N, Kanawati R, Rouveirol C. Supervised machine learning applied to link prediction in bipartite social networks[C] //Proc of 2010 IEEE/ACM Int Conf on Advances in Social Networks Analysis and Mining. Los Alamitos, CA: IEEE Computer Society, 2010: 326-330
[12]Wang Chao, Satuluri V, Parthasarathy S. Local probabilistic models for link prediction[C] //Proc of the 7th IEEE Int Conf on Data Mining (ICDM 2007). Los Alamitos, CA: IEEE Computer Society, 2007: 322-331
[13]Kashima H, Abe N. A parameterized probabilistic model of network evolution for supervised link prediction[C] //Proc of the 6th IEEE Int Conf on Data Mining (ICDM 2006). Los Alamitos, CA: IEEE Computer Society, 2006: 340-349
[14]Lü Linyuan. Link prediction on complex networks[J]. Journal of University of Electronic Science and Technology of China, 2010, 39(5): 651-661 (in Chinese)
(呂琳媛. 復雜網絡鏈路預測[J]. 電子科技大學學報, 2010, 39(5): 651-661)
[15]Huang Zan, Lin D K J. The time-series link prediction problem with applications in communication surveillance[J]. INFORMS Journal on Computing, 2009, 21(2): 286-303
[16]Silva Soares da P R, Cavalcante Prudencio R B. Time series based link prediction[C] //Proc of the 6th Int Joint Conf on Neural Networks. Piscataway, NJ: IEEE, 2012: 1-7
[17]Pietilainen A K, Diot C. The thlab/sigcomm2009 dataset[EB/OL]. (2012-07-15)[2015-02-20]. https://crawdad.cs.dartmouth.edu/thlab/sigcomm2009/20120715
[18]Girvan M, Newman M E J. Community structure in social and biological networks[J]. Proceedings of the National Academy of Sciences, 2002, 99(12): 7821-7826
[19]Ciobanu R I, Dobre C. The upb/mobility2011 dataset[EB/OL]. (2012-06-18)[2015-02-20]. http://www.crawdad.org/upb/mobility2011 /20120618
[20]Radicchi F, Castellano C, Cecconi F, et al. Defining and identifying communities in networks[J]. Proceedings of the National Academy of Sciences, 2004, 101(9): 2658-2663

Liao Guoqiong, born in 1969. PhD. Professor at the School of Information Technology, Jiangxi University of Finance and Economics. Senior member of China Computer Federation. His main research interests include database, data mining and social networks.

Wang Tingli, born in 1990. Master from the School of Information Technology, Jiangxi University of Finance and Economics. Her main research interests include data mining and social networks.

Deng Kun, born in 1980. PhD candidate at the School of Information Technology, Jiangxi University of Finance and Economics. His main research interests include data mining and social networks.

Wan Changxuan, born in 1962. PhD. Professor and PhD supervisor at the School of Information Technology, Jiangxi University of Finance and Economics. Senior member of China Computer Federation. His main research interests include Web data management and Web information retrieval.
Multi-User Location Proximity Prediction in Offline Ephemeral Social Networks
Liao Guoqiong1,2, Wang Tingli1, Deng Kun1,2, and Wan Changxuan1,2
1(SchoolofInformationTechnology,JiangxiUniversityofFinanceandEconomics,Nanchang330013)2(JiangxiProvinceKeyLaboratoryofDataandKnowledgeEngineering(JiangxiUniversityofFinanceandEconomics),Nanchang330013)
Offline ephemeral social network (OffESN) is defined as a new kind of offline social networks created at a specific location for a specific purpose temporally, and lasting for a short period of time. With the popularity of mobile intelligent terminals and the development of short distance communication technologies such as Bluetooth and RFID, the OffESN is receiving more and more attentions from industry and academic communities. Location proximity relations are encounter relations of the users in the OffESN. Aiming to the characteristics such as dynamic change and short duration time, this paper intends to study the problem of multi-user location proximity in the OffESN. First of all, the paper puts forward relevant concepts in the OffESN and defines the problem to be solved. Then, it designs the overall framework of multi-user location proximity prediction, including network segments collection, overlay networks construction, network filter and maximal close subgraphs discovery. Based on the framework and the splitting idea, the paper suggests a maximal close subgraph discovery algorithm for predicting multi-user location proximity. The algorithm uses weighted edge betweenness (WEB) as the basis of splitting, and uses the aggregate density as the termination condition of spitting, which can effectively solve the problem that both numbers of location proximity relations and the users in each location proximity are uncertain. Finally, the experiments on two real datasets verify the feasibility and efficiency of the suggested prediction strategy.
social networks; ephemeral social networks; location proximity; maximal close subgraphs; link prediction
2015-05-21;
2016-02-16
國家自然科學基金項目(61262009);江西省自然科學基金項目(20151122040083);江西省優勢科技創新團隊建設計劃項目(20113BCB24008)
TP18
This work was supported by the National Natural Science Foundation of China (61262009), the Natural Science Foundation of Jiangxi Province (20151122040083), and the Jiangxi Foundation of Superiority Science and Technology Innovation Team Building Program (20113BCB24008).
猜你喜歡
車主之友(2022年4期)2022-08-27 00:58:26
知音·下半月(2022年5期)2022-05-23 23:17:04
商用汽車(2016年11期)2016-12-19 01:20:16
商用汽車(2016年5期)2016-11-28 09:55:15
非公有制企業黨建(2016年1期)2016-07-19 13:02:51
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
衛星與網絡(2016年12期)2016-02-05 09:23:23
創業家(2015年10期)2015-02-27 07:55:08
創業家(2015年10期)2015-02-27 07:54:39
