搭建Hadoop實驗平臺
2016-11-26 05:19:18
網絡安全和信息化 2016年5期
引言:網上有很多介紹如何搭建Hadoop的文章,有的步驟不甚詳細,有的按其方法搭建會出現莫名其妙的問題。本文盡量細化步驟、簡化配置,并已將容易導致錯誤的部分提前修改,為初學者學習搭建Hadoop完全分布式集群環境提供方便。
實驗材料
1、VMware Workstation;
2、ubuntu14.04.3桌面版64位操作系統
3、jdk8u 65 64位4、hadoop2.7.1
實驗過程
用VMware Workstation創建4臺ubuntu虛擬機
Windows平臺下安裝好VMware Workstation虛擬機軟件。從ubuntu官方網站www.ubuntu.com下 載ubuntu14.04.3桌面版64位操作系統,通過VMware Workstation創建一臺ubuntu虛擬機。用戶名 hadoop,口令 hadoop,如圖1所示。
安裝 jdk和 hadoop,并配置環境變量
1、安裝jdk和hadoop:

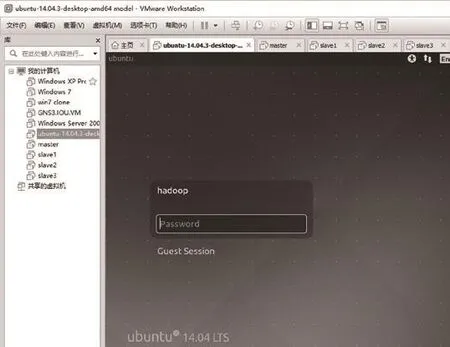
圖1 創建ubuntu虛擬機
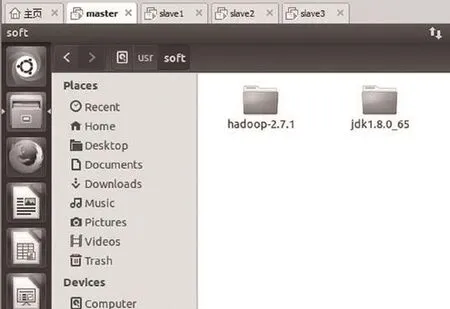
圖2 安裝jdk和ubuntu

圖3 測試jdk安裝是否成功


2、配置 jdk的環境變量

3、配置hadoop的環境量


如果顯示如圖4所示,則表示hadoop安裝成功。
以該虛擬機為模板,克隆出3臺虛擬機
Hadoop集群各節點信息如下:

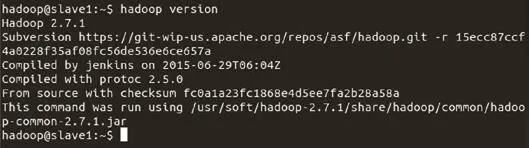
圖4 測試hadoop安裝是否成功
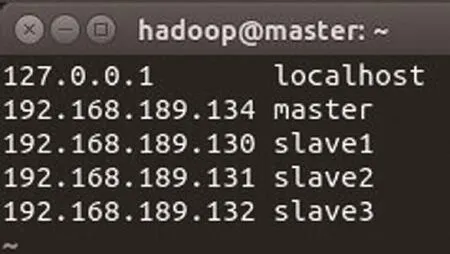
圖5 hosts文件內容

修改4臺ubuntu虛擬機的主機名:sudo vim /etc/hostname,hostname均為hadoop。
修改hosts文件,解析主機名:sudo vim /etc/hosts
hosts文件內容如圖5所示。
重啟虛擬機后主機名和hosts解析生效。
配置SSH無密鑰登錄
在4臺虛擬機上,安裝openssh-server安全連接軟件

4臺上均生成密鑰對:ssh-keygen t rsa,其位于家目錄下的隱藏目錄~/.ssh


修改 core-site.xml、hdfssite.xml、mapred-site.xml、yarn-site.xml及 slaves,為 4臺虛擬機分配不同角色,以組成hadoop完全分布式集群
4個文件位于/usr/soft/hadoop-2.7.1/etc/hadoop/目錄下
由于每4臺主機的xml文件配置必須相同,所以只需在master主機上修改這4個xml文件,然后遠程拷貝到其余3臺主機即可。
特別說明:默認的hadoop集群啟動臨時文件存放在/tmp/目錄下,每次重新開機就會被清空,與此同時namenode的格式化信息就會丟失。為避免hadoop集群啟動時出現namenode進程丟失故障,需在master主機上建立一個永久的臨時文件存放目錄:mkdir /home/hadoop/hadoop_tmp。
同時打開所有的xml文件:gedit *-site.xml。
1、core-site.xml用于配置namenode節點,修改后內容為


3、mapred-site.xml需 從mapred-site.xml.template模板復制而來,修改后內容為

4、yarn-site.xml用于配置resourcemanager,本實驗中resourcemanager由namenode節點兼任,修改后內容為





將上述4個xml文件從master上copy到其它3個節點,或者直接拷貝hadoop目錄,使4臺主機的xml文件相同。

另 外,需 在master和slave3節點上配置slaves文件,用于指定集群中的datanode節點是哪幾個。slaves文件內容如圖6所示。
至此,已完成hadoop集群的所有必需的配置工作。
格式化hdfs文件系統,啟動 hadoop集群
格式化hdfs文件系統:hadoop namenode format

圖6 slaves文件內容
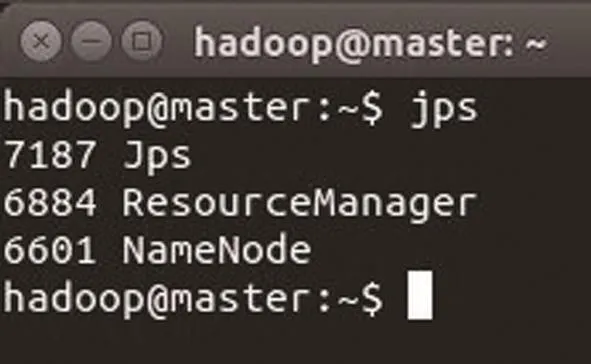
圖7 master節點進程信息
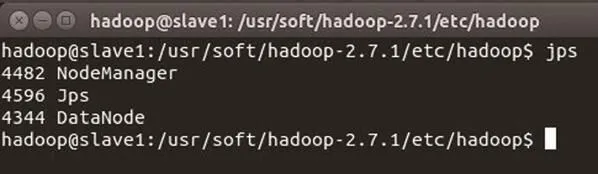
圖8 slave1 節點進程信息
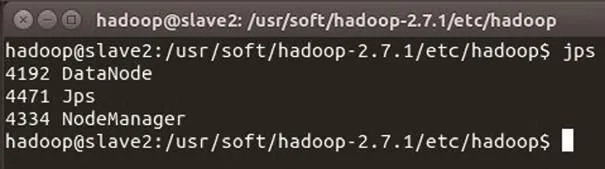
圖9 slave1 節點進程信息
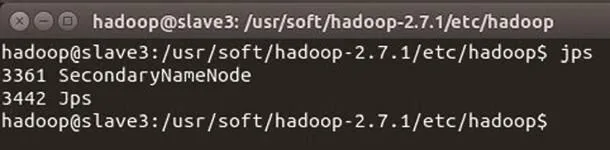
圖10 slave3 節點進程信息
提示Storage directory/home/hadoop/hadoop_tmp /dfs/name has been successfully formatted.
表示hdfs格式化成功。
啟 動hadoop集 群:start-all.sh
查看各節點的hadoop進程信息,使用命令:jps
master節點進程信息如圖7所示。slave1節點進程信息如 圖8所示。
slave2節點進程信息如圖9所示。
slave3節點進程信息如圖10所示。
如果以上顯示都正常,則表示hadoop集群啟動成功。
測試java程序以驗證hadoop是否能進行數據分析
本實驗將測試jdk自帶的wordcount程序。
先在master節點本地創建測試用例:vim test.txt
文本內容:

在hdfs文件系統下新建 input目 錄:hadoop fs-mkdir /input
查看新建目錄是否成功:hadoop fs ls /
顯示有input目錄了
將test.txt從本機上傳到hdfs文件系統:hadoop fs put test.txt /input
啟動java的wordcount程序


上述語句是一條完整的命令。
啟動了mapreduce,統計文本中單詞出現的次數,將結果輸出至output目錄。
查看結果:用瀏覽器打開 http://master:50070,有 了output目 錄,內 有2個文件_SUCCESS和part-r-00000。
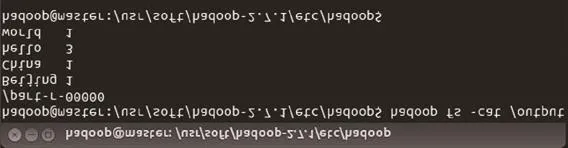
圖11 查看wordcount統計結果
查看wordcount統計結果:hadoop fs cat/output/part-r-00000,如果顯示結果如圖11所示,則表示mapreduce運算正常。
經驗總結
Hadoop集群的resource manager、namenode、secondary namenode、datanode、nodemanager等角色搭配比較靈活,也是經常困擾初學者的地方。
幾種角色要依賴4個xml文件和slaves來配置,弄清楚這個問題將對進一步學習Hadoop至關重要。
猜你喜歡
科學大眾(2022年11期)2022-06-21 09:20:52
中國外匯(2019年20期)2019-11-25 09:54:58
中華手工(2017年2期)2017-06-06 23:00:31
臺聲(2016年2期)2016-09-16 01:06:53
中外會展(2014年4期)2014-11-27 07:46:46
民主與科學(2014年3期)2014-02-28 11:23:03
教育與職業(2014年7期)2014-01-21 02:35:04
計算機與網絡(2013年1期)2013-06-05 05:31:50
祝您健康(1987年3期)1987-12-30 09:52:32
祝您健康(1987年2期)1987-12-30 09:52:28
