基于LDA與距離度量學習的文本分類研究
2016-11-29 05:34:12詹增榮
湖南師范大學自然科學學報 2016年5期
詹增榮,程 丹
(1.廣州番禺職業技術學院,中國 廣州 511483;2.廣州體育職業技術學院,中國 廣州 510650)
?
基于LDA與距離度量學習的文本分類研究
詹增榮1*,程 丹2
(1.廣州番禺職業技術學院,中國 廣州 511483;2.廣州體育職業技術學院,中國 廣州 510650)
提出了一種基于隱含狄利克雷分布(LDA)與距離度量學習(DML)的文本分類方法,該方法利用LDA為文本建立主題模型,借助Gibbs抽樣算法計算模型參數,挖掘隱藏在文本內主題與詞的關系,得到文本的主題概率分布.以此主題分布作為文本的特征,利用DML方法為不同類別的文本學習馬氏距離矩陣,從而較好的表達了文本之間的相似性.最后在學習到的文本間距離上,利用常用的KNN及 SVM分類器進行文本分類.在經典的3個數據集中的實驗結果表明,該方法提高了文本分類的準確率,并且在不同的隱含主題數目參數下能體現較好的穩定性.
文本分類;距離度量學習;隱含狄利克雷分布;主題模型
隨著互聯網的高速發展,文本數據作為最主要的信息載體之一以指數級的速度不斷增長.因此,如何有效地從海量文本數據中挖掘出有用的信息成為當前的迫切需求.文本自動分類技術作為自然語言處理的關鍵技術近年來廣泛受到關注并得到了快速的發展,已成為當前研究的熱點.文本自動分類的過程中主要的技術包括了文本的預處理、特征的提取、文本的表示、分類器的設計,以及分類效果的評估等.
在文本分類研究中,向量空間模型(Vector Space Model,VSM)[1]是數據挖掘領域經典的分析模型之一.VSM利用統計詞在文本和文本集中出現的頻率來表征詞對文本的重要性,最終將文本表示成一個向量,并通過余弦等不同的距離度量方式來計算文本之間的相似度.然而,由于自然語言的復雜性,類似文本語義等復雜問題并不能在VSM中得到建模,而且利用VSM表示文本得到的數據空間是極度高維且稀疏的.近年來,以隱含狄利克雷分布(Latent Dirichlet Allocation,LDA)[2]為代表的主題模型成為研究的熱點.基于LDA主題模型進行建模能很好地考慮文本語義的相似性問題,因而被廣泛應用到各個文本分類算法中,如Bao[3]、姚全珠[4]、李文波[5]等都使用LDA模型來對文本進行分類.
樣本間的距離度量是模式識別領域研究的核心問題之一,它對分類、聚類等模式分析任務非常重要,如K近鄰、支持向量機等分類算法的準確率就非常依賴于距離的定義.在文本分類中,為文本的特征向量選擇適合的距離度量方法將直接影響到最終分類的效果.為此,許多學者分別提出了不同類型距離度量學習(Distance Metric Learning,DML)方法,即從給定訓練集的相似或不相似的樣本中學習一個距離度量來提高分類或聚類等任務的準確率.Davis[6]等給出了一種基于信息理論的方法去學習一個馬氏距離,Weinberger[7]等闡述了就提高KNN分類器的準確率中的大間距框架的距離學習問題,Kulis[8]等給出了距離學習的綜述.多數的DML研究都是著重在尋找一個線性矩陣來最優化全局數據間的可分離性和緊湊性,但是如果不同類別的數據呈現出不同的分布,尋找一個適合全局數據的距離度量線性矩陣往往不太現實.一個可行的方法是針對不同的局部數據來學習不同的線性矩陣,從而滿足不同局部數據的最佳距離度量矩陣.
基于以上考慮,本文提出基于LDA和距離度量學習的文本分類方法.該方法首先利用LDA模型對文本集進行建模,即利用文本的統計特性將文本語料映射到各個主題空間,挖掘隱藏主題與詞的分布,從而得到文本的主題分布.然后,以此分布為文本特征,針對不同類別的文本通過距離度量學習得到適合該類別文本與其他文本最佳距離度量矩陣.最后,根據得到的不同類別文本的距離度量矩陣計算文本數據與該類別文本間的距離,再放到常見的KNN[9]或SVM[10]分類器中實現文本的分類.
1 相關理論
1.1 LDA模型
LDA模型[2]是由Blei提出等人在2003年提出的一種對離散數據集建模的主題概率模型.LDA模型相對于傳統的LSI[11]和PLSI[12]等模型不僅具有更加清晰的層次結構而且解決了隨著訓練文本數目增加主題個數不斷增加導致的過渡擬合問題,從而更加適合于大規模語料庫分析.
LDA是一種非監督機器學習技術,它的基本思想是文本由多個潛在的主題所構成,而每個潛在的主題又由文本中若干個特定詞匯構成.它將文本、主題、詞的結構構成三層貝葉斯概率模型,即文本中的主題服從Dirichlet分布,且任一主題中出現的詞服從多項式分布.如圖1所示,LDA模型具有非常清晰的層次結構.
給定一個文本集合D={d1,d2,…,dN}和隱含主題數K,LDA模型將按照圖2所示的有向概率圖來生成文本,其具體的過程如下:
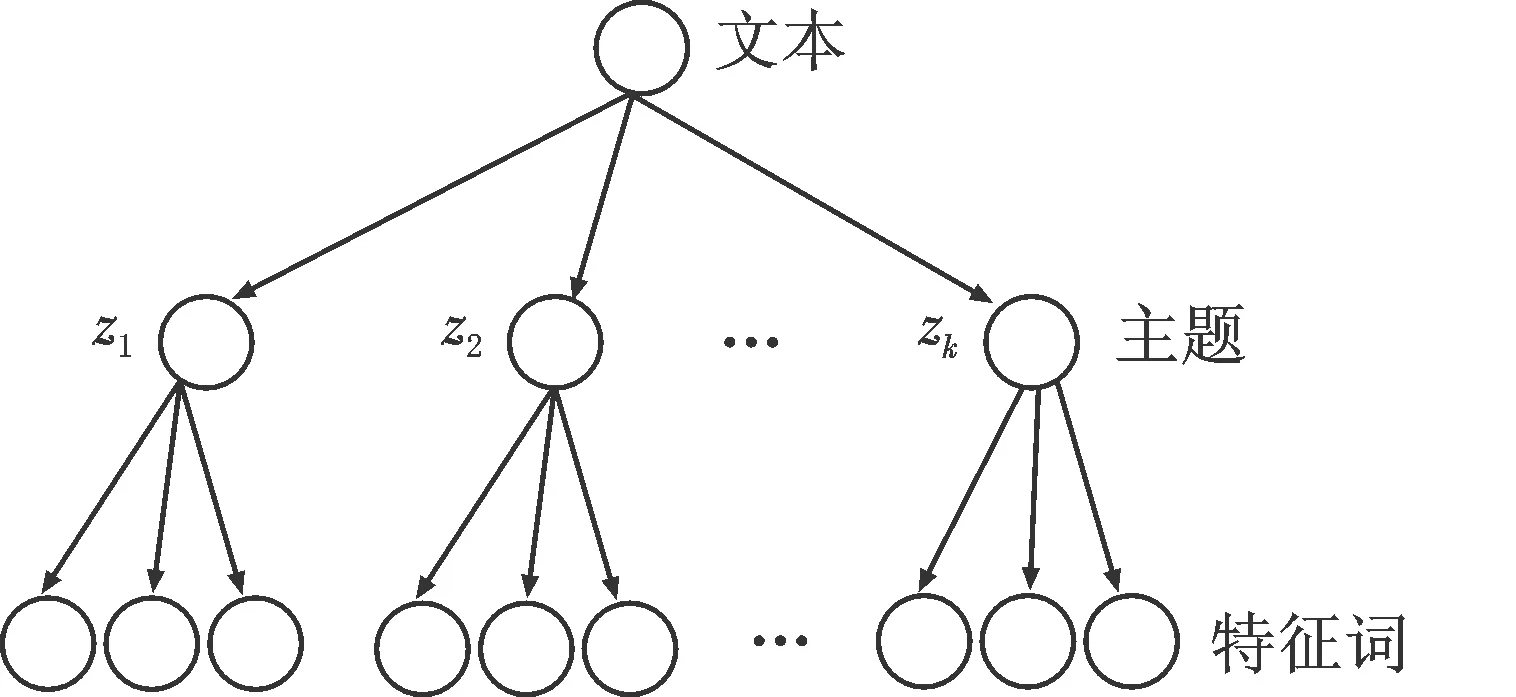
圖1 LDA隱主題模型拓撲結構圖Fig.1 LDA topological structure graph
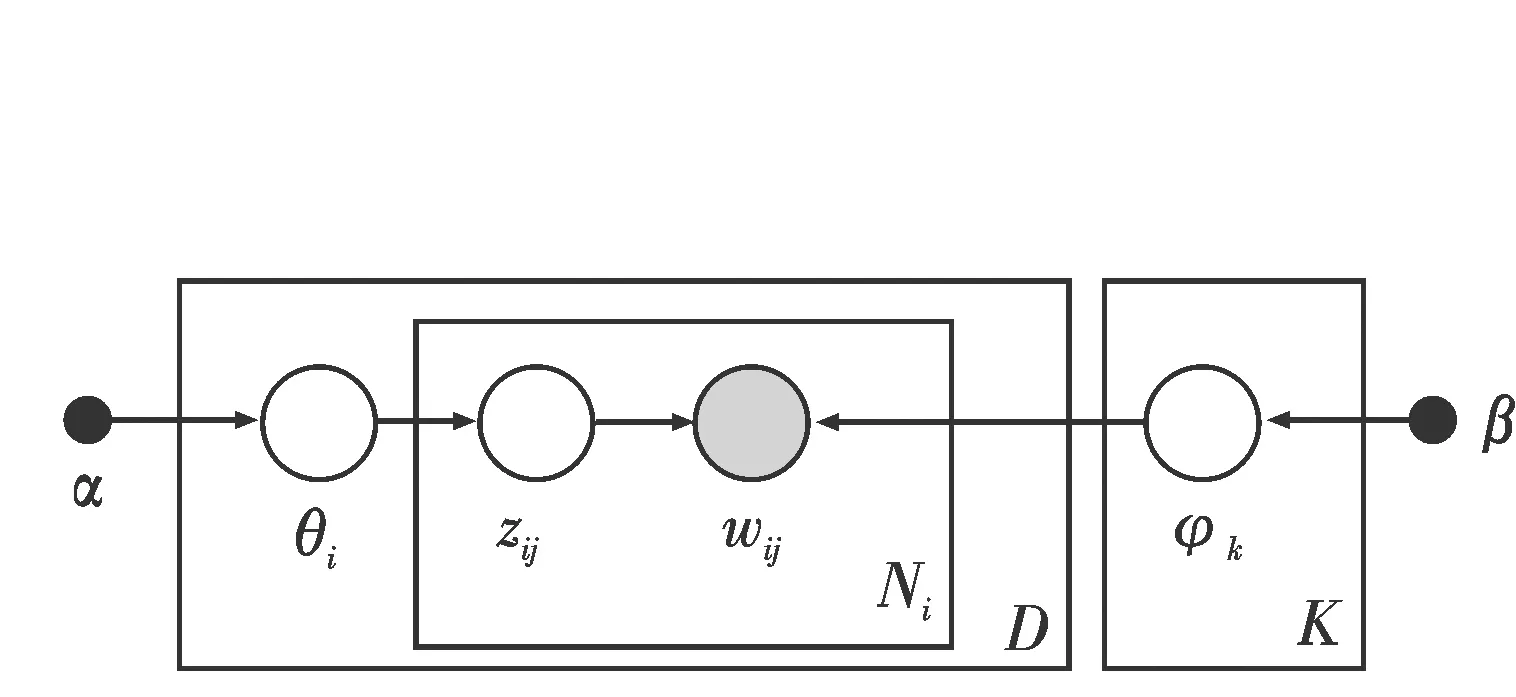
圖2 LDA隱主題模型有向概率圖Fig.2 LDA directed probability graph
1)對每個主題k∈{1,2,…,K},根據多項式分布φ~multinomial(β)得到該主題中詞多項式分布向量φk.
2)對文本集D中的文檔di,根據主題分布概率向量θ~Dir(α),取樣生成文檔di的主題分布θi.
3)對文檔di的每個詞wij,j∈{1,2,…,Ni},Ni為文檔di中特征詞的數目:
a)根據多項式分布z~multinomial(θi)中取樣生成文檔di第j個詞所屬的主題zij.
b)設主題zij=k,根據主題的詞概率分布w~multinomial(φk)生成相應的詞wij.
重復2和3過程直到文本集中所有的文本及文本的詞都生成完成后,最終得到每個文檔的主題概率分布和每個主題中詞的概率分布.因此,文檔di中的第j詞的概率為:
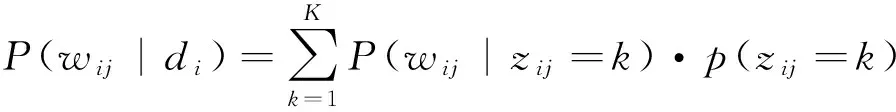
從而得到文本中每個詞的生成概率為P(wij,di)=P(di)·P(wij|di),式中P(di)為已知,結合先驗概率分布的參數α,β得到文檔di的概率密度為:
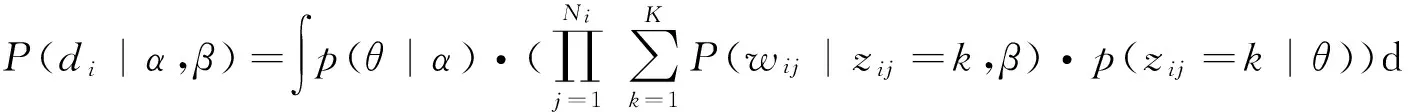
(1)
1.2 GP采樣
LDA對參數的估計比較常用的方法包括了變分推算方法和Gibbs抽樣方法.其中Gibbs抽樣算法屬于馬爾科夫鏈-蒙特卡羅(Markov Chain-Monte Carlo,MCMC)的一種特例,它通過構造收斂于目標概率分布的馬爾科夫鏈,并從鏈中抽樣出接近于該概率分布的樣本.由于Gibbs抽樣算法簡單且容易實現,對于聯合概率分布維度較高的情況非常適用,因此成為主題模型最常用的參數估計算法.
在式(1)中,需要估計的定參數有兩個,一個是在參數α下產生的文檔中主題的分布θ;第二是在確定主題后,由參數β產生的主題中詞的分布φ.利用Gibbs抽樣算法可以得到:
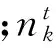
1.3 距離度量學習
歐式距離與馬氏距離作為最常用的樣本間距離度量方法,目前已經被廣泛應用到不同的分類算法中.兩個樣本xi和xj在Rd的歐式平方距離定義為:
d2(xi,xj)=‖xi-xj‖2=〈xi-xj,xj-xj〉,
而兩個樣本xi和xj在Rd中的馬氏平方距離
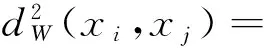
其中w是一個d×d的半正定參數矩陣.可以看出當w為單位矩陣時,馬氏距離就是歐式平方距離.絕大多數距離度量學習是去學習w這個半正定矩陣來作為馬氏距離的參數,例如信息論度量學習[6]將距離度量問題轉化為Bregman最優化問題,通過在線性條件限制下最小化LogDet散度來求得最優化的w.在距離度量學習中,最優化問題可以被描述成為在給定限制集合下的凸方程問題.既給定相似集合S={(i,j)|C(xi)=C(xj)}和不相似集合D={(i,j)|C(xi)≠C(xj)} 其中C(xi)表示xi的類別標簽,距離學習問題可以被定義為:
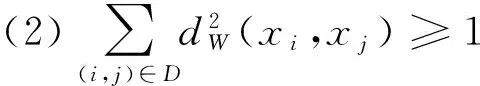
(2)
如在KNN分類算法中,給定分類的樣本集x={xi|i=1,2,…,n}和樣本對應的標簽{yi|i=1,2,…,n}.對于xi的類別,KNN分類器根據xi的最近k個領域樣本集合中所屬的不同類別標簽的數量比例來決定預測樣本的類別標簽.因此,KNN分類器中xi的目標鄰域樣本離xi越近,分類的準確率就越高,即xi與其他樣本點的距離可以用以下限制式子來表達.
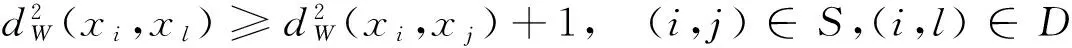
最優化式(2)中的目標函數變成尋找W使得xi到它同類別的其他樣本的距離最小,且盡量減少違反(2)式中第二個限制.從而可以將(2)中優化的目標轉換為

(3)
式中前部分主要代表了樣本點到它領域的距離之和,而后半部分為對于那些違反了(2)式第二限制的樣本點的懲罰,γ來懲罰系數.
在ITML[6]中兩個矩陣之間的布雷格曼散度的定義如下:
Dφ(X,Y)=φ(X)-φ(Y)-tr((φ(Y))T(X-Y)),
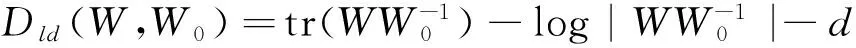
從而使得在距離度量學習中的優化問題可以被描述為去尋找一個正定矩陣W使得它W0與間的散度距離在滿足一定的約束下最近.即在給定相似集合S和不相似集合D時,優化問題可以表示為:
其中c(i,j)為第(i,j)個限制,ξ為包含松弛變量的向量,ξ0為包含判斷相似或不相似闕值的向量.
2 基于LDA與距離度量學習的文本分類
基于LDA與距離度量學習的文本分類算法主要是利用了LDA主題模型對文本進行建模并使用Gibbs抽樣方法間接計算模型的參數,在確定了主題數目K等參數后,得到文本集中所有文本上的主題概率分布.以文本的主題概率分布為特征向量,文本已有的類別標簽,并利用距離度量學習算法學習每個類別內樣本與測試樣本的最優距離,最后將得到的樣本間的最優距離放入到KNN或SVM等分類器中進行分類得到每個文本的類別.分類具體過程主要包括了文本的預處理、LDA建模、距離度量學習、文本分類等,算法的流程框架圖如圖3所示.
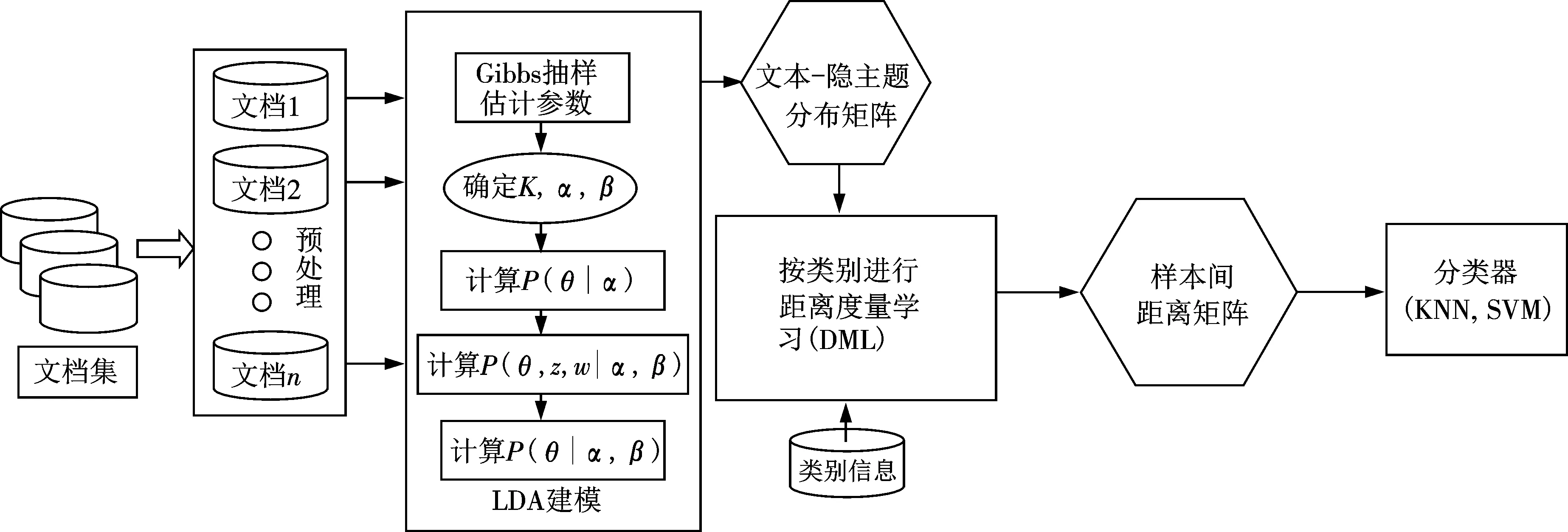
圖3 算法的流程圖Fig.3 Flowchart of the algorithm
2.1 文本預處理
針對實驗語料庫進行清洗、去停用詞、提取詞干,并過濾冗余的信息,建立初步的文檔向量空間模型.
2.2 LDA建模
利用LDA算法對文本集合中的文本進行主題建模,建模過程利用Gibbs抽樣方法來進行參數估計,并確定了主題數目K和參數α,β.通過計算得到主題分布向量θ,并最終得到文本-隱主題分布矩陣.
2.3 距離度量學習
尋找一個馬氏距離矩陣來達到最優化全局數據間的可分離性和緊湊性是距離度量學習研究目的,但是在數據呈現出不同的分布的情況下,很難得到一個適合全局數據的距離度量矩陣.因此,本節提出為不同的類別樣本數據學習一個適合該類別的馬氏距離矩陣w,用于表達該類別內數據樣本與其他數據樣本的距離度量.
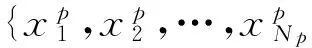

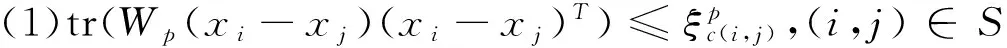
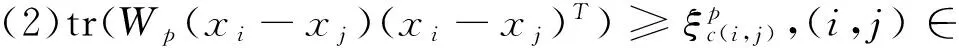
其中相似集合S和不相似集合D的定義為:當學習某一類別p的馬氏距離矩陣時,S中的元素為該類別所有元素的二元組合,D中的為該類別的元素與其他類別元素的二元組合.
2.4 文本分類
根據LDA建模獲得的所有文本的主題概率分布矩陣,結合樣本類別信息利用距離度量學習算法計算出樣本之間的距離,然后放到常見的KNN或SVM分類器中進行分類得到相應的測試樣本的類別.
3 實驗設計與結果分析
3.1 實驗環境
實驗在CPU為Intel Core 8核、內存為16G、操作系統為Windows 7的PC機上進行.主要算法采用了Matlab來實現,LDA算法利用文[13]中提供的Matlab Toolbox來實現,距離度量學習算法及KNN分類器算法是在ITML[6]中的算法的基礎上改進得到.SVM分類器選取了臺灣大學林智仁教授開發設計的LIBSVM[14]作為分類器的訓練環境實現.
3.2 實驗數據
實驗選擇了3個經典的數據集Reuters21578,20Newsgroups和TDT2作為實驗的數據,數據來源及預處理都來自于文[15].Reuters21578是路透社1987年中新聞專線的文檔集合.它包含了21 578個樣本,分成135個類別.為了實驗方便剔除了屬于多個類別的樣本,并從中選取了最大的9個類別集合共7 258個數據作為實驗數據.20Newsgroups文檔集合包含了18 846個文檔,平均分布為20個類別,為了減少實驗有效性,選取了全部類別作為實驗數據.TDT2(NIST Topic Detection and Tracking)文檔集包含了來自6個不同新聞源的文檔集合,總共有11 201個文檔數據,并被分成96個語義類別.為了簡化實驗結果,剔除了屬于多個類別的文檔數據,最后只保留了9 394個文檔.所有的數據集合都按照文[15]的方法做了預處理,包括剔除無用詞語、應用波特詞干算法等.最后都按照按照0.7的比例劃分訓練集和測試集.
3.3 評估方法
為了較好地描述模型對文本分類的效果,實驗從分類的準確率(Accuracy)、精確率(Precision)、召回率(Recall)、F測量來評估測試的結果,其中F測量是一種結合精確率和召回率的平衡指標.對于分類問題可以用表1所示的混合矩陣來表示分類結果的情況.根據表中的描述,實驗中各個評估方法的定義如下(其中一般取值為1):
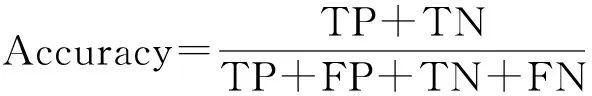
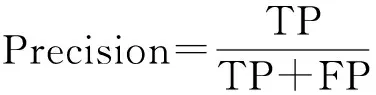
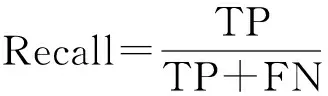


表1 分類評估混合矩陣
3.4 實驗結果分析
在經典的3個數據集進行預處理后分別采用3種算法進行實驗,包括傳統的KNN分類;LDA建模后進行KNN分類(LDA-KNN);LDA建模后利用距度量離學習算法計算樣本間距離后再進行KNN分類(LDA-DML-KNN).實驗得到結果如表2所示(其中LDA的主題數取值為100),從表2中可以看出,基于LDA主題模型與KNN相結合算法(LDA-KNN)相對于傳統的KNN算法具有較高的準確率,在Reuters和TDT數據集上的多項指標都有超過15%的提高.而融合距離度量學習的分類算法(LDA-DML-KNN)比LDA-KNN算法在準確率等指標上具有5%左右的提升.

表2 經典數據集上的實驗結果
鑒于主題數(T)的大小會影響實驗的效果,實驗針對不同的主題數目在3個數據集上分別使用KNN和SVM兩個分類器進行了測試,測試結果如圖4所示,其中KNN的領域數目k=10,SVM采用了高斯核函數(其中參數σ=1/4),且為了訓練樣本間不同類別的樣本距離取樣本到相互間距離的中值.在3個實驗集合實驗結果中,當主題數取得T=100時已經具有較好的效果.其次,結果表明融合距離度量學習的分類算法不僅取得較高的準確率且更加穩定.此外,在實驗中SVM分類器比KNN分類具有更好的分類效果,特別是在20Newsgroups數據集上.

圖4 不同主題數在KNN和SVM上分類的實驗結果Fig.4 Experimental results for classification with different topic number in KNN and SVM
4 總結
本文將LDA主題模型和距離度量學習應用到文本分類中,不僅將文本深層次的語義知識嵌入到模型中,并且學習了不同文本深層次語義之間的距離度量,從而提高了文本分類的準確率.此外,由于LDA主題模型所建立的文本主題空間的維度要遠遠小于文本的向量空間模型,大大提高了計算了速度.在文本分類常用的3個實驗數據集進行的實驗結果表明,該方法可以明顯提高文本分類效果,模型可以為數據挖掘、自然語言處理等學科的研究和實現提供借鑒與參考.
[1] SALTON G,WONG A,YANG C S.A vector space model for automatic indexing [J].Commun ACM,1975,18(11):613-620.
[2] BLEI D M,NG A Y,JORDAN M I.Latent Dirichlet allocation [J].Machine Learning Res,2003,29(3):993-1022.
[3] BAO Y,COLLIER N,DATTA A.A partially supervised cross-collection topic model for cross-domain text classification; proceedings of the 22nd ACM international conference on information & knowledge management[C].F.ACM,2013.
[4] 姚全珠,宋志理,彭 程.基于LDA模型的文本分類研究 [J].計算機工程與應用,2011,13(1):150-153.
[5] 李文波,孫 樂,張大鯤.基于Labeled-LDA模型的文本分類新算法 [J].計算機學報,2008,31(4):620-627.
[6] DAVIS J V,KULIS B,JAIN P,etal.Information-theoretic metric learning[C]//Proceedings of the 24th international conference on Machine learning,F.ACM,2007.
[7] WEINBERGER K Q,SAUL L K.Distance metric learning for large margin nearest neighbor classification [J].Machine Learning Res,2009,10(2):207-244.
[8] KULIS B.Metric learning: A survey [J].Found Trends Machine Learning,2012,5(4):287-364.
[9] COVER T M,HART P E.Nearest neighbor pattern classification [J].Inf Theory,IEEE Trans,1967,13(1):21-27.
[10] BURGES C J C.A tutorial on support vector machines for pattern recognition [J].Data Mining Knowledge Discovery,1998,2(2):121-167.
[11] DUMAIS S T.Latent semantic indexing (LSI): TREC-3 report [J].Nist Special Publication SP,1995,9(2):219.
[12] THOMAS H.Probabilistic latent semantic indexing[C]//Proceedings of the 22nd annual international ACM SIGIR conference on Research and development in information retrieval,Berkeley,California,USA,F.ACM,1999.
[13] GRIFFITHS T L,STEYVERS M.Finding scientific topics [J].Proc Nat Acad Sci,2004,101(suppl 1):5228-5235.
[14] CHANG C C,LIN C J.LIBSVM: a library for support vector machines [J].ACM Trans Intell Syst Technol (TIST),2011,2(3):27.
[15] ZHANG D,WANG J,CAI D,etal.Self-taught hashing for fast similarity search[C]//Proceedings of the 33rd international ACM SIGIR conference on Research and development in information retrieval,F.ACM,2010.
(編輯 CXM)
Research on Text Classification Based on LDA and Distance Metric Learning
ZHANZeng-rong1*,CHENGDan2
(1.Guangzhou Panyu Polytechnic,Guangzhou 511483,China; 2.Guangzhou Polytechnic of Sport,Guangzhou 510650,China)
A text classification method based on Latent Dirichlet Allocation (LDA)and distance metric learning (DML)were presented.The method models text data with LDA,which generate the topic distribution of different text through detecting the hidden relationship between different topics and words inside the text data,and parameters of the model are estimated with Gibbs sampling algorithm.The generated topic distribution is used as the features of the text data,and the DML method is used to learning the Mahalanobis distance metric for different classes so that the similarity between text data are well presented.Classifiers like KNN or SVM are used to classify text data based on the learning distances.Experimental results showed that this method can improve the text classification accuracy and is robust in setting different topic number.
text classification; distance metric learning; latent Dirichlet allocation; topic model
10.7612/j.issn.1000-2537.2016.05.012
2016-04-03
廣州教育科學規劃資助項目(2013A179,1201533765);廣州市屬高校科研計劃資助項目(2012B154);廣東省自然科學基金資助項目(2015A030313807);廣東省高等學校優秀青年教師培養計劃資助項目(YQ2015207)
*通訊作者,E-mail:zhanzr@gzpyp.edu.cn
TP391.41
A
1000-2537(2016)05-0070-07
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
制造技術與機床(2019年10期)2019-10-26 02:48:08
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
電子制作(2018年18期)2018-11-14 01:48:06
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
光學精密工程(2016年6期)2016-11-07 09:07:19
