基于數據融合的公交客流規模測算方法
2016-12-14 23:28:16李林波
城市交通 2016年1期
關鍵詞:成本
李林波,姜 嶼,王 婧,吳 兵
(1.同濟大學道路與交通工程教育部重點實驗室,上海201804;2.濟南市規劃設計研究院,山東濟南250101)
基于數據融合的公交客流規模測算方法
李林波1,姜 嶼1,王 婧2,吳 兵1
(1.同濟大學道路與交通工程教育部重點實驗室,上海201804;2.濟南市規劃設計研究院,山東濟南250101)
公交客流規模測算往往存在調查成本受限和準確度要求較高的矛盾。提出基于公交IC卡歷史數據與人工補充調查數據的數據融合測算方法,以準確推算公交客流規模。首先根據公交線路的基本屬性,采用聚類分析方法劃分線路類型,從每一類中選擇具有代表性的線路。基于IC卡數據分析公交客流時變特征,運用有序樣本聚類Fisher算法將線路小時刷卡量進行聚類分析。劃分刷卡量相似時段,進而采用優化方法確定調查抽樣率,確定相應的調查車輛進行人工補充調查,最終經過數據融合計算獲得公交客流規模。基于上海市某轄區IC卡數據進行案例分析,測算得到三類公交線路的日均客流量。
公共交通;客流規模;聚類分析;數據融合;公交IC卡;上海市
0 引言
優先發展公共交通往往需要通過財政扶持的形式激勵公交企業提升服務質量,因此需要對公交線路的實際客流規模進行評估。目前,政府獲取公交客流規模的主要方法有兩種:1)利用公交企業年報,但由于企業數據管理不健全,導致年報數據往往存在很大的誤差;2)利用公交IC卡(以下簡稱“IC卡”)數據,但是該數據只能反映持卡者的客流信息,無法反映總體公交客流情況,簡單地使用IC卡刷卡比例推算總體客流情況也無法精準地反映公共交通的實際服務情況。人工調查方法是獲取公交客流規模最為直接有效的方法,但由于調查費用太高而不現實。面對這一困境,基于IC卡客流數據,如何通過人工補充調查并采用數據融合技術對公交客流規模進行準確推算就顯得很有意義。
隨著信息技術的發展,越來越多的城市開始使用IC卡。各城市的IC卡系統發展的不統一導致信息研究方法的差異,主要包括上客車站判斷[1-2]、下客車站判斷[3-4]以及換乘判斷[5-6]三個內容。文獻[7]從數據管理、數據質量控制、數據分析與應用等方面詳細闡述利用IC卡系統進行公交客流調查的方法。文獻[8]對出行調查和IC卡信息利用進行對比分析,并探討兩者融合的可行性。文獻[1]和文獻[9]提出如何將IC卡記錄的原始信息轉化為可直接運用于城市交通規劃及公交運營調度的基本信息。文獻[10]對IC卡數據的采集方法和數據結構進行分析總結,確定IC卡數據分析的具體目標。這些研究成果為人工調查數據和IC卡數據的融合處理提供了借鑒。
本文提出一種公交客流規模測算方法,即通過分時段人工抽樣調查實際公交客流情況,并基于數據融合理念對IC卡數據進行總體擴樣。首先,考慮到調查成本的限制,將所有公交線路進行分類,選出可以代表該類型公交客流情況的公交線路。其次,分析公交客流的時變特征,提出線路小時刷卡量聚類分析方法,從調查成本和結果精度兩方面,借鑒最優化思想提出調查最佳抽樣率的計算方法,并根據IC卡數據分析所對應的刷卡時段,詳細梳理公交線路的運營調度計劃,確定具體被調查的公共汽車,制定調查方案。最后,基于數據融合理念對IC卡客流數據進行擴樣分析,測算公交客流總體規模。
1 IC卡數據聚類分析
1.1 聚類分析方法的優勢
在公交客流調查中,通過一條或幾條線路調查獲得的IC卡數據擴樣系數,以此對所有線路的IC卡客流進行總體客流規模估計的方法存在以下問題:1)由于不同線路客流情況不一樣,采用同樣的擴樣系數會造成較大誤差;2)同一線路在一天中的客流也存在顯著的時變特征,采用同一擴樣系數會放大或縮小客流總體規模。當然,增加調查線路是提高數據準確度的有效方法,但在實際過程中,受限于成本投入,其可操作性不強。
通過對不同線路客流情況的觀測發現,在公交線路走向、車型配置和運營方式等方面相似的線路,其客流特征具有相似性[11]。因此,可以考慮在進行公交客流規模測算時,先將線路進行聚類分析[10],進而抽取每一類線路中的部分車輛為代表進行調查分析,最終獲得反映該類線路的客流特征信息。這樣可以有效減小不同線路采用相同擴樣系數帶來的誤差,同時,對不同類型線路的具體劃分可以提高數據的有效性和結果的準確性。
此外,由于居民出行會隨時間呈現周期性變化,因而公交客流的總體特征也會呈現周變、日變和時變特性。通過對公交線路IC卡刷卡量的分析發現,任何公交線路的客流情況在某一時段里總是呈現相似的時變特征,主要表現為一天中各個小時的流量在某些相鄰時段內IC卡刷卡量的相似性[11]。鑒于這種相對穩定的特征,可以根據現有的小樣本數據將性質相似時段的IC卡數據進行歸類分析,這種按照時間順序來分析客流特征的過程在統計學中被歸為有序樣本聚類問題。
1.2 相似線路聚類分析
為了對數條信息完整的公交線路進行合理分類,需要選取聚類指標,聚類指標應能夠比較客觀、全面地反映每一類型線路刷卡量的變異特征。線路長度、車站數量為線路的自身屬性,會直接影響公交運營的實際情況,進而影響整條線路的客流量級、客流構成和IC卡刷卡比例等。線路類型是規劃者對公交線路屬性的劃分,不同類型線路的客流量及服務對象不同,每種交通對象群體都有不同的持卡比例,從而影響整條線路的刷卡情況。而平均發車間隔和線路擁擠程度則會影響乘客是否選擇乘坐該線路,不同社會地位、經濟條件對象的接受程度各不相同,進而反映的不同群體使用IC卡的比例也會相應受到影響[12]。
線路長度(LoR)、車站數量(NoBS)、線路類型(RT)、平均發車間隔(ADI)以及線路擁擠程度(CD)5個指標分別從總體、個體的角度影響線路的客流總量,能在一定程度上反映線路客流的變異性。因此,選擇這五個指標作為公交線路的聚類屬性構造樣本矩陣,并利用SPSS18.0軟件實現聚類過程。
1.3 相似小時聚類分析
相似小時聚類分析通常應用有序樣本聚類Fisher算法[13-14],可以有效劃分公交客流的相似時段,對于抽樣時間的選取具有重要的現實意義。
設有序變量依次為x1,x2,…,xn,其中每個變量代表公交客流小時刷卡數據,是一維向量。如果出最小誤差函數e隨分段數k變化的曲線,取該曲線拐彎處或開始變平處對應的分段數作為最適宜的分段數。
4)求解最優分段。確定分段數k后,在所有可能的分段方案表示對樣本x1,x2,…,xn的最優k分割,則一定是在某一個截尾子段的最優k-1分割之后再添加一段形成的。這樣就可以從各個截尾子段的最優二分段出發,建立一種遞推公式求出各種k值下的最優分割,從而使得求最優分割的精確解得以實現。具體步驟如下:
1)定義類直徑。設變量x1,x2,…,xn的某一歸類為其均值向量
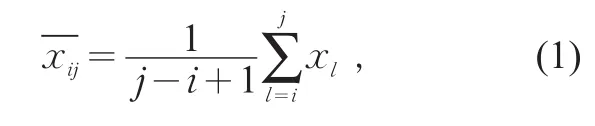
則類直徑
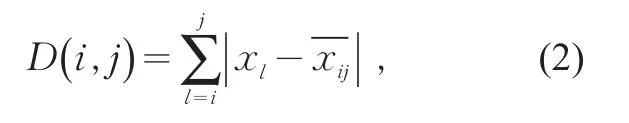
2)定義誤差函數。將n個樣本劃分為k個區間段,為記號簡單,變量xi用下標i表示,用表示某一種分法,即

其中1=i1<i2<…<ik≤n,定義這一分類的誤差函數
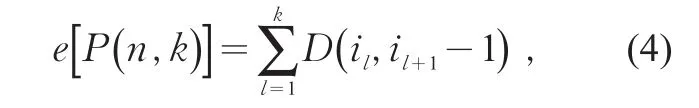
當n和k給定時,總離差平方和一定,當類內平方和越小,則類間平方和越大,分類越合理。因此,聚類的目的是要找到一種分法使誤差函數達到最小。

3)確定區間劃分個數。有序聚類法本身并未給出合適的劃分段數。本研究通過做中找出使達到極小值的最優k分段,記為若要將樣本劃成k段,首先確定jk使得達到極小值,即滿足
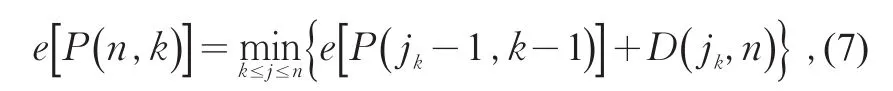
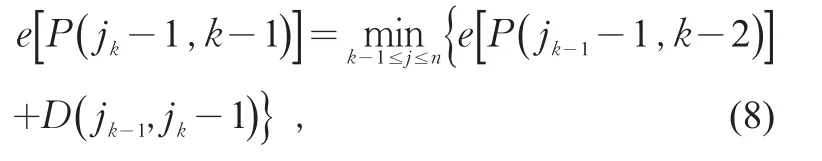
2 人工調查抽樣方案
2.1 抽樣率計算
調查成本及調查精度是抽樣調查的主要關注點。因此,在保證一定精度的條件下減少費用或在限定費用的條件下盡量提高精度十分重要。若不考慮非抽樣誤差,調查精度與樣本量在一定范圍內直接正相關。當抽樣樣本超過一定數量后,單位樣本量的增加對于精度的提高效果不再明顯。同時,調查成本與樣本量基本呈線性正相關關系。應該存在一個合適的抽樣率,使得調查精度與調查成本達到均衡最優。這可以被歸結為一個多目標最優化問題:抽樣率f為決策變量,兩個目標分別為調查成本最低及調查精度最高。
在公交客流跟車調查過程中,調查成本C調主要包括兩個部分:固定成本C固和變動成本C變。前者指與樣本量大小無關的成本,包括宣傳費用、調查組織協調費用等;后者是隨樣本量增加而增加的成本。如果單位樣本量的調查成本(包括人工費和材料費等)為C單,實際運營車輛數為N,抽樣率為f,則調查成本
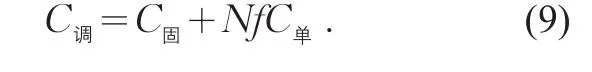
在統計學中,通常以允許相對誤差r來表示要求的精度。由簡單隨機抽樣的樣本量計算公式
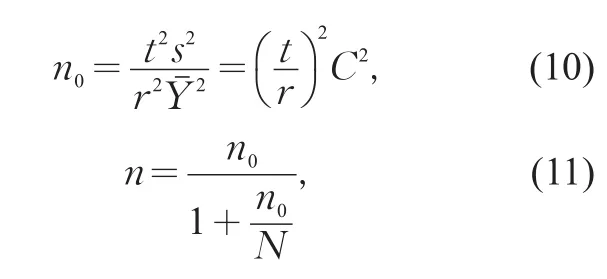
式中:n為樣本量;n0為重復抽樣樣本量。可以計算得到樣本的允許相對誤差r相對于抽樣率f的公式為
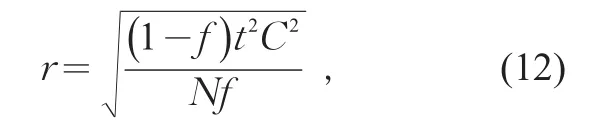
式中:t為對于一定置信度的百分位限值,當置信度為95%時t=1.96;s為總體標準差;為總體均值;C為總體變異系數,
由上可知,調查成本與調查精度兩個指標衡量量綱不同,需要對兩個指標進行量綱統一化處理。本研究從成本角度出發,提出調查精度成本折算系數Cr,將調查精度轉換為成本進行分析。值得一提的是,在不同調查過程中實施者對成本和精度的關注度不同,借鑒多目標規劃求解中加權求和的基本思想:決策者和分析者事先交換意見,根據p個目標的重要程度不同,分別乘以一組權系數然后相加作為目標函數,將多目標規劃問題轉換為單目標規劃問題求解,即
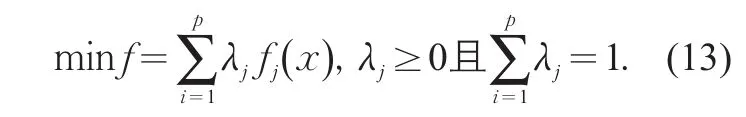
研究中根據具體調查情況,對調查成本和調查精度折算成本賦予權重。根據實際情況對二者的重視程度和限制要求賦予權重,兩權重之和為1。由此得到兩個指標的總成本與抽樣率的關系
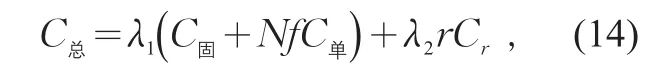
式中:λ1,λ2分別為調查成本和調查精度折算成本的權重,且λ1+λ2=1。當r=1時,即調查允許相對誤差為1,調查精度最差,則認為花費在此次調查中的變動成本全部無效;在調查線路的全部車輛時,成本最大,則Cr=NC單。那么,調查精度轉化的成本rCr越小,得到的調查精度越高。因此,計算合適的調查率,使得調查成本與調查精度達到均衡最優,即求得C總的最小值。對公式(14)關于f求導,令導數為零,即可得到合適的抽樣率取值。
2.2 抽樣車輛確定
通常情況下,公交客流量在一天中的不同時段有高有低,持卡乘客比例也不盡一致(如通勤時段乘客使用IC卡比例較高),但在所劃分的客流時段內具有一定的穩定性。因此,在獲得代表線路不同時段內的IC卡比例和客流特征后,可作為同類型中其他線路的參考值測算各條線路的公交客流量。車輛抽樣應遵循以下原則:確保抽樣車輛在一天內的班次盡可能多,并且運營班次覆蓋每一類客流時段。被選中車輛的首班發車時間定為抽樣調查開始時間。此外,為避免按照優化計算確定的抽樣車輛總量較少而不能覆蓋聚類后的時段,需適當增加抽樣車輛數量。
車輛抽樣方法包含四個步驟:
1)從調查成本和結果精度兩個角度出發,根據抽樣率計算公式,考慮實際情況賦予調查成本和調查精度相應的權重,計算得到調查的最佳抽樣率,并結合具體線路的車輛數,得到代表線路抽樣調查的樣本量(車輛數);
2)提前對公交線路的基本調度信息進行詳細梳理,了解所選調查日期的調度計劃安排,明確各運營車輛當天的運營班次總數及具體運營時間;
3)根據有序樣本聚類算法,利用代表線路歷史時期的IC卡數據,對該線路一天的客流時段進行聚類劃分;
4)比較該線路各運營車輛具體班次運營時間與聚類得到的公交客流時段,遵循車輛抽樣原則和計算所得抽樣車輛總量對車輛進行抽樣。
3 公交客流規模測算案例分析
3.1 數據來源
本文使用的IC卡數據均來自于上海市某轄區IC卡系統終端,日期為2011年10月1日—2012年9月30日以及2012年11月20日,研究時段為5:00—20:00。該區現有公共汽車運營企業兩家,公共汽車場站管理公司一家,停車場四家,公共汽車運營線路56條(包括市通郊線路14條、跨區線路10條、區內線路32條),運營車輛518輛,從業人員1 850余人,每車日均運營380 km,日均發送47班次。人工補充調查日期為2012年11月20日(星期二),補充調查日期的選擇充分考慮了代表線路的客流波動情況和天氣變化情況[11]。
3.2 相似線路聚類分析
利用SPSS18.0軟件對該區33條信息完整的公交線路進行聚類分析。設置最小聚類數為2,最大聚類數為4。聚類方法選擇Ward法(離差平方和法),轉換值標準化選擇按照個案Z得分,其余均選擇默認值。最終選擇將線路聚為三類:類型一發車間隔較小、線路相對擁擠;類型二屬于長距離線路、發車間隔中等;類型三屬于短距離、不擁擠線路,平均發車間隔較長(見表1)。此時每類線路特征較明顯且分類結果更加符合實際情況。
綜合考慮三種類型線路的屬性特征,各選取一條典型線路作為研究對象,分別為XN專線、SF專線和NQ7路,并以XN專線為例說明計算過程。
3.3 相似小時聚類分析
在線路相似小時聚類分析時,考慮到后續分析涉及逐小時的公交客流特征,所用數據應為每天每小時的完整數據。由于公共汽車在5:00前及20:00后客流量較少,且不是本研究重點關注的時段,因此選擇5:00—20:00作為研究時段。
以XN專線的IC卡刷卡記錄為基礎數據,由于人工補充調查日期是星期二,因此在剔除異樣數據后,取XN專線2011年10月1日—2012年9月30日期間所有星期二客流數據進行平均,以小時為單位進行統計,得到15個樣本數據(見圖1)。
為簡化計算,以每小時客流量占全天客流量的比值作為聚類屬性,得到有序聚類樣本:X={5.59,11.54,10.32,5.82,4.45,4.07,4.48,4.42,4.57,5.48,6.74,9.39,8.93,7.88,5.87}。采用Fisher算法,可以做出最小誤差函數e隨分段數k變化的曲線(見圖2)。曲線開始變平處對應的分段數為6,因此,將15個數據樣本分為6段較為適宜(見表2)。

表1 公交線路聚類結果Tab.1 Bus routes clustering
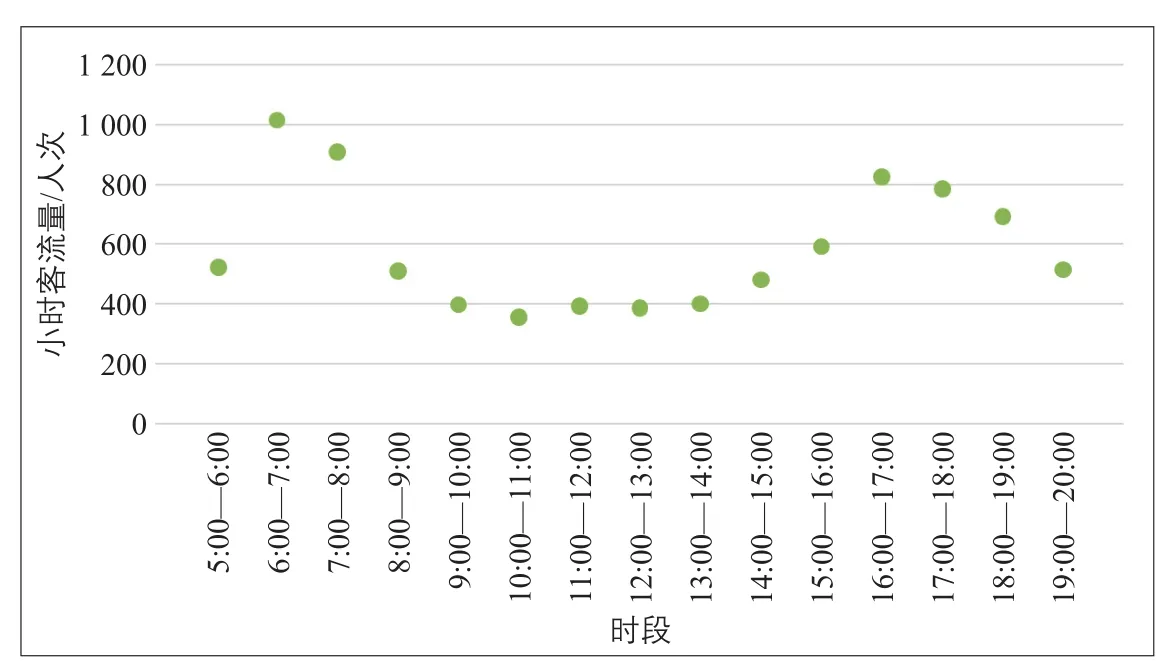
圖1 XN專線星期二小時客流量均值Fig.1 Average hour-flow of XN special line on Tuesday
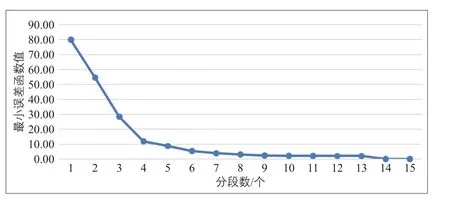
圖2 分段數k與最小誤差函數的關系Fig.2 Relationship between classification numberkand the minimum error function
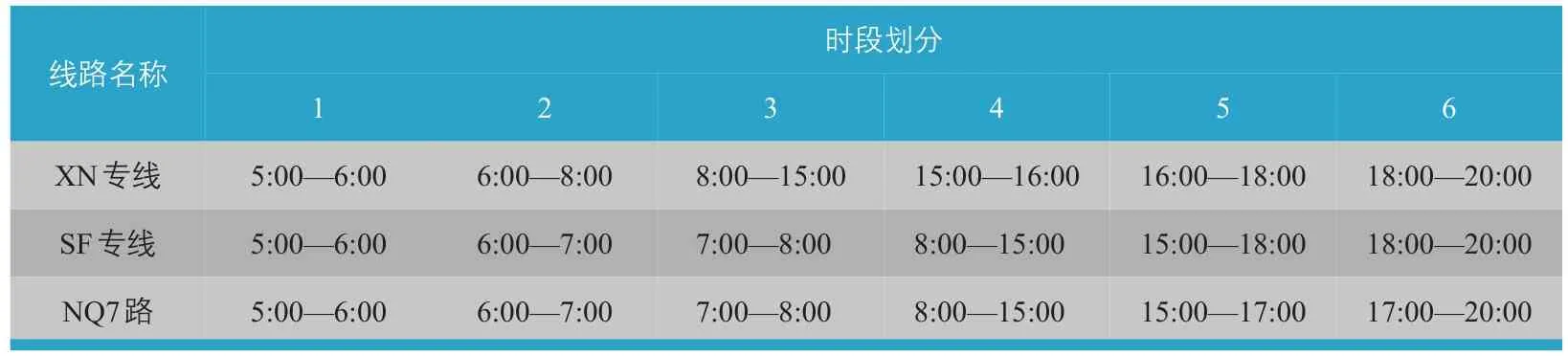
表2 研究線路時段劃分結果Tab.2 Time period classification of selected lines
3.4 抽樣率計算
XN專線實際運營車輛17輛,調查選擇95%的置信度,則t的取值為1.96。根據上海市歷史數據計算得到總體變異系數C為0.26。從總體調查角度看,平均每條線路固定成本為500元,單輛車的調查成本為800元,則線路的調查精度折算成本為13 600元。本次調查沒有明確強調成本、精度的重要性,故取λ1=λ2=0.5,據此可以得到線路不同抽樣率下調查成本變化情況(見圖3)。
在整個抽樣調查中,調查精度與樣本量在一定范圍內直接正相關(圖3中表現為調查精度折算成本與抽樣率負相關),然而,當樣本量超過一定值后,單位樣本量的增加對于精度的提高效果不再明顯(在抽樣率較高時,調查精度折算成本下降速度放緩)。
將線路數據代入公式(14),對抽樣率f求導,令導數為0,得到最佳抽樣率為17%。因此,XN專線應抽樣3輛車。采用類似方法,得到SF專線和NQ7路最佳抽樣率分別為16%和22%,抽樣量分別為3輛和2輛。
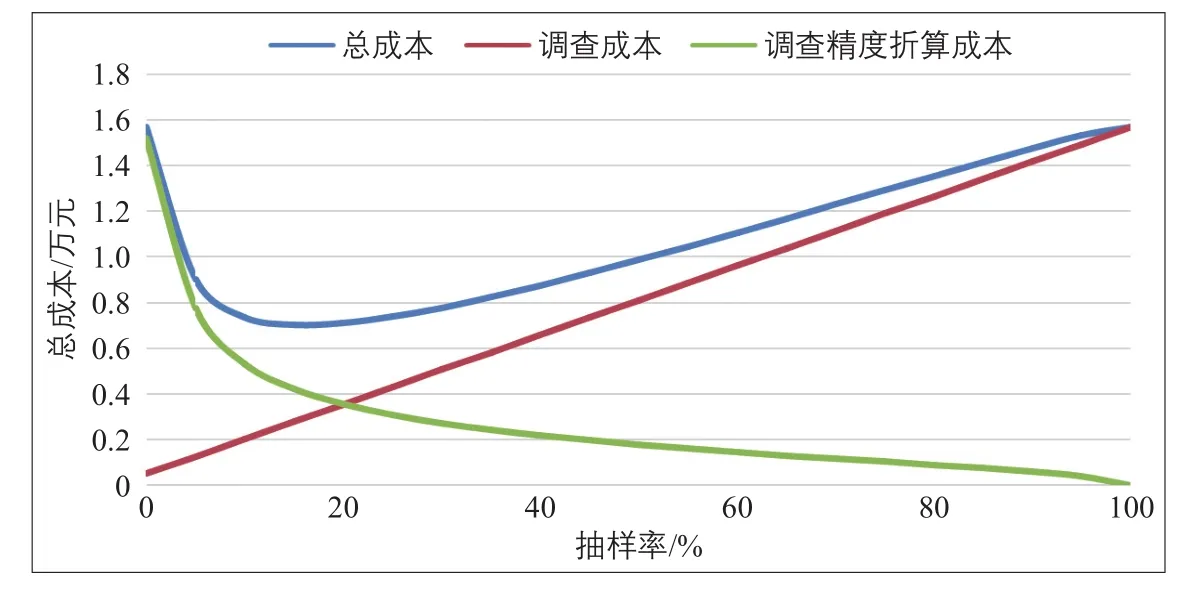
圖3 XN專線調查成本曲線Fig.3 Curve of investigation cost of XN special line
3.5 抽樣車輛確定
根據XN專線調度表可知,該線路首班車5:00從南橋汽車站發出,末班車22:35從莘莊地鐵站發出,全日共74班次,包括XN專線上行方向36班次,下行方向38班次。為保證所選車輛運行時間在上、下行兩個方向覆蓋各個客流時段,最終選取3號、7號及12號車作為調查對象(見圖4)。采用類似方法,得到SF專線調查開始時間依次為5:20,6:10及7:00;NQ7路調查開始時間依次為5:25和6:34。
3.6 日客流量測算
IC卡數據結構多樣,首先應篩選分析所需的四個字段:線路代碼、設備代碼、交易發生日期及交易發生時刻。然后根據線路代碼對照表篩選出調查線路,根據設備代碼對照表篩選出調查車輛。如果沒有設備代碼對照表,可根據跟車調查記錄的到站時間匹配相同時間的刷卡記錄,在整條數據中即可查詢對應的設備代碼。將三組人工補充調查數據按時間進行加和匯總,將整合后的上客數及刷卡人數統計表格轉化為以30 min為單位的統計表,根據客流時段劃分結果將IC卡數據比例分別取平均值,得到各客流時段IC卡刷卡量占客流總量的比例(見表3)。
顯然,IC卡比例在不同類型線路間以及各個時間段內均有很大差異。總體而言,類型三線路(以NQ7路為代表)的持卡比例整體較高,主要因為類型三線路基本均為區內線路,線路長度較短,乘客類型同質性較強。分時段對比,類型一線路(以XN專線為代表)在早晚高峰時段的持卡比例明顯高于其他時段,主要因為類型一線路發車間隔較小,線路相對擁擠,屬于典型的通勤線路;類型二線路(以SF專線為代表)屬于跨區線路,距離長,發車間隔長,因此在9:00—16:00的非高峰時段持卡比例最高,與居民進出市中心的情況比較吻合。
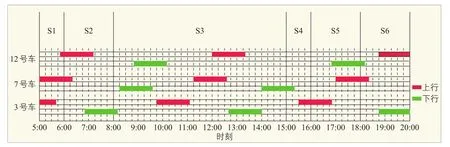
圖4 XN專線調查車輛運營時間對應的研究時段Fig.4 Time periods corresponding to operational time of surveyed vehicles of XN special line
使用MySQL軟件中的SQL語句編寫該線路客流總量的代碼,將人工補充調查日期當天的IC卡數據導入程序內,經過擴樣運算得到各線路的日均客流量(見表4)。
4 結語
本文基于調查成本與調查精度的綜合考慮,在對不同線路IC卡流量特征的觀測基礎上,提出采用通過聚類分析獲取補充調查的代表線路,并基于代表線路客流時段特征的差異,采用Fisher算法對代表線路的調查時段進行劃分,從而對同一線路獲取多個時段的IC卡數據擴樣系數,并將之應用于同類型其他線路的IC卡客流擴樣,從而獲得公交日客流量。這對于城市公共交通規劃和公交補貼政策的執行具有一定的參考價值,也在實際過程中得到很好的應用。此外,補充調查日期的選取非常關鍵,目前一般的方法是基于經驗。本研究采用的補充調查日期嚴格考慮了客流波動情況和天氣影響情況,盡量選擇能夠代表客流年日均值的時間進行調查[11],這是進行公交客流規模測算時需要注意的方面。
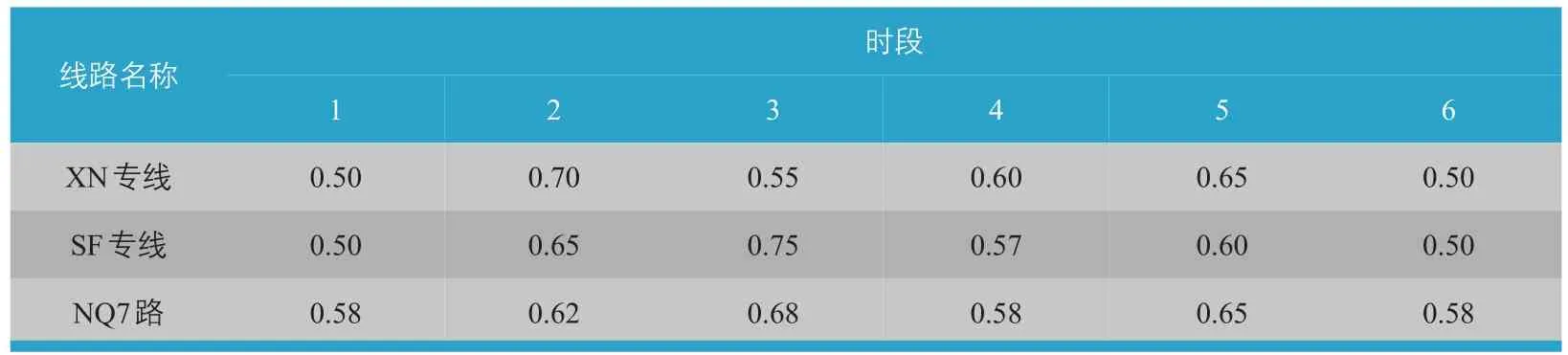
表3 研究線路各時段IC卡比例Tab.3 IC card using rate of selected lines in each time period

表4 各線路類型客流總量統計結果Tab.4 Total volume for each type of bus lines人次·d-1
[1]陳學武,戴霄,陳茜.公交IC卡信息采集、分析與應用研究[J].土木工程學報,2004,37(2):105-110.Chen Xuewu,Dai Xiao,Chen Qian.Approach on the Information Collection,Analysis and Application of Bus Intelligent Card[J].China Civil Engineering Journal,2004,37(2):105-110.
[2]陳紹輝,陳艷艷,賴見輝.基于GPS與IC卡數據的公交站點匹配方法[J].公路交通科技,2012,29(5):102-108.Chen Shaohui,Chen Yanyan,Lai Jianhui.An Approach on Station ID and Trade Record Match Based on GPS and IC Card Data[J].Journal of Highway and Transportation Research and Development,2012,29(5):102-108.
[3]Barry J,Newhouser R,Rahbee A,et al.Origin and Destination Estimation in New York City with Automated Fare System Data[J].Transportation Research Record,2002,1817(02-1045):183-187.
[4]郭婕.公交IC卡通勤乘客OD確定方法研究[D].南京:東南大學,2006.Guo Jie.The Method of Determining the OD of Bus IC Commuter[D].Nanjing:Southeast University,2006.
[5]陳君.基于IC卡數據的城市公共交通需求分析理論與方法[D].上海:同濟大學,2009.Chen Jun.Research on the Travel Demand AnalysisofUrban PublicTransportation Based on Smart Card Data[D].Shanghai:Tongji University,2009.
[6]Chu K A,Chapleau R.Enriching Archived Smart Card Transaction Data for Transit Demand Modeling[J].Transportation Research Record,2008,2063:63-72.
[7]Chu K A,Chapleau R,Trépanier M.Driver-as-sisted Bus Interview:Passive Transit Travel Survey with Smart Card Automatic Fare Collection System and Applications[J].Transportation Research Record,2009,45(2105):1-10.
[8]Trepanier M,Morency C,Blanchette C.Enhancing Household TravelSurveysUsing Smart Card Data[C]//Transportation Research Board.Transportation Research Board 88th Meeting Compendium of Papers DVD.Washington DC:Transportation Research Board,2009(09-1229):1-15.
[9]陳學武,戴霄,楊敏.先進的公交出行數據采集分析方法[C]//交通系統工程與智能交通運輸系統及智慧城市研究組.2005年海峽兩岸智能交通運輸系統學術研討會暨第二屆同舟交通論壇.智能交通運輸系統研究與實踐.上海:同濟大學,2005:595-603.
[10]戴霄.基于公交IC信息的公交數據分析方法研究[D].南京:東南大學,2006.Dai Xiao.Approach on the Information Analysis of Urban Public Traffic Base on the Data of Bus Intelligent Card[D].Nanjing:Southeast University,2006.
[11]王婧.公交客流調查與數據分析方法研究[D].上海:同濟大學,2015.Wang Jing.Research on Methods of Bus Ridership Survey and Data Analysis[D].Shanghai:Tongji University,2015.
[12]姜平,石琴,陳無畏,張衛華.公交客流預測的神經網絡模型[J].武漢理工大學學報(交通科學與工程版),2009,33(3):414-417.Jiang Ping,Shi Qin,Chen Wuwei,Zhang Weihua.ForecastofPassengerVolume Based on Neutral Network[J].Journal of Wuhan University of Technology(Transportation Science&Engineering),2009,33(3):414-417.
[13]方開泰.有序樣品的一些聚類方法[J].應用數學學報,1982,5(1):94-101.Fang Kaitai.Some Clustering Methods for the Order Sample[J].Acta Mathematicae Applicatae Sinica,1982,5(1):94-101.
[14]Fisher W D.On Grouping for Maximum Homogeneity[J].Journal of the American StatisticalAssociation,1958,53(284):789-798.
Passenger Volume Estimation Based on Data Fusion
Li Linbo1,Jiang Yu1,Wang Jing2,Wu Bing1
(1.The Key Laboratory of Road and Traffic Engineering of the Ministry of Education,Tongji University,Shanghai 201804,China;2.Ji'nan City Planning and Design Institute,Ji'nan Shandong 250101,China)
Accurate passenger flow estimation through surveys does not come without costs.This paper proposes a data fusion method based on the data from public transit IC card and supplementary surveys to accurately estimate passenger flow information.This paper first divides bus service routes into groups by their characteristics using cluster analysis method,and then selects one representative route from each group.Based on the temporary variation of bus passenger flow extracted from IC cards data,the paper categorizes IC card charging records per hour using Fisher algorithm of ordered sample cluster.By grouping time periods with similar IC card charging volumes,the paper determines the optimized sample rate and corresponding buses for the supplementary surveys.Consequently,bus passenger flows are estimated by data fusion method.Taking one district in Shanghai as an example,the paper demonstrates how to estimates daily passenger volumes of three types of bus routes using the above method.
public transit;passenger volume;cluster analysis;data fusion;public transit IC card;Shanghai
1672-5328(2016)01-0043-08
U491.1+7
A
10.13813/j.cn11-5141/u.2016.0107
2015-09-15
國家自然科學基金面上項目“基于出行服務鏈的城鎮群交通模式發展研究”(51178346)
李林波(1974—),男,湖南岳陽人,副教授,主要研究方向:交通規劃與管理。
E-mail:llinbo@tongji.edu.cn
猜你喜歡
廈門大學學報(哲學社會科學版)(2022年5期)2022-10-11 01:22:46
中國化肥信息(2021年6期)2021-08-21 02:42:16
河南電力(2021年5期)2021-05-29 02:10:00
電影(2018年12期)2018-12-23 02:18:48
特別健康(2018年2期)2018-06-29 06:13:42
領導決策信息(2017年10期)2017-05-17 04:49:02
風能(2015年9期)2015-02-27 10:15:24
私人飛機(2013年10期)2013-12-31 00:00:00
俄羅斯問題研究(2012年1期)2012-03-25 09:54:48
互聯網周刊(2009年14期)2009-08-04 09:37:06
