大數據分類挖掘算法及其概念漂移應用研究*
2016-12-19 01:12:23陸莉莉張永潘談海宇季一木
計算機與生活 2016年12期
陸莉莉,張永潘,談海宇,季一木
1.南京信息職業技術學院 計算機與軟件學院,南京 210023
2.南京郵電大學 計算機學院,南京 210023
大數據分類挖掘算法及其概念漂移應用研究*
陸莉莉1+,張永潘2,談海宇2,季一木2
1.南京信息職業技術學院 計算機與軟件學院,南京 210023
2.南京郵電大學 計算機學院,南京 210023
LU Lili,ZHANG Yongpan,TAN Haiyu,et al.Research on classification algorithm and concept drift based on big data.Journal of Frontiers of Computer Science and Technology,2016,10(12):1683-1692.
隨著大數據應用研究的不斷深入和分布式機器學習中流計算框架的涌現,針對數據流中概念漂移問題的研究是面向大數據挖掘領域的研究熱點之一。現有的針對概念漂移的研究成果主要還是依賴于數據結構和算法優化,通過計算資源有限的獨立計算機完成概念漂移的檢測。為此,提出一種面向大數據的基于Storm的抵抗概念漂移的分類挖掘算法S-CVFDT(Storm-concept very fast decision tree)及系統。該系統采用并行化窗口和S-CVFDT算法,利用并行化窗口機制檢測數據流中的突變型概念漂移,從而自適應地改變并行窗口大小,并通過S-CVFDT算法不斷更新漸進性概念漂移時的模型。分析與實驗結果表明,該算法可以快速有效地檢測到突變型概念漂移,降低系統因為突變型概念漂移造成的資源浪費,且模型建立效率、分類精度得到提高。
大數據;數據挖掘;分類算法;概念漂移
1 引言
隨著物聯網、社交網絡、云計算等技術不斷融入人們的生活,以及現有的計算能力、存儲空間、網絡帶寬的高速發展,人類積累的數據在互聯網、通信、金融、商業、醫療等諸多領域不斷地增長和累積[1]。互聯網搜索引擎支持的數十億次Web搜索每天處理數萬TB數據。全球主干通信網每天傳輸數萬TB數據。大型商場遍及世界各地的數以千計的門店每周都要處理數億交易。醫療行業每天的醫療記錄、病人資料和醫療圖像每天也都產生大量的數據。數據的爆炸式增長、廣泛可用和巨大數量使得真正的大數據時代到來。對于這些數據,人們不僅希望能夠從中提取出有價值的信息,更需要發現對決策提供有效支持的更深層次的規律。
大數據挖掘的目的就是為了從海量的實時數據中挖掘出隱含在其中的用戶感興趣的有價值信息,再將挖掘所得到的信息轉化成有組織的知識以模型等方式表示出來,最后將分析模型應用到現實生活中,從而提高效率,優化方案。大數據具有規模性(volume)、多樣性(variety)、高速性(velocity)和準確性(veracity)4個特點[2],其前期研究工作主要集中在規模性和多樣性上展開。目前廣泛存在并應用的數據是像金融、交通等場景下產生的流式數據,流式數據不同于傳統的靜態數據形態,作為一種新型大數據的數據形態,更多地體現了大數據要求的高速和準確的特點。流式數據需要人們從海量信息中更快地提取有用的信息。因此,基于大數據的實時數據挖掘研究顯得尤為重要。流式數據分為穩定數據流和動態數據流,穩定數據流[3]中的數據具有穩定獨立同分布的特點,而動態數據流是不獨立同分布的,因此會產生概念漂移。
分類是一種通過提取重要數據類模型從而進行數據分析的形式。分類挖掘算法作為一種有監督學習的算法,通過對已知類別的訓練集建立模型,從而預測新的數據集的類別,分類方法包括貝葉斯網絡、決策樹歸納、神經網絡等。分類挖掘算法廣泛應用在傳感器網絡、網絡入侵檢測、電話呼叫日志、銀行風險評估等場景中。這些場景下的數據往往隨著時間不斷產生,而且數據量大,數據模型可能發生變化[2]。如大型商場中顧客的購物傾向會隨著時間發生變化,網絡安全中對入侵檢測也隨著用戶不同而變化,工業生產中有問題的產品往往是相近的問題,然而共性的問題特征也是不斷變化的。社交網絡中用戶行為將隨著位置信息發生改變。
流式數據有數據量大,數據不斷產生,并且可能發生概念漂移3個特點。因此基于大數據的分類挖掘算法不僅需要對發生概念漂移的數據具有很高的靈敏度,并且需要對最新的數據盡早做出判斷,從而對模型進行自適應的調整。概念漂移是數據挖掘中一個需要重點研究的問題。目前的數據挖掘算法大多數都是針對靜態數據的,因此本質上都不具有抵抗流式數據概念漂移的能力。現有的數據挖掘系統不能實時更新數據,并且不能自適應計算模型,或者不能保持原本建立的模型[4]。
文獻[3]首次提出“概念漂移”的概念后,國內外的數據挖掘研究人員對概念漂移分別展開了深入研究。其中,文獻[5]通過時間序列分析方法,根據概念漂移發生的時間序列分為突變型概念漂移、漸變型概念漂移、重復型概念漂移、增量型概念漂移,并建立了滑動窗口和分類錯誤率的理論模型。文獻[6]提出了數據流分類挖掘算法,對數據的處理需要考慮有限內存、時間序列和單次處理的特點。文獻[7]根據環境變化引起的概念漂移將漂移分為虛漂移和實漂移。學術界在數據挖掘的抵抗概念漂移研究中,一方面通過改進單個分類器來解決數據概念漂移的問題,如文獻[8]的COBBIT、文獻[9]的CD3(concept drift)、文獻[10]的CVFDT;另一方面,研究人員通過集成分類器更新分類模型來提高分類精度和泛化能力。如文獻[11]提出的通過評估分類器精確度的閾值來不斷更新基分類器,從而不斷提高整體抵抗概念漂移的SEA(streaming ensemble algorithm)算法,缺點是該系統因為基分類器更新速度較慢,所以不適合突變性概念漂移。文獻[12]提出了對SEA改進的對基分類器設置權值的AWE算法。文獻[13]提出了一個能提高分類器反應速度的在線學習分類器ACE(adaptive classifiers-ensemble)算法。文獻[14-15]提出通過動態調整各基分類器的權值來提高分類性能。文獻[16-17]提出根據boosting算法思想,通過帶有權值的基分類器多數投票的機制,并動態增加投票精確度高的分類器,刪除投票精確度低的分類器來提高分類效果。文獻[18]研究了數據流中的樣本之間發生概念漂移的最大差值。文獻[19]通過利用Peano數據結構模型證明了決策樹分類方法適用于動態數據流。文獻[20]通過決策樹模型檢測數據子集,從而實現數據塊操作的模型。文獻[3]提出基于hoeffding樹的決策樹分類算法VFDT(very fast decision tree),該算法通過統計每個節點中樣本屬性的信息增益來選擇最佳分裂節點。對于數據流挖掘中概念漂移的研究,主要提出了評估數據集實時性權重和滑動窗口兩種策略。如文獻[21]提出根據樣本的生存時間,利用衰減函數來評估樣本的實時性的抵抗概念漂移策略,建模數據項的實時性要求根據其衰減函數來決定。文獻[22-24]提出利用可變的窗口盡可能地維持樣本,但是需要使用者提供未知的先驗參數,如概念漂移的時間尺度。在抵抗概念漂移的系統設計中,廣泛得到認可的系統有Last提出的OLIN(on line information network)[25]、Gama等人提出的UFFT(ultra fast forest of trees)[26]、Domingos等人提出的CVFDT[10]。
2 相關研究
2.1 OLIN
文獻[25]中Last提出了一種使用IFN(info-fuzzy network)網絡的在線分類系統,該系統又稱為OLIN,其根據動態數據流上的最新樣本建立滑動窗口。系統動態調整訓練樣本窗口的大小,并且根據概念漂移發生的頻率動態更新模型。OLIN系統將訓練樣本之間的概念漂移統計顯著性差異以及最新模型的預測準確率作為動態數據流是否發生概念漂移的標志。OLIN在重構模型過程中啟發式動態調整樣本數,如果概念未發生漂移,則增加當前模型建立所需的樣本。如果檢測到發生概念漂移,則減小窗口的大小,從而減少樣本。OLIN為每個新的滑動窗口建立一個新的模型。這個方法保證了隨著時間的推移,分類精度也能提高。但是OLIN算法有一個主要的缺點:生成新的模型時將產生很高的內存開銷,OLIN不考慮新的模型替代原有模型的開銷。
2.2 UFFT
Gama等人提出極速算法UFFT[26]。UFFT是基于二叉樹森林的有監督的分類學習算法。UFFT是增量式且在恒定時間內處理每個樣本,利用分析技術來選擇分裂標準處理連續數據流,通過信息增益評估每個可能分裂測試節點的好壞。對于多類的問題,算法為每一對可能相近的類建立一個二叉樹,從而構造一個樹的森林。UFFT算法在樣本訓練期間保持一個暫時的內存,保證給定數據流中有限的最新樣本固定時間內保存在數據結構中來支持插入和刪除。當測試節點一旦建立,葉子節點就變成帶有兩個子葉子節點的決策節點。通過短期內存中的樣本量初始化每個葉子節點的統計信息。UFFT算法在決策樹的每個節點上保持一個樸素貝葉斯分類器。通過樣本統計值建立的分類器在變成葉子節點時需要根據分裂準則評估其是否符合分裂要求。葉節點變成決策節點后遍歷節點的所有樣本,將通過樸素貝葉斯分類器進行分類。概念漂移探測方法最基本的思想是控制錯誤率。如果未發生概念漂移,樸素貝葉斯分類器的錯誤率會降低。發生概念漂移后,樸素貝葉斯的錯誤率將上升。當探測到給定節點的分類錯誤顯著上升時,表明現有的分裂節點不再合適。原來節點下的子樹將被修剪并重新變為葉子節點并重新初始化。

Table 1 Difference of VFDT and CVFDT表1 VFDT和CVFDT的異同點
2.3CVFDT
Hulten等人提出擴展VFDT的概念漂移自適應快速決策樹算法CVFDT[10],VFDT算法和CVFDT算法的異同點如表1所示。
表1中,m為VFDT中決策樹的節點個數;N為CVFDT中決策樹和替代子樹的節點個數;d為屬性個數;V為每個屬性值的最大值;C為類的個數。
CVFDT根據滑動窗口中的數據流樣本來持續檢測舊的決策樹的有效性,從而保證建立模型與概念漂移同步。當發現數據流發生概念漂移時,將以細粒度的方式更新它們。特別是每次選擇最佳屬性時都為每個候選屬性保留足夠的統計樣本時間。當新的樣本加入到窗口時,從屬性統計值中減去舊的樣本數的統計值。每當有Δn個新的樣本進入時,CVFDT在原先每個決策點重新決定最佳候選屬性。如果候選屬性中有一個比原先的決策屬性要好,則表明原先的決策不正確或者概念發生漂移。不管是原先的分裂屬性不正確,還是概念發生漂移,都會在繼續原先屬性分裂的同時,新的屬性開始尋找分裂屬性。在不斷的樹增長過程中,新的決策屬性產生時就相應地產生其替代子樹。通過周期性地使用新的樣本作為驗證集來比較新的決策樹和舊的決策樹的分類效果。如果新的決策樹模型比舊的模型更準確,CVFDT修剪舊樹(用新的替代子樹替換)。當新的決策樹模型在最大數量的檢驗樣本集檢驗下分類效果仍不如舊的決策樹模型,那么建立的新的決策樹模型也會被修剪。如果不只一個新的決策樹模型,那么將會修剪分類效果最差的那個。CVFDT算法過程包括CVFDTGrow過程、ForgetExample過程、Remove Example過程和CheckSplitValidity過程。
3 基于Storm的S-CVFDT抵抗概念漂移算法
基于Storm的S-CVFDT抵抗概念漂移算法如圖1所示,并行化窗口bwin根據數據流中的概念漂移自適應調整窗口大小。當并行化窗口檢測數據流未發生概念漂移時,則增大窗口中的樣本量,有利于快速建立分類模型。當并行化窗口檢測數據流發生概念漂移時,則減小并行化窗口的大小,有利于較快地適應概念漂移。基于Storm的S-CVFDT算法的建樹過程在每個決策節點建立替代子樹,通過CheckSplit-Validity檢測替代子樹的準確率,當替代子樹的準確率高于舊的子樹,則替換之。通過維持一個滑動窗口,不斷拋棄舊的樣本,添加新的樣本,不斷更新分類樹模型。基于大數據的流數據中主要包含突變式概念漂移和漸變式概念漂移,當數據流具有突變式概念漂移特點時,將需要頻繁調用CVFDT算法中的檢測替代子樹準確率模塊,從而增加了內存消耗,降低了分類決策樹的建立模型效率。而S-CVFDT算法通過并行化窗口bwin,將能夠自適應地根據數據流中的概念漂移,特別是突變型概念漂移來調整窗口的大小,從而有效解決系統針對突變型數據流時頻繁更新建樹模型,調用決策節點測試模塊和資源利用率等問題。
4 基于Storm的抵抗概念漂移系統S-CVFDT
4.1 抵抗數據流概念漂移系統模塊設計
面向大數據的數據挖掘算法中,為了使得模型能夠抵抗數據流發生的概念漂移,通常需要3個特點:(1)添加新的樣本、釋放舊的樣本的窗口;(2)探測數據流輸入端發生概念漂移的方法;(3)對輸入的最新樣本能夠不斷更新模型。抵抗數據流概念漂移系統通常包括3個模塊:樣本窗口模塊、探測概念漂移模塊和概念漂移評價模塊,如圖2所示。
①數據流分為子數據流stream1和子數據流stream2,分別添加到并行化窗口bwin1和bwin2中。
②概念漂移探測模塊根據概念漂移閾值判斷數據流是否發生概念漂移。
③如果發生概念漂移,則建模窗口控制模塊減小窗口的大小以抵抗概念漂移。如果未發生概念漂移,則增大窗口大小,提高建模效率。
④根據建模窗口中的樣本數據流建立決策樹模型。
⑤周期性地比較決策樹模型中替代子樹和原有屬性節點的分類精度,如果替代子樹的精度高于原有子樹,則替換之。

Fig.1 Parallel window S-CVFDT algorithm to resist concept drift圖1 基于Storm的并行化窗口S-CVFDT抵抗概念漂移算法
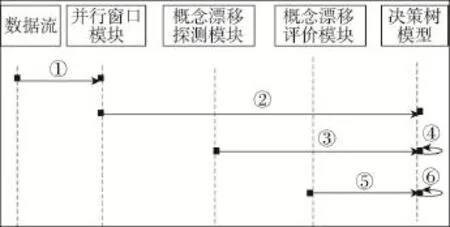
Fig.2 Frame of data mining for concept drift data stream圖2 流數據挖掘抵抗概念漂移框架圖
4.2 基于Storm的抵抗概念漂移并行化窗口bwin(bolt-window)
Storm是利用類MapReduce編程模型來處理流數據的分布式流計算框架。Storm主要用來對流數據進行實時分析。比如Twitter使用Storm來查找最新流行的話題和故事,利用對tweet博客查找結果的排序實現在線學習或者對廣告實時分析并生成內部日志。Storm相對于HadoopMapReduce的優點是其處理流數據的靈活性。實際上HadoopMapReduce在處理數據流時很復雜而且易錯。Storm提供了“至少一次”消息處理機制,且支持水平擴展。Storm因為沒有中間隊列,所以意味著操作開銷更少,更重要的是,Storm平臺的“justworks”機制保證了處理數據的容錯。Storm最基本的元素包括streams、spout、bolts和拓撲。Storm中的流實際上是元組的無限序列。元組是值的列表,每個值只要可以序列化,就可以賦值為任何類型。Storm是動態匹配類型,也就是說值的類型不需要聲明。spout是Storm的數據源,通常從如kestrel/kafka、http服務器日志或者Twitter流APIs這樣的外部數據源讀取數據。Storm中的bolt是一個或者多個輸入流的具體執行者。bolt能執行多個功能,如過濾元組、聚合元組、join多個數據流以及和外部件通信(如緩存或數據庫)。Storm在spout和bolt之間利用拉取方式傳遞元組,bolt從源件(bolt或者spout)拉取元組進行處理。這個特性可以保證當拓撲系統不能實時處理外部事件時,元組的丟失只會發生在spout。Storm中spout、bolt和流組成拓撲的是一個有向無環圖。
基于Storm的并行化窗口探測概念漂移模塊如圖3所示,將數據流分為子數據流stream1和子數據流stream2,分別添加到并行化窗口bwin1和bwin2中。通過檢測概念漂移窗口算法的bolt,來檢測數據流是否發生概念漂移,并將結果傳遞到結果bolt中。
4.3 基于Storm的并行化系統S-CVFDT
基于Storm的并行化系統S-CVFDT由并行窗口模塊、概念漂移探測模塊、S-CVFDT建樹模塊以及模型評價模塊組成,如圖4所示。數據流通過spout從外部數據源讀入。概念漂移探測模塊由并行窗口bolt和漂移探測bolt組成,其中根據并行化窗口算法通過探測bolt將控制信息返回到并行窗口模塊中,從而自適應調整并行化窗口的大小。S-CVFDT采用垂直并行設計。垂直并行更適合于具有很多屬性的實例,因為它把大部分的時間開銷用在每個屬性的信息增益的計算上。相比于水平并行,它占用更少的內存,因為它不需要在每一個bolt復制模型。建樹模塊的第一個bolt負責接收并行化窗口的數據,并將數據流傳遞到分發bolt;分發bolt將統計信息分發到每一個獨立計算bolt,并且計算信息增益;最后將聚集獨立bolt的統計信息得到最終的決策樹。由于原有的CVFDT算法在樣本具有大量屬性的情況下,在屬性增益的計算中耗費大量計算資源,從而降低建樹效率,S-CVFDT算法建樹模塊部分主要將Storm的分布式和并行化的流數據處理方式應用于系統中,用戶通過設置獨立bolt的個數處理樣本屬性,從而調整系統并行度,提高建樹效率。

Fig.3 Detection module for concept drift based on Storm by parallel window圖3 基于Storm的并行化窗口探測概念漂移模塊

Fig.4 Parallel system S-CVFDT for concept drift based on Storm圖4 基于Storm的并行化系統S-CVFDT
5 實驗仿真與驗證
5.1 基于Storm的S-CVFDT分類挖掘系統
基于Storm的流分類挖掘系統,既解決了由于傳統的流數據挖掘單機系統不能實現分布式計算信息熵從而提高效率的問題,同時通過并行化窗口的方案有效地抵抗了由于數據流概念漂移導致的模型準確率下降,系統資源消耗過高等問題。
基于Storm的S-CVFDT整體系統框架如圖5所示。

Fig.5 S-CVFDT system frame based on Storm圖5 基于Storm的S-CVFDT整體系統框架圖
(1)對帶有標簽屬性的流式數據樣本集進行有監督的學習,實現增量建樹,并實時監控概念漂移,形成不斷更新的分類決策樹模型,以內存數據庫Redis作為消息中間件保存不斷更新的決策樹模型。
(2)從Redis中取出實時決策樹模型,并利用數據流中的測試樣本集來測試決策樹模型的準確率。
(3)從Redis中取出符合準確率要求的決策樹模型對未知標簽的樣本數據流進行預測分析,并輸出分類結果。
5.2 S-CVFDT算法系統拓撲設計
基于Storm的抵抗概念漂移流分類挖掘算法并行化拓撲的構建過程如下:
(1)創建基于Storm的由spout和bolt組成的流分類分布式計算拓撲,設置噴發節點spout和計算節點bolt的邏輯關系。
(2)配置拓撲數據源和數據處理節點,設置數據計算節點并發數以及隨機的數據分發處理方式。
(3)設置DSourceSpout讀取數據源數據,并將數據源的屬性信息發送給ReadAttBolt,數據源屬性管理模塊ReadAttBolt提取數據源中的屬性,數據源的屬性值信息發送給概念漂移探測模塊BwinDetector-Bolt。
(4)BwinDetectorBolt接受DSourceSpout的數據源信息,探測是否發生概念漂移,從而控制窗口window Size,當數據流速率過高時,可以增加并發數來提高探測效率。
(5)S-CVFDTBolt初始化窗口W、各項參數和初始的決策樹模型,并將模型及各項參數發送給CheckingSplitNodeBolt。
(6)Att_midBolt接受ReadAttBolt提取數據源中的屬性,計算數據流樣本中所有屬性的個數,并將每個屬性打上標簽,分發給CheckingSplitNodeBolt。
(7)因為基于數據流的流分類挖掘算法中樣本的屬性增益將是系統資源消耗的絕大部分,所以通過垂直并行化來計算屬性熵增益。CheckingSplitNode-Bolt根據數據源樣本的屬性個數設置并發數,計算結果保存在Map<key,value>中,其中key代表是哪個屬性,value代表該屬性的信息增益值,將計算結果發送給ChooseMaxBolt。
(8)ChooseMaxBolt對Map中的所有屬性對應的value值進行排序,找出最大和次大的<key,value>即可確定決策節點進行分裂。
(9)更新決策樹,并將最新的決策樹模型寫入到Redis中。
(10)同時建立測試和分類拓撲,并通過拓撲中的EvaSpout分發測試數據源,DataSpout分發分類數據源,并分別從Redis中取出最新決策樹分類模型到classifyBolt中進行評估和分類。
5.3 系統的實現與分析
假設n為決策樹和替代子樹節點的個數,d為樣本屬性的個數,v為屬性值的最大個數,c為類的個數,則CVFDT算法的復雜度為O(ndvc)。因為CVFDT算法系統除了要存儲決策樹的數據結構以外,還包括處理樣本的存儲空間,假設樣本的大小為e,窗口的大小為w,所以CVFDT系統實際的空間復雜度為O(ndvc+we)。而因為S-CVFDT算法的窗口是自適應指數調整的,所以其空間復雜度是O(ndvc+elogw)。當數據流數據量很大時,空間復雜度呈指數減小。
概念漂移廣泛存在現實數據流中,數據流決策樹分類算法CVFDT能夠很好地解決概念漂移問題,但是因為其設計處理概念漂移機制時并不考慮概念漂移的類型,只是采用普適的方法,從而效率較低。本文提出的基于分布式計算平臺Storm的并行窗口算法設計不僅能夠有效檢測數據流中的概念漂移,從而自適應改變窗口提高其建立模型的準確率,也通過分布式計算平臺強大的計算能力,從而減小屬性信息熵的計算時間,提高效率。
在分類算法研究中,分類器的性能評估是重要的一部分。在訓練樣本上有很高性能的分類器在測試樣本中未必能收到同樣的結果。本文采用的是在大部分數據挖掘評估中廣泛使用的十字交叉驗證法。誤差率在分類算法的分類器設計中是一個重要的評估指標。分類器對測試樣本進行預測,如果正確,則分類成功,否則分類錯誤。通過建立決策樹評價拓撲將測試樣本通過evalspout發送數據流到evalbolt進行評估,并輸出分類器的誤差率。以下選取在流分類挖掘實驗中使用較廣泛的概念漂移數據流Hyperplane[27]作為算法性能實驗的數據源,其通過逐漸改變連續樣本的決定邊界來實現增量的概念漂移數據流。Hyperplane通過改變每個樣本0.01的修正權重值來實現漂移。另外數據集包含5%的噪聲,噪聲通過人為對樣本加上錯誤的類標簽實現。Hyperplane包含10 000個樣本和10個維度。如圖6所示,當樣本數較少時,S-CVFDT算法決策樹模型的準確率和CVFDT算法準確率相差不大,但是S-CVFDT算法隨著樣本的增加,模型建立的準確率不斷提高。

Fig.6 Comparison of accuracy between CVFDT algorithm and S-CVFDT algorithm圖6 S-CVFDT算法與CVFDT算法準確率比較
由于S-CVFDT具有并行窗口抵抗漸進型概念漂移的機制,當數據流概念發生漂移時,可以發現SCVFDT算法的準確率雖然有所下降,但是能夠很快恢復,并且當樣本數越大時能保持比CVFDT較高的準確率,如圖7所示。
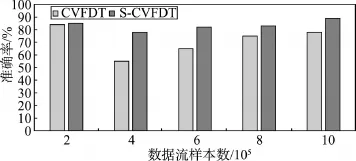
Fig.7 Comparison of accuracy between CVFDT algorithm and S-CVFDT algorithm based on concept drift圖7 S-CVFDT算法與CVFDT算法發生概念漂移時準確率比較
CVFDT算法單機情況下:每秒處理的待分類樣本數目在10 000~15 000條,而S-CVFDT算法基于分布式平臺Storm下每個分類拓撲每秒可處理的待分類樣本數目在20 000~30 000條,當分類樣本數量倍增時,可以增加分類處理bolt,從而提高分類效率。并且決策樹模型不斷從Redis中讀取更新最具實時性的分類模型,從而保證模型的準確率。
6 結束語
本文基于分布式計算平臺Storm提出了一種新的并行化窗口檢測和抵抗概念漂移的面向大數據的分類算法S-CVFDT,該算法利用并行化窗口中數據流分布的變化檢測突變型概念漂移,并通過垂直并行化改進CVFDT算法,從而實現模型的不斷更新和效率優化。實驗分析表明,與傳統單機檢測概念漂移和建立模型相比,S-CVFDT算法具有較優的概念漂移檢測能力和分類準確率。而與已有的概念漂移分類算法相比,S-CVFDT算法在分類正確率、抗噪性等方面表現優越。然而,該系統如何引入隨機森林決策投票機制,以及如何檢測數據流中的噪聲和誤報,以及分類拓撲并行化是下一步的研究目標和方向。
[1]Bryant R E,Katz R H,Lazowska E D.Big-data computing:creating revolutionary breakthroughs in commerce,science, and society[R/OL].AWhite Paper Prepared for the Computing Community Consortium Committee of the Computing Research Association(2008)[2016-06-17].http://cra.org/ccc/ resources/ccc-led-whitepapers/.
[2]Mitchell T M.Machine learning[M].New York:McGraw-Hill,1997.
[3]Domingos P,Hulten G.Mining high-speed data stream[C]// Proceedings of the 6th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining,Boston, USA,Aug 20-23,2000.New York:ACM,2000:71-80.
[4]Grossberg S.Nonlinear neural networks:principles,mechanisms and architecture[J].Neural Network,1988,1(1):17-61.
[5]Kuncheva L I.Classifier ensembles for changing environments[C]//LNCS 3077:Proceedings of the 5th Workshop on Multiple Classifier Systems,Cagliari,Italy,Jun 9-11,2004. Berlin,Heidelberg:Springer,2004:1-15.
[6]Gama J.A survey on learning from data streams:current and future trends[J].Progress in Artificial Intelligence,2012,1 (1):45-55.
[7]Widmer G,Kubat M.Effective learning in dynamic environments by explicit context tracking[C]//LNCS 667:Proceedings of the 6th European Conference on Machine Learning, Vienna,Austria,Apr 5-7,1993.Berlin,Heidelberg:Springer,1993:227-243.
[8]Kilander F,Jansson C.COBBIT—a control procedure for COBWEB in the presence of concept drift[C]//Proceedings of the 6th European Conference on Machine Learning,Helsinki,Finland,1993.Berlin,Heidelberg:Springer,1993: 244-261.
[9]Black M,Hickey R J.Maintaining the performance of a learned classifier under concept drift[J].Intelligent Data Analysis,1999,3(6):453-474.
[10]Hulten G,Spencer L,Domingos P.Mining time-changing data streams[C]//Proceedings of the 7th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining,San Francisco,USA,Aug 26-29,2001.New York: ACM,2001:97-106.
[11]Street W N,Kim Y S.A streaming ensemble algorithm (SEA)for large-scale classification[C]//Proceedings of the 7th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining,San Francisco,USA, Aug 26-29,2001.New York:ACM,2001:377-382.
[12]Wang Haixun,Fan Wei,Yu P S,etal.Mining concept-drifting data streams using ensemble classifiers[C]//Proceedings of the 9th International Conference on Knowledge Discovery and Data Mining,Washington,Aug 24-27,2003.New York: ACM,2003:226-235.
[13]Kyosuke N,Koichiro Y,Takashi O.ACE:adaptive classifiersensemble system for concept-drifting environments[C]// LNCS 3541:Proceedings of the 6th International Workshop on Multiple Classifier Systems,Seaside,USA,Jun 13-15, 2005.Berlin,Heidelberg:Springer,2005:176-185.
[14]Elwell R,Polikar R.Incremental learning of concept drift in nonstationary environments[J].IEEE Transactions on Neural Networks,2011,22(10):1517-1531.
[15]Muhlbaier M D,Polikar R.Multiple classifiers based incremental learning algorithm for learning in nonstationary environments[C]//Proceedings of the 2007 IEEE International Conference on Machine Learning and Cybernetics,Hong Kong,China,Aug 19-22,2007.Piscataway,USA:IEEE, 2007:3618-3623.
[16]Kolter J Z,Maloof M A.Dynamic weighted majority:a new ensemble method for tracking concept drift[C]//Proceedings of the 3rd IEEE International Conference on Data Mining,Melbourne,USA,Dec 19-22,2003.Washington: IEEE Computer Society,2003:123-130.
[17]Kolter J Z,Maloof M A.Using additive expert ensembles to cope with concept drift[C]//Proceedings of the 22nd International Conference on Machine Learning,Bonn,Germany, Aug 7-11,2005.New York:ACM,2005:449-456.
[18]Barve R D,Long P M.On the complexity of learning from drifting distributions[J].Information and Computation,1997, 138(2):170-193.
[19]Ding Qiang,Ding Qin,Perrizo W.Decision tree classification of spatial data streams using peano count trees[C]//Proceedings of the 2002 ACM Symposium on Applied Computing,Madrid,Spain,Mar 2002.New York:ACM,2002: 413-417.
[20]Ganti V,Gehrke J,Ramakrishnan R.Mining data streams under block evolution[J].ACM SIGKDD Explorations Newsletter,2002,3(2):1-10.
[21]Cohen E,Strauss M.Maintaining time-decaying stream aggregates[C]//Proceedings of the 22nd ACM SIGACT-SIGMOD-SIGART Symposium on Principles of Database Systems, San Diego,USA,Jun 9-12,2003.New York:ACM,2003: 223-233.
[22]Gama J,Medas P,Castillo G,et al.Learning with drift detection[C]//LNCS 3171:Advances in Artificial Intelligence, Proceedings of the 17th Brazilian Symposium on Artificial Intelligence,Sao Luis,Brazil,Sep 29-Oct 1,2004.Berlin, Heidelberg:Springer,2004:286-295.
[23]Klinkenberg R,Joachims T.Detecting concept drift with supportvector machines[C]//Proceedings of the 17th International Conference on Machine Learning,Stanford,USA, Jun 29-Jul 2,2000.San Francisco,USA:Morgan Kaufmann Publishers Inc,2000:487-494.
[24]Widmer G,Kubat M.Learning in the presence of concept drift and hidden contexts[J].Machine Learning,1996,23(1): 69-101.
[25]Last M.Online classification of nonstationary data streams [J].Intelligent DataAnalysis,2002,6(2):129-147.
[26]Gama J,Medas P,Rocha R.Forest trees for on-line data[C]// Proceedings of the 2004 ACM Symposium on Applied Computing,Nicosia,Cyprus,Mar 14-17,2004.New York: ACM,2004:632-636.
[27]Lin C H,Chi C Y,Wang Y H,et al.A fast hyperplane-based minimum-volume enclosing simplex algorithm for blind hyperspectral unmixing[J].IEEE Transactions on Signal Processing,2016,64(8):1946-1961.

LU Lili was born in 1978.She received the M.S.degree in computer software and theory from Nanjing University of Posts and Telecommunications in 2008.Now she is a lecturer at Nanjing College of Information Technology.Her research interests include cloud computing and big data,etc.
陸莉莉(1978—),女,江蘇南通人,2008年于南京郵電大學計算機軟件與理論專業獲得碩士學位,現為南京信息職業技術學院講師,主要研究領域為云計算,大數據等。

ZHANG Yongpan was born in 1994.He is an M.S.candidate at Nanjing University of Posts and Telecommunications.His research interest is data mining in big data.
張永潘(1994—),男,安徽宣城人,南京郵電大學碩士研究生,主要研究領域為大數據挖掘。

TAN Haiyu was born in 1987.He is an M.S.candidate at Nanjing University of Posts and Telecommunications.His research interest is data mining in big data.
談海宇(1987—),男,江蘇鹽城人,南京郵電大學碩士研究生,主要研究領域為大數據挖掘。

JI Yimu was born in 1978.He received the Ph.D.degree from Nanjing University of Posts and Telecommunications in 2008.Now he is a professor at Nanjing University of Posts and Telecommunications.His research interests include P2P network optimization,cloud computing security and stream data query in big data,etc.
季一木(1978—),男,安徽無為人,2008年于南京郵電大學通信與信息系統專業獲得博士學位,現為南京郵電大學教授,主要研究領域為P2P網絡優化,云計算安全,大數據流查詢挖掘等。
Research on ClassificationAlgorithm and Concept Drift Based on Big Data*
LU Lili1+,ZHANG Yongpan2,TAN Haiyu2,JI Yimu2
1.Institute of Computer&Software,Nanjing College of Information Technology,Nanjing 210023,China
2.School of Computer Science,Nanjing University of Posts and Telecommunications,Nanjing 210023,China
+Corresponding author:E-mail:lull@njcit.cn
With the deepening research of the application on big data and the emergence of more and more distributed computing framework,the research on concept drift in data stream becomes one of the research highlights in data mining for big data.The existing research on concept drift mainly depends on the data structure and algorithm optimization, the calculation mainly depends on the sole computer and limited resources to complete concept drift detection.Thus, this paper proposes a classification mining algorithm and system for big data based on Storm to resist concept drift. The S-CVFDT(Storm-concept very fast decision tree)algorithm system uses the parallel window mechanism to detect mutant concept drift in data stream and adaptively changes the parallel window size so as to update S-CVFDT algorithm model.The experimental analysis and results show that the algorithm can effectively detect mutant concept drift and lower the system resources waste.Not only the modeling is more efficient,but also the classification accuracy is improved.
big data;data mining;classification algorithm;concept drift
10.3778/j.issn.1673-9418.1608039
A
TP393
*The Youth Fund of Natural Science Foundation of Jiangsu Province under Grant No.BK20130876(江蘇省自然科學基金青年基金);the Research Foundation of Nanjing College of Information Technology under Grant No.YK20140402(南京信息職業技術學院科研基金).
Received 2016-08,Accepted 2016-10.
CNKI網絡優先出版:2016-10-19,http://www.cnki.net/kcms/detail/11.5602.TP.20161019.1458.006.html
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
現代裝飾(2022年1期)2022-04-19 13:47:32
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
現代裝飾(2020年2期)2020-03-03 13:37:44
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·高一版(2018年9期)2018-10-09 06:46:48
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
中學生數理化·高一版(2017年9期)2017-12-19 12:15:14
