一種樸素貝葉斯文本分類算法的分布并行實(shí)現(xiàn)
2016-12-26 08:36:52郭緒坤范冰冰
計(jì)算機(jī)應(yīng)用與軟件 2016年11期
郭緒坤 范冰冰
1(廣州體育學(xué)院 廣東 廣州 510500)2(華南師范大學(xué)計(jì)算機(jī)學(xué)院 廣東 廣州 510631)
?
一種樸素貝葉斯文本分類算法的分布并行實(shí)現(xiàn)
郭緒坤1范冰冰2
1(廣州體育學(xué)院 廣東 廣州 510500)2(華南師范大學(xué)計(jì)算機(jī)學(xué)院 廣東 廣州 510631)
針對當(dāng)前樸素貝葉斯文本分類算法在處理文本分類時(shí)存在的數(shù)據(jù)稀疏、分類不準(zhǔn)及效率低的問題,提出一種基于MapReduce的Dirichlet樸素貝葉斯文本分類算法。算法首先根據(jù)體征詞語義因素以及類內(nèi)分布情況對權(quán)重進(jìn)行加權(quán)調(diào)整,以此對的計(jì)算公式進(jìn)行修正;引入統(tǒng)計(jì)語言建模技術(shù)中的Dirichlet數(shù)據(jù)平滑方法來降低數(shù)據(jù)稀疏對分類性能的影響,并在Hadoop云計(jì)算平臺采用MapReduce編程模型實(shí)現(xiàn)本文算法的并行化。通過測試實(shí)驗(yàn)對比分析可知,該算法顯著提高了傳統(tǒng)樸素貝葉斯文本分類算法的準(zhǔn)確率、召回率,并具有優(yōu)良的可擴(kuò)展性和數(shù)據(jù)處理能力。
樸素貝葉斯 文本分類 TF-IDF修正 數(shù)據(jù)平滑 MapReduce并行化
0 引 言
隨著計(jì)算機(jī)技術(shù)的不斷發(fā)展,電子文檔特別是大數(shù)據(jù)成指數(shù)倍級增加,如何將大量文本以隸屬類別進(jìn)行有效分類并檢索成為數(shù)據(jù)挖掘與信息檢索領(lǐng)域的研究重點(diǎn)和熱點(diǎn)。主要的文本分類算法由樸素貝葉斯[1-3]、K近鄰[4]、神經(jīng)網(wǎng)絡(luò)[5]、支持向量機(jī)[6]、向量空間模型的Rocchio分類器[7]、最大熵[8]等。以貝葉斯概率理論為基礎(chǔ)基于統(tǒng)計(jì)的貝葉斯分類方法,假定文本特征獨(dú)立于類別,簡化了訓(xùn)練和分類過程計(jì)算,取得了令人滿意的分類效果,已成為文本分類中廣為使用的一種方法。文獻(xiàn)[9]提出了一種改進(jìn)的樸素貝葉斯分類方法,通過卡方檢驗(yàn)方法求文檔特征并降維,以文本特征來代替原始詞條進(jìn)行樸素貝葉斯分類;文獻(xiàn)[10]提出了基于特征相關(guān)的改進(jìn)加權(quán)樸素貝葉斯分類算法,算法考慮到特征項(xiàng)在類內(nèi)和類間的分布情況,并結(jié)合特征項(xiàng)間的相關(guān)度,調(diào)整權(quán)重計(jì)算值;文獻(xiàn)[11]提出了一種基于特征選擇權(quán)重的貝葉斯分類算法,采用卡方值和文檔頻數(shù)相結(jié)合的數(shù)值來表示特征詞的重要程度,以此獲得特征詞權(quán)重,建立加權(quán)貝葉斯分類器;文獻(xiàn)[12]對經(jīng)典樸素貝葉斯分類算法進(jìn)行了改進(jìn),提出了一種文本分類算法,提高了分類精度;文獻(xiàn)[13]提出了一種基于輔助特征詞的樸素貝葉斯文本分類算法,提高了類條件概率精確度。
以上算法在一定程度上提高了文本分類的性能,但也存在兩方面的局限:其一,文本分類過程中,語言中大部分詞都屬于低頻詞,容易造成數(shù)據(jù)稀疏問題;其二,由于其自身擴(kuò)展性和計(jì)算能力的限制,集中式平臺運(yùn)行傳統(tǒng)樸素貝葉斯文本分類算法時(shí),難以保證數(shù)據(jù)處理的高效性。為了解決以上兩個(gè)方面的問題,本文借鑒統(tǒng)計(jì)語言建模技術(shù)[8]中的數(shù)據(jù)平滑方法,提出一種基于Dirichlet樸素貝葉斯文本分類算法,同時(shí)采用MapReduce編程模型[9],在 Hadoop[10]云計(jì)算平臺上實(shí)現(xiàn)該算法的并行化。
1 樸素貝葉斯文本分類算法及改進(jìn)
1.1 樸素貝葉斯文本分類算法
樸素貝葉斯文本分類算法NB(Naive Bayes)是一種基于概率統(tǒng)計(jì)的學(xué)習(xí)方法。常用的模型為多變量伯努利模型和多項(xiàng)式模型。二者的計(jì)算粒度不一樣,多項(xiàng)式模型以單詞為粒度,伯努利模型以文件為粒度,因此二者的先驗(yàn)概率和類條件概率的計(jì)算方法都不同。計(jì)算后驗(yàn)概率時(shí),對于一個(gè)文檔d,多項(xiàng)式模型中,只有在d中出現(xiàn)過的單詞,才會參與后驗(yàn)概率計(jì)算,而伯努利模型中,沒有在d中出現(xiàn)但在全局出現(xiàn)的單詞,也會參與計(jì)算,不過是作為“反方”參與的。本文采用多項(xiàng)式模型[11]。
設(shè)文檔d由其所包含的特征詞d=(t1,t2,…,t|n|)表示,tk為特征詞,k=1,2,…,|n|,n是特征詞的集合,|n|為特征詞個(gè)數(shù)。同時(shí),集合C為目標(biāo)類別集合,C={C1,C2,…,Cm},Cj為類標(biāo)簽。根據(jù)貝葉斯公式,文檔d屬于類別Cj的概率為:
(1)
式中分母與類別無關(guān),故可將式(1)改為:
P(Cj|d)=P(Cj)P(d|Cj)
(2)
式中類先驗(yàn)概率P(Cj)和類條件概率P(d|Cj)都可以通過訓(xùn)練集學(xué)習(xí)獲得,一般用最大似然估計(jì)作為它們的估計(jì)值。P(Cj)可由式(3)估計(jì)得到:
(3)
式中Nj為類Cj的特征詞總數(shù),N為訓(xùn)練集的特征詞總數(shù)。
由于文檔d可由其所包含的特征詞表示,可將P(d|Cj)改寫為:
P(d|Cj)=P((t1,t2,…,t|n|)|Cj)
(4)
樸素貝葉斯假設(shè)特征詞ti和tj之間對類別的影響相互獨(dú)立,則式(4)可改寫為:
(5)
將式(5)代入式(2)中可得:
(6)
基于樸素貝葉斯獨(dú)立性假設(shè),將式(5)中文檔類條件概率轉(zhuǎn)換為求特征詞的類條件概率,特征詞的類條件概率P(tk|Cj)的計(jì)算式為:
(7)
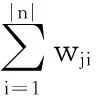
1.2 TF-IDF權(quán)重的改進(jìn)
特征詞的權(quán)重是計(jì)算向量相似度的關(guān)鍵,直接影響計(jì)算結(jié)果的準(zhǔn)確性,一般采用TF-IDF計(jì)算方法,其中,TF為特征詞頻率,反映特征詞在文本內(nèi)部的分布情況;IDF為特征詞的倒排文本頻率,反映了特征詞在整個(gè)文本集合的分布情況,TF-IDF將詞頻和反文檔頻率結(jié)合使用能基本體現(xiàn)特征詞的權(quán)重。但其并沒有考慮特征詞長度、在文本中位置以及類內(nèi)分布情況等對特征詞權(quán)重。本文根據(jù)體征詞語義因素以及類內(nèi)分布情況對權(quán)重進(jìn)行加權(quán)調(diào)整,以此修正TF-IDF的計(jì)算式。TF-IDF權(quán)重的計(jì)算式如下:
(8)
式中Wik為特征詞ti在文本dk中的TF-IDF權(quán)重,Numik為特征詞ti在文本dk中出現(xiàn)的次數(shù),N為文本數(shù),ni為出現(xiàn)特征詞ti的文本數(shù)。
1) 類別區(qū)分系數(shù)
一個(gè)特征詞的權(quán)重不僅僅由其在文本出現(xiàn)的頻率的決定,還體現(xiàn)與其對類別的區(qū)分能力。根據(jù)式(8)的TF-IDF權(quán)重計(jì)算,會存在兩個(gè)相等的特征詞t1、t2。若t1只出現(xiàn)在一個(gè)類別中,t2分散在多個(gè)類別中,很明顯t1對類別的區(qū)分度要強(qiáng)于t2,但僅兩者的TF-IDF權(quán)重是相等的。為了解決此種情形,本文引入類別區(qū)分系數(shù)α,表示類別Cj中包含特征詞ti的文本數(shù)與訓(xùn)練集中包含ti文本數(shù)的比值,比值越大,說明ti在類別Cj中出現(xiàn)的越頻繁,區(qū)分度越強(qiáng)。加入類別區(qū)分系數(shù)后,TF-IDF權(quán)重的計(jì)算式如下:
(9)
2) 位置權(quán)重系數(shù)
一段文字的首段往往重點(diǎn)點(diǎn)名題意,這些特殊的位置說明特征詞的權(quán)重受位置的影響。根據(jù)研究結(jié)果,本文設(shè)β為位置權(quán)重系數(shù),位置權(quán)重系數(shù)表如表1所示[18]。

表1 位置權(quán)重系數(shù)表
設(shè)Nti為特征詞ti出現(xiàn)在相應(yīng)位置的次數(shù),βti為特征詞ti的位置權(quán)重,加入位置權(quán)重系數(shù)后,TF-IDF權(quán)重的計(jì)算式如下:
(10)
3) 特征詞長度系數(shù)
詞語的長度也是影響特征詞權(quán)重的一個(gè)重要因素,詞語的長度越長,蘊(yùn)含的信息越多,出現(xiàn)的概率相對較低。由于長特征詞與短特征詞所包含語義的差別,本文引入特征詞長度系數(shù)δ加以區(qū)分。加入特征詞長度系數(shù)后,TF-IDF權(quán)重的計(jì)算式如下:
(11)
式中特征詞“新陳代謝”的長度系數(shù)δ為4。本文特征詞權(quán)重采用改進(jìn)后的TF-IDF算法進(jìn)行計(jì)算。樸素貝葉斯文本分類的目標(biāo)就是確定極大后驗(yàn)假設(shè)MAP,即求出文檔d最可能的類別值CMAP,表達(dá)式如下:
(12)
1.3 基于Dirichlet樸素貝葉斯文本分類算法
在自然語言語料庫中,特征詞出現(xiàn)的頻率Pt與其在頻率表中的排名ω之間有下列關(guān)系:
(13)
其中,K和σ都是常數(shù),K通常取值1,σ通常取值0.1。
如果詞表包含數(shù)十萬個(gè)詞,由式(13)可計(jì)算出其中排名前1000個(gè)最常用詞占各種文章全部詞的80%。計(jì)算過程如下:
=0.8=80%
上述計(jì)算過程表明,自然語言中的大多數(shù)詞出現(xiàn)的頻率都是稀疏的,并且無論怎樣擴(kuò)大訓(xùn)練詞庫,都無法保證所有詞的出現(xiàn)。因此,在式(12)中,由于存在數(shù)據(jù)稀疏問題,特征詞tk在類別Cj中可能出現(xiàn)零次,導(dǎo)致零概率問題。解決此問題的方法是采用Laplace平滑進(jìn)行估計(jì):
(14)
但是Laplace平滑方法會將所有沒出現(xiàn)詞的概率等同,這會導(dǎo)致未出現(xiàn)詞的概率過高,降低分類準(zhǔn)確率。本文將統(tǒng)計(jì)語言建模技術(shù)中的平滑方法應(yīng)用到樸素貝葉斯文本分類之中,以解決數(shù)據(jù)稀疏問題造成的概率失準(zhǔn)問題。
對任何句子S=(t1,t2,…,tk),可將其看作是具有以下概率值的馬爾科夫過程:
(15)
式中n為馬爾科夫過程的階數(shù)。n=1時(shí)為一元語言模型,單詞序列t1,t2,…,tn在文檔中出現(xiàn)的概率P(t1,t2,…,tn)=P(t1)P(t2)…P(tn),此時(shí)和樸素貝葉斯文本分類算法的獨(dú)立假設(shè)完全相同。由此,統(tǒng)計(jì)語言建模技術(shù)中的平滑方法也可適用于樸素貝葉斯文本分類算法中。基于此,本文引入了統(tǒng)計(jì)語言建模技術(shù)中的Dirichlet平滑方法代替Laplace平滑方法,提出了一種Dirichlit樸素貝葉斯文本分類算法DNB,改進(jìn)后特征詞的類條件概率P(tk|Cj):
(16)
式中ξ為調(diào)節(jié)分類性能的參數(shù),P(tk|C)表示tk在Cj中出現(xiàn)的預(yù)估概率。
2 算法的MapReduce并行化
2.1 文本預(yù)處理
文本預(yù)處理Job的工作流程:
(1) 辨析輸入詞語的相對路徑Path,然后將將其存放的目錄名作為類名Label;
(2) 利用中文分詞工具對文檔內(nèi)容進(jìn)行處理;
(3) 按照貝葉斯模型的要求形成輸入格式:每行一篇文檔,每篇文檔的格式為
2.2 文本向量化
文本向量化Job的工作流程:
(1) 讀取TD文件;
(2) 統(tǒng)計(jì)特征詞數(shù)目,生成文件WC;
(3) 讀取上一步生成的WC文件,給每個(gè)特征詞分配ID,生成文件Dictionary;
(4) 統(tǒng)計(jì)每個(gè)文檔中每個(gè)特征詞的詞頻TF,得到向量Vector_TF,生成文件TFVectors;
(5) 統(tǒng)計(jì)在所有文檔中每個(gè)特征詞出現(xiàn)的文檔頻率DF,生成文件DF-Count;
(6) 利用式(9)計(jì)算出每個(gè)特征詞的TF-IDF權(quán)重;
(7) 根據(jù)特征詞ti在文本dk中出現(xiàn)的次數(shù)Numik,在訓(xùn)練集中出現(xiàn)特征詞ti的文本數(shù)ni,在Cj中出現(xiàn)特征詞ti的文本數(shù)nj,統(tǒng)計(jì)特征詞ti的詞長及位置信息,對每個(gè)特征詞的TF-IDF權(quán)重進(jìn)行修正,得到Vector-TFIDF向量,生成文件TF-IDFVectors。
2.3 訓(xùn)練分類器
訓(xùn)練分類器Job的工作流程:
(1) 為類別建立索引,每個(gè)類別有對應(yīng)的ID,生成文件LabelIndex。
(2) 讀取文件TF-IDFVectors,累加相同類別文檔的向量Vector-TFIDF,計(jì)算出相同類別特征詞的權(quán)重之和TF-Num,得到Vector_TF-Num向量,生成文件TF-NumVectors。
(3) 讀取上一步得到的文件TF-NumVectors,累加所有類別的Vector_TF-Num向量,計(jì)算每個(gè)特征詞在所有類中的權(quán)重之和FNum,生成文件FNum-Count;累加每個(gè)類別所有特征詞的Vector_TF-Num向量,計(jì)算出每個(gè)類中所有特征詞的權(quán)重之和TNum,生成文件TNum-Count。
(4) 讀取文件TF-NumVectors、FNum-Count、FNum-Count,建一個(gè)行由所有類別構(gòu)成,列由所有特征詞構(gòu)成的二維矩陣Matrix-NaiveBayes,用TF-Num填充此矩陣,然后在Matrix-NaiveBayes的最后一行通過填充TNum增加一行,在最后一列填充FNum增加一列,從而構(gòu)造一個(gè)貝葉斯分類模型,生成文件NaiveBayes-Model。
2.4 測試分類器
測試分類器Job的工作流程:
(1) 讀取文件NaiveBayes-Model,建立NaiveBayes-Model對象。
(2) 在NaiveBayes-Model中取出相關(guān)參數(shù),根據(jù)式(16)計(jì)算特征詞的類條件概率,根據(jù)式(3)計(jì)算類先驗(yàn)概率,根據(jù)式(6)計(jì)算文檔對于所有類的后驗(yàn)概率PP,得到向量Vector_PP,生成文件Result
(3) 讀取文件Result,取最大后驗(yàn)概率對應(yīng)的類別為該輸入文檔的類別CMAP。
3 仿真實(shí)驗(yàn)與參數(shù)選擇
3.1 實(shí)驗(yàn)環(huán)境
仿真實(shí)驗(yàn)平臺由8節(jié)點(diǎn)組成的Hadoop集群,其中主節(jié)點(diǎn)1臺,其余為從節(jié)點(diǎn)。每個(gè)節(jié)點(diǎn)的配置如下:Intel Xeon E3-1231 CPU,16 GB內(nèi)存,1 TB硬盤,操作系統(tǒng)為CentOS 6.5,Hadoop版本選用1.2.1。
利用搜狗實(shí)驗(yàn)室提供的文本分類語料庫SogouC作為實(shí)驗(yàn)數(shù)據(jù)[19]。數(shù)據(jù)集包含12個(gè)類別,每個(gè)類別有10 000篇文檔,數(shù)據(jù)集大小約為107 MB。采用mmseg4j中文分詞器進(jìn)行分詞。
3.2 實(shí)驗(yàn)結(jié)果
實(shí)驗(yàn)采用準(zhǔn)確率P(Precision)和召回率R(Recall)來評估分類算法的性能[10],計(jì)算式如下:
(17)
(18)
式中TPj表示測試文檔集中正確分類到Cj的文檔數(shù),F(xiàn)Pj表示測試文檔集中錯(cuò)誤分類到類別Cj的文檔數(shù),F(xiàn)Nj表示測試文檔集中屬于類別Cj但被錯(cuò)誤分到其他類別中的文檔數(shù)。
3.3 本文算法的參數(shù)選擇
取70%的數(shù)據(jù)集作為訓(xùn)練集,其余30%作為測試集,選6個(gè)節(jié)點(diǎn)進(jìn)行測試實(shí)驗(yàn)。
參數(shù)ξ的取值為任意非負(fù)整數(shù),為了得到參數(shù)最佳的ξ,實(shí)驗(yàn)對ξ的取值從0開始以間隔1000為單位逐漸遞增。參數(shù)ξ的取值對Pj和Rj的影響,結(jié)果如圖1所示。
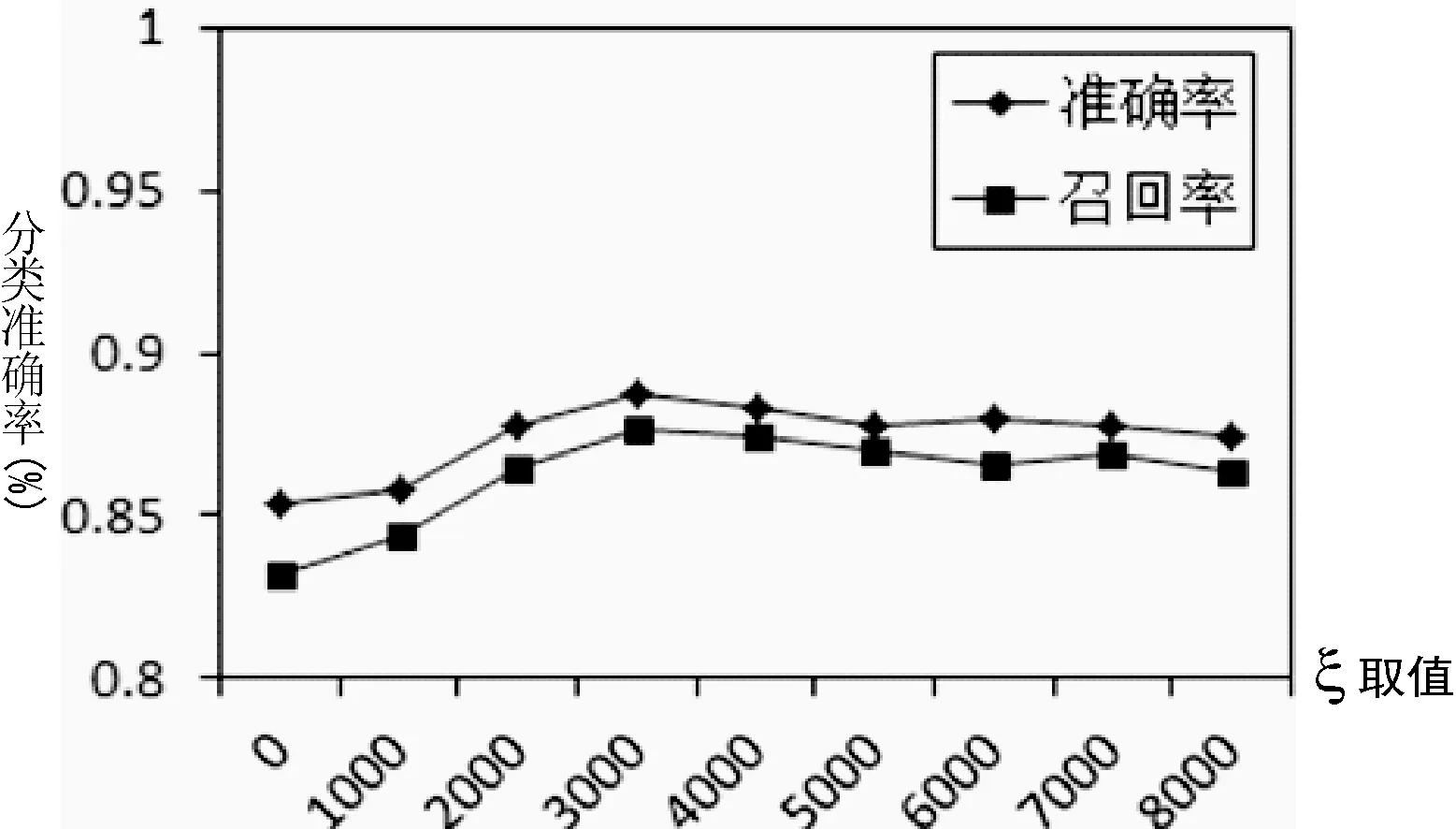
圖1 參數(shù)ξ的取值對準(zhǔn)確率,召回率的影響
從圖1的曲線圖可以看出,在參數(shù)ξ的值從0遞增到3000過程中,準(zhǔn)確率和召回率也在不斷增加,當(dāng)ξ取值在3000之后,準(zhǔn)確率和召回率隨著ξ的增加在緩慢減小,直至平穩(wěn)。當(dāng)取ξ為3000時(shí)準(zhǔn)確率和召回率最高,這里取ξ為3000。
4 實(shí)驗(yàn)結(jié)果分析
4.1 本文算法與樸素貝葉斯文本分類算法的性能對比
取70%的數(shù)據(jù)集作為訓(xùn)練集,其余30%的為測試集,選擇6個(gè)節(jié)點(diǎn)進(jìn)行測試實(shí)驗(yàn)。兩種算法準(zhǔn)確率和召回率的對比如圖2、圖3所示。
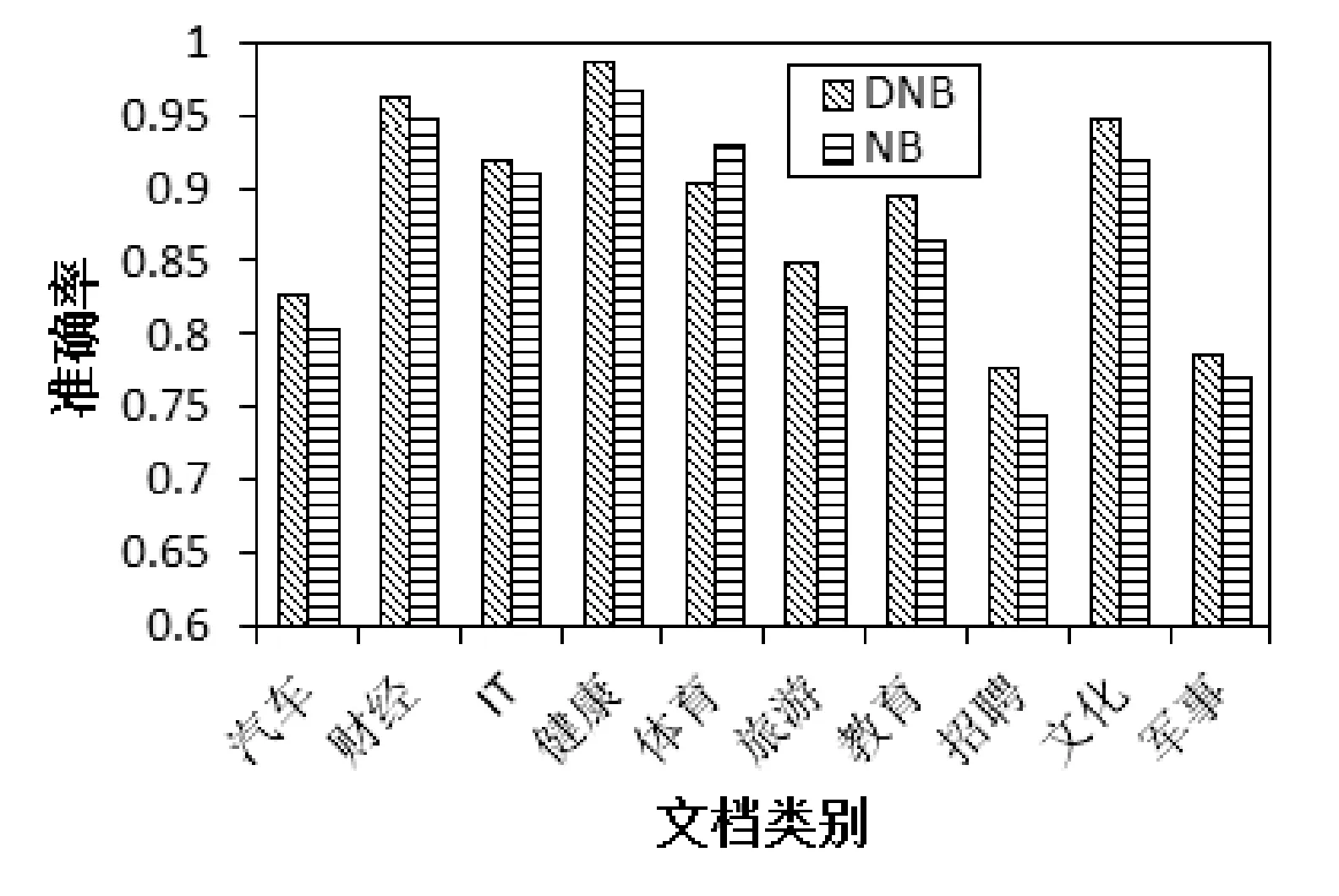
圖2 DNB與NB算法準(zhǔn)確率的對比
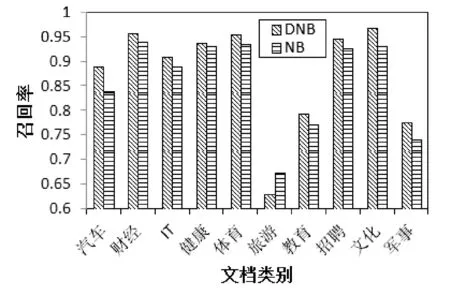
圖3 DNB與NB算法召回率的對比
從圖2、圖3我們可以看出,除個(gè)別類外,本文算法(DNB)的準(zhǔn)確率和召回率都優(yōu)于樸素貝葉斯文本分類算法(NB),從而說明經(jīng)過改進(jìn),本文算法提高了分類性能。
4.2 不同數(shù)據(jù)集對加速比的影響
對數(shù)據(jù)集進(jìn)行有返還抽樣,分別構(gòu)造150、250、450、850、1650 MB等5個(gè)大小不同的新數(shù)據(jù)集,然后分別從5個(gè)新數(shù)據(jù)集中取70%作為訓(xùn)練集,其余30%作為測試集,依次選擇1、5個(gè)節(jié)點(diǎn)進(jìn)行實(shí)驗(yàn)。實(shí)驗(yàn)結(jié)果見表2所示。
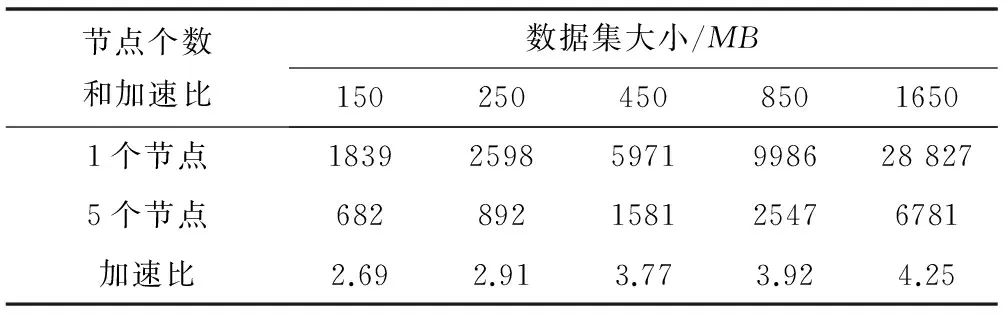
表2 不同數(shù)據(jù)集對加速比的影響
從表2可以看出,當(dāng)數(shù)據(jù)集較小時(shí),加速比[20]并不理想。這是由于數(shù)據(jù)集較小時(shí),節(jié)點(diǎn)間通信消耗的時(shí)間相對于處理數(shù)據(jù)時(shí)間還多,時(shí)間都耗在通信上。但隨著數(shù)據(jù)集的不斷增大,處理數(shù)據(jù)的時(shí)間大于節(jié)點(diǎn)間的通信時(shí)間消耗,加速比有了顯著提升。
4.3 不同節(jié)點(diǎn)數(shù)對運(yùn)行時(shí)間的影響
從1650 MB的數(shù)據(jù)集中取70%作為訓(xùn)練集,其余30%為測試集,從中選擇1、2、3、4、5個(gè)節(jié)點(diǎn)進(jìn)行測試。結(jié)果如圖4所示。
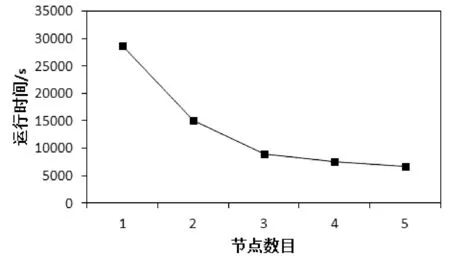
圖4 不同節(jié)點(diǎn)數(shù)對應(yīng)的運(yùn)行時(shí)間
從圖4我們可以看出,運(yùn)行時(shí)間隨節(jié)點(diǎn)數(shù)的增加而顯著減小,說明本文算法具有良好的擴(kuò)展性和高效性。
5 結(jié) 語
本文提出了一種基于MapReduce的Dirichlet樸素貝葉斯文本分類算法。為了提高樸素貝葉斯分類器的分類性能,本文根據(jù)體征詞語義因素以及類內(nèi)分布情況對權(quán)重進(jìn)行加權(quán)調(diào)整,以此修正TF-IDF的計(jì)算式,并引入統(tǒng)計(jì)語言建模技術(shù)中的數(shù)據(jù)平滑方法,以降低數(shù)據(jù)稀疏問題對分類性能的影響,同時(shí)基于MapReduce進(jìn)行并行計(jì)算,以提高分類算法對海量數(shù)據(jù)的處理能力。實(shí)驗(yàn)結(jié)果表明,本文算法相較于樸素貝葉斯文本分類算法有較高的準(zhǔn)確率和召回率,并具有優(yōu)良的可擴(kuò)展性和處理能力。
[1] Jyotishman Pathak.Text Classification Using A Naive Bayes Approach[D].Department of Computer Science Iowa State University.
[2] SangBum Kim,HaeChang Rim,DongSku Yook,et al.Effective Methods for Improving Naive Bayes Text Classifiers[C]//International Conforence on Prical:Trends in Artifical Intelligence,2002:479-484.
[3] Shen Yirong,Jiang Jing.Improving the Performance of Naive Bayes for Text Classification[C]//CS224N Spring,2003.
[4] Aynur Akkus,H Altay Guvenir.K Nearest Neighbor Classification on Feature Projections[D].Department of Computer Engr.and Info.Sei,Bilkent University,Ankara,Turkey,1998.
[5] Taeho Jo.Neuro Text Categorizer:A New Model of Neural Network for Text Categorization[C]//Proceedings of ICONIP,2000:280-285.
[6] Basu A,Watters C,Shepherd M.Support Vector Machines for Text Categorization[C]//Faculty of Computer Science Dalhousie University,Halifax,Nova Scotia,Canada B3H1W5,2003:103c.
[7] Thorsten Joachims.A probabilistic analysis of the Rocchio algorithm with TFIDF for text categorization[C]//Proceedings of ICML,1997:143-151.
[8] Nigam K.Using Maimum Entropy for Text Classification[C]//IJCAI-99 Workshop on Machine Learning for Information filtering,1999:61-67.
[9] 梁宏勝,徐建民,成岳鵬.一種改進(jìn)的樸素貝葉斯文本分類方法[J].河北大學(xué)學(xué)報(bào):自然科學(xué)版,2007,27(3):328-331.
[10] 饒麗麗,劉雄輝,張東站.基于特征相關(guān)的改進(jìn)加權(quán)樸素貝葉斯分類算法[J].廈門大學(xué)學(xué)報(bào):自然科學(xué)版,2012,51(4):682-685.
[11] 李艷姣,蔣同海.基于改進(jìn)權(quán)重貝葉斯的維文文本分類模型[J].計(jì)算機(jī)工程與設(shè)計(jì),2012,33(12):4726-4730.
[12] 邸鵬,段利國.一種新型樸素貝葉斯文本分類算法[J].數(shù)據(jù)采集與處理,2014,29(1):71-75.
[13] Zhang W,Gao F.An improvement to Naive Bayes for text classification[J].Procedia Engineering,2011,15(3):2160-2164.
[14] 丁國棟,白碩,王斌.文本檢索的統(tǒng)計(jì)語言建模方法綜述[J].計(jì)算機(jī)研究與發(fā)展,2015,43(5):769-776.
[15] Lee K H,Lee Y J,Choi H,et al.Parallel data processing with MapReduce:a survey[J].Sigmod Record,2012,40(4):11-20.
[16] ApacheHadoop.Hadoop[EB/OL].[2015-05-04].http://hadoop.apache.org.
[17] Puurula A.Combining modifications to multinomial naive bayes for text classification[M]//Information Retrieval Technology.Springer Berlin Heidelberg,2012:114-125.
[18] 裴頌文,吳百鋒.動(dòng)態(tài)自適應(yīng)特征權(quán)重的多類文本分類算法研究[J].計(jì)算機(jī)應(yīng)用研究,2011,28(11):4092-4096.
[19] 搜狗實(shí)驗(yàn)室.互聯(lián)網(wǎng)語料庫[EB/OL].[2016-01-02].http://www.sogou.com/labs/dl/c.html.
[20] Bauer R,Delling D,Wagner D.Experimental study of speed up techniques for timetable information systems[J].Networks,2011,57(1):38-52.
DISTRIBUTED PARALLEL IMPLEMENTATION OF A NAIVE BAYESIAN TEXT CLASSIFICATION ALGORITHM
Guo Xukun1Fan Bingbing2
1(Guangzhou Sport University,Guangzhou 510500,Guangdong,China)=2(College of Computer Science,South China Normal University,Guangzhou 510631,Guangdong,China)
According to the naive Bayes text classification algorithm in text classification of the existence of data sparse, inaccurate classification and low efficiency problem, this paper proposes a Dirichlet naive Bayes text classification algorithm based on MapReduce. Firstly, according to the words and signs within the meaning of the factors and the distribution of the weight classes is adjusted to be corrected on the TF-IDF; Then, we introduce Dirichlet data smoothing methods which in statistical language modeling techniques to reduce the impact on the classification performance of the sparse data, and we achieve this algorithm parallelization used by MapReduce programming model in the Hadoop cloud computing platform. Through experimental comparison analysis shows that the algorithm significantly improves accuracy and recall rate of traditional naive Bayes text classification algorithm, and it has excellent expansibility and data processing ability.
Naive bayes Text classification TF-IDF correction Data smoothing MapReduce parallelization
2016-01-28。廣東省教育廳2015重大科研立項(xiàng)青年項(xiàng)目。郭緒坤,講師,主研領(lǐng)域:文本分類與數(shù)據(jù)挖掘,計(jì)算機(jī)網(wǎng)絡(luò)。范冰冰,教授。
TP311
A
10.3969/j.issn.1000-386x.2016.11.056
猜你喜歡
數(shù)學(xué)小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
大眾健康(2021年6期)2021-06-08 19:30:06
甘肅教育(2020年8期)2020-06-11 06:10:02
制造技術(shù)與機(jī)床(2019年10期)2019-10-26 02:48:08
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2019年4期)2019-05-20 10:06:32
電子制作(2018年18期)2018-11-14 01:48:06
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
小學(xué)教學(xué)參考(2015年20期)2016-01-15 08:44:38
人間(2015年20期)2016-01-04 12:47:10
