基于證候要素的二階證實性因子分析在R語言lavaan包中的實現*
2017-01-09 13:43:46薛芳靜許碧云申春悌陳啟光陳炳為
中國衛生統計 2016年5期
黃 灝 薛芳靜 許碧云 申春悌 陳啟光 陳炳為△
基于證候要素的二階證實性因子分析在R語言lavaan包中的實現*
黃 灝1薛芳靜1許碧云2申春悌3陳啟光1陳炳為1△
目的探索高血壓陰虛夾濕證的證候要素,并介紹R語言lavaan包在結構方程模型中的應用。方法介紹lavaan包的語法,然后利用lavaan包中的二階證實性因子分析對1280例高血壓的陰虛夾濕證進行分析,以得到高血壓陰虛夾濕證的證候要素。結果陰虛夾濕證包含3個證候要素,病位主要在肝與腎、病性主要為虛與濕。結論利用R語言lavaan包實現結構方程模型是十分方便的。二階證實性因子分析方法可用于中醫證候分類及證候要素提取和命名。
lavaan包 二階證實性因子分析 證候要素
辨證論治是中醫學的精髓,證候是指內外環境變化所導致的機體病理生理整體反應狀態,是疾病發生和演變過程中某一階段病理本質的反映,它以一組相關的癥狀和體征為依據,從不同程度揭示出患者當前的病機綜合而成。證候要素是指組成“證候”本質的基本構成單位,是指組成證候的主要元素。本文利用二階證實性因子分析對中醫證候中的陰虛夾濕證進行證候要素分解[1]。
二階證實性因子分析屬于結構方程模型(structural equation model,SEM)的一種[2]。目前市場有很多軟件可用于擬合SEM模型,如R、LISREL、Mplus、EQS、Stata和AMOS等。其中R是一款免費的、開源的統計編程語言和計算環境[3]。R中有多個SEM的包,包括:lavaan、sem、lava和OpenMx[4]。目前使用較多的有lavaan包和sem包,本文以中醫證候要素的提取為實例介紹R語言lavaan包中結構方程模型的實現。借助R語言中lavaan包中的二階證實性因子分析對中醫證候中的陰虛夾濕證進行證候要素的分解。
結構方程模型及lavaan包簡介
1.結構方程模型簡介
在SEM中包括了兩種子模型,第一個為測量模型(measurementmodel),它是確定觀察變量與潛在變量之間關系;另一為結構模型(structuralmodel),是表示潛變量與潛變量之間關系的模型。它用公式表達如下:
測量模型:X=ΛXξ+δ與Y=Λyη+ε
結構模型:η=Bη+Γξ+ζ
其中ΛX是外生顯在變量(可觀測變量)X在外生潛在變量ξ上的因子載荷矩陣,ΛY是內生顯在變量Y在內生潛在變量η上因子載荷矩陣。δ、ε、ζ分別表示誤差[1]。下面以4個內生顯在變量及4個外生顯在變量,2個內生潛在變量及2個外生潛在變量來說明,其通徑關系如圖1。
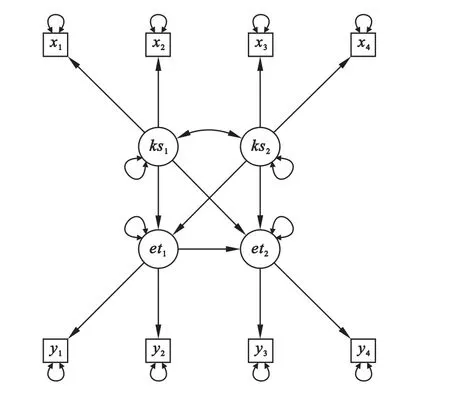
圖1 一個假設的結構方程的路徑圖
2.lavaan包簡介
對于R語言的lavaan包中需先對模型進行定義,在模型定義中主要用到一些符號與關鍵字,將其列出如表1。
在R語言中,首先需要安裝lavaan包,安裝程序如下:
install.packages(“lavaan”)#安裝lavaan包
library(“lavaan”)#調用lavaan包
lavaan包中結構方程模型的分析主要從以下幾步考慮:
(1)模型指定:以圖1的模型來說明,生成模型代碼(mymodel)如下:
mymodel<-′ks1=~x1+x2#ks1由變量x1與x2度量
ks2=~x3+x4#ks2由變量x3與x4度量
et1=~y1+y2#et1由變量y1與y2度量
et2=~y3+y4#et2由變量y3與y4度量
et1~ks1+ks2#ks1與ks2預測et1
et2~ks1+ks2+et1#ks1、ks2與et1預測et2
ks1~~ks2′#ks1與ks2相關
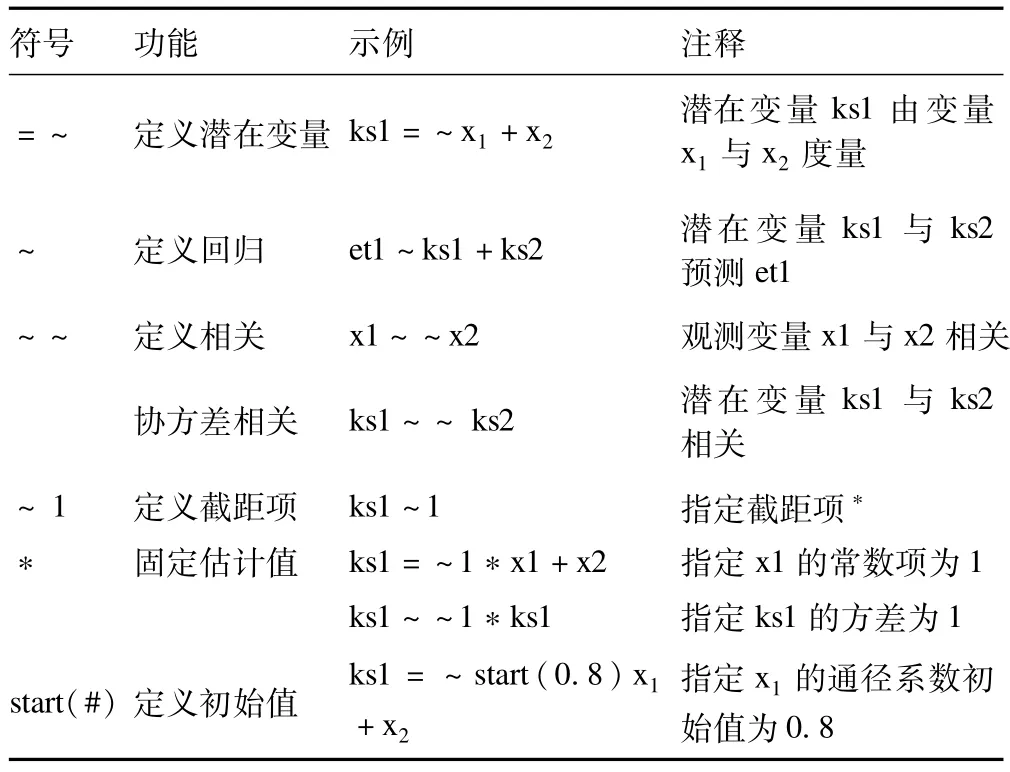
表1 R語言中lavaan包中主要命令
(2)模型運行:當完成結構方程模型設置后,可運行如下程序。
fit<-sem(model=,data=,meanstructure=,sample.nobs=,sample.mean=,sample.cov=,group=,bootstrap=,estimator=)
當模型為結構方程模型時,采用sem命令;當模型為證實性因子分析時,采用cfa或sem命令;當模型為潛在生長曲線模型時,采用grow th或sem命令。model用于指定模型名稱,如前面自定義的模型名稱為mymodel。對于結構方程模型一般考慮協方差矩陣來估計參數,但有些模型需要指定常數項,如潛在生長曲線模型,這時除了協方差矩陣外,還需要均數向量,這時模型的meanstructure指定TRUE,默認為不考慮均數向量。對于分析的數據有兩種格式,第一種是原始數據,則可用data選項,其中數據集為R語言的frame格式。如果數據形式為協方差矩陣時,則可用sample.nobs=樣本例數,sample.cov=樣本協方差矩陣的名稱(協方差的格式為下三角陣形式),sample.mean=樣本均數向量的名稱。如果模型中需要考慮多個組的結構方程模型,則選項group=組別變量名;如果需要進行bootstrap抽樣,則bootstrap=抽取的次數;estimator選項是指定模型估計的方法,對應的選項有ML、GLS、WLS、ULS、DWLS等,即采用最大似然估計、廣義最少二乘估計、加權最二乘估計、不加權最少二乘估計及對角線加權最少二乘估計等。R語言統計分析將結果都存在一個fit的對象(object)里面。
(3)結果輸出:
R語言在分析執行結束后并不顯示任何結果,但可以有選擇地從結果中提取感興趣的部分[5]。可以通過以下的命令來提取結果。
①summary(fit,standardized=,fit.measures=,rsquare=)
summary對模型擬合情況進行描述,給出模型擬合的卡方值、自由度和P值,同時給出統計量的方差。Standardized選項值為TRUE時輸出標準化回歸系數,否則默認不輸出。fit.measures=TRUE時輸出模型擬合的CFI、TLI、AIC、BIC、RMSEA及其95%可信區間、SRMR等擬合度的指數,默認時只輸出卡方、自由度及P值。rsquare=TRUE給出每個變量(可觀測變量及潛在變量)的復相關系數。
②modindices(fit,sort.=,minimum.value=,maximum.number=)
modindices給出模型的修正指數MI值,為模型修正提供依據。sort.=TRUE,按MI值從大到小排序,默認不進行排序。minimum.value=m,只保留MI≥m的修正結果,maximum.number=n,列出前n個較大MI值。
③fitMeasures(fit,“擬合指數名稱”)
fitMeasures函數計算了各種模型擬合的指數。默認給出所有的衡量指標,包括:CFI、TLI、GFI、AGFI、SRMR、RMSEA等。若只需要單個指標,只需要單個指標加入函數中即可,如fitMeasures(fit,“cfi”)。
④standardizedSolution(fit,type=)
standardizedSolution描述潛變量模型的標準化系數。type默認為“std.all”,即對顯變量和潛變量的分別進行標準化,若選項為“std.lv”,則只對模型中潛變量的進行標準化。因此,type大部分情況采用“std.all”的選項。
實例分析
資料來自2006年7月至2008年12月在常州、南京、沈陽和珠海四個地區五個三級甲等中醫院收集到的高血壓病例共計1280例。證候為陰虛夾濕的中醫四診信息有:目澀(x1)、耳鳴(x2)、目癢(x3)、目脹(x4)、耳聾(x5)、健忘(x6)、視物模糊(x7)、迎風流淚(x8)、足痛(x9)、尿后余瀝(x10)、小便不暢(x11)、便秘(x12)、小便清長(x13)、身重(x14)、口粘膩(x15)、夜間多尿(x16)、白苔(x17)、口咽干燥(x18)、浮腫(x19)、舌紫(x20)、四肢麻木(x21)指標,數據集稱為GHKX。
對于結構方程模型初始模型的建立有兩種方法,第一種方法是采用探索性因子分析來探索包含幾個因子;第二種方法是根據專業的知識構造初始模型。先采用因子分析得到陰虛夾濕包含三因子,并根據因子載荷系數構建二階證實性因子分析初始模型(mymodel):


構建初始模型后,采用cfa或sem命令對數據進行擬合:
fit<-cfa(mymodel,data=GHKX)
summary(fit,standardized=TRUE,fit.measures=TRUE)
modindices(fit,sort.=TRUE,minimum.value=10)
采用summary對結果進行輸出,得到部分擬合度指數、載荷系數、方差及協方差等。利用modindices列出模型的修正指數MI值,根據每一步的MI值大小,對模型進行調整。模型修正中x10與x11間的相關系數MI最大,其值為78.114,它是模型修正值。因此,在初始模型中加入“x10~~x11”重新擬合模型。如此循環反復,直到所有的MI值在5~10之間則停止修正,從而得到最終的模型。最終模型利用summary、fit-Measures與standardizedSolution得到擬合度、載荷系數及標準化系數。

表2 模型整體擬合度評價指標
模型擬合度中CFI、TLI、GFI、AGFI越大說明模型擬合越好[6]。Hu和Bentler(1998)推薦SRMR小于0.08認為模型可以接受[7]。RMSEA(近似誤差均方根)<0.05擬合好;0.08~0.10擬合一般;>0.10擬合不好。表2中x/df=1.596<3,CFI、TLI、GFI、AGFI均大于>0.90,SRMR與RMSEA均小于0.05,可見最終模型的擬合較好。
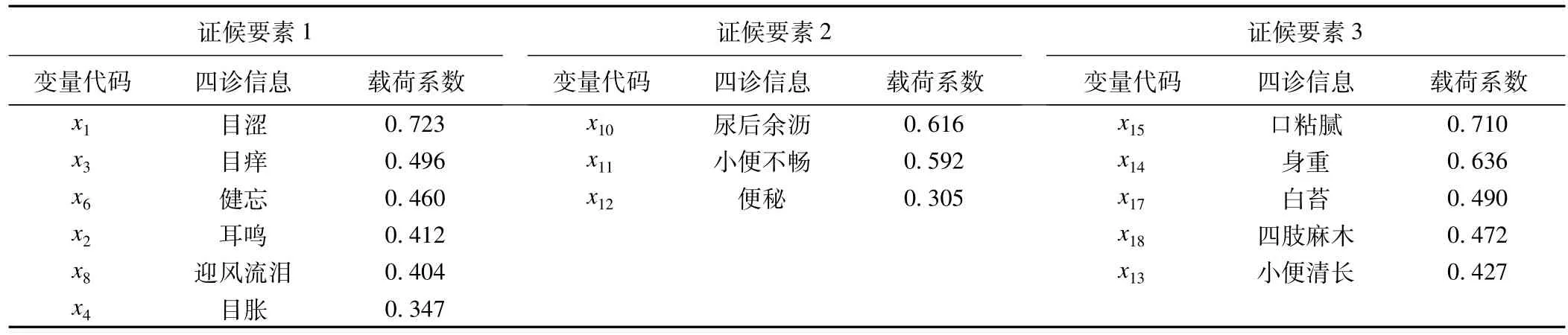
表3 二階證實性因子分析最終模型的標準化系數
結果分析可見,陰虛夾濕證包含3個證候要素,證候要素1包含6個指標,其中5個指標(目澀、目癢、健忘、耳鳴、迎風流淚)標準化系數高于0.4,證候要素1可以解釋為病位在肝,病性為氣虛;證候要素2包含3個指標,其中2個指標(尿后余瀝、小便不暢)標準化系數高于0.4,證候要素2可以解釋為病位在腎,病性為陰虛;證候要素3包含5個指標,標準化系數都高于0.4,證候要素3可以解釋為病性為濕。由此可見,陰虛夾濕證與篩選出的14個指標間有高度相關性,成功實現了中醫的證候要素的提取。
討 論
證候要素的提取便于中醫證候的命名,及中醫上的診療,因此將證候分解成中醫的證候要素有重要臨床意義。目前應用較多的實現潛在變量模型的軟件有LISREL、Mplus及AMOS,以上三個軟件均為商業版,R語言是一款免費的統計軟件包,在醫學研究中目前應用越來廣泛,每個軟件都有各自的優缺點。AMOS可以通過通徑圖來構建模型,也可通過程序,而R語言、LISREL、M plus是利用編程得到的。然而在模型修正時,選擇基于編程語言的軟件如R和LISREL比點擊式操作的軟件更具有系統性和便利性。
[1]陳炳為,陳啟光,許碧云.潛在變量模型及其在中醫證候中的應用概述.中國衛生統計,2009,26(5):535-538.
[2]Oberski DL.Lavaan survey:an R package for complex survey analysis of structural equation models.Journal of Statistical Software,2014,57(1):1-27.
[3]Fox J.Teacher′scorner:Structural equation modeling with the sempackage in R.Structural equation modeling:A Multidisciplinary Journal,2006,13(3):465-486.
[4]Song YE,Stein CM,Morris NJ.Strum:an R package for structural modeling of latent variables for general pedigrees.BMCgenetics,2015,16(1):1-2.
[5]湯銀才.R語言與統計分析.高等教育出版社,2008.
[6]秦浩,陳景武.結構方程模型原理及其應用注意事項.中國衛生統計,2009,23(4):367-369.
[7]侯杰泰,溫忠麟,成子娟.結構方程模型及其應用.北京:教育科學出版社,2004.
(責任編輯:鄧 妍)
國家自然科學基金(81273190)
1.東南大學公共衛生學院流行病與衛生統計系(210009)
2.南京大學醫學院附屬鼓樓醫院
3.南京中醫藥大學附屬常州中醫院
△通信作者:陳炳為,E-mail:drchenbw@126.com
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
哲學評論(2021年2期)2021-08-22 01:53:34
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
文苑(2020年4期)2020-05-30 12:35:30
中華詩詞(2019年7期)2019-11-25 01:43:04
小學生作文(中高年級適用)(2018年3期)2018-04-18 01:24:47
華北電力大學學報(社會科學版)(2016年4期)2016-12-01 03:59:30
影視與戲劇評論(2016年0期)2016-11-23 05:26:01
光學精密工程(2016年6期)2016-11-07 09:07:19
