視頻中目標檢測算法研究
2017-01-20 09:38:03張明軍俞文靜袁志黃志金
軟件 2016年4期
張明軍 俞文靜 袁志 黃志金

摘要:由于其實用價值和理論價值,目標檢測是智能視頻監控技術研究的重點,也是計算機視覺領域的一個研究熱點,引起了研究者廣泛關注。本文根據視頻圖像背景和前景目標的動或靜的情況進行分類,將目標檢測問題分為基于背景建模的目標檢測和基于目標建模的目標檢測兩類。對于每類問題,分別全面綜述了該問題的發展、常用算法模型及當前的研究成果等,然后討論了對各類算法模型的評測指標、評測數據集和評測結果,最后總結了當前這兩類目標檢測方法存在的不足以及給出了對未來發展的思考和展望。
關鍵詞:目標檢測;背景建模;目標建模;智能視頻監控
中圖分類號:TP391 文獻標識碼:A DOI:10.3969/j.issn.1003-6970.2016.04.011
0 前言
視頻監控是當前社會安防領域的重要組成部分,隨著監控攝像頭的快速增加,海量的監控視頻數據的處理便成了一個重大問題。隨著計算機視覺和人工智能的發展,智能視頻監控技術應運而生,就是為了解決海量視頻分析和處理的問題,并隨著社會對安全的重視,該技術也成了當前的研究熱點。目標檢測是從視頻或者圖像中提取出運動前景或感興趣目標,也就是確定當前時刻目標在當前幀的位置和所占大小。因此目標檢測是智能視頻監控技術的基礎,其性能的好壞直接影響了后續目標跟蹤、目標分類與目標識別等算法的性能。本文將對目標檢測的常見模型和方法進行分析和總結。
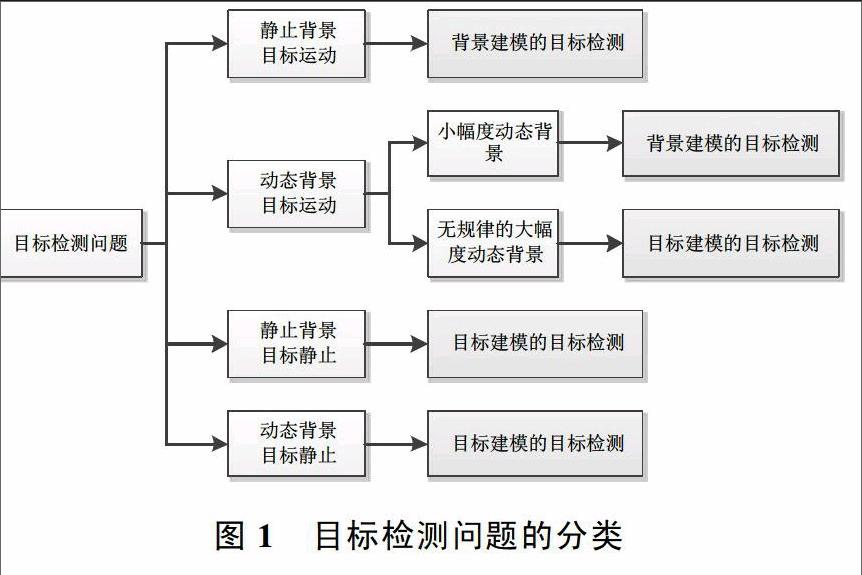
1 目標檢測問題的分類
從對象處理的過程來看,主要是從圖像的背景和前景目標進行處理,按照圖像背景和前景目標的不同情況可以將目標檢測分為幾類子問題,如圖1所示。解決這幾類問題的方法可以總結為2大類,分別是基于背景建模的方法和基于目標建模的方法。基于視頻的序列圖像中,人們對其中運動的物體會更感興趣,往往也包含主要信息,因此基于視頻的目標檢測主要是運動目標檢測,而這一類目標檢測則主要使用基于背景建模的方法。基于背景建模的方法不但要求目標要保持運動,并且要求背景盡可能保持不變(背景靜止),當背景發生變化時,則讓背景誤檢為目標,小幅度的背景變化尚可通過方法的改進加以修正,但大幅度的背景變化則讓該方法無能為力,基于目標建模的方法卻能解決這個問題。基于目標建模的方法不受應用場景的限制,不但可以對靜態場景視頻進行目標檢測,也可以檢測單幅靜態圖像或動態場景視頻中的目標。
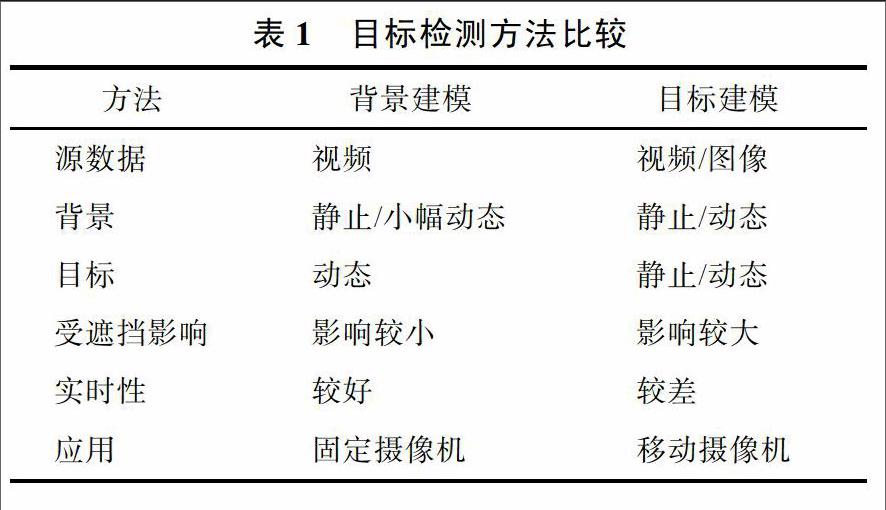
基于背景建模和目標建模的方法之間的比較如表1所示。
2 基于背景建模的目標檢測
2.1 幀間差分法
幀間差分法(Frame difference method)主要考慮相鄰視頻幀之間背景相對固定,而運動目標則有位置變化,那么相鄰幀進行相減,背景部分差值接近于0(理想狀態為0),而運動區域的差值則較大。設定一個閾值對背景進行過濾,則提取到運動目標。其數學模型如下:
(1)
(2)其中,It(x,y)It(x,y)表示t時刻像素點(x,y)的灰度值,It-1(x,y)表示t-1時刻像素點(x,y)的灰度值,Dt(x,y))為提取的運動目標的二值圖像,T為閾值。
二幀幀間差分法計算量小、實時性強,但檢測的目標不完整,存在“空洞”,位置不夠精確,在運動方向上目標被拉伸。為了改進二幀幀間差分法的不足,提出了三幀幀間差分法,其主要思想是對前后兩次差分圖像進行“與”操作。
2.2 背景減除法
背景減除法(Background subtraction method)是用當前幀與背景圖像或背景模型進行差分,對結果進行處理后得到運動目標區域。其數學模型如下:
(3)
(4)其中It(x,y)為視頻圖像序列中t時刻的圖像,Bt(x,y)為t時刻的背景圖像。式(4)為背景圖像的更新,其中α為背景更新率。對△It(x,y)進行閾值處理,可以得到運動目標區域的二值圖像Dt(x,y),同式(2)。
由上可知,只要背景不變化,背景減除法的目標檢測效果很好。但是,由于背景可能存在光照變化、背景擾動以及由于攝像機抖動導致的小幅度運動等影響,背景都會隨著時間而發生變化,所以怎樣定義背景和更新背景是該方法的難點和關鍵。研究者們提出了大量背景建模方法,如中值濾波、均值濾波、線性濾波、基于碼本的模型、非參數模型、隱馬爾科夫模型、Vibe方法、混合高斯模型(Gaussian Mixture Model,GMM)等。其中,GMM是目前普遍應用的一種背景建模方法。為了改善一些復雜場景的目標檢測效果,如去除“鬼影”和“陰影”等,研究者們對原有背景建模算法進行兩個方面的改進:一是對算法模型進行改進,以及多種算法結合并利用各自優勢進行優化;二是利用算法提取目標之后再對分割目標結果進行優化。
3 基于目標建模的目標檢測
3.1 滑動窗口策略的一般框架
基于目標建模的目標檢測一般采用滑動窗口的策略,即通過訓練好的模板在在圖像多個尺度上進行滑動窗口掃描,判斷各窗口是目標還是背景從而獲取目標。與背景建模的目標檢測不同的是,該方法不能提取目標輪廓,而是一個包圍目標的框。基于滑動窗口的目標檢測的一般框架如圖2所示。其中,特征抽取關系到目標檢測的可靠性和精度,而建立高效、準確、魯棒的目標表達模型及分類器則是窗口滑動策略的關鍵問題。
根據建模方法不同,基于滑動窗口的目標檢測主要分為全局剛性模板目標檢測模型、基于部件的目標檢測模型、基于視覺詞包的目標檢測模型和深度學習模型等。
3.2 全局剛性模板目標檢測模型
通過固定的窗口大小和特征對目標進行全局匹配,因此目標需要剛性不變,對形變目標則不能很好的進行檢測。典型的算法模型為Dalai和Triggs提出的HOG(HistogramsofOrientedGradients)模型。HOG是梯度方向直方圖特征,其核心思想是局部目標的外形能夠被光強梯度或邊緣方向密度分布所描述,通過將圖像劃分成小的連接單元(Cell),在每個Cell內部進行梯度方向統計得到直方圖描述。HOG整體檢測框架依然是以滑動窗口策略為基礎,并且使用線性分類器進行分類。
3.3 基于部件的目標檢測模型
基于部件的目標檢測模型(Part-Based Model,PBM)主要研究如何利用部件獲得目標的局部判別特征,能夠解決遮擋目標和多姿態目標等問題。該方法最早提出的模型是圖結構(Pictorial Structure),它使用一系列部件以及部件間的位置關系來表示目標。此后,在此基礎上先后提出了星座模型(ConstellationModel)、部件拼接模型(Patchwork of PartsModel)以及可形變部件模型(Deformable PartBased Model,DPBM)等。其中,DPBM在當前的目標檢測中具有重要的地位。DPBM主要由一個使用粗糙特征的全局模板和若干高分辨率(精細特征)的部件模板構成,還提出了隱支持向量機模型(Latent variable SVM),通過隱變量來建模物體部件的空間配置,并使用判別式方法進行訓練優化。
3.4 基于視覺詞包的目標檢測模型
視覺詞包(Bag-Of-Visual Words,BOVW)是一種圖像的中層特征描述,可以看作是對圖像低層視覺特征的聚合,通過利用圖像中包含的視覺單詞的統計或分布來表達圖像場景內容。BOVW是由Csurka等人于2004年首次將用于文本分類的詞包模型用于圖像物體分類而產生,由此出現了大量視覺詞包模型的研究,文獻對此進行了梳理和總結。基于視覺詞包的目標檢測則主要是通過訓練庫中的目標構建一個視覺詞包,然后對于給定的圖像抽取其局部特征,在視覺詞包上投票得到該圖像基于視覺詞包的特征表達,最后采用窗口滑動策略以及SVM分類來檢測目標。文獻提出基于詞包模型和顏色特征組合的食品區域檢測算法,文獻利用稀疏編碼的算法構建視覺詞包來定位高分辨率遙感圖像中的飛機目標。
3.5 基于深度學習的目標檢測模型
深度學習(Deep Learning)是近幾年的研究熱點,它通過多層神經網絡來抽象對數據的特征表達。一個典型的基于深度學習的目標檢測方法包括從輸入圖像上提取區域塊,用卷積神經網絡計算每個區域塊的特征,最后用線性SVM分類器對每個區域塊進行分類等步驟。文獻提出了基于R-CNN(Regions with Convolutional Neural Network)框架的目標檢測方法,文獻從利用貝葉斯優化的搜索算法以及懲罰CNN的不準確訓練兩個方面改進了基于深度CNN的目標檢測方法。
4 算法性能評測
4.1 算法評測指標
目標檢測算法評測通常采用查全率(Recall,R)和查準率(Precision,P)來評價算法的有效性。定義TP(True Positives)為正確檢測數,FP(FalsePositives)為誤檢數,FN(False Negatives)為漏檢數,則查全率和查準率如式(5)、(6)計算。
(5)
(6)
在算法評測上總是期望P值和R值越大越好,然而這兩個值往往會出現矛盾,因此就需要綜合考慮這兩個值,最常見的方法就是F-Measure。F-Measure是P和R的加權調和平均,如式(7)所示。
(7)當α=1時,則有式(8),即常見的F1。
(8)可知F1綜合了P和R的結果,當F1較高時則能說明目標檢測方法比較有效。此外,還有一種綜合P和R的評測指標,即平均查準率(Average Precision,AP)。在R曲線上進行均勻采樣得到相應的P值,將這些采樣得到的P值的求平均值作為AP值。
4.2 背景建模的目標檢測算法評測
眾多學者對背景建模的各種算法都進行了大量評測,最具代表性的評測則是Brutzer等人進行的。他們為了評測已有的背景建模方法在不同場景下的性能,人工合成了SABS(StuttgartArtificialBackgroundSubtraction)數據集,該數據集模擬了多種復雜場景,如動態背景、光線突變、噪聲干擾、低照度等。他們選取了9種有名的背景建模算法,并在此數據集上進行了性能評測,結果如表2所示。表中性能指標為F-Measure值。
對表2中9種算法的平均性能進行統計如圖3所示,可知不同復雜背景對目標檢測的影響較大,隨著場景復雜度的提升,算法性能下降較快。其中,光線變化、噪聲干擾對背景建模的運動目標檢測影響較大,而目標與背景表觀相似或目標偽裝、視頻編碼則對運動目標檢測影響較小。
4.3 目標建模的目標檢測算法評測
PASCAL VOC數據集是目標檢測領域目前公認的評測數據庫之一,該數據集的提出也相應的對目標檢測算法提出了巨大挑戰,促進了目標檢測算法的快速發展。從2007年開始,PASCAL VOC數據集類別數目固定為包括飛機(airplane)、自行車(bicycle)、鳥(bird)等20類,以后每年只增加部分樣本。PASCALVOC并組織了年度競賽,吸引了大量研究者使用該數據集評測所提出的算法。我們選取了4種目標檢測算法在PASCAL VOC 2007數據集上的評測結果如表3所示。表中性能指標為AP值,mAP(meanAP)為AP均值。
隨著大數據和硬件技術的快速發展,也使得在更大規模的數據庫上進行研究和評測成為必然。ImageNet便是一種大規模圖像數據庫,全庫截至2013年共有1400萬張圖像,2.2萬個類別,平均每類包含1000張圖像。除此之外,ImageNet還構建了一個包含1000類物體120萬圖像的子集,并以此作為ImageNet競賽的數據平臺,也逐漸成為計算機視覺相關算法評測的標準數據集。
5 總結及展望
基于視頻的兩類目標檢測方法可以解決目標檢測的不同子問題,正常情況下優勢明顯,但在特殊場景下也存在一些不足,如基于背景建模的目標檢測方法從復雜背景中提取前景目標則存在較大挑戰,基于目標建模的目標檢測針對不同的目標或場景則需要訓練不同的分類器,目標檢測耗時,難以滿足實時性等。這是因為這兩類目標檢測算法都是對中低層特征進行處理,容易受場景噪聲、目標和場景的狀態多變、目標類型多樣等影響。因此,研究者們依然在進行大量研究來提高算法的效率、精度和魯棒性,其研究的方向及發展趨勢主要表現在以下幾個方面:
(1)研究結合場景信息和目標狀態的分析方法,突破中低層特征的局限,構建特征提取新算子,提高算法的實用性。
(2)研究時域、空域、頻域信息,以及不同尺度空間特征信息的結合,綜合各種互補的信息,提高目標檢測的準確性。
(3)研究深度學習在目標檢測中存在的一些困難,如解釋性差、模型復雜、計算強度高等問題。深度學習無疑存在一些挑戰,但其天然的強大數據表達能力,無疑將會在大數據量的視頻中的目標檢測及其它視覺研究產生重要影響,也會將目標檢測等推向新的高度。
