一種改進的向量空間模型的文本表示算法
2017-02-09 02:09:21張小川于旭庭張宜浩
重慶理工大學學報(自然科學) 2017年1期
張小川,于旭庭,張宜浩
(重慶理工大學 計算機科學與工程學院, 重慶 400054)
一種改進的向量空間模型的文本表示算法
張小川,于旭庭,張宜浩
(重慶理工大學 計算機科學與工程學院, 重慶 400054)
文本表示是將可閱讀的文字轉換成計算機可識別的數據結構的過程,是文本信息處理領域中關注的基礎性問題。針對向量空間模型中文本表示的tf-idf算法僅考慮了詞項特征與文檔之間的關系,沒有考慮與類別關聯性的問題,引入數理統計卡方分布方法,以此改進了tf-idf算法,構成為新算法tf-idf-cθ。該算法將詞項的卡方分布值c作為文本表示的一個因子,用該c值來衡量詞項在文本類中分布的差異,并且引入詞性因子θ,得到改進向量空間模型的表示文本。對改進前后的2個算法進行文本分類實驗,結果表明:改進后的算法得到了提升,部分解決了詞項特征與類別的關聯性。
文本表示;向量空間模型;卡方分布;tf-idf
近年來互聯網時代方興未艾,國家也開始大力發展“互聯網+”,網上信息越來越豐富,其中許多都是文本信息。如何有效處理這些信息是文本挖掘、信息檢索等領域的研究熱點。
目前,大部分學者更關注此領域中的具體問題,例如文本分類、信息檢索、自動摘要生成、推薦用戶新聞、問答系統等算法的提出和改進。但是,文本表示同樣也是文本信息檢索過程中不容忽視的關鍵。文本表示是將可閱讀的文字轉換成計算機可識別的數據結構的過程,是文本信息處理領域中的基礎性問題。
當前文本表示模型主要有布爾模型(Boolean model)、概率模型(probabilistic model)和向量空間模型(vector space model)[1]。文獻[2]第1次提出自動文本檢索和信息檢索的概念。文獻[3]提出的向量空間模型是信息檢索領域最為經典的分析模型之一。在該模型中,文檔以向量的形式表示,實現自然語言在文本分類、相似度計算、模式識別等各個具體領域中的可計算性。因此,基于向量空間模型的文檔表示算法是進行任何自然語言處理的基礎和前提[4]。
針對向量空間模型中詞項權重的經典計算算法tf-idf(term frequency-inverse document frequency)未考慮詞項在類間分布情況的不足,提出一種改進算法tf-idf-cθ,對改進模型生成的相似度矩陣進行分類驗算,結果表明:tf-idf-cθ算法具有一定的可行性和有效性。
1 向量空間模型的構造
1.1 向量空間模型的基本概念
向量空間模型(VSM)是將文檔表示成n個無序特征詞項對應權值組成的向量空間,以此把文本處理轉化為向量運算[5]。
該模型的基本概念如下:
1) 文檔(document):文本或文本中的段落、句子集合。
2) 詞項(term):通過若干個基本語言單位(字、詞、短語等)表示文檔內容,這些語言單位稱為詞項。
3) 權重(term weight):表示每個詞項在文檔中重要程度。
1.2 向量空間模型的步驟
文檔生成向量空間模型通常包括5個步驟。
第1步 分詞 因為中文沒有明顯的切分標志,采用相應的分詞算法[6]將文檔分解,生成由詞項組成的集合。
第2步 去停用詞 根據停用詞表,過濾在文本中頻繁出現,但又無法表示特征的詞項,譬如“的”、“了”、“您好”等。
第3步 特征詞項選擇 從原始的詞項集合中選擇1個含有顯著類別信息的特征詞項子集[7]。
第4步 計算權重 對特征詞項進行賦值:
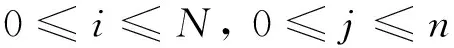
(1)
其中:wij表示特征詞項j在文檔i中的權重值;n為特征詞項總個數;N為文檔總個數。
第5步 歸一化 將特征向量標準化為單位向量:
(2)
第5步的歸一化是通過標準化各個分量,消除文檔長度對文本表示的可能影響。
由圖1可知,改進步驟4中的計算權重算法可使表示文本的向量空間模型更準確。
在產生向量空間模型的過程中,常見的有詞頻權值計算、布爾權值計算、tf-idf權值計算,其中tf-idf算法應用最廣泛。tf(term frequency)是詞項頻率,表示該詞項在文檔中出現的頻率;idf(inverse document frequency)是倒置文檔頻率,反映該詞項在文檔數據集中的重要程度[8]。具體公式如下:
(3)
(4)
(5)
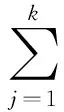
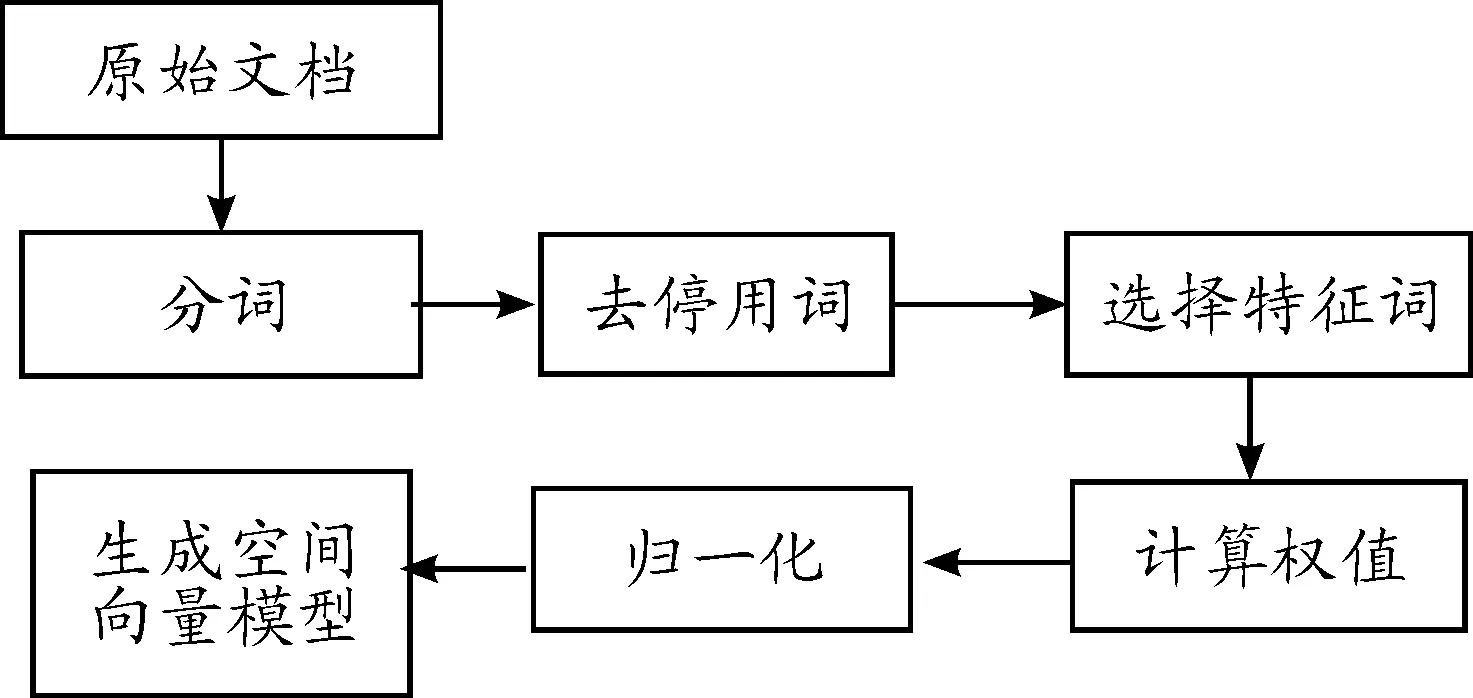
圖1 向量空間模型的產生步驟Fig.1 Produce steps of VSM
結合式(2)~(5)得出tf-idf計算權重的公式:
(6)
雖然tf-idf算法得到廣泛的應用,但也存在較明顯的缺點[9]:它把整個文檔語料庫作為衡量目標,沒有考慮詞項與類別的關聯性,即詞項在類間的分布情況[10]。文獻[11]從詞項權重和特征向量旋轉的角度說明了反文檔頻率的值不能很好地反映詞項的重要程度。文獻[12]提出一種改進的文本實時分類模型,該方法通過特征聚合和增量訓練算法,改進了VSM的特征提取策略,進一步對特征詞進行加權處理,可更好地劃分類別界限。文獻[13]提出一種WAKNN加權方法,該方法通過逐一嘗試權值,達到給每個特征詞加權的目的,但是該方法增加了計算代價。
本文引入卡方分布值c獲得最大限度區分不同文檔的能力,并且融入詞性因子θ到權值計算中。
2 改進文本表示算法——tf-idf-cθ函數
如以上所述,tf-idf函數僅考慮了特征與文檔之間的關系,沒有反映特征與類別的關聯性。本文首先引入卡方分布,彌補tf-idf算法的不足。實際上通過卡方分布值能夠反映出詞項在文本分類中的重要程度,進行量化后,定義為因子c,見式(7),即將因子c引入式(6)。
(7)
其中:A表示Ci類包含t詞項的文檔數量;B表示非Ci類包含t詞項的文檔數量;C表示Ci類不包含t詞項的文檔數量;D表示非Ci類不包含t詞項的文檔數量;N表示文檔的總數量。c的值越大,說明詞項和類之間的關聯度越大。
利用因子c改進式(6):
wik=tf*idf*c=
(8)
此外,本文引入詞性系數因子θ來量化不同詞性對于文本的重要程度。改進式(8)得到式(9)。θ定義如下:

其中0≤ω≤β≤α≤1。根據經驗,設置名詞的詞性因子最大,動詞、形容詞、副詞其次,其他最小。
改進的tf-idf-cθ函數如下:
(9)
式中:N表示文檔的總數量;nk表示包含詞項k的文檔數量;ck表示詞項k對應的卡方值;θk表示詞項k對應的詞性因子。另外,將tfik改進為(log(tfik)+1)是因為已有實驗表明,對詞項頻率tf取對數,會比直接使用更有效。并且為保證頻率為1的詞項具有非0權值,因此詞項頻率修正為log(tfik)+1。
式(9)的tf-idf-cθ算法內涵是融合詞項k在文檔和類中的比例分布情況,當c值很大時,k值就大。這也意味著詞項k的權值與c值的類別特征成正比,說明詞項k描述類的能力越大,文本類區分權值就越大。同理,詞性因子θ也一樣。
當通過tf-idf-cθ函數計算權值時,在原先只是將詞項頻率和逆文檔頻率相乘的基礎上,還考慮到了詞項在類中的分布比例問題,并且引入詞性因素。tf-idf-cθ算法綜合考慮這些影響因素,不增加其他的計算和分析難度,有很強的實用性。
3 實驗結果及分析
3.1 實驗數據集的選擇
由于常用的語料庫某些文章的篇幅較長,因此本文以復旦大學日月光華BBS站精華區文章為短文本實驗數據源,選取表1中的7個大類進行實驗。

表1 實驗數據集分布Table 1 Distribution of experimental data set
針對表1的7個類別,每個類別隨機選擇800篇文本,共5 600篇文本進行實驗。
3.2 評價指標的設置
實驗采用準確率(precision)和召回率(recall)為實驗對比指標,其中準確率考察分類的精確度,而召回率考察分類的完整性[14]。兩者定義見式(10)、(11)。
(10)
(11)
其中:n(i,j)表示在分類結果j中包含預定義類別i的文本個數;nj表示分類結果j中文本的個數;ni表示預定義類別i中文本的個數。
3.3 實驗結果的分析
為了驗證式(9)tf-idf-cθ算法改進的有效性,設計兩組對比實驗:
第1組實驗,將tf-idf-cθ算法同傳統tf-idf算法、未考慮詞性因子的tf-idf-c算法進行文本分類比較,以觀察卡方分布值c和詞性因子θ對分類結果的影響。
第2組實驗,通過測試3組詞性因子的值,觀察采用tf-idf-cθ的分類效果,得到最佳詞性因子取值組合。
同時為保證實驗的公平性,兩組實驗都采用相同的KNN分類算法。
表2為tf-idf算法分別加入因子c(式(8))和因子c、θ(式(9))進行實驗的結果。表2是采用3種不同算法得到的文本分類結果對比。其中詞性因子θ取值分別為:α= 0.5,β=0.3,ω=0.2。
表2 3種算法準確率和召回率比較情況
%
Table 2 Accuracy and recall rate of 3 algorithms
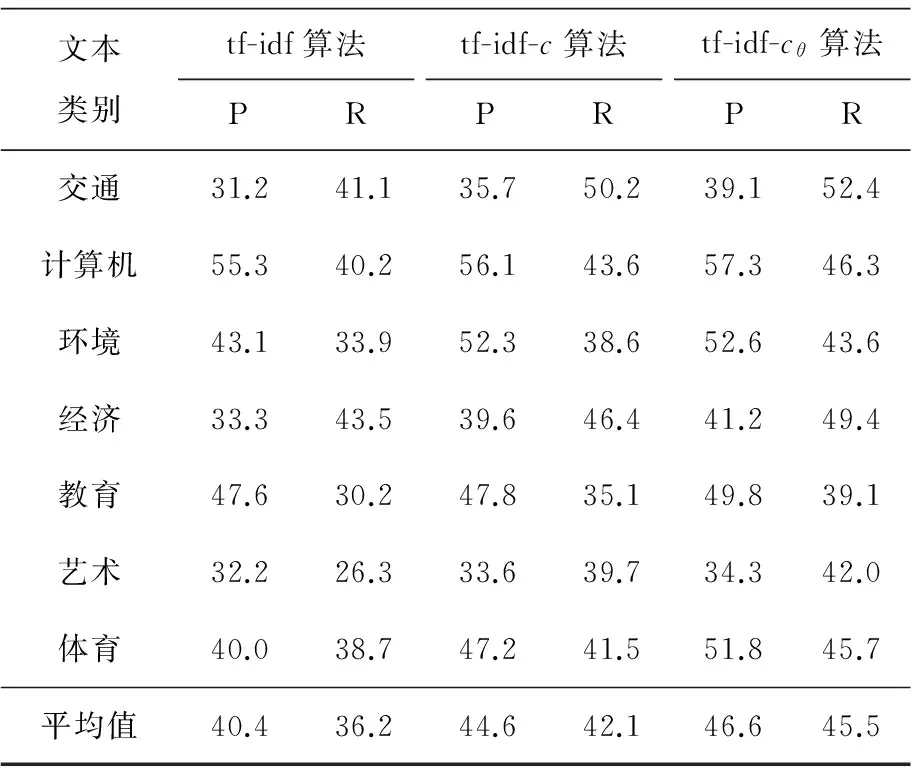
文本類別tf-idf算法PRtf-idf-c算法PRtf-idf-cθ算法PR交通31.241.135.750.239.152.4計算機55.340.256.143.657.346.3環境43.133.952.338.652.643.6經濟33.343.539.646.441.249.4教育47.630.247.835.149.839.1藝術32.226.333.639.734.342.0體育40.038.747.241.551.845.7平均值40.436.244.642.146.645.5
從表2中可以看出:tf-idf算法的準確率和召回率最低,改進的tf-idf-c算法在文本分類結果的準確率和召回率兩個方面均有3%~6%的提升,而考慮了詞性因子的tf-idf-cθ算法,準確率進一步提高,召回率也有一定的提高。利用柱形圖圖2、圖3能進一步直觀地反映準確率和召回率的對比情況。
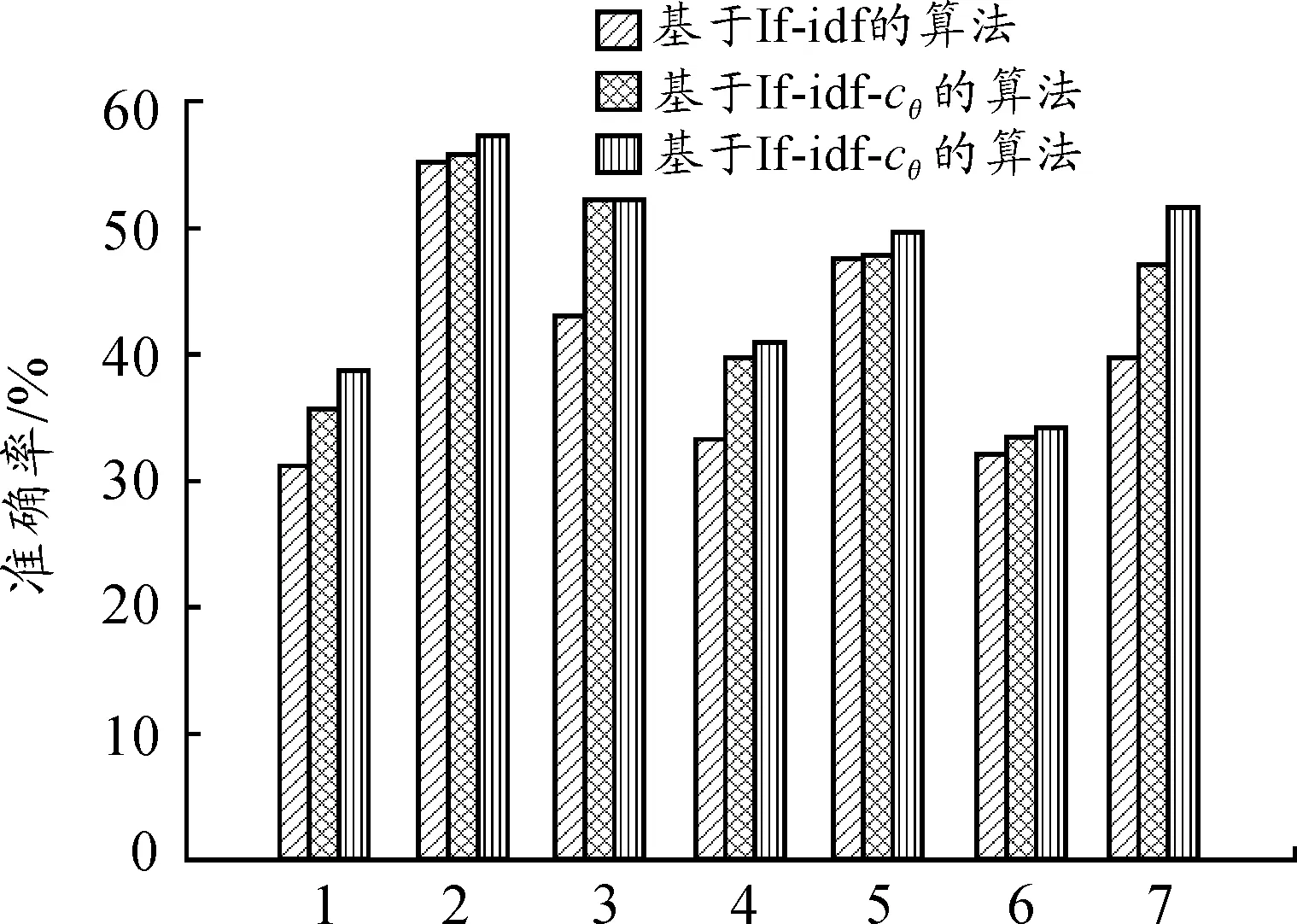
圖2 3種算法的準確率比較Fig.2 Accuracy rate cmparison of 3 algorithms
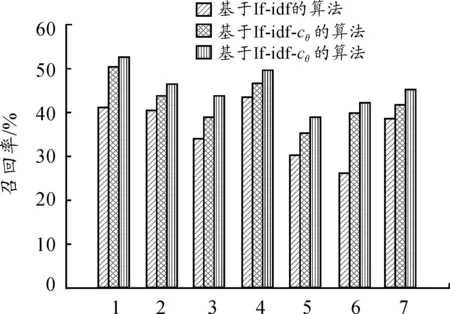
圖3 3種算法的召回率比較Fig.3 Recall rate comparison of 3 algorithms
從圖2、圖3可以看出:tf-idf-cθ算法對于個別類的召回率改進效果比較明顯,但在對不同類別分類結果的準確率和召回率提高效果不同,說明tf-idf-cθ算法在文本內容分類方面有一定程度的改善。
圖 4是第2組的實驗結果,展示了不同詞性因子取值組合對文本分類結果的影響。
從圖4可以看出:當組合為α= 0.5,β=0.3,ω=0.2時,文本分類的平均準確率最高,這也是針對第1組實驗采用該詞性因子取值組合的原因。

圖4 不同詞性因子組合的分類結果比較Fig.4 The classification results comparison of different factor combination
4 結束語
為了解決tf-idf算法對詞項在類間分布情況的不足問題,引入卡方分布方法,融合考慮了詞項在類中的分布比例和詞性因素,提出了改進的算法tf-idf-cθ。實驗結果表明:文本表示算法效果得到提升。盡管改進后的文本表示算法有較好效果,但針對整個文本分類問題仍存在進一步的提升空間,比如可結合具體處理文本領域中的相似度計算等方法,這也是后續的研究方向。
[1] 徐濤,于洪志,加羊吉.基于改進卡方分布量的藏文文本表示算法[J].計算機工程,2014,40(6):185-189.XU Tao,YU Hongzhi,JIA Yangji.Tibetan Document Representation Method Based on ImprovedChi-squared Statistic[J].Computer Enginnering,2014,40(6):185-189.[2] LEONG M K,ZHOU H.Preliminary Qualitative Analysis of Segmented vs Bigram Indexing in Chinese:Trec,1997[C]//Gaithersburg,Maryland.1997:551-557.
[3] SALTON G,WONG A,YANG C S.A Vector Space Model for Automatic Indexing[J].Communications of the ACM,1975,18(11):613-620.
[4] SUN Shuang,HE Liang,YANG Jing,et al.An Improved Algorithm for Weighting Keywords in Web Documents[J].Journal of Shanghai University(English Edition),2008,12(3):235-239.
[5] MICHAEL W.Berry,Murry Brovme,Understanding Search Engines Mathematical Modeling and Text Retrieval[D].USA:University of Tennessee,1995:31-39.
[6] 宋庭勇.基于語義的中文短文本模糊譜分類[D].上海:華東師范大學,2015.
SONG Tingyong.The Short Text Fuzzy Spectral Clustering Based on Semantic[D].Shanghai: East China Normal University,2015.
[7] 平源.基于支持向量機的分類及文本分類研究[D].北京:北京郵電大學,2012.
PING Yuan.Rearch on Clustering and Text Categorization Based on Support Verctor Machine[D].Beijing: Beijing University of Posts Telecommunications,2012.
[8] ROBERTSON S.Understanding inverse document frequency:on theoretical arguments for IDF[J].Journal of documentation,2004,60(5):503-520.
[9] 張蕓.基于BTM主題模型特征擴展的短文本相似度計算[D].合肥:安徽大學,2014.
ZHANG Yun.A Short Text Similarity Calculation Method Based on Feature Extension using BTM Topic Model[D].Hefei: Anhui University,2014.
[10]羅成飛.結合卡方分布與特征分類的文本特征降維方法[D].廣州:華南理工大學,2015.
LUO Chengfei.Based on CHI and feature clustering text feature reduction[D].Guangzhou:South China University of Technology,2015.
[11]雷軍程,黃同成,柳小文.一種基于權重的文本特征選擇算法[J].計算機科學,2012,39(7):250-275.
LEI Juncheng,HUANG Tongcheng,LIU Xiaowen.Improved Text Feature Selection Method Based on Text Feature Weight[J].Computer Science,2012,39(7):250-275.
[12]張曉輝,李瑩,常桂然,等.適于Internet新聞文本實時分類的動態向量空間模型DVSM[J].計算機科學,2004,31(6):64-67.
ZHANG Xiaohui,LI Ying,CHANG Guiran,et al.A Dynamic Vector Space Model for Internet News Textual Categorization[J].Computer Science,2004,31(6):64-67.
[13]HAN E H,GEORGE K.VIPIN K.Text categorization using weight adjusted k-nearest neighbor classification[R].Minnesota:Computer Science Department,2000.
[14]王有華,陳笑蓉.基于Kolmogorov復雜性的文本分類算法改進[J].計算機科學,2016,43(5):243-246.
WANG Youhua,CHEN Xiaorong.Improved Text Clustering Algorithm Based on Kolmogorov Complexity[J].Computer Science,2016,43(5):243-246.
(責任編輯 楊黎麗)
Text Representation Based on Improved Vector Space Model
ZHANG Xiao-chuan,YU Xu-ting,ZHANG Yi-hao
(College of Computer Science and Engineering, Chongqing University of Technology,Chongqing 400054, China)
Text representation transfers the readable text into computer-identifiable data structure, and it is a fundamental problem in text information processing field. As a text representation approach in Vector Space Model(VSM), tf-idf algorithm just considers the relevancy between term feature and document, but class. In order to solve this problem, the paper introduce the Chi-square concept of mathematical statistics, and propose a text representation algorithm——tf-idf-cθ.And the algorithm takes the termcvalue as a factor of a text representation, andcvalue measures the term distribution difference in classes, and also considers the term characteristic asθvalue to produce the corresponding text representation based on the improved VSM. Last, it classifies short text using two algorithms above, and the experiment results show that the modified method is more effective, and partly solve the relevancy between term feature and class.
text representation; VSM; CHI; tf-idf
2016-10-12
國家自然科學基金資助項目(61502064);重慶市“121”科技支撐示范工程項目(cstc2014fazktjcsf40009)
張小川(1965—),男,教授,主要從事人工智能、計算機軟件研究,E-mail:zxc@cqut.edu.cn;于旭庭(1990—),女,碩士研究生,主要從事人工智能、計算機軟件研究,E-mail:1527593026@qq.com。
張小川,于旭庭,張宜浩.一種改進的向量空間模型的文本表示算法[J].重慶理工大學學報(自然科學),2017(1):87-92.
format:ZHANG Xiao-chuan,YU Xu-ting,ZHANG Yi-hao.Text Representation Based on Improved Vector Space Model[J].Journal of Chongqing University of Technology(Natural Science),2017(1):87-92.
10.3969/j.issn.1674-8425(z).2017.01.014
TP391
A
1674-8425(2017)01-0087-06
猜你喜歡
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
制造技術與機床(2019年10期)2019-10-26 02:48:08
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
電子制作(2018年18期)2018-11-14 01:48:06
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
發明與創新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
