科學數據眾包處理研究
2017-02-22 04:31:44趙江華穆舒婷王學志林青慧周園春
計算機研究與發展 2017年2期
趙江華 穆舒婷 王學志 林青慧 張 兮 周園春
1(中國科學院計算機網絡信息中心 北京 100190)2(中國科學院大學 北京 100049)3 (天津大學管理與經濟學部 天津 300072) (zjh@cnic.cn)
科學數據眾包處理研究
趙江華1,2穆舒婷3王學志1林青慧1張 兮3周園春1
1(中國科學院計算機網絡信息中心 北京 100190)2(中國科學院大學 北京 100049)3(天津大學管理與經濟學部 天津 300072) (zjh@cnic.cn)
獲取科學數據的最終目的是根據具體需要從數據中提取有用的知識,并將這些知識應用到具體的領域中,幫助決策制定者制定決策.由于科學數據規模越來越大,而且呈現結構復雜的特點,如半結構化或非結構化,難以通過計算機實現自動化處理.眾包通過高效調用人力資源,成為進行科學大數據眾包處理的解決方案之一.針對科學大數據眾包處理的特點,圍繞人才篩選機制、任務處理模式和結果評估策略3方面對科學數據眾包體系進行研究,并通過地理空間數據云平臺開展地學領域的基于眾包的遙感影像信息提取實驗.研究表明,科學數據不僅能夠通過眾包模式來進行處理,而且通過合理的設計眾包流程能夠獲得高質量的數據結果.
眾包;科學大數據;數據處理;人才篩選;質量評估
科學數據是以解決世界上現存的社會和環境問題為驅動的[1],必須由數據轉化為信息,進而轉化為知識才能夠得到應用,從而體現其價值[2].傳統的科學數據處理方式為科學工作流.科學工作流系統可自動化科學數據處理任務的編排、執行、監控以及追蹤[3],清楚地說明計算任務和數據質檢的關系,便于科學家定義多階段的計算和數據處理通道,是管理科學數據處理過程的有用工具[4].
隨著數據獲取技術的提高,以及計算機網絡和數據存儲技術的發展,海量科學數據資源的積累和傳播成為可能.天文學、大氣科學、基因組學、生命科學、地球與空間科學等學科正在產生越來越多的科學數據.據估計,到2020年,天文學產生的數據將達到60PB[5].科學研究的時空范圍越來越大,使得數據處理的工作量急劇增加,從而對科學大數據的高效處理和分析產生更大的需求.
科學大數據的處理和分析工作因其性質可分為自動化處理和非自動化處理.自動化的數據處理工作通常首先設定明確的目標和工作步驟,然后建立科學工作流[6].對于求解規模大的問題,工作流的各個步驟可在復雜的分布式計算機系統上并行處理,如超級計算機、分布式集群系統、網格或云平臺[7].然而,由于大量的半結構化和非結構化的科學數據產生,使得科學大數據呈現結構復雜性的特點.這類數據往往難以通過計算機實現自動化處理,因此,傳統的基于集群或云平臺的科學工作流方法已經不能完全滿足數據密集型的科學大數據處理.而且人工智能和機器學習等方法往往也需要人工的反饋來學習新的知識和做決策支持,受制于科學家有限的時間和精力,科學大數據處理面臨極大的挑戰.
眾包作為一種分布式的群智計算模式,通過互聯網高效地調用分布全球的人力資源,對于處理人類比較擅長而計算機難以自動化處理的任務有很大優勢.因此,如何高效地利用人類和計算機組成的全球大腦網絡[8],來解決科學大數據快速精準的處理成為本文主要探索研究的方向.
本文首先對科學大數據眾包處理方法、眾包管理機制和質量控制研究現狀進行總結,分析了基于眾包的科學數據處理體系所面臨的關鍵問題和挑戰,并對其進行研究;然后通過在地學領域開展基于眾包的科學數據處理實驗,來對本文提出的解決方案進行驗證;最后對本文進行了總結,并對未來的研究方向進行了展望.
1 相關工作
1.1 數據眾包處理方法
眾包是由英文合成詞Crowdsourcing一詞翻譯而來,最早由Howe提出[9],即將過去由公司內部員工執行的工作,以自由自愿的形式交給大眾去完成的做法.作為一種分布式的問題解決和生產模式,眾包模式在科學數據處理領域有著極大的優勢:1)眾包模式打破了專職科學家和業余科學家的界限,不僅使有一技之長的任何個人都可以投入自己的精力、時間和技能參與到科學數據處理和知識創造中,并獲得回報,還使得科學家有更多時間和精力投入到對專業水平要求更高的研究創新中[10];2)公眾的參與使得眾包成為知識傳播的絕佳方式,基于眾包的科學數據處理可以提高科學研究的影響力和公眾的科學素養[11];3)研究表明依靠達成一致共識的公眾來生產費時且難以自動化,但有科學價值的數據產品,不僅可降低時間和金錢成本,而且在提供有更多訓練或評價反饋的情況下,眾包得到的數據結果比專家結果更高[12];4)基于眾包的科學數據處理使公眾成為勞動力、技能、計算能力甚至是資金支持的重要來源[13],不僅改變了專職科學家的工作模式,還可降低成本,優化科研資源配置.
根據數據處理內容和公眾參與形式,科學數據眾包處理方法主要有協作集成式、競賽選擇式和微任務市場3類.
協作集成式是由科學家或研究人員將科學數據處理任務分解為簡單任務,公眾無需具備任何專業知識即可參與.Zooniverse即是一個典型案例,科學家首先將科學數據處理工作設計成框選圖像內容和添加標記等可重復進行的簡單任務,然后在Zooniverse平臺上發布,公眾通過平臺所提供的交互可視化平臺,在接受一個簡單培訓后,即可進行分類和標注.例如發布在Zooniverse平臺上的Galaxy Zoo項目,將全球的85萬志愿者組織起來,對海量星系圖片進行識別和分類,以尋找行星和查看天文物體.已有50多篇科研文章基于該項目產生的數據發表[14].此類眾包方式多采用投票方式進行數據質量的控制,即將一個任務分發給多人處理,選擇多數人相同的結果為正確結果.但由于此類眾包任務對參與數據處理的人數要求較高,且任務分解工作復雜,同時還需進行后期的數據結果的分析和整理,因而時間成本較高.
競賽選擇式是將定義好的科學數據處理任務進行在線發布,公眾提交相應的解決方案,任務發布方在對解決方案進行分析和評價后,選擇最優的方案,并給予方案提供者相應的報酬.競賽選擇式眾包平臺有Kaggle[15],Crowdforge[16]和Innocentive[17]等.競賽類任務通常比較復雜,需要公眾具備相關技能并投入大量時間,因此對參與者的要求較高,任務報酬也較高,不適合難以自動化的大規模科學數據處理工作.
微任務市場是首先將大任務劃分為多個小任務,然后基于第三方平臺,將小任務分配給不同的人處理[6].此類任務簡單、獨立,通常需要較少時間和知識就可以完成,報酬通常也非常低,例如識別圖片或視頻中的物體.而且處理結果往往容易驗證,因此可以利用最廣大的勞動力資源,以低成本獲得很好的結果.Amazon的Mechanical Turk(MTurk)即是典型的微任務平臺,該平臺發布的任務多種多樣,包括輸入、修改、驗證給定信息、比較、分類、信息檢索、知識綜合、認知實驗、判斷和決策、用戶界面評價等.大量研究表明MTurk是一個非常有用的數據采集和評價平臺,但由于目前科學數據處理工作復雜性越來越高,有些任務難以進行分解,因此科學數據處理的眾包體系需要進一步的完善.
1.2 眾包管理機制
眾包管理機制可以定義為通過有效地引導用戶參與和使用他們的知識與技能來實現特定業務的過程.Saxton等人認為,與傳統企業管理不同的是,眾包平臺的管理重點不是增強員工的潛在技能和留住員工,而是發現和利用參與者的潛在技能并且吸引更多有才能的人加入[1].影響用戶持續參與眾包的原因有很多,很多學者在這方面進行了有意義的研究.
Saxton等人重點研究了3種管理控制系統:酬金方案、建立信任系統和投票評價機制[1].Brabham通過對Istockphoto和Threadless這2個眾包社區進行研究發現,影響用戶參與眾包社區的主要動機有金錢激勵、提高個人技能、獲得趣味和自我成就感,此外,對社區的認同感和熱愛也是用戶持續參與眾包行為的重要原因[18].可以看出,影響用戶持續參與行為的因素主要有財務激勵和內在激勵2種.
Lakhani等人的研究表明金錢和其他獎勵是個人參與眾包交易的關鍵動機.除了金錢報酬外,獎勵的形式有很多,包括積分、獎品、虛擬貨幣等[19].DiPalantino等人認為眾包是一種基于技能的全支付模式的拍賣,并且發現獎勵可以提高用戶參與的頻率[20].Harris 發現在找到合適的人來完成任務的情況下,增加報酬可以提高任務最終的完成質量[21].目前,像豬八戒這樣的眾包平臺就是通過獎金吸引眾多人參與的.Kaggle,Innocentive等網站的高額獎金也是吸引全世界的科學家參與的重要原因.
但是,很多眾包平臺,比如youtube以及國內的一些字幕組都是沒有任何報酬的,吸引他們參與的更多是一些內在需求.Huberman等人發現youtube上沒有關注的用戶會傾向于停止上傳,而持續增加的關注度則會對用戶的分享上傳行為產生積極影響[22].Howe指出,大眾很多都是因為興趣和愛好參與眾包項目[23].夏恩君等人認為,個體參與眾包活動的動因既包括內部動機也包括外部動機,完成任務帶來的成就感是大眾持續參與眾包的主要內在動機[24].Kaggle吸引人的另一個原因是它的競爭排名機制已經成為全球頂尖數據科學家證明自己實力的重要參考,參加競賽增加的經驗以及帶來的名譽等收獲也是激勵各方人才積極參加的原因.
在公民科研項目中,參與動機則主要為內在激勵.Raddick研究了志愿者參與這類公民科研的動機.研究發現大部分志愿者參與此類活動的主要動機是參與到科學研究中、為科學研究做貢獻.另外,社交互動體驗、成就感等也會影響志愿者參與的意愿[25].此外,Greenhill等人以Zooniverse為例,研究了游戲化行為對于用戶的激勵作用,研究發現游戲化可以激發用戶參與任務、貢獻自己的時間和精力的意愿,并且有助于提高用戶對于平臺的忠誠度[26].
1.3 眾包質量控制
質量是任務結果滿足任務發布者需求的程度.Allahbakhsh等人認為質量取決于2方面,即發布者的任務設計和任務完成者的資質.任務完成者的資質包括聲譽和能力;任務設計是任務發布者發布的信息,包括任務定義、用戶界面、任務復雜程度和獎勵政策[27].同時,作者還總結了在任務設計階段和運行階段的質量管理措施.
眾包面向的用戶是不確定的,眾包獨立匿名的特點使得對于眾包用戶的資格審查難度增加,這使得眾包的質量具有較大的不確定性.科學大數據的眾包對于數據結果質量的要求更高,因此質量控制是設計科學大數據眾包平臺的重要內容.對眾包質量控制的研究集中在2方面:1)結果質量控制;2)眾包任務設計.
結果質量評估主要是根據用戶提交的任務結果的歷史數據剔除不合格的參與者.一些眾包網站,如Amazon Mechanical Turk采取冗余信息標識正確答案,即讓大量的人重復做同一任務,然后用投票的方法來決定正確答案.但是,大量的冗余是昂貴的,極大地提高了眾包網站的成本.針對此,Dawid和Skene提出了基于期望最大化算法的解決方案.他們的算法首先通過用戶提交的結果來估計每個任務的正確答案,然后通過將用戶提交的答案與估計的正確答案對比來評估用戶質量,最終使用用戶的總誤差之和來給每個用戶的質量評分,從而剔除惡意操作者,提升眾包平臺的效率[28].Ipeirotis等人認為用任務結果對用戶進行評價受個人偏好的影響,存在偏差,因此在此基礎上提出了消除用戶個人偏好、恢復故有誤差率的方法,以獲得更可靠的質量評估[29].Tong等人提出了一個利用眾包的方法對復雜版本數據進行檢測和修復的模型,用戶只需通過對數據進行簡單識別.在模型中,作者加入了一個信任模型,根據參與者的歷史任務數據對參與者的信用評級,以便篩選出信譽最好的參與者以提高眾包質量[25].
眾包的任務設計對于最終的質量也有一定影響.Sorokin等人發現,酬金的高低會影響不同類型眾包參與者的參與意愿,進而影響到任務質量.酬金較低時,對任務感興趣的人會明顯變少;而酬金較高時,則會吸引很多惡意參與者,即想利用規則漏洞贏得酬金而不認真完成任務的用戶[30].Kittur等人指出眾包任務應當保證通過欺騙的手法騙取酬金和認真完成所花的時間基本相同,以此來減少惡意用戶行為[31].此外,一些眾包平臺還通過只接受發達國家的人承接任務來減少惡意用戶,Eickhoff等人在研究中已經證實了這種做法的有效性,但是也指出,采取人員過濾的做法會使得任務的完成周期變長.他們進一步指出,相比人員過濾的方法,通過任務來過濾用戶更加高效,他們發現惡意用戶通常較少參與需要較高創造性的任務,因此通過增加任務的復雜程度可以有效較少惡意用戶,從而提高任務質量[32].
2 科學數據眾包處理體系
科學數據眾包處理體系主要包括眾包人才篩選、眾包任務處理模式與方法以及眾包結果質量評估3方面.相比于傳統的眾包任務,科學數據處理專業性較強,需由專業人士或專業基礎較好的業余愛好者來完成,這對人才篩選和管理提出挑戰;而且科學數據處理通常為數據密集型和計算密集型,往往需要可擴展的計算和存儲資源,如何為用戶提供一個私有的計算機存儲、處理環境并匯聚相應數據資源成為關鍵;同時科學數據處理任務對數據質量要求較高,質量控制方法復雜.因此本文主要針對科學數據眾包處理體系中的人才篩選機制、任務處理模式和結果評估策略3方面展開研究.
2.1 眾包人才篩選機制
2.1.1 眾包人才評價與管理
研究表明,任務領取人的能力對于任務完成的結果質量影響很大[31,33],因此,在進行任務分配時,人才選取成為獲取高質量數據結果的關鍵.本文采用人才分級管理機制,通過多種方式的審核,對參與科學數據處理的人才進行評價和分級,管理流程圖如圖1所示:
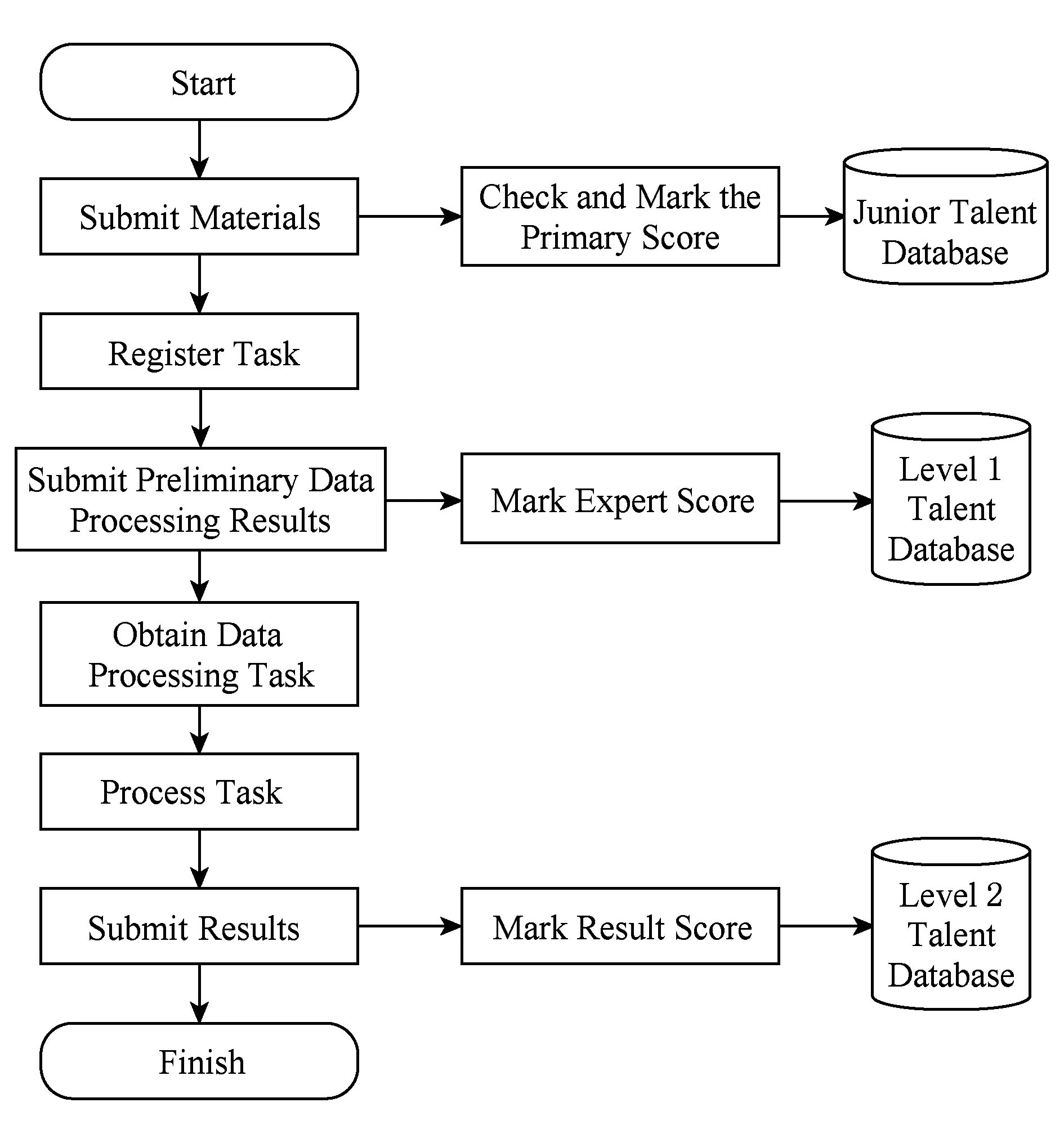
Fig. 1 Flow chart of talents assessment mechanism圖1 人才評價機制流程圖
將所有參與科學數據處理的人才分為3類:初級人才、1級人才和2級人才.其中初級人才需在科學數據處理眾包平臺提交相關材料,經平臺審核后,給予其初級評分s0,并存儲到初級人才數據庫.報名參與科學數據處理眾包任務的人需提交數據預處理結果和任務解決方案等補充材料,經專家評價以及考核后,給予其專家評分s1,并存儲到1級人才庫.對于專家評分高的人才將成為眾包任務領取人,參與科學數據處理.最終平臺根據眾包任務領取人提交的數據結果質量,再次對任務領取人進行結果評分s2,并存儲到2級人才庫.具體評分方法如下:
一項眾包任務T對任務領取人的能力要求集合為{C1,C2,…,Cz}.對于不同層次的人才評分,所依據的能力要求不同.人才的初級評分根據其信息完整程度、數據處理經驗和數據處理工具熟練程度等方面來設定;1級人才的專家評分的依據是任務申請人時間上是否能夠保證完成任務,以及申請人的數據預處理能力、數據處理能力、編程能力、挖掘算法熟悉程度、數據處理態度等;2級人才的結果評分則根據對其提交的數據處理結果的質量評價來確定.眾包候選人對任務數據處理能力Px的滿足程度Sx可通過模糊性語言變量子集{不滿足,基本滿足,比較滿足,非常滿足}來表示,并分別以數值{0,0.6,0.8,1.0}來量化表示.
各個層次的人才評分描述為
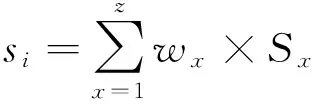
(1)
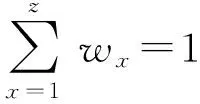
2.1.2 眾包人才篩選與任務分配
針對眾包任務Ti,設定任務能力要求閾值,閾值需根據子任務的數據處理工作量、重要性等因素確定.搜索滿足能力要求的眾包任務候選人,并進行任務分配,人才篩選與任務分配算法如算法1所示.
算法1. 人才篩選流程算法.
輸入:任務集T,初級人才庫P0,1級人才庫P1,2級人才庫P2;
輸出:任務分配結果.
計算任務數n;
初始化能力要求閾值λ1和λ2;
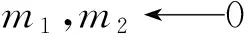
foreachtalentinP2do
ifs2>λ2thenm2++;
endif
endfor
ifm2>nthen
按分數s2從高到低對人才進行排序;
為s2值最大的n個人分配任務;
else
為m2個人分配任務;
foreachtalentinP1do
ifs1>λ1thenm1++;
endif
endfor
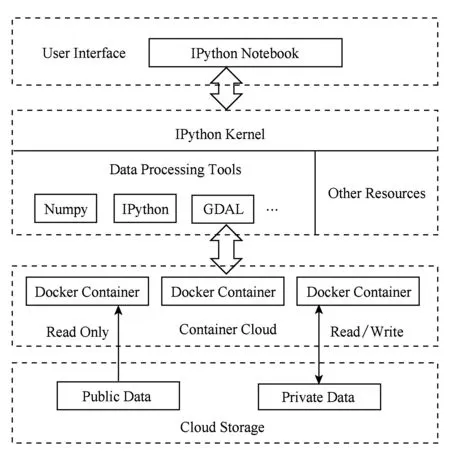
ifm1+m2>nthen
為s1值最大的n-m2個人分配任務;
else
do
根據s0對初級人才進行排序篩選并標記專家評分;
將標記有專家評分的人才加入到P1人才集合中;
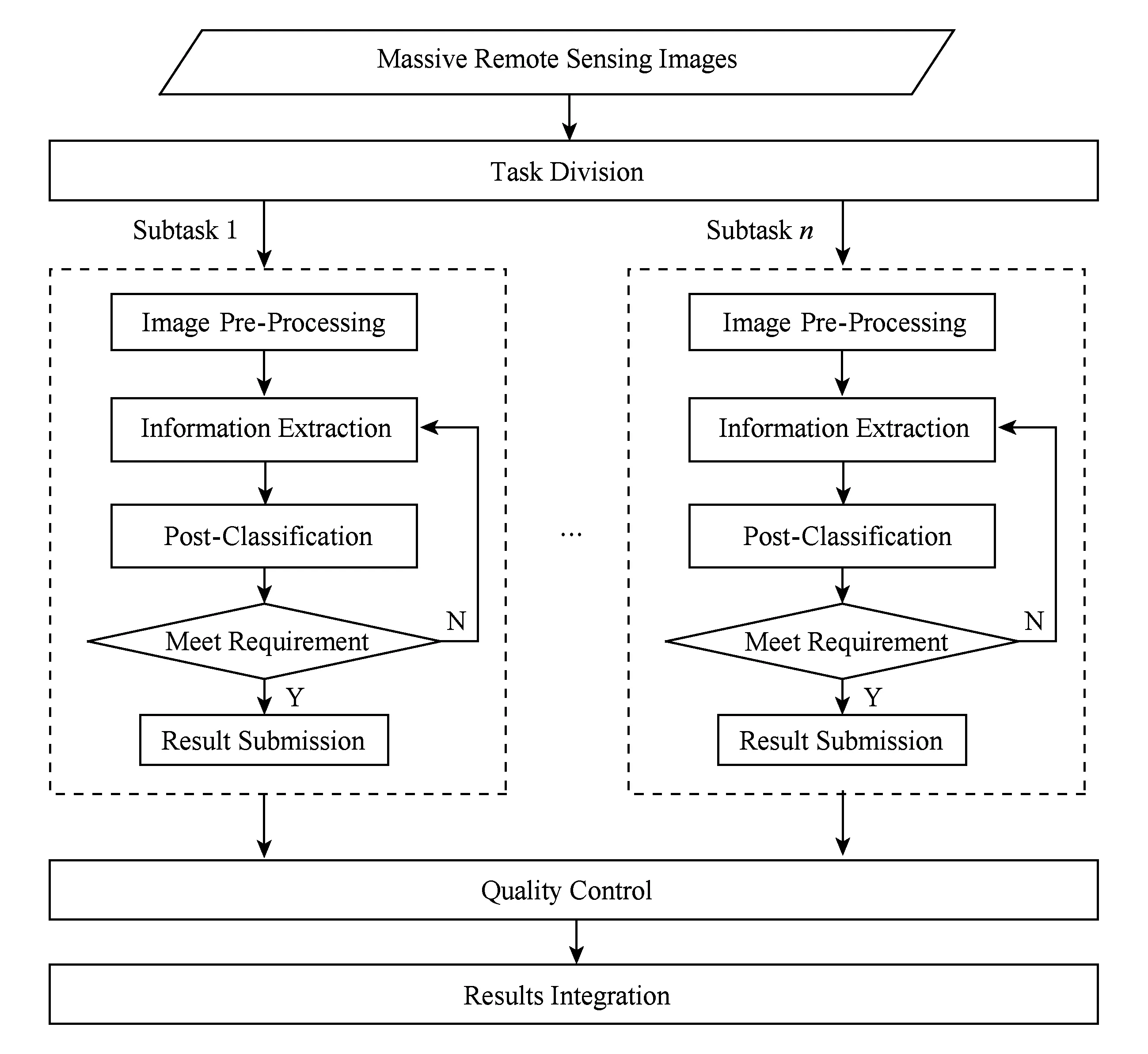
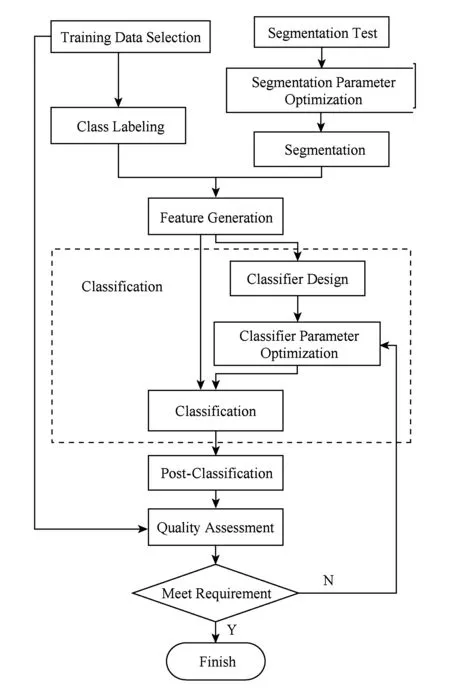
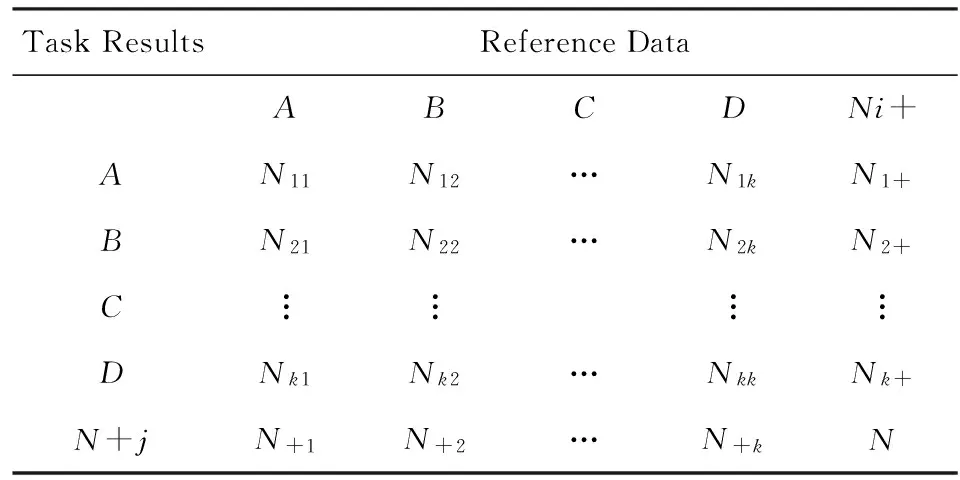
whilem1+m2 分配剩下的n-m1-m2個任務; endif endif Return任務分配結果. 首先將大的科學數據處理任務劃分為n個子任務;然后根據數據質量要求,篩選領取過科學數據處理眾包任務的2級人才,如果符合要求的人才數大于或等于n,則將任務分配給評分高的前n人,否則先對2級人才進行任務分配,再從1級人才庫中篩選評分高于設定的能力要求閾值的人才,并將剩余任務進行分配;當篩選出的1級和2級人才數目仍小于n時,則從初級人才庫中篩選,并標記專家評分,直到任務分配完成. 2.2 眾包任務處理模式 針對科學數據處理的性質,眾包任務的執行可分為線上和線下2種方式.線下方式由任務領取人下載數據后,利用個人的計算資源完成科學數據的處理,最后提交眾包結果;線上方式為任務領取人在線訪問和組織數據資源,并利用在線的計算資源進行數據的處理和存儲.針對線上方式,平臺需為眾包領取人提供在線的數據組織和訪問,以及計算資源的管理與使用. 2.2.1 數據資源的組織與訪問 眾包數據分為公共數據和私人數據.平臺采用分布式文件系統對數據進行存儲,對于不能提供下載的科學數據,可通過存儲在公共數據中,任務領取人可進行讀取,在線處理,將數據處理結果直接存儲到私人數據存儲空間中.數據管理系統如圖2所示: Fig. 2 Data resources management system圖2 數據資源管理系統 系統采用用戶空間文件系統(FUSE技術)實現符合POSIX的文件接口,用戶通過虛擬文件系統訪問分布式文件系統中的數據,公共數據的訪問權限為只讀,私有數據則可進行讀寫操作.同時任務領取人可通過客戶端接口或FTP進行數據的組織.系統允許任務領取人上傳本地存儲的數據.基于jqueryDjango實現的多文件上傳模塊,前端窗口支持拖拽上傳、可對等待上傳的文件進行排序管理、實時顯示正在上傳文件的狀態并針對上傳失敗的情況給出錯誤提示信息等.后端針對上傳文件的大小采用不同的存儲方案:小文件由內存直接寫入硬盤;大文件則進行分片存儲,接受到的小片文件首先寫入臨時文件夾,當所有文件全部接受成功后再寫入目標文件夾. 2.2.2 計算資源的管理與使用 對于數據量較大的科學數據處理任務,本文采用計算資源隔離容器為任務領取人提供數據快速獲取平臺和可配置的計算資源,具體架構體系如圖3所示: Fig. 3 Architecture of data and computing resources service圖3 計算資源服務架構圖 系統為每個任務領取人提供可擴展的計算資源和云存儲環境.任務領取人可通過IPython Notebook編程進行計算資源、數據處理工具和數據資源的調用.IPython Notebook是一個連接到IPython Kernel的基于Web的交互式計算環境,允許用戶在Python環境中靈活定制和實時執行代碼,并可交互式地調用數據處理工具包和系統資源.采用IPython Notebook實現,可支持基于網絡交互實現復雜的科學計算,如科學繪圖、并行計算、Linux系統shell調用等.IPython Kernel負責管理這些工具資源,并為IPython Notebook提供公共接口.IPython Kernel和數據處理工具被封裝在Docker的虛擬文件系統中,每個Docker實例執行一個IPython Kernel,負責接收和處理來自IPython Notebook的請求,以及讀取云存儲中的數據資源. 2.3 眾包結果評估策略 質量評價的目的是在一定范圍內量化數據結果質量或根據數據質量對數據結果進行分類,識別出合格的數據結果.本文采用迭代回歸的質量控制方法,結合多源數據、專家知識以及定量評價算法等,實現高效、準確的眾包結果質量評價.數據質量控制算法如算法2. 算法2. 數據質量控制流程. 輸入:任務處理結果集合R,當前任務領取人集合K,P={P0,P1,P2}; 輸出:合格的數據集結果. for each result inRdo 根據質量評價算法計算E(R); ifE(R)=1 then 集成數據結果; else ifE(R)=0 then 反饋修改意見給任務領取人k; else ifE(R)=-1 then Replace the talentk; end if 對任務領取人k進行評分; end for Return合格的數據集成結果. 對于每個眾包任務的數據結果,根據數據質量評價算法計算該任務的評價結果E(R),數據質量評價算法如下: 1) 確定數據質量評價指標 參考Wang等人提出的全面描述數據質量的指標體系,包括可信性、準確性、完整性、一致性、易理解性和客觀性等質量指標[34],根據科學數據處理任務的內容和領域特點,確定數據質量評價指標集合{I1,I2,…,Iq}. 2) 數據質量評價指標的計算 收集并整理相關數據資源,利用專家知識和經驗,結合多源數據對數據結果進行各個質量指標的計算,計算公式如下: Ii=f(E,M,A), (2) 其中,Ii為第i個指標的評分,為取值介于0到100的實數;E為專家知識;M為多源數據資源;A為定量評價算法庫,數據質量評價指標和定量評價算法庫采取“邊構建,邊使用,邊修改”的方式來補充和完善. 3) 指標權重的確定 將已完成的同類任務的評價數據作為訓練樣本,利用機器學習方法,如邏輯回歸,進行指標權重參數的優化. 4) 得到評價結果 計算數據質量評價結果: (3) 其中,θi為第i個指標的權重,E(R)取值范圍為{-1,0,1}.“-1”代表“放棄”,表示數據結果完全不合格;“0”代表“修改”,表示為數據基本合格,但還需進一步修改和完善,對于“修改”類的數據結果,根據評價結果反饋修改意見;“1”代表“合格”,表示數據質量滿足處理要求的結果. 采用定性和定量指標相結合的方法,不僅可避免評價結果的模糊性,還可充分利用專家知識提出修改意見,提高數據處理結果的精度,同時保障了任務領取人的利益. 隨著遙感技術的發展,新一代遙感平臺的出現,遙感影像在空間分辨率、時間分辨率、光譜分辨率和輻射分辨率上都有了很大程度的提高.遙感影像信息提取(remote sensing information extracting)是從遙感影像上獲取目標地物信息的過程.由于遙感具有覆蓋面廣、及時快速的優勢[35],通過遙感影像提取地物類型或土地利用類型信息已經成為監測城市擴張、環境監測和災害評估的有力手段,對人類的可持續發展具有重要意義[36]. 隨著遙感數據集的不斷增長,各類研究對遙感圖像的時間、空間跨度要求越來越大.由于遙感影像成像條件不同,目前沒有一種完美的分類器或算法能夠實現大量遙感影像的全自動提取,因此,眾包模式成為解決這一問題的解決方案.本文通過一系列的遙感影像信息提取任務對提出的眾包體系進行了實踐.所提取的土地利用類型包括水體、建筑用地、耕地、林地、草地、未利用地等,覆蓋區域包括北京、石家莊、上海、天津、青海、武漢、承德、張家口、蘇州等省市. 3.1 數 據 Landsat數據是覆蓋全球的中等空間分辨率的對地觀測數據,從1972年7月發射第一顆Landsat系列衛星開始,已進行了40多年的連續對地觀測,成為長期陸表狀態及其變化監測研究的最有效遙感數據之一.2008年由美國USGS免費對全球開放使用后,Landsat系列數據在生態環境監測、能源與資源管理、災害監測、城市規劃等領域得到廣泛應用[37-40].Landsat數據可通過地理空間數據云平臺GSCloud(www.gscloud.cn)免費下載. 3.2 任務處理方法 根據時空規則將整個數據處理任務劃分為多個子任務,對于大規模遙感影像信息提取任務,通常采用時間和空間相結合的方法進行任務劃分,每個子任務由領取人通過人機協作方式使用面向對象方法提取地物信息,最后進行數據質量的控制,并合并各子任務合格的數據處理結果.基于眾包的遙感影像信息提取的整體流程如圖4所示.任務領取人可通過GSCloud對Landsat影像進行在線處理,如植被指數計算、條帶修復等. Fig. 4 Flow chart of crowdsourcing based remote sensing image information extraction圖4 基于眾包的遙感影像信息提取流程圖 3.2.1 影像信息提取方法 為保證信息提取結果的質量一致性,我們對數據處理方法做了規定.遙感影像信息提取方法可分為面向像元的方法和面向對象的方法.面向對象方法的基本思想是首先將遙感影像中空間相鄰的像元分割成一個個同質性的對象,然后將這些對象作為最小的分類單元利用光譜、紋理、幾何和上下文信息對影像進行分類,完成地物信息的提取[41].和面向像元的方法相比,面向對象方法通過圖像分割將目標從影像中分離出來,將原始圖像轉化為更抽象更緊湊的形式,便于特征提取和參數測量,因此使得更高層次的分析和理解成為可能[42]. 在使用面向對象方法進行影像信息提取時,由于遙感影像的成像條件不同,空間變異性高,復雜多樣,且遙感影像的分析與理解需要從不同的尺度著手,所以不存在一種完美的分類器可自動準確地提取遙感影像的信息.實驗任務規定采用半自動的遙感影像信息提取方法,即利用人腦對遙感影像的綜合理解和分析,將人的知識與經驗融入到面向對象信息提取中來,具體方法如圖5所示. Fig. 5 Semi-automatic remote sensing imageinformation extraction framework圖5 半自動化遙感影像信息提取技術路線圖 半自動化遙感影像信息提取方法首先選擇并提取特征進行影像分割,根據目視判讀優化分割參數;其次,根據影像分割結果,構建特征向量;再次,選擇分類器對影像進行分類;再次,對分類結果進行后處理及質量評價,對于精度較差的結果,重新優化影像分割參數或調整分類器參數.通過將人機交互和自動計算相結合,不僅降低地物信息識別和提取的錯誤,還可提高信息提取效率. 3.2.2 質量評價方法 針對任務領取人提交的影像解譯結果,采用定性和定量相結合的方式進行數據質量評價.首先由GSCloud平臺專家利用同一區域多時期解譯結果以及OpenStreetMap數據進行綜合評價,評價指標選擇準確性、完整性和一致性.OpenStreetMap為由公眾編輯的全世界地圖,數據類型包括點、線、面數據.其中,點數據為感興趣區;線數據包括道路、水系、鐵路等;面數據包括土地利用數據、自然地物、居民區等,其數據精度與專業數據相當[43].通過疊加遙感影像、多時期數據結果以及OpenStreetMap數據檢查數據的拓撲關系、位置和屬性信息,并統計數據質量問題和誤差信息.定量評價步驟為: 1) 采用規則采樣與選擇性采樣相結合的方式對研究區進行驗證點的混合采樣,即在規則采樣的基礎上再根據定性評價的統計信息對研究區易出現提取信息誤差的區域增加采樣點; 2) 人工標記采樣點真實地物信息作為參考數據,并基于混淆矩陣對分類結果進行精度評價.混淆矩陣是一個用于表示分為某一土地利用類型的像元個數與地面檢驗為該類別數的比較陣列.矩陣中的列代表參考數據,行代表數據分類結果的土地利用類型,如表1所示. 3) 根據混淆矩陣計算總體分類精度.總體精度(overall accuracy)為被正確分類的像元總和除以總像元數,計算方法如下: (4) 其中,k為類別數,Ni i為第i類土地利用信息提取正確的像元數;N為影像的像元總數.規定總體精度大于85%的結果為合格結果. Table 1 The Confusion Matrix 表1 混淆矩陣 3.3 結 果 從2015年5月至今,基于地理空間數據云平臺累計擬定并發布基于Landsat影像的遙感信息提取任務共36個.GSCloud是一個基于云計算技術的海量地學數據資源查詢、下載、在線處理和可視化的服務平臺.經過對遙感數據的長期整理、存儲與處理,GSCloud已積累了成規模的遙感數據資源,包括LANDSAT,MODIS,Sentinel,EO-1,DEM,NCAR,NOAA及LUCC數據集等,并集聚了全國14萬專業用戶.用戶主要為科研院所的研究人員和學生,以及科技公司專業技術人員,均可利用相應的技能和業余時間參與科學數據處理工作.通過該任務系列的發布,目前GSCloud初級人才庫共有專業人員1 106人,1級人才庫即任務申請人共697人,2級人才庫即最后參與數據處理共64人.其中典型的大規模遙感影像信息提取任務——青藏高原5期湖泊提取任務——報名人數為239人,經過初級評分、專家評分以及人才篩選后,共23人參與數據處理,進入2級人才庫.至此地理空間數據云已初步形成科學數據采集、數據眾包處理與人才管理的生態系統.部分眾包任務的數據處理結果已在GSCloud (http:www.gscloud.cnhelpcases)發布. 利用眾包模式將大量具有一定專業技能的公眾的時間和精力有效地聚集在一起來處理計算機難以自動化處理的大量科學數據,一直是一項復雜的挑戰.本文針對基于眾包的科學數據處理所面臨的人才評價與任務分配、數據與計算資源服務以及數據質量評價與控制3個關鍵問題進行研究,提出了人才分級管理機制、隔離容器提供數據和計算資源、以及迭代回歸的質量控制方法.并借助地理空間數據云平臺在地學領域海量數據積累、在線計算服務、以及14萬專業用戶的優勢,開展了一系列基于眾包的遙感影像信息提取實驗.結果表明,在有良好的流程機制和平臺支持下,公眾可以參與到科學大數據處理中來,并產生合格的數據結果. 為了讓更多的公眾參與到科學數據處理中來,如何進行領域知識的封裝,向公眾提供簡單可用的處理工具或任務完成方法,讓無專業知識的公眾可以參與其中將成為下一步要解決的問題.同時,建立一個公眾可以高效協作的平臺還可以加快科學數據的處理速度.可以預見,眾包在科學數據處理領域的強大優勢將逐漸顯現并最終帶來科研模式的改變. [1]Saxton G D, Oh O, Kishore R. Rules of crowdsourcing: Models, issues, and systems of control[J]. Information Systems Management, 2013, 30(1): 2-20 [2]Koulouzis S, Vasyunin D, Cushing R, et al. Cloud data federation for scientific applications[G] //LNCS 8374. Berlin: Springer, 2014: 13-22 [3]Liu Shaowei, Kong Lingmei, Ren Kaijun, et al. A two-step data placement and task scheduling strategy for optimizing scientific workflow performance on cloud computing platform[J]. Chinese Journal of Computers, 2011, 34(11): 2121-2130 (in chinese)(劉少偉, 孔令梅, 任開軍, 等. 云環境下優化科學工作流執行性能的兩階段數據放置與任務調度策略[J]. 計算機學報, 2011, 34(11): 2121-2130) [4]Juve G, Rynge M, Deelman E, et al. Comparing futuregrid, Amazon EC2, and open science grid for scientific workflows[J]. Computing in Science and Engineering, 2013, 15(4): 20-29 [5]Berriman B, Deelman E, Juve G, et al. High-performance compute infrastructure in astronomy: 2020 is only months away[J]. Astronomical Data Analysis Software and Systems XXI, 2012, 461: 91-94 [6]Kulkarni A P, Can M, Hartmann B. Turkomatic: Automatic recursive task and workflow design for mechanical turk[C] //Proc of CHI’11 Extended Abstracts on Human Factors in Computing Systems. New York: ACM, 2011: 2053-2058 [7]Liu J, Pacitti E, Valduriez P, et al. A survey of data-intensive scientific workflow management[J]. Journal of Grid Computing, 2015, 13(4): 457-493 [8]Bernstein A, Klein M, Malone T W. Programming the global brain[J]. Communications of the ACM, 2012, 55(5): 41-43 [9]Howe J. The rise of crowdsourcing[J]. Wired Magazine, 2006, 14(6): 1-5 [10]Schenk E, Guittard C. Towards a characterization of crowdsourcing practices[J]. Journal of Innovation Economics & Management, 2011, 7(1): 93-107 [11]Wei Tongqi, Jiang Tao, Tao Siyu, et al. Science sourcing—A new model of scientific cooperration[J]. Scientific Management Research, 2015, 33(2): 16-19 (in chinese)(衛垌圻, 姜濤, 陶斯宇, 等. 科研眾包——科研合作的新模式[J]. 科學管理研究, 2015, 33(2): 16-19) [12]See L, Comber A, Salk C, et al. Comparing the quality of crowdsourced data contributed by expert and non-experts[J]. PLoS ONE, 2013, 8(7): 1-11 [13]Source J P C. Citizen science: Can volunteers do real research?[J]. BioScience, 2008, 58(3): 192-197 [14]Smith A M, Lynn S, Lintott C J. An introduction to the zooniverse[C] //Proc of the 1st AAAI Conf on Human Computation and Crowdsourcing. Palo Alto, CA: AAAI, 2013 [15]Arganda-Carreras I, Turaga S C, Berger D R, et al. Crowdsourcing the creation of image segmentation algorithms for connectomics[J]. Frontiers in Neuroanatomy, 2015, 9: 1-13 [16]Kittur A, Smus B, Khamkar S, et al. Crowdforge: Crowdsourcing complex work[C] //Proc of the 24th Annual ACM Symp on User Interface Software and Technology. New York: ACM, 2011: 43-52 [17]Simperl E. How to use crowdsourcing effectively: Guidelines and examples[J]. LIBER Quarterly, 2015, 25(1): 18-39 [18]Brabham D C. Crowdsourcing as a model for problem solving an introduction and cases[J]. Convergence: The International Journal of Research into New Media Technologies, 2008, 14(1): 75-90 [19]Boudreau K, Lakhani K. Using the crowd as an innovation partner[J]. Harvard Business Review, 2013, 91(4): 60-69 [20]DiPalantino D, Vojnovic M. Crowdsourcing and all-pay auctions[C] //Proc of the 10th ACM Conf on Electronic Commerce. New York: ACM, 2009: 119-128 [21]Harris C. You’re hired! An examination of crowdsourcing incentive models in human resource tasks[C] //Proc of the Workshop on Crowdsourcing for Search and Data Mining (CSDM) at the 4th ACM Int Conf on Web Search and Data Mining (WSDM). New York: ACM, 2011: 15-18 [22]Huberman B A, Subrahmanyam A, Romero D M, et al. Crowdsourcing, attention and productivity[J]. Journal of Information Science, 2009, 35(6): 758-765 [23]Howe J. Crowdsourcing: Why the power of the crowd is driving the future of business[M]. Danvers, MA: Crown Business, 2009 [24]Xia Enjun, Zhao Xuanwei, Li Sen. Current situation and trend of overseas crowdsourcing research[J]. Technology & Economy, 2015, 34(1): 28-36 (in chinese)(夏恩君, 趙軒維, 李森. 國外眾包研究現狀和趨勢[J]. 技術經濟, 2015, 34(1): 28-36) [25]Reed J, Raddick M J, Lardner A, et al. An exploratory factor analysis of motivations for participating in Zooniverse, a collection of virtual citizen science projects[C] //Proc of the 46th Hawaii International Conf on System Sciences (HICSS). Piscataway, NJ: IEEE, 2013: 610-619 [26]Greenhill A, Holmes K, Lintott C, et al. Playing with science: Gamised aspects of gamification found on the online citizen science project-zooniverse[J]. Game-On, 2014, (11): 15-24 [27]Allahbakhsh M, Benatallah B, Ignjatovic A, et al. Quality control in crowdsourcing systems: Issues and directions[J]. IEEE Internet Computing, 2013, 17(2): 76-81 [28]Dawid A P, Skene A M. Maximum likelihood estimation of observer error-rates using the EM algorithm[J]. Applied Statistics, 1979, 28(1): 20-28 [29]Ipeirotis P G, Provost F, Wang J. Quality management on Amazon mechanical turk[C] //Proc of the ACM SIGKDD Workshop on Human Computation. New York: ACM, 2010: 64-67 [30]Sorokin A, Forsyth D. Utility data annotation with Amazon mechanical turk[J]. Urbana, 2008, 51(61): 820 [31]Kittur A, Nickerson J V, Bernstein M, et al. The future of crowd work[C] //Proc of the 2013 Conf on Computer Supported Cooperative Work. New York: ACM, 2013: 1301-1318 [32]Eickhoff C, de Vries A. How crowdsourcable is your task[C] //Proc of the Workshop on Crowdsourcing for Search and Data Mining (CSDM) at the 4th ACM Int Conf on Web Search and Data Mining (WSDM). New York: ACM, 2011: 11-14 [33]Ho C J, Vaughan J W. Online task assignment in crowdsourcing markets[C] // Proc of the 26th AAAI Conf on Artificial Intelligence. Palo Alto, CA: AAAI, 2012: 45-51 [34]Wang R Y, Strong D M. Beyond accuracy: What data quality means to data consumers[J]. Source Journal of Management Information Systems, 1996, 12(4): 5-33 [35]Bello O M, Aina Y A. Satellite remote sensing as a tool in disaster management and sustainable development: Towards a synergistic approach[J]. Procedia-Social and Behavioral Sciences, 2014, 120: 365-373 [36]Xu Y, Liu Y. Monitoring the near-surface urban heat island in Beijing, China by satellite remote sensing[J]. Geographical Research, 2015, 53(1): 16-25 [37]Qin Y, Xiao X, Dong J, et al. Mapping paddy rice planting area in cold temperate climate region through analysis of time series Landsat 8 (OLI), Landsat 7 (ETM+) and MODIS imagery[J]. ISPRS Journal of Photogrammetry and Remote Sensing, 2015, 105(2016): 220-233 [38]Otukei J R, Blaschke T. Land cover change assessment using decision trees, support vector machines and maximum likelihood classification algorithms[J]. International Journal of Applied Earth Observation and Geoinformation, 2010, 12(Suppl): 27-31 [39]Jung H S, Park S W. Multi-sensor fusion of landsat 8 thermal infrared (TIR) and panchromatic (PAN) images[J]. Sensors, 2014, 14(12): 24425-24440 [40]Fritz S, See L, Mccallum I, et al. Mapping global cropland and field size[J]. Global Change Biology, 2015, 21(5): 1980-1992 [41]Blaschke T. Object based image analysis for remote sensing[J]. ISPRS Journal of Photogrammetry and Remote Sensing, 2010, 65(1): 2-16 [42]Vieira M A, Formaggio A R, Rennó C D, et al. Object based image analysis and data mining applied to a remotely sensed Landsat time-series to map sugarcane over large areas[J]. Remote Sensing of Environment, 2012, 123: 553-562 [43]Haklay M. How good is volunteered geographical information? A comparative study of OpenStreetMap and ordnance survey datasets[J]. Environment and Planning B: Planning and Design, 2010, 37(4): 682-703 Zhao Jianghua, born in 1989. PhD candidate from University of Chinese Academy of Sciences. Her main research interests include massive data processing, data mining and analysis, Web mining. Mu Shuting, born in 1993. MSc. Her main research interests include big data analysis for social and crowdsourcing. Wang Xuezhi, born in 1979. PhD, associate professor. His main research interests include massive temporal-spatial data processing and analysis. Lin Qinghui, born in 1979. PhD, associate professor. Her main research interests include massive data resource aggregation, analysis, and sharing. Zhang Xi, born in 1982. PhD, professor. His main research interests include big data analysis for social, business and science, crowdsourcing, and data policy and practice. Zhou Yuanchun, born in 1975. PhD, professor. Senior Member of CCF. His main research interests include data mining, and big data processing. Tong Y, Cao C C, Zhang C J, et al. Crowdcleaner: Data cleaning for multi-version data on the Web via crowdsourcing[C]Proc of the 30th IEEE Int Conf on Data Engineering. Piscataway, NJ: IEEE, 2014: 1182-1185℃ Crowdsourcing-Based Scientific Data Processing Zhao Jianghua1,2, Mu Shuting3, Wang Xuezhi1, Lin Qinghui1, Zhang Xi3, and Zhou Yuanchun1 1(ComputerNetworkInformationCenter,ChineseAcademyofSciences,Beijing100190)2(UniversityofChineseAcademyofSciences,Beijing100049)3(CollegeofManagementandEconomics,TianjinUniversity,Tianjin300072) The ultimate goal of acquiring scientific data is to extract useful knowledge from the data according to specific needs and apply the knowledge to specific areas to help decision makers make decisions. As the volume of scientific data becomes larger, and the structure becomes more complex, such as semi or unstructured data, it is difficult to automatically process these data by computers. By incorporating human computing power in data processing, crowdsourcing has become one of the solutions for big scientific data processing. By analyzing the characteristics of crowdsourcing scientific data processing tasks to citizens, this paper studies three aspects, which are talent selection mechanism, task execution mode, and result assessment strategy. Then a series of crowdsourcing-based remote sensing imagery interpretation experiments are carried out. Results show that not only scientific data can be processed through crowdsourcing paradigm, but also by designing reasonable procedure, high-quality data can be obtained. crowdsourcing; scientific big data; data processing; talent selection; quality assessment 2016-11-15; 2016-12-30 國家重點研發計劃項目(2016YFB1000600,2016YFB0501900);國家自然科學基金項目(71571133);中國科學院戰略性先導科技專項(XDA06010307) This work was supported by the National Key Research Program of China (2016YFB1000600, 2016YFB0501900), the National Natural Science Foundation of China( 71571133), and the Strategic Priority Research Program of the Chinese Academy of Sciences (XDA06010307). 周園春(zyc@cnic.cn) TP391
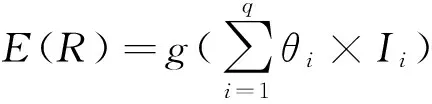
3 眾包案例研究
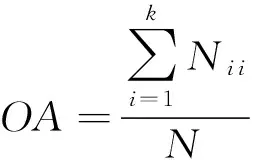
4 結 論






猜你喜歡
心理學報(2022年4期)2022-04-12 07:38:02
石油瀝青(2021年4期)2021-10-14 08:50:44
水泵技術(2021年3期)2021-08-14 02:09:20
小小藝術家(2019年6期)2019-06-24 17:39:44
今古傳奇·故事版(2016年15期)2016-09-07 06:57:32
中國慣性技術學報(2015年1期)2015-12-19 13:12:17
小雪花·成長指南(2015年3期)2015-05-04 00:04:37
中國教育技術裝備(2015年19期)2015-03-01 02:43:07
測繪科學與工程(2013年3期)2013-03-11 15:07:36
俄羅斯問題研究(2012年1期)2012-03-25 09:54:51
