大數據處理平臺Spark基礎實踐研究
2017-02-23 05:45:12邱麗娟
無線互聯科技 2017年1期
關鍵詞:數據處理
邱麗娟
(廈門南洋職業學院,福建 廈門 361102)
大數據處理平臺Spark基礎實踐研究
邱麗娟
(廈門南洋職業學院,福建 廈門 361102)
Spark是主流的大數據并行計算框架。文章將通過幾段Scala腳本,演示在Spark環境下通過Map-Reduce框架處理大數據。
大數據;Spark;Map-Reduce 框架
Spark基于內存計算,提高了在大數據環境下數據處理的實時性。與很多分布式軟件系統相同,用戶可以將Spark部署在大量廉價的Linux硬件之上,形成性價比很高的計算集群。Spark提供了一個更快、更通用的數據處理平臺。和Hadoop相比,Spark可以讓程序在內存中運行時速度提升100倍,或者在磁盤上運行時速度提升10倍。在100 TB Daytona GraySort比賽中,Spark戰勝了Hadoop,它只使用了十分之一的內在,但運行速度提升了3倍。Spark也已經成為針對PB級別數據排序的最快的開源引擎。
理解Spark大數據處理,一個關鍵概念便是RDD。由于Map-Reduce Schema on Read處理方式會引起較大的處理開銷。Spark抽象出分布式內存存儲結構彈性分布式數據集RDD進行數據的存儲。RDD模型很適合粗粒度的全局數據并行計算,但不適合細粒度的、需要異步更新的計算。RDD是Spark的基本計算單元,一組RDD可形成執行的有向無環圖RDD Graph。
Spark的整體工作流程為:客戶端提交應用,主節點找到一個工作節點啟動Driver,Driver向主節點或者資源管理器申請資源,之后將應用轉化為RDD Graph,再由DAGScheduler將RDD Graph轉化為Stage的有向無環圖提交給TaskScheduler,由TaskScheduler提交任務給Executor執行。
1 計算圓周率

2 單詞計數
單詞計數是最常見的大數據處理場景,也是理解Map-Reduce的最佳范例。
所謂Map-Reduce,就是指把任意復雜的計算任務,分解為兩個函數:(1)map函數:接受一個鍵值對,值是一行數據,鍵是根據值計算獲得的哈希。map函數產生一組中間鍵值對,Map-Reduce框架會將map函數產生的中間鍵值對當中的鍵相同的值傳遞給reduce函數。(2)reduce函數:接受一個中間鍵值對,鍵是唯一的,值是一個數組。reduce對值進行歸并。
正是借助Map-Reduce框架,才解決了把計算任務“切片”交給大規模集群的問題,任務得以并行計算,最后匯總結果。這里為簡化起見,不考慮標點符號對計算結果的影響,并假設所有的單詞之間以空格間隔。

3 倒排索引
倒排索引(inverted index)源于實際應用中需要根據屬性的值來查找記錄。在索引表中,每一項均包含一個屬性值和一個具有該屬性值的各記錄的地址。由于記錄的位置由屬性值確定,而不是由記錄確定,因而稱為倒排索引。
搜索引擎的關鍵步驟便是建立倒排索引。相當于為海量的網頁做了一個索引,用戶想看與哪一個主題相關的內容,直接根據索引即可找到相關的頁面。
假設存在6篇文章,每篇文章的ID已知,文章ID與文章內容之間以Tab建間隔:

對以上文章創建倒排索引的Scala程序如下:
/*讀取數據,數據格式為一個大的HDFS文件中用 分隔不同的文件,用 分隔文件ID和文件內容,用" "分隔文件內的詞匯*/

/*將(詞,文檔ID)的數據進行聚集,相同詞對應的文檔ID統計到一起,形成(詞,"文檔ID1,文檔ID2,文檔ID3……”),形成簡單的倒排索引*/
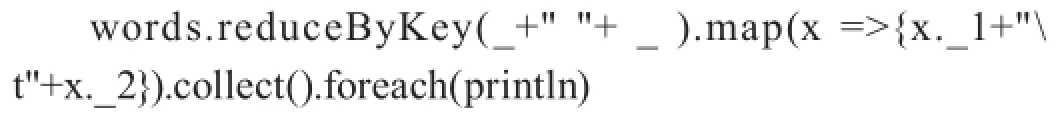
4 計算中位數
統計海量數據時,經常需要預估中位數,由中位數大致了解某列數據,做機器學習和數據挖掘的很多公式中也需要用到中位數。
假設數據按照下面的格式存儲:1 2 3 4 5 6 8 9 11 12 13 15 18 20 22 23 25 27 29
計算中位數的思路是:將整體的數據分為K個桶,統計每個桶內的數據量,然后統計整個數據量;根據桶的數量和總的數據量,可以判斷數據落在哪個桶里以及中位數的偏移量;取出這個中位數。Scala腳本如下:
Research on Spark basis practice of big data processing platform
Qiu Lijuan
(Xiamen Nanyang University, Xiamen 361102, China)
Spark is the major framework of parallel computing of big data. This article will illustrate how to process big data through Map-Reduce framework under the background of Spark by several Scala scripts.
big data; Spark; Map-Reduce framework


邱麗娟(1978— ),女,江西南昌,本科,講師;研究方向:程序設計。
猜你喜歡
中學生數理化·自主招生(2022年9期)2022-05-30 10:48:04
心理學報(2022年4期)2022-04-12 07:38:02
水泵技術(2021年3期)2021-08-14 02:09:20
電子測試(2018年4期)2018-05-09 07:28:12
當代化工研究(2016年9期)2016-03-20 16:22:13
中國慣性技術學報(2015年1期)2015-12-19 13:12:17
計算機工程(2015年4期)2015-07-05 08:28:04
西華師范大學學報(自然科學版)(2015年3期)2015-02-27 15:31:22
聯合國青年技術培訓(2014年7期)2014-04-12 00:00:00
中國質量與標準導報(2014年7期)2014-02-28 22:24:35
