基于改進的隱馬爾可夫模型在網頁信息抽取中的研究與應用
2017-02-27 10:58:42雙哲孫蕾
計算機應用與軟件 2017年2期
雙 哲 孫 蕾
(華東師范大學計算機科學技術系 上海 200241)
基于改進的隱馬爾可夫模型在網頁信息抽取中的研究與應用
雙 哲 孫 蕾
(華東師范大學計算機科學技術系 上海 200241)
信息抽取是從大量的數據中準確、快速地獲取目標信息,提高信息的利用率。考慮網頁數據的特點,提出一種適用于網頁信息抽取改進的隱馬爾科夫模型(HMM),即結合最大熵模型(ME)在特征知識表示方面的優勢,在HMM模型中加入后向依賴,利用發射單元特征來調整模型參數。改進后的HMM狀態轉移概率和觀察輸出概率不僅依賴于模型的當前狀態值,而且可以以模型的前向狀態值和后向特征值加以修正。實驗結果表明,使用改進后的HMM模型應用到網頁信息抽取中,可以有效地提高網頁信息抽取的質量。
隱馬爾可夫模型 最大熵模型 網頁信息抽取
0 引 言
隨著互聯網技術及應用的不斷成熟與深入,面對日益增多的海量網頁信息,人們需要一種自動化工具來幫助人們從中快速發現真正需要的信息,并將這些信息自動分類、提取,使其有益于信息后續的檢查比較及自動處理,由此需要相應成熟的網頁信息抽取技術從搜索引擎得到的結果網頁中抽取目標信息。網頁數據和傳統的自由文本數據相比具有半結構化、更新快、形式多樣等特點。目前涉及這一熱點研究課題的相關方法和技術有:(1) 基于包裝器生成技術適用于格式固定的網頁,但在移植及維護上較困難[1];(2) 基于NLP的信息抽取方法適用于純文本的抽取任務,但網頁數據被標簽分割無法直接使用;(3) 基于本體的信息抽取方法需要較大的成本構造本體[2-3];(4) 基于DOM樹的技術基于網頁本身的結構,其適用于相似結構的網頁,包括DSE算法[4]和MDR算法[5];(5) 大量網頁可通過讀取后臺數據庫填充到統一模板生成,從而形成了基于模板的抽取技術,但其使用范圍有限[6]。文中所研究與改進的基于隱馬爾可夫模型(HMM)的網頁信息抽取模型,具有易于建立、不需要大規模詞典和規則集、移植性好、投入成本較少等顯著優勢。然而,目前該類模型還存在著其信息抽取的準確率及效率有待進一步改進和完善的不足,其中已有的工作成果和進展,如文獻[7-9]應用HMM抽取論文頭部信息,用shrinkage改進模型概率估計,并用隨機優化技術動態選擇模型結構;文獻[10]在網頁中以語義塊作為抽取單元,并利用投票機制優化發射概率分布;文獻[11-12]在網頁中選擇功能內容塊(即邏輯內容相關聯的塊被組織在一起)抽取單元,結合VIPS和DOM等技術識別并抽取一個目標塊;文獻[13]提出的MEMM將文本詞匯本身包含的特征信息結合到馬爾科夫模型中,但MEMM只是考慮了抽象特征,并未對文本詞匯進行統計;文獻[14-16]提出并驗證了在很多應用中二階模型的有效性,若為了提高模型的描述能力而單純增加模型階數,參數空間會成指數增長,而容易引發數據稀疏等問題。
在此,提出改進的HMM用于網頁數據的有效抽取,即將抽取信息的模型擴展為二階且同時考慮文本上下文特征信息,利用最大熵模型(ME)在特征知識表示方面的優勢,在HMM模型中加入后向依賴,利用發射單元特征來調整模型參數。改進后的HMM狀態轉移概率和觀察輸出概率不僅依賴于模型的當前狀態值,而且擬進一步地利用模型的前向狀態值和后向特征值加以修正完善。從而解決了在以往的HMM中沒有考慮抽取對象的上下文特征和文本詞匯本身包含的特征信息等問題。
1 基于改進的HMM的網頁信息抽取的工作流程概述
隱馬爾可夫模型(HMM)是信息抽取的重要方法之一,文中針對HMM不足,結合網頁數據的特征,提出了改進的HMM用于網頁信息抽取。改進后的HMM充分考慮了抽取對象的上下文特征和文本詞匯本身包含的特征信息,修正了模型的轉移概率和發射概率(即在模型訓練階段利用最大熵原理優化了模型參數;在模型解碼階段讓改進的viterbi算法更有效地完成信息抽取)。文中所研討的網頁信息抽取的主要方法和技術流程如圖1所示,其中:(1) 數據預處理:依據所處理數據的特征,將數據劃分為分組序列;(2) 初始化模型:確定模型的狀態集和模型的拓撲結構;(3) 模型訓練:在訓練集中使用ML算法[15]和與最大熵相關的GIS算法[13]來訓練獲取模型的參數;(4) 完成信息抽取:采用改進的viterbi算法求最佳狀態標記序列,結合標注結果以結構化形式存入數據庫表中。

圖1 基于HMM信息抽取主要執行過程
2 基于改進的HMM 的網頁信息抽取的功能剖析
2.1 網頁數據準備
2.1.1 數據預處理
網頁信息抽取預處理就是依據所處理數據的特征選取基本抽取單元。網頁中數據被HTML標簽、分隔符等元素分割成一個個的語義塊[10],使得屬于同一個狀態的內容將以很大的概率組織在同一個語義塊內,文中保留了HTML標簽和分隔符是為了更易于將邏輯相關的內容組織在一起以形成語義塊分組。文中采用語義塊分組作為觀察序列的基本抽取單元,如此同類別的數據被組織在一起,明顯比以單個單詞為抽取單元的效率更高。所以文中基于文獻[10]語義塊分組的思想對網頁數據進行預處理,形成分組序列。并將數據預處理后的格式設定為:原始序列Raw、特征序列Type、狀態序列State[17]。
2.1.2 網頁信息抽取模型狀態集的改進描述
值得說明的是:為了對預處理后的分組序列標注相對應的狀態序列state,需要構造相對應的狀態集,而狀態集的選擇對最終抽取結果具有重要的影響。在構造一個基于HMM的網頁信息抽取模型時,首先要確定模型的結構,即應該包含多少個狀態及各個狀態之間如何轉換,一個理想的初始模型是一個狀態對應一個標記類型,且任意兩個狀態間可以相互轉移。但是從文獻[7]的結論中我們得知這種方式并不是最優的,而一個標記類型定義多個狀態又會增加模型復雜度。另外若兩個單詞以相同的頻率出現在同一個狀態內,目前一般的做法是讓這兩個單詞具有相同的重要程度,但是這種做法卻忽略了一個重要的信息,那就是在同一個狀態內多個單詞具有順序或前后關系。在此,為每一個標記類型定義兩個狀態:開始狀態(start)和剩余狀態(rest)。如論文的“title”標記,就包括:title.s和title.r。這種結構十分適合網頁數據的特點,如“地址”標簽addr.s之后就會是具體的地址addr.r。在此提出的模型中除了包含正常狀態外,還包含一些特殊的狀態標記如start、end。
2.2 信息抽取模型的訓練階段
模型訓練階段,在完全標記的樣本集中給定了觀察序列O和其相對應的狀態序列Q,為了確定釋放該觀察序列的模型λ且使該觀察序列的釋放概率P(O|λ)最大,通常采用最大似然估計(ML)算法中相關的統計公式[15]訓練獲取HMM的參數集。
傳統HMM是能隨機狀態轉移并輸出符號的有限狀態自動機[7]如圖2(a),其包括觀察層和隱藏層,觀察層是待識別的觀察序列,隱藏層即狀態序列是一個馬爾可夫過程。文中利用最大熵模型(ME)在特征知識表示方面的優勢,考慮被抽取對象上下文特征信息且同時增加模型階數以增加模型的描述能力后,在模型中加入了前向、后向依賴。改進的HMM主要擴展了兩個假設條件:(1) 改進的HMM在t時刻的狀態不僅由t-2和t-1時刻的狀態決定,且由t和t+1時刻觀察序列所具有的特征決定;(2) 在t時刻輸出觀察值的概率不僅依賴于t時刻所處的狀態而且依賴于t-1時刻的狀態。

圖2 HMM模型的改進
在利用被抽取對象特征方面,最大熵原理提供一種方法,可以集成各種特征與規則到一個統一的框架下。如文獻[13]提出的MEMM是一個指數模型,其將被抽取對象的抽象特征作為輸入,并在馬爾科夫狀態轉移的基礎上選擇下一個狀態,其結構接近于有窮狀態自動機如圖2(b)。加入特征集合后影響了狀態之間的關聯,因而需用狀態轉移概率矩陣和特征-狀態轉移概率矩陣來描述新的狀態之間的關聯。從觀察序列相鄰兩項中提取數據特征,即t和t+1時刻相鄰兩項觀察所具有的特征部分決定了t時刻所處的狀態,以此可以從觀察序列中得到模型對后向數據特征的依賴,如圖2(c)所示。在現實應用中可根據具體的應用領域而構造不同的特征集合,如在論文頭部信息抽取中是否大寫字母開頭、是否含有人名或人名縮寫、是否是數字、是否含有@或email等。
改進的HMM與傳統的HMM訓練獲取參數集對比如表1所示。
需要特別說明的是:
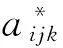
(1)
其中,r=∑k[λ×aijk+ (1-λ)×∑f(Cf,k× ff,k((ot,ot + 1),st))]為歸一化參數;引用文獻[13,18]中論述的最大熵原理在NLP各分支應用中的公式,在此在給定的特征集上定義一個二值函數如下式:
fi,j((ot,ot+1),st)=
(2)
接著,基于最大熵思想及上述定義,在改進后的HMM中需要構造一個特征-狀態轉移的概率矩陣,即式(1)中參數C就是利用最大熵原理從觀察值序列的特征中獲取的特征-狀態轉移概率矩陣C={Ci,j}NF×NS,其中元素Ci,j就是從特征i到狀態j的概率,滿足條件:∑jCi,j= 1,其中NF是特征的個數,NS是狀態的個數。在訓練階段對各個觀察序列進行特征提取,在完全標記的訓練數據中每個觀察特征都對應一個狀態,因此可以利用改進的GIS算法統計獲取特征-狀態轉移概率矩陣,算法過程如圖3所示。

圖3 利用改進的GIS算法求特征-狀態概率轉移矩陣方法流程
2) 在使用最大熵原理統計被抽取對象的特征信息方面,相比于MEMM沒有統計詞匯本身信息[13],但在改進后的模型中使用符號輸出概率矩陣統計詞匯本身信息,且改進后的模型t時刻的觀察值依賴于t-1和t時刻的狀態如式(2)所示。
2.3 完成信息抽取階段
為了完成信息抽取需要解決的是解碼問題,即給定訓練得到的模型參數λ和觀察值序列O,求與觀察值序列對應且使得P(Q|O,λ)最大的最佳狀態序列Q,通常采用的是viterbi算法。

定義δt(i,j)為t時刻沿路徑q1,q2,…,qt-1,qt(qt-1=si,qt=sj)釋放部分觀察值序列O1,O2,…,Ot的最大釋放概率式如(3):
δt(i,j)=maxP(q1,q2,…,qt-1=Si,qt=
Sj,O1O2,…,Ot,Ot+1|λ)
(3)
通過推導可得t+1時刻路徑的最大概率如式(4):
(4)
另外,定義一個用于存儲回溯路徑的數組變量如式(5):
(5)
求最佳狀態序列的改進Viterbi算法主要實現步驟如下:
(1) 初始化:δ1(i)=πibi(Oi),Ψ1(i)=0
δ2(i,j)=πiaijbi(o1)bij(o2),Ψ2(i,j)=0
(2) 遞歸: /*模型的改進應用于此處*/
where(1≤j,k≤N&&2≤t≤T-1):
1≤i,j,k≤N,2≤t≤T-1
(3) 終結:
(4) 回溯求最佳路徑:
2.4 針對模型進一步優化的改進建議
1) 針對實際應用過程中,從訓練語料中學習模型的參數時經常需要面對訓練數據不足的情況,而使用最大似然(ML)估計模型參數時將會出現參數概率為零的情況。為避免出現上述情況使用參數平滑處理。主要的平滑技術包括:利用頻率信息進行平滑的Good-Turing;使用低階模型和高階模型的線性組合的線性插值平滑;回退低階模型近似求解的katz`s回退式平滑[8]。文中依據上述三種平滑思想,結合文獻[16]中提及的Back-off shrinkage思想,進一步改進平滑技術以適應將HMM應用到網頁信息抽取中,文中統計在全局中數據出現的次數融入平滑公式中,對狀態轉移與觀察值輸出概率進行平滑處理。如狀態轉移概率P(Si→Sj→Sk)=λ1P(Si→Sj→Sk)+λ2Pglobal(Si∪Sj∪Sk)其中,Pglobal(si∪sj∪sk)是三者在整個訓練集中出現的概率;對觀察值發射概率P(Vm|Si→Sj)=λ1P(Vm|Si→Sj)+λ2Pglobal(Vm)其中,Pglobal(Vm)是Vm在整個訓練集中出現的概率。
2) 如何解決在測試階段出現了而在訓練階段沒有遇到的單詞的發射概率,這就是OOV(outofvocabulary)問題。文中我們將使用較有效的最小頻率法:讓fmin表示最小頻率,詞匯表中單詞在訓練數據集上的發射頻率都不會小于fmin,其他的單詞如果他們的頻率小于fmin,就會將他們標記為
3 實驗結果與分析
實驗一是模型有效性的驗證,選擇改進后的HMM與一階HMM(基本抽取單元分別選擇單詞和語義塊)、二階HMM,在語料庫DBLP[19]和CORA[20]上的對比結果。文中選擇F1參數衡量信息抽取模型的質量,F1參數綜合了準確率和召回率的結果,F1參數越大說明模型的質量越好,實驗結果如圖4所示。由實驗結果可知在考慮了前向和后向依賴的情況下各個狀態的抽取質量均有提升,而Author、Data、Email等項由于較為明顯的特征信息可以取得明顯的效果。而某些數據項由于并非頻繁出現或特征不明顯而使得結果并沒有較大的改善。試驗中還比對了采用語義塊后的效果,由于減少了將單個單詞錯誤地分到其他狀態的概率,而抽取結果有明顯提升。

圖4 模型抽取結果質量對比
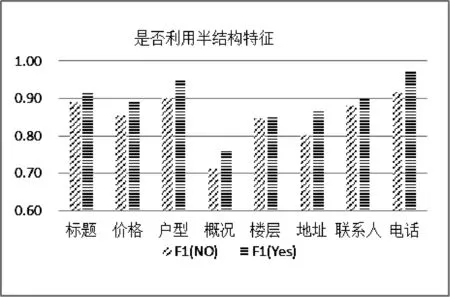
圖5 網頁數據集上抽取結果對比
4 結 語
作為NLP的重要分支,信息抽取相對信息檢索更深層次的數據挖掘,在海量信息的時代其研究價值越來越受到重視。文中結合最大熵原理利用數據特征信息改進HMM,在改進后的HMM中有效地考慮了模型前向依賴和后向依賴。結合網頁數據特征,提出基于改進的HMM的網頁信息抽取模型,對網頁數據進行信息抽取,有效地適應了網頁結構的變化、充分地利用了網頁的半結構化信息。通過對比實驗,驗證了改進后的HMM方法可以有效地實現了針對網頁數據的信息抽取,且具有更好的性能。后續研究可以著眼于:將改進后的模型應用到元數據的抽取,自動學習模型的結構,利用主動學習技術減少對標記樣本的依賴,從而可以實現模型的自動化構造。
[1]CrescenziV,MeccaG,MerialdoP.RoadRunner:towardsautomaticdataextractionfromlargewebsites[C]//Proceedingsofthe27thInternationalConferenceonVeryLargeDataBases,2001:109-118.
[2]GutierrezF,DouD,FickasS,etal.Ahybridontology-basedinformationextractionsystem[J].JournalofInformationScience,2015:1-23.
[3]ZhangN,ChenH,WangY,etal.Odaies:ontology-drivenadaptivewebinformationextractionsystem[C]//IntelligentAgentTechnology,IEEE/WICInternationalConferenceon.IEEEComputerSociety,2003:454.
[4]WangJ,LochovskyFH.Data-richsectionextractionfromHTMLpages[C]//ProceedingsoftheThirdInternationalConferenceonWebInformationSystemsEngineering.IEEEComputerSociety,2002:313-322.
[5]LiuB,GrossmanR,ZhaiY.Miningdatarecordsinwebpages[C]//9thACMSIGKDDInternationalConferenceonKnowledgeDiscoveryandDataMinig.ACMPress,2003:601-606.
[6] 楊少華,林海略,韓燕波.針對模板生成網頁的一種數據自動抽取方法[J].軟件學報,2008,19(2):209-223.
[7]SeymoreK,McCallumA,RosenfeldR.LearninghiddenMarkovmodelstructureforinformationextraction[C]//AAAIWorkshoponMachineLearningforInformationExtraction,1999:37-42.
[8]FreitagD,McCallumAK.InformationextractionwithHMMsandshrinkage[C]//AAAIWorkshoponMachineLearningforInformationExtraction,1999:31-36.
[9]FreitagD,McCallumA.InformationextractionwithHMMstructureslearnedbystochasticoptimization[C]//ProceedingsoftheSeventeenthNationalConferenceonArtificialIntelligenceandTwelfthConferenceonInnovativeApplicationsofArtificialIntelligence,2000:584-589.
[10]LaiJ,LiuQ,LiuY.WebinformationextractionbasedonhiddenMarkovmodel[C]//ComputerSupportedCooperativeWorkinDesign(CSCWD),2010 14thInternationalConferenceon.IEEE,2010:234-238.
[11]ZhongP,ChenJ.AgeneralizedhiddenMarkovmodelapproachforwebinformationextraction[C]//WebIntelligence,2006IEEE/WIC/ACMInternationalConferenceon.IEEEComputerSociety,2006:709-718.
[12]ChenJ,ZhongP,CookT.DetectingwebcontentfunctionusinggeneralizedhiddenMarkovmodel[C]//Proceedingsofthe5thInternationalConferenceonMachineLearningandApplications.IEEEComputerSociety,2006:279-284.
[13]McCallumA,FreitagD,PereiraFCN.MaximumentropyMarkovmodelsforinformationextractionandsegmentation[C]//ProceedingsoftheSeventeenthInternationalConferenceonMachineLearning,2000:591-598.
[14]MariJF,HatonJP,KriouileA.Automaticwordrecognitionbasedonsecond-orderhiddenMarkovmodels[J].IEEETransactionsonSpeech&AudioProcessing,1997,5(1):22-25.
[15]DuS,ChenT,ZengX,etal.Trainingsecond-orderhiddenMarkovmodelswithmultipleobservationsequences[C]//Proceedingsofthe2009InternationalForumonComputerScience-TechnologyandApplications.IEEEComputerSociety,2009:25-29.
[16]OjokohB,ZhangM,TangJ.AtrigramhiddenMarkovmodelformetadataextractionfromheterogeneousreferences[J].InformationSciences,2011,181(9):1538-1551.
[17]GengJ,YangJ.AUTOBIB:automaticextractionofbibliographicinformationontheweb[C]//ProceedingsoftheInternationalDatabaseEngineeringandApplicationsSymposium.IEEE,2004:193-204.
[18]BergerAL,PietraVJD,PietraSAD.Amaximumentropyapproachtonaturallanguageprocessing[J].ComputationalLinguistics,1996,22(1):39-71.
[19]DBLP:ComputerScienceBibliography[OL].http://dblp.uni-trier.de/.
[20]CORA[DS/OL].http://www.cs.umass.edu/~mccallum/data/.
[21]SmallSG,MedskerL.Reviewofinformationextractiontechnologiesandapplications[J].NeuralComputingandApplications,2014,25(3):533-548.
[22] 郭喜躍,何婷婷.信息抽取研究綜述[J].計算機科學,2015,42(2):14-17,38.
[23] 李榮,馮麗萍,王鴻斌.基于改進遺傳退火HMM的Web信息抽取研究[J].計算機應用與軟件,2014,31(4):40-44.
[24] 陳釗,張冬梅.Web信息抽取技術綜述[J].計算機應用研究,2010,27(12):4401-4405.
RESEARCH AND APPLICATION FOR WEB INFORMATION EXTRACTION BASED ON IMPROVED HIDDEN MARKOV MODEL
Shuang Zhe Sun Lei
(DepartmentofComputerScienceandTechnology,EastChinaNormalUniversity,Shanghai200241,China)
The task of information extraction is to obtain the objective information precisely and quickly from a large scale of data and improve the utilization of information. According to the characteristics of web data, an improved hidden Markov model (HMM) for web information extraction is proposed, which means combining the advantage of maximum entropy (ME) model in the representation of feature knowledge. The backward dependency assumption in the HMM is added and the model parameters are adjusted by using the characteristic of the emission unit. The state transition probability and the output probability of the improved HMM are not only dependent on the current state of the model, but also be corrected by the forward and backward state values of the historical state of the model. The experimental results show that applying the improved HMM model to web information extraction can effectively improve the quality of web information extraction.
Hidden markov model Maximum entropy model Web information extraction
2016-01-29。國家自然科學基金項目(61502170)。雙哲,碩士生,主研領域:數據挖掘,信息抽取。孫蕾,副教授。
TP3
A
10.3969/j.issn.1000-386x.2017.02.007
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
中華手工(2017年2期)2017-06-06 23:00:31
光學精密工程(2016年6期)2016-11-07 09:07:19
中外會展(2014年4期)2014-11-27 07:46:46
河南科技(2014年23期)2014-02-27 14:19:15
