醫學影像云存儲模型的研究與設計
2017-02-27 10:58:45齊來軍周麗娟任仲山
計算機應用與軟件 2017年2期
齊來軍 周麗娟* 任仲山,3
1(首都師范大學信息工程學院 北京 100048)2(成像技術高精尖創新中心 北京 100190)3(中國科學院軟件研究所 北京 100190)
醫學影像云存儲模型的研究與設計
齊來軍1,2周麗娟1,2*任仲山1,2,3
1(首都師范大學信息工程學院 北京 100048)2(成像技術高精尖創新中心 北京 100190)3(中國科學院軟件研究所 北京 100190)
為解決早期云計算模型對醫學小文件存儲出現的單節點問題,數據高冗余造成數據的不一致性以及檢索效率低等方面的問題,提出一種新型云存儲模式。模型中,引入BWFS算法實現優化海量醫學小文件序列化合并,優化糾刪碼算法實現數據塊編碼,減少數據塊的冗余存儲,而且引入位圖索引技術與HBase索引結合形成新型并行索引策略,優化HBase主索引的缺點。實驗表明,新型存儲模型通過使用BWFS算法和糾刪碼技術減少了集群主控節點的內存消耗,在保證數據快速恢復的情況下,減少了集群數據的冗余存儲,并行索引技術提高了醫學數據影像的檢索效率。
醫學影像數據 云存儲 并行索引 編碼技術
0 引 言
近年來海量數據急劇增長,云計算技術應用到互聯網、金融、醫學等各大研究領域。醫學影像是病人相關疾病檢測的載體,醫護人員通過對病人的影像進行檢測與診斷。互聯網時代,借助云存儲模型實現海量醫學數據的實時存儲和處理。然而,傳統的云存儲模型中存在大量的醫學小文件,數據冗余存儲,索引復雜等瓶頸。因此,需要對傳統的云平臺進行優化升級。
1 相關工作
本文圍繞項目“第三方專科影像服務關鍵技術研究與應用示范”展開,關注醫學影像數據分布式存儲關鍵技術研究[1]。眼科醫學影像數據屬于小文件范疇,海量小文件上傳到HDFS中會造成主存儲節點內存開銷的瓶頸,數據冗余存儲,并且HBase檢索效率低等。研究內容主要針對當前項目出現的問題進行優化和改造。首先,針對醫學影像數據小文件的特點,提出了BWFS算法,該算法以影像的容量為權重,為其分配合理的序列化進程,實現小文件的快速合并;其次,在數據存儲方面,舍棄HDFS的備份機制,采用數據編碼規范技術,對數據塊進行編碼,優化數據塊的冗余存儲;最后,在數據檢索方面,考慮到冷熱數據因素對檢索效率的影響,構造bitmap索引與HBase索引結合的雙重索引,提高了海量醫學數據檢索效率。
2 數據云存儲模型
2.1 影像數據云平臺研究
Hadoop平臺提供的HDFS適合存儲大數據文件,但不適合存儲小文件和大量隨機讀寫的應用場景。為滿足醫學影像數據中心的海量圖像的存儲和檢索要求,針對小文件處理,數據容災技術以及數據檢索這些瓶頸問題,設計了一種新型的存儲模型[2],提供了醫學影像“在線-近線”的二極存儲架構,提高了醫學數據的可用性。大型醫院依然保留傳統的PACS的在線數據,確保影像診斷業務的性能和連續性,近線和離線數據可遠程存儲在云平臺影像數據中心。醫學系統架構分成三層,底層是數據存儲層[3];中間層是數據優化層;上層是文件訪問組層,封裝了客戶端數據存儲和檢索請求服務。為此,眼科云存儲平臺總體集群環境結構如圖1所示。

圖1 醫療云存儲平臺總體集群結構示意圖
服務訪問層:傳統的醫療設備、PACS系統通過API服務改造后通過WebService服務實現了與云接入;中間優化層實現數據的緩存處理和小文件的序列化操作,形成序列化大文件,降低了NameNode節點的內存消耗;存儲層首先通過數據編碼規范技術,實現對醫學數據塊的編碼,形成校驗碼數據塊。在保證數據快速檢索的情況下,優化了HDFS的冗余存儲;同時優化數據索引,實現了對冷熱醫學數據索引的雙重存儲,便于醫學影像數據的存儲和檢索。
2.2 醫療影像云存儲技術架構
根據“第三方專科影像服務關鍵技術研究與應用示范”的應用需求,結合云計算技術的發展。醫學影像數據云存儲模型基于Hadoop開源架構,并對其進行優化整合,項目中利用Hadoop平臺實現了計算資源、內存、硬盤、網絡等資源的池化。同時應用中從數據緩存,數據冗余存儲和數據索引三方面進行優化和改造,具體的云數據存儲技術架構如圖2所示。
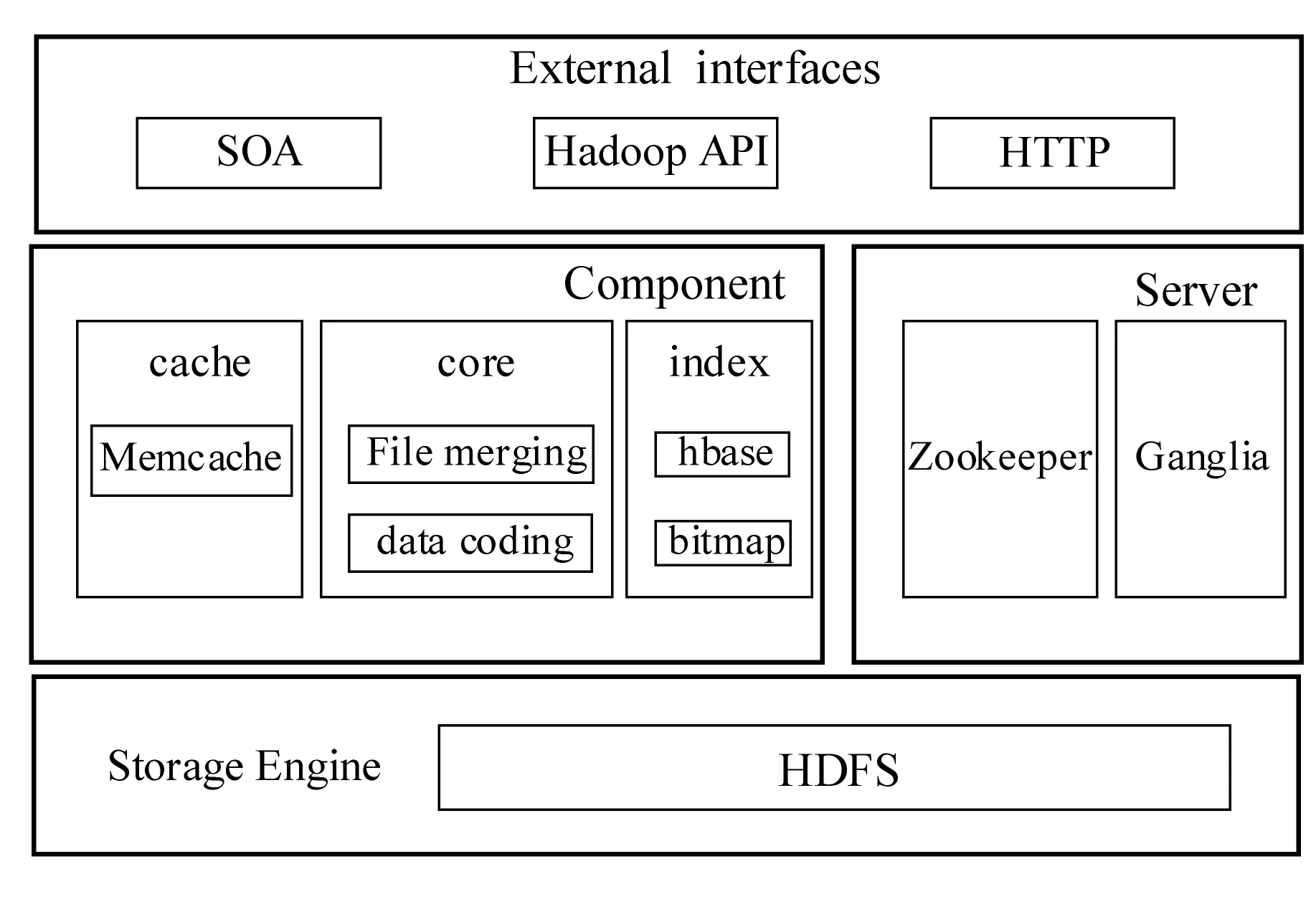
圖2 海量醫療數據云存儲技術架構圖
由圖2所述,項目主要對傳統的云存儲模型進行三方面的優化,首先為醫學小文件處理提供了BWFS文件序列化算法,實現文件的歸并化處理[4];其次構建了雙重索引,提高了醫學文件的檢索效率;最后引入數據編碼技術,既降低數據冗余,又保證數據的一致性。
3 醫學影像文件處理技術
醫學影像數據屬于小文件范疇,且為非結構化數據類型,大小不確定,而且生成十分迅速。單次上傳需占用的元數據容量為150 KB字節[5]。過多的小文件不僅消耗大量的NameNode的節點內存,而且增加了對HDFS訪問次數,對數據的實時存儲和檢索帶來很大影響。為此,提出BWFS算法在資源池實現小文件資源序列處理[5],將批量小文件序列化成大文件。
3.1 BWFS算法思想
為解決醫學小文件上傳造成的NameNode節點消耗問題,借用BWFS算法開啟兩條序列化進程,實現小文件的合并,后續開啟第三條進程實現對合并后的文件再次序列化操作,為數據編碼提供原始數據。BWFS算法開啟兩條并行的序列進程sf1、sf2,進程池的容量為block大小(128 MB),該算法依據文件的容量為權重,為文件選擇合理的序列化進程sf進行序列化,當序列化進程達到容量時,開啟第三條進程bsf,將序列化后的文件再次進行序列化操作。在bsf進程中,當文件總容量達到或接近1280 MB時,對大文件數據的分塊和編碼,隨后上傳到HDFS中。
3.2BWFS算法內容
BWFS算法,即Big Weight File Sequence,以文件的容量為權重,在一定的時間范圍內,為文件選擇合適的進程進行序列化操作。為了更好地描述該算法,特對相關的函數進行定義。
定義1 在時間點tn,上傳容量為sn的小文件表示為fn,如式(1)表示。
fn=(tn,sn)
(1)
式中n表示第n個上傳的小文件,tn表示第n個小文件上傳的時間點,sn表示第n個文件的容量大小。因此用式(2)表示按照時間順序上傳的小文件,即:
f=(t,s)=f1,f2,…,fn
(2)
定義2 對上傳的小文件序列化歸并操作的進程稱之為小型序列化進程,用sf表示。
算法中并行開啟兩個序列化進程sf1和sf2,其容量大小為128 MB。小文件上傳后,進程sf1和sf2獲取小文件的容量大小和自身剩余容量的大小這因素為小文件選擇合理的序列化進程進行序列化操作。小文件在序列化資源池中進行序列化描述如圖3所示。
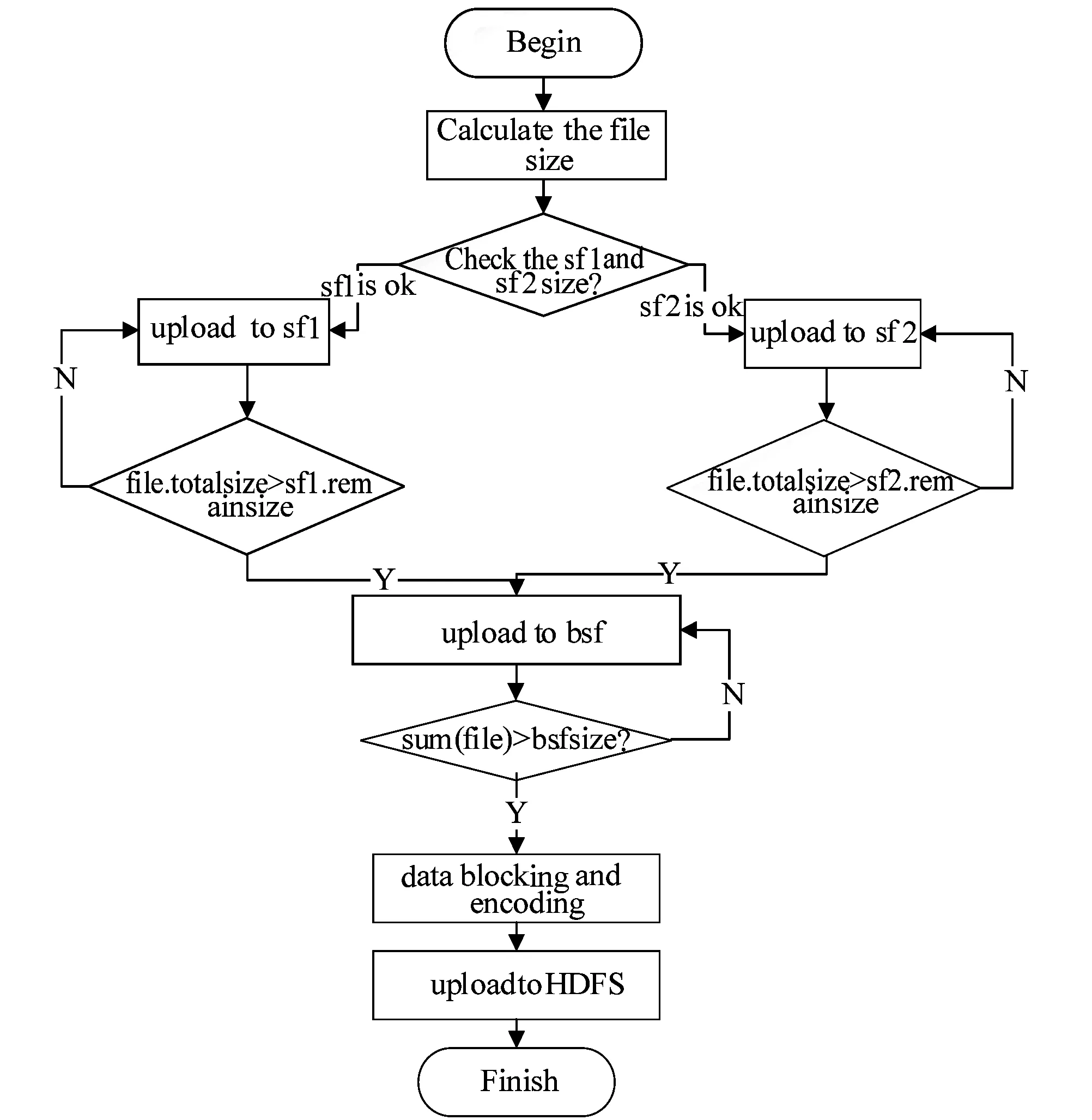
圖3 醫學小文件序列化流程圖
定義3 序列化進程sf1或sf2達到其容量時,將序列化后小文件上再次序列化的進程稱之為大型序列化進行,用bsf表示。
算法中此進程主要實現將序列化后的小文件再次進行序列化操作,一方面優化了小型序列化操作,另一方面,形成了適合分布式文件系統block的大文件,減少了對HDFS的訪問次數。
結合上文的序列化合并算法的描述和其流程的設計,基于BWFS算法的醫學小文件序列化合并的核心執行流程如下:
1. 初始化進程sf1和sf2,設置進程容量為128 MB。
2. 上傳文件f1,在sf1和sf2剩余容量相等的條件下,默認將文件上傳到sf1,sf2進程仍處于空閑等待狀態。
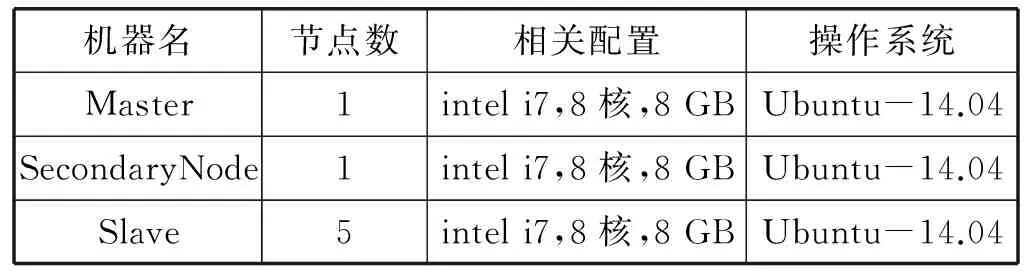
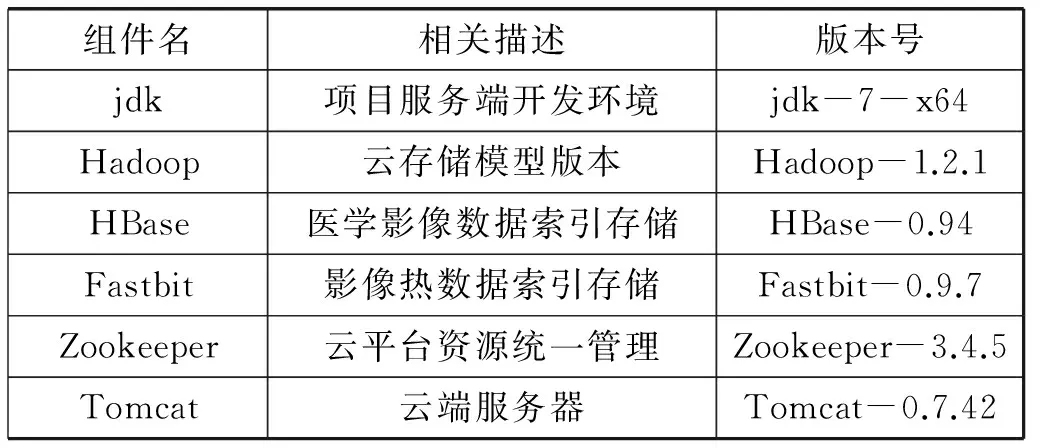
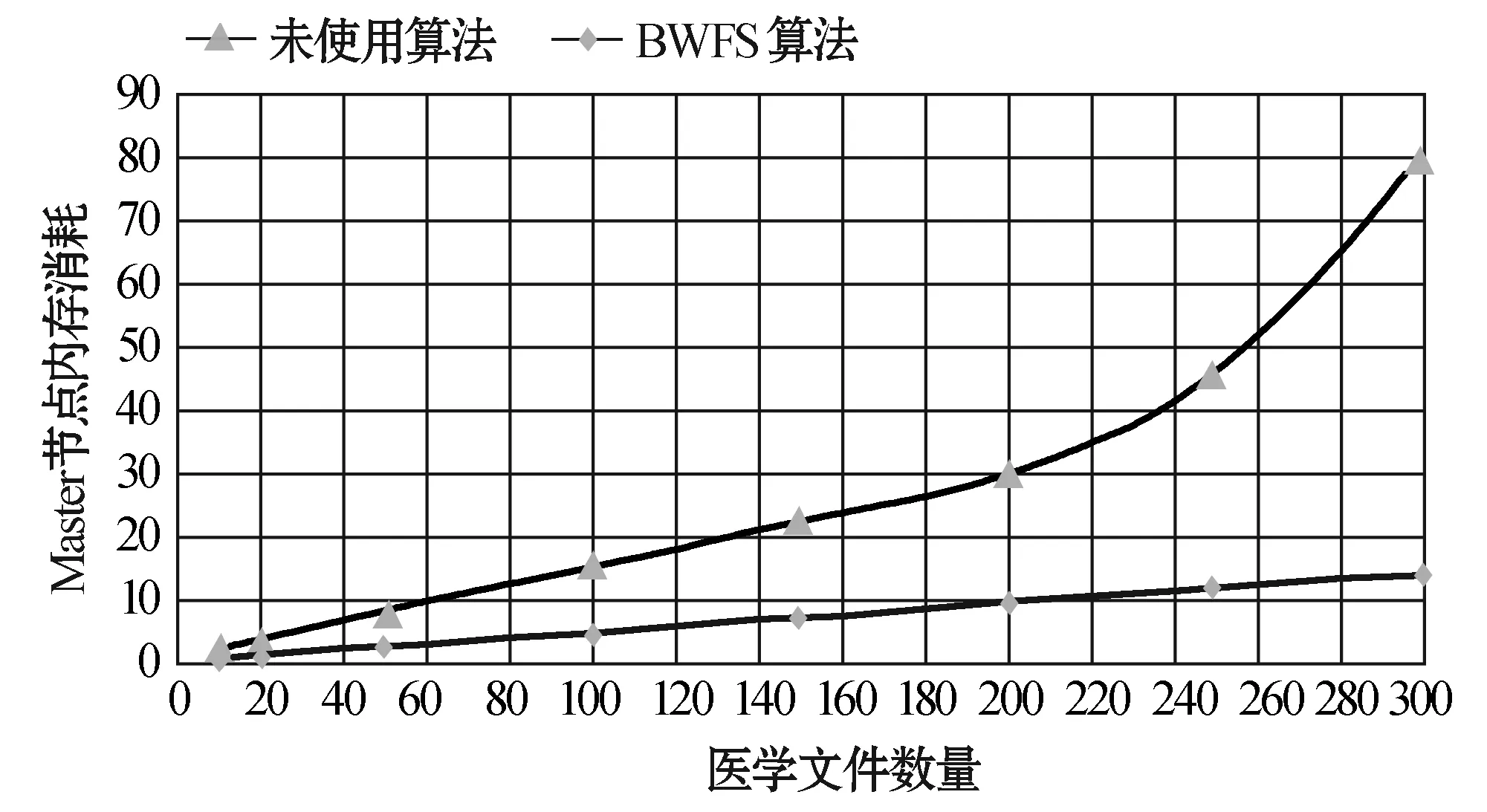
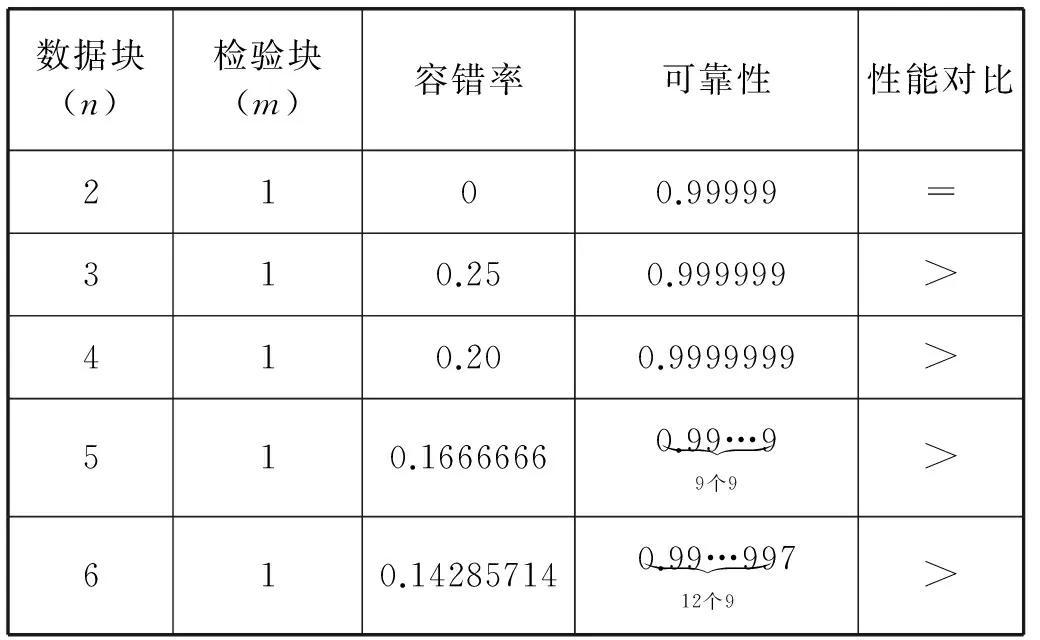
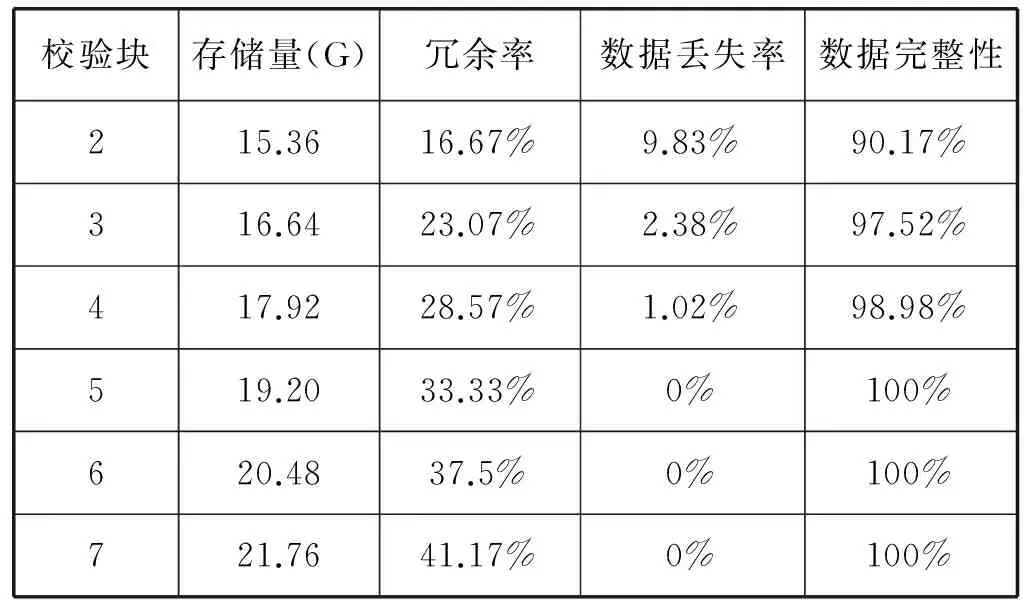
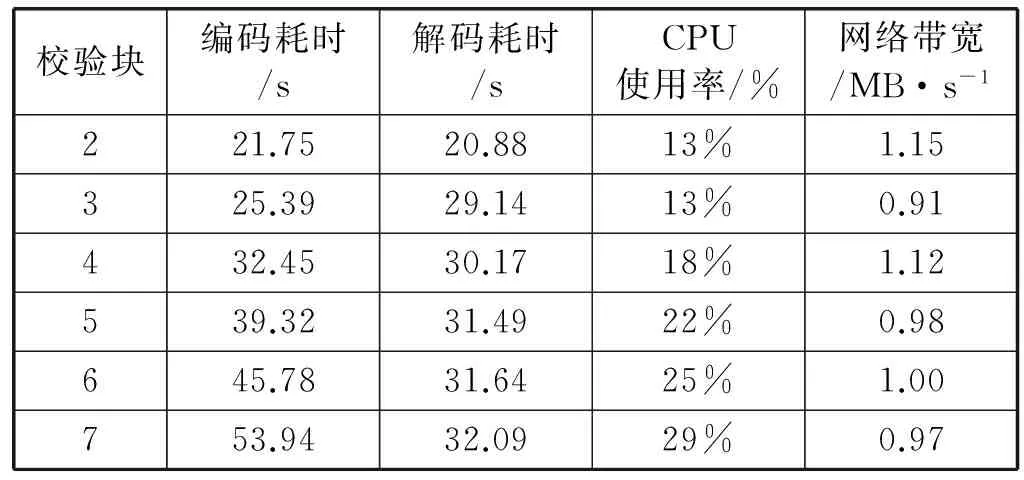
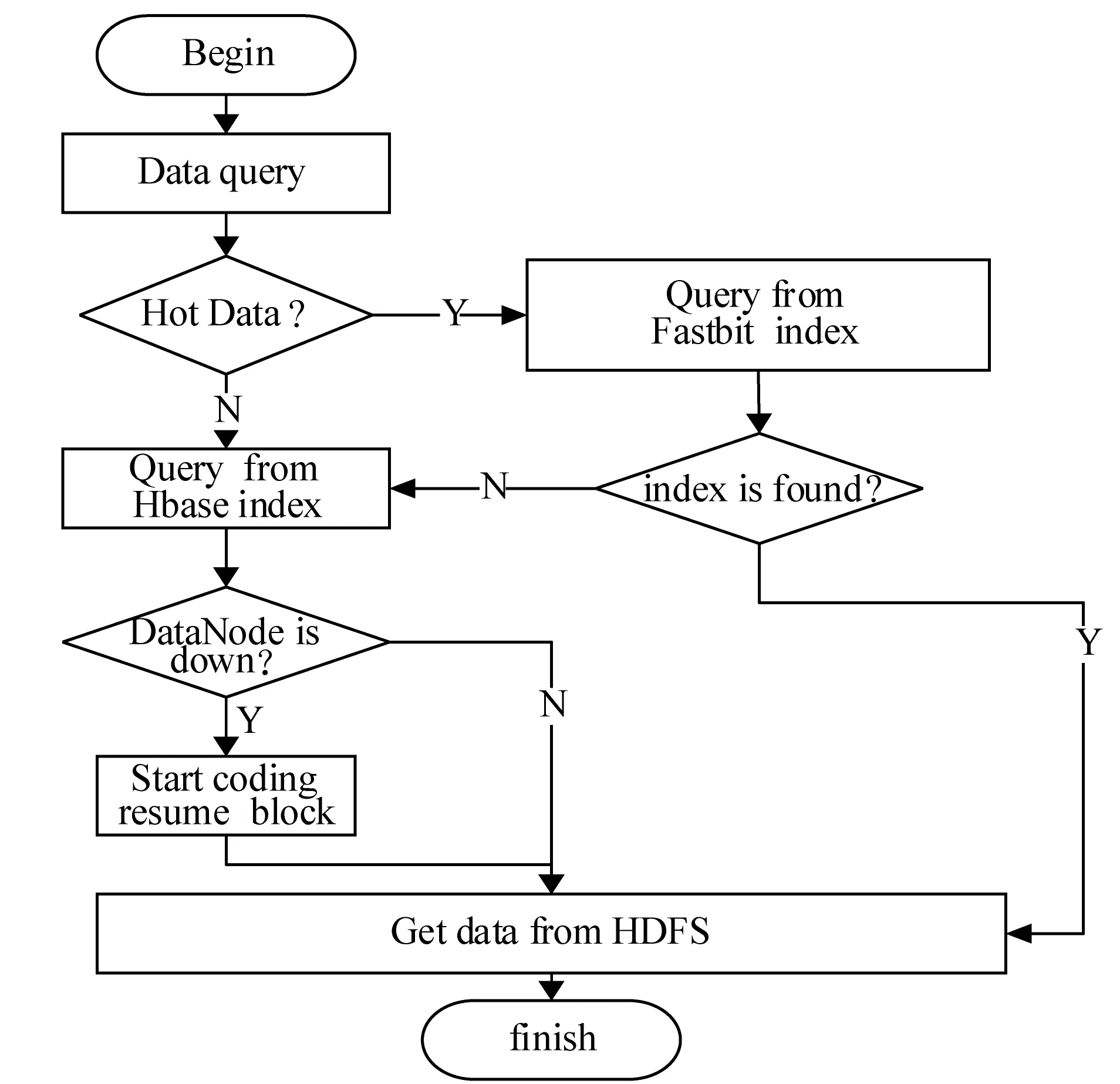
3. 后續小文件f2上傳,判斷s2+s1與sf1.remainsize大小,ifs2+s1 4. 文件f3上傳,假設在f2上傳到sf2中,需求解s3+s1,s3+s2大小,并與sf1和sf2剩余容量進行比較,若s3+s1 圖4 小文件上傳到bsf進程流程示意圖 5. 重復執行步驟4,為后續的小文件選擇合適的進程進行序列化操作。 6. 求解bsf(即big sequence file)中上傳的醫學影像小文件f1,f2,…,fk,…,fn-1對應的s1,s2,…,sk,…,sn-1的數據和與進程bsf的容量進行比較,ifs1+s2+…+sn-1 BWFS算法設計的核心思想是雙重實現一些小文件序列化歸并操作,最大限度地減少元數據占據Namenode節點內存,為集群節省更多的系統資源。在文件序列化后,通過文件分塊和編碼實現源數據的冗余存儲。 3.3 醫學影像云存儲模型集群部署 為了驗證BWFS算法在醫學影像云存儲平臺的應用效果,監測BWFS算法對小文件合并是否減少Master 節點的內存消耗,以及上傳批量小文件系統相應的時間。為此結合醫學云存儲模型搭建基于Hadoop醫學影像云存儲平臺,集群中節點配置和部署如表1所示。 表1 Hadoop集群節點部署圖 在醫學影像云存儲平臺中,集群Master節點是NameNode節點,管理整個分布式文件系統的元數據和對DataNode節點的狀態監控,Slave節點為資源存儲節點,SecondaryNode節點負責對元數據備份。集群中相關開發組件版本如表2所示。 表2 集群相關組件描述 以上兩表分別給出了醫學影像云存儲平臺架構的集群部署和相關組件信息描述。為后續BWFS算法實驗和數據編碼實驗相關數據的采集提供了平臺基礎。 3.4 BWFS算法實驗測試與評估 部署Hadoop集群,將小文件合并的BWFS算法應用在項目開發中[7],并且對客戶端提供序列化合并接口,若不采用序列化接口,則表示直接上傳到HDFS中。 批量上傳小文件的對比實驗的大致流程如下: 1. 批量上傳小文件份數10份(單文件的容量為15 MB),檢測元數據占Master節點的內存消耗(單位為M),同時監測在整個文件上傳的過程中云服務響應時間(單位為s)。 2. 使用BWFS算法,上傳小文件份數為20、30、50、100、150、200、250、300份。進而統計各個點Master節點的內存消耗和上傳過程中系統響應的時間。 3. 不使用BWFS算法,統計分別上傳小文件份數10、20份,直到300份消耗Master節點內存和每次上傳系統響應的時間。 4. 從Master節點內存消耗方面,對兩種情況進行比較。 5. 從上傳批量消耗時間方面,對兩種情況進行比較。 6. 將測試的結果進行可視化對比,對BWFS算法效果進行評估。 實驗中,通過檢測元數據的信息量確定Master節點的內存消耗;同時監測上傳所消耗的時間。批量上傳醫學小文件,Master節點內存消耗對比如表3所示。 表3 Master節點內存消耗對比表 數據表明,采用BWFS算法在序列化醫學小文件上減少了Master節點的內存消耗。可視化表示兩種情況下Master節點的內存消耗,如圖5所示其中藍色標記的曲線代表未使用序列化算法消耗內存的曲線圖,紅色標記曲線代表使用BWFS算法的消耗Master節點內存曲線圖。 圖5 批量上傳小文件Master節點內存消耗對比圖 由圖5所示,小文件數量增多,在未使用序列化算法的情況下,NameNode節點內存消耗急劇增大,在上傳300份小文件時,節點內存消耗近80 MB。然使用BWFS實現小文件的序列化操作,在上傳300份小文件的情況下,僅僅消耗Master節點內存約為12 MB,是未使用算法消耗內存的七分之一,并且隨著小文件的增加,內存消耗曲線變化非常緩慢,因此BWFS算法很適合海量醫學小文件上傳后的序列化合并操作。 實驗中對每次完成批量醫學影像數據上傳的消耗時間也進行了監測,其中s1表示的是在未使用序列化算法的情況下,系統完成上傳所消耗的時間,s2表示使用BWFS算法系統消耗的時間,具體如表4所示。 表4 批量上傳完成消耗的時間對比表 對上傳批量小文件消耗的時間對比進行可視化表示,如圖6所示,其中黑色表示使用BWFS算法系統消耗的時間,灰色表示未使用序列化算法系統消耗的時間。 圖6 批量上傳小文件消耗時間對比圖 由圖6可知,少量數據上傳時,系統響應的時間差別不明顯,但批量文件上傳時,兩者之間的時間消耗越來越大。在上傳300份小文件時,應用BWFS法可以使系統響應的縮減到原來的十分之一,因此在處理海量醫學小文件時,BWFS算法具有很好的優勢。Hadoop2.X集群引入了HA(High Availablity),即高可用方案[7],解決NameNode的單節點問題,若將BWFS算法應用結合到高版本的Hadoop集群中,不僅實現海量醫學小文件的序列化存儲,而且縮減對HDFS的訪問次數,更加提高了系統的穩定性和高可用性,具有很好應用價值。 傳統云存儲模型實現了海量醫學數據的持久化存儲,同時為了保證數據存儲的完整性和可靠性,提高海量數據的檢索效率,采用數據備份的技術實現了對海量數據的無損和擴充備份。在云環境中,考慮到網絡帶寬、CPU性能等方面的影響,很難保證數據的完整性、一致性和分區容錯性等特性。為此,借鑒糾刪碼技術[9],這樣既可實現海量數據較少冗余存儲,又能當數據節點出現故障時,能夠及時實現數據的迅速恢復。 4.1 數據編碼方法內容 糾刪碼是一種數據保護的方法,實現原數據分割成片,把冗余數據塊擴展、編碼、并將其存儲在不同的位置,借此理念,將其應用在海量醫學云存儲模型中。 (3) 向量D表示元數據分塊,向量C表示檢驗信息塊,同時矩陣Fi表示F的行,會有FD=C,假設將F定義成大小為m×n的范德蒙矩陣,并且令fi,j=ji-1,即求出數據塊的校驗矩陣信息C。隨后,依據利用范德蒙行列式[11],得出數據塊編碼方法如式(4)所示: (4) 通過計算得到矩陣L便是所需的n+m個等長的數據塊d1d2,d3,…,dn和檢驗塊c1,c2,c3,…,cm,將數據塊和校驗塊一同存儲到HDFS中。在數據讀取時,若其中有m塊丟失時,將這個m塊對應的矩陣F和矩陣L所對應的行刪除,進而得到新的n×n的矩陣F′和n×1的矩陣L′。由于矩陣F′是非奇異矩陣,對F′求逆矩陣F′-1,進而得到數據恢復的矩陣式(5)所示: D=(F′)-1L′ (5) D矩陣即是元數據塊信息向量,求解到D即可實現原數據塊的快速恢復。綜上所述,在進程bsf中,在超過其閾值的情況下,首先進行數據分塊,之后利用式(4)生成校驗碼塊,其中校驗塊和元數據塊的大小一致,之后通過將其存儲到HDFS中,數據塊的索引存儲到HBase中。 4.2 數據編碼技術實驗和性能評估 隨著海量數據的存儲,傳統的Hadoop集群的副本機制造成大量的數據冗余,造成大量資源的浪費,不利平臺的拓展。醫療云存儲模型通過編碼規范技術極大地減少了集群數據的冗余,實現數據的檢驗備份,即使在DataNode節點出現問題時,也可做到數據快速恢復[12]。 醫療影像云存儲平臺中,假設使用n+m個DataNode節點,可以容忍系統最多有m個塊出現故障,q表示單個DataNode的可靠性(q=99.999%)眼科影像云存儲平臺提供的可靠性(P),使用式(6)表示。 (6) 同時用reds表示冗余率,n表示切分數據塊的數量,m表示編碼校驗塊的數量,切分和編碼數據帶來的冗余率的計算用式(7)表示。 reds=m/(n+m) (7) 當n=2,m=1時,可靠性P=0.999999,,精確度可以達到6個9,此時的冗余率為33.3%。通過式(6)和式(7)當節點校驗塊為1的情況下,擴大原數據的塊的個數,求解數據的容錯率和系統的可靠性,并與傳統的Hadoop集群默認提供的可靠性(99.999%)性能進行對比,如表5所示。 表5 數據編碼技術系統可靠性 由表5得知,從理論角度在默認檢驗塊為1的情況下,增加集群中的存儲節點數量,可以看數據的可靠性快速增高,遠高于Hadoop默認的可靠性能。 4.3 醫學數據編碼實驗測試 醫學數據編碼技術包含數據編碼算法和數據解碼算法,醫學小文件從序列化資源池bsf中進行分塊并進行編碼,形成源數據塊和校驗塊存儲到HDFS中,當源數據塊丟失后,會調用解碼算法實現對源數據的恢復。在醫學云存儲模型中,數據恢復時只需要找到其中的一塊校驗碼,采用解碼算法實現對原數據快的恢復。 為驗證數據編碼技術在平臺中的應用效果,特進行測試。實驗中設置序列化資源池bsf的容量為1280 MB,對列化文件進行分塊處理,默認塊大小為128 MB,形成10塊原數據。同時設置校驗塊數分別為2,3,…,7。分別進行100次實驗,統計醫療影像數據的所占用的存儲空間和醫學影像數據的丟失率,在保持云平臺高性能的條件下,確定原數據n和校驗塊m最佳的數據。 表6 編碼技術在實驗中性能數據采集表 由表6可以看出,采用數據編碼規范技術降低了數據的冗余率,在原數據塊10塊,校驗塊為5時,數據的丟失率為0。此時存儲數據僅是傳統Hadoop存儲平臺的二分之一,為云平臺節省了50%的存儲空間。項目中同樣使用了傳統的Hadoop副本策略進行存儲數據,測試發現在副本為3時,進行100次實驗測得數據的丟失率為4.15%,采用副本為4時,同樣的100次實驗數據的丟失率為2.12%,相比使用數據編碼技術,在校驗塊為4時,數據的安全性均高于相應的副本策略。因此數據編碼在較低冗余存儲的情況下,保證了數據的安全性[12]。 實驗中對數據編碼和解碼時消耗,以各節點CPU使用率和網絡帶寬等方面進行統計,驗證云平臺性能的穩定性。 表7中的數據表示在實驗100份數據時,編碼算法和解碼算法平均的耗時時間。數據表明,隨著校驗塊增多數據編碼耗時增加,同時數據解碼時間降低,編碼和解碼時間總體小于100 s,過程中CPU的使用率均低于30%,網絡帶寬在1 MB/s左右,滿足醫學影像云平臺的性能要求。當出現源數據塊丟失后,使用解碼算法實現了數據的快速恢復,保證醫學數據的完整性和一致性[13]。 表7 編碼技術在實驗中資源使用描述 綜上所述,數據編碼技術在沒有增加過多的存儲空間開銷的基礎上,通過冗余編碼來保證數據的高可靠性和可用性。相對于傳統的Hadoop云存儲模型中,數據的安全性取決于副本所在的DataNode節點,若所有的副本節點無法提供正常的服務時,那么該數據失效。采用編碼技術,只需找到校驗塊數據,即可實現原數據的快速恢復,不僅減少數據的冗余,而且保證數據的高一致性,因此具有很好的科研價值和商業應用價值。 4.4 醫學數據編碼改進 云存儲模型實現了醫學數據的快速讀寫,然而醫學數據分為冷熱數據。對那些上傳較早,并長時間未被訪問的數據稱之為冷數據,而最新上傳或反復被訪問的數據稱為熱數據。 為了能夠實現對海量醫學數據的訪問,對云存儲平臺數據索引進行升級改造[14]。提出Fastbit+HBase的雙重索引,對熱數據采用位圖索引,并將索引寫入到HBase中,實現了海量數據的索引的雙重存儲。對熱數據設置時間周期,bitmap為定期更新存儲索引信息,對超過時間周期尚未被訪問的數據,其索引將會從bitmap索引中刪除,冷數據索引主要存儲在HBase中。 Bitmap索引是基于內存的索引,在數據檢索時,可以根據索引實現數據的快速查詢;同時又屬于key-value存儲類型,與HBase存儲機制相似,很容易實現索引復制到HBase中;并且bitmap索引占用的內存空間不大,索引表定期更新,HBase索引存儲屬于持久化存儲,并且是一次寫入多次讀取的機制,不會造成數據索引的丟失,屬于持久化存儲。因此在云存儲平臺中,使用bitmap索引與HBase索引相結合[15],對提高醫學影像數據的檢索具有很好應用效果。 醫學數據檢索時,根據用戶提交的請求,判斷檢索信息的類。如果是熱數據,則從位圖索引中查找,否則到HBase索引中查找[16]。若位圖索引查找不到索引時,回到持久化索引中進行檢索,當出現DataNode宕機時,便啟用數據編碼技術,獲取校驗塊信息,并實現數據塊的恢復,進而實現數據的檢索。數據檢索流程如圖7所示。 圖7 醫學數據檢索流程圖 數據檢索時,bitmap索引會掛在到內存,實現對熱數據的檢索,同樣的對于冷數據,需要到HBase索引表中檢索,進而查找相關的數據。結合數據編碼技術的應用,源數據塊索引與校驗塊索引相同,同時滿足熱數據索引存儲在bitmap索引中,并且持久化到HBase中。在Hadoop集群中,當DataNode節點宕機時,采用上述的檢索方法,首先在bitmap索引對校驗塊數據進行檢索,否則到HBase索引中檢索校驗塊,并通過數據解碼算法,完成對源數據塊的恢復[17],進而實現了對海量醫學數據的快速檢索。 本文針對傳統云計算模型在數據存儲和檢索以及數據冗余等方面出現的瓶頸問題提出BWFS算法實現小文件序列化合并,減少對Master節點的內存消耗和對HDFS訪問次數;使用糾刪碼數據編碼技術,在降低數據冗余存儲前提,實現了對海量醫學數據的快速恢復;并引入一種基于位圖索引的列式存儲bitmap與HBase索引相結合的并行索引[18],實現了醫學數據的快速檢索。將其應用在醫學影像數據云存儲系統中降低海量數據的冗余存儲,提高海量數據的檢索效率,提高了醫學影像的分析效率,具有很好的應用價值。 [1] 王意潔, 孫偉東, 周松, 等. 云計算環境下的分布存儲關鍵技術木[J]. 軟件學報, 2012, 23(4): 962-986. [2] 胡濤, 周兵, 鄭明輝, 等. 基于Hadoop的移動云存儲系統研究與實現[J]. 華中科技大學學報(自然科學版), 2013, 41(S2): 181-183. [3] 羅鵬, 龔勛.HDFS數據存放策略的研究與改進[J]. 計算機工程與設計, 2014, 35(4): 1127-1131. [4] 謝華成, 陳向東. 面向云存儲的非結構化數據存取[J]. 計算機應用, 2012, 32(7): 1924-1928,1942. [5] 熊煉, 徐正全, 王濤, 等. 云環境下的時空數據小文件存儲策略[J]. 武漢大學學報(信息科學版), 2014, 39(10): 1252-1256. [6] 李鐵, 燕彩蓉, 黃永鋒, 等. 面向Hadoop分布式文件系統的小文件存取優化方法[J]. 計算機應用, 2014, 34(11): 3091-3095,3099. [7] 張源悍. 基于Hadoop平臺的高可用性云存儲系統的設計與實現[D]. 哈爾濱:哈爾濱工業大學, 2014. [8] 杜勇. 基于HDFS的云數據備份系統的設計與實現[D]. 長春:吉林大學, 2011. [9] 敖莉, 舒繼武, 李明強. 重復數據刪除技術[J]. 軟件學報, 2010, 21(5): 916-929. [10] 許文龍. 基于Hadoop分布式系統的重復數據檢測技術研究與應用[D]. 長沙:湖南大學, 2013. [11] 王禹, 趙躍龍, 侯昉. 基于矩陣運算的最小冗余存儲再生碼MSRRC研究[J]. 計算機科學, 2014, 41(11A): 191-194,207. [12] 張亮. 云存儲數據完整性檢測技術研究[D]. 大連:大連理工大學, 2014. [13] 陳蘭香, 許力. 云存儲服務中可證明數據持有及恢復技術研究[J]. 計算機研究與發展, 2012, 49(S1): 19-25. [14] 丁琛. 基于HBase的空間數據分布式存儲和并行查詢算法研究[D]. 南京:南京師范大學, 2014. [15]LiuYB,WangF,JiKF,etal.NVSTdataarchivingsystembasedonFastBitNoSQLdatabase[J].JournaloftheKoreanAstronomicalSociety, 2014, 47(3): 115-122. [16] 卓海藝. 基于HBase的海量數據實時查詢系統設計與實現[D]. 北京:北京郵電大學, 2013. [17] 顏湘濤, 李益發. 基于消息認證函數的云端數據完整性檢測方案[J]. 電子與信息學報, 2013, 35(2): 310-313. [18] 孟必平, 王騰蛟, 李紅燕, 等. 分片位圖索引:一種適用于云數據管理的輔助索引機制[J]. 計算機學報, 2012, 35(11): 2306-2316. THE RESEARCH AND DESIGN OF MEDICAL IMAGE CLOUD STORAGE MODEL Qi Laijun1,2Zhou Lijuan1,2*Ren Zhongshan1,2,3 1(CollegeofInformationEngineering,CapitalNormalUniversity,Beijing100048,China)2(AdvancedInnovationCenterforImagingTechnology,Beijing100190,China)3(InstituteofSoftware,ChineseAcademyofSciences,Beijing100190,China) In order to solve the single node problem of the small medical files in storage and the inconsistency of high data redundancy and the low retrieval efficiency in the early storage model,a new type of cloud storage mode is put forward.In this model,the BWFS algorithm is applied to optimize the serialization consolidation of massive medicine small files.Optimizing erasure codes algorithms to realize data blocks,which reduces the redundant storage of data block.At the same time,the bitmap index technology is applied to combining with the HBase index,which forms a new index technology.Experiments show that the new cloud storage model reduces the memory consumption of master node in the cluster by using BWFS algorithm and erasure coding technology,under the circumstance of ensuring rapid recovery,this model reduces redundant data storage,and the parallel indexing technology has improved the efficiency of searching the massive medical image data. Medical imaging data Cloud storage Parallel index Coding technology 2015-11-11。國家自然科學基金項目(31571563);北京市屬高等學校創新團隊建設與教師職業發展計劃項目資助;高可靠嵌入式系統技術北京市工程研究中心;國外訪學項目(067145301400);北京市高精尖——成像技術高精尖創新中心項目(GXTC-1663074)。齊來軍,碩士生,主研領域:云計算,大數據。周麗娟,教授。任仲山,博士生。 TP3 A 10.3969/j.issn.1000-386x.2017.02.011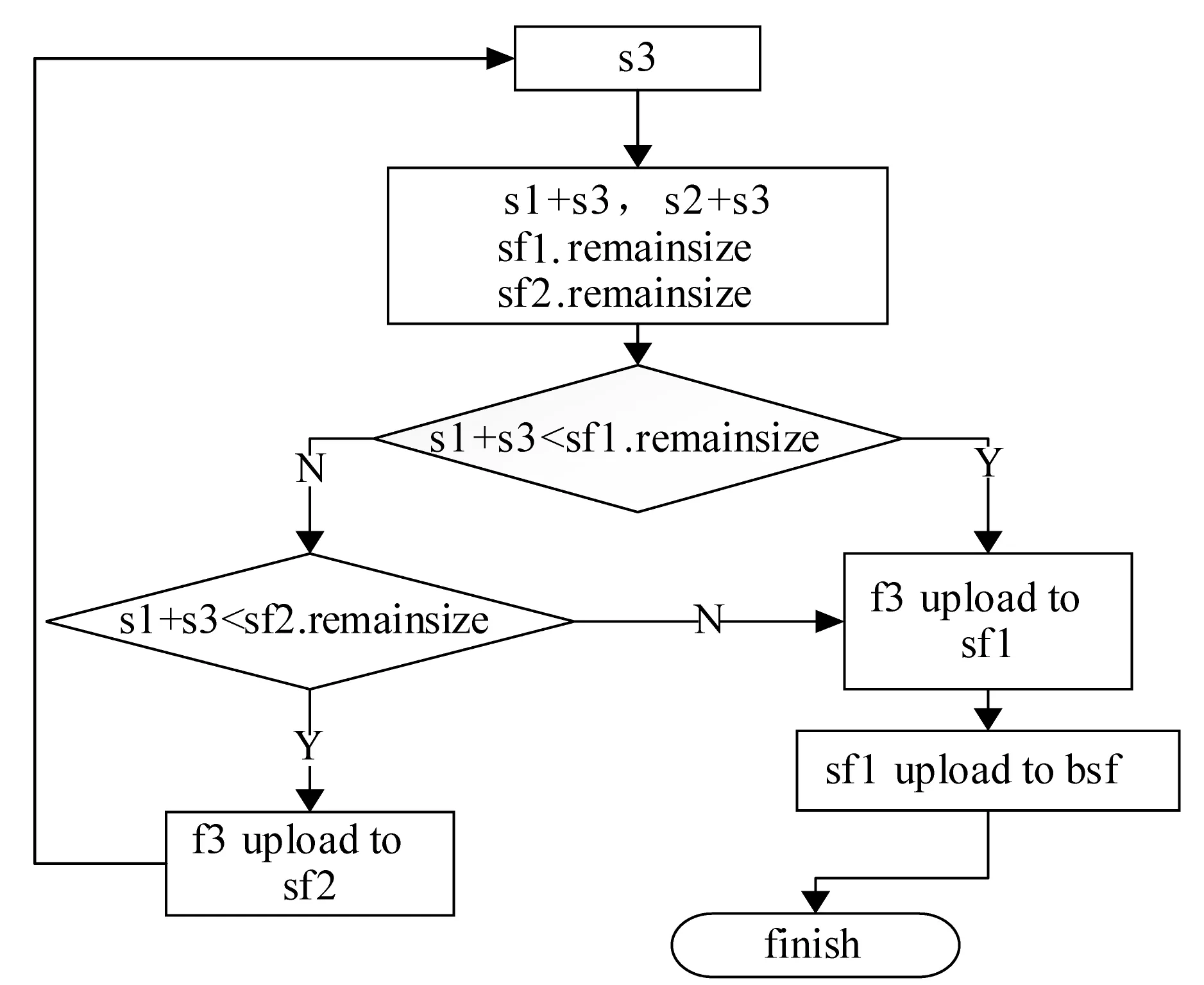



4 醫學數據編碼技術

5 結 語
