基于前綴項集的Apriori算法改進
2017-02-27 11:09:58于守健周羿陽
計算機應用與軟件 2017年2期
于守健 周羿陽
(東華大學計算機學院 上海 201600)
基于前綴項集的Apriori算法改進
于守健 周羿陽
(東華大學計算機學院 上海 201600)
關聯規則的挖掘是數據挖掘中一個重要內容,主要目的是找到事務數據庫中的有趣的模式。Apriori算法是關聯規則挖掘的最經典算法之一,但是它本身存在著效率上的瓶頸。在深入了解Apriori算法前提下,提出基于前綴項集的候選集存儲結構,并利用哈希表在快速查找上的優勢,大大提高了經典Apriori算法在連接步驟和剪枝步驟中的效率。實驗證明改進后的Apriori算法在一定支持度下比經典Apriori算法有著更大的效率優勢,并且支持度越小時提升效率越大。
數據挖掘 Apriori算法 前綴項集 關聯規則 哈希表
0 引 言
隨著計算機技術在各個行業的迅猛發展,各行業所產生的數據也越來越多,但是如何在這些海量數據中獲取有價值的信息也成了一個新的問題。數據挖掘,即數據知識發現,正是在這個大背景下應運而生。數據挖掘[1]是從大量的數據中挖掘出隱含的、未知的、用戶可能感興趣的知識和規則。關聯規則是數據挖掘中的一個重要內容,它最先由Agrawal等提出[2],主要解決的是顧客交易事務庫中項集之間的關聯規則問題。隔年,Agrawal等人又提出了計算關聯規則的最經典的算法,即Apriori算法[3],它是由k-項集來推斷(k+1)-項集并通過剪枝來獲得k-項集的算法。但是由于Apriori算法在計算候選集中的計算瓶頸問題,近年來也出現了針對不同方面的的算法改進方式。Zhang等[4]提出了基于分類的改進的Apriori算法,在效率上有一定程度的提升。Jia等[5]從事務數據庫劃分和動態項集統計的角度對經典Apriori算法進行改進。Liu等[6]在研究煤炭隱患數據時提出了數據庫矩陣化的方法來進一步提升算法效率。Wang等[7]提出一種優化的方法來減少對事務庫重復搜索的次數,從而達到提高效率的目的。Vaithiyanathan等[8]針對事務數據庫中相同興趣的關系對其進行壓縮的方法來改進算法效率。Lin[9]提出基于MapReduce計算模型的Apriori算法以提高大量數據的候選集生成效率。Zhang等[10]是從要分析的數據,即醫療數據的特征出發,提出一種針對該數據特點的改進Apriori算法。
上述提到的改進算法大多是通過減少對事務數據庫遍歷的次數來提高算法的效率,但是這些算法并沒有針對Apriori算法的兩個重要步驟,即連接和剪枝步驟進行改進。本文將針對經典Apriori算法的這兩個重要步驟,即連接步驟和剪枝步驟,采用一種新的基于前綴項集的存儲方式,并利用哈希表快速查找的特征來提高改進算法在兩個步驟中的查找效率。本文首先介紹經典Apriori算法以及其不足之處,再具體介紹算法的改進之處,最后介紹在具體數據集上經典Apriori算法與改進Apriori算法的效率比較。
1 Apriori算法
1.1 Apriori 算法介紹
Apriori算法是一種經典的挖掘關聯規則的頻繁項集算法,其基本思想是使用逐層迭代方法,先求得k-項集,再由k-項集去探索(k+1)-項集。Apriori算法利用頻繁項集性質的先驗知識,首先找出頻繁1-項集的集合,記作L1。用L1得到2-項集的集合L2,再用L2得到L3,直至不能找到頻繁k-項集。Apriori算法的主要包括下面3個步驟:
(1) 連接步驟:連接k-頻繁項集生成(k+1)-候選項集,記作Ck+1。連接的條件是2個k-項集的前(k-1)項相等且它們的第k項不相等。記li[j]為li中的第j項,則條件為:
l1[1]=l2[1]∧l1[2]=l2[2]∧…∧l1[k-1]=l2[k-1]∧l1[k]≠l2[k]其中l1和l2是k-項集集合Lk的子集,l1[k]≠l2[k]是確保不產生重復的k-項集。由l1和l2連接產生的結果項集為:
{l1[1],l1[2],l1[3],…,l1[k],l2[k]}
(2) 剪枝步驟:從候選項集Ck+1中挑選出真實頻繁項集Lk+1。因為候選項集Ck+1是真實頻繁項集Lk+1的超集。根據Apriori性質:頻繁k-項集的任意子集必定也是頻繁的,即頻繁k-項集的任意(k-1)-項集也必定是頻繁的。利用此性質查找是否Ck+1的k-項子集是否都在Lk中,如果不成立,則將該候選(k+1)-項集從Ck+1中刪除。
(3) 計數步驟:掃描數據庫,累加(k+1)-候選集在數據庫中出現的次數。再根據給定的最小支持度閾值生成(k+1)-項集。
1.2 Apriori算法的不足
Apriori是挖掘關聯規則的最經典算法之一,但是也存在著效率不高的問題。Apriori算法的時間消耗主要在以下3個方面:
(1) 在連接步驟,利用k-項集連接產生(k+1)-候選項集時,判斷連接條件時比較次數太多。假設Lk中有m個k-項集,則連接步驟需要進行比較的時間復雜度為O(k×m2)。
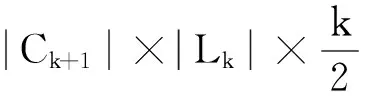
(3) 在計數步驟中,對Ck+1中候選項集的支持度計數中,需要掃描次數據庫|Ck+1|。
上述即經典Apriori算法的時間消耗的主要三個方面,在引言中提到的改進的算法也主要是針對其中的第三個步驟,即計數步驟作出改進以提升效率,本文將針對其中的前兩個步驟,即連接步驟和剪枝步驟的計算瓶頸,提出一種基于前綴項集的改進Apriori算法。
2 Apriori算法改進
2.1 算法改進思想
在1.2節中已經分析了傳統Apriori算法的不足之處,所以對其改進也著重在1.2節中提到的3個步驟中。由于Apriori算法中記錄中的各項均已經是按字典排序的,因此由Apriori算法生成的候選項集也是有序的。
(1) 基于前綴項集的存儲方式
在新提出的基于前綴項集的改進算法中,我們引入一種新的存儲項集的方法——基于前綴項集的存儲方法。對于每個項集我們修改其保存方式:對于Lk中各k-項集我們采用類似Map
例如:數據庫如表1所示,設最小支持度為2。
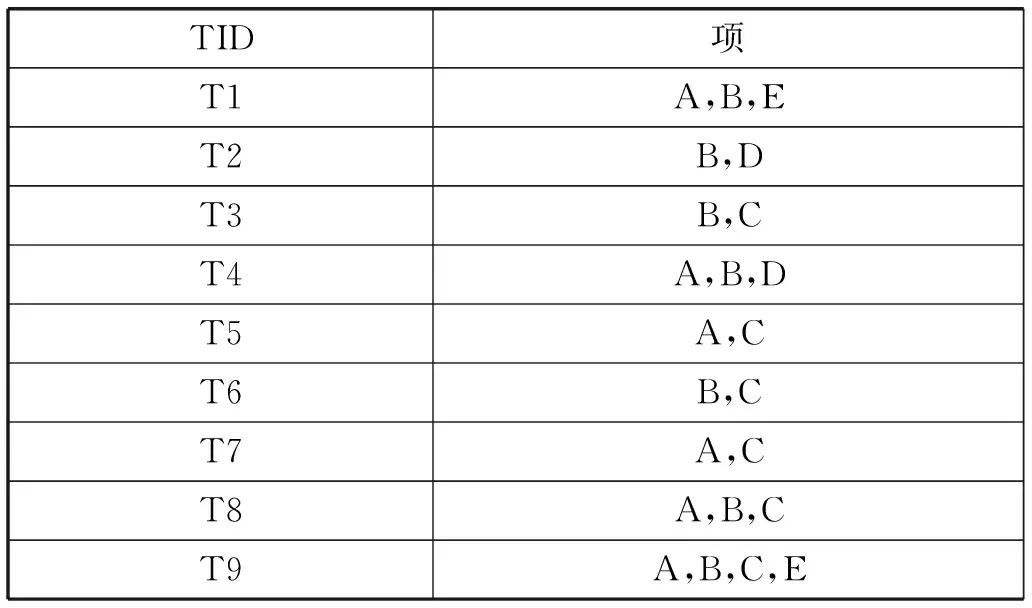
表1 事務表TD
傳統的Apriori算法掃描數據庫,得到每個項在數據庫中出現的次數,并得到1-項集及計數,再基于1-項集迭代產生滿足最小支持度的2-項集及計數。下面是傳統的Apriori算法得到的內容如表2所示。
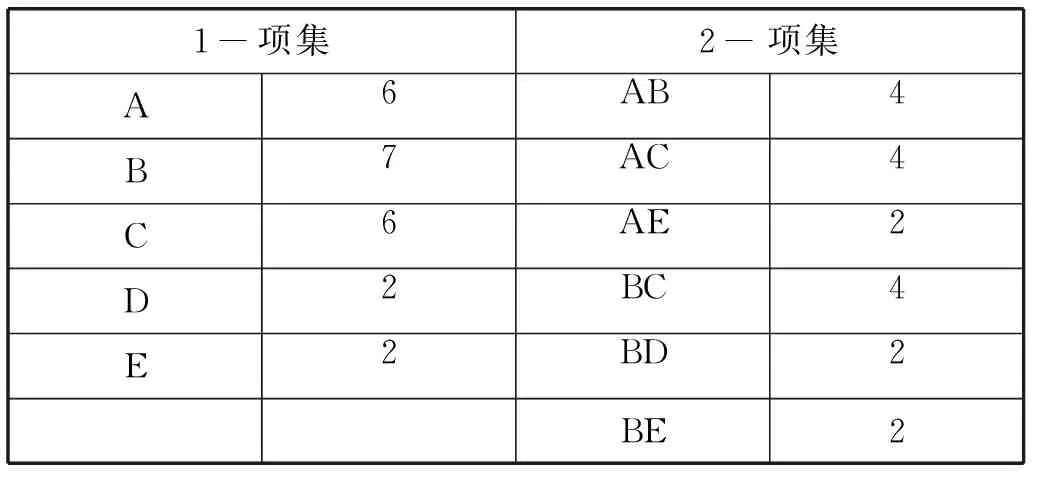
表2 傳統存儲方式
利用基于前綴項集的保存方式如表3所示。
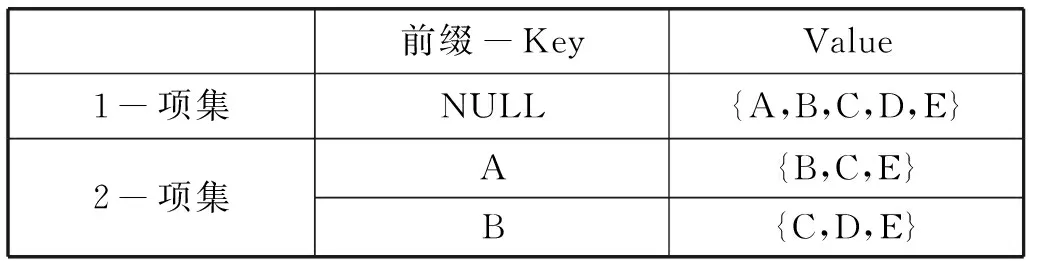
表3 基于前綴項集存儲方式
表3中,因為1-項集只有一個項,所以其前綴內容設為NULL;在上表中還可以清楚地看到若前綴的長度為n,則其代表的項集長度則為(n+1),因為value中記錄的是該項集的最后一個項的內容。
(2) 基于前綴項集的連接步驟
在基于前綴項集存儲方式的建立后,在連接步驟進行k-項集間的連接操作時,則只要對相同前綴-key的value中任意兩個項進行合并,再加上該前綴-key即可成為新的(k+1)-項候選項集。例如,對表3中的2-項集進行連接,前綴-key為A對應的value集中連接操作可得到{{B,C},{B,D},{C,D}},前綴-key為B對應的value集中連接操作可得到{{C,D},{C,E},{D,E}}。
(3) 基于前綴項集的剪枝步驟
由1.1節中對傳統剪枝步驟的介紹可以知道,(k+1)-候選項集是由LK中的兩個k-項集連接得到,并且如果(k+1)-候選項集的某個k-項子集不在Lk中時,該(k+1)-候選項即從Ck+1中移除。下面提出一個定理:
定理1 如果由兩個k-項集、,連接產生的(k+1)-項集的k-項子集不在Lk中,則該k-項子集中必然同時包含l1[k],l2[k]。
證明:l1、l2連接后得到的(k+1)-項候選集為{l1[1],l1[2],l1[3],…,l1[k],l2[k]}。
如果該(k+1)-項候選集的k-項子集不同時包含l1[k],l2[k],則可能的情況只有l1[1]、l1[2],l1[3]…,l1[k]、l1[1],l1[2],l1[3],…,l2[k]}即、l1、l2。而l1、l2屬于Lk,所以若k-項子集不屬于Lk,則k-項子集中必同時包含l1[k],l2[k]。
由定理1可知,在進行剪枝過程中只需考慮(k+1)-項候選集中同時包含用于連接的兩個k-項集尾項的可能的k-項子集即可。針對表3中的例子,遍歷可能出錯的2-項子集可以得到如表4所示。
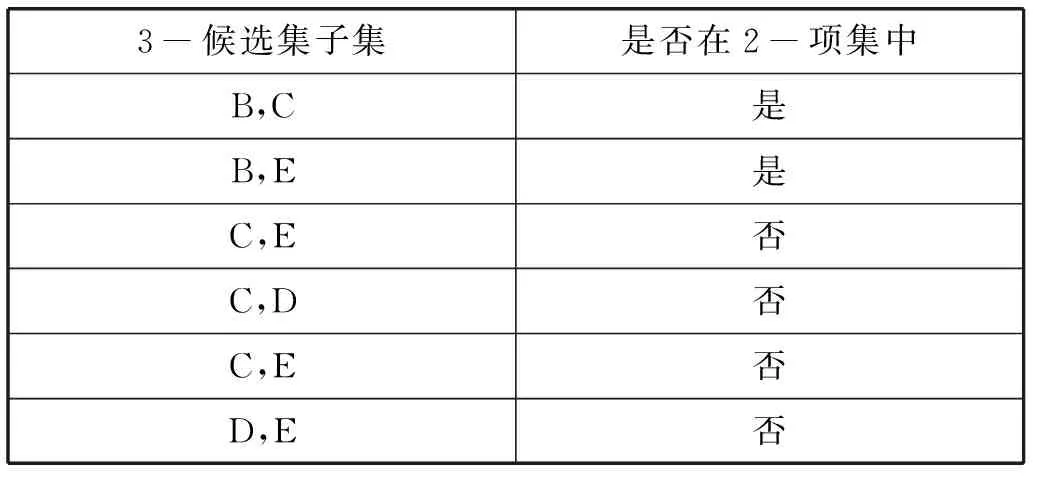
表4 剪枝過程
如表4中所示,只有{{B,C},{B,E}}是可能的2-項候選子集,再加上其對應的前綴-key,得到{{A,B,C},{A,B,E}},即得剪枝后的3-項候選子集C3。
得到(k+1)-項候選集后,再遍歷原始數據庫,執行計數步驟,即找出滿足最小支持度的k-項集,針對表3中例子,可以知道{{A,B,C},{A,B,E}}都滿足最小支持度,所以將他們加入到基于前綴項集存儲中,如表5所示。

表5 3-項集存儲方式
2.2 算法實現
完整的算法可描述為:
輸入:事務數據庫D,最小支持度min_sup
輸出:頻繁項集L
1) L1=D的1-項集
2) Map
3) 將L1導入map中,key為null,value為L1中項的并集
4) for(k=2;Lk-1φ;k++){
5) Ck=pre_apriori_gen(map,k-2);
6) 對Ck中每個項集計數,Lk={c∈Ck|c.count>min_sup}
7) }
8) Return ;
procedurepre_apriori_gen(map:Map
1) for each key in map{
2) if(key.length()==k){
3) c:=key與(value中任意兩個值)的有序組合;
4) if(map.containsKey(c[0:k])){
5) If(c的任意(k+1)子集存在于map的(key,value)中){
6) 將c加入Ck;
7) }
8) }
9) else continue;
10) }
11) Return Ck
3 實驗結果與分析
實驗采用的數據是瑞金醫院的糖尿病臨床處方數據共120 000行,數據中記錄的是每次就診的處方藥品編號。本實驗運行機器配置為Intel Core i5 2.7 GHz處理器,8 GB 1866 MHz LPDDR3 內存。
實驗從兩方面來對經典Apriori算法和基于前綴項集的Apriori算法來進行效率上的比較:一方面是當測試總數固定時不同的支持度下的算法運行效率的比較,另一方面是當支持度固定后不同的測試總數下算法的運行效率的比較。
實驗1結果如下圖所示。
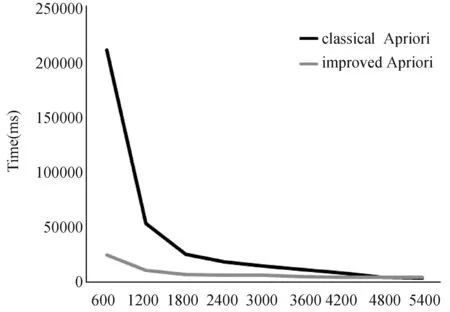
圖1 不同支持度下的運行時間比較
圖1描述的是兩種算法在測試樣本總數一定,共12萬條數據時,不同的最小支持度下運行的時間比較。從圖1中可以看到,當支持度越小時改進的Apriori算法比經典Apriori算法的效率優勢越明顯。從圖中還可以看出當支持度達到一定值時,由于達到支持度要求的頻繁項集數很少,所以此時改進算法的效率優勢一般。

表6 不同支持度下時間及時間減少率
表6顯示了經典Apriori算法和改進Apriori算法在不同支持度下的具體運行時間以及后者相對前者的減少率。
實驗2結果如圖2所示。
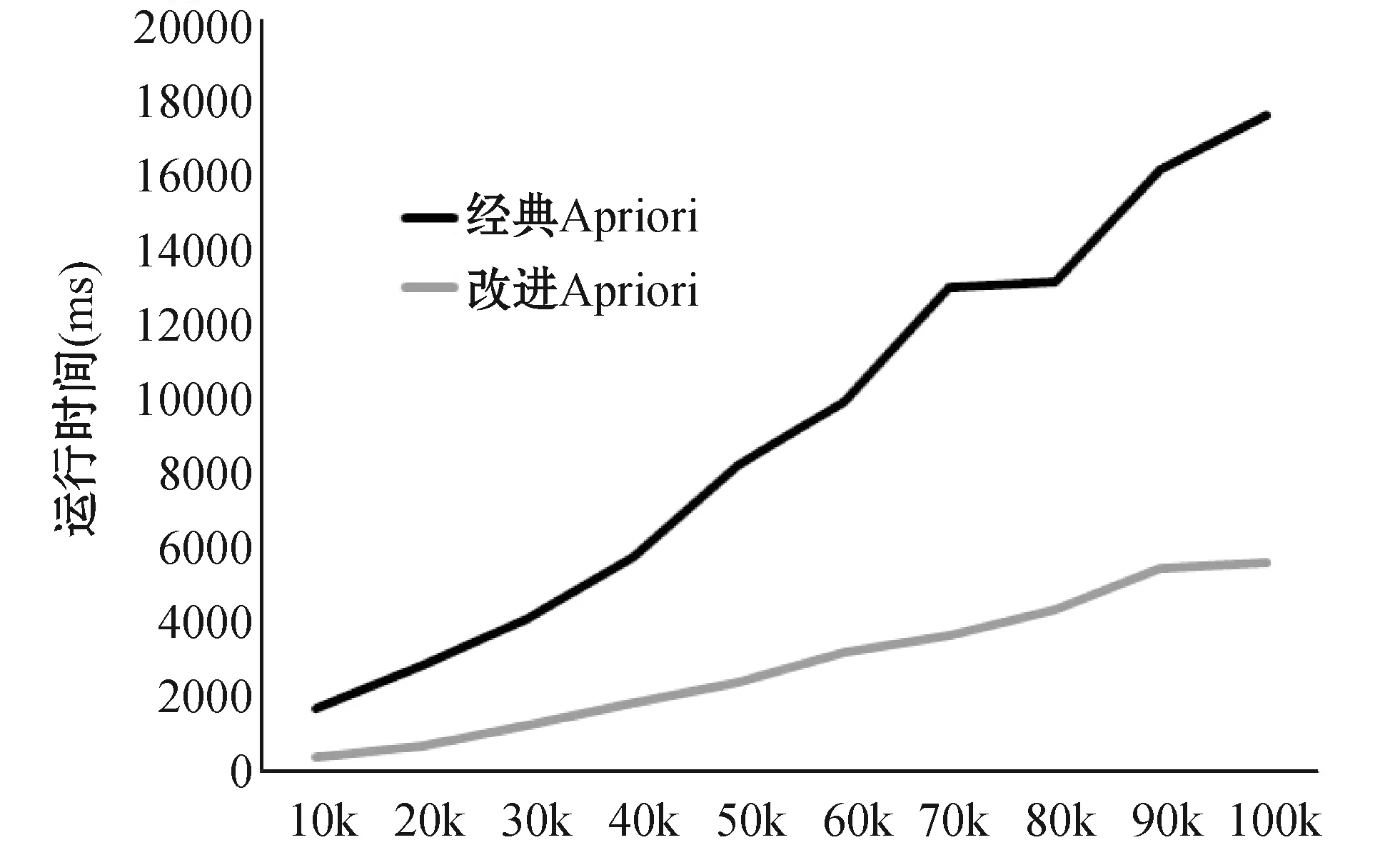
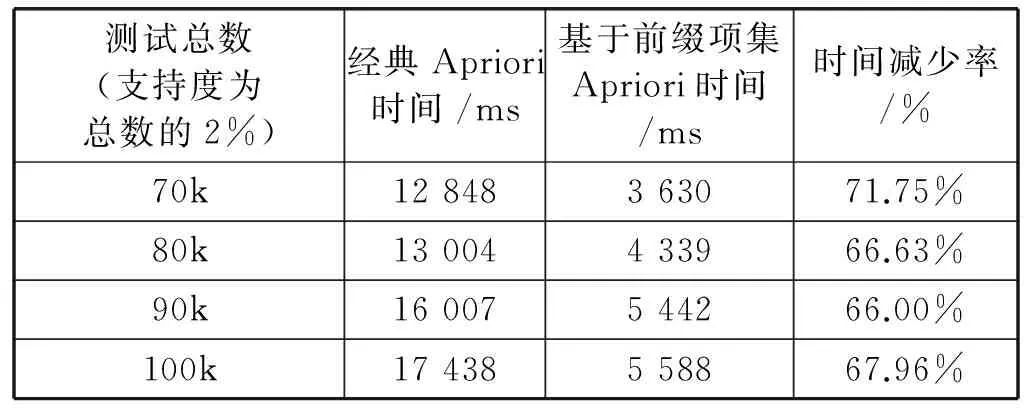
圖2 相同支持度不同測試總數下的運行時間比較
圖2描述的是兩種算法在不同測試總數,但支持度都為測試總數的2%時運行時間的比較。從圖2可以看出,在相同支持度下測試總數越大,算法的運行時間越長,并且改進的Apriori算法相比經典Apriori算法在效率上有著穩定的提升效果。
表7介紹了兩種算法在相同支持率但測試總數不同的情況下運行的時間比較,可以看出在支持度為測試總數2%時,改進Apriori算法在效率上明顯高于經典Apriori算法,并且效率的提升率穩定在70%左右。
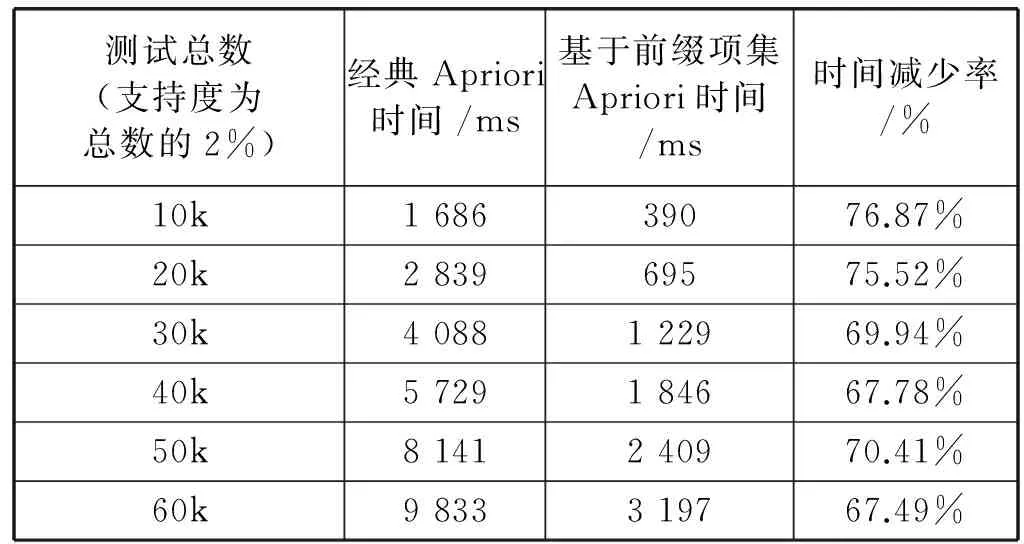
表7 不用測試總數下時間及時間減少率
續表7
實驗表明,基于前綴項集的Apriori算法是有效可行的。
4 結 語
本文在對經典Apriori算法的深入研究基礎上,指出了該算法在連接、剪枝步驟中的一些局限,并提出了基于前綴項集的數據存儲方式以及在該存儲方式上的算法改進,使得在連接步驟和剪枝步驟的運行時間得到很大程度的減少。最后在支持度和測試總數兩個維度上的實驗結果也證明了算法的可行性。
[1] Han J,Kamber M,Pei J.Data mining:Concepts and techniques[J].3rd ed.San Francisco:Morgan Kaufmann Publishers,2001.
[2] Agrawal R,Imieliński T,Swami A.Miningassociationrules between setsof items inlarge databases[C]//Proceedings of the 1993 ACM SIGMOD International Conference on Management of Data,1993:207-216.
[3] Agrawal R,Srikant R.Fast algorithms for mining association rules in large databases[C]//Proceedings of the 20th International Conference on Very Large Data Bases,1994:487-499.
[4] Zhang C S,Li Y.Extension of local association rules mining algorithm based on apriori algorithm[C]//Software Engineering and Service Science (ICSESS),2014 5th IEEE International Conference on.IEEE,2014:340-343.
[5] Jia Y,Xia G,Fan H,et al.An Improved Apriori Algorithm Based on Association Analysis[C]//2012 Third International Conference on Networking and Distributed Computing,2012:208-211.
[6] Liu S,Peng L.Analysis of Coal Mine Hidden Danger Correlation Based on Improved A Priori Algorithm[C]//Intelligent Systems Design and Engineering Applications,2013 Fourth International Conference on.IEEE,2013:112-116.
[7] Wang P,An C,Wang L.An improved algorithm for Mining Association Rule in relational database[C]//Machine Learning and Cybernetics (ICMLC),2014 International Conference on.IEEE,2014,1:247-252.
[8] Vaithiyanathan V,Rajeswari K,Phalnikar R,et al.Improved apriori algorithm based on selection criterion[C]//Computational Intelligence & Computing Research (ICCIC),2012 IEEE International Conference on.IEEE,2012:1-4.
[9] Lin X.MR-Apriori:Association Rules algorithm based on MapReduce[C]//Software Engineering and Service Science (ICSESS),2014 5th IEEE International Conference on.IEEE,2014:141-144.
[10] Zhang W,Ma D,Yao W.Medical Diagnosis Data Mining Based on Improved Apriori Algorithm[J].Journal of Networks,2014,9(5):1339-1345.
[11] Han J,Pei J,Yin Y.Mining Frequent Patterns without Candidate Generation[C]//Proceedings of ACM SIGMOD International Conference on Management of Data,2000:1-12.
THE IMPROVEMENT OF APRIORI ALGORITHM BASED ON PREFIXED-ITEMSET
Yu Shoujian Zhou Yiyang
(CollegeofComputerScienceandTechnology,DonghuaUniversity,Shanghai201600,China)
The mining of association rule is an important method for discovering interesting relations between variables in large databases.Apriori algorithm is one of the most classical algorithms of association rules,but it has bottleneck in efficiency.Thus,a candidate item set storage structure based on prefixed-item set is proposed with the help of the quick search of hash map,and the efficiency of classical Apriori algorithm in connecting and pruning step has been improved greatly.The experiments show that the improved Apriori algorithm does better in efficiency than the classical Apriori algorithm in certain degree’s support,and the smaller support,the better efficiency.
Data mining Apriori algorithm Prefixed-itemset Association rules Hash map
2015-10-21。于守健,副教授,主研領域:Web服務,企業應用集成,數據庫與數據倉庫。周羿陽,碩士。
TP3
A
10.3969/j.issn.1000-386x.2017.02.052
猜你喜歡
甘肅教育(2020年14期)2020-09-11 07:57:42
中學生數理化(高中版.高考數學)(2020年5期)2020-06-02 09:19:08
商周刊(2017年9期)2017-08-22 02:57:49
財經(2017年15期)2017-07-03 22:40:49
財經(2017年2期)2017-03-10 14:35:35
財經(2016年15期)2016-06-03 07:38:02
財經(2016年3期)2016-03-07 07:44:46
財經(2016年6期)2016-02-24 07:41:51
時代英語·高二(2015年1期)2015-03-16 00:08:11
中國衛生(2014年11期)2014-11-12 13:11:32
