探討人工智能在檔案開放鑒定中的應用
2017-03-12 07:37:33馮佳
檔案管理理論與實踐-浙江省基層檔案工作者論文集 2017年0期
馮 佳
(浙江省嘉善縣檔案局)
檔案工作的根本目的是整合各種檔案信息資源以便于社會大眾的利用,檔案開放是社會大眾獲取和利用檔案信息最基本也是最重要的途徑。隨著科技的日新月異,電子信息技術也給檔案工作帶來了巨大的變革,“智慧檔案”的概念隨之應運而生。新技術的引進和運用不會改變檔案工作的根本目的,而是為了更加高效、更加便捷地為社會大眾服務。
我國于20世紀80年代開始提出檔案開放政策,并于1987年公布的《中華人民共和國檔案法》規定:“國家檔案館保管的檔案,一般應當自形成之日起滿30年向社會開放。經濟、科學、技術、文化等類檔案向社會開放的期限可以少于30年,涉及國家安全或者重大利益以及其他到期不宜開放的檔案向社會開放的期限可以多于30年”。但在檔案開放利用的實際工作中,還存在著許多限制和不足。本文旨在探析利用人工智能技術在檔案開放鑒定中的應用來解決這些問題。
一、檔案開放利用現狀分析
(一)我國檔案開放程度分析
從全國綜合檔案館的館藏數據和開放數據來看我國檔案的開放程度(以下數據來源于國家統計局)。據統計,2015年國家綜合檔案館館藏檔案數量為58641.7萬卷,2006年國家綜合檔案館館藏檔案數量為21656.5萬卷,10年間館藏檔案增長率為170.78%。2015年國家綜合檔案館開放檔案為9266.3萬卷,2006年為5746.3萬卷,10年間開放檔案增長率為61.26%,可以看出開放檔案的增長速率相較于館藏檔案緩慢了很多。2015年國家綜合檔案館的館藏數據為58641.7萬卷,開放檔案數據為9266.3萬卷,開放率僅為15.8%,而且開放率逐年在下降。
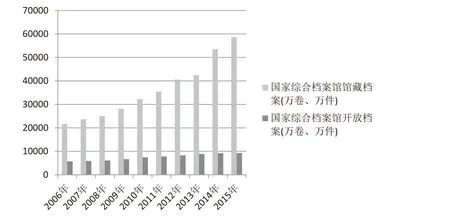
圖1 2006—2015年國家綜合檔案館館藏檔案數量和開放檔案數量
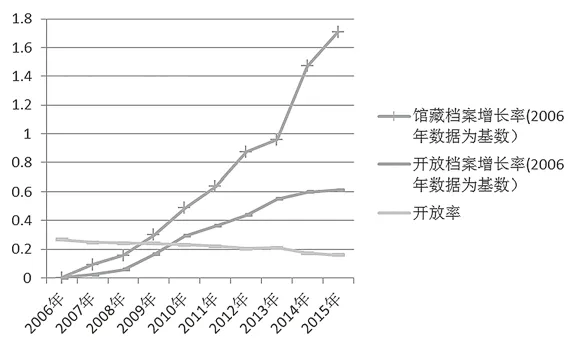
圖2 2006—2015年館藏檔案增長率、開放檔案增長率和開放率
(二)我國檔案利用程度分析
從全國綜合檔案館的利用檔案數量來看,2006年國家綜合檔案館利用檔案1166.4萬卷,2015年為1978.3萬卷,增加率為69.6%。但是2015年的利用檔案在已開放檔案中利用率為21.3%,相對于整個館藏數量則僅僅為3.37%,檔案資源利用率極低。根據浙江省統計局數據,2015年檔案資料利用人次為47.52萬人;又根據國家統計局數據,浙江省2015年總人口為5539萬人,這些數據表示浙江省檔案利用人次僅占總人口的0.86%,意味著浙江省檔案資源與99%以上的社會大眾無關。
二、檔案開放的主要瓶頸
相對于國外檔案的高開放率,我國檔案自20世紀80年代提出開放以來一直處于比較低的開放率,其主要原因有兩個方面。第一,檔案法律法規對檔案開放時間起著引導性和約束性作用,基本上要形成滿30年才能開放。第二,開放鑒定困難,由于人力和能力等方面條件約束,無法準確和準時地理解內容并做出鑒定,保密過度而開放減少,往往會導致開放數量減少。如圖3所示,2006年人均管理檔案數為0.9545萬卷,而到2015年時上升至3.1895萬卷。2006年國家綜合檔案館數為3154個,專職員工為22689人;而10年后綜合檔案館數上升至3322個,人員卻降低至18386人(以上數據均取自國家統計局)。
開放鑒定困難造成檔案開放率逐年遞減,而法律法規導致開放的檔案時效性較差,無法滿足社會大眾的需求,也就產生了上一節檔案資源與99%以上的社會大眾無關的局面。
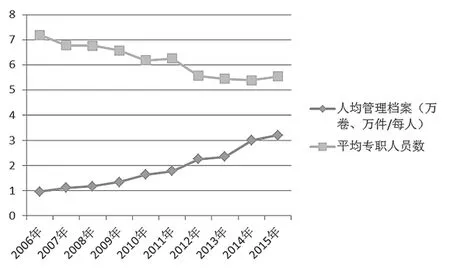
圖3 人均管理檔案數和檔案館平均專職人員數
三、人工智能技術
隨著近年來人工智能技術的興起,各行各業都引入了人工智能的技術來提升生產力和效率,檔案行業也不例外。浙江、江蘇、青島等省市陸續提出了“智慧檔案”并進行了試點探索,而本文旨在探討運用人工智能技術中的深度學習方法來實現檔案的開放鑒定工作。
(一)人工智能技術實現原理
傳統意義上,計算機使用方式是我們通過鼠標或者鍵盤等輸入裝置給它一連串指令,然后計算機按照指令去執行并輸出結果,一一對應,非常明確。而人工智能最大的不同點在于,它接受的是數據,自己分析,然后輸出結果。
以一個經驗豐富的檔案工作者鑒定一份檔案是否開放為例,他首先需要了解這份檔案的內容,然后根據自己的經驗來給出鑒定結果。如圖4所示,我們人工智能技術的原理就是模擬這種方式,利用已有的歷史數據,得出某種模型,并利用這種模型來預測未知屬性。人工智能中計算機學習的方式與人腦思維的經驗過程是非常相似的,不過計算機能考慮更多的可能性,執行更加復雜的運算,也擁有更快的速度。利用這種技術,我們便可以使用計算機來對檔案做開放鑒定。

圖4 人工智能與人類的對比
(二)自然語言處理
在分析數據前,首先要讓計算機“讀懂”數據,也就是自然語言處理。機器處理自然語言的歷史一般認為是從1950年Alan Turing在Mind雜志上發表的“計算的機器和智能”開始的,經過了60多年的發展,這個領域已經取得了實質性的突破。機器自然語言處理從用語法規則去理解自然語言,轉變成了基于數學模型和統計的方法去分析自然語言(吳軍,2014)。在中文中,詞是表達語義的最小單位,機器處理自然語言是建立在詞的基礎上的,所以中文分詞就是把一整段的句子分成單獨的幾個詞。
自然語言處理包括句法語義分析、信息抽取、文本挖掘、機器翻譯、信息檢索、圖像識別等等,結合現下jieba分詞、Word2Vec等幾個最流行的工具,機器就能“讀懂”檔案的內容了。注意,這里讀懂被加了引號,是因為現階段自然語言處理都是基于統計模型的,而不是基于語義模型。
(三)學習方法
計算機能讀懂檔案后,就需要進行學習。計算機學習主要有訓練和預測兩個方面,對應于人類的歸納和推測。計算機學習的方法有很多種,比較經典的有回歸算法、神經網絡、SVM支持向量機、聚類算法、降維算法、推薦算法、樸素貝葉斯等等。按訓練的歷史數據有無標簽,我們可以將算法基本分為監督學習算法和無監督學習算法。因為檔案開放只有可開放和不可開放兩種結果,所以需要使用監督學習算法,而神經網絡算法是當下非常流行的一種監督學習算法,遞歸神經網絡(RNN)非常適合運用于自然語言處理,例如Socher et al.(2013c)成功使用了遞推神經網絡來預測語句情感,并取得了80.7%的準確率。所以,神經網絡算法也非常適合計算機來做檔案開放鑒定。
神經網絡算法是人工智能中的一個新的領域,它的原理是模仿人腦的機制來解釋和處理數據,建立大腦神經網絡系統傳遞信息,可以用于分析圖像、聲音和文本。所謂深度學習神經網絡,就是擁有層數非常多的神經網絡。舉個例子,想要在圖5的三個圖中讓電腦識別是否有人臉,設計幾個神經元來判斷是否有眼睛,是否有鼻子,是否有嘴巴,是否有頭發,等等,然后依靠最終神經元的輸出判斷是否有人臉,如圖6所示。如果想判別是男人的臉還是女人的臉,或者判定其他更復雜的東西,就需要增加更多的神經網絡層。
神經網絡算法運用到檔案的開放鑒定中分為兩個步驟:訓練和預測。訓練的意思就是把已經由人工劃分好的歷史數據讓機器學習,得出一個模型。經過不斷地參數調整,這個模型就可以擁有較高的檔案開放鑒定準確率了。機器鑒定檔案會有以下三個優點:鑒定標準統一,效率高,無須相關專業知識即可鑒定。

圖5 判別人臉的例子
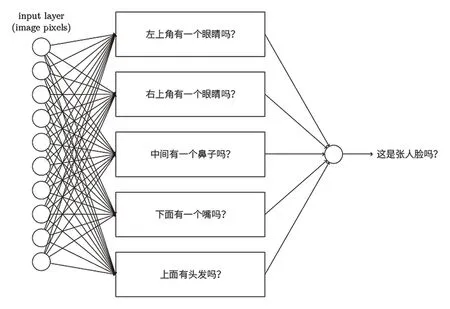
圖6 簡易神經網絡
(四)不足與展望
運用人工智能技術中的神經網絡算法來鑒定檔案是否開放,還存在著許多實際操作中的問題。第一,模型訓練需要檔案全文數字化,導致訓練數據的數量需求量非常大,至少千萬級別,而2015年全國開放檔案才9266.3萬卷,訓練數據獲取難。第二,算法設計和參數調整需要相當大的人力和時間,神經網絡是一個非常年輕的領域,理論建立并不完備,很多方面都要摸索著前進。第三,可能會有部分誤判,由于模型預測過程完全是黑箱模式,無法知道判別的具體依據。盡管有著諸多困難,但這些在實現“智慧檔案”的道路上是不可避免的,人工智能技術的引入會加快“智慧檔案”的實現。
猜你喜歡
中等數學(2022年2期)2022-06-05 07:10:50
小學科學(學生版)(2021年7期)2021-07-28 06:44:42
小學生學習指導(低年級)(2020年6期)2020-07-25 02:31:36
科技傳播(2019年22期)2020-01-14 03:06:34
商界(2019年12期)2019-01-03 06:59:05
IT經理世界(2018年20期)2018-10-24 02:38:24
小學生學習指導(低年級)(2018年9期)2018-09-26 05:59:44
瘋狂英語·新讀寫(2018年2期)2018-09-07 09:32:10
消費導刊(2017年20期)2018-01-03 06:26:40
小康(2017年16期)2017-06-07 09:00:59
