基于云計算的SPRINT算法研究
2017-03-29 04:52:54楊潔,黃剛
計算機技術與發展 2017年3期
關鍵詞:分類
楊 潔,黃 剛
(南京郵電大學 計算機學院,江蘇 南京 210003)
基于云計算的SPRINT算法研究
楊 潔,黃 剛
(南京郵電大學 計算機學院,江蘇 南京 210003)
決策樹是數據挖掘中非常重要的一種技術,常用來做數據分析和預測。傳統的決策樹算法在處理海量數據挖掘時,受到CPU和內存的限制,導致算法存在消耗時間過長,容錯性差,存儲量小的缺點。面對海量數據的處理,云計算在這方面具有非常多的優勢。針對決策樹中優秀的SPRINT算法,首先對SPRINT算法進行了優化,然后為了讓優化后的算法更好地應用于云計算,對算法實現了并行化。傳統的SPRINT算法在生成決策樹時,會發生多值偏向問題,在生成一個節點時,通過計算兩層的Gini指數來降低多值偏向的影響。在算法并行化時,通過將數據分發到各個處理器執行,然后進行匯總處理,從而減少算法執行的總時間。實驗結果表明:基于云計算平臺的SPRINT改進算法具有更好的分類正確率,同時算法的執行速度也得到了明顯的提高。
云計算;MapReduce;SPRINT算法;Gini指數
0 引 言
數據挖掘發展至今,已經產生了許多實用的數據挖掘方法,包括決策樹算法、貝葉斯方法、人工神經網絡方法、支持向量機方法、聚類分析方法等。SPRINT算法是決策樹算法中的一種經典算法。SPRINT算法是對SLIQ算法的進一步優化,在內存的數據量駐留方面,改進了決策樹的數據結構。由于種種優點,越來越多的人投身到SPRINT算法的研究中,主要集中在對算法的本身進行改進。但是,如今的數據量越來越大,無疑給算法工程師帶來了許多新的艱巨挑戰。單純對算法本身的改進已經不能滿足于現在的需求,而云計算的出現解決了這個問題。然而,僅僅將傳統的SPRINT算法應用于云計算平臺,并不能充分發揮云計算的計算能力。
文中對SPRINT算法進行改進,通過計算兩層的Gini指數來產生一個決策節點。改進后的算法雖然增加了計算量,但產生的分割屬性優于未改進的SPRINT算法,即產生了更優的決策樹。
1 云計算平臺
1.1 云計算簡介
云計算這個新名詞出現在2007年的第3季度,不到半年,它受到的關注程度就遠遠超過了先前大熱的網格計算,并且在今天也沒有任何減弱的趨勢[1]。云計算具有以下特點:“云”具有很大的規模性;云計算為了方便用戶接入,使用了虛擬化技術,該技術可以讓用戶在任意地點使用各種不同的終端設備從“云”獲得自己需要的服務;作為商業模型,“云”在創建階段和維護階段,在開銷方面,也具有前所未有的性價比[2]。1.2 MapReduce編程模型
MapReduce最初來源于Google的幾篇論文,是一種用于處理海量數據挖掘的并行編程模型[3]。
MapReduce的運行模型如圖1所示。
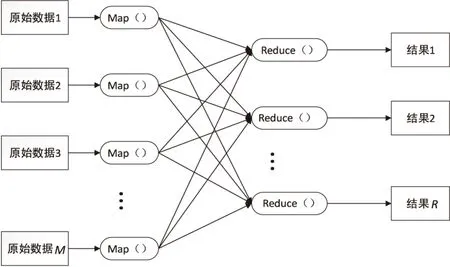
圖1 MapReduce的運行模型
MapReduce降低了編程人員的要求,在編程時他們不需要關心程序運行的具體細節,只需要編寫兩個主要的函數:
Map:(in_key,in_value)→{(keyi,valuei)|i=1,2,…,k}
Reduce:(key,[value1,value2,…,valuem])→(key,out_value)
Map函數需要的輸入參數和Reduce函數所輸出的結果會根據不同的應用發生變化。in_key和in_value是Map的輸入參數,它們指明了Map操作所要處理的原始數據是什么。Map操作結束后,會產生一些中間結果,它們以鍵值對的形式存在,即(key,value)對。在Map階段結束后,系統會對所有的中間結果進行整理,使具有相同key的value集結在一起,也就是說,Reduce的輸入參數是(key,[value1,value2,…,valuem])。Reduce的工作就是對這些具有相同鍵key的value值進行歸并處理,最終產生(key,out_value)的結果。其中每一個Reduce都會產生自己的結果,最后,將所有Reduce的結果合在一起就成了最終結果[4]。
2 SPRINT算法
2.1 基本思想
SPRINT算法創建決策樹的過程:
輸入:節點n,數據集D,分割方法CL;
輸出:一棵決策樹,根節點為n,決策樹基于數據集D和分割算法CL。
ProcedureBuildTree(n,D,CL)
初始化根節點:
以CL為分割依據,計算D中的數據,生成節點信息;
If(節點n滿足分割條件)
選擇最好的效果將D分為D1、D2;
創建節點n的子節點n1、n2;
TDTree(n1,D1,CL);
TDTree(n2,D2,CL);
endIf
end
SPRINT算法的終止條件一般存在3種情況:
(1)當前生成的節點中,所有的樣本數據如果都屬于同一個類,那么這個節點就是一個葉節點,即算法終止計算,同時用這個共同的類作為該葉節點的類標記。
(2)所有屬性都已經用完,沒有多余的屬性用作測試屬性。
(3)當前節點內的樣本數少于用戶規定的閾值,則用該節點內占大多數的類作為該葉節點的類標記[5]。
2.2 SPRINT算法的數據結構
SPRINT算法定義了兩個特殊的數據結構:屬性列表和類直方圖。在SPRINT算法之前的決策樹方法中,數據都必須長時間駐留在內存,限制了大數據的處理,SPRINT使用屬性列表解決了這個問題,并取消了數據的多次排序。屬性列表用一個三元組表示,即<屬性值,類別標識,行索引>。其中行索引是自動生成的。初始化根節點時,對于離散屬性,屬性列表沒有什么強制要求,而對于連續屬性,屬性列表則需要對它進行排序處理。在算法生成決策樹的過程中,隨著數據的不斷分割,節點不斷的生成,與節點相對應的屬性列表也在被分割,然而屬性列表順序卻沒有改變,也就是說該屬性列表也是有序的,因此,不用對屬性列表進行重排[6]。
類直方圖的作用是記錄節點上數據的屬性類別的分布情況,這些數據用于計算對應節點的最佳分割屬性。決策樹節點在處理連續屬性時,需要維護2個統計直方圖,分別為Cbelow和Cabove。其中,Cbelow表示A≤C的類分布情況,Cabove表示A>C的類分布情況,A代表數據中該連續屬性的一個值,C代表當前選取的連續屬性分割值。隨著樹的創建,直方圖不斷更新,以尋找最佳分割點。對于每一個離散屬性,節點只需要維護1個直方圖,該直方圖也被稱為統計矩陣,用來對這個離散屬性具有的所有離散值分布情況進行記錄[7]。
2.3 分割指數
SPRINT算法采用Gini指數作為分割標準。在屬性選擇標準中,Gini指數算法是采用數據集的不純度作為屬性選擇標準的。一個節點t的Gini指數計算公式為:
(1)
其中,P(i|t)表示給定節點t中屬于類i的記錄所占的比例;C表示所有類的總個數。
如果以A作為集合,將集合劃分成節點B1和節點B2,則分割后的Gini指數計算方法為:
(2)
其中,n,n1,n2分別為A,B1,B2的記錄數。
SPRINT算法在所有的屬性中,選擇Ginisplit(A)具有最小值的A*作為分割標準,因為Ginisplit(A)越小表明分割屬性選擇得越好[8]。
3 SPRINT算法存在的缺點和改進方案
SPRINT算法通過Gini值來選擇分割屬性,然而這會引發多值偏向問題。多值偏向會導致生成非最優甚至是錯誤的決策樹,原因在于多值偏向在選擇分割屬性時,往往會選擇取值個數較多的屬性作為分割屬性,這就將分割結果與屬性的取值個數關聯到了一起,這種關聯是沒有道理的。文獻[9]首先通過理論分析,研究了多值偏向問題,然后直接通過算法表達式進行推理,證明了選擇Gini指數作為分割標準確實會引發多值偏向問題[9]。
針對多值偏向問題,文中提出了一種對SPRINT算法的改進方案。假設A為測試屬性,屬性A具有2個屬性值,每個屬性值對應的概率為p1,p2。算法先對屬性A進行第一次分割,{B1,B2}為這兩個節點的屬性,分別對應的不純度為Ginisplit(B1)和Ginisplit(B2),則:
(3)
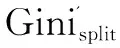
算法的詳細步驟如下:
(1)存在屬性候選集Q,算法依次從Q中選取每一個屬性作為測試屬性A,對A先進行一次二元分割,生成兩個新節點{B1,B2},并且每個節點的屬性值概率分別為p1和p2,此時不用計算兩個節點的Gini值。然后算法對B1和B2節點再次進行分割,又分別產生兩個節點,共計四個節點。計算Ginisplit(B1)和Ginisplit(B2)。
(4)對于所有生成的節點,如果滿足算法的停止條件,就將該節點設置為葉節點,并用它的所屬類標記,否則,就運用步驟(1)~(3)對節點繼續進行分割,直到算法結束。
4 基于MapReduce的并行化
4.1 原始數據的預處理
在云計算平臺中,考慮到負載均衡的原則,采用水平分割對整個數據集進行分段,將數據集平均地分配到所有處理器中。這樣數據集中的種類屬性能夠被均勻分組,不需要對數據再進行其他操作[10]。由于SPRINT算法對于連續數據是有特別要求的,即要求連續數據是已經排好序的。在算法開始時,由于原始數據中的連續屬性是沒有經過排序的,所以,在對數據水平分割后,處理器需要對其中的連續屬性進行排序和重新分組操作,使得連續屬性的屬性列表是一張相鄰有序的表[11]。
4.2 并行計算節點的最佳分割屬性
在并行環境中,計算當前節點的最佳分割屬性時,需要對連續屬性和離散屬性分別進行處理。
對于連續屬性,算法初始化Cbelow和Cabove類直方圖,同時各個節點進行通信。Cbelow記錄該處理器之下的數據,Cabove記錄該處理器之上的數據[12]。然后對該屬性列表的所有數據進行檢索,同時更新兩個類直方圖,并且根據直方圖的信息,計算每個連續值的Gini指數。在當前計算的所有連續值中選取一個具有最小Gini指數的連續值作為該屬性的第一層最佳分割點。
對于離散屬性,每個處理器根據自身所擁有的數據建立對應該屬性局部的類直方圖C,同時獲取一個協助處理器,這個協助處理器的任務是匯總同一屬性的所有局部類直方圖,將這些信息相加,就得到了該屬性的全局類直方圖信息[13]。然后根據協助處理器所記錄的該屬性全局直方圖信息,就能夠計算出該屬性的第一層最佳分割點。
4.3 分割節點的屬性列表
完成最佳分割點的計算之后,每個處理器根據該最佳分割和行索引,對自己擁有的屬性列表進行分割,同時創建局部哈希表。然后,所有處理器進行通信,共享自己剛剛建立的局部哈希表,所有哈希表進行匯總整理后,就可以創建全局哈希表。每個處理通過查找該全局哈希表,對自己的數據進行分割,分割完后,將分割的數據存入子節點中。分配完后,決策樹的一個節點就創建了。重復以上步驟,直到滿足節點不再需要分割的條件,即為葉子節點[14]。
5 實 驗
5.1 實驗內容
實驗所選取的數據集來自于UCI網站的Acute Inflammations數據集。該數據集的數據來源是一個醫學專家數據集測試系統,它將執行的推斷是診斷泌尿系統的兩種疾病。數據集總共包含6個屬性,其中有1個連續屬性。數據集內的數據形式為“35,9nonoyesyesyesyesno”,最后2個是類別屬性,decision:Inflammation of urinary bladder和decision:Nephritis of renal pelvis origin。實驗選擇第一個類別屬性。
實驗對數據集使用未改進的SPRINT算法進行分割,產生的決策樹如圖2所示。

圖2 原SPRINT算法生成的決策樹
然后將同一數據集用改進后的算法進行分類,產生的決策樹如圖3所示。
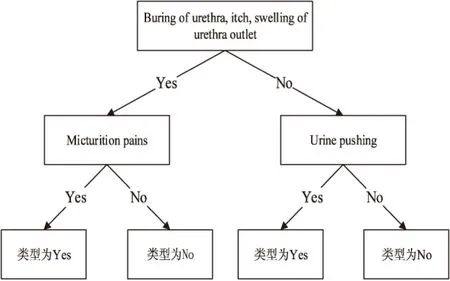
圖3 改進SPRINT算法生成的決策樹
5.2 實驗結果分析
下面,分析改進后的算法是如何生成圖2的決策樹的,僅分析第一個分割屬性的生成過程。算法依次將各個節點作為第一個分類屬性,然后選取另一個分類屬性進行決策。如果選擇Buring of urethra對樣本先進行分類,接著分別選取5個其他的屬性進行分類,左子樹用Temperature of patient分類,結果為:
Ginisplit(Temperature of patient<38.0)=20/50Gini(左)+30/50Gini(右)=20/50(1- (20/20)2-(0/20)2)+30/50(1-(9/30)2- (21/30)2)=0.252
若左子樹用Occurrence of nausea分類,結果為:
Ginisplit(Occurrence of nausea)=41/50Gini(左)+9/50Gini(右)=41/50(1-(20/41)2- (21/41)2)+9/50(1-(9/9)2-(0/9)2)= 0.409 7
若左子樹用Lumbar pain分類,結果為:
Ginisplit(Lumbar pain)=20/50(1-(20/20)2- (0/20)2)+30/50(1-(9/30)2-(21/30)2)= 0.252
若左子樹用Urine pushing分類,結果為:
Ginisplit(Urine pushing)=0/50(1-(0)2-(0)2)+50/50(1-(21/50)2-(29/50)2)=0.487 2
若左子樹用Micturition pains分類,結果為:
Ginisplit(Micturition pains)=29/50(1-(29/29)2-(0/29)2)+21/50(1-(0/21)2-(21/21)2)=0
然后計算右子樹,得到Ginisplit(Urine pushing)=0,那么最小的Ginisplit’(Buring of urethra)=50/120Ginisplit(Micturition pains) +70/120Ginisplit(Urine pushing)=0。
用同樣的方法計算其他分割點的Ginisplit’,選出最小的Ginisplit’(A*),A*=Buringofurethra時,Ginisplit’(A*)最小,所以選擇Buringofurethra作為第一層的分割屬性。
5.3 改進算法應用于并行化環境
實驗運用Adult數據集。實驗過程中,不斷添加物理機的個數,產生的折線圖如圖4所示。

圖4 生成第一個節點和計算節點數量的關系
從圖中可以看出,隨著計算節點的不斷增加,算法運行時間不斷縮減。
6 結束語
文中對SPRINT算法進行了改進,當算法選取最佳分割屬性時,不僅考慮該次分割的Gini指數,而且繼續考慮下次分割帶來的Gini指數。改進算法在層數上明顯優于原算法。在算法的執行時間上,通過在云計算平臺上增加計算節點,可以大大提高算法的執行速度。實驗結果表明,文中提出的算法是有效的。
[1] 李玲娟,張 敏.云計算環境下關聯規則挖掘算法的研究[J].計算機技術與發展,2011,21(2):43-46.
[2] 張曉洲.云計算關鍵技術及發展現狀研究[J].網絡與信息,2011,25(9):36-37.
[3] 王靜紅,王熙照,邵艷華,等.決策樹算法的研究及優化[J].微機發展(現更名:計算機技術與發展),2004,14(9):30-32.
[4] Dean J,Ghemawat S.MapReduce:simplified data processing on large clusters[J].Communications of the ACM,2008,51(1):107-113.
[5] Settouti N,Aourag H.A comparative study of the physical and mechanical properties of hydrogen using data mining research techniques[J].JOM,2015,67(9):1-9.
[6] Hu Q H,Che X J,Zhang L,et al.Rank entropy-based decision trees for monotonic classification[J].IEEE Transactions on Knowledge and Data Engineering,2012,24(99):1.
[7] 王熙照,楊晨曉.分支合并對決策樹歸納學習的影響[J].計算機學報,2007,30(8):1251-1258.
[8] Chen Jin,Luo Delin,Mu Fenxiang.An improved ID3 decision tree algorithm[C]//Proceedings of 2009 4th international conference on computer science & education.[s.l.]:[s.n.],2009:127-130.
[9] 韓松來,張 輝,周華平.決策樹算法中多值偏向問題的理論分析[C]//全國自動化新技術學術交流會會議論文集(一).出版地不詳:出版者不詳,2005.
[10] Elyasigomari V,Mirjafari M S,Screen H R C,et al.Cancer classification using a novel gene selection approach by means of shuffling based on data clustering with optimization[J].Applied Soft Computing,2015,35:43-51.
[11] 王云飛.SPRINT分類算法的改進[J].科學技術與工程,2008,8(23):6248-6252.
[12] 董 峰,劉遠軍.數據挖掘中決策樹SPRINT算法探討[J].邵陽學院學報:自然科學版,2007,4(2):23-25.
[13] 魏紅寧.基于SPRINT方法的并行決策樹分類研究[J].計算機應用,2005,25(1):39-41.
[14] Yang Shiueng-Bien,Yang Shen-I.New decision tree based on genetic algorithm[C]//Computer control and automation.[s.l.]:[s.n.],2010:115-118.
Research on SPRINT Algorithm Based on Cloud Computing
YANG Jie,HUANG Gang
(School of Computer,Nanjing University of Posts and Telecommunications,Nanjing 210003,China)
Decision tree is a very important technology in data mining,which is often used for data analysis and forecasting.When the traditional decision tree algorithm is dealing with massive data mining,the CPU and memory is limited,resulting in its shortcomings like long time-consuming,poor fault tolerance and small storage capacity.Faced with massive data processing,cloud computing has a lot of advantages in this respect.It places emphasis on the good algorithm of SPRINT.First of all,it is optimized,and then parallelized in order to make the optimized algorithm better applied to cloud computing.When traditional SPRINT algorithm generates the decision tree,multi-valued bias problem will happen,and when it generates a node,through the calculation of Gini index of two layer,the effects of multi-valued bias is reduced.In parallel algorithm,through the distribution of data to the processor execution,then collecting and processing,the total time of execution is reduced.The experimental results show that the improved SPRINT algorithm based on cloud computing platform has better classification accuracy,and at the same time,its execution speed gets obvious improvement.
cloud computing;MapReduce;SPRINT algorithm;Gini index
2016-04-12
2016-08-10
時間:2017-01-10
國家自然科學基金資助項目(GZ211018)
楊 潔(1991-),男,研究方向為計算機云計算與大數據應用;黃 剛,教授,研究方向為計算機軟件理論及應用。
http://www.cnki.net/kcms/detail/61.1450.TP.20170110.1028.070.html
TP301.6
A
1673-629X(2017)03-0108-05
10.3969/j.issn.1673-629X.2017.03.022
猜你喜歡
西北民族大學學報(自然科學版)(2021年4期)2021-12-29 02:54:24
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
大眾健康(2021年6期)2021-06-08 19:30:06
小聰仔(科普版)(2020年12期)2021-01-18 09:16:52
東方少年·布老虎畫刊(2020年4期)2020-06-08 15:48:10
學生天地(2019年32期)2019-08-25 08:55:22
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
小天使·一年級語數英綜合(2017年11期)2017-12-05 18:49:56
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
