海量圖書檢索信息的快速查詢系統(tǒng)優(yōu)化設計研究
2017-04-10 20:28:46高玉平
現(xiàn)代電子技術 2017年6期
關鍵詞:信息檢索
高玉平
摘 要: 以往依據(jù)關鍵詞的檢索方法,在對海量圖書檢索信息進行查詢過程中,無法滿足海量信息的大批量檢索需求,存在查詢效率低和誤差高的缺陷。因此,設計基于分布式架構的海量圖書檢索信息的快速查詢系統(tǒng),系統(tǒng)中的各組件通過并行數(shù)據(jù)庫和分布式存儲實現(xiàn)交互。該系統(tǒng)的功能模塊包括用戶管理模塊、數(shù)據(jù)抽取模塊、索引創(chuàng)建模塊、文本查詢模塊及索引檢索模塊。分析了系統(tǒng)各功能模塊的設計和實現(xiàn)過程,這些功能模塊共同對外提供圖書信息的快速查詢服務。實驗結果表明,所設計系統(tǒng)可實現(xiàn)海量圖書檢索信息的快速、精確查詢,并且具有較高的索引創(chuàng)建和索引檢索性能。
關鍵詞: 海量圖書信息; 信息檢索; 快速查詢系統(tǒng); 分布式架構
中圖分類號: TN911?34; TP39 文獻標識碼: A 文章編號: 1004?373X(2017)06?0005?05
Abstract: The previous keywords retrieval method can not meet the retrieval requirements massive information in the query process of information retrieval for mass books, and has defects of low query efficiency and high error. Therefore, a fast query system for massive bookinformation retrievalthe is designed. Each assembly in the system realizes their interaction by means of parallel database and distributed storage. Function modules of the system are user management module, data extraction module, index creation module, text query module and index retrieval module. The process of each function module′s design and implementation of the system is analysed. These function modules provide a fast query service of book information. The experimental results indicate that the system can realize fast and accurate query of retrieval information of massive books, and has high index creation and index retrieval performance.
Keywords: massive book information; information retrieve; fast query system; distributed framework
0 引 言
隨著信息技術和互聯(lián)網(wǎng)技術的快速發(fā)展,當前的信息總量不斷增加。圖書是重要的信息存儲方式,圖書信息的數(shù)量和規(guī)模也呈現(xiàn)膨脹式增長趨勢。從海量圖書信息中快速獲取用戶所需的數(shù)據(jù),成為相關人員著手解決的關鍵問題[1?3]。而以往的依據(jù)關鍵詞的檢索方法,對海量圖書檢索信息進行查詢過程中,無法滿足海量信息的大批量檢索需求,存在查詢效率低和誤差高的缺陷[4?5]。文獻[6]通過分詞方法完成海量圖書檢索信息的查詢,該方法按照相應的規(guī)范和方法對文本進行自主分詞,再對檢索結果進行詞匯匹配分析,完成圖書檢索信息的快速查詢,但是該方法無法對中文進行有效分詞,存在查詢準確率低的缺陷。文獻[7]分析了依據(jù)局域網(wǎng)以及純文本種類的圖書信息查詢系統(tǒng),該種系統(tǒng)需要對各接口進行二次開發(fā),存在工作量高的缺陷,導致圖書信息查詢效率大大降低。文獻[8]提成了依據(jù)關鍵詞全文檢索的圖書信息查詢方法,但是關鍵詞通常無法準確反映用戶的查詢意圖,該方法會向用戶顯示大量的信息,存在查準率低的問題。文獻[9]設計了依據(jù)Web的圖書信息查詢系統(tǒng),采用Web技術從海量圖書檢索信息中查詢用戶所需信息。但是海量的圖書信息會降低用戶查詢興趣度,并且從海量信息中采集滿足用戶的有價值信息,需要耗費大量的時間。文獻[10]依據(jù)關鍵詞的檢索方法,對海量圖書檢索信息進行查詢過程中,無法滿足海量信息的大批量檢索需求,存在查詢效率低和誤差高的缺陷。
針對上述問題,設計了基于分布式架構的海量圖書檢索信息的快速查詢系統(tǒng)。實驗結果表明,所設計系統(tǒng)可實現(xiàn)海量圖書檢索信息的快速、精確查詢,并且具有較高的索引創(chuàng)建和索引檢索性能,取得了令人滿意的效果。
1 海量圖書檢索信息的快速查詢系統(tǒng)優(yōu)化設計
1.1 系統(tǒng)的架構設計
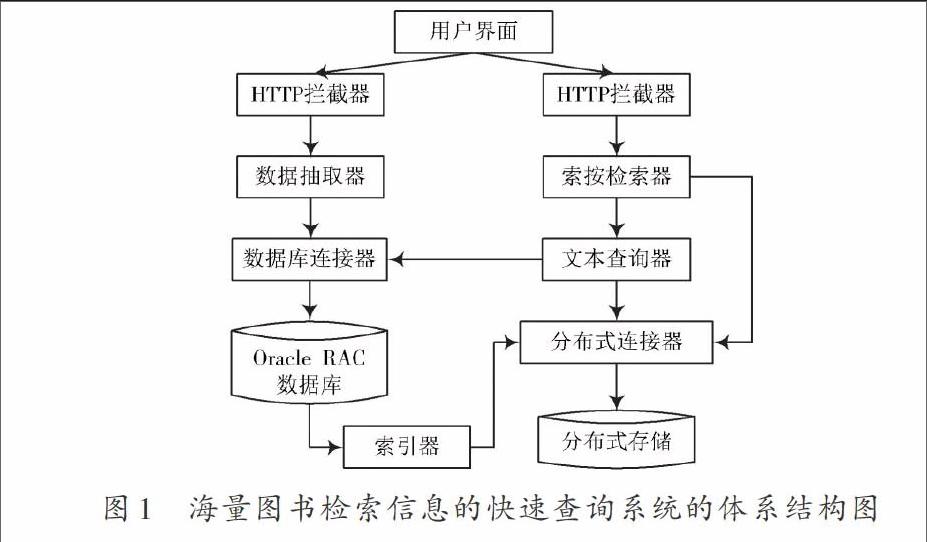
基于分布式架構的海量圖書檢索信息的快速查詢系統(tǒng)的結構圖如圖1所示。從圖1可以看出該系統(tǒng)包括用戶界面、HTTP攔截器、數(shù)據(jù)庫連接器、數(shù)據(jù)抽取器、索引器、索引檢索器、文本查詢器及索引分布式連接器等組件。這些組件間實現(xiàn)交互的連接件為并行數(shù)據(jù)庫 Oracle和分布式存儲。
用戶界面組件通過JSP技術完成界面的展示,通過Struts2技術分析用戶提成的圖書信息查詢申請,采用JDBC技術訪問Oracle數(shù)據(jù)庫,實現(xiàn)數(shù)據(jù)庫數(shù)據(jù)的讀寫操作,塑造依據(jù)B/S體系結構的Web應用程序。
數(shù)據(jù)庫連接器、數(shù)據(jù)抽取服務、HTTP攔截器、索引更新服務組件,用于實現(xiàn)海量圖書信息數(shù)據(jù)抽取以及文本索引維護。數(shù)據(jù)庫連接器、文本查詢服務、HTTP攔截器以及索引檢索服務組件實現(xiàn)關鍵詞查詢,主要有海量圖書信息全文查詢和文本信息查詢兩部分。其中,數(shù)據(jù)庫連接器實現(xiàn)JDBC同Oracle數(shù)據(jù)庫間的連接。數(shù)據(jù)抽取器實現(xiàn)對數(shù)據(jù)庫的CRUD處理,分布式連接器實現(xiàn)應用程序同分布式存儲間的連接,進而采用相關服務,完成索引的管理和信息查詢。HTTP攔截器實現(xiàn)用戶申請和響應申請。索引檢索器可控制分布式存儲中的檢索服務,實現(xiàn)海量圖書信息索引的檢索。文本查詢器完成通過rowid及其他查詢條件查詢數(shù)據(jù)庫的操作任務。分布式存儲是依據(jù)全文索引的分布式存儲系統(tǒng),其在Lucene服務引擎中集成了大量接口,確保用戶調用相關操作命令,完成圖書信息的查詢操作。分布式存儲可將圖書信息的全文索引分割成不同的分段、分片以及分片副本,并分別保存在分布式存儲集群中不同數(shù)據(jù)節(jié)點并可對不同的分片進行操作和協(xié)助,確保不同數(shù)據(jù)節(jié)點間通信的均衡化。一個索引由不同的分片構成,各分片可看成微小的搜索引擎。
對索引進行查詢是分布式處理過程,也就是分布式存儲應查詢索引中的不同分片中的數(shù)據(jù)復制,并將查詢結果匯總至單一結果集中。同種硬件條件下,該種查詢方式可支撐海量的信息負載查詢,實現(xiàn)海量圖書檢索信息的快速查詢。系統(tǒng)中的數(shù)據(jù)庫存儲Oracle RAC組件,完成數(shù)據(jù)的并行存儲。
1.2 系統(tǒng)功能模塊的設計與實現(xiàn)
設計的海量圖書檢索信息快速查詢系統(tǒng)通過HTTP服務方式對外提供服務。該系統(tǒng)的功能模塊包括用戶管理模塊、數(shù)據(jù)抽取模塊、索引創(chuàng)建模塊、索引重構模塊、文本查詢模塊及索引檢索模塊。這些模塊共同對外提供圖書信息的快速查詢服務。
系統(tǒng)中的用戶管理模塊對用戶信息進行管理,依據(jù)不同的用戶種類,修改用戶權限信息和登錄信息等;數(shù)據(jù)抽取模塊采集數(shù)據(jù)庫中的文本備份數(shù)據(jù),將數(shù)據(jù)集反饋給索引創(chuàng)建模塊完成數(shù)據(jù)的操作。索引創(chuàng)建模塊讀取采集的文本數(shù)據(jù)集,通過分布式存儲創(chuàng)建索引引擎,塑造文本索引,同時將索引寫入文件系統(tǒng)中;索引檢索模塊實現(xiàn)用戶的圖書信息檢索,可檢索相應分區(qū)中的索引數(shù)據(jù)集,并且將獲取的索引數(shù)據(jù)集當成文本查詢模塊的查詢條件;文本查詢模塊采集數(shù)據(jù)庫中文本數(shù)據(jù),將滿足rowid的匹配數(shù)據(jù)集合,通過多線程手段打包返回。
1.2.1 數(shù)據(jù)抽取模塊的設計與實現(xiàn)
設計的數(shù)據(jù)抽取模塊采用Quartz 定時器技術,在每天的0:00運行數(shù)據(jù)抽取模塊的定時任務,并將抽取出的文本信息結果集當成索引創(chuàng)建模塊的輸入信息。設置創(chuàng)建索引的終止時間為定時任務的開始時間,采集數(shù)據(jù)庫中低于該時間的全部分區(qū)數(shù)據(jù),依據(jù)分區(qū)名創(chuàng)建索引。如果創(chuàng)建索引失敗,則結束本次創(chuàng)建索引任務,等待下次創(chuàng)建索引任務開始。
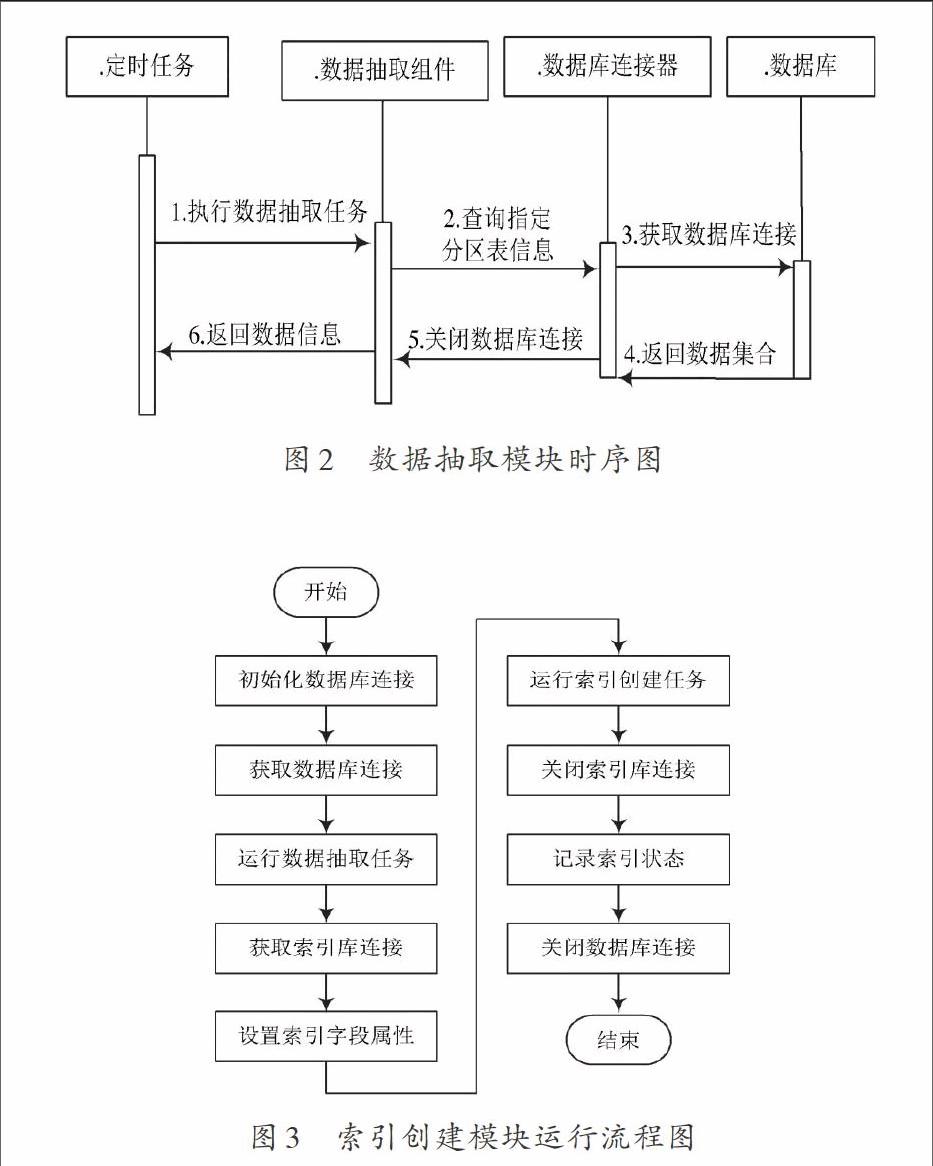
Quartz定時器能夠同J2EE 和J2SE應用程序融合,運行十個、百個、甚至萬個Jobs的日程序表。通過Java庫發(fā)布文件(.jar文件)開發(fā)Quartz,該文件中存在全部的Quartz功能,這些功能的關鍵接口(API)為Scheduler接口,該種接口可實現(xiàn)任務在日程中的融合和終止。Quartz定時器內的任務可為Java代碼,定時器通過調用作業(yè),確保作業(yè)處于工作時間。定時器可創(chuàng)造可循環(huán)的調度表。定時任務通過Quartz定時器,在固定的時間內運行數(shù)據(jù)抽取模塊,采集數(shù)據(jù)庫中不同分區(qū)數(shù)據(jù),并將采集到的數(shù)據(jù)讀入內存,向文本索引創(chuàng)建過程提供依據(jù)。圖2時序圖描述了定時任務采用數(shù)據(jù)抽取模塊完成文本信息采集的流程。
1.2.2 索引創(chuàng)建模塊設計與實現(xiàn)
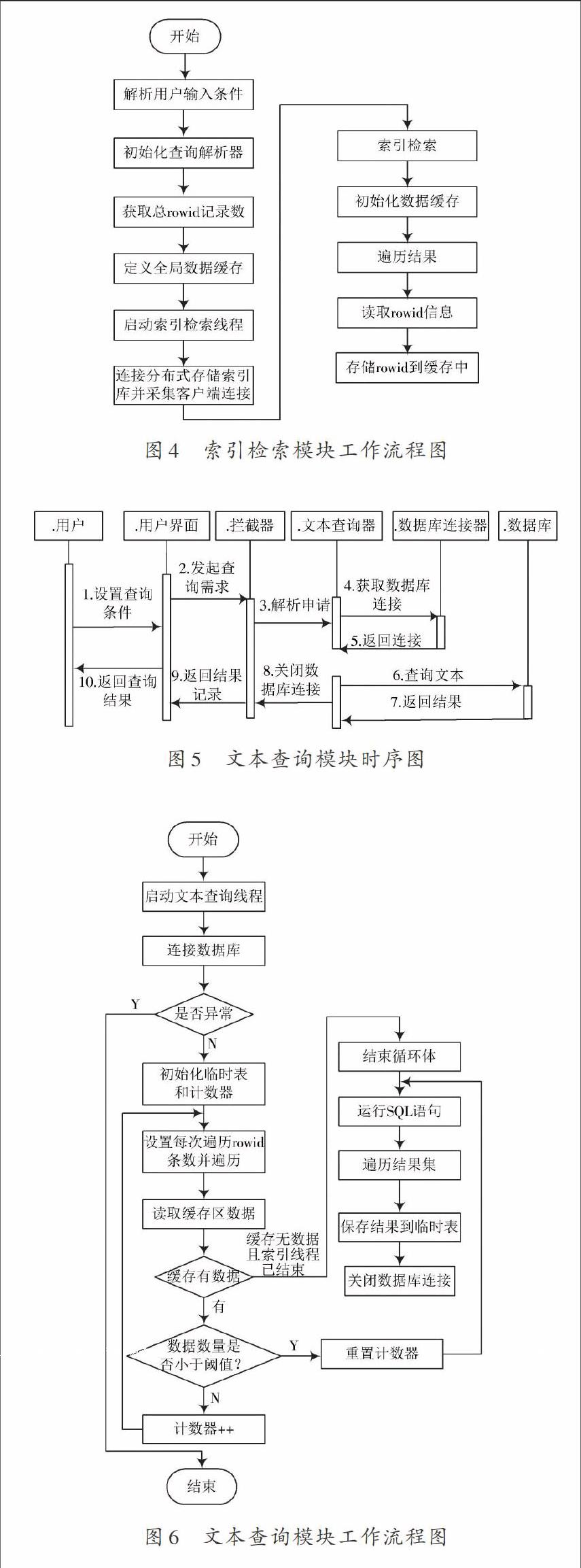
采用類IndexTaskManager完成索引創(chuàng)建模塊,該類采用Quartz定時任務器申請運行,通過數(shù)據(jù)抽取模塊、數(shù)據(jù)庫連接請求執(zhí)行以及分布式存儲索引庫連接器交互,實現(xiàn)索引創(chuàng)建模塊的運行。圖3給出了索引創(chuàng)建模塊的運行流程圖。
1.2.3 索引檢索模塊的設計與實現(xiàn)
塑造全文索引過程中,各分區(qū)名以及索引名間相互對應。依據(jù)不同的發(fā)送日期劃分不同的數(shù)據(jù)分區(qū)。因此,當用戶查詢條件中不存在起始和終止時間,則檢索索引索引文件;否則按照用戶申請的時間,檢索相應的索引分區(qū)名,極大增強了圖書信息的檢索效率。索引檢索模塊的結果為rowid的集合,是文本查詢模塊進行分析的依據(jù)。索引檢索模塊的運行流程圖如圖4所示。
1.2.4 文本查詢模塊的設計
通過文本查詢器運行文本查詢模塊,其采用數(shù)據(jù)連接器同Oracle 數(shù)據(jù)庫相連,檢索數(shù)據(jù)庫分區(qū)表,同時將檢索結果反饋給用戶。文本查詢模塊的時序圖如圖5所示。文本查詢模塊采用文本查詢線程,運行數(shù)據(jù)庫查詢任務。該線程采集全局共享緩存區(qū)中的 rowid信息,同時依據(jù)用戶查詢條件,構成SQL 語句,對數(shù)據(jù)庫進行查詢,最終向數(shù)據(jù)庫臨時表中存儲查詢結果,為用戶界面進行導出數(shù)據(jù)提供服務。文本查詢模塊通過SQL查詢數(shù)據(jù)庫,因為 Oracle數(shù)據(jù)庫要求SQL的最高長度為4 500個字符,因此,設置rowid每次查詢700個,利用In方式查詢。文本查詢模塊的運行流程圖如圖6所示。
2 實驗分析
通過實驗對本文設計的基于分布式架構的海量圖書檢索信息的快速查詢系統(tǒng)的性能進行測試。實驗通過表1和表2 的多條件檢索和單關鍵詞查詢條件檢索測試用例,檢測本文系統(tǒng)的測試結果的有效性。
通過表1和表2可以看出,本文系統(tǒng)可準確查詢出多條件檢索和單關鍵詞查詢條件檢索結果,是有效的圖書檢索信息查詢系統(tǒng)。
實驗對基于關鍵詞的信息查詢系統(tǒng)和本文系統(tǒng)的性能進行檢測時,主要對兩種系統(tǒng)的索引創(chuàng)建以及檢索性能進行測試。檢測數(shù)據(jù)是單臺Oracle數(shù)據(jù)庫服務器中的3.5億條圖書信息記錄,分布式存儲以及檢索服務器模擬3個服務器,同時模擬6個分片以及單個備份節(jié)點當成檢測環(huán)境,對本文系統(tǒng)的查詢性能進行檢測。
分析兩種系統(tǒng)的CPU占用率、內存占率、I/O的使用率等指標,對本文系統(tǒng)的索引創(chuàng)建性能進行檢測。兩種進行圖書檢索信息查詢過程中的索引創(chuàng)建壓力測試結果如圖7和圖8所示。
具體性能值如表3,表4所示。
分析圖7、圖8以及表3和表4可得,相對比基于關鍵詞的圖書信息查詢系統(tǒng),本文系統(tǒng)創(chuàng)建索引的效率和性能較高,并且會增加文件存儲空間;本文系統(tǒng)的I/O讀寫更為頻繁,吞吐量更高。說明本文系統(tǒng)能夠完成海量圖書檢索信息的快速、準確查詢。
表5和表6分別是基于關鍵詞的圖書信息查詢系統(tǒng)以及本文系統(tǒng)的索引檢索性能測試結果,包括樣本數(shù)量、吞吐量以及平均值三個參數(shù)。其中,樣本數(shù)量表示發(fā)送到服務器的全部用戶申請數(shù)量;吞吐量值是系統(tǒng)服務器單位時間操作的用戶查詢申請數(shù);平均值是系統(tǒng)進行圖書信息查詢過程中的總運行時間同申請數(shù)的比值。
對比表5和表6可以看出,本文系統(tǒng)的樣本數(shù)量、吞吐量以及平均值均優(yōu)于基于關鍵詞的信息查詢系統(tǒng),本文系統(tǒng)具有較高的索引檢索性能。
通過上述實驗可得相對于基于關鍵詞的信息查詢系統(tǒng),本文系統(tǒng)的索引創(chuàng)建性能和檢索性能都較高,可以滿足用戶的查詢需求。
3 結 論
以往的依據(jù)關鍵詞的檢索方法,在對海量圖書檢索信息進行查詢過程中,無法滿足海量信息的大批量檢索需求,存在查詢效率低和誤差高的缺陷。因此,本文設計基于分布式架構的海量圖書檢索信息的快速查詢系統(tǒng),該系統(tǒng)中的各組件通過并行數(shù)據(jù)庫和分布式存儲實現(xiàn)交互。該系統(tǒng)的功能模塊有用戶管理模塊、數(shù)據(jù)抽取模塊、索引創(chuàng)建模塊、索引重構模塊、文本查詢模塊及索引檢索模塊。分析了系統(tǒng)各功能模塊的設計和實現(xiàn)過程,這些功能模塊共同對外提供圖書信息的快速查詢服務。實驗結果表明,所設計系統(tǒng)可實現(xiàn)海量圖書檢索信息的快速、精確查詢,并且具有較高的索引創(chuàng)建和索引檢索性能。
參考文獻
[1] 羅芳,李春花,周可,等.基于多屬性的海量Web數(shù)據(jù)關聯(lián)存儲及檢索系統(tǒng)[J].計算機工程與科學,2014,36(3):404?410.
[2] 劉鵬.基于Hadoop的結構化電子病歷存儲檢索系統(tǒng)研究與改進[J].中國數(shù)字醫(yī)學,2015,10(1):40?42.
[3] 孫霞,禹龍,田生偉,等.基于一致性Hash的分布式海量分子檢索模型[J].計算機應用,2015,35(4):956?959.
[4] 李維乾,李莉,張曉濱,等.Hadoop平臺下突發(fā)水污染應急預案并行化處置[J].西安工程大學學報,2015,29(6):733?739.
[5] 曹鋒.基于細微特征區(qū)分的海量圖像檢索模型仿真[J].計算機仿真,2015,32(9):368?371.
[6] 董岳珂.發(fā)現(xiàn)系統(tǒng)引發(fā)的關于信息素養(yǎng)教育的思考[J].圖書館論壇,2014,34(4):58?63.
[7] 宋一兵.基于本體的文獻情報信息檢索方法研究[J].青島理工大學學報,2015,36(4):82?86.
[8] 張廣慶,葛唯益,賀成龍.基于Simhash的海量相似文檔快速搜索優(yōu)化方法[J].指揮信息系統(tǒng)與技術,2015,6(2):61?65.
[9] 萬艷麗,雷行云,王巖,等.基于層次化深度學習的海量醫(yī)學影像組織與檢索研究[J].醫(yī)學信息學雜志,2015,36(5):46?51.
[10] 黃杰,曹錦梅,努爾艾拉·阿布力孜,等.維吾爾語在圖書館數(shù)據(jù)庫查詢系統(tǒng)中的應用[J].電腦與信息技術,2014,22(5):53?55.
猜你喜歡
華東理工大學學報(自然科學版)(2025年1期)2025-02-26 00:00:00
吉林化工學院學報(2021年8期)2021-09-06 09:35:12
科教導刊·電子版(2021年30期)2021-01-03 17:32:37
電腦與電信(2018年11期)2018-02-16 05:41:16
山西青年(2018年5期)2018-01-25 16:53:40
新聞傳播(2016年18期)2016-07-19 10:12:06
新聞傳播(2016年11期)2016-07-10 12:04:01
現(xiàn)代計算機(2016年11期)2016-02-28 18:35:15
地理與地理信息科學(2015年4期)2015-10-13 08:29:20
河南科技(2014年11期)2014-02-27 14:10:19
