一種改進的支持向量機模型研究
2017-04-10 08:48:47郭晨晨朱紅康
陜西科技大學學報 2017年2期
關鍵詞:分類
郭晨晨, 朱紅康
(山西師范大學 數學與計算機科學學院, 山西 臨汾 041000)
一種改進的支持向量機模型研究
郭晨晨, 朱紅康*
(山西師范大學 數學與計算機科學學院, 山西 臨汾 041000)
傳統的支持向量機無法充分、有效地檢測出類間重疊區域中的少數實例,也無法對不平衡的數據集作出合理分類,而類的重疊分布和不平衡分布在復雜數據集中是常見的.因而,它們對支持向量機的分類性能產生負面影響.基于此,提出了一種利用距離度量代替支持向量機松弛變量的改進模型.在一定程度上解決了支持向量機處理復雜數據集中類間重疊和不平衡的問題.最后,利用合成數據集和UCL數據庫中的數據集的實驗驗證了該算法的先進性.
支持向量機; 重疊; 不平衡; 松弛變量; 距離度量
0 引言
自Vapnik[1]提出支持向量機,因其有效的分
類性能,嚴謹的數學理論基礎,成為處理分類問題的熱門技術.在小樣本數據集、非線性分類問題中有很好的效果,特別對于高維數據的處理,可以有效的避免維數災難[2].支持向量機主要原理是最大化超平面邊距同時最小化分類誤差.但SVM無法充分、有效地檢測出類間重疊區域中的少數實例,也無法對不平衡的數據集作出合理分類.因為類間存在重疊區域時,類間清晰的超平面邊緣將不存在.而數據集中同時存在大樣本類和小樣本類時,支持向量機的處理結果往往趨向于大樣本類,使分類結果產生嚴重的偏差.針對SVM存在的問題,目前已經提出了一批實用的方法,比如對數據預處理方式進行調整,對大樣本類多取樣,對小樣本類少取樣[3-5];改良核函數矩陣調整聚類邊界降低迭代過程中原核矩陣與保形變換核矩陣之間會產生偏差[6];對誤報率和漏報率之間進行權衡控制[7];通過修改松弛變量減少異常數據點對自適應邊緣和決策函數的影響,利用數據點的平均值和標準差來克服數據擾動等[8-10].
本文試圖通過一種新的方式改善這一問題.即調整決策邊界,設置邊緣為適當距離提高分類性能.由于原有松弛變量模型在學習階段對離群數據點并不敏感,因而采用了新型的松弛變量模型,用距離度量代替原來的松弛變量,并在訓練階段適當擴大了異常點與正常點的距離.從而降低類分布的影響,使得大樣本類和小樣本類都能得到很好的劃分.基于距離度量的松弛變量被包含在對偶問題的最優函數中,參數由梯度下降法得到.使得改進的松弛變量模型不容易受到復雜數據集的影響.
1 改進松弛變量的支持向量機
1.1 傳統支持向量機
Vapnik[1]提出的支持向量機主要處理二分類問題,其核心思想如下:
在一個樣本空間中,由決策邊界將所有樣本分為兩個部分,即對訓練樣本集進行二元分類.對于一個含有n個樣本點的訓練樣本集,每個樣本點都表示為一個二元組,(xi,yi)(i=1,2,…,n)其中xi=(xi1,xi2,…,xik)T對應于第i個樣本的屬性集,yi∈{-1,1}表示分類結果.將原始空間中的樣本點xi通過映射函數φ(x)映射到高維特征空間中,得到線性支持向量機決策邊界基本形式如公式(1)所示:
f(x)=w·φ(x)+b
(1)
由于訓練數據集中可能存在的噪聲,即線性SVM不可分情況.必須考慮邊緣寬度與線性決策邊界允許的訓練錯誤數目之間的折中.從而引入松弛變量實現邊緣“軟化”,如公式(2)所示.
(w·φ(x)+b)≥1-ξi,當yi=+1;
(w·φ(x)+b)≤-1+ξi,當yi=-1.
(2)
式(2)中:?i,ξi≥0.
由于在決策邊界誤分樣本數沒有限制,從而可能產生邊緣很寬,但誤分離很多訓練實例的決策邊界.修改目標函數,以懲罰松弛變量值很大的決策邊界.修改后的目標函數如公式(3)所示.
s.t.yi(w·φ(x)+b)≥1-ξi
(3)
式(3)中:C是軟邊緣懲罰參數.
1.2 改進松弛變量的支持向量機
雖然在傳統SVM中利用軟邊緣的方法解決了線性不可分的問題,但這都建立在數據集中的類是大致平衡且少重疊的.針對數據集中存在的類間重疊和不平衡問題,利用距離度量代替原來的松弛變量ξi,在馬氏空間中放大了正常樣本與異常樣本的距離,如圖1所示.

圖1 馬氏空間中正常樣本與異常樣本的距離示意圖
此外,為了發現一個最佳超平面及邊緣以達到克服擾動的最大魯棒性并且減少錯誤分類風險的概率,超平面的變化過程如圖2所示.

圖2 超平面與邊緣變化過程
以上通過圖示展示改進產生的相關變化,下面對距離度量代替松弛變量ξi做具體解釋.
傳統的線性支持向量機的不可分情況如公式(3)所示,這里作出改進,將距離D(x)2替換原來的松弛變量ξi,并且最小化向量w而非原來的w與誤差余量的和.D(x)2表示每個樣本點與其各自類中心的歸一化距離,修改后的目標函數如下:
s.t.yif(xi)≥1-θD(xi)2
(4)
式(4)中:θ是預選參數,用于測量松弛變量的平均影響,距離計算如公式(5)所示:
(5)
式(5)中:S-1是協方差矩陣的逆,μ是均值向量,t是轉置符號.
樣本點與其各自類中心間的距離在一定范圍才能建立聯系,距離D(x)2滿足需要下面的約束條件:
0≤D(xi)2≤1
(6)
確定距離D(x)2,得到支持向量滿足下面的等式:
yif(xi)=1-θD(xi)2
(7)
由此,該優化問題的拉格朗日函數可以記作如下形式:
(8)
式(8)中:αi叫做拉格朗日乘子.
為了最小化拉格朗日函數,采用與傳統方法相似化的方法進行處理.對Lp關于w和b求偏導,并令它們等于0,得到(9)、(10)兩個等式:
(9)
(10)
w可由公式(11)得到:
(11)
使用b的平均值作為決策邊界的參數,計算公式如下:
αi{yif(xi)-1+θD(xi)2}=0
(12)
對于支持向量,將公式(11)帶入公式(8)可得:
(13)
這樣,不可分的對偶問題可以轉化為下面的優化問題:
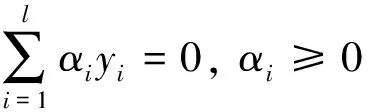
(14)
通過求解對偶問題得到最優參數w和b后,可以根據符號進行分類(公式1),參數θ可由梯度下降法求得,這是一個一階優化算法.本方法需要最大化公式(13)并且找到合適的參數θ,從而進行如下計算:
(15)

t≥0.
(16)
由于θ的不同取值會對整個優化問題的性質產生根本影響,因此需要對參數θ進行分類討論:
情況1:當θ=0,則邊緣不用修改,此問題轉化為硬邊緣SVM問題;
情況2:當θ=1,則該問題同傳統SVM相同;
情況3:當0<θ<1,則0<θ×D(xi)2<1,該算法對決策邊界右側的異常點有較好的效果,每個類中心的影響是有限的;
情況4:當θ>1,則θ×D(xi)2>1,對于落在錯誤位置的異常點,該算法性能強大.較大的θ使得支持向量靠近類中心,因而更容易得到一個清晰的決策邊界.然而,分類的錯誤率也會隨之增加,調整后的決策邊界更趨向于檢測異常點.

(17)

(18)
1.3 算法描述
根據上節的推導過程,設計相應的算法進行實驗分析.該算法需要對數據集xi進行最大次數T次的迭代運算,在每一次的迭代中,自適應的計算函數D(x)2并更新參數θ和σ的值,算法如下:
輸入:訓練數據集xi,核函數K,最大迭代次數T,終止條件η,核函數參數σ,規則化參數θ.
子函數:邊緣函數Margin(xi,σ) ,訓練模型SVM(xi,K,σ,θ) ,V-折交叉驗證函數V-Fold(xi,v) ;
主函數:v←1
{
xiv←V-Fold(xi,v);
Ctv←SVM(xiv,K,σK);
t←0;
While(Ctv-Ctv+1<η&t { t←t+1; } End While Cv←Ctv; v←v+1; } ReturnAccuracy; 輸出:Cv. 2.1 數據集復雜度的度量 分類算法性能的好壞很大程度上取決于訓練數據集本身的特性,以前的研究往往通過減少未知數據集的選取進行分類的弱比較,很難從統計學和幾何類分布角度來考慮分類結果.基于此,為了提高數據復雜度度量的合理性,采用兩種量度方式進行綜合評估. 2.1.1 Fisher鑒別準則 Fisher的廣義判別式(F1)[11]用來對兩個類間的區別進行鑒別,公式如下: (19) 這樣對于多維或多類數據集的類間重疊率(R1),可以表示為如下形式: (20) 2.1.2 重疊率 對于重疊率的計算,該方法采用的指標R2[12]進行度量,具體公式如下: (21) 式(21)中: min maxi=min{max(fi,ci),max(fi,c2)}, max mini=max{min(fi,ci),min(fi,c2)}, max maxi=max{max(fi,c1),max(fi,c2)}, min mini=min{min(fi,c1),min(fi,c2)}. max(fi,ci)和min(fi,ci)分別是類ci(i=1,2) 的特征值fi中的最大值和最小值.R2的值越小表明類間的重疊程度越高. 2.2 性能度量 準確率度量是將數據集中所有的類看成同等重要,因此并不適合分析不平衡數據集.在不平衡數據集中,少數類往往比多數類更有意義. 二元分類問題中,少數類通常記為正類,多數類記為負類.表1顯示了匯總分類模型正確和不正確預測的實例數目的混淆矩陣. 表1 類不是同等重要的二分類問題的混淆矩陣 混淆矩陣中的計數可以表示為百分比的形式.靈敏度定義為被模型正確預測的正樣本的比例,即: (22) 同理,特指度定義為被模型正確預測的負樣本的比例,即: (23) 精確度定義為模型正確預測的所有樣本的比例,即: (24) 通過該算法與傳統SVM進行性能對比來展示改進算法在復雜數據集分類性能上獲得的提升.對合成數據集的各個變量進行控制,產生三種因素的不同組合來研究類不平衡問題與類間重疊問題對分類精度產生的影響. 3.1 析因實驗 實驗一設計加入了三個程度的“類不平衡”因素、三個程度的“類重疊”因素、兩個種類的“分類器”幾種不同的情況,將它們安排在同一個析因實驗中.根據不同的處理組合產生合成數據集.每個數據集分為兩個類并且隨機地以二維正態分布,共100個實例. 重疊性根據重疊程度劃分為三個層次:低度:μ1=40,μ2=60;中度:μ1=45,μ2=55;高度:μ1=50,μ2=50. 則合成數據集的協方差矩陣定義為: 同理,將不平衡性劃分為三個不同層次.低度:50%的實例屬于第一類,50%的實例屬于第二類;中度:75%的實例屬于第一類,25%的實例屬于第二類;高度:90%的實例屬于第一類,10%的實例屬于第二類. 分類器因素:一種是傳統的SVM,一種是本文改進算法. 根據上面的各種因素設計出9種不同的合成數據集,其中坐標軸Y軸對類重疊性和類不平衡性沒有影響.分別將類重疊的低、中、高三種程度表示為1、2、3,類不平衡的低、中、高三種程度表示為一、二、三,“×”表示少數類,“Ο”表示多數類,實驗結果如圖3所示. 圖3 合成數據集聚類實驗 表2顯示了用R1和R2兩種測量指標對合成數據集的計算結果. 表2 合成數據集的R1和R2指標計算結果 根據表2中的指標數據,得到最終實驗結果,如表3所示. 表3 數據集不同程度重疊性和不平衡性的度量結果對比 從表3可知,改進算法在靈敏度和準確度上均有較大提升,特別在高度重疊性和高度不平衡性的合成數據集中體現的尤為明顯,在中低度層面基本保持不變.結果表明,數據復雜性(重疊性和不平衡性)對分類精確度影響明顯,且成反相關性. 3.2 UCI數據集實驗 實驗二設計從UCI數據庫中選擇6個數據集進行測試,如表4所示. 表4 UCI數據集測試 表4中,第二列中括號中的數據分別表示多數類和少數類樣本的數量,即正樣本和負樣本的數量.僅從正負樣本的比例分析,German、Glass、BCW數據集存在低度不平衡性,Yeast和Car數據集存在中度不平衡性,Abalone數據集存在高度不平衡性.但考慮復雜性度量指標R1和R2,Yeast是最不平衡的.因此,單一分析正負樣本率不能充分了解數據集的特性. 除了考慮數據復雜度對分類精度產生的影響外,還需要對分類器的性能進行驗證.使用4-交叉驗證法驗證傳統SVM和本文改進算法的性能.該方法將原始數據集分為兩部分,一部分為訓練數據集,一部分為測試數據集.首先用訓練集對分類器進行訓練,再利用驗證集來測試訓練得到的模型,以此來做為評價分類器的性能指標.使用多折交叉驗證主要為了提高可利用的訓練數據集樣本數量.此外,可以分為多個相互獨立的測試數據集有效地覆蓋整個樣本空間.實驗二重復4次,得出結果. 核函數選擇徑向基核函數(Radial Basis Kernel Function),利用梯度下降法獲得參數θ和σ,終止條件設置為100,并在迭代50次后得到穩定的參數.實驗結果如表5所示. 表5 SVM與本文所提算法在UCI數據庫上的對比結果 由表5可得,改進算法關于三種指標的度量值均優于傳統SVM.此外,由4-交叉驗證法得到參數的θ值與數據集的復雜度成正相關,而參數σ僅依賴于數據的規格參數.從表5可得,前三個數據集參數θ值均少于1.5,數據集的復雜度相應地呈現低度狀態,而參數σ明顯不具有這樣的性質. 根據以上兩個實驗可得,改進算法在分類性能方面明顯優于傳統SVM,即柔性地距離邊緣適合在重疊且不平衡類分布的區域預測稀有樣本. 本文展示了一種新的SVM二次優化模型,通過改變特征空間中決策邊界到邊緣的距離改良邊緣的性能.自適應的邊緣模型可以在訓練復雜數據集方面顯示良好的分類性能.現實生活中往往存在這樣的規律,少數類的正確分類要比多數類的正確分類更有價值.因此,本文所提方法才顯示出其應用的潛力.未來的工作是將本方法應用到更多現實生活中存在不平衡和重疊性的數據集中,并根據應用情況調整算法細節. [1] Vapnik V.The nature of statistical learning theory[M].New York:Springer Verlag,1995:142-165. [2] Tan P N,Steinbach M,Kumar V.Introduction to data mining[M].New Jersey:Addison Wesley,2005:115-131. [3] Zhao H,Chen H,Nguyen T.Stratified over-sampling bagging method for random forests on imbalanced data[M].Switzerland:Springer International Publishing,2016:46-60. [4] Vluymans S,Tarragó D S,Saeys Y.Fuzzy rough classifiers for class imbalanced multi-instance data[J].Pattern Recognition,2016,53:36-45. [5] Liu Alexander,Ghosh J,Martin C.Generative oversampling for mining imbalanced datasets[C]∥Proceedings of 2007 International Conference on Data Mining .Las Vegas,Nevada,USA :CSREA Press,2007:66-72. [6] Wu G,Chang E Y.KBA:Kernel boundary alignment considering imbalanced data distribution[J].IEEE Transactions on Knowledge and Data Engineering,2005,17:786-794. [7] 徐小鳳,劉家芬,鄭宇衛. 基于密度的空間數據聚類的正常用戶篩選方法[J].計算機應用,2015,35(S1):43-46. [8] Trafalis T B,Gilbert R C.Robust classification and regression using support vector machines[J].European Journal of Operational Research,2006,173(3):893-909. [9] Trafalis T B,Gilbert R C.Robust support vector machines for classification and computational issues[J].Optimization Methods and Software,2007,22:187-198. [10] Song Q,Hu W,Xie W.Robust support vector machine with bullet hole image classification[J].IEEE Transactions on Systems Man and Cybernetics Part C (Applications and Reviews) ,2002,32:440-448. [11] Mollineda R A,Snchez J S,Sotoca J M.Data characterization for effective prototype selection[J].Iberian Conference on Pattern Recognition & Image Analysis,2005,523(20):295-302. [12] Ho T K,Basu M.Complexity measures of supervised classification problems[J].IEEE Transactions on Pattern Analysis & Machine Intelligence,2002,24(3):289-300. 【責任編輯:蔣亞儒】 Research on an improved support vector machine model GUO Chen-chen, ZHU Hong-kang* (School of Mathematics and Computer Science, Shanxi Normal University, Linfen 041000, China) Traditional support vector machines can not sufficiently and effectively detect the instance of the minority class in the overlap region and can not make a reasonable classification of the imbalanced data sets.However,the overlapping and imbalanced of the classes are common in complicated data sets.As a result,they have a negative impact on the classification performance of support vector machines.Based on this,an improved model is proposed to replace the slack variables of support vector machine based on distance measure.To a certain extent,it solves the problem that the support vector machine is dealing the overlapping and imbalanced of the classes in complicated data sets.Finally,the advanced nature of the algorithm is verified by the experimental results of the data set in the synthetic data set and the UCL database. support vector machine; overlapping; imbalanced; slack variable; distance measure 2017-01-16 基金項目:山西省自然科學基金項目(2015011040) 郭晨晨(1992-),男,山西長治人,在讀碩士研究生,研究方向:計算機應用 朱紅康(1975-),男,山西汾西人,副教授,博士,研究方向:數據挖掘,zhuhkyx@126.com 1000-5811(2017)02-0189-06 TP18 A


2 性能測試


3 實驗





4 結論
猜你喜歡
西北民族大學學報(自然科學版)(2021年4期)2021-12-29 02:54:24
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
大眾健康(2021年6期)2021-06-08 19:30:06
小聰仔(科普版)(2020年12期)2021-01-18 09:16:52
東方少年·布老虎畫刊(2020年4期)2020-06-08 15:48:10
學生天地(2019年32期)2019-08-25 08:55:22
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
小天使·一年級語數英綜合(2017年11期)2017-12-05 18:49:56
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
