基于交互式條件隨機場的RGB-D圖像語義分割
2017-04-14 00:47:16左向梅茍婷婷
計算機應用與軟件 2017年3期
左向梅 趙 振 茍婷婷
(中國飛行試驗研究院 陜西 西安 710089)
基于交互式條件隨機場的RGB-D圖像語義分割
左向梅 趙 振 茍婷婷
(中國飛行試驗研究院 陜西 西安 710089)
RGB-D圖像語義分割是場景識別與分析的基礎步驟,基于條件隨機場(CRF)的圖像分割方法不能有效應用于復雜多變的現實場景,因此提出一種交互式條件隨機場的RGB-D圖像語義分割方法。首先利用中值濾波和形態重構方法對Kinect相機拍攝的RGB-D圖像進行預處理,降低圖像噪聲及數據缺失;其次,利用基于條件隨機場的分割方法對經過預處理的圖像進行自動分割,得到粗略的分割結果;最后,用戶通過交互平臺,將代表正確場景信息的標簽反應到條件隨機場模型中并進行模型更新,改善分割結果。通過多組實驗驗證了該算法不僅滿足用戶對于復雜場景分割與識別的需求,而且用戶交互簡單、方便、直觀。相較于傳統的基于條件隨機場分割方法,該方法得到較高的分割精度和較好的識別效果。
條件隨機場 語義分割 交互式 RGB-D圖像
0 引 言
隨著科技的發展,Kinect深度相機的出現解決了在激光掃描設備和深度相機系統中存在的實際困難,簡單、廉價、方便的特性使它成為計算機視覺領域的研究熱點。Kinect相機獲取的RGB-D圖像[1]既包含了被拍攝物體的RGB圖像,也包含了深度信息,因其豐富的數據特點使得其廣泛應用于圖像語義分析與理解的相關領域。
圖像語義分割[2]包含了傳統的圖像分割和目標識別兩個任務,其目的是將圖像分割成多個具有語義信息的塊,并識別出分割塊的類別,最終得到一幅含有語義標注的圖像。目前存在的語義分割方法一般是通過構建條件隨機場模型來完成圖像分割和識別兩個任務。條件隨機場模型[3]是一種基于無向圖的概率模型,用來對序列數據進行標記,具有很強的概率推理能力。其優勢在于充分考慮了圖像中不同物體之間的位置關系,能夠對物體類別有合理的推斷。但是現實場景復雜,純粹的依靠算法來完全自動實現分割和識別并不能滿足要求。因此,用戶干涉的圖像分割技術成為新的研究熱點。
目前廣泛應用的主要有基于圖割理論[4]、隨機游走[5]、圖匹配[6]等交互式分割方法。雖然它們理論依據不同,但是都具有相似的步驟思想。大體概括為:選取圖像中的某些區域進行標記,用標記的像素根據制定的規則進行訓練,得到相關分類模型后對其他像素進行標記,完成圖像語義分割。這些算法相較于自動分割方法雖然效果有所提高,但是依舊存在一些不足:對用戶輸入要求較高,用戶選擇的位置和數量都會影響分割結果,并且要不斷調整輸入,交互量較大;由于算法的限制,現有分割方法大多用于單一目標分割中,對于多目標分割問題,很難快速得到準確的結果。
針對以上問題,本文提出了一種交互式RGB-D圖像語義分割方法,巧妙地將手動操作融入到自動分割過程中,加入少量的人工交互操作,卻很好地改善了分割精度,這是以前自動方法所達不到的。
1 方 法
本文方法主要分為三個步驟:首先對Kinect相機獲得的RGB-D圖像進行預處理,去除噪聲并改善像素缺失狀況;其次,利用基于條件隨機場的圖像分割方法對經過預處理的圖像進行初始分割,得到大體的分割結果,這樣有利于減少后續的交互工作量;最后,用戶通過交互平臺,將反應場景正確信息的標簽傳遞到交互能量函數項中,并進行模型更新,得到改善后的分割結果。圖1為本文方法流程圖。

圖1 基于交互式條件隨機場的圖像分割流程圖
1.1 圖像預處理
從Kinect得到的深度圖含有大量的噪聲,手動拍攝時Kinect輕微晃動以及場景中的光線干擾,都會增加圖像噪聲。而且深度估計算法還產生大量的稍縱即逝的人為干擾,尤其是靠近邊緣的區域。所以在提取圖像特征并進行識別之前,必須進行圖像去噪。為此,使用中值濾波器[7]對圖像進行去噪。
深度圖像除了包含噪聲外,還會出現數據缺失的部分,這些區域從彩色相機是可見的,但沒有出現在深度圖像上。比如對黑色吸光物體或鏡面和低反射率表面,它們的深度沒能被估計,出現了深度圖上的孔。因此本文使用形態學重構方法[8]對其進行修補。
使用中值濾波去噪和形態學重構補洞后效果如圖2所示。

圖2 深度圖像預處理
1.2 圖像自動分割
圖像進行預處理之后,在進行交互式分割之前,先使用基于條件隨機場的方法進行自動分割,這樣可以減少后續的交互工作量。條件隨機場[3]是由Lafferty等提出的一個基于統計序列分割和標記的方法,是一個在給定輸入節點的前提下,計算輸出節點的條件概率的無向圖模型。
本文中條件隨機場能量函數E(y)測量了圖像中每個像素i對應的可能標簽yi的代價。yi可以取一組離散數據集{1,2,…,C},C代表類別數。能量函數由三項組成:(1)一元代價函數φ,依賴于像素位置i、局部描述符xi和學習的參數θ;(2)相鄰像素i和j的標簽勢函數ψ(yi,yj);(3)相鄰兩像素點i和j之間的空間連續性η(i,j),它的形式依不同的圖像而有所不同。能量函數定義如下:

(1)
1.2.1 一元勢函數
本文中一元勢函數φ是由局部幾何模型和位置先驗概率這兩部分組成:

(2)
1) 幾何模型
幾何模型P(yi|xi,θ)是用一系列D維的局部描述符xi訓練而成。幾何模型的訓練框架描述如下:
在給定從訓練圖片中提取出來的描述符集合:X={xi:i=1,2,…,N}情況下,我們用大小為H(1000)的單隱藏層和C維的最大軟間隔輸出層來訓練一個神經網絡,表示成P(yi|xi,θ)。它含有參數θ(大小為(D+1)×H和(H+1)×C的兩個權重矩陣),通過使用反向傳播和交叉熵損失函數學習而成。
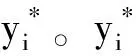
經過訓練后,神經網絡模型生成了P(yi|xi,θ)和描述符xi之間的映射。在使用條件隨機場模型之前,本文利用基于圖割的分割方法產生超像素{s1,s2,…,sk}[9],計算兩種不同的超像素點集合:僅用顏色圖像得到的SRGB和利用顏色與深度圖像共同生成的SRGBD。我們利用超像素來聚合一元勢函數產生的初步預測結果。然后,對于圖像的每個超像素sk,我們對所有落入該超像素的概率P(yi|xi,θ)求平均值,然后給在sk內的每個像素點賦予計算出的均值類概率。
2) 位置先驗概率
位置先驗概率P(yi,i)有兩種不同的形式,第一種獲得了目標的二維位置,類似于其他的語義分割方法。第二種是一種新穎的利用深度信息的三維位置先驗概率。



1.2.2 標簽勢函數
關于這一項我們選用相對簡單的Potts 模型[10]:
(3)
使用簡單的標簽轉換模型使得我們能夠清楚地看到相對于條件隨機場中的其他兩個勢函數、深度值的好處。在實驗中我們將d的值設為3。
1.2.3 空間轉換勢函數
空間轉換代價η(i,j)提供了一個機理來抑制或者鼓勵每個位置的標簽轉換(獨立于建議的標簽類)。我們用下面的勢函數形式表示:
η(i,j)=η0exp{-αmax(|I(i)-I(j)|-t,0)}
(4)
其中|I(i)-I(j)|表示在圖像中相鄰像素點i和j之間的梯度,t為一個閾值,而α和η0是尺度因子,η0=100。
1.3 交互式圖像分割
對圖像進行自動分割后,其分割結果并不是很好,因此,我們在上述模型中增加了交互能量函數項,將當前場景的正確信息反應到條件隨機場模型中并進行模型更新,改善分割結果。我們的交互項是通過交互平臺由用戶對自動分割結果中錯誤的部分簡單地畫幾筆實現的。模型更新能量函數如下所示:
(5)
這里E1(ci:xi)測量了像素i的在特征xi條件下標簽為ci的概率,E2(ci:cj)測量了兩個相連像素標簽的一致性。通過使用圖割方法[11]可以有效最小化模型更新能量函數。下面詳細描述我們能量函數各組成部分的含義和作用。
1.3.1 交互能量函數
能量函數E1(ci:xi)依據像素i的特征評價了它屬于某個物體標簽的概率。它由兩項組成,來自于深度相機的顏色和深度信息的局部外觀和幾何模型:
(6)

(7)
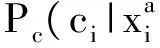
(8)
這里d(x,ci)是當前像素與對象類ci最近聚類中心的顏色值開方距離,ξ是一個比較小的數,為了避免分母為0,一般取10e-6。
(9)
? 高度hi:像素i在平面擬合面上的投影到地面的距離
? 尺寸si:覆蓋該像素的平面擬合面的尺寸
? 方向θi:平面擬合面法向量與地面法向量夾角
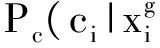
(10)
能量項E2(ci,cj)用來約束鄰域像素標簽的光滑性。我們用下式來計算該項:
E2(ci,cj)=δ[ci≠cj]sim(fi,fj)
(11)
這里,fi=[r,g,b,d]T為像素i的顏色值和深度值的串聯。兩個像素之間的相似性由式(12)計算:
(12)
其中σ是像素特征間的平均距離。
1.3.2 模型更新

2 系統實現及實驗結果
2.1 系統實現
本文系統采用C++開發,所使用的開發環境是微軟的VisualStudio2010,鏈接的庫包括:微軟基礎類(MFC),開放圖像庫(OpenGL),開放計算機視覺庫(OpenCV)等。
系統界面如圖3所示,其中菜單欄包括文件、視圖、運行、更新四項。左邊子窗口為標簽面板和參數設置面板,中間為圖像顯示區域,右邊為渲染的深度數據顯示區。其中文件項完成對文件的讀取和保存;視圖項調整界面顯示內容;運行項包括對用戶標簽、分割標簽、模型存儲等操作;更新項可以重新加載數據。

圖3 系統軟件界面
2.2 實驗結果
圖4展示了對我們拍攝的幾個場景中的部分圖像,使用交互式分割方法得到的結果,并與自動分割結果進行了對比。圖4(a)中的灰度條代表了不同類別的物體標簽;圖4(b)-(g)為六組圖像分割結果,每一組從左到右依次為RGB圖像(包含人工交互筆畫)、對應的深度圖像、自動分割結果、交互式分割結果。從圖中可以看出,使用自動分割方法雖然能達到大體分割結果,但對于一些物體還是出現了標簽錯誤的情況。比如自動分割時圖4(b)中椅子背部分被錯分為沙發,圖4(d)中桌子部分被錯分為柜子,沙發部分被錯分為桌子。
使用我們的交互式分割方法,增加少量的人工交互操作后,可以很大程度上改善分割效果,得到用戶要求的分割精度。與其他交互式分割方法相比,不需要用戶預先進行盲目的標記,大大減少了工作量,從圖中可以看出每組圖像的交互不超過6筆。而且我們不是簡單地進行前景和背景單一分割,而是實現了多目標分割,識別了圖像中多類物體。通過將自動分割結果及交互式分割結果與真實標簽圖像進行誤差計算,如表1所示,可以看出,交互式分割結果準確率明顯高于自動分割結果。

表1 自動分割與本文交互式分割準確率對比

圖4 自動與交互式圖像分割對比
除了對實驗結果準確率的分析,我們還對圖4中6組圖像分割過程中交互的次數及時間進行了記錄,見表2所示。運行該系統的計算機配置:Windows7 操作系統,至強3.2GHz處理器,16GB內存。從表2可以看出,每幅圖像第一次交互所需的筆畫數量最多,交互時間較長,隨后只需要較少的交互量就可以在短時間內達到用戶期望的分割結果,本文中所使用的實驗圖像最多只需要交互三次就能完成語義分割。
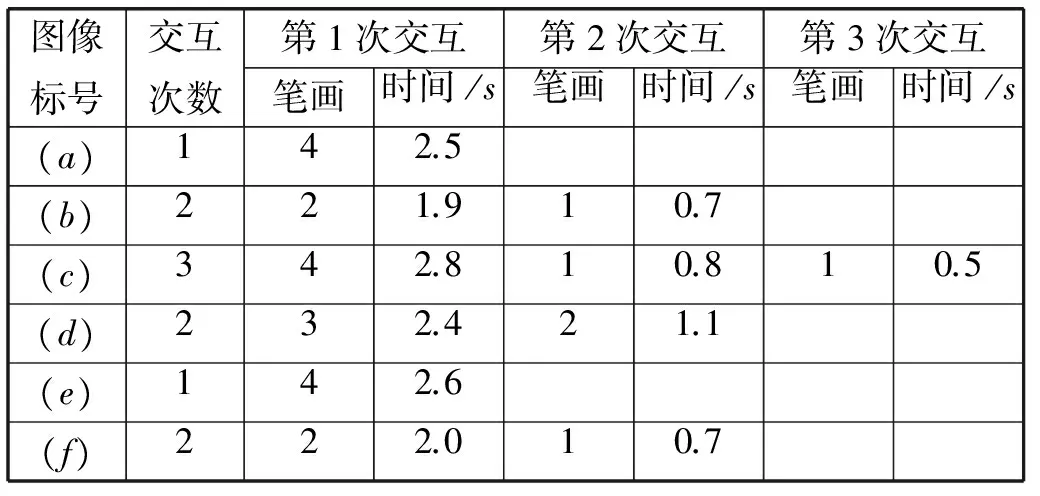
表2 本文交互式分割時間表
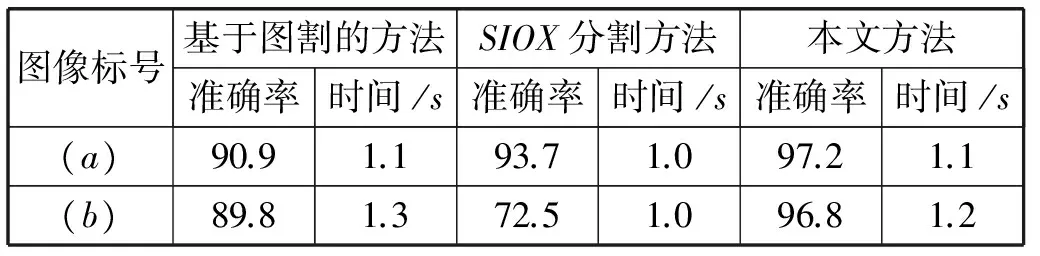
為了進一步驗證本文系統的性能,將我們的方法與基于圖割的交互式分割方法[14]及SIOX交互式分割方法[15]進行對比,分割結果見圖5所示。圖5(a)、(b)為兩組實驗圖像及結果,其中第一列為RGB圖像(包含人工交互筆畫),第二列為基于圖割的交互式分割結果,第三列為SIOX交互式分割結果,第四列為本文交互式分割結果。表3為圖5(a)、(b)兩組圖像的分割準確率及時間。從圖5及表3可以看出,相比于其他兩種方法,在近似相同的時間消耗情況下,我們的方法能夠得到更好的分割結果,從而達到用戶對圖像的分割需求。

圖5 不同交互式分割方法對比結果
圖像標號基于圖割的方法SIOX分割方法本文方法準確率時間/s準確率時間/s準確率時間/s(a)90.91.193.71.097.21.1(b)89.81.372.51.096.81.2
上述實驗是在假定人工交互給出的都是正確標簽的情況下進行的,所以外觀函數里的權重系數αp和幾何函數里的系數αg設定為較大的值,從而增加人工交互對分割結果的影響。但在實際操作中,難免會存在錯誤的人工交互,通過減小權重系數αp和αg,可以降低人工交互對系統分割結果的影響。當人為引入錯誤的信息后,系統依然保留原有的判斷,從而提高系統的魯棒性。圖6為兩組實驗結果,從圖6中可以看出,當αp和αg設以較大的值(αp=0.6,αg=0.7),人工錯誤地操作將桌子標記為椅子,結果系統誤將桌子顯示為椅子,由此可以看出人工交互對系統的影響較大。考慮到人為錯誤信息的引入,適當降低αp和αg的值(αp=0.4,αg=0.5),圖中可以看出,盡管人為將桌子錯誤標記為椅子,但是由于人工操作對系統影響降低,系統自身判斷占據較大比重,所以依舊將桌子判斷為桌子,從而提高了系統的魯棒性。

圖6 兩組引入人工錯誤信息后的實驗結果對比圖
盡管通過降低權重系數αp和αg的值,可以減輕人為錯誤信息引入后對系統系統性能的負面影響,但這是以削弱人工對系統的影響為代價。有時候系統本身判斷的確是錯誤的,人工就需要多次的操作才能糾正系統自身的判斷失誤,不免帶來系統效率上的降低。因此,為了保證系統擁有較高的使用效率的同時,對人為錯誤信息擁有一定的處理能力,選取合適的權重系數αp和αg的值需要根據用戶不同的需求來決定。
3 結 語
本文提出了一種交互式的圖像分割和標簽方法,提取RGB-D圖像的語義區域。當對圖像進行分割時,首先使用基于條件隨機場模型的方法對圖像進行初始分割,隨后通過少量人工交互,動態地調整辨別型模型來反映當前場景的信息,從而改善分割結果。依據我們的實踐,只需要簡單的畫幾筆就能很好地提高分割精度,這對于自動分割方法來說是很難達到的。而且,當前的分割信息自動地集成到我們學習的條件隨機場模型中,所以對于后續的圖像也能改善分割精度。雖然我們提出的交互式圖像分割方法能很好地提高分割精度,對用戶交互操作量也比較少,但是交互操作會影響分割速度,所以后續工作需要進一步優化能量函數,在提高精度的同時不增加計算時間。
[1]ShaoL,HanJ,KohliP,etal.ComputervisionandmachinelearningwithRGB-Dsensors[M].Switzerland:SpringerInternationalPublishing, 2014: 3-26.
[2]KohliP,LadickL,TorrPH.Robusthigherorderpotentialsforenforcinglabelconsistency[J].InternationalJournalofComputerVision, 2009, 82(3): 302-324.
[3]LaffertyJD,McCallumA,PereiraFCN.Conditionalrandomfields:probabilisticmodelsforsegmentingandlabelingsequencedata[C]//ProceedingsoftheEighteenthInternationalConferenceonMachineLearning,Williamstown,MA,USA.SanFrancisco,CA,USA:MorganKaufmannPublishers, 2001: 282-289.
[4]BoykovYY,JollyMP.InteractivegraphcutsforoptimalboundaryandregionsegmentationofobjectsinN-Dimages[C]//ProceedingoftheEighthIEEEInternationalConferenceonComputerVision,Vancouver,BC,Canada, 2001: 105-112.
[5]GradyL.Randomwalksforimagesegmentation[J].IEEETransactionsonPatternAnalysisandMachineIntelligence, 2006, 28(11): 1768-1783.
[6]NomaA,GracianoABV,JrRMC,etal.Interactiveimagesegmentationbymatchingattributedrelationalgraphs[J].PatternRecognition, 2012, 45(3): 1159-1179.
[7]HwangH,HaddadRA.Adaptivemedianfilters:newalgorithmandresults[J].IEEETransactionsonImageProcessing, 1995, 4(4): 499-502.
[8] 文華. 基于數學形態學的圖像處理算法的研究[D]. 哈爾濱:哈爾濱工程大學, 2007.
[9]BoykovY,Funka-LeaG.GraphcutsandefficientN-Dimagesegmentation[J].InternationalJournalofComputerVision, 2006, 70(2): 109-131.
[10]YuanJ,BaeE,TaiXC,etal.Acontinuousmax-flowapproachtoPottsmodel[C]//11thEuropeanConferenceonComputerVision,Heraklion,Crete,Greece.Springer, 2010: 379-392.
[11]BoykovY,VekslerO,ZabihR.Fastapproximateenergyminimizationviagraphcuts[J].IEEETransactionsonPatternAnalysisandMachineIntelligence, 2001, 23(11): 1222-1239.
[12]LiY,SunJ,TangCK,etal.Lazysnapping[J].ACMTransactionsonGraphics, 2004, 23(3): 303-308.
[13]ChumO,MatasJ.RandomizedRANSACwithT(d,d)test[C]//Proceedingsofthe13thBritishMachineVisionConference,Cardiff,UK, 2002: 448-457.
[14]RotherC,KolmogorovV,BlakeA. “GrabCut”:Interactiveforegroundextractionusingiteratedgraphcuts[J].ACMTransactionsonGraphics, 2004, 23(3): 309-314.
[15]FriedlandG,JantzK,RojasR.SIOX:simpleinteractiveobjectextractioninstillimages[C]//Proceedingsofthe2005IEEEInternationalSymposiumonMultimedia,Irvine,CA,USA, 2005: 253-260.
RGB-D IMAGE SEMANTIC SEGMENTATION METHOD BASED ONINTERACTIVE CONDITIONAL RANDOM FIELDS
Zuo Xiangmei Zhao Zhen Gou Tingting
(ChineseFlightTestEstablishment,Xi’an710089,Shaanxi,China)
RGB-D image semantic segmentation is the primary step of scene recognition and analysis, and the image segmentation method based on conditional random fields (CRF) cannot be applied in complex and volatile scenes, therefore an RGB-D image semantic segmentation method with interactive conditional random fields is proposed. Firstly, preprocess the depth and color images generated from Kinect with median filter and morphology reconstruction method, reducing the image noise and missing data. Secondly, automatically segment the preprocessed images with conditional random fields to obtain the rough segmentation. Finally, user takes the correct labels into the conditional random fields’ model to update the model through an interactive platform, which can improve the segmentation results. Compared with the traditional segmentation method based on conditional random fields, the proposed method can achieve better performance in scene understanding and analysis.
Conditional random fields Semantic segmentation Interactive RGB-D image
2015-07-09。左向梅,工程師,主研領域:模式識別與圖像處理。趙振,工程師。茍婷婷,碩士生。
TP391.41
A
10.3969/j.issn.1000-386x.2017.03.032
猜你喜歡
中學生數理化·七年級數學人教版(2020年11期)2020-12-14 06:59:52
開放教育研究(2020年2期)2020-03-31 01:54:14
藝術品鑒證.中國藝術金融(2018年8期)2019-01-14 01:14:28
藝術品鑒證.中國藝術金融(2018年10期)2019-01-08 02:44:26
藝術品鑒證.中國藝術金融(2018年12期)2018-08-26 06:03:48
現代語文(2016年21期)2016-05-25 13:13:44
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
大連民族大學學報(2015年2期)2015-02-27 08:28:11
