構建縣域早稻氮磷鉀施肥的系統聚類方法研究
2017-04-14 05:28:41李娟章明清孔慶波姚寶全劉德友
植物營養與肥料學報 2017年2期
李娟,章明清*,孔慶波,姚寶全,劉德友
(1 福建省農業科學院土壤肥料研究所,福州 350013;2 福建省農田建設與土壤肥料技術推廣總站,福州 350003;3 仙游縣土壤肥料技術推廣站,福建仙游 351200)
構建縣域早稻氮磷鉀施肥的系統聚類方法研究
李娟1,章明清1*,孔慶波1,姚寶全2,劉德友3
(1 福建省農業科學院土壤肥料研究所,福州 350013;2 福建省農田建設與土壤肥料技術推廣總站,福州 350003;3 仙游縣土壤肥料技術推廣站,福建仙游 351200)
【目的】為建立縣域早稻氮磷鉀施肥類別,探討多點肥效試驗資料的定量分類方法。【方法】以仙游縣26 個早稻“3414”設計的氮磷鉀肥試驗結果為例,探討不同系統聚類分析方法的適用性及其類別間差異顯著性。【結果】對生產條件和生產技術水平差異較小的縣域肥效試驗資料,以能使類別間距離空間擴展范圍較大的歐氏距離-離差平方和法為最佳系統聚類分析方法,可將 26 個試驗資料清晰地分成 3 類,分別對應于該縣的高產、中產和低產稻田類型;兩兩類別間的空白區產量和平衡施肥產量均達到差異顯著水平,且在 95% 置信區間下,稻谷產量水平在 3 個類別間幾乎不出現交叉重疊。在此基礎上,根據 3 種施肥類別對應的試驗點資料,分別建立三元二次多項式類特征肥料效應方程,進而得到這 3 個施肥類別的推薦施肥量。【結論】歐氏距離-離差平方和法系統聚類分析是縣域多點肥效試驗資料的一種有效定量分類方法,可將仙游縣早稻分為具有統計顯著性差異的 3 個氮磷鉀施肥類別。
早稻;施肥;聚類分析;類別
近 10 年來,我國各地在測土配方施肥工作中完成了眾多的作物氮磷鉀肥效試驗。然而這些多點分散試驗資料必須合理分類總結,才能為制定推薦施肥方案提供科學依據。迄今不少學者研究提出了許多肥料試驗資料的分類或聚類方法,諸如在早期提出的經驗聚類法、連續函數法、t 檢驗聚類法、協方差聚類法等[1]。在 20 世紀 80 年代前后,Colwell 等[2]提出了回歸系數平均法,王興仁等[3]提出分類回歸綜合法,毛達如等[1]提出動態聚類法,楊壽春等[4]提出按照無肥區產量水平劃分歸類等,吳良歡等[5]對水稻肥料效應的分類方法及其類內距離閾值的確定方法進行了探討。王興仁等[3]詳細闡述了多點肥效試驗資料進行分類匯總的理論基礎,毛達如等[1]提出了類特征肥效方程的概念,即根據在同一個土壤肥力等級或同一個施肥類別內的多點試驗資料,取各試驗處理產量平均值所建立的肥料效應方程。縱觀現有肥料效應分類或聚類方法,都是從多點肥料試驗結果中找出具有一定代表性的類肥料效應方程作為推薦施肥的依據。但是,有關不同聚類分析方法的有效性以及分類結果在類與類之間是否具有統計顯著性差異,在以往的研究中未引起足夠的重視。近年來,雖然系統聚類方法在土壤學中得到廣泛的應用[6-10],但卻鮮見在肥料效應方程領域的相關研究報道。
為此,本研究根據福建省仙游縣早稻的多點氮磷鉀肥效試驗資料,探討不同系統聚類方法對定量分類效果的影響,并進行類別間差異顯著性檢驗,旨在為多點田間試驗資料的歸納匯總和施肥決策提供科學依據。
1 材料與方法
1.1 試驗設計
以仙游縣 2007 年至 2009 年的早稻試驗資料為例。這些試驗均采用“3414”設計方案,共 14 個處理 , 即:1) N0P0K0;2) N0P2K2; 3) N1P2K2; 4) N2P0K2; 5) N2P1K2;6) N2P2K2;7) N2P3K2; 8) N2P2K0;9) N2P2K1;10) N2P2K3;11) N3P2K2;12) N1P1K2;13) N1P2K1;14) N2P1K1。其中,“2”水平的當地推薦施肥量為 N 165 kg/hm2、P2O550 kg/hm2和K2O116 kg/hm2,“0”水平表示不施肥,“1”水平的用量為“2”水平的 50%,“3”水平的用量為“2”水平的 150%。選擇當地具有代表性的土壤類型和肥力水平的稻田作為試驗地。
試驗采用多點分散不設重復和區組排列的試驗方法,小區面積 20 m2。供試品種選用當地大面積種植的良種。氮肥用尿素 (N 46%),磷肥用過磷酸鈣(P2O512%),鉀肥則用氯化鉀 (K2O 60%)。基肥中的氮、鉀肥占總用量的 50%,磷肥做基肥施用,余下的氮、鉀肥在水稻分蘗期施用。試驗區周圍設 1 m寬以上的保護行,其它的栽培管理措施與大田生產一致。試驗水稻收獲時,各小區單收單稱,分別記錄鮮重產量和曬干重,各試驗點的供試土壤類型和主要處理產量結果見表 1。
每個田間試驗實施前,按規范采集一個混合基礎土樣。用常規方法[11]測定土壤主要理化性狀,其中,pH 為電位法,有機質為重鉻酸鉀容量法,堿解氮為堿解擴散法,Olsen-P 為 0.5 mol/L 碳酸氫鈉提取—鉬銻抗比色,速效鉀為 1 mol/L 乙酸銨提取—火焰光度計測定。26 個供試土壤的 pH 為 5.4 ± 0.2,土壤有機質為 22.8 ± 5.1,土壤堿解氮、Olsen-P 和速效鉀含量分別為 143.1 ± 45.9、28.8 ± 23.8 和 37.8 ± 24.8 mg/kg。
1.2 系統聚類分析方法
目前,系統聚類分析的數學方法有很多種[12],本文 選 用 在 土 壤 學 中 有 代 表 性 的 幾 種 聚 類 方 法[13]。 其中,描述樣本間“距離”的數學表達式分別選用歐氏距離、街區距離和相似系數等 3 種方法。
歐氏距離的計算公式為:
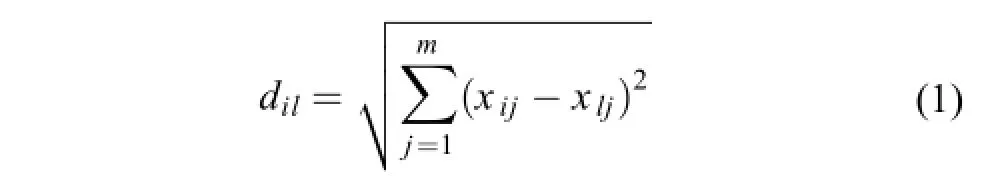
街區距離的計算公式為:

相似系數的計算公式為:


表1 早稻各試驗點供試土壤類型和主要處理產量Table 1 Soil types and the early rice yields in the main treatments of the experiment sites
式 (1)、(2) 和 (3) 中,i 和 l 是試驗點編號,i,l等于 1、2、3、…、n,n 為試驗點總個數。k 和 j 為各試驗點處理編號,k 和 j 等于 1、2、3、…、m,m為各試驗點處理數,m = 14。例如,xij和 xlj分別表示第 i、l 試驗點的第 j 處理產量。
聚類方法分別選用最短距離法、最長距離法和離差平方和法等 3 種方法。其中,離差平方和法的計算公式為:

式 中 , t 表 示 類 別 Gt,nt表 示 類 別 Gt的 試 驗 點 數 ,其它符號的意義與上述公式相同。xtij表示類別 Gt中第 i 個 試驗 點的 第 j 處理 產 量 ,表 示 類 別 Gt中 nt個試驗點的第 j 處理產量的算術平均值。
1.3 聚類分析結果的統計檢驗

在聚類分析中,類別之間差異顯著性檢驗常用 F檢驗,用于判斷兩兩類別間的差異是否顯著。F 值計算公式[14]為:式中,n1、n2分別表示類別 1 和類別 2 的試驗點數;Xˉ 表示類均值向量,即類內各試驗點相同處理產量平均值,每個類共有 14 個處理的產量平均值;S-1為兩類間的交叉乘積和矩陣的逆矩陣,具體計算方法可參考文獻[12]。
具體聚類分析過程和聚類譜系圖繪制采用MATLAB R2014a 軟件的統計分析工具箱完成。
2 結果與分析
2.1 不同聚類方法對分類結果的影響
圖 1 和圖 2 的聚類分析結果表明,不同聚類方法對 26 個早稻“3414”氮磷鉀肥效試驗的 14 個處理產量的分類效果有很大的差異。當采用歐氏距離時,最短距離法 (圖 1a) 的縱坐標并類距離空間最大只有 250 左右,聚類譜系圖甚至出現單方向的“樓梯”狀,以致無論采用何種不同的閾值,除其中的一個類別外,其余類別都只含 1 個或者少數幾個樣本,分類效果最差;最長距離法 (圖 1b) 的縱坐標并類距離空間擴張到 1000 左右,分類效果有明顯改善,但是,分成 3~5 類時,3 號試驗點被單獨分成一類,導致該類別因試驗點數太少而缺乏代表性;離差平方和法 (圖 1c) 的縱坐標并類距離空間進一步擴張到 1500左右,可將 26 個試驗點清晰地分成 3 類,而且每一類都包含若干個試驗點,具有最佳的聚類效果。采用街區距離法的分類效果與歐氏距離法大致相同。
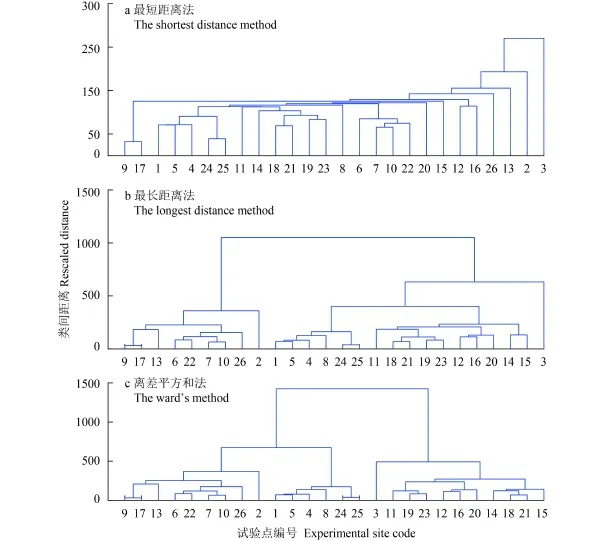
圖1 歐氏距離的聚類結果Fig. 1 Clustering results of the Euclidean distance
采用相似系數作為樣本間距離的表征時,最短距離法、最長距離法和離差平方和法,也會使樣本并類距離空間呈現擴展的趨勢,但都被限制在小于或等于 1,導致圖 2a 和圖 2b 的聚類譜系圖都出現“樓梯”狀,不能將 26 個試驗點清晰分類,但圖 2c 的離差平方和法聚類效果在聚類譜系圖上與圖 1c 相似。
因此,從聚類譜系圖看,對仙游縣 26 個早稻氮磷鉀肥效試驗結果而言,離差平方和法具有最好的分類效果。
2.2 肥效類別間差異顯著性檢驗
不同聚類分析方法得到的各類別所含試驗點序號結果見表 3。從圖 1c 和圖 2c 的聚類圖可以清楚看到,對 26 個試驗點的最佳分類數應為 3 類,但是,分成 3 類是否真的合理?還需要進行統計檢驗。
在數理統計中,為了使有關統計量能夠準確計算或得到有意義的結果,都要求樣本數必需大于觀測指標數。針對“3414”設計的肥效試驗,每個試驗點有 14 個處理,即每個樣本有 14 個產量指標。因此,要進行類別間 14 個產量均值的差異顯著性檢驗,每個類別必需要有 14 個以上試驗點。表 2 結果顯示,多數施肥類別均達不到此要求,因而不可能將每個試驗的 14 個處理都用來作為檢驗的產量觀測指標。事實上,在施肥實踐中,空白產量和平衡施肥產量才是最重要的施肥參考指標,故只需確保這 2 個產量指標在類別間有顯著差異,即可滿足指導施肥的需要。參考傅德印方法[16],將各試驗點的處理 1 空白區產量和處理 6 平衡施肥產量這兩個指標,作為類別間差異顯著性檢驗的依據,結果見表 3。
F 檢驗結果表明,用相似系數表征各試驗點間“距離”的聚類分析效果最差,歐氏距離和街區距離的聚類效果大體相當,與圖 1 和圖 2 的聚類譜系圖結果相一致。具體而言,歐氏距離和街區距離對應的最長距離法和離差平方和法組成的 4 種聚類方法具有較好的效果。在 3 個類別中,兩兩類別均值差異均達到極顯著水平,表明它們的分類結果都是有效的。但是,歐氏距離—最長距離法的類別 1 只含有一個試驗點,缺少代表性;與街區距離相比,歐氏距離具有明確的幾何意義。因此,針對仙游縣的縣域 26 個試驗資料而言,歐氏距離-離差平方和法是最佳系統聚類分析方法。

圖2 相似系數法聚類結果Fig. 2 Clustering results of the similarity coefficient method
2.3 早稻氮磷鉀肥效的類特征肥效方程
根據歐氏距離-離差平方和的系統聚類方法,對照 26 個試驗點在 3 個類別中的歸屬 (表 2),結果表明,該聚類方法綜合反映了縣域稻田的肥力狀況和生產力。其中,類別 1 (G1) 的 6 個試驗點中,灰沙田土屬占了 4 個,另外 2 個是黃泥田土屬,表明是以灰沙田為主的類特征肥效函數類別;該類農田大都位于河流兩岸或坡地與平地交界處,生產條件尚好,但漏水漏肥較嚴重,是當地的中產田;類別 2 (G2) 的 9 個試驗點中,黃泥田土屬占了 5 個,灰沙田和灰泥田土屬各占 3 個和 1 個,是以黃泥田土屬為主的類特征肥效函數組別;該類農田大都位于丘陵坡地上或遠離村鎮的耕地,土壤理化性狀和生產條件普遍較差,是當地的低產田。類別 3 (G3) 的 11個試驗點中,灰泥田土屬占了 8 個,黃泥田和灰沙田土屬各占 2 個和 1 個,表明該組是以灰泥田土屬為主的類特征肥效函數類別;該類土壤肥力較高,生產條件較好,是當地的高產田。
對處理 1 和處理 6 試驗產量的統計結果 (表 3)表明,由于縣域內生產條件和生產水平差異較小,類內產量變異很小。在高、中、低三個肥力等級類別中,空白區產量的變異系數分別只有 13.3%、4.3%和 14.1%,平衡施肥產量的變異系數則分別只有 6.2%、2.9% 和 6.7%。結果表明,在 95% 置信水平下,稻谷產量水平在 3 個類別間幾乎不出現交叉重疊,結果提高了早稻不同施肥類別在推薦施肥量上的唯一性和可靠性。為求得各施肥類別的推薦施肥量,分別對各類別的相應試驗結果計算各處理產量均值[1],建立三元二次多項式肥效模型 (表 3),表明 3 個類特征肥效方程均達到統計顯著水平,典型性判別[15]表明它們均屬于典型肥效函數。因此,根據表 3 的類特征肥料效應方程以及當地肥料和稻谷市場平均價格,用邊際產量導數法計算試驗區域內的最大施肥量和經濟施肥量及其預計產量 (表 4),結果為仙游縣不同產量水平的早稻合理施肥提供了定量施肥依據。

表2 不同聚類分析結果的試驗點歸屬和類間均值差異顯著性檢驗Table 2 Sample belongings of the clustering analysis and the mean value difference significance test between the classes

表3 仙游縣早稻氮磷鉀類特征肥效方程和空白區、平衡施肥處理產量Table 3 Response function of early rice to N, P and K fertilization and the yields in blank and balanced fertilization treatments in Xianyou County
3 討論與結論
3.1 區域氮磷鉀施肥類別的系統聚類方法
雖然數學家們對聚類分析方法做了許多研究和討論[12],但是目前還沒有一個公認和最佳的具體聚類方法。圖 1 和圖 2 可以看出,同樣 26 個試驗資料,用不同方法所得的聚類效果有很大的差別。凡是使縱坐標并類距離空間擴張范圍較大的系統聚類分析方法都有較清晰的分類效果,而使縱坐標并類距離空間壓縮的方法都會導致類別分辨力下降。
從數學上看,本研究選中的最短距離法、最長距離法和離差平方和法三種聚類方法,前者使樣本或類的空間距離被壓縮,后者使空間距離擴張,而離差平方和法則使樣本或類的空間距離進一步擴張。劉多森等[13]研究表明,使距離空間濃縮的方法會導致分類靈敏度降低,使距離空間擴張的方法會提高分類靈敏度,但靈敏度過高有時可能出現不合理的結果。因此,若被研究的樣本差異較大時,采用最短距離法可能會有較好的效果,反之分類效果就可能很差。本文研究的 26 個早稻氮磷鉀試驗資料都來自仙游縣,區域范圍較小,生產條件和生產水平差異不大,樣點間的“距離”較小。因此,采用最短距離法的分類效果不佳 (圖 1a 和圖 2a),而采用使樣點或類的距離空間較大程度擴張的離差平方和法,提高了分類靈敏度,能將 26 個試驗點清晰地分成3類 (圖 1c 和圖 2c)。

表4 仙游縣不同肥力等級或目標產量早稻推薦施肥量Table 4 Fertilization recommendation for early rice in different soil fertility and target yields in Xianyou County
因此,在解決實際問題時,應根據研究對象的特點和各種方法的數學性質,選擇最適宜的系統聚類方法,同時還需考慮這些方法的專業領域的適用性[13]。
3.2 分類有效性及其類均值差異顯著性檢驗
聚類分析的前提是不同類別之間存在顯著性差異。如果類與類之間沒有顯著水平的差別,分類則是無效的。在施肥實踐上,如果各類特征肥效方程之間沒有顯著差異,其指導施肥的針對性和準確性就難以保證。因此,對聚類分析得到的各個類別進行差異顯著性檢驗,是一個不可忽略的技術環節。
本文采用歐氏距離-離差平方和法,將 26 個早稻氮磷鉀肥效試驗資料的類特征肥效方程分成 3類。考慮到試驗數量只有 26 個,難以滿足樣點數必須大于產量觀測指標數的數理統計一般要求,不可能將各試驗點的 14 個處理產量全部納入統計檢驗。針對這種情況,傅德印[16]研究指出,可選擇對所研究問題密切相關而且具有較強分辨能力的變量作為檢驗的指標依據,具體可根據實際問題和經驗人為地挑選檢驗指標。為此,本研究選擇處理 1 空白區產量和處理 6 平衡施肥產量兩個產量指標,作為類別間差異顯著性的檢驗依據。表 3 的結果表明,G12、G13 和 G23 的 F 值分別為 16.7**、10.9**和 36.4**,均達到極顯著差異,說明分類是有效的。因此,在施肥實踐中,可根據空白區產量和平衡施肥產量兩個參數,來區分上述 3 個類特征肥效方程。
在諸多聚類分析方法中,系統聚類方法應用最為普遍[12]。它不需要像動態聚類方法那樣需要事先人為確定要分成多少類,而是根據系統聚類譜系圖和專業知識及實際應用需要,劃定某個閾值從而確定分類組別數量,這也是系統聚類方法的優點之一。然而,在應用中盲目套用系統聚類分析方法的情況很多,對不同聚類分析方法的適用性、聚類過程的合理性、聚類結果的有效性等問題分析和重視不夠,更談不上對聚類分析結果進行統計檢驗[16]。事實上,系統聚類方法是按照聚類步驟并類后得到一張聚類譜系圖,該圖只反映樣本 (或變量) 之間的親疏關系和程度,其本身并沒有給出分類。因此,在劃定分類數后,分類結果是否有效?應該進行相應的統計檢驗,并具體化為分組后的各類之間的均值向量的差異顯著性檢驗[13,16]。
3.3 類特征肥效方程的構建
根據歐氏距離-離差平方和的系統聚類分析方法,將仙游縣早稻氮磷鉀肥效的 26 個試驗點分成 3類。分析表明,這 3 類分別對應于該縣的高產、中產和低產稻田類型。根據王興仁等[3]和毛達如等[1]的建議,將同一個施肥類別內的各試驗點求取相同處理產量均值,建立三元二次多項式類特征肥效方程。典型性判別[15]表明,3 個類別的肥效方程均屬于典型式,而且 3 類的空白區產量和平衡施肥產量均值有顯著差異;在 95% 置信區間下,稻谷產量水平在 3 個類別間幾乎不出現交叉重疊,提高了指導早稻合理施肥的可靠性和結果的唯一性。
已有研究表明,當前作物肥效方程出現大量非典 型式[15,17-19]。 如果 完 全舍 棄這 些為數 眾多 的非 典 型肥效方程的試驗結果,不僅造成巨大浪費,而且會造成區域施肥量的估計偏畸[2]。當前,“3414”設計的肥效試驗大都采用多點分散不設重復的試驗方法,相當于一個隨機區組設計。田間肥料試驗表明,一個試驗點的肥料效應曲線可能出現多種形狀,但多點平均效應一般都是拋物線[20]。因此,利用多點試驗的相同處理產量均值建立類特征肥效方程的方法,不僅避免了試驗信息的偏畸,而且為經濟施肥量的計算提供了可能,從而使多點試驗資料真正起到施肥決策的依據。
[1]毛 達如, 張 承東. 多 點肥料效應函 數的動態聚 類方法[J]. 北 京農業大學學報, 1991, 17(2): 49-54. Mao D R, Zhang C D. Dynamic clustering method of multipoint fertilizer response function [J]. Journal of Beijing Agricultural University, 1991, 17(2): 49-54.
[2]Colwell J. D. The derivation of fertilizer recommendations for crop in non-uniform environment[J]. Fertilizer, Crop Quality and Economy.1974, 936-961.
[3]王興仁, 陳倫壽, 毛達如, 等. 分類回歸綜合法及其在區域施肥決策中的應用[J]. 土壤通報, 1989, 20(1): 17-21. Wang X R, Chen L S, Mao D R, et al. Classification regression synthesis method and its application for regional fertilization decision-making [J]. Chinese Journal of Soil Science, 1989, 20(1):17-21.
[4]楊守春, 陳倫壽, 劉光崧, 等. 黃淮海平原主要作物優化施肥與土壤培肥研究總論, 黃淮海平原主要作物優化施肥與土壤培肥技術[M]. 北京: 中國農業科學出版社, 1991. 1-26. Yang S C, Chen L S, Liu G S, et al. Summary of main crop optimized fertilization and soil fertility improvement in the Huang-Huai-Hai Plain: Technique of main crop optimized fertilization and soil fertility improvement in the Huang-Huai-Hai Plain [M]. Beijing:China Agricultural Science Press, 1991. 1-26.
[5]吳 良歡, 陶 勤南. 水稻 肥料多點試 驗聚類分析閾 值及其應用[J]. 中國水稻科學, 2000, 14(3): 144-148. Wu L H, Tao Q N. Threshold of cluster analysis for rice dispersed fertilizer experiments and its application [J]. Chinese Journal of Rice Science, 2000, 14(3): 144-148.
[6]陳 歡, 曹承富, 張存嶺, 等. 基于主成分-聚類分析評價長 期 施肥對砂姜黑土肥力的影響[J]. 土壤學報, 2014, 51(3): 609-617. Chen H, Cao C F, Zhang C L, et al. Principal component cluster analysis of effects of long-term fertilization on fertility of lime concretion black soil [J]. Acta Pedologica Sinica, 2014, 51(3):609-617.
[7]Jalali M. Multivariate statistical analysis of potassium status in agricultural soils in Hamadan, Western Iran [J]. Pedosphere, 2010, 20(3): 293-303.
[8]Jin X H, Yao Y H, Liu W L. Principal component analysis and cluster analysis of soil nutrients for planting Schisandrachinensis (Turcz) Baoll in Yanbian Area [J]. Medicinal Plant, 2011, 2(6): 1-4.
[9]Tagarakis A, Liakos V, Fountas S. Management zones delineation using fuzzy clustering techniques in grapevines [J]. Precision Agriculture, 2013, 14: 18-39.
[10]Chen F W, Liu W Y, Chang F J. Improvement of the agricultural effective rainfall for irrigating rice using the optimal clustering model of rainfall station network [J]. Paddy Water Environment, 2014, 12:393-406.
[11]魯如坤. 土壤農業化學分析方法[M]. 北京: 中國農業科技出版社, 2000. 146-196. Lu R K. Soil agricultural chemical analysis method [M]. Beijing:China Agricultural Science and Technology Press, 2000. 146-196.
[12]袁志發, 宋世德. 多元統計分析(第二版)[M]. 北京: 科學出版社, 2009. 278-293. Yuan Z F, Song S D, Multivariate statistical analysis (the second edition) [M]. Beijing: Science Press, 2009. 278-293.
[13]劉多森, 曾志遠. 土壤和環境研究中的數學方法和建模[M]. 北京:農業出版社, 1987. 134-165. Liu D S, Zeng Z Y. Mathematical method and modeling of soil and environment [M]. Beijing: Agriculture Press, 1987. 134-165.
[14]陳彥光. 基于 MATLAB 的地理數據分析[M]. 北京: 高等教育出版社, 2012. 159-180. Chen Y G. Geographic data analysis based on the MATLAB [M]. Beijing: Higher Education Press, 2012. 159-180.
[15]章明清, 林代炎, 林仁塤, 姜永. 極值判別分析在三元肥效模型推薦施肥中的作用[J]. 福建農業學報, 1995, 10(2): 54-59. Zhang M Q, Lin D Y, Lin R X, Jiang Y. Function of distinguish analysis on extreme value in recommendatory fertilization for threefertilizer efficiency model[J]. Fujian Journal of Agricultural Sciences, 1995, 10(2): 54-59.
[16]傅德印. Q型系統聚類分析中的統計檢驗問題[J]. 統計與信息論壇, 2007, 22(3): 10-14. Fu D Y. Statistical test problem at Q-mode hierarchical cluster analysis [J]. Statistics & Information Forum, 2007, 22(3): 10-14.
[17]王興仁. 二元二次肥料效應曲線等產線圖在科學施肥中的位置(一)[J]. 土壤通報, 1985, 16(1): 30-34. Wang X R. The position of yield contour chart of binary quadratic curve of fertilizer response such as production position in scientific fertilization (1) [J]. Chinese Journal of Soil Science, 1985, 16(1):30-34.
[18]王興仁. 二元二次肥料效應曲線等產線圖在科學施肥中的位置(二)[J].土壤通報, 1985, 16(2): 86-88. Wang X R. The position of yield contour chart of binary quadratic curve of fertilizer response such as production position in scientific fertilization (2) [J]. Chinese Journal of Soil Science, 1985, 16(2):86-88.
[19]章明清, 徐志平, 姚寶全, 等. Monte Carlo 法在多元肥效模型參數估計和推薦施肥中的應用[J]. 植物營養與肥料學報, 2009, 15(2):366-373. Zhang M Q, Xu Z P, Yao B Q, et al. Using Monte Carlo method for parameter estimation and fertilization recommendation of multivariate fertilizer response model [J]. Plant Nutrition and Fertilizer Science, 2009, 15(2): 366-373.
[20]李娟, 章明清, 姚寶全, 等. 福建單季稻氮磷鉀推薦施肥量研究[J].福建農業學報, 2015, 30(10): 933-938. Li J, Zhang M Q, Yao B Q, et al. Recommended N, P and K fertilization for single-cropping rice in fujian [J]. Fujian Journal of Agricultural Sciences, 2015, 30(10): 933-938.
Building fertilization categories of N, P and K fertilization for early rice using systematic clustering method in county territory
LI Juan1, ZHANG Ming-qing1*, KONG Qing-bo1, YAO Bao-quan2, LIU De-you3
( 1 Soil and Fertilizer Institute, Fujian Academy of Agricultural Sciences, Fuzhou 350013, China; 2 Fujian Cropland Construction and Soil and Fertilizer Station, Fuzhou 350003, China; 3 Soil and Fertilizer Technology Extension Station, Xianyou County, Xianyou, Fujian 351200, China )
【Objectives】Quantitative classification methods of multi-point experimental data of fertilizer responses were studied to build fertilization categories of N, P and K fertilizers of early rice in county territory.【Methods】Based on results of the 26 field experiments of “3414”early rice response to N, P and K fertilization in Xianyou County, Fujian Province, China, applicability of different system clustering analysis methods and their significant differences were explored.【Results】Based on the county experimental data of fertilizer response to production conditions and the little differences of production technology, and the best system clustering analysis method by Euclidean distance-Ward’s method for larger spatial extension between the categories, the 26 experimental datasets were clearly divided into three categories, which were corresponding to the high yield paddy, middle yield paddy and low yield paddy respectively in the county. There were significant differences between blank area yields and the yields of the balanced fertilization between two categories, and rice yields hardly overlapped among the three categories with the 95% confidence interval. Based on the three fertilization categories corresponding to the experimental data, class feature fertilization response function of quadratic polynomial was developed respectively, and then recommendation rates of fertilizers of the three fertilization categories were gained.【Conclusions】System clustering analysisby Euclidean distance-Ward’s method is effective quantitative classification method for the county multi-point fertilization response data, and early rice can be divided into three fertilization categories of N, P and K fertilizers with statistically significant differences in Xianyou county.
early rice; fertilization; clustering analysis; category
2016-03-28 接受日期:2016-07-12
國家自然科學基金項目(31572203); 福建省公益科研專項(2014R1022-5); 福建省農業科學院 PI 項目(2016PI-31)資助。
李娟(1977—),女,福建建陽人,碩士,副研究員,主要從事平衡施肥和施肥與環境研究。
Tel:059-187572840,E-mail:lj-95@163.com。* 通信作者 E-mail:zhangmq2001@163.com
猜你喜歡
礦山安全信息(2022年40期)2022-04-07 02:16:52
當代水產(2021年10期)2021-12-05 16:31:48
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
今日農業(2020年20期)2020-11-26 06:09:10
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
聚氯乙烯(2018年9期)2018-02-18 01:11:34
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
