基于多標簽學習的卷積神經網絡的圖像標注方法
2017-04-17 05:18:48高耀東侯凌燕楊大利
計算機應用 2017年1期
高耀東,侯凌燕,楊大利
(北京信息科技大學 計算機學院,北京 100101)
(*通信作者電子郵箱bistu2015@gmail.com)
基于多標簽學習的卷積神經網絡的圖像標注方法
高耀東*,侯凌燕,楊大利
(北京信息科技大學 計算機學院,北京 100101)
(*通信作者電子郵箱bistu2015@gmail.com)
針對圖像自動標注中因人工選擇特征而導致信息缺失的缺點,提出使用卷積神經網絡對樣本進行自主特征學習。為了適應圖像自動標注的多標簽學習的特點以及提高對低頻詞匯的召回率,首先改進卷積神經網絡的損失函數,構建一個多標簽學習的卷積神經網絡(CNN-MLL)模型,然后利用圖像標注詞間的相關性對網絡模型輸出結果進行改善。通過在IAPR TC-12標準圖像標注數據集上對比了其他傳統方法,實驗得出,基于采用均方誤差函數的卷積神經網絡(CNN-MSE)的方法較支持向量機(SVM)方法在平均召回率上提升了12.9%,較反向傳播神經網絡(BPNN)方法在平均準確率上提升了37.9%;基于標注結果改善的CNN-MLL方法較普通卷積神經網絡的平均準確率和平均召回率分別提升了23%和20%。實驗結果表明基于標注結果改善的CNN-MLL方法能有效地避免因人工選擇特征造成的信息缺失同時增加了對低頻詞匯的召回率。
圖像自動標注;多標簽學習;卷積神經網絡;損失函數
0 引言
隨著互聯網技術的發展以及個人手持設備的普及,互聯網上的圖像、視頻數據正呈指數增長。互聯網公司一方面希望能夠方便有效地管理互聯網上的海量圖像數據;另一方面希望適應用戶的搜索習慣,即基于文本的圖像搜索(Text-Based Image Retrieval, TBIR)方式。互聯網公司為每張圖像添加相應的標簽信息,即圖像標注。目前采用的比較成熟的方法是提取圖片所在網頁的上下文信息作為標簽信息[1],但是存在噪聲多、沒有上下文文本信息等諸多問題。與此同時,在城市安全中,對監控視頻的場景的標注也得到越來越多的關注,進而有專家學者提出根據圖像本身的視覺信息進行圖像自動標注的方法。
目前圖像自動標注的方法主要分為兩大類:一是基于統計分類的圖像標注方法;二是基于概率模型的圖像標注方法。基于分類的標注方法是將圖像的每一個標注詞看成一個分類,這樣圖像標注問題就可以看作是圖像的分類問題,但是由于每張圖片包含多個不同的標注詞,因而圖像標注問題又屬于一個多標簽學習(Multi-label Learning)問題。主要的方法有基于支持向量機(Support Vector Machine, SVM)的方法[2-5]、K最近鄰(K-Nearest Neighbor,KNN)分類方法[6-7]、基于決策樹的方法[8-9]、基于BP神經網絡(Back Propagation Neural Network, BPNN)[10]以及深度學習的方法[11-12]等。基于概率的方法主要是通過提取圖像(或者圖像區域)的視覺信息(如顏色、形狀、紋理、空間關系等),然后計算圖像的視覺特征與圖像標注詞之間的聯合概率分布,最后利用該概率分布對未標注圖像(圖像區域)進行標注。主要的方法有Duygulu等[13]和Ballan等[14]提出的機器翻譯模型以及主題相關模型[15-17]等。
傳統的方法在圖像標注領域取得了一定的進展,但是因為需要人工選擇特征,從而造成信息缺失,導致標注精度不夠,召回率低;而深度學習模型雖然在圖像識別分類領域取得了比較高的成就,但是大部分都是針對網絡本身或者是針對單標簽學習的改進,而針對屬于多標簽學習的圖像標注的應用和改進較少。因此本文根據多標簽學習的特點,同時考慮到標注詞的分布不均問題,提出基于標注結果改善的多標簽學習卷積神經網絡模型方法。首先,修改了卷積神經網絡的誤差函數;然后,構建一個適合圖像自動標注的多標簽學習卷積神經網絡;最后,利用標注詞的共生關系對標注結果進行改善。
1 卷積神經網絡
卷積神經網絡(Convolutional Neural Network, CNN)是Fukushima等[18]基于感受野概念提出的神經認知機,并由Le Cun等[19]在MNIST(Mixed National Institute of Standards and Technology database)手寫數字數據集上取得突破性進展。卷積神經網絡采用的局部連接、下采樣以及權值共享,一方面能夠保留圖像的邊緣模式信息和空間位置信息,另一方面降低了網絡的復雜性。另外卷積神經網絡可以通過網絡訓練出圖像特征,很大程度上解決了傳統方法中因為人工選擇特征導致信息丟失的問題。之后大量科研人員通過調整網絡模型結構、修改激活函數、改變池化方法、增加多尺度處理、Dropout方法、mini-batch正則化方法等[20-24]一系列措施使得卷積神經網絡的效果更加顯著,例如2015年微軟亞洲院在ILSVRC(ImageNet Large Scale Visual Recognition Challenge database)圖像數據集上的分類錯誤率首次達到了比人眼識別效果還要低[25]。因此本文嘗試利用卷積神經網絡在圖像特征自學習方面的優勢,對圖像進行自動標注。
1.1 卷積層與池化層
一個典型的卷積神經網絡,通常是由輸入層、多個交替出現的卷積層和池化層(Pooling)、全連接層以及輸出層構成。卷積層是卷積神經網絡進行特征抽取的關鍵部分,每個卷積層可以使用多個不同的卷積核(Kernel),從而得到多個不同的特征圖(Feature map)。卷積層的輸出如式(1):

(1)
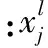
由于在卷積操作過程中存在重復卷積的元素,因此為了減少冗余信息以及快速減低特征維數,在卷積操作之后進行一次池化操作,常用的操作有最大池化、均值池化以及金字塔池化[20]等。經過一次池化操作,特征圖維度會減低到原來1/n,n代表池化規模,如圖1所示。
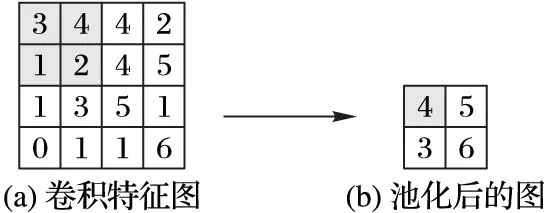
圖1 規模為2×2的最大池化示意圖
可以看出,在每一個2×2的池化窗口中選擇一個最大的值輸出,再經過激活函數(圖1中省略了激活函數),得到一個池化層的特征圖。
1.2 基于多標簽學習的損失函數
在監督學習問題中通過損失函數(lossfunction)來度量輸出的預測值與真實值之間的錯誤的程度,并且通過求解最小化損失函數,來調整權值。卷積神經網絡同樣是一種監督學習,通常情況下使用均方誤差(MeanSquaredError,MSE)函數作為損失函數,如式(2)~(3):
(2)
(3)
其中:E(i)是單個樣本的訓練誤差;d(i)是對應輸入x(i)的期望輸出;y(i)是對應輸入x(i)的網絡預測輸出;m為樣本數量。
但是包括該損失函數在內的大多數的損失函數只是等價地考慮某個標簽是否屬于某一個樣本x,而沒有區別對待屬于樣本x的標簽和不屬于樣本x的標簽。因此,為了讓卷積神經網絡能更好地適用于圖像自動標注,本文將文獻[10]提出的一種排序損失的損失函數(式(4))應用到卷積神經網絡:
(4)
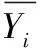
然而在圖像標注問題中,由于一個圖片樣本往往對應多個標注詞,而有些標注詞會出現在各種不同的場景中,而有些標注詞只會在特定的場合才會出現,從而造成各標注詞分布是不均勻的。例如:藍天、樹木等詞出現的頻率要遠遠高于其他標注詞,而像蜥蜴、老虎等詞出現的頻率則少于其他標注詞。因此為了提高對低頻詞匯的召回率,本文對式(4)進行了修改:
(5)
其中αk是一個與詞頻有關的系數:
(6)
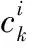
2 基于標注詞共生矩陣的標注改善
在圖像標注中,同一張圖片包含著多個事物(標注詞),反之就是說出現在同一張圖片中的標注詞它們之間是存在某種相關性的,比如說,太陽和藍天、沙灘和大海等。同樣這些標注詞之間的相關性有強有弱,本文對所有的樣本的標注信息進行統計,得到一個標注詞的共生矩陣R:
Rij=S(i,j)/S(i)
(7)
其中:S(i,j)代表標注詞i和標注詞j同時出現的次數,S(i)表示標注詞i出現的次數。通過式(7)可以看出得到的共生矩陣不是一個對稱的矩陣,也就是說標注詞i與標注詞j之前存在某種聯系,但是可能標注詞i對標注詞j的依賴性更大。例如,有太陽則必然有天空,而出現天空不一定會有太陽的出現。因此本文結合標注詞的相關性對網絡預測出的結果進行相關性的調整。對卷積神經網絡輸出的結果C,通過式(8),得到最終的模型標注結果O:
O=R*C
(8)
3 本文的卷積神經網絡模型結構
本文采用如圖2所示的一種卷積神經網絡結構,輸入層是一張完整的圖像,分別是R、G、B三個通道;然后通過4個卷積層,卷積核大小分別為11,9,7,5,卷積核個數分別為20,40,60,80;4個采用最大池采樣的池化層,池化大小分別為3,3,3,2;最后是兩個全連接層,并且為了防止過擬合使用Dropout,概率設置為0.6;輸出層節點是224個節點。所有的激活函數均采用的是ReLU激活函數,學習率初始化為0.01。
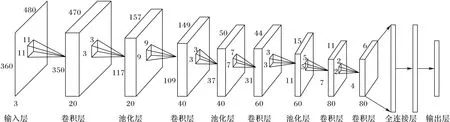
圖2 本文使用的卷積神經網絡結構
4 實驗與結果分析
本文采用的是由imageCLEF組織提供的公開圖像標注數據集IAPRTC-12,包含18 000張圖片,圖片大小為480×360,其中訓練集包含14 000張圖片,測試集為4 000張圖片,包含276個標注詞,但是由于某些標注詞沒有在測試集或者是訓練集中出現,所以本文實際用到的標注詞是224個,平均每個圖片包含4.1個標簽。同時該數據集中各標注詞分布不均勻,最少的標注詞訓練樣本量只有1個,最大的標注詞訓練樣本量有3 834個。
本文首先驗證卷積神經網絡在特征學習方面要優于傳統的人工選擇特征,使用SVM、BPNN以及采用MSE誤差函數的CNN(ConvolutionalNeuralNetworkusingMeanSquareErrorfunction,CNN-MSE)進行對比實驗;然后測試基于多標簽學習的卷積網絡的方法(Multi-LabelLearningConvolutionNeuralNetwork,CNN-MLL)以及基于標注詞共生關系的標注結果改善的方法(下文簡稱改善的CNN-MLL)有效性與近幾年在該數據集上取得效果較好的算法(SparseKernelwithContinuousRelevanceModel(SKL-CRM)[14]、DiscreteMultipleBernoulliRelevanceModelwithSupportVectorMachine(SVM-DMBRM)[4]、KernelCanonicalCorrelationAnalysisandtwo-stepvariantoftheclassicalK-NearestNeighbor(KCCA-2PKNN)[6]、NeighborhoodSetbasedonImageDistanceMetricLearning(NSIDML)[7]等)進行對比。
4.1 評價指標
本文采用的是平均準確率P、平均召回率R以及F1,作為實驗結果的評價標準,計算式如下:
F1=2PR/(P+R)
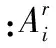
4.2 實驗結果
由于BP神經網絡以及SVM需要人工提取圖像特征進行訓練和測試,所以本文參考其他文獻[5,8,17]中常用的圖像特征提取方法,分別提取了圖像的Gist特征(特征向量維度為500)、SIFT(Scale-InvariantFeatureTransform)特征(特征向量維度為3 250)、小波紋理特征(向量維度為500)以及顏色直方圖(特征向量維度250),并全部經由詞包形式轉換,組合共5 000維特征,并對數據進行歸一化處理。
其中SVM采用的核函數是徑向基核函數,該核函數在本數據集中表現最好,懲罰系數為0.3;BP神經網絡采用的4層的網絡結構輸入層5 000個節點,兩個隱藏層節點數分別為3 000,1 000。
因為樣本的平均標注詞的個數是4.1,向上取整,所以本文選擇5個概率輸出值最高的標注詞作為每個測試樣本的標注結果,然后計算平均準確率和平均召回率。本實驗平臺處理器采用的是酷睿I5,代碼是基于Theano庫開發的,基于CNN-MLL方法的網絡訓練時間與CNN-MSE方法的訓練時間相差不大,兩種方法的訓練時間都在一天左右。各方法實驗結果如表1。
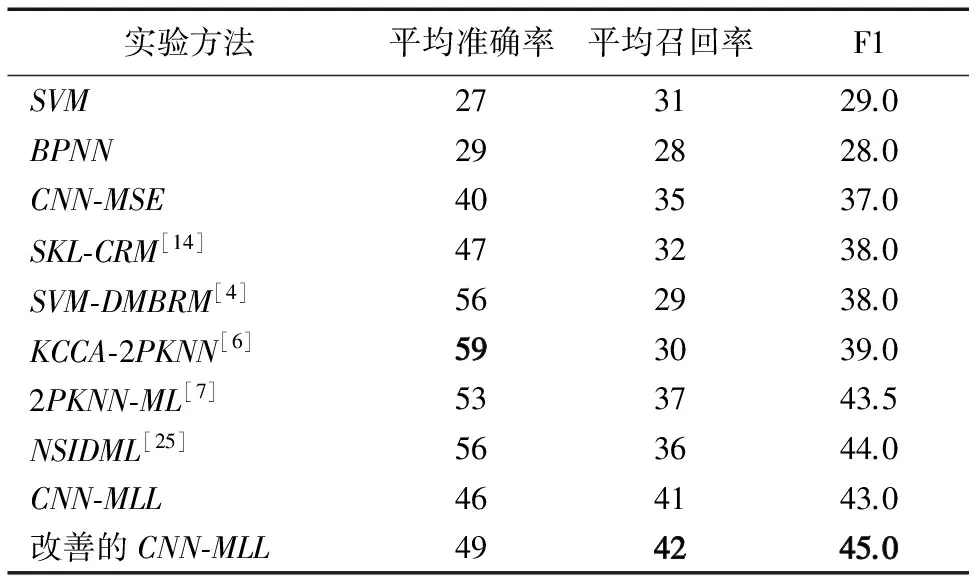
表1 各圖像標注方法實驗結果 %
表1中有參考文獻的算法的各項數據來源于其文獻。通過表1,可以看出基于CNN-MSE的標注方法在平均準確率和平均召回率上都有很大的提高,平均準確率較BPNN提高了37.9%,平均召回率較SVM提高了12.9%。表明在大數據量的圖像數據集中卷積神經網絡在特征學習方面要比傳統的手工選擇特征要好很多,區分度更大。同時通過CNN-MSE和CNN-MLL的實驗結果可以看出,采用改進的多標簽排序策略的損失函數要比常用的均方誤差函數要好,在平均準確率和平均召回率上分別提升15.0%和17.1%。而最后采用標注詞間的共生關系對網絡標注進行改善,使得平均準確率和平均召回率再次提升6.5%和2.5%。從整體改進上來看本文的方法較普通卷積神經網絡平均準確率和平均召回率分別提升了22.5%和20.0%,改進效果明顯。另外本文方法在平均準確率上雖然低于其他方法,但是在平均召回率上有很大提升,較2PKNN-ML方法提高了13.5%,同時F1的值也是最高的。
另外為了驗證本文對式(3)的改進的有效性,本文對比了式(3)的誤差函數跟式(4)的誤差函數對低頻詞匯的召回率情況,這里分別統計了樣本量在150以下的標簽的平均準確率、平均召回率以及總的平均準確率,結果如表2。
表2 兩種多標簽學習誤差函數實驗結果 %
Tab.2 Experimental results of two kinds of multi-label learning error function %

使用的誤差公式樣本量低于150準確率召回率總體準確率召回率式(4)34294641式(3)29214338
由表2可知經過改進的誤差函數(式(4))對低頻詞匯的標注準確率和召回率均遠高于沒有改進的誤差函數(式(3)),而總體的平均準確率以及平均召回率也稍高于沒有改進的誤差函數。因此改進方法有效。
本文考慮到樣本的不平衡性,這里給出了基于標注結果改善的CNN-MLL方法得到的每個標注詞的準確率和召回率曲線,如圖3所示。

圖3 數據集中每個標簽的準確率、召回率和F1的值
圖3中的標簽序號是根據標簽對應的訓練樣本的數量從小到大排序得到的順序號。當訓練樣本數量只有1~10時(1~17號標簽),曲線的值都是0,主要是這里的訓練樣本數量占比太少,在訓練的時候基本被忽略了;樣本數量在100~300時(101~181號標簽),曲線的值基本要高于其他部分的值,平均能達到60%以上,這部分樣本數量分布比較均勻,測試樣本數量也基本維持在50左右,同時這部分詞匯大都是一些具體的事物,特征比較明顯。但是也有例外的像110號、135號、153號等標簽分別是generic-objects、construction-other以及mammal-other等,這些標簽雖然也是具體事物但是包含的東西較廣泛,而且與其他標注詞偶有類似,因此導致識別度也較低。而在181號標簽往后,曲線的值開始下降但是較穩定,主要是這部分標注詞對應的訓練樣本的數據量較大,且各樣本的數量差距較大(在300~3 000),同樣的這些標注詞對應的測試樣本的數據量也較大且不均勻;同時這些詞匯都是一些高頻詞匯像藍天、樹木、人群以及一些抽象的詞匯等,雖然訓練樣本多,但是同一標注詞在不同樣本中彼此視覺差異性較大,因此誤判的較多。另外通過圖3還可以看出在142號標簽之后召回率開始比準確率的值要高。
通過上述分析,不難看出標注圖像樣本庫的人工標注精度、樣本差異性大小以及樣本數量分布均衡性等,對標注實驗影響很大。
5 結語
本文提出的基于多標簽學習的卷積神經網絡以及結合標注詞共生關系對標注結果進行改善的模型,在IAPR TC-12大規模圖像自動標注數據集的實驗中,本文方法較SVM以及BPNN方法標注的準確率和召回率均有明顯提高,相比與目前標注效果較好算法在準確率有所下降,但是在召回率上有一定的提升。綜合準確率和召回率來看,本文方法在標注性能上有所提升,證明本文方法是有效的。
進一步的工作擬在以下兩方面進行:1)針對卷積神經網絡的結構作優化調整;2)嘗試在全連接層添加人工特征,補充特征信息以提高標注的準確率。
References)
[1] 許紅濤,周向東,向宇,等.一種自適應的Web圖像語義自動標注方法[J].軟件學報,2010,21(9):2183-2195.(XU H T, ZHOU X D, XIANG Y, et al.Adaptive model for Web image semantic automatic annotation [J].Journal of Software, 2010, 21(9): 2186-2195.)
[2] YANG C B, DONG M, HUA J.Region-based image annotation using asymmetrical support vector machine-based multiple instance learning [C]// Proceedings of the 2006 IEEE Computer Society Conference on Computer Vision and Pattern Recognition.Washington, DC: IEEE Computer Society, 2006: 2057-2063.
[3] GAO Y, FAN J, XUE X, et al.Automatic image annotation by incorporating feature hierarchy and boosting to scale up SVM classifiers [C]// Proceedings of the 2006 ACM International Conference on Multimedia.New York: ACM, 2006: 901-910.
[4] MURTHY V N, CAN E F, MANMATHA R.A hybrid model for automatic image annotation [C]// Proceedings of the 2014 ACM International Conference on Multimedia Retrieval.New York: ACM, 2014: 369.
[5] 吳偉,聶建云,高光來.一種基于改進的支持向量機多分類器圖像標注方法[J].計算機工程與科學,2015,37(7):1338-1343.(WU W, NIE J Y, GAO G L.Improved SVM multiple classifiers for image annotation [J].Computer Engineering & Science, 2015, 37(7): 1338-1343.)
[6] MORAN S, LAVRENKO V.Sparse kernel learning for image annotation [C]// Proceedings of the 2014 International Conference on Multimedia Retrieval.New York: ACM, 2014: 113.
[7] VERMA Y, JAWAHAR C V.Image annotation using metric learning in semantic neighbourhoods [M]// ECCV’12: Proceedings of the 12th European Conference on Computer Vision.Berlin: Springer, 2012: 836-849.
[8] HOU J, CHEN Z, QIN X, et al.Automatic image search based on improved feature descriptors and decision tree [J].Integrated Computer Aided Engineering, 2011, 18(2): 167-180.
[9] 蔣黎星,侯進.基于集成分類算法的自動圖像標注[J].自動化學報,2012,38(8):1257-1262.(JIANG L X, HOU J.Image annotation using the ensemble learning [J].Acta Automatica Sinica, 2012, 38(8): 1257-1262.)
[10] ZHANG M L, ZHOU Z H.Multilabel neural networks with applications to functional genomics and text categorization [J].IEEE Transactions on Knowledge & Data Engineering, 2006, 18(10): 1338-1351.
[11] READ J, PEREZCRUZ F.Deep learning for multi-label classification [J].Machine Learning, 2014, 85(3): 333-359.
[12] WU F, WANG Z H, ZHANG Z F, et al.Weakly semi-supervised deep learning for multi-label image annotation [J].IEEE Transactions on Big Data, 2015, 1(3): 109-122.
[13] DUYGULU P, BARNARD K, DE FREITAS J F G, et al.Object recognition as machine translation: learning a lexicon for a fixed image vocabulary [C]// ECCV 2002: Proceedings of the 7th European Conference on Computer Vision.Berlin: Springer, 2002: 97-112.
[14] BALLAN L, URICCHIO T, SEIDENARI L, et al.A cross-media model for automatic image annotation [C]// Proceedings of the 2014 International Conference on Multimedia Retrieval.New York: ACM, 2014: 73.
[15] WANG C, BLEI D, LI F F.Simultaneous image classification and annotation [C]// Proceedings of the 2009 IEEE Computer Society Conference on Computer Vision and Pattern Recognition.Washington, DC: IEEE Computer Society, 2009: 1903-1910.
[16] 李志欣,施智平,李志清,等.融合語義主題的圖像自動標注[J].軟件學報,2011,22(4):801-812.(LI Z X, SHI Z P, LI Z Q, et al.Automatic image annotation by fusing semantic topics[J].Journal of Software, 2011, 22(4): 801-812.)
[17] 劉凱,張立民,孫永威,等.利用深度玻爾茲曼機與典型相關分析的自動圖像標注算法[J].西安交通大學學報,2015,49(6):33-38.(LIU K, ZHANG L M, SUN Y W, et al.An automatic image algorithm using deep Boltzmann machine and canonical correlation analysis [J].Journal of Xi’an Jiaotong University, 2015, 49(6): 33-38.)
[18] FUKUSHIMA K, MIYAKE S.Neocognitron: a new algorithm for pattern recognition tolerant of deformations and shifts in position [J].Pattern Recognition, 1982, 15(6): 455-469.
[19] LE CUN Y, BOSER B, DENKER J S, et al.Handwritten digit recognition with a back-propagation network [M]// Advances in Neural Information Processing Systems.San Francisco, CA: Morgan Kaufmann Publishers, 1990: 396-404.
[20] KRIZHEVSKY A, SUTSKEVER I, HINTON G E.ImageNet classification with deep convolutional neural networks [EB/OL].[2016-04-10].https://papers.nips.cc/paper/4824-imagenet-classification-with-deep-convolutional-neural-networks.pdf.
[21] HE K, ZHANG X, REN S, et al.Spatial pyramid pooling in deep convolutional networks for visual recognition [C]// ECCV 2014: Proceedings of the 13th European Conference on Computer Vision.Berlin: Springer, 2014: 346-361.
[22] SZEGEDY C, LIU W, JIA Y, et al.Going deeper with convolutions [C]// Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition.Piscataway, NJ: IEEE, 2015: 1-9.
[23] HE K, ZHANG X, REN S, et al.Delving deep into rectifiers: surpassing human-level performance on ImageNet classification [C]// Proceedings of the 2015 IEEE International Conference on Computer Vision.Washington, DC: IEEE Computer Society, 2015: 1026-1034.
[24] IOFFE S, SZEGEDY C.Batch normalization: accelerating deep network training by reducing internal covariate shift [C]// Proceedings of the 32nd International Conference on Machine Learning.Washington, DC: IEEE Computer Society, 2015: 448-456.
[25] JIN C, JIN S W.Image distance metric learning based on neighborhood sets for automatic image annotation [J].Journal of Visual Communication and Image Representation, 2016, 34: 167-175.
This work is supported by the Key Projects in the National Science and Technology Pillar Program during the Twelfth Five-year Plan Period of China (2015BAK12B00).
GAO Yaodong, born in 1991, M.S.candidate.His research interests include machine learning, pattern recognition.
HOU Lingyan, born in 1964, M.S., associate professor.Her research interests include multimedia technology, pattern recognition.
YANG Dali, born in 1963, Ph.D., associate professor.His research interests include pattern recognition, signal enhancement.
Automatic image annotation method using multi-label learning convolutional neural network
GAO Yaodong*, HOU Lingyan, YANG Dali
(CollegeofComputer,BeijingInformationScienceandTechnologyUniversity,Beijing100101,China)
Focusing on the shortcoming of the automatic image annotation, the lack of information caused by artificially selecting features, convolutional neural network was used to learn the characteristics of samples.Firstly, in order to adapt to the characteristics of multi label learning of automatic image annotation and increase the recall rate of the low frequency words, the loss function of convolutional neural network was improved and a Convolutional Neural Network of Multi-Label Learning (CNN-MLL) model was constructed.Secondly, the correlation between the image annotation words was used to improve the output of the network model.Compared with other traditional methods on the Technical Committee 12 of the International Association for Pattern Recognition (IAPR TC-12) benchmark image annotation database, the experimental result show that the Convolutional Neural Network using Mean Square Error function (CNN-MSE) method achieves the average recall rate of 12.9% more than the Support Vector Machine (SVM) method, the average accuracy of 37.9% more than the Back Propagation Neural Network (BPNN) method.And the average accuracy rate and average recall rate of marked results improved CNN-MLL method is 23% and 20% higher than those of the traditional CNN.The results show that the marked results improved CNN-MLL method can effectively avoid the information loss caused by the artificially selecting features, and increase the recall rate of the low frequency words.
automatic image annotation; multi-label learning; Convolution Neural Network (CNN); loss function
2016-06-15;
2016-09-12。 基金項目:“十二五”國家科技支撐計劃項目(2015BAK12B00)。
高耀東(1991—),男,安徽合肥人,碩士研究生,主要研究方向:機器學習、模式識別; 侯凌燕(1964—),女,湖南長沙人,副教授,碩士,主要研究方向:多媒體技術、模式識別; 楊大利(1963—),男,河北陽原人,副教授,博士,主要研究方向:模式識別、信號增強。
1001-9081(2017)01-0228-05
10.11772/j.issn.1001-9081.2017.01.0228
TP391.41; TP18
A
猜你喜歡
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
世界科學技術-中醫藥現代化(2020年2期)2020-07-25 02:05:36
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
兒童故事畫報(2019年5期)2019-05-26 14:26:14
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
