基于中醫(yī)方劑數(shù)據(jù)庫的Top-Rank-k頻繁模式挖掘算法
2017-04-20 05:38:56秦琦冰
計算機應(yīng)用 2017年2期
秦琦冰,譚 龍,2
(1.黑龍江大學(xué) 計算機科學(xué)技術(shù)學(xué)院,哈爾濱 150080; 2.黑龍江省數(shù)據(jù)庫與并行計算重點實驗室(黑龍江大學(xué)),哈爾濱 150080)
(*通信作者電子郵箱tanlong@hlju.edu.cn)
基于中醫(yī)方劑數(shù)據(jù)庫的Top-Rank-k頻繁模式挖掘算法
秦琦冰1,譚 龍1,2*
(1.黑龍江大學(xué) 計算機科學(xué)技術(shù)學(xué)院,哈爾濱 150080; 2.黑龍江省數(shù)據(jù)庫與并行計算重點實驗室(黑龍江大學(xué)),哈爾濱 150080)
(*通信作者電子郵箱tanlong@hlju.edu.cn)
為降低中醫(yī)(TCM)方劑頻繁模式挖掘過程中對經(jīng)驗參數(shù)的依賴,提高挖掘結(jié)果的準(zhǔn)確性,針對中醫(yī)方劑的數(shù)據(jù)特點,提出一種基于帶權(quán)無向圖的Top-Rank-k頻繁模式挖掘算法。該算法可以直接挖掘出頻繁k-itemset(k≥3)而無需產(chǎn)生1-itemset和2-itemset,并隨之快速回溯到核心藥物組合的頻繁項集所對應(yīng)的方劑信息;此外,采用一種動態(tài)位向量(DBV)的壓縮機制對無向圖中邊的權(quán)重進行壓縮存儲,以有效地提高算法的空間存儲效率。分別對中醫(yī)方劑數(shù)據(jù)集、真實數(shù)據(jù)集(Chess、Pumsb和Retail)和合成數(shù)據(jù)集(T10I4D100K和Test2K50KD1)進行測試和比較,結(jié)果表明該算法與iNTK和BTK相比具有更高的時間和空間效率,而且也可以應(yīng)用于其他類型的數(shù)據(jù)集。
中醫(yī)方劑;Top-Rank-k;頻繁模式;帶權(quán)無向圖;動態(tài)位向量
0 引言
數(shù)據(jù)挖掘指的是從大量的數(shù)據(jù)中通過相應(yīng)的算法發(fā)現(xiàn)隱藏于其中未知且可能有用的信息[1-2]。在數(shù)據(jù)挖掘領(lǐng)域,頻繁模式挖掘始終扮演著至關(guān)重要的作用[3]。在傳統(tǒng)的頻繁模式挖掘過程中,用戶需要輸入最小支持度閾值來生成滿足條件的頻繁模式集合,因此傳統(tǒng)的頻繁模式挖掘可能會產(chǎn)生以下兩個問題[4]: 1)用戶很難準(zhǔn)確設(shè)置合適的最小支持度,如果閾值太小可能會產(chǎn)生大量的頻繁模式,閾值太大可能會把某些關(guān)鍵信息過濾掉;2)傳統(tǒng)的頻繁模式挖掘結(jié)果中往往包含大量用戶不感興趣的關(guān)聯(lián)規(guī)則。
基于上述問題,Han等[5]提出了一種新的挖掘任務(wù)——Top-k的頻繁閉模式,其中k是被挖掘的頻繁閉模式的數(shù)量,并且模式的最小長度為min_l。為了更好地解決上述問題,Wang等[6]提出了一種有效的挖掘算法——TFP(Top-kFrequent Patterns)算法。然而,在Top-k的頻繁閉模式過程中,用戶同樣需要輸入?yún)?shù)min_l,這對于用戶同樣是很難精確把握的。在此基礎(chǔ)上,Deng等[7]提出了一種Top-Rank-k頻繁模式的挖掘任務(wù),并且提出了解決該問題的FAE(Filtering And Extending)算法。與Top-k的頻繁閉模式不同的是,在Top-Rank-k頻繁模式挖掘過程中,用戶不需要設(shè)置參數(shù)min_l;由于此挖掘過程中是按照Rank-k對于候選模式進行篩選,因此能夠包含更多用戶感興趣的規(guī)則。
在上述學(xué)者的研究基礎(chǔ)上,F(xiàn)ang等[8]在FAE算法的基礎(chǔ)上,采用一種數(shù)據(jù)垂直分布的形式,將頻繁模式的計數(shù)轉(zhuǎn)化為一種Tid-lists相交操作,有效地提高了挖掘效率。Deng[9]將事務(wù)數(shù)據(jù)庫采用PPC-tree進行存儲,對所有的項集按照Node-list進行編碼,將Top-Rank-k頻繁模式挖掘轉(zhuǎn)化為Node-list的操作,提出了NTK(Node-list Top-Rank-K)算法。Huynh-Thi-Le等[10]在NTK算法的基礎(chǔ)上,將Subsume的概念及其相關(guān)性質(zhì)應(yīng)用到Top-Rank-k頻繁模式中,提出了iNTK(improved Node-list Top-Rank-K)算法。由于PPC-tree在構(gòu)建采用“先建樹后編碼”的方式,所以該過程需要掃描兩次事務(wù)數(shù)據(jù)庫,隨著事務(wù)數(shù)據(jù)庫的增加,算法效率有待提高,因此Dam等[11]采用一種“邊建樹邊編碼”的方式,設(shè)計和實現(xiàn)了更加有效的數(shù)據(jù)結(jié)構(gòu)——TB-tree,并在此基礎(chǔ)上采用B-list的方式進行編碼,提出了更加有效的BTK(B-list Top-Rank-K)算法。
本研究團隊一直從事中醫(yī)方劑中治療消渴病[12]方劑的數(shù)據(jù)挖掘工作。消渴病是以多飲、多食、多尿、身體消瘦,或尿濁、尿中有甜味為主要表現(xiàn)的一種臨床常見病、多發(fā)病,嚴(yán)重危害著人類的健康,中醫(yī)對于消渴病的預(yù)防和治療有著豐富而且獨特的經(jīng)驗[13],因此,對《中醫(yī)方劑大辭典》中收錄的治療消渴病腎陰虛型方劑的研究也尤為重要。在研究中發(fā)現(xiàn),在實際中醫(yī)方劑數(shù)據(jù)挖掘中,用戶很難設(shè)置合理的最小支持度閾值,因此相比傳統(tǒng)的頻繁模式,Top-Rank-k頻繁模式挖掘更加具有實際應(yīng)用價值。此外,治療消渴病相關(guān)癥型的方劑中往往存在大量的頻繁k-itemset,而相比1-itemset、2-itemset而言,k-itemset(k≥3)對于治療消渴病腎陰虛型也更具有重要的臨床參考價值。同時,在對方劑數(shù)據(jù)庫的Top-Rank-k頻繁模式挖掘過程中,上述傳統(tǒng)的算法在找到頻繁項集結(jié)果后,卻不能有效發(fā)現(xiàn)該頻繁項集所對應(yīng)的方劑名稱,而方劑名稱和頻繁項集的對應(yīng)關(guān)系,對方劑規(guī)律分析具有重要意義。
因此,針對上述研究問題,本文提出了一種基于帶權(quán)無向圖(Weighted Undirected Graph, WUG)的Top-Rank-k頻繁模式挖掘算法(Top-Rank-kfrequent patterns mining algorithm based on WUG, WUG_TK)。該算法在動態(tài)位向量(Dynamic Bit Vector, DBV)[14]的數(shù)據(jù)結(jié)構(gòu)基礎(chǔ)上引入相關(guān)的性質(zhì)對無向圖中的權(quán)重進行壓縮存儲,可以有效地提高空間效率;同時通過搜索頻繁項集環(huán),大幅減少對原始數(shù)據(jù)庫的掃描次數(shù),避免產(chǎn)生大量的候選項集,能夠直接有效地挖掘出滿足條件的k-itemset(k≥3),并且快速回溯到該頻繁項集所對應(yīng)的方劑名稱,提高對于中醫(yī)方劑數(shù)據(jù)挖掘效率。
1 系統(tǒng)模型
1.1 基本概念
本文系統(tǒng)模型為,存在項集I={I1,I2,…,Im},事務(wù)數(shù)據(jù)庫D={〈TID,T〉|T?I},其中:TID為代表每一條事務(wù)的標(biāo)識符;T為項的集合稱為模式或者項集;T的支持度用Sup(T)表示。本文中所涉及到的概念介紹如下:
定義1 模式的Rank。假設(shè)存在某模式A,以及事務(wù)數(shù)據(jù)庫D,A模式的Rank記為RA,則:
RA=|{Sup(X)}|X?I∧Sup(X)≥Sup(A)}|
其中|Y|表示集合Y里面的元素數(shù)目。
例如在表1的事務(wù)數(shù)據(jù)庫中,I2分別出現(xiàn)在TID1、TID2、TID3、TID4、TID5模式中,Sup(I2)=5,通過計算其他模式的支持度可以發(fā)現(xiàn)Sup(I2)最大,因此{I2}的Rank為1,記為:RI2=1。
定義2Top-Rank-k頻繁模式。假設(shè)存在事務(wù)數(shù)據(jù)庫D和閾值k,?A?I,如果RA≤k,那么A為Top-Rank-k頻繁模式。
Top-Rank-k頻繁模式挖掘的目的是在給定的事務(wù)數(shù)據(jù)庫D和閾值k基礎(chǔ)上, 發(fā)現(xiàn)所有的模式Rank不超過k的模式集合,記為STop-Rank-k,則:
STop-Rank-k={X|X?I∧RX≤k}
例如在表1的事務(wù)數(shù)據(jù)庫中,假設(shè)k=3, 則滿足條件的Top-Rank-k頻繁模式如下所示:
STop-Rank-k={{I1},{I2},{I1I2},{I4},{I5},
{I1I4},{I1I5},{I2I4},{I2I5},{I1I2I4},{I1I2I5}}
文獻[7]中已經(jīng)證明Top-Rank-k頻繁模式挖掘過程滿足反單調(diào)性,即:?模式A?B,如果模式A不是Top-Rank-k頻繁模式,那么B也一定不是Top-Rank-k頻繁模式。
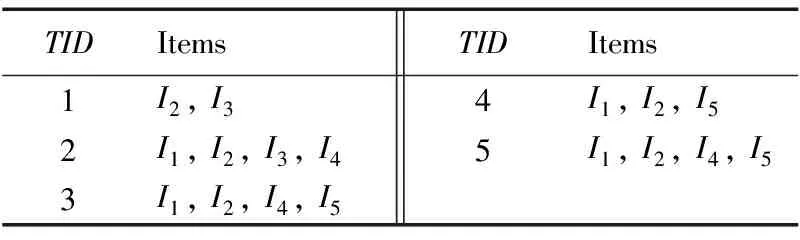
表1 事務(wù)數(shù)據(jù)庫表
1.2 DBV數(shù)據(jù)結(jié)構(gòu)
Top-Rank-k頻繁模式挖掘過程中,如何對數(shù)據(jù)進行高效存儲十分重要。Dong等[15]提出的BitTable-FI和Song等[16]提出的Index-BitTableFI都是根據(jù)事務(wù)的數(shù)量,采用一種基于數(shù)據(jù)垂直分布的定長的方式進行儲存。當(dāng)處理數(shù)據(jù)比較稀疏時,BitTable-FI和Index-BitTableFI會造成空間的浪費,因此,本文采用一種更加高效的數(shù)據(jù)結(jié)構(gòu)——動態(tài)位向量(DBV)[14]進行存儲,并且在此基礎(chǔ)上引入了有關(guān)DBV的定義以及與本文算法有關(guān)的性質(zhì)和操作。
DBV數(shù)據(jù)結(jié)構(gòu)包含兩個域,用二元組的形式表示:〈Pos,BVecor〉,其中:Pos表示存儲的第一個非0位的位置;BVecor表示從Pos開始到尾部最后一個非0位置的所有二進制位(本文中采取十進制的形式表示)。
例如,在表1中,n=5,在申請1個char類型存儲空間(8位)的情況下,按照從低位到高位的按位存儲,項I1存在的TID為2,3,4,5,即:t(I1)=〈0,1,1,1,1,0,0,0〉,項I1二進制位存儲方式如圖1所示。
圖1 項I1二進制位存儲方式
Fig.1BinarybitstoragemodeofitemI1
由此可見,當(dāng)數(shù)據(jù)比較稀疏時,低位和高位存儲的0會造成空間浪費,因此采用DBV數(shù)據(jù)結(jié)構(gòu)進行存儲,如圖2所示。
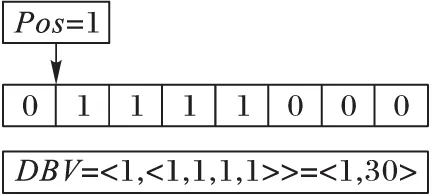
圖2 項I1的DBV存儲方式
在t(I1)=〈0,1,1,1,1,0,0,0〉中,存儲的第一個非0位的位置是1,所以Pos=1,則項I1的DBV存儲方式為:
DBV(I1)=〈1,〈1,1,1,1〉〉=
〈1,〈21+22+23+24=30〉〉=〈1,30〉
下面介紹兩個DBV之間的相交操作。
定義3 對于任意兩個DBV,假設(shè)DBV1=〈Pos1,BVector1〉,DBV2=〈Pos2,BVector2〉,當(dāng)且僅當(dāng)DBV1∩DBV2=DBV1時,DBV1是DBV2的子集,即:DBV1?DBV2。
定義4 對于任意兩個DBV,假設(shè)DBV1=〈Pos1,BVector1〉,DBV2=〈Pos2,BVector2〉,當(dāng)且僅當(dāng)Pos1=Pos2,|BVector1|=|BVector2|,?i∈[0,|BVector1|-1],BVector1[i]=BVector2[i],則DBV1與DBV2相等,即:DBV1=DBV2
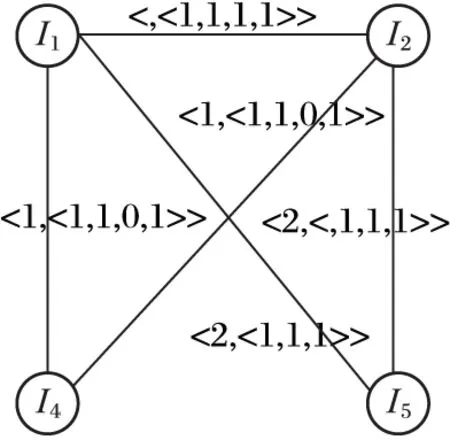
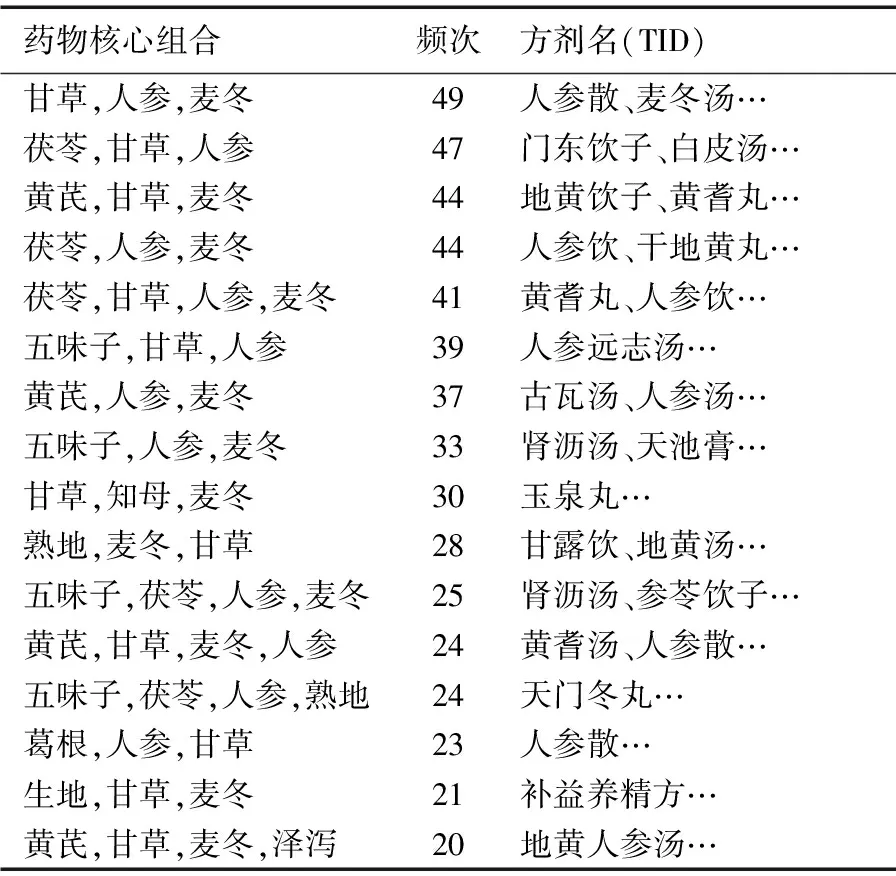
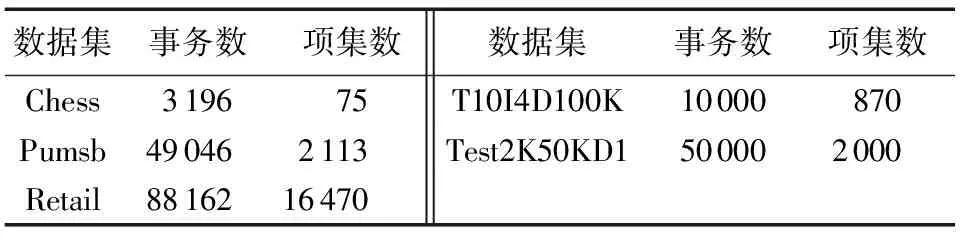
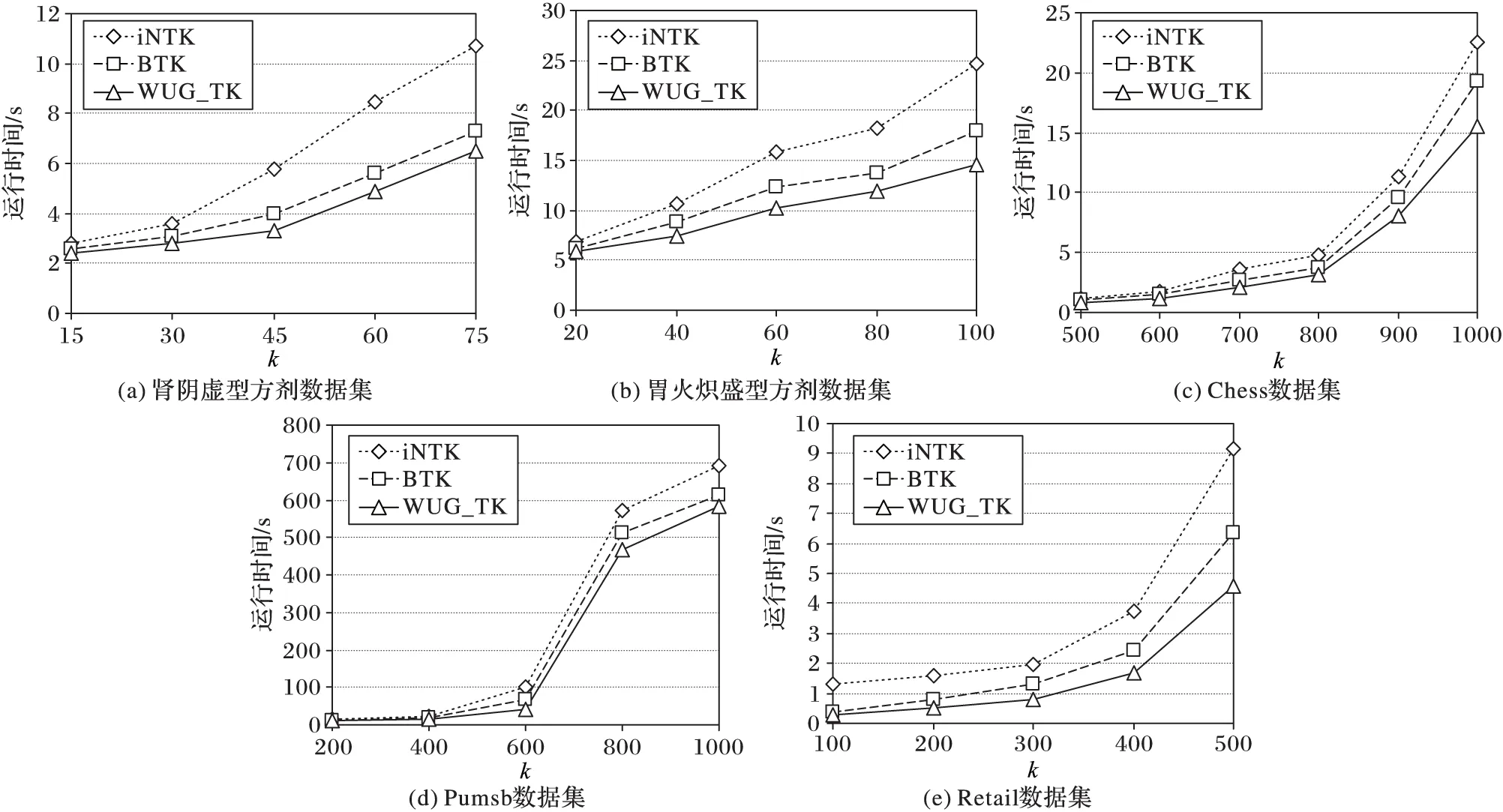
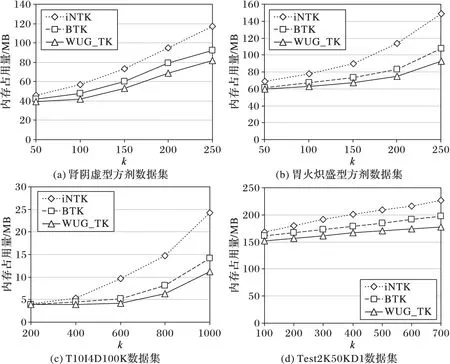
性質(zhì)1 對于任意兩個DBV,假設(shè)DBV1=〈Pos1,BVector1〉,DBV2=〈Pos2,BVector2〉,如果Pos1+|BVector1| 證明 當(dāng)Pos1+|BVector1| 當(dāng)Pos2+|BVector2| 對于兩個DBV之間的相交操作之前,首先要對于DBV1和DBV2進行相交操作,以判斷是否存在子集、相等、空集,如果存在,則由上述定義3、定義4和性質(zhì)1直接進行計算。否則,從Posmax的位置對BVector進行&操作,如果&操作結(jié)果為0,則Posmax+1,直到&操作結(jié)果為1,則Posmax記錄下該位置;從該位置開始進行&操作,一直到剩余位都是0。具體算法DBV_Intersection如下所示: Input:DBV1=〈Pos1,BVector1〉,DBV2=〈Pos2,BVector2〉 Output:DBV_finalProcedure DBV_Intersection(DBV1,DBV2) 1) Pos=max(Pos1,Pos2) 2) i=Pos1 3) j=Pos1 4) count=|BVector1|-i<|BVector2|-j?|BVector1|-i:|BVector2|-j //intersection操作中的位數(shù) 5) whilecount>0 andBVector1[i] &BVector2[j]=0 //找到第一個非零位 6) i=i+1;j=j+1; 7) Pos=Pos+1;count=count-1; 8) i1=i+count-1;j1=j+count-1; 9) whilecount>0 andBVector1[i1] &BVector2[j1]=0 //找到最后一個非零位 10) i1=i1-1;j1=j1-1; 11) count=count-1; 12) Fork=0 tocount-1 //找到進行intersection操作的位置 13) BVector[k]=BVector1[i] &BVector2[j] 14) i=i+1;j=j+1; End procedure 如圖3中所示,DBV(I3)=〈0,〈1,1〉〉,DBV(I1)=〈1, 〈1,1,1,1〉〉,則從Pos_I1開始對DBV數(shù)據(jù)結(jié)構(gòu)中的BVector進行&操作,則DBV(I1I3)=〈1,1〉=〈1,2〉。 圖3 I1和I3的DBV_Intersection 1.3 帶權(quán)無向圖 針對中醫(yī)方劑Top-Rank-k頻繁模式挖掘,本文采用一種帶權(quán)無向圖對于Top-Rank-k頻繁模式進行存儲,該算法可以直接產(chǎn)生更加符合中醫(yī)數(shù)據(jù)特點的頻繁模式(k-itemset,k≥3),而且可以有效地回溯到該頻繁模式所對應(yīng)的方劑名,這對于中醫(yī)方劑數(shù)據(jù)挖掘有著重要意義。另外,該算法還可以避免產(chǎn)生大量的候選項集,提高算法效率。 本文中帶權(quán)無向圖中的節(jié)點由項集I中的項組成;節(jié)點項之間如果是Top-Rank-k頻繁模式,則有邊;1-itemset為點集V;E為邊集;E(Vx,Vy)表示點Vx和Vy的邊;Top-Rank-k頻繁模式閾值為k。則有以下定義: 定義5 權(quán)重。假設(shè)存在項集X、Y,以及DBV(X)和DBV(Y),如果DBV(XY)=DBV(X)∩DBV(Y),則稱該DBV(XY)為X與Y之間的權(quán)重。 例如DBV(I3)={0,{1,1}},DBV(I1)=〈1,〈1,1,1,1〉〉,則DBV(I1I3)=〈1,1〉=〈1,2〉,則DBV(I1I3)則為I1與I3之間的權(quán)重,Sup(I1I3)=|DBV(I1I3)|=1。 對于任意兩個項集X和Y,如果XY模式Rank不大于k,即:RXY≤k,則X與Y之間存在邊E(X,Y),該邊加入到E中,同時weight(X,Y)=DBV(XY)。重復(fù)此過程生成可存儲Top-Rank-k頻繁模式的帶權(quán)無向圖,具體的生成算法Procedure WUG_GEN如下所示: Input: Transactional DatabaseD,kOutput: WUG Procedure WUG_GEN(D,k) 1) For eachVj∈L1 2) For eachVi∈L1(i≠j) 3) CountSup(VjVi) and sort in descending order bySup(VjVi) 4) IfR(VjVi)≤k 5) AddE(Vi,Vi) to Edge setE; //增加邊E(Vi,Vi)到邊集E中 6) weight(Vi,Vj)=DBV_Intersection 7) End if; 8) End for; 9) End for; End procedure 定理1 在給定的帶權(quán)無向圖中,對于某個點集合V′中任意兩點Vi和Vk,如果都存在一條邊E(Vi,Vk)∈E,則V′中所有的點構(gòu)成一條Top-Rank-k頻繁項集環(huán),即為Top-Rank-k頻繁項集。 證明 假設(shè)?Vi∈V(1≤i≤m),?V′=〈V1,V2,…,Vi, …,Vj, …,Vk〉,如果對于?Vi∈V′, ?Vj∈V′,使得E(Vi,Vj)∈E成立,由ProcedureWUG_GEN和Top-Rank-k頻繁模式挖掘過程中的反單調(diào)性[7]可知,{V1,V2,Vi,…,Vj, …,Vk}為Top-Rank-k頻繁項集,即存在一條Top-Rank-k頻繁項集環(huán),該環(huán)路經(jīng)過的頂點〈V1,V2,…,Vk〉即為滿足Rank條件的頻繁項集。 本文在帶權(quán)無向項圖的基礎(chǔ)上,提出了一種Top-Rank-k頻繁模式挖掘算法(WUG_TK)。算法中使用帶權(quán)無向圖存儲Top-Rank-k頻繁模式,圖中頂點集合即為1-itemset,頂點之間邊的權(quán)值即為DBV(ViVj),如果存在Top-Rank-k頻繁項集環(huán),則環(huán)上面的頂點即為滿足Rank條件的頻繁項集。環(huán)路的每條邊的權(quán)值,進行與(&)操作,其結(jié)果即為頻繁項集所在的TID。該TID在具體中醫(yī)方劑數(shù)據(jù)處理中,即為頻繁藥物組合所對應(yīng)的方劑名稱。 在上述生成的帶權(quán)無向圖(WUG)的基礎(chǔ)上,搜索Top-Rank-k頻繁項集環(huán)的操作見Procedure Mining_Top-Rank-k_Frequent Patterns算法,該算法調(diào)用Procedure Top-Rank-k_Frequent Patterns loop來完成對Top-Rank-k頻繁項集環(huán)的搜索。 Mining_Top-Rank-k_Frequent Patterns算法描述如下: Input: WUG Output: Top-Rank-k_Frequent Patterns,TIDProcedureMining_Top-Rank-k_Frequent Patterns(WUG) 1) WhileV≠?do 2) ForeachVi,Vj(i≠j)ofV 3) IfE(Vi,Vj)∈Ethen //Vi,Vj之間有邊相連 4) L=Vi∪Vj,V′=V-{Vi,Vj} //L為其中任意兩點都有邊相連的點集合; //V′為含有未搜索到的點的集合 5) Search Top-Rank-k_Frequent Patterns loop(L,V′); //調(diào)用Procedure Top-Rank-k_Frequent Patterns loop //來搜索Top-Rank-k頻繁項集環(huán) 6) End If; 7) End For; 8) End While; End procedure; Procedure Top-Rank-k_Frequent Patterns loop(L,V′) 1) WhileV′≠nulldo 2) ForunvisitedVkofV′ 3) IfE(Vk,?Vj∈V′)∈Ethen; 4) L=L∪Vk,V′=V′-{Vk}; 5) OutputLandweight_&; //輸出Top-Rank-k_Frequent Patterns和對應(yīng)的TID 6) Endif; 7) Endfor; 8) Endwhile; Endprocedure 例如在表1事務(wù)數(shù)據(jù)庫中,設(shè)k=3,根據(jù)WUG_GEN算法:I1出現(xiàn)TID分別為2、3、4、5,則DBV(I1)=〈1,〈1,1,1,1〉〉=〈1,30〉,I2出現(xiàn)TID分別為1、2、3、4、5,則DBV(I2)=〈0,〈1,1,1,1,1〉〉=〈0,31〉,因為DBV(I1)是DBV(I2)的子集,則DBV(I1)∩DBV(I2)=DBV(I1)=〈1,〈1,1,1,1〉〉,則Sup(I1I2)=4,此時R(I1 I2)=1,則頂點I1頂點I2之間存在一條邊E(I1,I2),weight(I1,I2)=〈1,〈1,1,1,1〉〉=〈1,30〉,以此類推可以生成如圖4所示的Top-Rank-3的頻繁模式圖。 圖4 Top-Rank-3的頻繁模式圖 根據(jù)Mining_Top-Rank-k_Frequent Patterns算法:對于WUG(V,E,W)中?E(Vi,Vj)∈E,例如圖1中的點I1和點I2,從V′=V-{I1,I2}={I4,I5}中選取點I4,則E(I4,I1)∈E,E(I4,I2)∈E,則點I1、點I2和點I4之間存在一條Top-Rank-3頻繁項集環(huán),則I1I2I4為滿足Rank小于等于3的頻繁3-itemset,weight(I1,I2) &weight(I1,I4) &weight(I2,I4)=〈1,〈1,1,0,1〉〉,即I1I2I4出現(xiàn)的TID為2、3、5。同理可以由圖4可以生成Rank小于等于2的頻繁3-itemsetI1I2I5,I1I2I5出現(xiàn)的TID為3、4、5。 3.1 實驗設(shè)置與結(jié)果 實驗環(huán)境為IntelCorei3-3110M2.4GHzCPU,4GBRAM,操作系統(tǒng)為Windows7。算法在VisualStudio2012,.NetFrameworkVersion4.5.50709的環(huán)境下實現(xiàn)。 中醫(yī)方劑實驗數(shù)據(jù)是從《中醫(yī)方劑大辭典》中收錄的治療消渴病腎陰虛型方劑中篩選出來的346首方劑,包含163味中藥藥材。針對數(shù)據(jù)的前期準(zhǔn)備處理主要是針對藥物組成的規(guī)范,該規(guī)范包括:藥材的重名和異名處理、同名異方的處理、藥材計量單位的統(tǒng)一。在此規(guī)范數(shù)據(jù)基礎(chǔ)上,構(gòu)建方劑數(shù)據(jù)庫。 通過對《中醫(yī)方劑大辭典》中收錄的方劑進行分析,初步按照編號、方劑名、組成、別名、性、味、歸經(jīng)、功效等8個屬性進行描述,完成對原始數(shù)據(jù)庫的構(gòu)建;然后利用基于帶權(quán)無向圖的Top-Rank-k頻繁模式挖掘算法對數(shù)據(jù)源存儲的方劑進行分析研究。 根據(jù)本次治療腎陰虛型方劑數(shù)量和用到的中藥個數(shù),結(jié)合經(jīng)驗判斷以及不同參數(shù)提取數(shù)據(jù)的預(yù)讀,篩選出部分有價值的Top-Rank-16的k-itemset(k≥3)及所對應(yīng)的方劑名見表2。 表2 治療腎陰虛型組方中Top-Rank-16藥物核心組合 3.2 算法性能對比及分析 本文提出的WUG_TK算法主要與Huynh-Thi-Le等[10]的iNTK算法和Dam等[11]的BTK算法分別從運行時間、消耗空間作了對比實驗。對比實驗數(shù)據(jù)集分別采用中醫(yī)方劑數(shù)據(jù)集和公開測試數(shù)據(jù)集。中醫(yī)方劑數(shù)據(jù)集實驗數(shù)據(jù)采用《中醫(yī)方劑大辭典》中收錄的治療消渴病腎陰虛型和胃火熾盛型兩種癥型方劑。其中,治療腎陰虛型方劑共346首,包含163味中藥藥材;治療消渴病胃火熾盛方劑共382首,包含218味中藥藥材。公開測試數(shù)據(jù)集如表3所示,主要包括Chess、Pumsb和Retail三個真實數(shù)據(jù)集(http://fimi.ua.ac.be/data/),以及T10I4D100K和Test2K50KD1人工合成數(shù)據(jù)集。其中人工合成數(shù)據(jù)集主要是由LUCS-KDD數(shù)據(jù)生成器合成的。算法運行時間的對比實驗在真實數(shù)據(jù)集上進行,結(jié)果如圖5所示;而算法消耗空間的對比實驗在人工模擬數(shù)據(jù)集上進行,結(jié)果如圖6所示。 表3 對比實驗數(shù)據(jù)集 圖5 算法運行時間對比 圖6 算法空間消耗對比 實驗中,三種算法通過設(shè)置不同的k值進行實驗比較。當(dāng)平均項數(shù)目較小時,生成有效項集的概率就會降低,符合條件的Top-Rank-k的頻繁模式就會增多,挖掘代價也會相應(yīng)增加。因此,實驗中對不同的實驗數(shù)據(jù)集選擇不同的閾值,從而保證實驗結(jié)果的有效性。 由于WUG_TK算法通過帶權(quán)無向圖直接產(chǎn)生k-itemset(k≥3),避免了候選項集的產(chǎn)生,而iNTK和BTK都采取了“建樹-編碼”的過程,與之相比,WUG_TK算法不需要對數(shù)據(jù)集中的項集進行編碼,而是在構(gòu)造完成的帶權(quán)無向圖上直接搜索符合Rank條件的頻繁模式環(huán),從而大幅提高了算法的運行效率,因此WUG_TK算法性能明顯優(yōu)于iNTK和BTK算法。 由于WUG_TK算法中對于權(quán)重采用DBV的壓縮數(shù)據(jù)結(jié)構(gòu)進行存儲,可以有效地提高空間利用率,而iNTK算法和BTK算法在運行過程中都需要采用臨時表對中間結(jié)果集進行存儲,從而也造成了過大開銷。因此本文提出的WUG_TK算法在空間效率上也優(yōu)于iNTK算法和BTK算法。 本文根據(jù)中醫(yī)方劑的數(shù)據(jù)特點,提出了一種基于帶權(quán)無向圖的Top-Rank-k頻繁模式挖掘算法WUG_TK。該算法在不產(chǎn)生1-itemset和2-itemset的前提下,可以直接產(chǎn)生k-itemset(k≥3),更加符合中醫(yī)方劑挖掘的需求;同時WUG_TK可以回溯到頻繁項集所在的方劑名,這對方劑規(guī)律分析具有重要意義;此外,WUG_TK算法中采用DBV數(shù)據(jù)結(jié)構(gòu)對于無向圖中的權(quán)重進行壓縮存儲,可以有效地降低空間復(fù)雜度。實驗結(jié)果表明,WUG_TK算法與iNTK和BTK算法相比具有更高的時間和空間效率。 由于本文中DBV數(shù)據(jù)結(jié)構(gòu)采取了一種位向量的方式進行動態(tài)壓縮存儲,當(dāng)處理的數(shù)據(jù)過于稠密時,數(shù)據(jù)中往往存在大量的非0位,此時DBV的壓縮效果還有待提高。另外,由于中醫(yī)方劑Top-Rank-k頻繁模式挖掘中往往存在冗余,這就會造成挖掘效率的降低,下一步將針對如何在挖掘過程中減少信息冗余進行研究。 References) [1] SOLANKI S K, PATEL J T.A survey on association rule mining [C]// ACCT 2015: Proceedings of the 2015 5th International Conference on Advanced Computing & Communication Technologies.Washington, DC: IEEE Computer Society, 2015: 212-216. [2] CHEN H, LI T, LUO C, et al.A decision-theoretic rough set approach for dynamic data mining [J].IEEE Transactions on Fuzzy Systems, 2015, 23(6): 1958-1970. [3] KARTHIKEYAN T, RAVIKUMAR N.A survey on association rule mining [J].International Journal of Advanced Research in Computer and Communication Engineering, 2014, 3(1): 5223-5227. [4] LE B, VO B, HUYNH-THI-LE Q, et al.Enhancing the mining top-rank-kfrequent patterns [C]// SMC 2014: Proceedings of the 2014 IEEE International Conference on Systems, Man and Cybernetics.Piscataway, NJ: IEEE, 2014: 2008-2012. [5] HAN J, WANG J, LU Y, et al.Mining top-k frequent closed patterns without minimum support [C]// ICDM ’02: Proceedings of the 2002 IEEE International Conference on Data Mining.Washington, DC: IEEE Computer Society, 2002: 211-218. [6] WANG J, HAN J, LU Y, et al.TFP: an efficient algorithm for mining top-kfrequent closed itemsets [J].IEEE Transactions on Knowledge and Data Engineering, 2005, 17(5): 652-664. [7] DENG Z-H, FANG G-D.Mining top-rank-kfrequent patterns [C]// Proceedings of the 2007 International Conference on Machine Learning and Cybernetics.Piscataway, NJ: IEEE, 2007: 851-856. [8] FANG G-D, DENG Z-H.VTK: vertical mining of top-rank-kfrequent patterns [C]// FSKD’08: Proceedings of the 2008 5th International Conference on Fuzzy Systems and Knowledge Discovery.Washington, DC: IEEE Computer Society, 2008, 2: 620-624. [9] DENG Z-H.Fast mining top-rank-kfrequent patterns by using node-lists [J].Expert Systems with Applications, 2014, 41(4): 1763-1768. [10] HUYNH-THI-LE Q, LE T, VO B, et al.An efficient and effective algorithm for mining top-rank-kfrequent patterns [J].Expert Systems with Applications, 2015, 42(1): 156-164. [11] DAM T-L, LI K, FOURNIER-VIGER P, et al.An efficient algorithm for mining top-rank-kfrequent patterns [J].Applied Intelligence, 2016, 45(1): 96-111. [12] 吳長汶,張轉(zhuǎn)喜,吳水生,等.從五味太過探討“甘邪”與消渴病因的關(guān)系[J].中華中醫(yī)藥雜志,2015(3):670-672.(WU C W, ZHANG Z X, WU S S, et al.Exploration on the relationship between the sweet-evil and consumptive thirst pathogenesis based on theory of excess of five kinds of taste [J].China Journal of Traditional Chinese Medicine and Pharmacy, 2015(3): 670-672.) [13] 榮開明.復(fù)興中醫(yī)藥學(xué)的幾點思考[J].湖北中醫(yī)藥大學(xué)學(xué)報,2015,17(2):59-62.(RONG K M.Considerations on revival of TCM [J].Journal of Hubei University of Chinese Medicine, 2015,17(2):59-62.) [14] VO B, HONG T-P, LE B.DBV-Miner: a dynamic bit-vector approach for fast mining frequent closed itemsets [J].Expert Systems with Applications, 2012, 39(8): 7196-7206. [15] DONG J, HAN M.BitTableFI: an efficient mining frequent itemsets algorithm [J].Knowledge-Based Systems, 2007, 20(4): 329-335. [16] SONG W, YANG B, XU Z.Index-BitTableFI: an improved algorithm for mining frequent itemsets [J].Knowledge-Based Systems, 2008, 21(6): 507-513. This work is partially supported by the National Natural Science Foundation of China (81273649), Natural Science Foundation of Heilongjiang Province (F201434), Graduate Student Innovation and Research Item of Heilongjiang University (YJSCX2016- 018HLJU). QIN Qibing, born in 1990, M.S.candidate.His research interests include machine learning, data warehouse, data mining. TAN Long, born in 1971, M.S., associate professor.His research interests include machine learning, sensor network, data mining. Top-Rank-kfrequent patterns mining algorithm based on TCM prescription database QIN Qibing1, TAN Long1,2* (1.CollegeofComputerScienceandTechnology,HeilongjiangUniversity,HarbinHeilongjiang150080,China;2.KeyLaboratoryofDatabaseandParallelComputingofHeilongjiangProvince(HeilongjiangUniversity),HarbinHeilongjiang150080,China) The dependency of the empirical parameters in frequent patterns mining of Traditional Chinese Medicine (TCM) prescriptions should be reduced to improve the accuracy of mining results.Aiming at the characteristics of TCM prescription data, an efficient Top-Rank-kfrequent patterns mining algorithm based on Weighted Undirected Graph (WUG) was proposed.The new algorithm can directly mining frequentk-itemset (k≥3) without mining 1-times and 2-times, and then quikly backtrack to the corresponding prescription of the frequent itemsets of core drugs combination.Besides, the compression mechanism of Dynamic Bit Vector (DBV) was used to store the edge weights in undirected graph to improve the spatial storage efficiency of the algorithm.Experiments were conducted on TCM prescription datasets, real datasets (Chess, Pumsb and Retail) and synthetic datasets (T10I4D100K and Test2K50KD1).The experimental results show that compared with iNTK (improved Node-list Top-Rank-K) and BTK (B-list Top-Rank-K), the proposed algorithm has better performance in terms of time and space, and it can be applied to other types of data sets. Traditional Chinese Medicine (TCM) prescription; Top-Rank-k; frequent pattern; Weighted Undirected Graph (WUG); Dynamic Bit Vector (DBV) 2016- 08- 12; 2016- 09- 08。 基金項目:國家自然科學(xué)基金面上項目(81273649);黑龍江省自然科學(xué)基金面上項目(F201434);黑龍江大學(xué)研究生創(chuàng)新科研項目重點項目(YJSCX2016-018HLJU)。 秦琦冰(1990—),男,山東濰坊人,碩士研究生,主要研究方向:機器學(xué)習(xí)、數(shù)據(jù)倉庫、數(shù)據(jù)挖掘; 譚龍(1971—),男,黑龍江哈爾濱人,副教授,碩士,CCF會員,主要研究方向:機器學(xué)習(xí)、傳感器網(wǎng)絡(luò)、數(shù)據(jù)挖掘。 1001- 9081(2017)02- 0329- 06 10.11772/j.issn.1001- 9081.2017.02.0329 TP311.13 A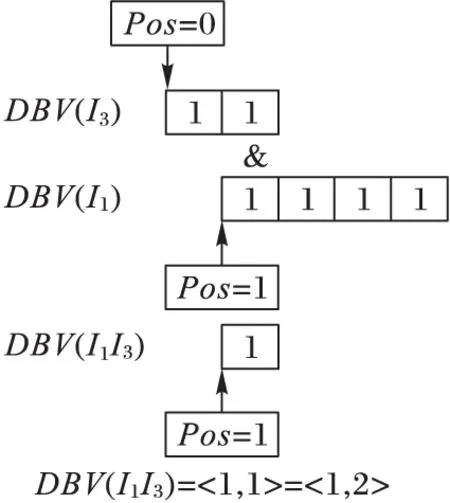
2 WUG_TK
3 實驗與結(jié)果分析
4 結(jié)語
猜你喜歡
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42大眾投資指南(2021年35期)2021-02-16 01:06:26小哥白尼(趣味科學(xué))(2019年6期)2019-10-10 01:01:50電力與能源(2017年6期)2017-05-14 06:19:37財經(jīng)(2017年2期)2017-03-10 14:35:35發(fā)明與創(chuàng)新(2016年38期)2016-08-22 03:02:52太空探索(2016年5期)2016-07-12 15:17:55財經(jīng)(2016年15期)2016-06-03 07:38:02財經(jīng)(2016年3期)2016-03-07 07:44:46財經(jīng)(2016年6期)2016-02-24 07:41:51
