一種改進的SVM增量學(xué)習(xí)算法研究
2017-04-21 14:28:05黃建校邵曦
無線互聯(lián)科技 2017年3期
黃建校 邵曦

摘要:通過對訓(xùn)練樣本集的幾何特征和機器學(xué)習(xí)迭代過程中支持向量的變化情況分析,文章提出一種改進的基于KKT條件和殼向量的SVM增量學(xué)習(xí)算法。算法使用包含原支持向量集的小規(guī)模擴展集——殼向量,將其作為新一輪迭代的初始訓(xùn)練樣本集。同時,基于樣本是否違背KKT6件的錯誤驅(qū)動策略,對新增的大量樣本進行篩選,以此得到更加精簡有效的新增樣本集。實驗結(jié)果表明,與傳統(tǒng)的增量學(xué)習(xí)算法相比,改進的算法在模型訓(xùn)練的收斂速度和對未知樣本集的分類準(zhǔn)確度方面都有明顯的提高。
關(guān)鍵詞:SVM;殼向量;KKT條件;增量學(xué)習(xí)
1.SVM算法研究背景
隨著互聯(lián)網(wǎng)時代和多媒體信息技術(shù)的飛速發(fā)展,大量的網(wǎng)絡(luò)資源也隨之產(chǎn)生,其中也包括受眾面非常廣泛的數(shù)字音樂。面對數(shù)量龐大和風(fēng)格多樣的數(shù)字音樂,一個非常重要的需求是準(zhǔn)確而快速地查詢出符合用戶喜好的音樂。為此,人們需要設(shè)計一個高效快速的音樂分類系統(tǒng)。
針對音樂分類,許多研究者已經(jīng)提出了各自的方法,大體可以分為3類:一是在音樂特征提取的選擇和特征向量的維度上作改進;二是在分類算法的選擇上作改進;三是在多分類問題的解決方法上作改進。其中,研究最多的是對分類算法的改進。而在這些研究當(dāng)中,應(yīng)用最為廣泛的技術(shù)就是支持向量機(Support Vector Machine,SVM)。
雖然經(jīng)典的SVM算法應(yīng)用廣泛,但其依然存在一定的局限性。由于SVM是一種監(jiān)督式的學(xué)習(xí)算法,它不具備增量學(xué)習(xí)的能力,只能使用少量給定的己標(biāo)注的樣本作為訓(xùn)練樣本進行訓(xùn)練,以此來得到分類模型。然而,在現(xiàn)實應(yīng)用中,數(shù)字音樂的數(shù)據(jù)量通常呈現(xiàn)出在線式增長的特點,對這樣級別數(shù)據(jù)量的音樂樣本進行類別標(biāo)注,無論是在人力上還是在時間成本上,都是不現(xiàn)實的。因此尋找更高效率的svM增量學(xué)習(xí)算法,篩選可以涵蓋大量未標(biāo)注樣本所含信息量的代表性樣本進行標(biāo)注來改善分類模型的訓(xùn)練速度和分類精度,具有十分重要的意義。
從提高增量學(xué)習(xí)訓(xùn)練速度的角度出發(fā),sved等基于SVM提出一種簡單增量學(xué)習(xí)算法,該算法使用能夠代表初始樣本集但數(shù)量較小的支持向量進行訓(xùn)練。然而,該算法完全忽略了非支持向量,而有些非支持向量可能攜帶著由于訓(xùn)練前期樣本不夠豐富而沒有顯性表現(xiàn)出來的重要分類信息。申曉勇等通過分析訓(xùn)練樣本的特點,結(jié)合KKT條件,提出一種計數(shù)器淘汰算法,有效地去除了少量無用樣本,但該算法在增量學(xué)習(xí)的過程中需要對所有的歷史訓(xùn)練樣本進行學(xué)習(xí),這將在很大程度上增加存儲空間成本,同時也會使得增量學(xué)習(xí)的速度減慢。文獻使用訓(xùn)練樣本到類樣本中心點的距離和該樣本到分類決策平面的距離的比值,無異于改善分類模型性能的樣本剔除,但算法存在一定的主觀性,分類模型的穩(wěn)定性無法得到保證。
研究發(fā)現(xiàn),不同類別的訓(xùn)練樣本在空間中呈現(xiàn)聚類分布,并且類樣本集的邊緣樣本相比支持向量,包含更多的分類信息,這類樣本被稱之為殼向量。文獻基于樣本的幾何分布特點,使用訓(xùn)練樣本集中的殼向量和類與類之間邊界上的殼向量作為初始訓(xùn)練樣本集參與訓(xùn)練。文獻提出一種基于殼向量的增量式快速增量學(xué)習(xí)算法,該算法使得求解二次優(yōu)化問題的計算量大大減少,提高了增量學(xué)習(xí)的收斂速度。但利用該算法只適用于線性空間中的兩分類問題,不適合在現(xiàn)實中推廣使用。
本文算法在總結(jié)分析前人學(xué)習(xí)算法的基礎(chǔ)上,提出一種改進的SVM增量學(xué)習(xí)算法,將KKT條件和殼向量相結(jié)合,分別從新增樣本集和初始訓(xùn)練樣本集的角度,降低學(xué)習(xí)過程中的存儲空間占有量,提高用于模型訓(xùn)練的樣本集的豐富性和可靠性,從而改善分類模型的收斂速度和分類性能。
2.SVM相關(guān)理論
SVM是在嚴(yán)謹(jǐn)?shù)慕y(tǒng)計學(xué)習(xí)理論的基礎(chǔ)上發(fā)展起來的一種用于解決分類問題的機器學(xué)習(xí)算法,該算法將結(jié)構(gòu)風(fēng)險最小化原則和統(tǒng)計學(xué)習(xí)當(dāng)中的VC維理論相結(jié)合,采用核函數(shù)映射的方式實現(xiàn)非線性的SVM,通過尋找使得分類間隔最大化的最優(yōu)超平面,實現(xiàn)對不同類別樣本的分類,在解決小樣本、非線性以及高維模式識別等問題中效果顯著。相比傳統(tǒng)的分類學(xué)習(xí)方法有著更好的學(xué)習(xí)性能和泛化能力,被廣泛應(yīng)用于文本分類、目標(biāo)識別和時間序列預(yù)測等領(lǐng)域U5471。
對于線性二分類問題,假設(shè)給定類別標(biāo)簽的訓(xùn)練樣本集為(X1,y1),(x2,y2),…(xn,yn),xi∈Rd,yi∈{+1,-1}。其中,n為訓(xùn)練樣本集的總數(shù),d樣本特征的維度,y樣本的類別標(biāo)號。尋找最優(yōu)超平面可以歸納為求解平面f(x)=wx+b的最優(yōu)解,使得該平面能夠正確地將兩類已知樣本分離開,同時要求如圖1所示的分類間隔Margin最大化。
定理2若新增樣本中存在某些違反KKT條件的樣本,則這些違反KKT條件的樣本中肯定存在新的支持向量;若新增樣本中不存在違反KKT條件的樣本,則新增樣本中肯定不存在新的支持向量。
定理3若新增樣本中存在違反KKT條件的樣本,則上次訓(xùn)練結(jié)果中的非支持向量有可能轉(zhuǎn)化為支持向量。
根據(jù)上述定理可知,yif(xi)<1是新增樣本(xi,yi)違背KKT條件的充要條件。若新增樣本滿足原分類器對應(yīng)的KKT條件,那么該新增樣本的加入對原支持向量集不會產(chǎn)生影響,也不會改善原分類器的性能,可舍棄該樣本。反之,如果新增樣本不滿足當(dāng)前分類器對應(yīng)的KKT條件,那么該新增樣本將使得原支持向量集發(fā)生變化,應(yīng)當(dāng)將其加入到下一輪的模型迭代中參與訓(xùn)練。通過這種方式,新一輪的迭代訓(xùn)練只需考慮不滿足KKT條件的新增樣本,從而大大減少對新增樣本的學(xué)習(xí)時間,同時又不會影響新增樣本集原本所包含的分類信息。
3.2利用殼向量代替支持向量
根據(jù)支持向量機的原理可知,在訓(xùn)練分類器的過程中,所利用的是對分類器的性能起決定性的支持向量。而在SVM增量學(xué)習(xí)的過程中,支持向量會隨著新增樣本的加入發(fā)生變化。
原支持向量可能轉(zhuǎn)變?yōu)榉侵С窒蛄浚侵С窒蛄恳部赡苻D(zhuǎn)變?yōu)橛兄诟纳品诸惼餍阅艿闹С窒蛄俊6鴤鹘y(tǒng)的SVM增量學(xué)習(xí)算法,僅僅利用了支持向量,對于可能包含重要分類信息的非支持向量則完全舍棄,這將在很大程度上影響分類器的訓(xùn)練收斂速度和分類準(zhǔn)確率。因此,在增量學(xué)習(xí)的過程中,新一輪的迭代訓(xùn)練樣本集應(yīng)該將歷史訓(xùn)練樣本集中的非支持向量考慮在內(nèi)。
根據(jù)對訓(xùn)練樣本集幾何分布特征的分析,發(fā)現(xiàn)最有可能轉(zhuǎn)變?yōu)橹С窒蛄康臉颖臼穷悩颖镜倪吔绺浇臉颖荆疵總€類對應(yīng)的樣本集中位于幾何邊緣的樣本。這種特征的樣本,就是本文算法所用到的殼向量。它不僅保留了原來的支持向量,而且還包括了最可能轉(zhuǎn)變?yōu)橹С窒蛄康姆侵С窒蛄浚@使得原本被舍棄的可能包含重要分類信息的樣本得以保留。獲取殼向量的方法如下:首先求出訓(xùn)練樣本集中各類別樣本對應(yīng)的最小超求體,然后以超球面上的點作為初始的殼向量,通過迭代方法求出其極點集合,最后從所得集合中舍棄多余的內(nèi)點,從而得到訓(xùn)練樣本集所對應(yīng)的殼向量。
3.3算法描述
在傳統(tǒng)的SVM增量學(xué)習(xí)算法中,每一輪的迭代訓(xùn)練只考慮支持向量,而對于可能轉(zhuǎn)變?yōu)樾碌闹С窒蛄康姆侵С窒蛄坎扇×巳P丟棄的措施,所訓(xùn)練得到的分類器的泛化性能較差。同時,該算法對于新增樣本的選擇策略是將其全部加入到原訓(xùn)練集,這將大大增加分類器訓(xùn)練的時間成本。基于上述不足之處,本文綜合考慮原訓(xùn)練樣本集和新增樣本集的特點,使用包含更多樣本分類信息的殼向量代替支持向量,它不僅包含了原來的支持向量集,而且保留了最有可能轉(zhuǎn)變?yōu)樾碌闹С窒蛄康姆侵С窒蛄俊M瑫r,根據(jù)樣本是否違背KKT條件,從新增樣本集中篩選出包含更多分類信息量的樣本,以此減少模型訓(xùn)練時間。該算法使得訓(xùn)練得到的分類器在性能和訓(xùn)練時間上都能得到較好的優(yōu)化。具體算法如下:
(1)設(shè)初始訓(xùn)練樣本集為Traino,對應(yīng)的初始殼向量為Hullo,第k次增量樣本集為Addk,第k次增量學(xué)習(xí)中違背KKT條件的增量樣本集為Addk-violateo其中,k=l,2…n,n為加入增量樣本的最大次數(shù)。
(2)利用上述求解殼向量的方法,求解初始訓(xùn)練樣本集Traino中各類樣本對應(yīng)的殼向量并求并集,得到Traino的殼向量Hullo。
(3)將殼向量Hullo作為新的訓(xùn)練樣本集,使用標(biāo)準(zhǔn)SVM算法訓(xùn)練得到分類模型Modelo。
加入新增樣本集Addk,如果k>,2,則算法終止;否則轉(zhuǎn)
(3)。
(4)根據(jù)分類模型Modelk-1,從Addk中選擇違背KKT條件的增量樣本,確定參與第k次增量學(xué)習(xí)的新增樣本集Addk violate。
(5)如果Addk-violateo=φ,置HUllk=HUllk-1,Modelk=Modelk-1,k=-k+l,轉(zhuǎn)(3);否則轉(zhuǎn)(6)。
(6)對殼向量Hullk=Hullk-1UAddkk-violateo進行增量學(xué)習(xí),得到新的分類模型Modelk,并置k=-k+l,轉(zhuǎn)(3)。
4.實驗結(jié)果與分析
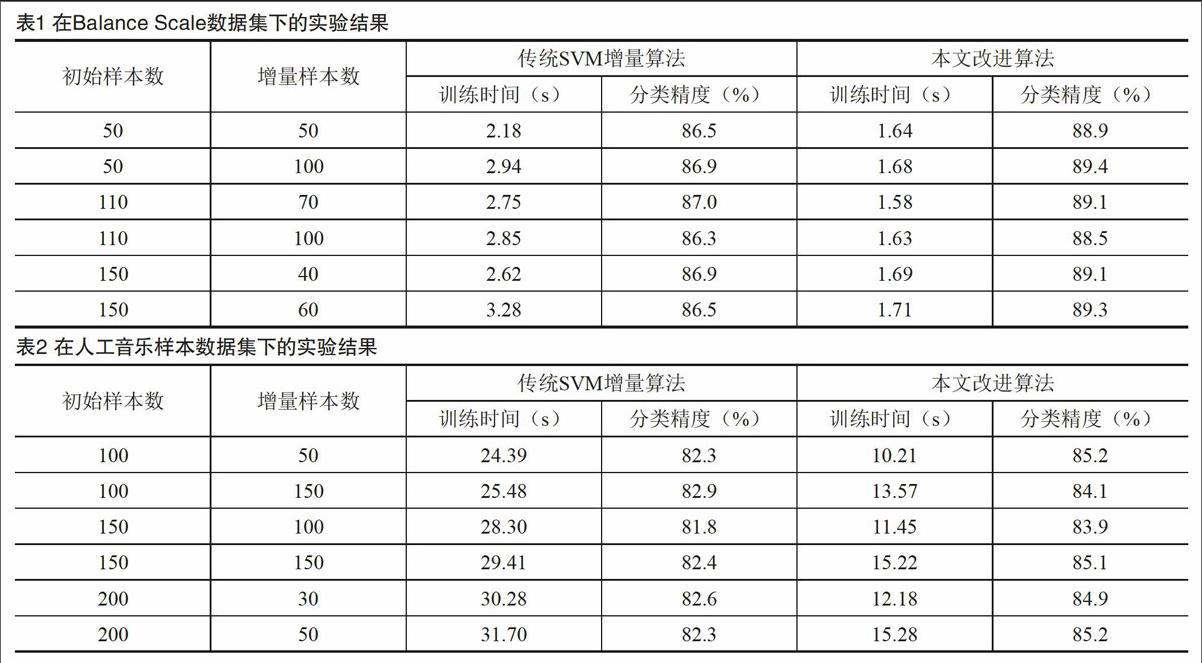
為了驗證本文算法的可行性和有效性,本節(jié)分別從收斂速度和分類準(zhǔn)確率兩個角度,將本文提出的改進的增量學(xué)習(xí)算法與經(jīng)典的SVM增量學(xué)習(xí)算法進行對比分析。實驗所用的數(shù)據(jù)集為UCI數(shù)據(jù)庫中的Balance Scale數(shù)據(jù)集和人工采集的音樂樣本數(shù)據(jù)集。
Balance scale數(shù)據(jù)集:共有625個樣本,樣本特征維數(shù)為4,樣本類別數(shù)為3,訓(xùn)練樣本數(shù)為470,測試樣本數(shù)為155。
人工采集的音樂樣本數(shù)據(jù)集:共有3 301個樣本,樣本特征維數(shù)為100,樣本類別數(shù)為5,訓(xùn)練樣本數(shù)為2 500,測試樣本數(shù)為801。
實驗采用的分類環(huán)境為SVMlight,并根據(jù)實驗數(shù)據(jù)的特點,選用徑向基核函數(shù)。實驗所需的初始訓(xùn)練樣本集通過聚類算法生成。為排除單次實驗結(jié)果的偶然性,實驗將10次同樣條件下的運行結(jié)果取平均值作為該條件下的實驗結(jié)果。兩個數(shù)據(jù)集的實驗結(jié)果如表1-2所示。
由表1-2所示的實驗結(jié)果可知,與經(jīng)典的SVM增量學(xué)習(xí)算法相比,本文算法的分類精度明顯高于前者,該結(jié)果表明,相比之前的支持向量,殼向量包含了更多有用的分類信息。同時,本文算法的訓(xùn)練時間相比前者縮短了接近一半。這也說明,選擇違背KKT條件的新增樣本參與訓(xùn)練的方法是可行的,不僅縮短了訓(xùn)練時間,而且無用樣本的剔除也進一步改善了模型的分類性能。以上結(jié)果驗證了本文算法的可行性和有效性。
5.結(jié)語
本文基于支持向量機的特性和前人的研究成果,提出一種改進的增量學(xué)習(xí)算法。該算法綜合考慮歷史訓(xùn)練樣本和新增訓(xùn)練樣本的特點,使用殼向量代替支持向量,以此來保留更多的歷史分類信息。同時利用KKT條件對新增的訓(xùn)練樣本集進行約簡,只保留最有可能轉(zhuǎn)變?yōu)橹С窒蛄康臉颖緟⑴c新一輪的增量訓(xùn)練。實驗結(jié)果表明,相比經(jīng)典的SVM增量學(xué)習(xí)算法,該算法具備較短的訓(xùn)練時間和較高的分類精度,并且能夠保證良好的推廣效果。
