基于度量學習的服裝圖像分類和檢索
2017-04-24 10:25:08包青平孫志鋒
計算機應用與軟件 2017年4期
包青平 孫志鋒
(浙江大學電氣工程學院 浙江 杭州 310058)
基于度量學習的服裝圖像分類和檢索
包青平 孫志鋒
(浙江大學電氣工程學院 浙江 杭州 310058)
在服裝圖像分類和檢索問題上,由于服裝花紋樣式的多樣性和圖像中不同環境背景的影響,普通卷積神經網絡的辨識能力有限。針對這種情況,提出一種基于度量學習的卷積神經網絡方法,其中度量學習基于triplet loss實現,由此該網絡有參考樣本、正樣本和負樣本共三個輸入。通過度量學習可以減小同類別特征間距,增大不同類別特征間距,從而達到細分類的目的。此外把不同背景環境下的圖像作為正樣本輸入訓練網絡以提高抗干擾能力。在服裝檢索問題上,提出融合卷積層特征和全連接層特征的精細檢索方法。實驗結果表明,度量學習的引入可以增強網絡的特征提取能力,提高分類準確性,而基于融合特征的檢索可以保證結果的精確性。
服裝 分類 檢索 多標簽 度量學習
0 引 言
近年來,網上購物越來越流行,網購交易量也逐年增加,而服裝網絡零售是其中第一大類目,占比約25%。服裝電子商務的快速發展,促進了服裝圖像分類、檢索技術的進步。目前在國內各大電商購物平臺,比如淘寶、京東等,主要是通過關鍵字或文本來檢索圖像。該技術要求事先對服裝圖像進行細分類并打上相應的標簽。但是隨著服裝圖像數量的爆發式增長,其缺點越來越顯著。首先,關鍵字只能描述易于提取的語義特征,并不能全面地反映服裝的特征;其次,人工標注工作量大且主觀性誤差[1]。隨著圖像處理技術的發展,出現了以圖搜圖技術,即通過對圖像特征的提取,獲得特征表示,然后進行相似性度量或聚類,從而獲得檢索和分類結果。而基于圖像處理技術的服裝圖像檢索和商品推薦也獲得了越來越多的關注[2-4]。
傳統圖像特征描述方法包括GIST特征[5]、SIFT特征[6]、HOG特征[7]等。在背景、光照等的影響下,應用這些方法在服裝圖像分類和檢索中往往準確率不高或者方法過于復雜。Bossard等[8]融合HOG、SURF、LBP特征,采用遷移森林進行服裝圖像多類別分類,只取得41.36%的準確率。Liu等[3]使用人體部位檢測器檢測圖像中人物主體的關鍵區域,如肩、膝蓋等部位,然后提取和融合這些區域的HOG、LBP、顏色矩、顏色直方圖等特征,以此進行圖像檢索。
近年來,深度學習取得了突破性的進展,其中卷積神經網絡CNN(convolutional neural network)已成為圖像領域的研究熱點。Krizhevsky等[9]提出的深層CNN模型在ILSVRC2012中取得了巨大的突破,并引發了CNN研究的熱潮。本文深入分析了使用CNN進行服裝圖像的多標簽細分類和檢索,并引入基于triplet loss[10-11]的度量學習以提高網絡特征提取能力,從而提高分類準確度,之后融合該網絡卷積層和全連接層的特征輸出進行圖像檢索。
1 卷積神經網絡
CNN是為識別二維形狀而設計的一種多層感知器,是深度神經網絡的一種。CNN通常由多個卷積層、池化層和全連接層組成。
卷積層通常用于提取圖像的局部特征,如邊緣信息等。卷積層中采用了權值共享,從而大大減少了權值的數量,降低了網絡模型的復雜度。卷積層的輸入為:
z(l+1)=w(l)x(l)+b(l)
(1)
輸出為:
x(l+1)=f(z(l))
(2)
式(1)中w(l)為第1層的卷積核,b(l)為偏置,式(2)中f(·)為激活函數,目前普遍使用的激活函數是ReLU函數[12],使用該激活函數主要是能避免梯度消失問題。
池化層仿照人的視覺系統進行降維(下采樣),抽象圖像特征表示,使得CNN具有一定的平移和旋轉不變性。根據下采樣方式的不同,可以分為均值池化、最大值池化、隨機池化三種[13],在分類任務中采用較多的是最大值池化。
全連接層通常用于輸出,根據不同的目標函數連接相應的損失層,比如分類任務中,通常會連接Softmax分類器。
2 服裝圖像分類
在使用CNN進行圖像分類時,一般包括圖片預處理、網絡訓練和訓練參數調優等步驟,其總體流程如圖1所示。其中預處理主要是把圖像變化為符合CNN輸入需求的標準圖像。在誤差反向傳播過程中,通常使用隨機梯度下降法SGD(stochasticgradientdescent)進行參數更新。通過多次的前向和反向傳播,不斷地更新卷積層、全連接層等的參數,使得網絡逐步逼近最優解。
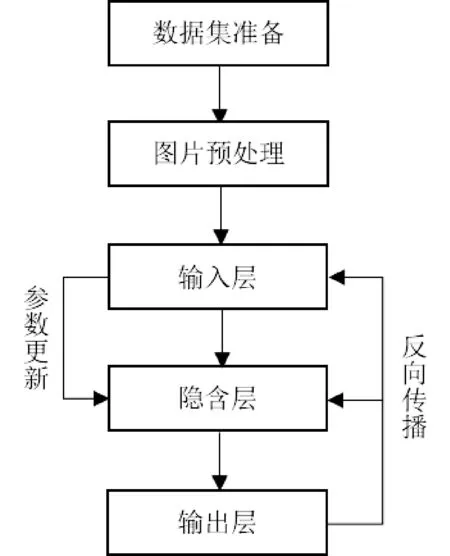
圖1 CNN網絡訓練流程
2.1 多標簽分類
常見的CNN網絡通常用于單標簽分類,而我們所要處理的服裝圖像通常有多個語義屬性,比如花紋、領型等,單標簽學習并不適用,因此需要采用多標簽[14]或多任務學習[15]。本文采用了多標簽學習,網絡結構如圖2所示。輸入圖像大小為256×256,提取該圖像227×227的子塊或其鏡像作為CNN的輸入。網絡淺層為3個卷積模塊(包括卷積層和池化層),結構和AlexNet[9]中的定義一致。由于各個屬性標簽之間沒有明顯的相關關系,因此全連接層FC2層由多個獨立的、平行的子層組成,各子層連接相關屬性的Softmax分類器,所有的FC2子層共享FC1的輸出。
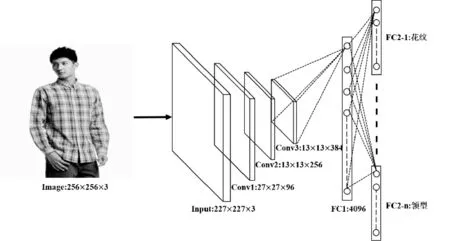
圖2 多標簽學習網絡結構
2.2 度量學習
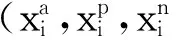

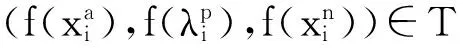
(3)
其中T是所有三元組的集合,α為閾值參數。從而損失函數tripletloss可表達為:
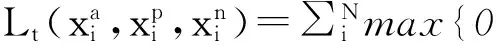
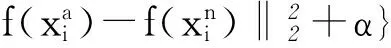
(4)
進一步可以得到損失函數的偏導數如下:
(5)
(6)
(7)
從tripletloss的定義可以發現,該損失函數除了可以增大不同類別間的距離之外,還減小了同類間的距離,因此可以提取更精細的特征。
在本文的服裝圖像分類和檢索問題中,環境背景、光照等因素往往會影響卷積神經網絡的效果,因此可以選擇不同場景下同類別的圖像作為正樣本輸入進行訓練,這樣可以增強網絡的特征提取能力。本文最終使用的CNN網絡結構如圖3所示,由于有3個輸入圖像,因此有3個平行的共享參數的CNN網絡。這3個CNN網絡的FC1的輸出,經過L2規范化后輸入tripletloss層。因此網絡總的損失函數為:
L=ωLtriple+(1-ω)Lsoftmax
(8)
參數ω表示tripletloss所占比重。
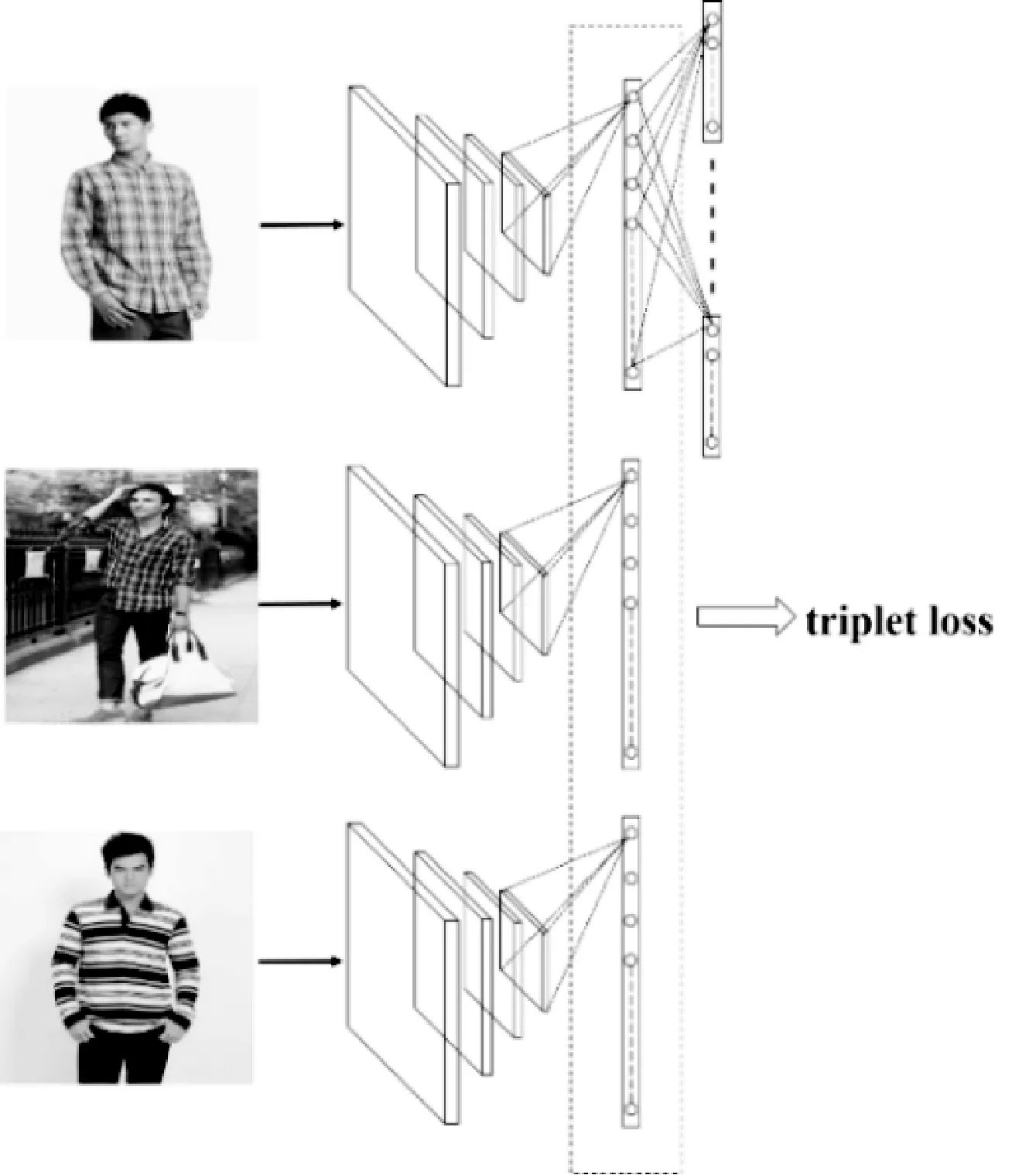
圖3 加入triplet loss的CNN網絡
3 服裝圖像檢索
通常訓練好的CNN網絡具備良好的特征提取能力,因此可以使用CNN的分類預測結果和隱含層的特征向量進行圖像檢索,檢索流程如圖4所示。在神經網絡中,深層特征往往代表圖像總體的、抽象的特征,而淺層特征則更多地代表具體的局部特征。因此選擇不同的隱含層輸出作為特征向量進行檢索可能會得到不同的結果。
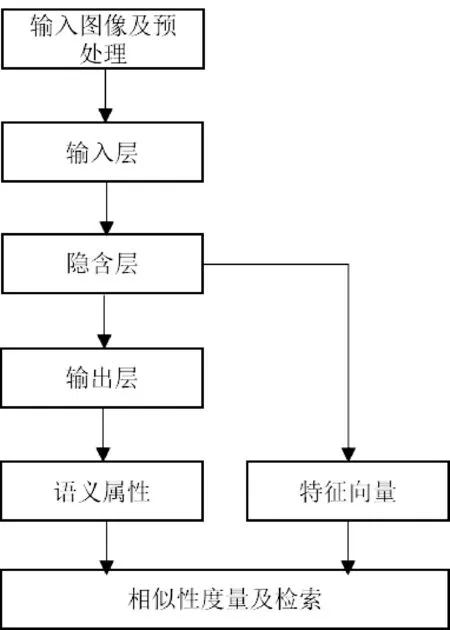
圖4 使用CNN進行圖像檢索的流程
在服裝圖像檢索時,以往通常根據服裝語義屬性進行快速檢索[18],但是語義屬性往往是抽象屬性,并不能描述一些細致的特征,因此若能同時考慮圖像細致特征,則可以提高檢索的精確度。本文采取融合卷積層Conv3和全連接層FC1的輸出作為特征向量進行檢索,其中Conv3的輸出是13×13×384=64 896維,FC1的輸出是4 096維,融合后是68 992維,之后進行降維處理用于檢索。
4 實驗和分析
4.1 數據集
實驗所用的服裝圖像均采集自互聯網,總共28 057張,其中22 057張用于訓練,剩下6 000張用于檢測。數據集中,大約80%采集自淘寶、亞馬遜等購物網站,這些圖像沒有復雜的背景,人物主體突出;其余20%圖像來自社交網絡,會有不同的背景和光照條件。本文主要對服裝的5類語義屬性進行分析,如表1所示,其中上身服裝的主要屬性有圖案、袖子長短、領口形狀,下身服裝屬性有形狀和長短。

表1 服裝的語義屬性
4.2 服裝圖像分類
在使用tripletloss的網絡中,如何選擇三元組樣本關系到網絡的整體性能。若訓練集大小為n,則所有可能的三元組選擇為n3種。如果隨機選取的話,則可能大部分選中的三元樣本的損失函數值為0,從而在后向傳播中對參數的更新起的作用很小[19],因此要盡可能選取對tripletloss有貢獻的樣本。本文中采取了如下方法:每迭代5 000次,重新采樣生成三元組的方法。采樣時,首先使用當前的網絡獲取每張圖像的特征表達;對于某張參考圖像,根據式(9)計算概率來選取3張同類別的正樣本圖像,從式子的定義可以發現特征間距越大的同類圖像越容易被選中。采取隨機選擇而不是直接選擇特征間距最大的,是因為這樣可以減少可能存在的噪聲樣本所帶來的影響。此外還需保證正樣本中有來自于不用的環境場景的圖像。對于負樣本的選取,簡單地選擇不屬于本類的特征距離最近的3張圖像。
(9)
其中Pi,j表示對于第i張圖像,選中同類別的第j張圖像作為正樣本的概率,αi,j表示第i、j兩張圖像特征向量的歐氏距離。
在訓練過程中,學習速率的初始值設為0.01,每經過10 000次迭代將學習速率減小為原來的1/10,動量設置為0.9,權重衰減系數設置為0.000 2。在引入tripletloss進行訓練時,設置式(3)中的閾值參數α設置為0.8,式(8)中的參數ω設置為0.3,訓練總共迭代20 000次。圖5對比了兩種網絡結構的訓練過程,其中ML-CNN表示多標簽網絡,tML-CNN表示加入了tripletloss的多標簽網絡。從圖中可以發現ML-CNN收斂速度比tML-CNN的快,迭代6 000次后已經收斂。另外,由于在tML-CNN訓練過程中要重新采樣生成三元組,因此tripletloss在其后期迭代中起主要作用。從測試準確率中也可看出,前5次測試時ML-CNN和tML-CNN的準確率相當,之后ML-CNN的測試準確率基本保持穩定,而tML-CNN的測試準確率緩慢上升直至穩定。
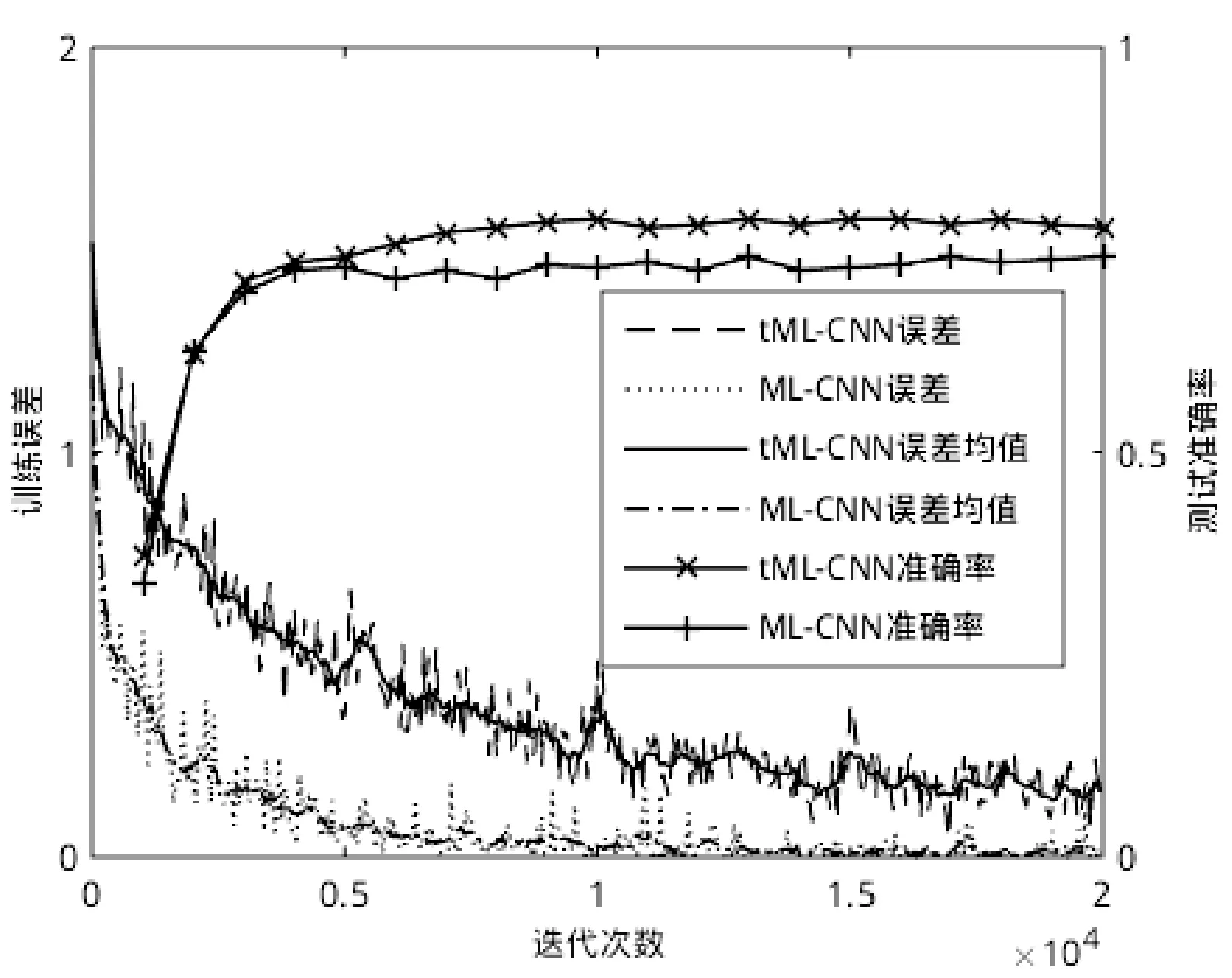
圖5 網絡訓練過程
表2為各語義屬性的最終分類結果,從表中可以發現多標簽網絡由于要同時識別多個屬性,準確性往往比單標簽的要低,而加入tripletloss之后可以提高多標簽網絡的分類準確性,對各個屬性的分類準確性均有4%左右的提升。
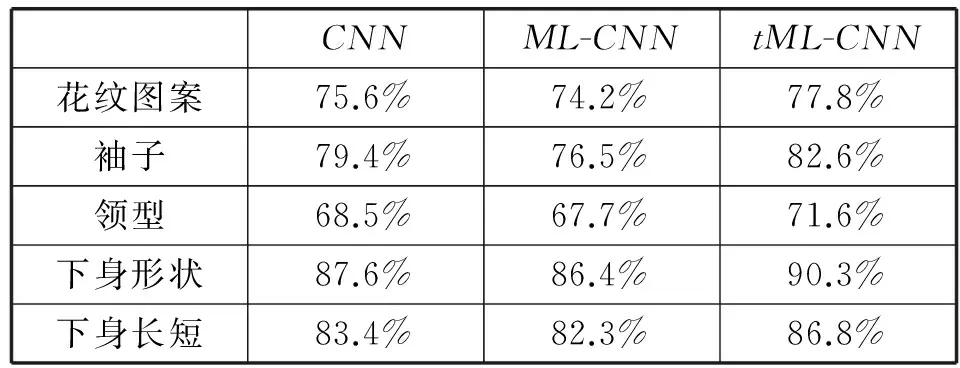
表2 服裝屬性分類結果
4.3 服裝圖像檢索
我們構建了一個含15 000張圖像的服裝圖像數據庫,每張圖像都標注了語義屬性,然后把每張圖像輸入到訓練好的網絡中,提取Conv3和FC1的特征輸出,之后進行PCA訓練,降維到1 024維。檢索圖像時,為了加快檢索速度,首先選取有相同語義屬性的服裝,然后比較待查圖像和數據庫中圖像的特征向量的距離來獲得檢索結果。實驗平臺下檢索一張圖像花費約1.5s,其中大部分時間用于特征向量的比較上。
表3說明了以不同的隱含層輸出特征進行檢索的結果,其中Conv3&FC1表示融合Conv3和FC1層的特征,Top-k(表中k分別取5和10)準確率表示前k個檢索結果中包含有待檢索圖像的準確率。從表中可以看出融合Conv3和FC1特征比單獨采用它們進行檢索的準確率要高,有近3%的提升。
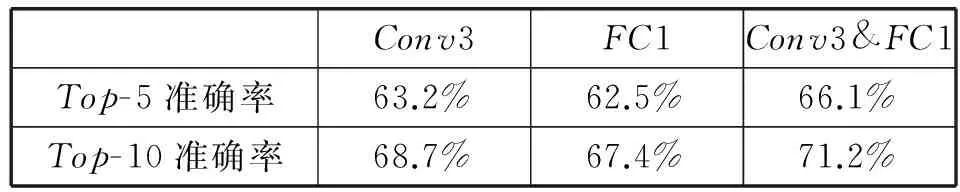
表3 服裝屬性分類結果
此外由于檢索時采用了使用語義屬性來縮小檢索范圍以加快檢索的方法,因此若待檢索圖像的語義屬性預測錯誤,那么檢索結果就會出錯。因此對于分類準確率不高的語義屬性在檢索時可以不予考慮,比如表2中,領型的分類準確性相對較低,那么在檢索時可以選擇忽略這個語義屬性。
服裝圖像檢索結果示例如圖6所示,從圖中可以看到檢索結果不僅體現了全局的語義屬性信息,而且包含了局部了紋理信息。

圖6 服裝圖像檢索示例(每行第一張圖片為輸入,后五張為檢索結果)
5 結 語
本文提出了一種基于度量學習的卷積神經網絡方法用于服裝圖像的分類和檢索。該網絡使用了多標簽分類,可以同時識別圖像中服裝的多個屬性。基于tripletloss的度量學習的引進可以增強網絡的特征提取能力,提高分類準確性。對于服裝圖像檢索問題,使用了融合了卷積層輸出和全連接層輸出的特征向量,同時保留了服裝的整體和局部信息。在檢索過程中,首先定位有相同屬性的圖像,然后比較各圖像特征向量間的相似性,從而得到檢索結果。
[1] 盧興敬.基于內容的服裝圖像檢索技術研究及實現[D].哈爾濱:哈爾濱工業大學,2008.
[2]ManfrediM,GranaC,CalderaraS,etal.Acompletesystemforgarmentsegmentationandcolorclassification[J].MachineVisionandApplications,2014,25(4):955-969.
[3]LiuS,SongZ,LiuG,etal.Street-to-shop:Cross-scenarioclothingretrievalviapartsalignmentandauxiliaryset[C]//ComputerVisionandPatternRecognition(CVPR),2012IEEEConferenceon.IEEE,2012:3330-3337.
[4]JagadeeshV,PiramuthuR,BhardwajA,etal.Largescalevisualrecommendationsfromstreetfashionimages[C]//Proceedingsofthe20thACMSIGKDDInternationalConferenceonKnowledgeDiscoveryandDataMining.ACM,2014:1925-1934.
[5]OlivaA,TorralbaA.Modelingtheshapeofthescene:aholisticrepresentationofthespatialenvelope[J].InternationalJournalofComputerVision,2001,42(3):145-175.
[6]LoweDG.Distinctiveimagefeaturesfromscale-invariantkeypoints[J].InternationalJournalofComputerVision,2004,60(2):91-110.
[7]DalalN,TriggsB.Histogramsoforientedgradientsforhumandetection[C]//ComputerVisionandPatternRecognition,2005IEEEComputerSocietyConferenceon.IEEE,2005:886-893.
[8]BossardL,DantoneM,LeistnerC,etal.Apparelclassificationwithstyle[C]//11thAsianConferenceonComputerVision.Springer,2012:321-335.
[9]KrizhevskyA,SutskeverI,HintonGE.ImageNetClassificationwithDeepConvolutionalNeuralNetworks[C]//AdvancesinNeuralInformationProcessingSystems25,2012:1106-1114.
[10]HofferE,AilonN.Deepmetriclearningusingtripletnetwork[C]//3rdInternationalWorkshoponSimilarity-BasedPatternAnalysisandRecognition.SpringerInternationalPublishing,2015:84-92.
[11]SchroffF,KalenichenkoD,PhilbinJ.FaceNet:Aunifiedembeddingforfacerecognitionandclustering[C]//Proceedingsofthe2015IEEEConferenceonComputerVisionandPatternRecognition,2015:815-823.
[12]MaasAL,HannunAY,NgAY.Rectifiernonlinearitiesimproveneuralnetworkacousticmodels[C]//Proceedingsofthe30thInternationalConferenceonMachineLearning(ICML),2013:1-6.
[13]ZeilerMD,FergusR.Stochasticpoolingforregularizationofdeepconvolutionalneuralnetworks[DB].arXivpreprintarXiv:1301.3557,2013.
[14]WeiY,XiaW,HuangJ,etal.CNN:Single-labeltomulti-label[DB].arXivpreprintarXiv:1406.5726,2014.
[15]AbdulnabiAH,WangG,LuJ,etal.Multi-taskCNNmodelforattributeprediction[J].IEEETransactionsonMultimedia,2015,17(11):1949-1959.
[16]ChopraS,HadsellR,LeCunY.Learningasimilaritymetricdiscriminatively,withapplicationtofaceverification[C]//ComputerVisionandPatternRecognition,2005IEEEComputerSocietyConferenceon,2005:539-546.
[17]HadsellR,ChopraS,LeCunY.Dimensionalityreductionbylearninganinvariantmapping[C]//ComputerVisionandPatternRecognition,2006IEEEComputerSocietyConferenceon.IEEE,2006:1735-1742.
[18]LinK,YangHF,LiuKH,etal.Rapidclothingretrievalviadeeplearningofbinarycodesandhierarchicalsearch[C]//Proceedingsofthe5thACMInternationalConferenceonMultimediaRetrieval.ACM,2015:499-502.
[19]WangJ,SongY,LeungT,etal.Learningfine-grainedimagesimilaritywithdeepranking[C]//ComputerVisionandPatternRecognition(CVPR),2014IEEEConferenceon.IEEE,2014:1386-1393.
CLOTHING IMAGE CLASSIFICATION AND RETRIEVAL BASED ON METRIC LEARNING
Bao Qingping Sun Zhifeng
(CollegeofElectricalEngineering,ZhejiangUniversity,Hangzhou310058,Zhejiang,China)
On the problem of clothing image classification and retrieval, the general convolutional neural network has limited ability to identify because of diverse patterns and different backgrounds in image. To solve this problem, a convolution neural network method based on metric learning is proposed, in which the metric learning is based on the triplet loss, and the network has three inputs: the reference sample, the positive sample and the negative sample. By means of metric learning, it is possible to reduce the intra-class feature distance and increase the inter-class feature distance, so as to achieve the fine-grained classification. In addition, the images in different backgrounds are input into the training network as positive samples to improve the anti-interference ability. On the problem of clothing retrieval, a fine-grained retrieval method is proposed, which combines features of convolutional layers and fully-connected layers. The experimental results show that the introduction of metric learning can enhance the feature extraction ability of the network and improve the accuracy of classification, and the retrieval based on combined features can ensure the accuracy of the results.
Clothing Classification Retrieval Multi-label Metric learning
2016-03-17。包青平,碩士生,主研領域:深度學習。孫志鋒,副教授。
TP391.4
A
10.3969/j.issn.1000-386x.2017.04.043
猜你喜歡
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
開放教育研究(2020年2期)2020-03-31 01:54:14
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
現代語文(2016年21期)2016-05-25 13:13:44
大連民族大學學報(2015年2期)2015-02-27 08:28:11
