基于語(yǔ)言現(xiàn)象的文本蘊(yùn)涵識(shí)別
2017-04-26 01:39:40馮文賀劉茂福
中文信息學(xué)報(bào) 2017年1期
任 函,馮文賀,劉茂福,萬(wàn) 菁
(1.廣東外語(yǔ)外貿(mào)大學(xué) 語(yǔ)言工程與計(jì)算實(shí)驗(yàn)室,廣東 廣州 510006;2.武漢大學(xué) 湖北語(yǔ)言與智能信息處理研究基地,湖北 武漢 430072;3.武漢科技大學(xué) 計(jì)算機(jī)學(xué)院,湖北 武漢 430065;4.廣東外語(yǔ)外貿(mào)大學(xué) 詞典研究中心,廣東 廣州 510420)
基于語(yǔ)言現(xiàn)象的文本蘊(yùn)涵識(shí)別
任 函1,2,馮文賀1,2,劉茂福2,3,萬(wàn) 菁4
(1.廣東外語(yǔ)外貿(mào)大學(xué) 語(yǔ)言工程與計(jì)算實(shí)驗(yàn)室,廣東 廣州 510006;2.武漢大學(xué) 湖北語(yǔ)言與智能信息處理研究基地,湖北 武漢 430072;3.武漢科技大學(xué) 計(jì)算機(jī)學(xué)院,湖北 武漢 430065;4.廣東外語(yǔ)外貿(mào)大學(xué) 詞典研究中心,廣東 廣州 510420)
該文提出一種基于語(yǔ)言現(xiàn)象的文本蘊(yùn)涵識(shí)別方法,該方法建立了一個(gè)語(yǔ)言現(xiàn)象識(shí)別和整體推理判斷的聯(lián)合分類模型,目的是對(duì)兩個(gè)高度相關(guān)的任務(wù)進(jìn)行統(tǒng)一學(xué)習(xí),避免管道模型的錯(cuò)誤傳播問(wèn)題并提升系統(tǒng)精度。針對(duì)語(yǔ)言現(xiàn)象識(shí)別,設(shè)計(jì)了22個(gè)專用特征和20個(gè)通用特征;為提高隨機(jī)森林的泛化能力,提出一種基于特征選擇的隨機(jī)森林生成算法。實(shí)驗(yàn)結(jié)果表明,基于隨機(jī)森林的聯(lián)合分類模型能夠有效識(shí)別語(yǔ)言現(xiàn)象和總體蘊(yùn)涵關(guān)系。
文本蘊(yùn)涵識(shí)別;語(yǔ)言現(xiàn)象;隨機(jī)森林
1 引言
文本蘊(yùn)涵識(shí)別(Recognizing Textual Entailment)是一個(gè)判斷命題之間邏輯推導(dǎo)關(guān)系的挑戰(zhàn)任務(wù),其定義為:給定一個(gè)語(yǔ)段T(Text)和一個(gè)假設(shè)H(Hypothesis),如果H的意義可以從T的意義中推斷出來(lái),那么就認(rèn)為T蘊(yùn)涵H,記為T→H[1]。文本蘊(yùn)涵識(shí)別是自然語(yǔ)言理解的重要研究課題之一,能夠廣泛用于問(wèn)答系統(tǒng)、多文檔自動(dòng)摘要、信息抽取、機(jī)器閱讀等自然語(yǔ)言處理應(yīng)用[2-3]。
文本蘊(yùn)涵識(shí)別需要考察多種推理關(guān)系,例如,詞義、句法和語(yǔ)義變換。現(xiàn)有文本蘊(yùn)涵識(shí)別研究往往集中于針對(duì)某一特定類型的推理問(wèn)題設(shè)計(jì)精確的解決方案,這種方式雖然能夠提高針對(duì)這類問(wèn)題的推理能力,然而由于文本蘊(yùn)涵識(shí)別涉及的推理關(guān)系眾多,使得這種方式對(duì)于文本蘊(yùn)涵識(shí)別的整體性能提升非常有限[4]。為此,一些文本蘊(yùn)涵識(shí)別研究嘗試對(duì)推理中涉及的語(yǔ)言現(xiàn)象進(jìn)行分類,并據(jù)此建立語(yǔ)言現(xiàn)象的標(biāo)注方法和資源[5-7]。例如,
T:喬姆斯基是20世紀(jì)最偉大的語(yǔ)言學(xué)家之一,他提出了形式語(yǔ)法理論。
H:喬姆斯基創(chuàng)立了形式語(yǔ)法理論。
其中,“提出”和“創(chuàng)立”屬于詞義蘊(yùn)涵(Lexical Entailment)現(xiàn)象,“他”和“喬姆斯基”屬于指代(Coreference)現(xiàn)象。顯然,獲取這些語(yǔ)言現(xiàn)象將有助于對(duì)兩個(gè)句子的蘊(yùn)涵關(guān)系進(jìn)行判斷。
目前,針對(duì)文本蘊(yùn)涵中語(yǔ)言現(xiàn)象的研究主要集中在資源標(biāo)注方面,而利用標(biāo)注的語(yǔ)言現(xiàn)象進(jìn)行文本蘊(yùn)涵識(shí)別的相關(guān)研究則非常缺乏。本文提出一種基于語(yǔ)言現(xiàn)象的文本蘊(yùn)涵識(shí)別方法。該方法建立了一種語(yǔ)言現(xiàn)象識(shí)別和整體推理判斷的聯(lián)合分類模型,對(duì)兩個(gè)高度相關(guān)的任務(wù)進(jìn)行統(tǒng)一學(xué)習(xí),避免了管道模型的錯(cuò)誤傳播問(wèn)題。針對(duì)語(yǔ)言現(xiàn)象識(shí)別,設(shè)計(jì)了22個(gè)專用特征和20個(gè)通用特征;為提高隨機(jī)森林的泛化能力,提出一種基于特征選擇的隨機(jī)森林生成算法。實(shí)驗(yàn)結(jié)果表明,基于隨機(jī)森林的聯(lián)合分類模型能夠有效識(shí)別語(yǔ)言現(xiàn)象和總體蘊(yùn)涵關(guān)系。
本文第二部分簡(jiǎn)要介紹基于語(yǔ)言現(xiàn)象的文本蘊(yùn)涵識(shí)別相關(guān)工作;第三部分介紹基于語(yǔ)言現(xiàn)象的文本蘊(yùn)涵識(shí)別模型;第四部分對(duì)實(shí)驗(yàn)結(jié)果進(jìn)行分析;第五部分對(duì)全文工作進(jìn)行總結(jié)和展望。
2 相關(guān)工作
基于語(yǔ)言現(xiàn)象的文本蘊(yùn)涵識(shí)別策略通過(guò)分析語(yǔ)言現(xiàn)象獲取局部片斷的推理關(guān)系,再進(jìn)行整體蘊(yùn)涵判斷。該策略一般涉及資源建設(shè)和蘊(yùn)涵識(shí)別兩個(gè)部分。
2.1 資源建設(shè)
現(xiàn)有語(yǔ)言現(xiàn)象的資源建設(shè)工作主要基于英語(yǔ)。Garoufi[8]從對(duì)齊、上下文及指代三個(gè)方面歸納了23種現(xiàn)象來(lái)標(biāo)注T和H的推理關(guān)系。他在RTE-2的測(cè)試數(shù)據(jù)集上共標(biāo)注了400個(gè)蘊(yùn)涵的文本對(duì),并隨機(jī)選取了25%的矛盾類進(jìn)行標(biāo)注。Sammons等[7]定義了39類語(yǔ)言現(xiàn)象,并在RTE-5中挑選了210個(gè)文本對(duì)進(jìn)行標(biāo)注,然后用標(biāo)注結(jié)果對(duì)現(xiàn)有RTE參賽系統(tǒng)進(jìn)行評(píng)估。Bentivogli[5]將語(yǔ)言現(xiàn)象歸為詞匯、句法、詞匯-句法關(guān)系、篇章及推理五大類,在RTE-5數(shù)據(jù)集上進(jìn)行了90個(gè)文本對(duì)的標(biāo)注實(shí)踐。這一工作與其它工作的區(qū)別在于,T和H被分解成一系列推理過(guò)程,每次分解的結(jié)果用(T,Hi)表示,其中T為原始語(yǔ)段,Hi表示一系列假設(shè),然后通過(guò)人工總結(jié)這一系列(T,Hi)中所含語(yǔ)言現(xiàn)象里存在的推理關(guān)系。
此外,Kaneko等[6]定義了26類推理現(xiàn)象,并用于標(biāo)注RITE-2任務(wù)中的日語(yǔ)語(yǔ)料。而第一份中文語(yǔ)言現(xiàn)象標(biāo)注語(yǔ)料則由RITE-3任務(wù)[9]給出,其中包括19類蘊(yùn)涵現(xiàn)象和九類矛盾現(xiàn)象,共標(biāo)注了581對(duì)訓(xùn)練集和1 200對(duì)測(cè)試集數(shù)據(jù)中的語(yǔ)言現(xiàn)象。
從規(guī)模上看,這些資源標(biāo)注數(shù)量比較有限,但他們的工作使得語(yǔ)言現(xiàn)象的標(biāo)注資源在推理中的作用顯得更為重要,并也形成了一些可供參考的標(biāo)注資源。
2.2 蘊(yùn)涵識(shí)別
基于語(yǔ)言現(xiàn)象的蘊(yùn)涵識(shí)別還是一個(gè)鮮有涉足的研究領(lǐng)域。Huang等[10]對(duì)推理現(xiàn)象識(shí)別進(jìn)行了初步探索。他們考察了矛盾類語(yǔ)言現(xiàn)象,并為每類現(xiàn)象總結(jié)出啟發(fā)式規(guī)則。為考察語(yǔ)言現(xiàn)象的識(shí)別效果,他們?cè)O(shè)計(jì)了兩個(gè)實(shí)驗(yàn),第一個(gè)實(shí)驗(yàn)分別統(tǒng)計(jì)機(jī)器和人工識(shí)別語(yǔ)言現(xiàn)象的準(zhǔn)確率;在第二個(gè)實(shí)驗(yàn)中,他們將自動(dòng)識(shí)別的語(yǔ)言現(xiàn)象作為特征,放入SVM進(jìn)行訓(xùn)練。第一個(gè)實(shí)驗(yàn)結(jié)果顯示,機(jī)器標(biāo)注的結(jié)果(52.38%)與人工結(jié)果(95.24%)的性能相去甚遠(yuǎn),但第二個(gè)實(shí)驗(yàn)結(jié)果顯示,僅利用五個(gè)矛盾類語(yǔ)言現(xiàn)象作為特征進(jìn)行學(xué)習(xí)得到的分類器性能與RTE-5全部參評(píng)系統(tǒng)的平均準(zhǔn)確率相當(dāng)。這在一定程度上體現(xiàn)語(yǔ)言現(xiàn)象對(duì)文本推理系統(tǒng)的有效性。然而,到目前為止,還沒有利用語(yǔ)言現(xiàn)象進(jìn)行文本蘊(yùn)涵識(shí)別的大規(guī)模研究。
3 基于語(yǔ)言現(xiàn)象的文本蘊(yùn)涵識(shí)別
本文提出一種基于語(yǔ)言現(xiàn)象的文本蘊(yùn)涵識(shí)別方法。該方法建立了一種語(yǔ)言現(xiàn)象識(shí)別和整體推理判斷的聯(lián)合分類模型,并利用改進(jìn)的隨機(jī)森林方法進(jìn)行訓(xùn)練和預(yù)測(cè)。
3.1 語(yǔ)言現(xiàn)象類別
本文實(shí)驗(yàn)基于中文蘊(yùn)涵語(yǔ)料,為此,我們以RITE-3評(píng)測(cè)任務(wù)中定義的漢語(yǔ)語(yǔ)言現(xiàn)象為基礎(chǔ)定義本實(shí)驗(yàn)中的語(yǔ)言現(xiàn)象類別。RITE-3語(yǔ)料包括19類蘊(yùn)涵現(xiàn)象和九類矛盾現(xiàn)象,共標(biāo)注了581對(duì)訓(xùn)練集和1 200對(duì)測(cè)試集數(shù)據(jù)中的語(yǔ)言現(xiàn)象。我們對(duì)其定義的語(yǔ)言現(xiàn)象進(jìn)行如下改進(jìn):
1) 將Relative_clause與Clause合并,稱為Clause現(xiàn)象,原因是兩者所表示的語(yǔ)言現(xiàn)象非常相近,都是T中包含了H中沒有的句法成分。
2) 將Antonym、Exclusion:Modality和Exclusion:Modifier合并,稱為Antonym現(xiàn)象,原因是后兩者所表示的語(yǔ)言現(xiàn)象屬于意義相對(duì)的成分,與Antonym包含對(duì)義關(guān)系相似。
3) 去掉Paraphrase、Inference和Exclusion:common_sense三類語(yǔ)言現(xiàn)象,原因是這三類現(xiàn)象體現(xiàn)了對(duì)文本的解釋和重寫,而非僅僅是詞匯或句法的替換,識(shí)別這類語(yǔ)言現(xiàn)象已相當(dāng)于對(duì)整體進(jìn)行推理判斷。因此,我們將包含這三類現(xiàn)象的文本對(duì)直接利用推理判斷模型進(jìn)行識(shí)別,不再為其指定語(yǔ)言現(xiàn)象類別。
改進(jìn)后的語(yǔ)言現(xiàn)象包括16類蘊(yùn)涵現(xiàn)象和六類矛盾現(xiàn)象,如表1所示。
3.2 語(yǔ)言現(xiàn)象識(shí)別
語(yǔ)言現(xiàn)象識(shí)別的任務(wù)是,找出T和H中包含的語(yǔ)言現(xiàn)象。一種方法是,為每類語(yǔ)言現(xiàn)象設(shè)計(jì)對(duì)應(yīng)的規(guī)則,若T和H中存在符合規(guī)則的文本片斷對(duì),則認(rèn)為存在該語(yǔ)言現(xiàn)象。例如,
T:水蘊(yùn)草為雌雄異株的植物。
H:水蘊(yùn)草為雌雄異株的生物。
該語(yǔ)言現(xiàn)象為“上下位關(guān)系”,可為其制定啟發(fā)式規(guī)則:若T存在某一詞語(yǔ),H中存在其上位詞,則認(rèn)為該文本對(duì)包含“上下位關(guān)系”這一語(yǔ)言現(xiàn)象。該方法對(duì)于比較簡(jiǎn)單的詞匯類語(yǔ)言現(xiàn)象具有一定的識(shí)別能力。然而,對(duì)于比較復(fù)雜的文本,簡(jiǎn)單的規(guī)則往往導(dǎo)致準(zhǔn)確率不高;若編制比較復(fù)雜的規(guī)則,又會(huì)面臨召回率降低的問(wèn)題,其原因在于約束條件過(guò)多。Huang等[10]的實(shí)驗(yàn)也表明,采用規(guī)則方法難以獲得理想的識(shí)別性能。
本文提出一種基于機(jī)器學(xué)習(xí)的方法,將語(yǔ)言現(xiàn)象識(shí)別看作一個(gè)學(xué)習(xí)問(wèn)題,即首先通過(guò)訓(xùn)練數(shù)據(jù)獲得語(yǔ)言現(xiàn)象識(shí)別知識(shí),再對(duì)測(cè)試數(shù)據(jù)進(jìn)行預(yù)測(cè)。為此,我們定義了一組專用特征,如表1所示。這些專用特征所覆蓋了本文定義的語(yǔ)言現(xiàn)象。
專用特征可分為兩類,一類為詞匯類特征;另一類為句法、語(yǔ)義類特征。絕大多數(shù)詞匯類特征都需要利用世界知識(shí)進(jìn)行判斷。如縮略詞、上下位、同義詞等。我們使用同義詞詞林、HowNet、百度漢語(yǔ)、金山詞霸漢語(yǔ)等詞典識(shí)別同義、反義、上下位關(guān)系、整體—部分關(guān)系等語(yǔ)言現(xiàn)象。對(duì)于縮略語(yǔ)現(xiàn)象,除采用以上資源進(jìn)行識(shí)別外,還利用規(guī)則從中文維基百科中抽取縮略語(yǔ)集合進(jìn)行識(shí)別。對(duì)于對(duì)義關(guān)系,采用一種基于HowNet詞匯語(yǔ)義相似度的方法[11]進(jìn)行計(jì)算,該方法利用了義原的反義、對(duì)義關(guān)系和義原信息計(jì)算詞匯相似度。對(duì)于詞匯蘊(yùn)涵關(guān)系,采用一種基于詞向量的方法[12]進(jìn)行計(jì)算,該方法從中文維基百科語(yǔ)料上訓(xùn)練出100維的詞向量,并利用分類的方法識(shí)別詞匯蘊(yùn)涵關(guān)系。對(duì)于Spatial現(xiàn)象,利用已抽取的地理信息資源[13]進(jìn)行識(shí)別。

表1 語(yǔ)言現(xiàn)象專用特征
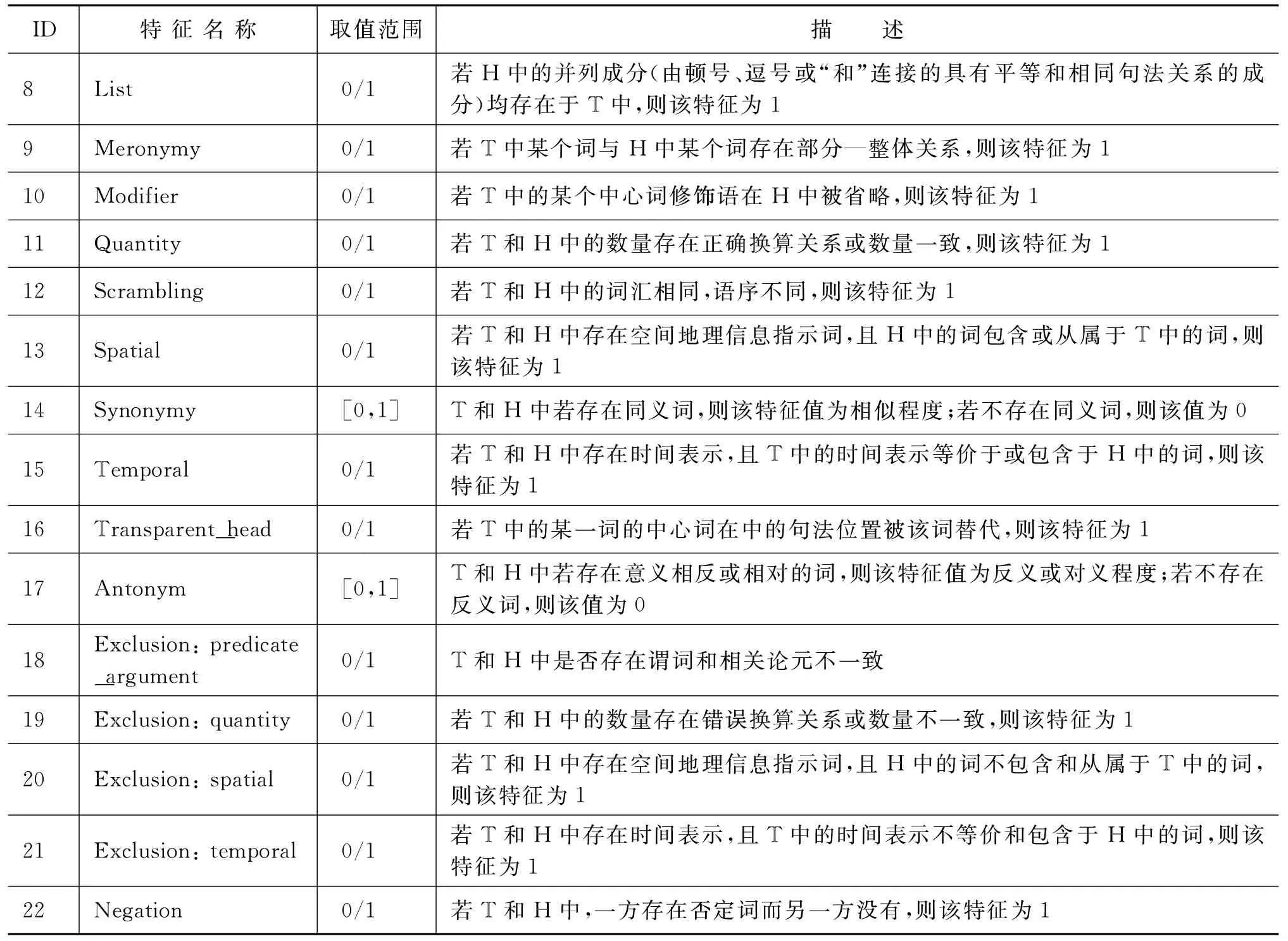
續(xù)表
對(duì)于句法、語(yǔ)義類特征,首先利用Stanford CoreNLP*http://nlp.stanford.edu/工具對(duì)T和H進(jìn)行句法和語(yǔ)義分析,再利用結(jié)果進(jìn)行識(shí)別。特別地,對(duì)于Coreference特征,利用上述工具進(jìn)行指代消解,再進(jìn)行識(shí)別;對(duì)于Case_alternation、List特征,首先為每種句式制定相應(yīng)匹配規(guī)則,再結(jié)合句法分析結(jié)果進(jìn)行結(jié)構(gòu)匹配。
定義專用特征的目的是描述特定語(yǔ)言現(xiàn)象,即每一個(gè)特征描述一種特定的語(yǔ)言現(xiàn)象。然而,僅憑專用特征難以完整地描述語(yǔ)言現(xiàn)象。為此,我們加入了通用特征,這些通用特征包括詞匯、句法和語(yǔ)義的相關(guān)性特征,目的是聯(lián)合專用特征進(jìn)行語(yǔ)言現(xiàn)象識(shí)別。通用特征有助于語(yǔ)言現(xiàn)象的識(shí)別,例如當(dāng)詞匯相似度較高、句法相似度較低,并且Case_alternation特征為真時(shí),表明文本對(duì)存在句式變換的可能性較高。
通用特征利用了我們提出的15種蘊(yùn)涵識(shí)別特征,包括重疊特征、相似度特征、結(jié)構(gòu)特征和語(yǔ)言學(xué)特征[13]。此外,還利用了以下五種特征:Jaro-Winkler距離、Manhattan距離、切比雪夫距離、歐式距離和Jaccard相似度。
3.3 文本蘊(yùn)涵識(shí)別
文本蘊(yùn)涵識(shí)別的任務(wù)是,利用語(yǔ)言現(xiàn)象識(shí)別結(jié)果對(duì)文本對(duì)(T,H)進(jìn)行整體推理判斷。這一步驟是必要的,因?yàn)樘N(yùn)涵或矛盾語(yǔ)言現(xiàn)象存在并不代表T和H具有蘊(yùn)涵或矛盾關(guān)系。例如,
T:美國(guó)疾病控制與預(yù)防中心通報(bào)美國(guó)首宗愛滋病感染案例。
H:美國(guó)疾病控制與預(yù)防中心通報(bào)全球首宗愛滋病感染案例。
盡管“美國(guó)”包含于“全球”,但T和H并不具有蘊(yùn)涵關(guān)系,理由很明顯:局部推理關(guān)系并不能代表總體推理關(guān)系。因此,除語(yǔ)言現(xiàn)象識(shí)別結(jié)果外,我們還需結(jié)合上下文才能進(jìn)行整體推理判斷。
文本蘊(yùn)涵識(shí)別的一種主要策略是分類的方法,即將文本對(duì)(T,H)表示成特征向量,然后利用機(jī)器學(xué)習(xí)方法進(jìn)行分類,輸出蘊(yùn)涵或非蘊(yùn)涵的判斷結(jié)果。基于此,我們可以將語(yǔ)言現(xiàn)象識(shí)別結(jié)果作為向量的一維,加入到現(xiàn)有特征向量中參與訓(xùn)練。然而,這一方法存在以下問(wèn)題:1)語(yǔ)言現(xiàn)象識(shí)別結(jié)果僅占特征向量的一維,比重過(guò)小;2)語(yǔ)言現(xiàn)象識(shí)別的錯(cuò)誤可能會(huì)造成錯(cuò)誤傳播,影響整體推理判斷的性能。
基于此,本文提出一種語(yǔ)言現(xiàn)象識(shí)別與整體推理判斷的聯(lián)合分類模型,其目的是用一個(gè)統(tǒng)一的模型解決兩個(gè)高度相關(guān)的任務(wù),能夠在一定程度上避免上述問(wèn)題。模型的輸入為文本對(duì)(T,H),輸出為蘊(yùn)涵或不蘊(yùn)涵的判斷,以及文本對(duì)中存在的語(yǔ)言現(xiàn)象。
本文采用隨機(jī)森林(Random Forest,RF)作為聯(lián)合分類器,理由如下:
1) RF適合處理特征較多的問(wèn)題。語(yǔ)言現(xiàn)象識(shí)別需要利用42種特征,蘊(yùn)涵判斷需要用到20種特征,盡管通用特征既可用于識(shí)別語(yǔ)言現(xiàn)象,也可用于進(jìn)行推理判斷,但總體特征數(shù)仍較多。而RF能夠處理高維數(shù)據(jù),不用進(jìn)行特征選擇,因此適合本任務(wù)。
2) RF適合處理輸出較多的任務(wù)。本模型的輸出為語(yǔ)言現(xiàn)象類別(22種)和蘊(yùn)涵判斷結(jié)果(蘊(yùn)涵/非蘊(yùn)涵),共有44種組合,遠(yuǎn)多于一般分類問(wèn)題的類別個(gè)數(shù)。對(duì)于一般文本蘊(yùn)涵識(shí)別而言,只需獲得最終蘊(yùn)涵判斷結(jié)果即可;本文定義組合類別的目的在于獲得語(yǔ)言現(xiàn)象的識(shí)別結(jié)果并進(jìn)行分析,同時(shí)該結(jié)果也可與其他文本蘊(yùn)涵識(shí)別模型結(jié)合以改進(jìn)蘊(yùn)涵識(shí)別性能,或?qū)ζ渌谋咎N(yùn)涵識(shí)別系統(tǒng)進(jìn)行評(píng)估。
3) RF對(duì)于分布不均衡的數(shù)據(jù)能夠保持穩(wěn)定的性能。從RITE-3的語(yǔ)料統(tǒng)計(jì)[9]上看,在訓(xùn)練集中出現(xiàn)較多的語(yǔ)言現(xiàn)象,如Inference出現(xiàn)次數(shù)多達(dá)75次,而Meronymy語(yǔ)言現(xiàn)象則僅出現(xiàn)四次,存在明顯的樣本偏置。
另一方面,RF泛化能力的一個(gè)決定因素是隨機(jī)樹的平均相關(guān)度,相關(guān)度越低則泛化能力越強(qiáng)。我們可以通過(guò)特征選擇提高樹之間的差異性,以此改進(jìn)RF的分類性能。對(duì)于本問(wèn)題而言,樹之間的差異性體現(xiàn)在語(yǔ)言現(xiàn)象的識(shí)別,即專用特征;而通用特征主要分析T和H的相關(guān)程度,不同蘊(yùn)涵現(xiàn)象的文本對(duì)可能體現(xiàn)出相同的相關(guān)程度,若某些建樹過(guò)程都使用了通用特征而未使用專用特征,可能導(dǎo)致生成的樹的差異程度過(guò)小。因此,有必要在建樹時(shí)分配一定數(shù)量的專用特征和通用特征。為此,本文提出一種改進(jìn)特征選擇的隨機(jī)森林生成算法,算法描述如圖1所示。

圖1 隨機(jī)森林生成算法
在預(yù)測(cè)階段,由K個(gè)決策樹分別對(duì)測(cè)試數(shù)據(jù)進(jìn)行投票,計(jì)算所有投票數(shù),找出票數(shù)最高的類別即可得到測(cè)試數(shù)據(jù)的蘊(yùn)涵關(guān)系及包含的語(yǔ)言現(xiàn)象。
4 實(shí)驗(yàn)結(jié)果及分析
4.1 數(shù)據(jù)準(zhǔn)備
實(shí)驗(yàn)采用RITE-3中文任務(wù)的訓(xùn)練和測(cè)試語(yǔ)料,包括581對(duì)訓(xùn)練數(shù)據(jù)和1 200對(duì)測(cè)試數(shù)據(jù)。每條數(shù)據(jù)包括一個(gè)語(yǔ)段T和一個(gè)假設(shè)H,并標(biāo)注了一個(gè)語(yǔ)言現(xiàn)象和整體蘊(yùn)涵關(guān)系(蘊(yùn)涵/非蘊(yùn)涵)。其中,訓(xùn)練集包含370對(duì)具有蘊(yùn)涵關(guān)系的文本對(duì),211對(duì)具有非蘊(yùn)涵關(guān)系的文本對(duì);測(cè)試集分別包含600對(duì)蘊(yùn)涵關(guān)系與非蘊(yùn)涵關(guān)系的文本對(duì)。為方便處理,首先對(duì)數(shù)據(jù)進(jìn)行以下規(guī)范化操作:
1) 將文本中的中英文標(biāo)點(diǎn)符號(hào)統(tǒng)一替換成中文標(biāo)點(diǎn)符號(hào);
2) 統(tǒng)一度量單位,如長(zhǎng)度為米,重量為千克;
3) 將漢字大寫數(shù)字轉(zhuǎn)換為阿拉伯?dāng)?shù)字;
4) 將全角字符轉(zhuǎn)換為半角字符;
5) 將分?jǐn)?shù)統(tǒng)一轉(zhuǎn)換為漢語(yǔ)表示,如“×分之×”;
6) 將日期統(tǒng)一轉(zhuǎn)換為××××年××月××日格式。
4.2 實(shí)驗(yàn)結(jié)果
本實(shí)驗(yàn)評(píng)估了本文提出的隨機(jī)森林方法對(duì)語(yǔ)言現(xiàn)象和整體蘊(yùn)涵關(guān)系的識(shí)別性能。實(shí)驗(yàn)評(píng)估手段為準(zhǔn)確率(Precision)、召回率(Recall)和F1值。
實(shí)驗(yàn)設(shè)置了四個(gè)系統(tǒng),第一個(gè)系統(tǒng)(svm_combined)直接利用專用特征和通用特征建立特征空間,并利用SVM進(jìn)行學(xué)習(xí)和預(yù)測(cè);第二個(gè)系統(tǒng)(svm_cascaded)采用兩階段識(shí)別方法,首先利用專用特征進(jìn)行語(yǔ)言現(xiàn)象識(shí)別,再將識(shí)別結(jié)果作為特征,和通用特征一起建立特征空間(實(shí)驗(yàn)中提高了識(shí)別特征的權(quán)重),利用SVM進(jìn)行訓(xùn)練和預(yù)測(cè);第三個(gè)系統(tǒng)(RF-FS)采用基于隨機(jī)森林的聯(lián)合分類模型,但樹的構(gòu)建采用完全隨機(jī)特征選擇的方法;第四個(gè)系統(tǒng)(RF+FS)在第三個(gè)系統(tǒng)基礎(chǔ)上采用改進(jìn)的隨機(jī)森林生成算法,即本文方法。基準(zhǔn)系統(tǒng)(baseline)采用我們?cè)贜TCIR-11上的參賽系統(tǒng)[13]。該系統(tǒng)采用分類方法,利用字串、相似度、結(jié)構(gòu)和語(yǔ)言學(xué)共15種特征構(gòu)建基于SVM的分類系統(tǒng)。實(shí)驗(yàn)結(jié)果如表2所示。
實(shí)驗(yàn)結(jié)果表明:
1) 識(shí)別語(yǔ)言現(xiàn)象能夠有效提高文本蘊(yùn)涵識(shí)別系統(tǒng)的性能。從本文方法與基準(zhǔn)系統(tǒng)的性能對(duì)比上看,蘊(yùn)涵關(guān)系識(shí)別的準(zhǔn)確率、召回率和F1值分別高出13.89%、2.5%和9.2%,非蘊(yùn)涵關(guān)系識(shí)別的三個(gè)指標(biāo)分別高出6.06%、8.33%和7.74%,顯示出本文方法的性能顯著優(yōu)于基準(zhǔn)系統(tǒng);從svm_cascaded和基準(zhǔn)系統(tǒng)的性能對(duì)比上看,準(zhǔn)確率和F1值在蘊(yùn)涵類關(guān)系識(shí)別上分別提高3.42%和2%,在非蘊(yùn)涵類關(guān)系識(shí)別上分別提高1.53%和3.46%,說(shuō)明僅加入語(yǔ)言現(xiàn)象識(shí)別結(jié)果,也能在一定程度上改進(jìn)蘊(yùn)涵識(shí)別系統(tǒng)的性能。
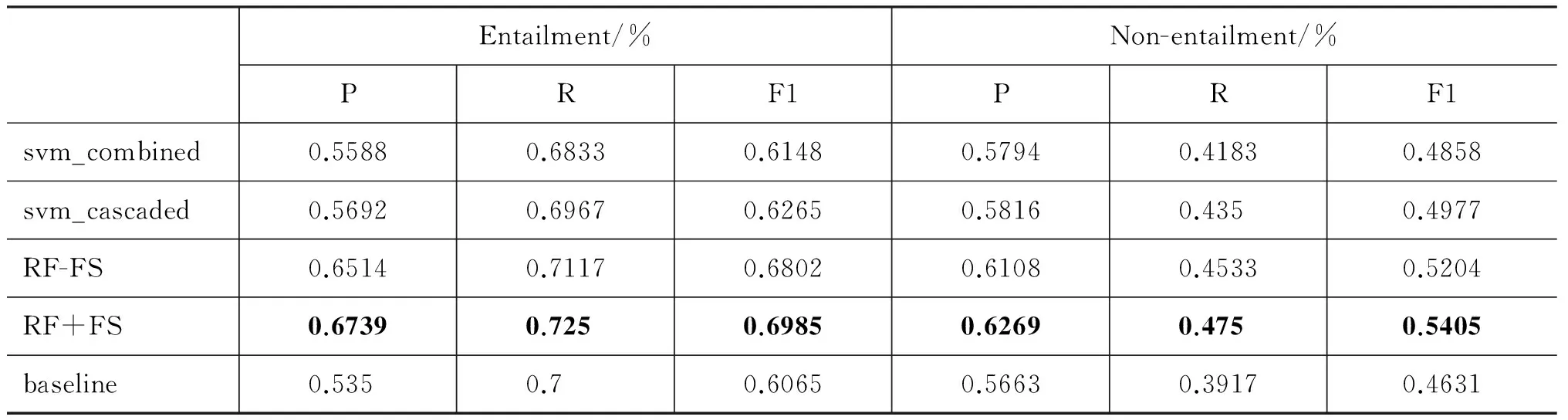
表2 文本蘊(yùn)涵識(shí)別結(jié)果
2) 在隨機(jī)森林的建樹過(guò)程中進(jìn)行特征選擇,能夠提高模型的泛化能力,從而改進(jìn)蘊(yùn)涵識(shí)別的性能。對(duì)比RF+FS與RF-FS的實(shí)驗(yàn)結(jié)果,在準(zhǔn)確率、召回率和F1值三個(gè)指標(biāo)上,蘊(yùn)涵關(guān)系識(shí)別分別高出2.25%、1.33%和1.83%,非蘊(yùn)涵關(guān)系識(shí)別分別高出1.61%、2.17%和2.01%,表明模型的分類性能在經(jīng)過(guò)特征選擇后有了一定程度的提高。事實(shí)上,語(yǔ)言現(xiàn)象識(shí)別和整體推理判斷屬于相互關(guān)聯(lián)的兩個(gè)問(wèn)題,因此所建的分類樹要能對(duì)兩個(gè)問(wèn)題進(jìn)行判斷,采用特征選擇方法則對(duì)分類樹特征集合中的專用特征和通用特征進(jìn)行了一定比例的分配,避免了分類樹特征類別單一的問(wèn)題。
3) 與SVM相比,隨機(jī)森林能夠更有效地處理語(yǔ)言現(xiàn)象識(shí)別和整體推理判斷的聯(lián)合分類問(wèn)題。對(duì)比RF-FS與svm_cascaded的實(shí)驗(yàn)結(jié)果,在準(zhǔn)確率、召回率和F1值三個(gè)指標(biāo)上,蘊(yùn)涵關(guān)系識(shí)別分別高出8.22%、1.5%和5.37%,非蘊(yùn)涵關(guān)系識(shí)別分別高出2.92%、1.83%和2.27%,說(shuō)明隨機(jī)森林能夠更有效地處理多特征、多類別的分類問(wèn)題;另一方面,與隨機(jī)森林的蘊(yùn)涵類識(shí)別準(zhǔn)確率比較,SVM的準(zhǔn)確率過(guò)低,表明很多數(shù)據(jù)都被錯(cuò)誤地識(shí)別為蘊(yùn)涵類,其中的大部分原因是由于數(shù)據(jù)不均衡導(dǎo)致的。這也表明,隨機(jī)森林方法具有更穩(wěn)定的性能。
此外,從實(shí)驗(yàn)結(jié)果上看,svm_combined的性能不如svm_cascaded,其原因在于,盡管svm_combined使用了更多的特征,但由于數(shù)據(jù)集中每個(gè)文本對(duì)只包含一種語(yǔ)言現(xiàn)象,因此這些特征具有排斥性,導(dǎo)致數(shù)據(jù)稀疏,從而影響分類性能。
我們還對(duì)本文定義的22類語(yǔ)言現(xiàn)象識(shí)別結(jié)果進(jìn)行了統(tǒng)計(jì)。統(tǒng)計(jì)數(shù)據(jù)來(lái)自RF+FS與RF-FS的語(yǔ)言現(xiàn)象識(shí)別結(jié)果。此外,我們還建立了一個(gè)基于SVM的分類系統(tǒng),用于識(shí)別語(yǔ)言現(xiàn)象。該系統(tǒng)使用專用特征和通用特征進(jìn)行訓(xùn)練和預(yù)測(cè),輸出為語(yǔ)言現(xiàn)象類別。實(shí)驗(yàn)評(píng)估指標(biāo)為F1以及Marco-F1值[9]。實(shí)驗(yàn)結(jié)果如表3所示。
實(shí)驗(yàn)結(jié)果表明:
1) 對(duì)于語(yǔ)言現(xiàn)象識(shí)別而言,隨機(jī)森林的性能要優(yōu)于SVM。從總體性能上看,RF-FS的Macro-F1比SVM方法高3.89%,而RF+FS比SVM方法高4.75%。從具體的語(yǔ)言現(xiàn)象上看,對(duì)RF-RS和RF+FS的大部分語(yǔ)言現(xiàn)象的F1值均高于SVM方法。
2) 相對(duì)于SVM,隨機(jī)森林方法能夠顯著提高部分語(yǔ)言現(xiàn)象識(shí)別性能。對(duì)比RF+FS與SVM方法,前者識(shí)別Lexical_entailment、Modifier、Antonym等語(yǔ)言現(xiàn)象的F1值均高于后者10%以上。其原因在于,語(yǔ)言現(xiàn)象識(shí)別與整體推理判斷具有一定的關(guān)聯(lián)性,例如一個(gè)矛盾類現(xiàn)象出現(xiàn)在整體為蘊(yùn)涵關(guān)系的文本對(duì)中的可能性較低。而隨機(jī)森林方法為聯(lián)合分類方法,兩個(gè)任務(wù)在訓(xùn)練中相互影響,有助于各自識(shí)別性能的改進(jìn)。本實(shí)驗(yàn)中的SVM方法則未將整體推理關(guān)系用于識(shí)別。
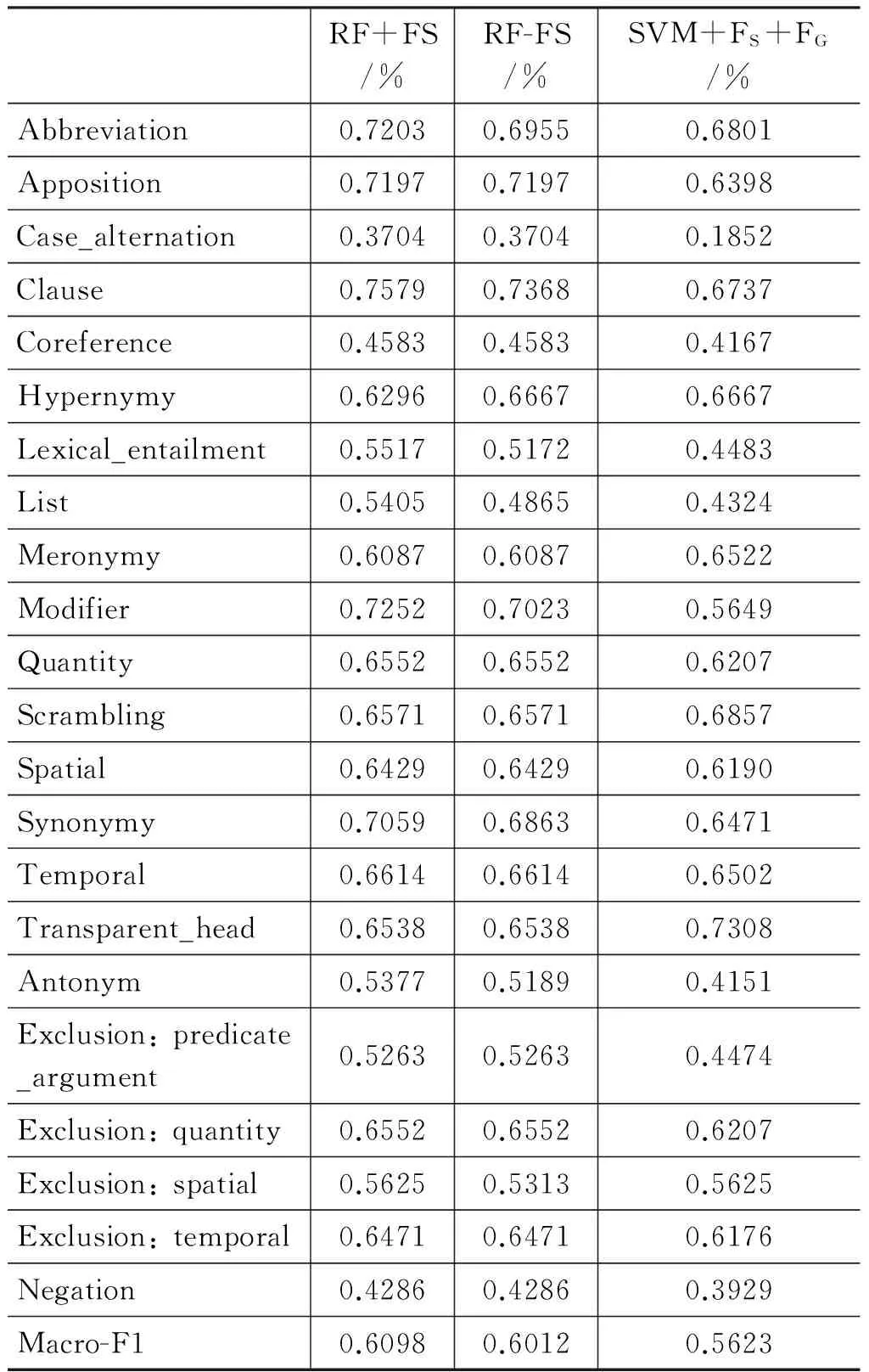
表3 語(yǔ)言現(xiàn)象識(shí)別結(jié)果
3) 某些語(yǔ)言現(xiàn)象比較復(fù)雜,識(shí)別這類現(xiàn)象需要用到更多知識(shí),系統(tǒng)識(shí)別性能也有待提高。例如,在RF+FS系統(tǒng)上,Case_alternation現(xiàn)象的F1值僅有37.04%,其原因在于語(yǔ)言形式變化多樣,僅通過(guò)定義一些匹配模板難以得到準(zhǔn)確的包含句式轉(zhuǎn)換的文本片斷。又如,Antonym現(xiàn)象的F1值較低的原因之一是許多對(duì)義關(guān)系并未識(shí)別出來(lái),其原因在于本實(shí)驗(yàn)中僅采用了HowNet以及一些漢語(yǔ)詞典作為反義詞資源,知識(shí)非常有限。
5 結(jié)論
本文提出一種基于語(yǔ)言現(xiàn)象的文本蘊(yùn)涵識(shí)別方法。該方法建立了一種語(yǔ)言現(xiàn)象識(shí)別和整體推理判斷的聯(lián)合分類模型,并利用改進(jìn)的隨機(jī)森林方法進(jìn)行訓(xùn)練和預(yù)測(cè)。為識(shí)別語(yǔ)言現(xiàn)象,本文設(shè)計(jì)了22類專用特征和20類通用特征;為提高隨機(jī)森林的泛化能力,本文提出一種基于特征選擇的隨機(jī)森林生成算法,通過(guò)在建樹時(shí)分配一定數(shù)量的專用特征和通用特征,以增加生成的樹的差異度。實(shí)驗(yàn)結(jié)果表明,識(shí)別語(yǔ)言現(xiàn)象能夠有效提高文本蘊(yùn)涵識(shí)別系統(tǒng)的性能;同時(shí),在隨機(jī)森林的建樹過(guò)程中進(jìn)行特征選擇,能夠提高模型的泛化能力,從而改進(jìn)語(yǔ)言現(xiàn)象識(shí)別和整體推理判斷的性能。
[1] Dagan I,Glickman O.Probabilistic Textual Entailment:Generic Applied Modeling of Language Variability[C]//Proceedings of PASCAL Workshop on Learning Methods for Text Understanding and Mining.2004.
[2] Androutsopoulos I,Malakasiotis P.A Survey of Paraphrasing and Textul Entailment Methods[J].Journal of Artificial Intelligence Research,2010,38(1):135-187.
[3] Dagan I,Dolan B.Recognizing textual entailment:Rational,evaluation and approaches[J].Natural Language Engineering,2009,15(4):i-xvii.
[4] Cabrio E.Specialized Entailment Engines:Approaching Linguistic Aspects of Textual Entailment[C]//Proceedings of the 14th International Conference on Applications of Natural Language to Information Systems,2009:305-308.
[5] Bentivogli L,Cabrio E,Dagan I,et al.Building textual entailment specialized data sets:a methodology for isolating linguistic phenomena relevant to inference[C]//Proceedings of the International Conference on Language Resources and Evaluation.2010:3542-3549.
[6] Kaneko K,Miyao Y,Bekki D.Building Japanese Textual Entailment Specialized Data Sets for Inference of Basic Sentence Relations[C]//Proceedings of the 51stAnnual Meeting of the Association of Computational Linguistics 2013:273-277.
[7] Sammons M,Vydiswaran V G V,Roth D.“Ask not what Textual Entailment can do for you…”[C]//Proceedings of the Annual Meeting of the Association for Computational Linguistics.2010:1199-1208.
[8] Garoufi K.Towards a better understanding of applied textual entailment:Annotation and evaluation of the RTE-2 dataset.Germany,Saarland University.Master Thesis.2007.
[9] Matsuyoshi S,Miyao Y,Shibata T,et al.Overview of the NTCIR-11 Recognizing Inference in TExt and Validation (RITE-VAL) Task[C]//Proceedings of the 11th NTCIR Conference.2014:223-232.
[10] Huang H H,Chang K C,Chen H H.Modeling Human Inference Process for Textual Entailment Recognition[C]//Proceedings of the 51st Annual Meeting of the Association for Computational Linguistics.2013:446-450.
[11] 江敏,肖詩(shī)斌,王弘蔚,等.一種改進(jìn)的基于知網(wǎng)的詞語(yǔ)語(yǔ)義相似度計(jì)算[J].中文信息學(xué)報(bào),2008,22(5):84-89.
[12] 張志昌,周慧霞,姚東任,等.基于詞向量的中文詞匯蘊(yùn)涵關(guān)系識(shí)別[J].計(jì)算機(jī)工程,2016,42(2):169-174.
[13] Ren H,Wu H,Tan X,et al.The WHUTE System in NTCIR-11 RITE Task[C]//Proceedings of the 11th NTCIR Conference.2014:309-316.
Recognizing Textual Entailment Based on Inference Phenomena
REN Han1,2,FENG Wenhe1,2,LIU Maofu2,3,WAN Jing2
(1.Laboratory of Language Engineering and Computing,Guangdong University of Foreign Studies,Guangzhou,Guangdong 510006,China; 2.Hubei Research Center for Language and Intelligent Information Processing,Wuhan University,Wuhan,Hubei 430072,China; 3.College of Computer Science and Technology,Wuhan University of Science and Technology,Wuhan,Hubei 430065,China;4.Center for Lexicographical Studies,Guangdong University of ForeignStudies,Guangzhou,Guangdoing 510420,China)
This paper introduces an approach of textual entailment recognition based on language phenomena.The approach asopts a joint classification model for language phenomenon recognition and entailment recognition,so as to learn two highly relevant tasks,avoiding error propagation in pipeline strategy.For language phenomenon recognition,22 specific and 20 general features are employed.And for enhancing the generalization of random forest,a feature selection method is adopted on building trees of random forest.Experimental results show that the joint classification model based on random forest recognizes language phenomena and entailment relation effectively.
recognizing textual entailment; language phenomena; random forest

任函(1980—),博士,助理研究員,主要研究領(lǐng)域?yàn)樽匀徽Z(yǔ)言處理。E-mail:hanren@whu.edu.cn馮文賀(1976—),通信作者,博士,講師,主要研究領(lǐng)域?yàn)槔碚撜Z(yǔ)言學(xué)、計(jì)算語(yǔ)言學(xué)。E-mail:wenhefeng@gmail.com劉茂福(1977—),博士,教授,主要研究領(lǐng)域?yàn)樽匀徽Z(yǔ)言處理。E-mail:liumaofu@wust.edu.cn
1003-0077(2011)00-0184-08
2016-09-03 定稿日期:2016-11-05
國(guó)家自然科學(xué)基金(61402341);國(guó)家社會(huì)科學(xué)基金(11&ZD189);華中師范大學(xué)中央高校基本科研業(yè)務(wù)費(fèi)教育科學(xué)專項(xiàng)資助(ccnu16JYKX014);教育部人文社科項(xiàng)目(13YJC740022);河南高校哲社基礎(chǔ)研究重大項(xiàng)目(2015-JCZD-022);廣東外語(yǔ)外貿(mào)大學(xué)語(yǔ)言工程與計(jì)算實(shí)驗(yàn)室2016年招標(biāo)課題(LEC2016ZBKT002)
TP391
A
猜你喜歡
數(shù)學(xué)小靈通(1-2年級(jí))(2021年4期)2021-06-09 06:25:56
瘋狂英語(yǔ)·新策略(2019年10期)2019-12-13 08:43:28
制造技術(shù)與機(jī)床(2019年10期)2019-10-26 02:48:08
當(dāng)代陜西(2019年10期)2019-06-03 10:12:04
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2019年4期)2019-05-20 10:06:32
電子制作(2018年18期)2018-11-14 01:48:06
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(jí)(2017年9期)2017-10-13 22:27:46
數(shù)學(xué)小靈通·3-4年級(jí)(2017年9期)2017-10-13 08:10:54
小學(xué)教學(xué)參考(2015年20期)2016-01-15 08:44:38
