基于詞向量的藏文詞性標注方法研究
2017-04-26 01:41:47鄭亞楠
中文信息學報 2017年1期
鄭亞楠,珠 杰,2
(1.西藏大學 計算機科學與技術系,西藏 拉薩 850000;2.西南交通大學 信息科學與技術學院,四川 成都 610031)
基于詞向量的藏文詞性標注方法研究
鄭亞楠1,珠 杰1,2
(1.西藏大學 計算機科學與技術系,西藏 拉薩 850000;2.西南交通大學 信息科學與技術學院,四川 成都 610031)
藏文詞性標注是藏文信息處理的基礎,在藏文文本分類、自動檢索、機器翻譯等領域有廣泛的應用。該文針對藏文語料匱乏,人工標注費時費力等問題,提出一種基于詞向量模型的詞性標注方法和相應算法,該方法首先利用詞向量的語義近似計算功能,擴展標注詞典;其次結合語義近似計算和標注詞典,完成詞性標注。實驗結果表明,該方法能夠快速有效地擴大了標注詞典規模,并能取得較好的標注結果。
詞向量;藏文;詞性標注
1 引言
藏文信息處理起步于20世紀80年代,經過三十多年的發展,已取得一些令人矚目的成績。但由于缺乏統一標準,詞處理技術尚不夠成熟,加上藏文語料嚴重匱乏,其研究一直進展緩慢。藏文詞性標注作為藏文信息處理中一項重要的基礎性工作,其標注效果直接制約著藏文信息處理技術的發展,并對藏文詞法分析、句法分析和語義分析等研究領域有很大影響。雖然藏文信息處理研究在技術上充分利用已有的國內外先進的處理方法,但其基礎語料資源相對貧乏,各研究單位公開的語料較少且多為未標注語料,應用價值非常有限。因此,針對藏文詞性人工標注費時又費力的問題,本文提出了一種基于詞向量模型的詞性標注方法。
深度學習模型訓練的詞向量具有良好的語義特征,是表示詞語特征的常用方式,一般用Distributed Representation表示。詞向量是一個稠密、低維的實數向量,它的每一維表示詞語的一個潛在特征,該特征捕獲了有用的句法和語義特征。本文充分利用詞語之間的語義相似關系擴充原始標注詞典,并結合擴充后的標注詞典與詞向量近似計算對測試語料進行詞性標注。
2 相關工作
詞性標注是計算機自動語言分析和理解的一個重要環節,其任務是為文本中的每一個詞都標記上一個恰當的語境詞類標記符號,即確定每個詞的名詞、動詞、形容詞或其他詞類屬性[1]。漢語、英語等語言的詞性標注研究較為成熟,都有開源的標注系統。藏文詞性標注起步相對較晚,研究基礎相對薄弱,采用的標注方法大多借鑒漢語、英語等國內外較為成熟的方法。
2004年,江荻[2]最先討論了藏文詞性標注問題。2006年,才讓加[3]等根據藏文詞類的功能和性質提出了一種藏文的詞性分類及代碼。扎西加[4]等以藏文語法理論和漢語、英語詞性劃分為依據,將藏文詞語劃分為26個基本類和九個特殊類。蘇俊峰[5]等使用人工標注的語料統計詞和詞性,并通過訓練二元語法的HMM模型參數,運用Viterbi算法完成了基于統計方法的藏文詞性標注。扎西多杰[6]等以四萬詞的語料庫作為訓練語料,同樣采用HMM模型對20篇文章進行詞性標注,其標注正確率達到84%。華卻才讓[7]等在分析現有藏文詞性標注方法的基礎上,提出了感知機訓練模型的判別式藏文詞性標注方法,并在573句人工標注的語料上進行了相關實驗,取得了較好的效果。于洪志[8]等研究了融合語言特征的最大熵藏文詞性標注模型,并通過實驗證明音節特征可以顯著提高藏文詞性標注的效果。康才畯[9]采用最大熵結合條件隨機場模型實現了藏文詞性標注,并在小規模語料訓練下達到了 87.76%的準確率。綜上所述,可以看出在已有的藏文詞性標注研究中,均是采用統計模型的方法進行詞性標注。由于統計方法需要大規模的語料來提高精度,而藏文公開的語料較少,各研究人員的實驗條件和實驗語料不統一,使得實驗結果相差較大,還達不到可實際應用的程度。
3 詞性標注算法
3.1 標注集的確定
由于目前還沒有一個統一的藏文詞類劃分標準,因此,各研究單位和人員所用詞類劃分的粒度和標記符號并不相同。本文參照前人對標注集的研究,將藏文詞語分為一、二、三級類別,其中包括三個一級類別,16個二級類別,70個三級類別。然后根據藏文文法特點,在該標注集的基礎上按照劃分粒度不同分別定義了粗切分標注集和細切分標注集,涉及到的相關概念定義如下。
定義1 將最初統計的各標注類別所包含的詞語稱為種子。
定義2 將藏文詞語中數量及詞性無太大變化的虛詞組成的集合稱為固定標注集,標注規范及各類詞數統計結果如表1所示,稱之為固定標注庫。
定義3 將藏文詞類標注集中二級類別和三級類別相結合的標注規范稱為粗切分,如表2所示,稱之為粗切分標注庫。該表包含了標注規范和種子數量,在標注庫擴充算法中將其作為粗切分的種子庫。
定義4 將藏文詞類標注集中三級類別的標注規范稱為細切分,如表3所示,稱之為細切分標注庫。該表包含了標注規范和種子數量,在標注庫擴充算法中將其作為細切分的種子庫。
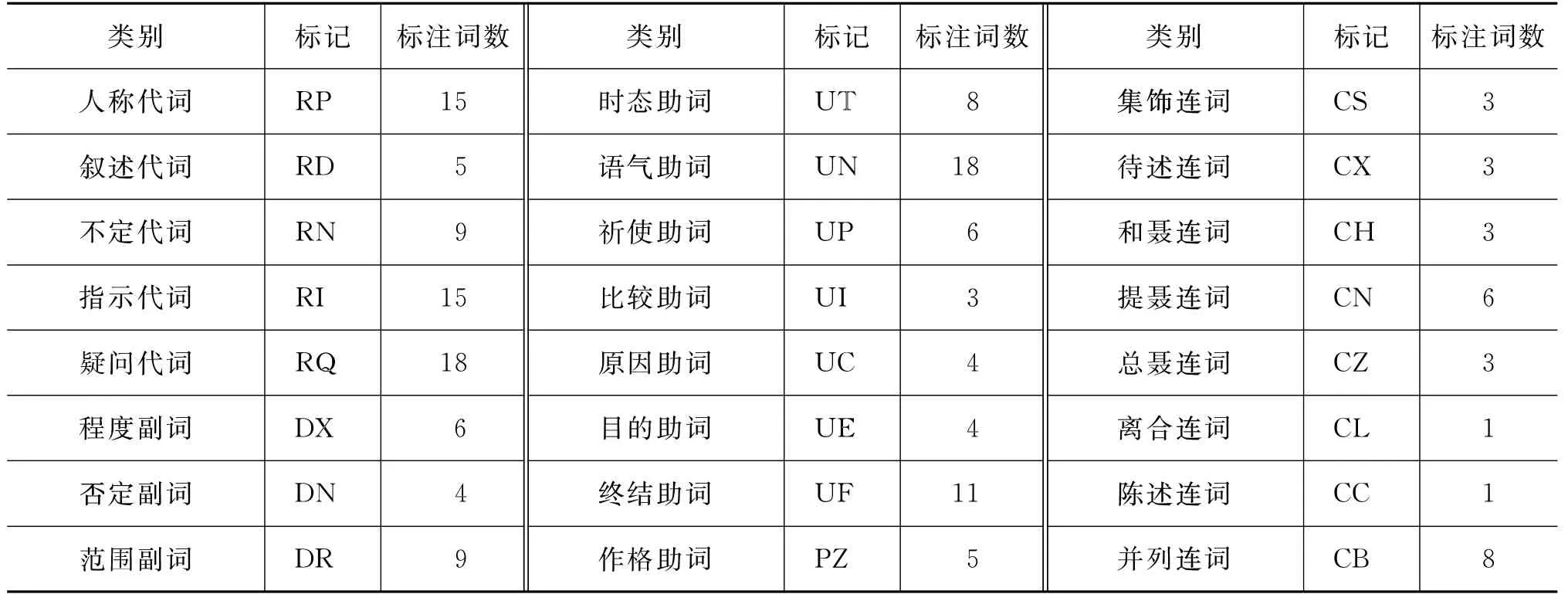
表1 固定標注庫
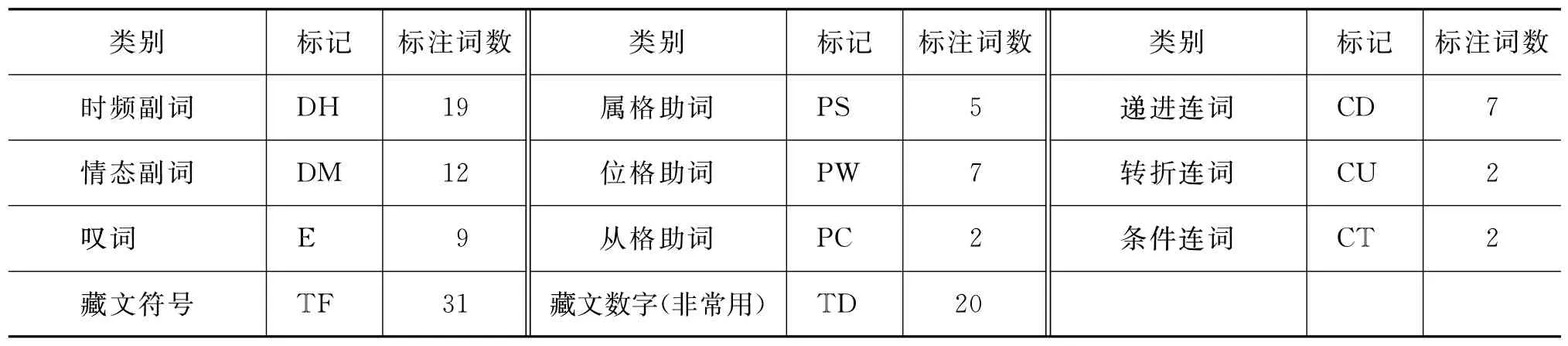
續表
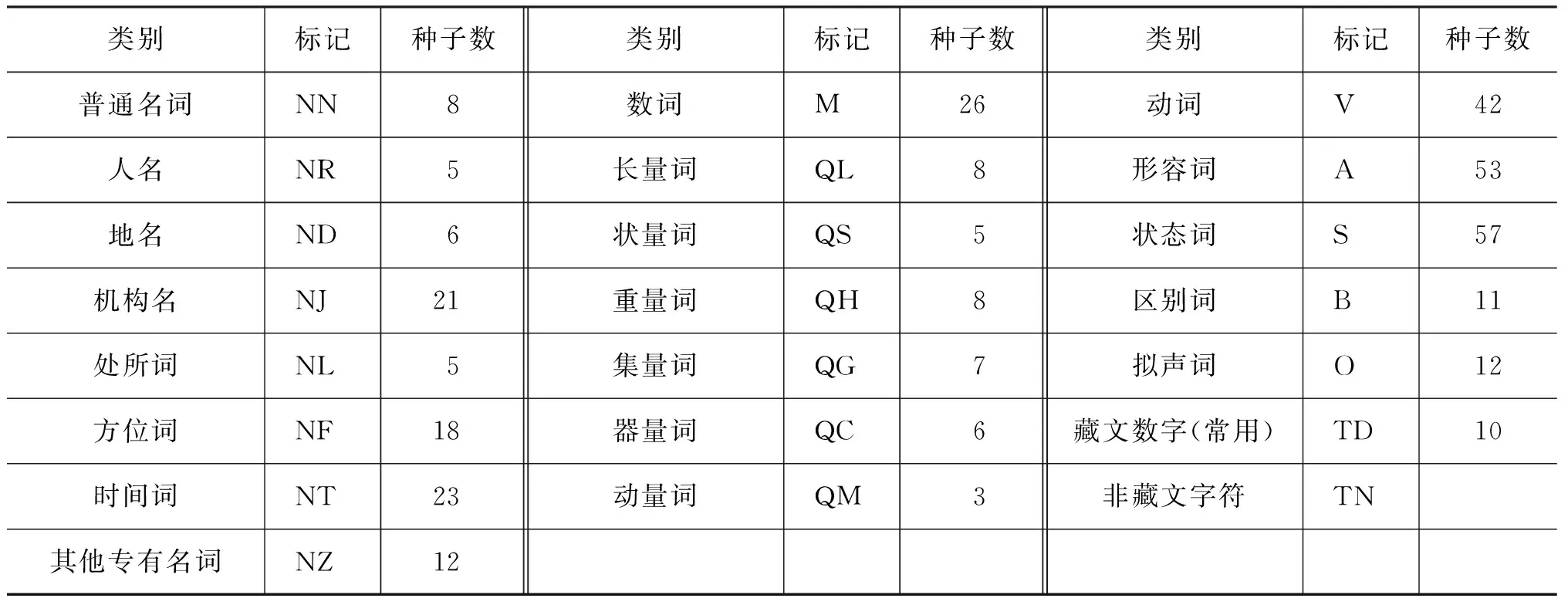
表2 粗切分標注庫
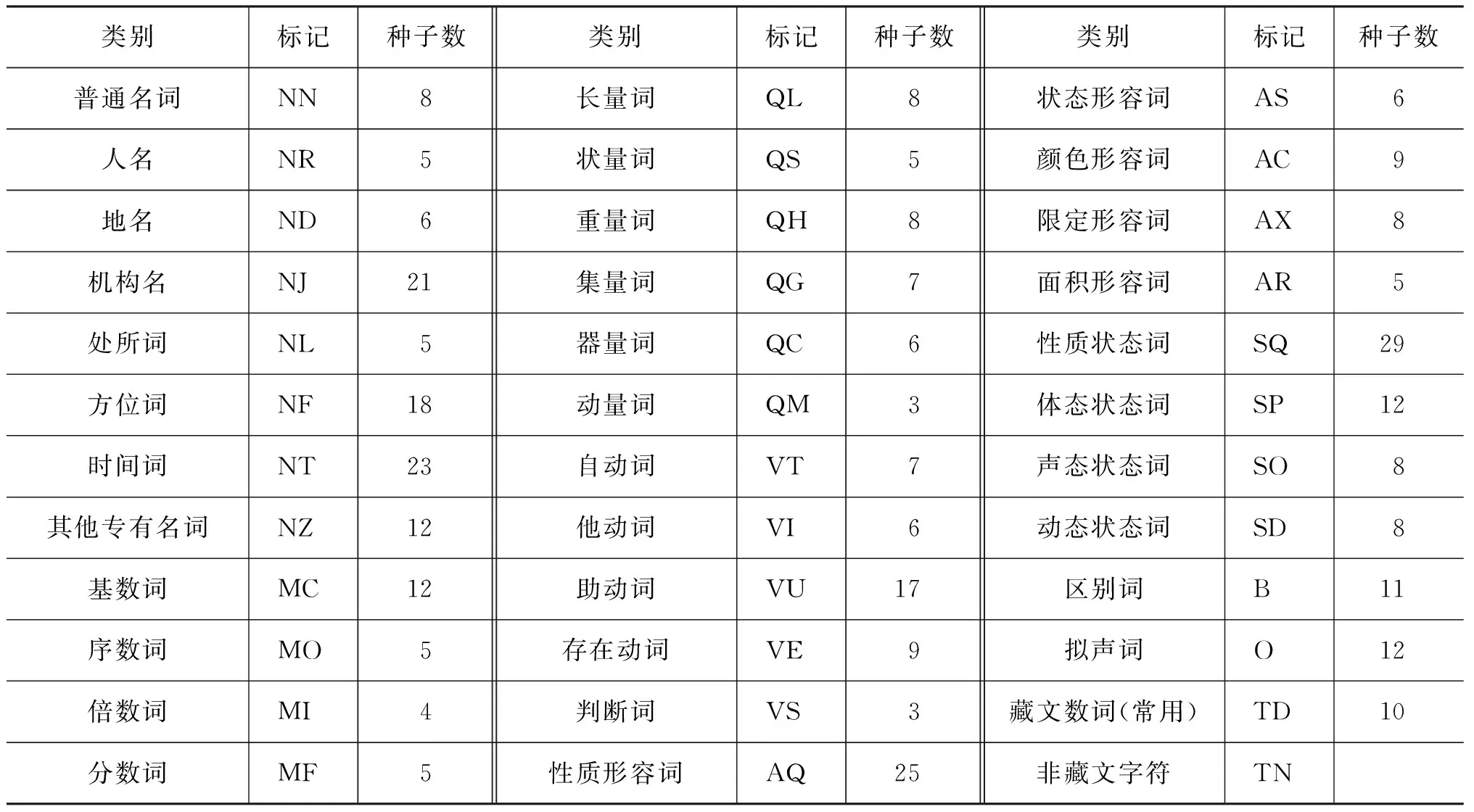
表3 細切分標注庫
3.2 標注庫擴充算法
Mikolov[10]通過三個詞向量的計算,例如,X=vector("king")-vector("man")+vector("woman")可以預測出"queen"的結果。本文提出的標注庫擴充算法利用詞向量的語義近似計算功能對種子庫中的詞語進行近似計算,進而得到擴充后的標注庫。算法的具體過程如圖1所示。

圖1 標注庫擴充算法
在標注庫擴充算法中,初始狀態下,含有已標記詞性的詞庫稱為種子庫。在種子庫中,每個詞性只將少數的典型詞作為種子,稱之為目標詞。算法執行過程中,遍歷種子庫中所有的目標詞,并通過詞向量對每一個目標詞進行語義相似計算。按照相似度計算值的大小降序排列,取出前n個相似詞,作為擴充詞的候選詞。遍歷所有候選詞,若該候選詞已存在于種子庫和固定標注庫中,則不添加到種子庫,否則就將該候選詞添加到種子庫中,并以目標詞的詞性來標注該候選詞。通過反復迭代,使得種子庫中所含已標記詞性的詞數量不斷地增加,直至迭代結束,可得到擴充后的標注庫。
3.3 詞性標注算法
詞性標注算法是通過固定標注庫、標注庫和語義近似計算相結合的一種標注方法。該算法中,首先輸入已分好詞的句子,然后遍歷句子中所有詞,判斷該詞是否存在于固定標注庫和標注庫中。若存在,則直接標記該詞語;否則,先將其作為目標詞進行語義相似計算,再確定其詞性。根據語義近似計算的結果降序排列,取出前n個詞,從計算值最高的詞開始,逐個與標注庫進行比對,一旦找到一個詞與標注庫中的詞相匹配,就用該詞的詞性來標注目標詞。最后,既不在固定標注庫和標注庫中,也不能通過詞向量的語義近似計算來標注詞性的詞,就用NULL來標記。
設句子集合:S={s1,s2,……,sn},其中si={w1/w2/……/wm}是詞序列組成的一個句子,n為句子的個數。X表示固定標注庫,Y表示標注庫,V表示詞向量,與上節表示方式相同。具體標注算法如圖2所示。

圖2 詞性標注算法
4 實驗及數據分析
4.1 實驗語料
實驗中使用的詞向量,是以2009年、2010年和2014年《西藏日報》的文本內容作為語料,經過斷句、分詞和特殊標點符號的處理之后,利用word2vec訓練得到。按照word2vec工具提供的skip-gram模型,在窗口大小5、迭代次數100、學習參數0.025的條件下,在50維度下完成訓練。
本文采用的測試語料是分詞后由人工標注的500條句子,并按兩種方案完成實驗。第一種方案中采用粗切分種子庫和固定標注庫相結合進行詞性標注;第二種方案中采用細切分種子庫和固定標注庫相結合進行詞性標注。其中固定標注庫共包含35個詞性,粗切分種子庫共包含22個詞性,細切分種子庫共包含36個詞性。
4.2 不同實驗方案下的結果對比
本次實驗采用了三個評測指標,分別為召回率、精確度和F1值。
4.2.1 實驗1
該實驗是粗切分種子庫和固定標注庫相結合的一種詞性標注方法。
(1) 固定語義近似詞數n=2,通過調整迭代次數來完成詞性標注。算法1的實驗參數如表4所示。
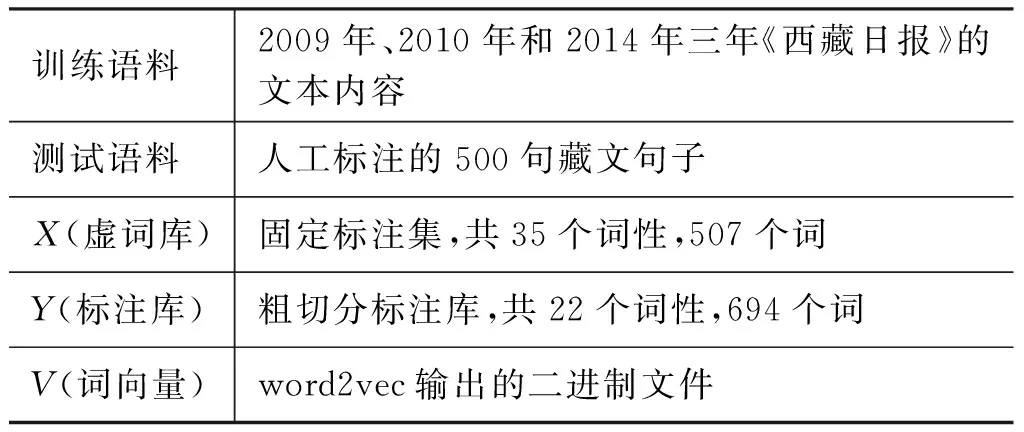
表4 方案1實驗參數設置
實驗中迭代次數t分別設為5、10、15、20;算法2的詞性標注結果如表5所示。
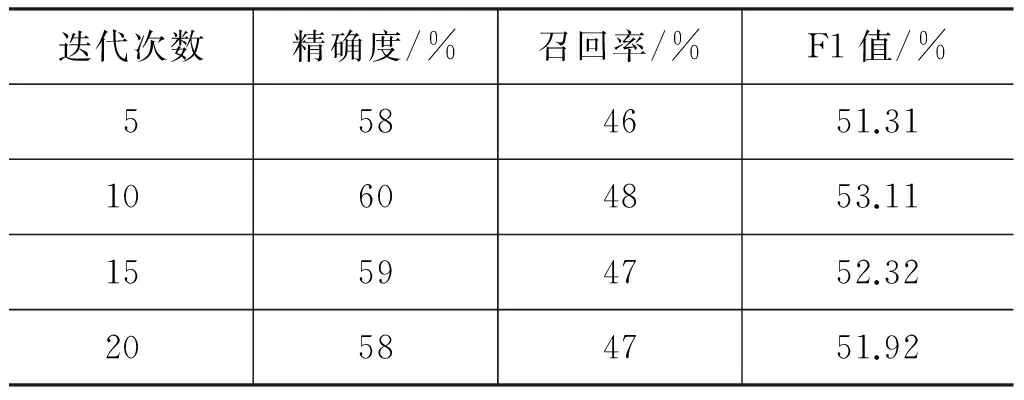
表5 不同迭代次數下詞性標注結果(粗分集+固定標注集)
從實驗結果可以看出,隨著迭代次數的增加,詞性標注的精確度和召回率均呈現出先增加后減小的趨勢,在迭代次數為10的情況下,F1值得到了最好的標注結果。
(2) 固定迭代次數t=10,通過調整語義近似詞數n來完成詞性標注,實驗中n分別設為1、2、3、4;算法2的詞性標注結果如表6所示。
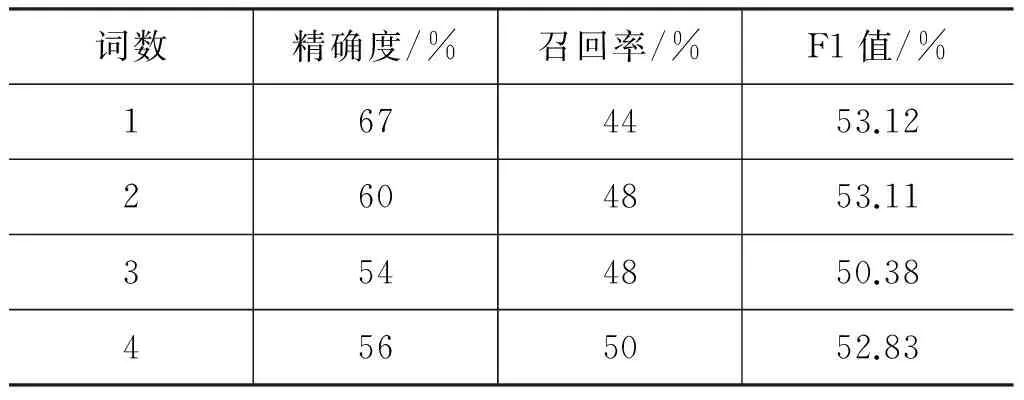
表6 不同近似詞組數下詞性標注結果(粗分集+固定標注集)
從實驗結果可以看出,隨著近似詞組數的增加,詞性標注效果精確度逐漸下降,召回率逐漸上升,在詞數為1的時候,F1值取得了最好的效果。
4.2.2 實驗2
該實驗是細切分和固定標注集結合的一種詞性標注方法。
(1) 固定語義近似詞數n=2的,通過調整迭代次數來完成詞性標注。算法1的實驗參數如表7所示。
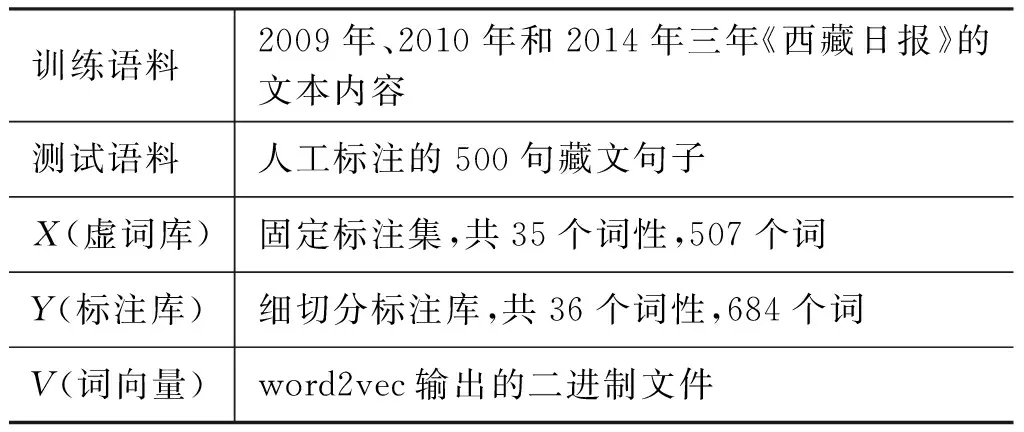
表7 方案2實驗參數設置
實驗中迭代次數t分別設為5、10、15、20;算法2的詞性標注結果如表8所示。
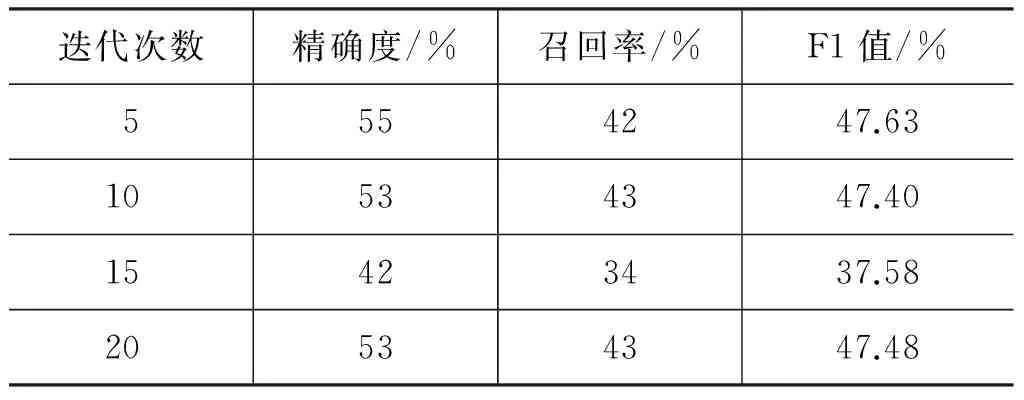
表8 不同迭代次數下詞性標注結果(細分集+固定標注集)
從實驗結果可以看出,隨著迭代次數的增加,詞性標注的精確度和召回率逐漸下降,且低于粗分集+固定標注集的結果。這是符合客觀規律的,標注集越細,區分難度越大。
(2) 固定迭代次數t=10,通過調整語義近似詞數n來完成詞性標注,實驗中n分別設為1、2、3、4;算法2的詞性標注結果如表9所示。
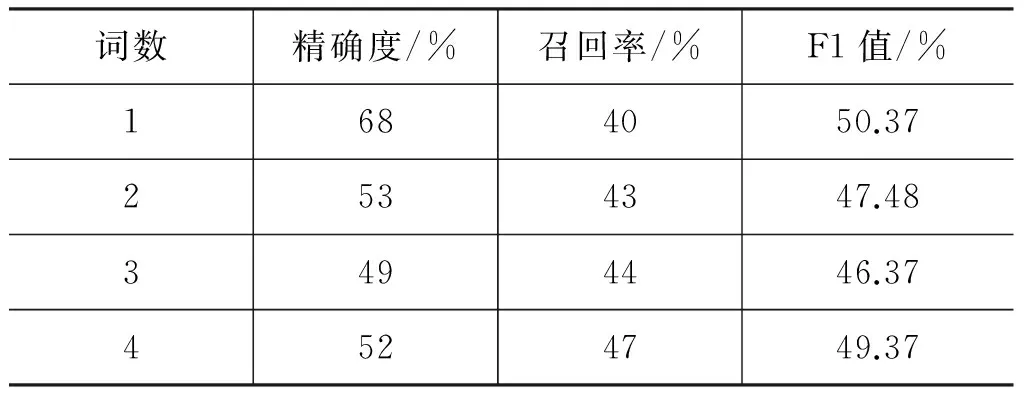
表9 不同近似詞組數下詞性標注結果(細分集+固定標注集)
從實驗結果可以看出,隨著n的增加,詞性標注效果精確度依然呈現出逐漸下降的趨勢,但召回率有所上升,整體F1值均低于第一種實驗方案。
由以上實驗可知,精確度最高可達68%,召回率最高值為50%。實驗整體上隨著近似詞數逐漸增大,迭代次數逐漸增加,呈現出精確度逐漸下降,召回率逐漸上升的趨勢。該實驗結果證明本文提出的方法對標注詞典擴展和詞性標注是行之有效的。
5 結論與展望
在充分研究現有藏文詞性標注方法的基礎上,本文提出了一種基于詞向量的藏文詞性標注方法。該方法首先利用詞向量的語義相似計算完成種子庫的擴充,然后結合已擴充的標注庫和語義相似計算對測試數據進行詞性標注。同時,分別以“粗分集+固定標注集和細分集+固定標注集”進行實驗,并將其結果進行了對比分析。
與現有的藏文詞性標注方法相比較,該方法不依賴大規模的詞典,擺脫了人工標注詞典耗時耗力的局限性,較好地解決了未登陸詞的詞性標注,為研究藏文詞性標注提供了一種新視角。但分析其標注結果,該方法還有很大的提升空間,離實際應用還有一定的距離。本文認為造成實驗結果偏低的原因主要有以下幾點:(1)訓練出來的藏文詞向量不是最好的,因此直接影響語義近似計算結果; (2)測試數據可能包含一些錯誤標注; (3)種子庫擴充時未考慮兼類詞的情況; (4)詞向量中未包含的詞語,無法獲得其向量表示,故不能進行近似計算。針對以上問題如何進行改進是我們今后研究的主要方向。
[1] 洛桑嘎登,趙小兵.藏文詞級處理研究現狀及熱點方法[J].電腦知識與技術,2015,11:183-185.
[2] Jiang D.Text-annotation Oriented Tibetan-Chinese Dictionary and Its Construction[C]//Proceedings of the 4thChina-Japan Joint Conference to Promote Cooperation in Natural Language Processing.(CJNLP-04),HongKong,2004:10-15.
[3] 才讓加,吉太加.藏語語料庫中詞性分類代碼的確定[C]//中文信息處理前沿進展-中國中文信息學會二十五周年學術會議論文集.北京:清華大學出版社,2006.
[4] 扎西加,珠杰.面向信息處理的藏文分詞規范研究[J].中文信息學報,2009,24(3):113-123.
[5] 蘇俊峰,祁坤鈺,本太.基于HMM的藏語語料庫詞性自動標注研究[J].西北民族大學學報:自然科學版.2009,30(1):42-45.
[6] 扎西多杰,安見才讓.基于HMM藏文詞性標注的研究與實現[J].計算機光盤軟件與應用.2012,12:100-101.
[7] 華卻才讓,劉群,趙海興.判別式藏語文本詞性標注研究[J].中文信息學報.2014,28(2):56-60.
[8] 于洪志,李亞超,江昆等.融合音節特征的最大熵藏文詞性標注研究[J].中文信息學報.2013,27(5):160-165.
[9] 康才畯.藏語分詞與詞性標注研究[D].上海師范大學博士學位論文,2014.
[10] T Mikolov,W T Yih,G Zweig.Linguistic regularities in continuous space word representations[C]//Proceedings of the NAACL-HLT,2013:746-751.
A Method of Tibetan POS Tagging Based on Distributed Representation
ZHENG Yanan1,ZHU Jie1,2
(1.Department of Computer Science,Tibetan University,Tibetan,Lhasa 850000,China;2.School of Information Science and Technology,Southwest Jiaotong University,Sichuan,Chengdu 610031,China)
Part of Speech (POS) tagging is fundamental to Tibetan processing,with a wide applications in Tibetan text classification,information retrieval,machine translation and other fields.This paper proposes a method of Tibetan POS tagging based on distributed representation.First,this method extends the dictionary by semantic approximation according to the distributed representation.Then the POS tagging is completed according to the dictionary and the semantic similarity.Experimental results show that this method can expand the dictionary with a better result.
distributed representation; Tibetan; POS

鄭亞楠(1992—),碩士研究生,主要研究領域為藏文信息處理、數據挖掘。E-mail:zs_zyn@yeah.net珠杰(1973—),副教授,碩士生導師,主要研究領域為藏文信息處理、數據挖掘。E-mail:rocky_tibet@qq.com
1003-0077(2011)00-0112-06
2016-06-01 定稿日期:2016-08-05
國家自然基金(61262058 );國家社會科學基金(15ZDB11);西藏高校青年教師創新支持計劃項目(QC2005_18);高原學者計劃—珠杰
TP391
A
猜你喜歡
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
開放教育研究(2020年2期)2020-03-31 01:54:14
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
發明與創新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
現代語文(2016年21期)2016-05-25 13:13:44
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
大連民族大學學報(2015年2期)2015-02-27 08:28:11
