
分布式實時日志密度數據流聚類算法及其基于 Storm 的實現
2017-05-02 22:39:06張輝王成龍王偉
中國新通信 2017年6期
張輝+王成龍+王偉
【摘要】 日志對于每個系統來說,都是不可忽視的一部分。現階段構建的日志分析平臺對數據的處理響應時間差較大,實時性不能得到保證,因此 提出了基于Storm 框架的實時日志密度數據流聚類算法RL-DSCA(Real-time Log density stream clustering algorithm)。該算法綜合了經典數據流聚類框架 Clustream和一種基于密度的聚類算法DBSCAN實現了多粒度的數據存儲。算法可以實現多線程并行的增量更新。設計RL-DSCA算法基于Storm 的實現方案,通過ELK進行實時數據采集,選用Kafka作為中間件實現數據緩沖,Redis存儲中間結果,最后部署 Storm 的拓撲對RL-DSCA算法進行實現。性能分析及實驗結果表明: Bolt線程數量的增加不會影響到聚類的效果,RL-DSCA算法達到了較高的精度。
【關鍵字】 RL-DSCA ELK Storm Kafka Redis 增量更新
一、引言
日志信息可以作為特定指標項的分析源來處理某些特定的信息,將日志數據作為原始數據,這樣有助于數據分析的準確性。但是日志數量巨大,如何準確、及時的篩選海量日志中的關鍵信息成為了亟待解決的問題。
聚類分析是處理數據流的常用分析手段,本文RLDSCA算法使用兩層聚類框架處理數據同時兼顧實時和歷史離線數據,并加入了DBSCAN算法處理可能出現的噪聲數據和非球形數據,并將其應用到Storm的計算架構。對Storm計算架構設計實驗從聚類精度和計算效率方面對RL-DSCA算法的有效性進行了驗證。
二、Storm計算框架
BackType開發了分布式計算系統Storm,并在2011年被Twitter開源,該系統能夠很容易可靠地處理無界持續的流數據,進行實時計算。
三、聚類算法分析
3.1 Clustream算法概述
數據流聚類框架Clustream在二十一世紀初被Aggarwal與Han 等人提出,該框架主要引入了兩個概念:簇和時間幀,將聚類過程分為了兩類:在線部分(微聚類)、離線部分(宏聚類)。在線部分實時處理新到達的數據,并周期性地存儲統計結果;離線部分就利用這些統計結果結合用戶輸入得到聚類結果。
微簇信息需要在特定時刻被維護,基本方法就是存儲中間結果以供離線階段查詢。實際的應用中,往往近期數據對結果的影響比較大,而對于歷史數據僅僅是對結果起到補充的作用,時間幀結構很好的解決了這個問題,它用來劃分時間軸并根據粗細程度的不同來區分不同的時刻。不僅滿足了用戶需求也滿足了內存的需求。
兩階段聚類框架,能適應數據流短時間涌入、有序無窮、單次掃描的特點,并挖掘數據流潛在的演化特征,但是對離群點的識別,非球形數據的聚類處理效果并不理想,有待改進。
3.2 DBSCAN算法概述
DBSCAN 是一種基于密度的聚類算法[1],它通過密度的高低劃分簇類,而且對簇類的識別不受噪聲數據的影響 [2]。DBSCAN 可以處理高維數據,有效的排除形狀大小不規則的簇和噪聲對象。
DBSCAN 對用戶定義的參數Eps和MinPts 很敏感,一般靠經驗確定[3]。.
四、RL-DSCA算法設計
4.1算法概述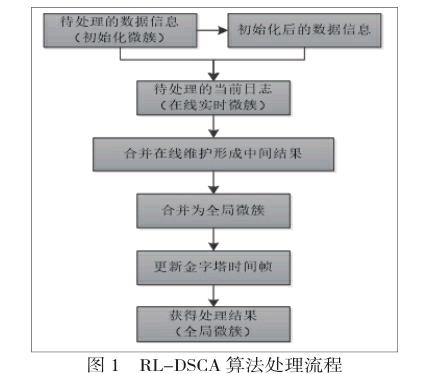
本文設計的分布式實時日志數據流密度聚類算法RLDSCA將 CluStream 算法和DBSCAN算法相結合。既體現了CluStream框架對流數據處理的優勢,又利用了DBSCAN算法克服了CluStream框架對非球形和噪聲數據聚類效果不佳的缺點。
微聚類部分分為兩大部分:微簇的實時日志增量更新(局部更新結果存放在Redis)和合并局部更新進行全局微簇增量更新,算法的總體處理過程如圖1所示。
4.2實時局部微簇增量更新全局增量
微簇的在線更新任務有多個節點負責并執行,節點流程圖如圖2所示。
聚類的過程一般分為兩個階段,首先對數據簇的形態進行識別,隨后對初始化的數據進行處理,其結果將被發送到BoltB中進行匯總。對核心點進行DBSCAN 聚類。按照DBSCAN 算法的思想,如果兩個簇的核心點是一類,那么這兩個核心點是互相直接密度可達的,它們代表的簇要歸為一類。通過遍歷篩選后,最終不屬于任何類的點則為噪聲對象。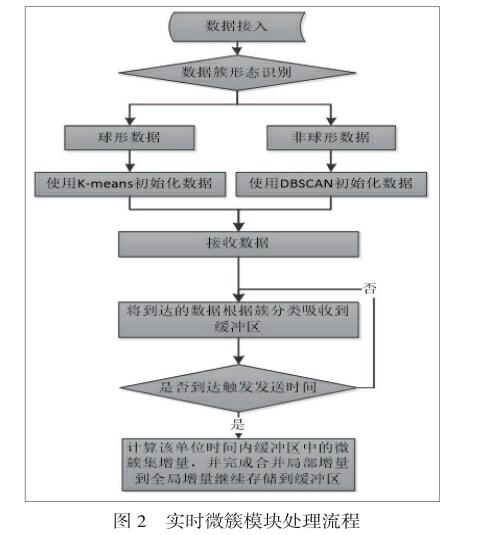
Storm 框架本身不負責計算結果的保存,在加入CluStream算法框架兩層模型和DBSCAN算法后,可以將中間局部增量結果存放在Redis中,以便合并為全局增量。
微簇的在線維護節點按照Strom滑動窗口觸發機制單位時間向合并節點發送在該單位時間內的增量。即發送在該單位時間內生成新微簇與舊微簇增量并將實時結果保存在Redis中。
五、RL-DSCA算法在日志綜合管理平臺的實現方案
5.1開發環境及采用的測試數據集
硬件環境包括Storm集群,Kakfa集群,Zookeeper集群,Storm包括1個Nimbus和4個Supervisor;Kafka集群包括5個節點;Zookeeper集群也包括5個節點,集體配置如表1所示。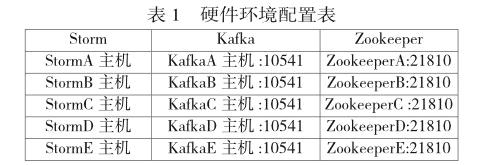
軟件環境:jdk-1.7.0_79、logstash-2.3.4、elasticsearch-2.3.4、storm-0.9.5、kafka_2.9.1-0.8.2.0
zookeeper-3.3.5、python-2.7.12。
操作系統:Linux version 3.10.0-327.el7.x86_64
數據集:用戶話單日志信息(約2 billon/day)。
5.2平臺架構及處理流程
日志綜合處理平臺主要由三層組成,包括:數據采集層、數據分析及存儲層以及數據展示層。可以實現對日志從采集到分析處理的全過程并在頁面監控平臺顯示。RL-DSCA算法在Storm平臺的Topology關系如圖3所示。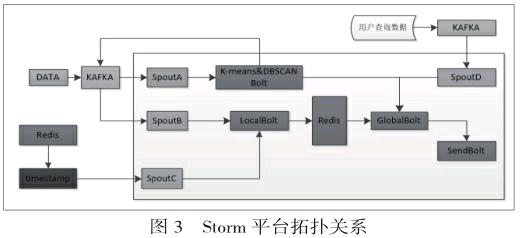
SpoutA接收待初始化的數據,并將其發K-means&DBSCANBolt 通過數據簇形態識別以初始化微簇;SpoutB從Kafka中接收初始化后待處理的流數據,將其發送至LocalBolt進行局部微聚類;SpoutC用作處理時間戳,每單位時間向LocalBolt發送一次信息,當接收到時間戳消息,將局部微聚類更新結果存放到Redis做實時局部微聚類更新結果的保存,并合并原有的增量信息發送到GlobalBolt;SpoutD通過消息中間件 Kafka接收用戶發送的查詢參數。
六、實驗結果分析
實驗主要針對RL-DSCA算法應用在Storm平臺上對Storm集群數據處理、RL-DSCA算法精確度、RL-DSCA算法實現效果三方面進行試驗分析。
6.1 Storm集群數據處理能力分析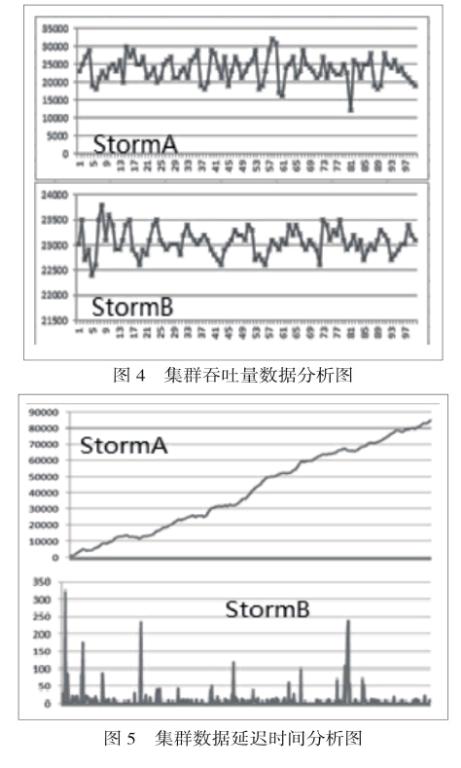
本實驗比較不使用RL-DSCA算法的Storm集群和使用RL-DSCA算法的Storm集群對同樣的數據量處理能力比較。為了方便比較將不使用RL-DSCA算法的Storm集群稱為Storm-A集群,使用RL-DSCA算法的Storm集群稱為Storm-B集群。首先對Strom-A集群進行數據分析。吞吐量和數據延遲分別如圖4和圖5所示。
由圖4和圖5大概分析可得集群A平均吞吐量在25000條/秒,數據延遲時間與時間正比增加,分析主要原因在于Bolt之間處理的速度隨著數據的大量涌入而變慢,數據量堆積,所以延遲增加。而改進后的Strom-B集群反而吞吐量下降到了23000條/秒,這是因為新算法的引進改變了集群的處理負載,使其更加均衡的分布在各個節點,這點從數據延遲就可以看出,大部分的處理延遲較小基本可以忽略,偶爾的延遲較大,分析其原因是由于多個任務由一個調度器來調度,數據流注入Spout并不規則,可能在某個時間發送Spout獲得大量數據并同時發送。但是數據延遲并沒有持續增加,并且在延時增加的一段時間內迅速恢復正常說明了短時間內大量涌入的數據能被集群及時的“消化”,從而側面證明了該算法提升了Strom集群處理性能。
6.2 算法精確程度分析
本節設計了對比實驗測試RL-DSCA算法的精度。首先對話單日志數據進行簇形態識別,球根據形態的不同而分別處理,為了穩定性本測試使用單機測試,單機運行K-means和DBSCAN算法,單機運行RL-DSCA算法,以及在 Storm平臺上分布式多節點( LocalBolt 線程數分別為1與4,同時Worker 數設為1與4) 運行RL-DSCA算法進行聚類,聚類簇數為30。測試多次取其平均值,數軸表示簇內各個數據點到中心點的平均距離。測試結果如圖6所示。
上述實驗結果表明,線程數的增加并沒有對算法的精確性產生大的影響,基本可以認定該算法的精確性與K-means算法以及DBSCAN算法一致。
6.3 算法實現效果分析
由于設計的RL-DSCA算法按照單位時間進行分布式聚類,并且按照單位時間合并中間結果,算法的處理速度與到達數據的流速有關。改變分布式 RL-DSCA算法的并行線程數,通過 UI界面觀測各線程的線程處理壓力( capacity)。
由測試結果可以看出,單個 LocalBolt 線程的處理壓力隨著線程數的增加呈倒數減小趨勢;而 GlobalBolt 線程的線程壓力隨著 LocalBolt 線程的增加呈近線性增加趨勢。該測試結果與理論一致。本文所實現RL-DSCA算法的簇內各點與簇中心平均距離相比K-means算法以及DBSCAN算法有稍微的差距, 但是差距微乎其微,考慮到RL-DSCA算法是一種動態算法,其性能遠高于靜態算法,切單點處理條數穩定,所以本文所實現的RL-DSCA算法有著明顯的優勢。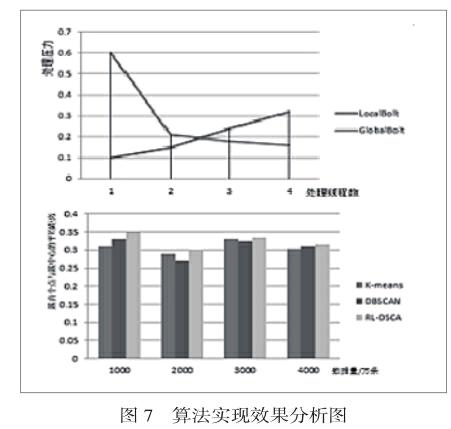
七、結束語
本文設計了一種分布式實時日志密度流數據聚類算法RL-DSCA,該算法綜合運用了流聚類算法CluStream和DBSCAN算法處理各類形態數據簇,并有效的屏蔽了噪聲數據,將RL-DSCA應用到流數據計算平臺 Storm 的計算架構中,引入了微簇的時間屬性參數和中間結果Redis緩存機制。對話單日志數據集的聚類實驗結果及性能分析表明了RL-DSCA算法在聚類精度和計算效率方面的優勢,也說明了RL-DSCA算法基于 Storm 的實現方案的可行性。
但是對數據簇形態的識別會出現誤差影響實驗結果的準確性,今后應在數據簇形態的識別中加強理論研究并應用到實際開發中。
參 考 文 獻
[1] 葉大田,張銳,錢翔.基于密度提取的細胞熒光圖像標識算法[J].清華大學學報:自然科學版,2013(1):129-132.
[2] 侯榮濤,朱斌,馮民學.基于 DBSCAN聚類算法的閃電臨近預報模型[J].計算機應用,2012,32(3):847-851.
[3] 潘淵洋,李光輝,徐勇軍.基于DBSCAN的環境傳感器網絡異常數據檢測方法[J].計算機應用與軟件,2012,29( 11):69-72.
