基于R的圖書館用戶借閱行為數據挖掘研究
2017-05-10 07:24:10侯松霞
創新科技 2017年2期
關鍵詞:數據挖掘
侯松霞

[摘 要] 本文針對圖書館數據低效利用的現狀,采用了基于R的數據挖掘技術對圖書館借閱數據進行了深入挖掘,以期發現這部分數據所隱含的價值。通過數據挖掘從借閱數據中探索其中隱含的規律,并將挖掘出的規律信息進行實際應用,從而實現數據挖掘對數據中價值的發現和高效利用。
[關鍵詞] R;圖書館用戶;借閱行為;數據挖掘
[中圖分類號] TP311 [文獻標識碼] A [文章編號] 1671-0037(2017)2-91-6
Data Mining Study of Library Users' Borrowing Behavior based on R
Hou Songxia
(Tianjin Transportation Vocational College, Tianjin 300112)
Abstract: The article aims at the status of inefficient use of library data, adopts R based data mining technology, and deeply evacuates the borrowing data of library, hoping to find the implied values of the data. In order to complete the efficient use of the value of the data by data mining, we explore the implied laws of the borrowing data by data mining and apply the mined laws into practical application .
Key words: R; library users; borrowing behavior; data mining
1 引言
評判一個圖書館服務水平的基本標準應當是借閱者的借閱需求滿足情況。為盡可能滿足借閱者的借閱需求,圖書館需要在館藏文獻管理及對借閱者提供個性化服務兩個方面做出努力。因此,需要通過對用戶借閱行為進行深入的數據挖掘,得到更加接近真實的用戶需求情況。通過對用戶的借閱興趣、借閱習慣進行分析總結,在預測未來的借閱行為的基礎上,發揮圖書館對用戶的引導教育作用。
2 圖書館用戶借閱行為分析數據特點
圖書館的服務對象主要可以分為:教師和學生。根據專業的不同,又可以進一步細分,如學生用戶可以進一步細分為理工類學科與人文社科類學科等。顯然,各類用戶群對信息的需求層次差異很大,同一用戶群中不同專業的用戶信息需求也存在較大差異[1]。圖書館用戶的學科專業性非常明顯,信息需求主要集中在與專業領域緊密相關的專業文獻上,不同專業的用戶需求差異十分明顯,可以根據挖掘數據的結果進行分析,將書籍的擺放位置和書籍的數量進行調整,而相同專業的用戶也具有相近的興趣度,可以通過數據挖掘技術對各個用戶的借閱行為數據進行挖掘,并對挖掘結果進行專業性的分析,針對各個用戶的相似性開展大量的個性化服務。
3 挖掘過程
3.1 數據挖掘目標的確定
本文數據挖掘采用R語言,其目的是根據圖書館用戶借閱行為的數據來得到用戶的借閱習慣、借閱特點等,最終實現對館藏文獻的優化管理及對借閱者提供個性化服務[2]。挖掘工作的重點應該是分析并獲取:1.用戶類型及各自類型的借閱特點;2.不同種類圖書的利用率。
3.2 數據獲取
在用戶利用圖書館的資源過程中會留下諸如讀者基本信息、借閱歷史、檢索歷史等大量的有價值信息,這就是我們進行數據挖掘的數據來源,通過對用戶信息和借閱歷史的挖掘來得到我們需要的信息。
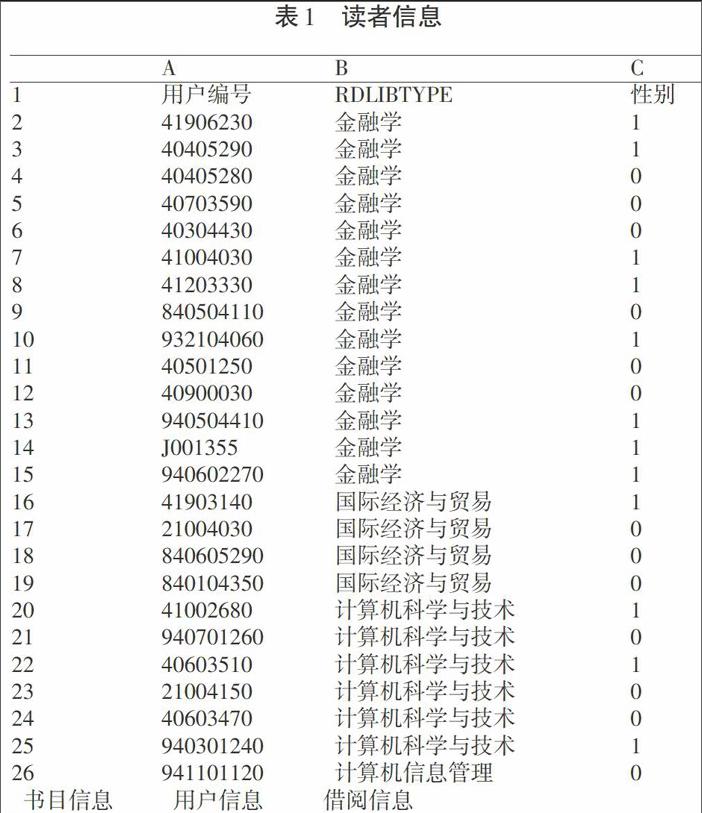
3.2.1 讀者信息。讀者的具體身份信息作為數據挖掘中的一項基礎數據。主要用來為用戶分類、借閱行為分類聚類提供信息,由于數據量龐大,在預處理時需刪掉無用的數據,保留本次挖掘所需數據,如用戶編號、專業、性別屬性,如表1所示,本文針對某圖書館近幾年的圖書借閱情況進行挖掘。
3.2.2 書目信息。書目信息與用戶信息類似,是所有館藏書目的一個數據庫,主要包括書目名稱、書目編號、出版社、所屬類別、類別編號、館藏位置、入館時間、下架時間等屬性。通過預處理后,所選擇的有效數據如表2所示。
3.2.3 讀者借閱記錄。讀者借閱歷史記錄主要包含了借閱的目標信息(書籍數據)、時間信息及連接信息(編號數據),如表3所示。其中目標信息的主要組成部分為書籍的屬性信息;時間信息的主要內容包含借閱書籍的起止時間信息;聯系信息主要內容為用戶編號等起聯系作用的信息[3]。但是這三種信息不應該被撕裂開來,而應該是呈相互關聯、缺一不可的關系。在這里主要為方便敘述將其分為三類:
第一,目標信息。目標信息是進行聚類分類的重要核心數據,主要通過用戶編號與用戶信息進行連接從而進行數據挖掘。在此只截取數據中書名及圖書編號等數據進行概化后用于數據挖掘;
第二,時間信息。時間信息對于數據挖掘的主要意義是進行時間序列的分析,其主要內容包括借閱時間、歸還時間等;
第三,聯系信息。聯系信息則為用戶編號等起聯系性作用的數據。這部分信息是利用數據挖掘技術獲取圖書館文獻利用狀況的關鍵,通過對它們的統計、歸類、分析有助于了解書刊的使用情況并進行預測分析同樣需要通過基于屬性的歸納算法進行數據概化。最后得到的主要屬性有圖書主題、圖書編號、借閱時間段、借閱時長。
3.3 數據預處理
從圖書館得到的用戶數據往往十分雜亂,結構化進行的并不完全,而且存在大量的無效信息。因此需要對其數據進行預處理。
經過預處理后的數據結構如表4所示。
3.4 挖掘過程
根據指導圖書館實現其館藏文獻優化目標及給借閱者提供個性化推薦的目標,對具體的挖掘任務進行分配。根據借閱行為的主體及客體,我們將挖掘分為三個大的環節[4]。首先是對整體數據的大的挖掘,即得出高頻借閱者和高頻書籍,通過這一步驟的挖掘,我們會對于整體的數據結構有直觀的理解。其次是對館藏文獻的挖掘。對文獻的挖掘,要考慮時間要素、優質資源、待下架資源這三方面的信息。最后是對于借閱者的需求信息的挖掘,其目的是挖掘出讀者的不同需求。
3.4.1 據概覽。通過對多個數據集的聯立(merge()函數)得到了數據的整體情況。經過對預處理數據進行簡單的統計,其中借閱記錄10 342條,借閱者編號(人數)3 321個,圖書編號4 032個。如圖1所示。
然后對數據中的用戶和書目進行統計,發現國際經濟與貿易,金融學,成教院,信息管理與信息系統,計算機科學與技術和數學與應用數學專業的同學借閱量最多,然后將所有出現次數前5的單位單獨導出,作為后續分析中的重點挖掘對象。同理導出被借閱書籍最多的種類,作為向學校推薦加強館藏建設的重點內容。如圖2所示。
3.4.2 挖掘文獻使用規律
圖書館的文獻被借閱情況,其往往表現出一定的規律性。
第一,對時間要素的挖掘
在時間序列上,往往表現在特定時間的某種類型書籍被大量借閱,而突然增大的借閱量必然會影響圖書館的服務質量。所以通過對時間要素的挖掘,我們可以對圖書館在借閱量增加的時候對圖書館的工作情況進行適當的調整。如圖3所示。
經過觀察發現數據集中在2011年的11月,因此時間序列上以天數為劃分標準,然后利用table()函數及plot()函數來繪制出不同月份圖書借閱量的圖表。以便于直觀地對借閱量的月度變化進行掌握。通過對圖書館不同月份借閱量的對比,我們可以根據圖4看出,在該月,圖書借閱量隨著時間變化呈現出明顯的規律性變化,整體呈現出波動性變化。再結合周度記錄的圖表圖5,可以得出圖書館的借閱活動相對高峰期出現在每周的周二前后,并且在周五前后將出現一個較明顯的低落,經過分析后判斷出這種規律性變動,主要是因為學校在課程安排以周為單位。很多同學會在新的一周開始時接到教師安排的新的學習任務,為了滿足專業性的知識需求,會在周一之后開始去圖書館借閱書籍,這直接導致了周二前后借閱高潮的出現。在經過一周的學習后,面對即將到來的周末,由于周末休息時間較長,部分讀者利用周末安排了外出游玩等社交休閑活動,因此借閱熱情減退,這也導致了周五前后的借閱量低潮的出現。
第二,對優質資源的挖掘。圖書館中存在著大量的優質資源,這些優質資源常常處于被借閱的狀態,但是在實際流通中其表現出的流通率卻并不高,因為這些資源經常被同一用戶反復借閱[5]。這就為我們挖掘出這一部分優質的資源埋下了巨大的障礙,因為既不能單純以流通率來判斷(部分書籍可能因為封面設計吸引眼球而被頻繁借閱,但質量并不足夠優質),也不能單純以被借閱時長來判斷(部分書籍被借走但卻長期停留在書架上)。
因此,在篩選出優質資源時需要考慮多個參數的影響:a.平均借閱時間;b.被借閱次數;c.重復借用率。在這三個參數都滿足閾值的記錄時應該基本滿足優質資源的標準。但是,因為這種篩選方法在閾值這個門檻上將大量的新進書籍排除在外,所以還需要再進行重新考慮。為尋求更合適的篩選方法,我們可以通過聚類分析的方法來進行初步的探索(即對新進書籍與歷史書籍進行聚類分析)。
第三,對待下架資源的挖掘。在獲取了優質資源目錄的同時,我們還需要對圖書館中的陳舊資源進行清理,以避免部分類新購進書籍因為書架資源有限而無法陳列出來。對待下架資源的挖掘需要考慮兩方面的因素:1.新增加的書籍數量,這是驅動對待下架資源挖掘的動力;2.文獻的被借閱量,這是評判一本書籍是否需要下架的主要因素。
因為文獻使用的量是動態變化的,所以通過數據挖掘對歷史數據的分析,獲取平均上架數量對于圖書館的優化館藏排架結構十分重要。新增書籍的數量可以通過書目記錄信息獲得,而流通數量可以通過以下方式獲得:首先利用往年相同時期的流通數量變化情況,特別是在高校圖書館,由于院系課程進度的原因,會出現周期性學生大量借閱同類書籍文獻的現象,利用這一已知規律,可以很方便地來推算當前流通數量。當然這有一個前提,就是該類書籍必須具有這種周期性變化,在這里可以使用回歸分析、時間序列分析的方法來獲取這些規律。當某類圖書不存在周期性借閱起伏時可以利用其回歸曲線的變化趨勢來分析,如果曲線歷來比較平穩,說明這類書籍的在館率比較穩定,而如果偶然出現一次高峰,我們可以向上文一樣通過關聯挖掘獲取其當時借閱量突增的原因。
第四,挖掘用戶特點。通過對借閱者與借閱記錄的聯合挖掘,可以得出大量的用戶需求信息,而這些需求信息,是指導圖書館實現其館藏文獻優化目標及給借閱者提供個性化推薦的重要指導。要實現對這些聯合信息的挖掘,我們需要頻繁使用到關聯規則的挖掘,因此在此進行較為具體的描述。我們主要采用的是購物籃分析(Market Basket Analysis)[6]。購物籃分析是通過顧客購物時的籃子內的商品所顯示的信息來研究顧客的購買行為,通過這些信息,可以了解到不同顧客的不同需求以及需求的原因,從而得到一定的規律。主要的目的在于找出什么樣的東西應該放在一起,并藉由這些規則的挖掘獲得利益與建立競爭優勢。這種思路對于我們進行圖書的個性化推薦具有重要參考價值。我們可以通過對借閱者借閱記錄中的書籍進行匯總,進而形成每個借閱者的“數據籃子”,然后對眾多的“數據籃子”進行匯總,通過apriori算法,對其進行相關性的挖掘,然后對形成的關聯規則進行排序,將其中聯系性較強的數據進行推廣利用,主要的目的在于推斷借了某本書的人還會借閱哪本書,并藉由這些信息來實現對讀者的個性化推薦。
關聯規則的挖掘包括兩個階段的工作,首先是對于資料的整理,因為一般的數據集需要經過整理符合其算法的需求才可以進行下一步的輸入處理。在此過程中,主要利用as(transactions,數據集名稱)函數將一般性的數據轉換為購物籃類型的數據。如圖6所示。
其次,就是具體的關聯過程。是從資料集合中找出所有的高頻項目組,在圖書館用戶行為數據挖掘中,使用關聯規則挖掘技術,對數據庫中的紀錄進行資料挖掘,首先必須要設定最小支持度與最小信賴度兩個門檻值。符合此需求的關聯規則將必須同時滿足以上兩個條件。最后,再由這些高頻項目組中產生關聯規則,若經過挖掘過程所找到的關聯規則(如「專業,書目類別」),滿足設定最小支持度與最小信賴度兩個門檻值,將可接受該關聯規則。因此,今后若有某讀者已確定某一相關要素,則圖書館將可推薦該讀者借閱某一類書籍。如圖7所示。
在對整體數據進行關聯分析之后,又對不同類別數據(如金融系等)進行了多次重復性關聯之后[7],我們得出很多的結論,如通過對整體數據挖掘發現借閱計算機類圖書的讀者往往會再借閱一些文學性的書籍,而對管理學專業的挖掘表明,管理學學生的借閱內容范圍往往十分廣泛,不易形成關聯規則(支持度往往不高),這些結論對于圖書館的館藏內容進行優化就具有比較明顯的作用,而且根據得出的具體關聯規則,還可以在進行圖書推薦時針對不同院系的學生進行相對個性化的推薦。
4 結語
因為本次挖掘完全依賴數據驅動,只是根據數據內容上挖掘出需要的規則,所以源數據的準確性完全決定了本次挖掘準確性,但是部分的數據挖掘過程因為數據量太小,僅為幾百條,所以進行個性化推薦的挖掘中得出的結論可能會受此影響。與此同時,我們只是對源數據進行了挖掘,對于源數據的準確性并未深究,所以,本次挖掘結果并不一定與實際情況吻合。通過數據挖掘這一工具,我們得到的用戶模型必定與事實存在著一定的差異。因此,將模型與實際情況進行驗證,并進行適當的調整應當是提高挖掘結果準確性的一種重要思路。
參考文獻:
[1] 李賢虹.基于數據挖掘的讀者個性化信息服務系統的研究與設計[D].南昌:南昌大學,2009.
[2] 譚云江.基于數據挖掘技術的高校圖書館讀者行為研究[J].圖書情報工作,2012(S).
[3] 艾金勇.圖書館讀者借閱行為的關聯規則挖掘研究[J].情報探索,2017(1):40-43.
[4] 陳靜榮.圖書借閱分析系統的數據挖掘技術[J].農業圖書情報學刊,2017(2):69-72.
[5] 陳潔.數據挖掘在高校圖書館服務中的應用探析[J]. 大學圖書情報學刊,2016(2):53-57.
[6] 陳麗芳.基于Apriori算法的購物籃分析[J].重慶工商大學學報(自然科學版),2014(5).
[7] 郝海濤.關聯規則的數據挖掘在圖書館系統中的應用[J].信息通信,2016(6):74-76.
猜你喜歡
艦船科學技術(2022年14期)2022-09-22 03:10:36
大眾投資指南(2021年35期)2021-02-16 01:06:26
中國交通信息化(2020年1期)2020-07-27 02:50:04
電力與能源(2017年6期)2017-05-14 06:19:37
中國中醫藥信息雜志(2016年7期)2016-12-01 06:07:55
信息通信技術(2015年6期)2015-12-26 01:16:46
西安工程大學學報(2014年2期)2014-02-28 18:03:05
河南科技(2014年23期)2014-02-27 14:18:43
電子設計工程(2014年18期)2014-02-27 12:00:13
電子設計工程(2014年18期)2014-02-27 12:00:12
