回眸大數據
2017-05-12 03:37:20王國強吳秋月
張江科技評論 2017年2期
■文 /王國強 杜 影 吳秋月
王國強,中國科協創新戰略研究院研究員。
杜影,吳秋月,中國科協創新戰略研究院研究助理。
大數據革命的歷史是人類認知世界、改造世界的一個縮影。
在2011年麥肯錫公司發布《大數據:下一個創新、競爭和生產力的前沿》研究報告、高德納公司發布《2011年度新興技術成熟度曲線》研究報告之后,經2012年英國牛津大學教授維克托·邁爾-舍恩伯格(Viktor Mayer-Sch?nberger)所著《大數據時代:生活、工作與思維的大變革》一書的宣傳推廣,大數據概念(Big Data)迅速風靡全球,一夜之間“火”了起來,成為科研機構、高校、企業、政府部門等各界的“新寵”,但其中也不乏質疑的聲音。
近年來,隨著大數據技術的成熟,大數據產業已經升級為國家戰略。當前,德國“工業4.0”、美國“創新戰略”、英國“農業技術戰略”、日本“復興戰略”、韓國“智慧首爾2015”以及我國《“十三五”規劃》都把開發運用大數據作為奪取新一輪競爭制高點的重要抓手,大數據時代已真正來臨。回眸大數據的形成與發展,我們可以看到,大數據革命的歷史同樣是人類認知世界、改造世界的一個縮影。
大數據概念的前世今生
任何概念都是人類長期認知活動的結晶。大數據作為一個術語的歷史雖然短暫,但是大數據概念的形成與發展卻源遠流長。顧名思義,大數據本質上還是數據。要理解大數據概念,就要知道什么是數據。所謂數據,簡單地講,就是用符號化的方式表達和記錄信息,而語言、文字、數字和數學符號則是這種信息表達方式最早、最重要的形式,其中數與數據的關系最為密切。
信息從直覺表達開始到抽象表達體系的形成是一個漫長的過程。從語言的出現到文字的形成,歷經3萬多年,才搭建起人類認識現實世界和自身存在的“信息”框架。人類語言系統的發展,特別是文字書寫系統的誕生,大大提高了人類的認知能力,有效記錄了不同時期人類之間相互交流、交際的信息,形成了當今龐大的人類認知的知識集合——人類的文化世界。
同樣,從人類的原始計數方法的產生到數字符號的出現,再到現代數學符號體系的形成,也經歷了一個漫長的過程。計數是人類對數的認識的第一次抽象,在人類的蒙昧時期,中國古人有“結繩記事”和“刻痕記數”。在公元前8000年至公元前3500年間,兩河流域有蘇美爾人的計數泥板。在人類漫長的生產勞動和生活實踐中,由于“有無”“多少”“大小”“得失”等量的表達需要,出現了數和量的概念,這是人類關于數的認識的第二次抽象。公元前四五千年,尼羅河流域的古埃及人創造了十進制象形文數字,兩河流域的蘇美爾人和巴比倫人創造了六十進制的巴比倫數字。二進制的發現則較晚,是近代科學的產物。18世紀初,德國著名哲學家、數學家戈特弗里德·威廉·萊布尼茨(Gottfried Wilhelm Leibniz)發現了用“0”和“1”兩個數字表示的二進制數制運算規律。1854年,英國數學家喬治·布爾(George Boole)借鑒了二進制的運算規則,把形式邏輯轉化為一種代數運算,建立了布爾代數,為第三次科技革命重要標志之一的計算機的發明與應用奠定了理論基礎。
隨著計算機應用的不斷發展,各種各樣的信息都可以用“0”和“1”表示,從而把信息變成了一種可以存儲、復制、運算、判斷的數字化信息,這就是現代意義上的數據概念。在計算機普遍使用的今天,數以及可以轉換成數字的圖形、表格、文字都是數據的組成部分。數據概念不再僅僅用于表征事物的特定屬性,更為重要的是它已成為推演事物運動、變化規律的重要依據和基礎。
大數據概念發展史
1944年
美國衛斯理大學藏書樓管理員弗萊蒙特·雷德(Fremont Rider)預測,圖書館的藏書量將超出人們的管理能力。

1964年
哈 里·格 雷(Harry Gray)和亨利·拉斯頓(Henry Ruston)在《電子計算機學報》上發表文章表達了對知識快速增長的擔憂。

1975年
1975年,日本郵電部實施“信息流普查”計劃,調查報告預言了“碎片化信息時代”的到來。
大數據概念是人們在對數據的規模、結構、速度不斷變化的認識過程中形成的。隨著人類行為的日趨復雜而規模不斷擴張,人們一直坐擁不斷增長的海量信息,同時也面臨信息保存處理難的社會問題。1944年,美國衛斯理大學藏書樓管理員弗萊蒙特·雷德(Fremont Rider)認為,美國高校藏書樓的規模每16年就會翻一番,圖書的數量將超出人們的管理能力。1961年,科學計量學奠基人普賴斯(Derek John de Solla Price)通過研究科技期刊和論文得出,新期刊的數量將以指數形式增長而不是以線性形式增長,每15年翻一番,每50年以10的指數倍進行增長。1964年,哈里·格雷(Harry Gray)和亨利·拉斯頓(Henry Ruston)在美國電氣與電子工程師協會(IEEE)雜志《電子計算機學報》上發表文章表達了對知識快速增長的擔憂,并建議:“不發表或發表不超過2 500字的文章以應對信息爆炸時代的到來。”
1975年,日本郵電部實施“信息流普查”計劃,其后的調查報告指出,社會正在進入一個新階段,在這一階段,處于優勢地位的是那些能夠滿足個人需求的碎片性的、更為詳細的信息,而不再是那些傳統的被大量復制的、一致性的信息。報告預言了“碎片化信息時代”的到來。1980年,美國社會思想家阿爾文·托夫勒(Alvin Toffler)在《第三次浪潮》中前瞻性地指出,20世紀80年代計算機數據處理能力的大幅度提升將給人類社會帶來革命性的影響,并預言說:“如果說IBM公司的主機拉開了信息化革命的大幕,那么‘大數據’才是第三次浪潮的華彩樂章。”1997年,美國國家航空航天局的研究人員邁克爾·科克斯(Michael Cox)和戴維·埃爾斯沃思(David Ellsworth)首次在論文中正式提出大數據概念及其存儲所帶來的被稱之為“大數據問題”的問題,標志著大數據概念初步形成。
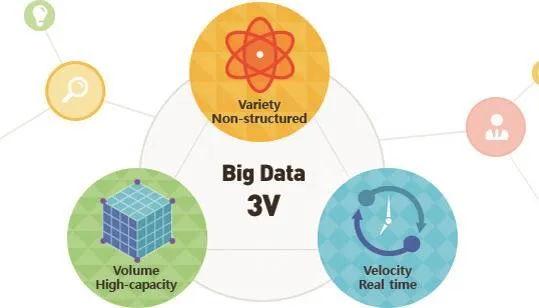
2001年,高德納公司分析師道格拉斯·蘭尼(Douglas Laney)把大數據的特征概括為3個“V”:Volume(數據體量大)、Velocity(高速處理速度快)、Variety(數據類型繁多),進一步揭示了大數據多樣性、多變性的數據特征。2008年,《自然》(Nature)雜志推出了名為“大數據”的專欄,“大數據”開始成為互聯網技術行業中的熱門詞匯。2011年,麥肯錫公司發布《大數據:下一個創新、競爭和生產力的前沿》,首次談到大數據的采集與應用,大數據開始走出技術圈進入商業圈。2012年,舍恩伯格出版《大數據時代》一書,開大數據系統研究之先河,大數據概念開始在社會上廣泛流行。
互聯網、社交網絡、電子商務和移動互聯網的快速發展,使人類社會的數據量呈現井噴式爆發性增長。據統計,目前人類一年產生的數據相當于人類進入現代化以前產生數據的總和。特別是社交媒體的出現,使這種快餐式碎片化海量信息“數據豐富而信息貧乏”的問題更加突顯。據中國互聯網絡信息中心的數據顯示,2016年下半年用社交媒體獲取新聞資訊的用戶比例高達90.7%,微信、微博參與新聞評論的比例分別為62.8%和50.2%,朋友圈、微信公眾號轉發新聞的比例分別為43.2%和29.2%。2013年,IBM公司在白皮書《分析:大數據在現實世界中的應用》解析說明會上提出大數據“4V”理論 :即Volume(數據體量大)、Velocity(高速處理速度快)、Variety(數據類型繁多)、Value(價值密度低)。大數據概念最終取代了數據概念,形成了當前意義上的數據概念,即所涉及的數據量規模巨大到無法通過人工,在合理時間內獲取、管理、處理并整理成為人類所能解讀的信息。
1980年
美國社會思想家阿爾文·托 夫 勒(Alvin Toffler)在《第三次浪潮》中指出,大數據是第三次浪潮的華彩樂章。
1997年
美國國家航空航天局的研究人員正式提出大數據概念及其存儲所帶來的被稱之為“大數據問題”的問題,標志著大數據概念初步形成。

2001年
高德納公司分析師道格拉 斯·蘭 尼(Douglas Laney)把大數據的特征概括為3個“V”,揭示了大數據多樣性多變性的數據特征。
大數據技術的發展歷程
社會的需求永遠是技術發展的動力,大數據技術也是如此。所謂大數據技術,就是處理“海量數據”的技術。它是在人們不斷解決“數字化信息問題”“海量信息問題”“非結構海量信息問題”等社會需求中逐漸產生發展起來的,大體上可分為3個階段:大數據技術前期、大數據技術形成期和大數據技術突破期。
計算機的發明與應用要求人們把事物信息轉化為可計算、可度量、數字化的數據。從20世紀50年代到90年代初,隨著1946年第一臺數字電子計算機ENIAC的誕生和發展,人們開始普遍使用二進制中“0”和“1”兩個數字來表達信息,采用電子線路來執行算數運算、邏輯運算和儲存信息。大量用“0”或“1”代表的信號反過來又產生龐大快速的數據流,由此導致了涉及數字的轉換、存取、處理、控制等一系列高技術的發展,如微電子技術、光電傳輸技術、數字壓縮和編碼技術、多媒體數據庫技術等。1971年,英特爾公司生產出了世界上第一個微處理器芯片4004,人類第一次將高智能賦予無生命的設備,這是人工智能和計算處理歷史上的重要轉折點。它的誕生使微處理器打破了由大型中央處理器一統天下的局面,從而將計算機帶到辦公室的桌子上。微處理器的發明發展,使得數字轉化的速度、效率和范圍大大提高,讓計算機技術應用無處不在。20世紀70年代中期,曾有人對計算機的各種應用做過統計,列出了6 000多種應用,在這些應用中,直接對人類產生最大影響的就是數據庫技術的應用。數據庫技術是數據處理和信息管理系統的核心技術,主要通過研究數據庫的結構、存儲、設計、管理以及應用的基本理論方法,來實現對數據庫數據進行處理、分析和理解的技術。其中,數據模型是數據庫系統的核心和基礎。計算機技術、數字化技術、數據庫技術等共同構建了大數據的技術基礎。
海量信息的處理使數據挖掘理論與技術不斷發展。從20世紀90年代至21世紀初,隨著信息數字化能力和數據庫技術的不斷發展,人們開始思考如何解決大數據的“數據豐富而信息貧乏”的問題,于是數據挖掘技術應運而生。1989年8月,在美國底特律召開的第11屆國際聯合人工智能學術會議上,數據挖掘 (Data Mining,也稱Knowledge Discovery in Database,簡稱KDD)概念被正式提出。從1995年開始,一年一度的KDD國際學術會議讓“數據挖掘”一詞逐漸在學術圈流行。數據挖掘指的是從數據庫的大量數據中揭示出隱含的、先前未知的、潛在有用信息的過程。主要的技術方法有面向數據庫或數據倉庫的技術、機器學習、統計學、可視化、模式識別、神經網絡、模糊集、粗糙集、遺傳算法、決策樹、最近鄰技術等。復雜的數據挖掘系統通常采用多種數據挖掘技術。隨著數據挖掘理論和數據庫技術的逐步成熟,一批商業智能工具和知識管理技術開始被應用,如數據倉庫、專家系統、知識管理系統等。此時,人們對大數據技術研究主要集中在“算法”(Algorithms)、“模型”(Model)、“模式”(Patterns)、“識別”(Identification)等問題上,大數據技術開始形成并不斷發展,人類處理海量信息的能力得到大幅度提升。
2008年
“大數據”開始成為互聯網技術行業中的熱門詞匯。

2011年
麥肯錫公司發布《大數據:下一個創新、競爭和生產力的前沿》,大數據開始走出技術圈進入商業圈。

2013年
IBM公司在白皮書《分析:大數據在現實世界中的應用》解析說明會上提出大數據“4V”理論。大數據概念最終取代了數據概念,形成了當前意義上的數據概念。
非結構海量數據的迫切需求讓大數據技術取得突破。隨著計算機、互聯網和數字媒體進一步普及,以文本、圖形、圖像、音頻、視頻等非結構化數據為主的信息急劇增加,特別是以2004年Facebook創立為標志的社交網絡的流行,直接導致了大量非結構化數據的涌現,使得傳統的處理數據和海量數據的數據庫技術難以應對。如何存儲、查詢、分析、挖掘和利用這些非結構化數據信息成為社會的又一個重大難題。為應對這一挑戰,人們開始對數據處理系統和數據庫架構進行重新審視,這就出現了各種非結構化數據處理技術,如基于NoSQL的非結構化數據管理系統、網絡代價估算、多種支持模式演化等。2009年,谷歌公司軟件工程師杰夫·迪恩(Jeff Dean)在BigTable基礎上開發了全球首個分布式數據庫Spanner,標志著“云計算”(Cloud Computing)、“大規模數據集并行運算算法”(MapReduce)、“開源分布式系統基礎架構”(Hadoop)等大數據前沿技術理論開始走向成熟,并行運算與分布式系統成為當前大數據處理的主要技術方法并得到廣泛應用。
大數據產業發展現狀
2011年,麥肯錫公司發布的《大數據:創新、競爭和生產力的下一個前沿領域》研究報告,讓“大數據”走進商業應用領域。2012年1月,瑞士達沃斯世界經濟論壇發布《大數據,大影響》大會報告,讓“數據就像貨幣或黃金一樣是新的經濟資產類別”成為產業界的共識。2015年,全球大數據產業市場規模為1 403億美元,我國大數據產業市場規模為1 692億元人民幣,預計到2020年,全球大數據市場規模將超過10 270億美元,我國大數據市場規模將接近13 626億元人民幣。
美國是世界上第一個發展大數據產業的國家,也是世界各國大數據產業的領頭羊。2012年3月,美國奧巴馬政府發布“大數據研究和發展倡議”,宣布將投資2億多美元以拉動大數據產業的發展,正式將大數據發展戰略從商業行為上升到國家戰略,標志著大數據已成為當今時代的重要特征。2012年4月19日,美國軟件公司Splunk成功上市,成為第一家上市的大數據處理公司,這一年被美國IT行業稱為大數據元年。在美國政府的推動下,EMC、IBM、惠普、微軟、甲骨文等IT老牌巨頭積極通過并購實現技術整合,推出大數據相關產品和服務,Splunk、Clustrix、Junar、DataSift等一大批大數據新興企業也開始出現,形成了美國政府、企業、科研院校和非營利機構等利益相關、系統共進的產業發展局面。
受美國影響,世界發達國家紛紛制定大數據發展戰略,英國有《數據能力發展戰略規劃》、日本有《創建最尖端IT國家宣言》、韓國有《大數據中心戰略》,歐盟有《數據價值鏈戰略計劃》。2012年7月,聯合國發布的《大數據促發展:挑戰與機遇》政務白皮書指出,大數據對聯合國和各國政府來說是一個歷史性的機遇,世界各國對大數據產業的關注達到了前所未有的程度。高德納公司數據顯示,2014年全球數據中心系統支出達1 430億美元,比2013年增長2.3%。大數據對全球IT開支的直接或間接推動達2 320億美元,預計到2018年這一數據將增長3倍。美國國際數據集團(IDG)調查顯示,世界各國70%的大企業和56%的中小企業已經部署或者正在計劃部署與大數據有關的項目和計劃。
中國和美國幾乎在同一時期關注大數據產業。2008年,秦皇島開發區確定把大數據產業作為龍頭產業,提出建設“中國數谷”的目標,在國內率先提出大數據產業概念。從2011年底到2012年上半年,國金證券計算機研究團隊陸續推出3篇關于大數據的系列分析報告,首次在中國資本市場系統全面地闡述了大數據潛在的巨大社會意義和經濟意義,開資本市場大數據之先河。2012年,首屆數據科學與信息產業大會召開,標志著我國學術界、產業界和資產市場達成了共識,共同推進大數據的發展和落地。2013年,寬帶資本、用友軟件、云基地、百度在線、阿里巴巴等與大數據密切相關的企業共同發起成立“中關村大數據產業聯盟”,標志著我國大數據行業系統推進局面初步形成。
從2014年開始,我國大數據產業發展進入了快速推進期,呈現出3個特點。一是市場規模增速不斷加快。易觀國際數據顯示,我國大數據市場規模達到75.7億元,同比增長28.4%,但與全球53.2%的增速仍有不小的差距。二是國外大數據企業進入國內市場的數量增多,除IBM、微軟、谷歌、甲骨文、亞馬遜等已經在中國市場站穩腳跟的傳統企外,Teradata、Splunk、Cloudera、Tableau、Hortonworks、10Gen等大數據企業也紛紛入駐。三是大數據產業政策逐漸推升為國家戰略。2015年,我國將軟件及大數據產業寫入“十三五”規劃,并印發《促進大數據發展行動綱要》。2016年,我國頒布了《大數據產業發展規劃(2016—2020年)》。2015年,國內大數據產業高速發展,市場規模已達1 105.6億元,較2014年增長44.15%。其中,大數據基礎設施建設、大數據軟件和大數據應用分別占比64.53%、25.47%和10%。2016年,環境保護部、國務院辦公廳、國土資源部、國家林業局、煤礦與煤炭城市發展工作委員會、交通運輸部、農業部均推出大數據發展意見和方案,地方政府也紛紛出臺有關大數據產業發展的戰略,國內大數據產業政策從全面、總體規劃逐漸朝各大產業、各細分領域不斷延伸,標志著中國大數據產業政策已開始逐步落地。
當前,隨著大數據技術被廣泛應用到醫療衛生、食品安全、終身教育、智慧交通、公共安全、科技服務等各個領域,大數據產業進入到蓬勃發展的全新時期。但是,大數據產業發展仍然面臨技術上的系統性和政策上的協同性等問題。
大數據火熱背后的不同聲音
“大數據”無疑是最受當今社會各界關注的時髦詞匯之一,但人們對大數據的關注點并不相同。根據高德納公司的新興技術成熟度曲線研究報告,2015年和2016年大數據已連續兩年沒有出現在該曲線上,這說明大數據技術已脫離概念炒作進入應用階段。根據媒體對大數據報道的內容,從技術社會學的視角看,人們對大數據的反思也從對技術不確定性的擔心上升到技術的倫理價值判斷。
大數據有誤導結果的可能。大數據時代,“讓數據說話”的盛行使更多的社會空間被量化,定量科學和客觀方法的地位在一定程度上模糊了主觀與客觀之間的界限。美國微軟研究院首席研究員克凱特·克勞福德(Kate Crawford)在其《對大數據的再思考》文章中認為:“數字無法自己說話。不論其規模有多大,數據集歸根到底是人類設計的產物,而大數據的工具并不能使人們擺脫曲解、隔閡和錯誤的成見。”也就是說,大數據存在著偏見與盲區,“先天不足”。因此,一部分人認為,不僅某些數據并非中性,而且大數據測量對象的測量設計決策也源于設計者的主觀詮釋,大數據并不能完全準確地推出客觀規律,被神化的大數據極有可能誤導結果。
大數據不一定是好數據。互聯網和各種社交媒體每時每刻都提供巨量的數據,這些數據摻雜著大量冗余的、混亂的、虛假的甚至是有害的內容,數據對象的價值密度被不斷降低。但是,大數據倡導者仍努力從不確定中尋找確定性的結論,熱情地擁抱著這種“混亂”。百度公司董事長兼首席執行官李彥宏在百度聯盟大會上就曾表示:“現在每天產生大量數據,但很多是沒有價值的數據,沒有顯示出足夠的威力。”數據分析不可能不經過篩選而維持其完全原始的狀態,這些數據盡管已經覆蓋了數以百萬計的用戶群體,但依然有其局限性,真正需要的數據可能被更多混亂的海量“大”數據所掩蓋和淹沒。諸如此類的“魏則西事件”加劇了人們對數據“真偽”的擔心,著名導演尤小剛在談到利用大數據進行創作時就提醒說:“如果僅僅把浮于表面上的炒作結果放進去,很可能對文化建設造成某些破壞和誤導。”
被剝離語境的大數據將毫無意義。數據在經過篩選簡化套入模型時,其語境常常難以評估和保留。過去的社會學家和人類學家是通過問卷調查、訪談、觀察以及對照實驗來搜集關于人類關系的數據,并用這些數據來描述人類的“個人關系網絡”。社交網站興起后,大量研究者則常常是通過社交媒體去收集分析用戶信息,借此描述人們的社交關系。盡管社交網絡大數據是建立在聯系的緊密度上,但聯系的緊密度不等同于關系的緊密度,兩個沒聯系的人也不一定沒關系,兩個有關系的人也不一定有聯系。舍恩伯格在《大數據時代》一書中就講到,只有能夠想象并重建人們行為的發生語境,你所觀察到的行為才有意義,缺乏對行為語境的了解,就不可能推出任何因果關系,也無法理解人們的行為原因。大數據面臨處理語境問題的挑戰。
大數據造成新的“數字鴻溝”。大數據時代,來自硬件的數字鴻溝在縮小,而來自軟件的數字鴻溝在擴大。一是擁有數據的差別。例如,一些數據免費使用,一些數據有償使用,還有一些數據嚴禁流出,這就導致了數據獲取的差別;一些數據資源豐富且使用權限較大,而另一些卻很少有機會拿到“數據通行證”,這就造成了數據儲備使用的差別。二是公眾利用數據的能力不同。在大數據時代,非結構化數據往往占有很大的比例,同樣,擁有數據并不代表著能夠利用數據。世界經濟論壇發布的《2015年全球信息技術報告》指出,各國之間的數字鴻溝正在擴大。在技術大步前進時,這個問題更加令人擔憂。欠發達國家有可能會更加落后,必須盡快采取具體行動,應對這樣的局面。
大數據存在隱私安全的倫理問題。技術進步不可避免會帶來一些社會問題,大數據也不例外。大數據分析不僅面臨傳統的物理安全、網絡安全、數據安全等問題,還面臨新的隱私保護和信任安全問題。360公司董事長周鴻祎說過:“大數據時代可以不斷采集數據,當看起來是碎片的數據匯總起來,每個人就變成了透明人。每個人在干什么、想什么,云端全部都知道。”大數據讓我們時刻暴露在“第三只眼”之下。京東商城、天貓商城在時刻監視著我們的購物習慣,谷歌公司、360公司在監視著我們的網頁瀏覽習慣,微信、QQ在監視著我們的社交關系,我們無時無刻不在被監視、被數據化。盡管許多大數據的提供者盡力消除數據中的個人信息,但身份重新被確認的風險仍然很大,不法分子仍可以從大量的公共數據集中推斷出個人信息并進行售賣。
