基于協同過濾的個性化微博推薦算法研究
2017-05-12 23:34:23秦曉暉
軟件工程 2017年3期
摘 要:當前,微博已經成長為世界上最有影響力的社交網絡服務之一。隨著微博的流行,微博上大量的數據也使得用戶無法快速獲取他感興趣的信息。推薦系統是通過研究用戶已有數據來發掘用戶興趣,從而為用戶推薦可能感興趣的對象,如產品、網頁、微博等。本文介紹了一種基于協同過濾推薦技術的微博推薦算法,從影響用戶興趣度的隱性因素,以及微博互聯網中的數據采集和預處理等角度對微博推薦進行研究。使用矩陣分解對隱性因素建模,在已有用戶與微博、用戶與微博發布者影響因素的基礎上,提出微博與微博發布者影響因素,提高了原算法的準確度。
關鍵詞:微博推薦;協同過濾;矩陣分解
中圖分類號:TP391 文獻標識碼:A
Abstract:Currently,micro-blog has become one of the most influential networking services throughout the world. Along with its increasing growth of popularity,the large number of information available on micro-blog has obstructed people from accessing the messages they are interested in.The micro-blog recommendation system picks out and recommends the objects (e.g.products,webpages,micro-blogs,etc.) via analyzing the existing data of the user.The paper proposes a micro-blog recommendation algorithm based on the collaborative filtering technique,explores some recessive factors which may influence user's interest and studies micro-blog recommendation from the perspective of data collecting and preprocessing on micro-blog networks.While the previous studies only focus on the relationship between the user and the publisher,and that between the user and the micro-blog post,this paper adopts matrix decomposition to model recessive factors and proposes the influence factors between the publisher and the micro-blog post.Finally,the experimental results show that the new algorithm significantly improves the accuracy of micro-blog recommendation.
Keywords:micro-blog recommendation;collaborative filtering;matrix decomposition
1 引言(Introduction)
目前被廣泛應用的協同過濾算法[1]在推薦系統[2]中發揮著很重要的作用。隨著信息種類的豐富,我們需要對一些很難基于內容來分析的信息,尤其是對一些復雜的甚至難以表達的概念進行興趣分析,協同過濾算法表現出了一定的優越性。矩陣分解算法[3]目前已經被廣泛地應用于推薦系統中,它作為隱語義模型中的一種方法取得了一定的成就。協同過濾算法一般可以分為基于相似鄰居的方法[4,5]和基于模型的方法[6,7]這兩大類,目前隱因子概率模型或者矩陣分解模型經常被用來解決一些問題。本文主要使用基于模型算法中的矩陣分解算法,具體使用隱因子模型來度量影響微博用戶喜好的一些隱性因素。
本文向用戶進行微博推薦是通過用戶對微博的興趣度來分析的,那么就需要找出影響用戶對于微博興趣度的一些隱性因素,而矩陣分解作為一種隱含語義模型可以很好地幫我們找出這些隱性因素。因此在微博中并不需要指出微博具體的屬性類別,可以使用隱語義模型構建矩陣:比如構建一個user-tweet矩陣R見公式(1),其中Rij表示用戶i對微博j的興趣度,通過對矩陣R分解得到矩陣P和矩陣Q,其中f為影響用戶興趣度的隱性屬性,這個過程就稱為奇異值分解[7,8]。
從上述過程可以看出我們無需確定屬性的具體類別和屬性的個數,只需要設置隱因子模型中的屬性個數值作為屬性分類的粒度即可,值越大即代表分類的粒度越細。通過隱因子模型,在不知道微博的類型和用戶喜歡的微博類別的前提下也可以得到用戶對每個類別的興趣度。
2 基于協同排序的微博推薦算法(Collaborative ranking method for tweet recommendation)
2.1 微博排序優化準則
本文研究用戶對微博喜好度的排序,我們使用協同排序算法,它是基于隱因子模型的協同過濾方法。首先定義表示低維向量,同時定義和來表示用戶和微博的屬性空間向量。那么就可以通過公式(3)來預測用戶u對微博i的喜好度:
2.2 基于矩陣的隱因子分解模型
本文中通過研究用戶、微博和微博發布者三者之間的隱性因素來預測用戶對微博的興趣度。因此可以將用戶—微博矩陣使用SVD方法拆分為三個矩陣,具體分解為用戶—微博矩陣、用戶—發布者矩陣、發布者—微博矩陣,矩陣分解的過程不僅極大地豐富了我們的模型,使得一些潛在影響因素被挖掘出來,而且一定程度上緩解了由于轉發行為少而導致的矩陣稀疏問題。
(1)用戶—微博主題偏好分解
由于用戶微博轉發次數導致數據稀疏的問題,本文通過微博內容信息來緩解該問題,不同的主題可以使用不同的詞來代表,因此可以將微博的隱因子模型轉化為主題詞語的隱因子組合,于是轉化為分解模型(7):
其中,表示用戶—屬性矩陣,表示詞—屬性矩陣,矩陣中的每一個詞w都屬于微博i,Z為微博i中詞的個數,乘以對每個詞的權重進行歸一化。這樣的轉化由原來的用戶對一條微博的喜好度轉變為用戶對詞或主題的喜好度,從而緩解了矩陣稀疏問題。
(2)用戶—發布者社會關系分解
除了微博內容還可以將用戶與發布者的社會關系也考慮進模型。如果用戶對發布者發布的微博主題感興趣的話,也就是用戶的興趣與該微博發布者的微博主題很相似,那么該用戶轉發該發布者的微博的可能性就比較高,因此通過用戶與微博發布者之間的隱性因子可以預測用戶轉發該條微博的概率,詳見公式(8):
公式(11)表示通過挖掘用戶、微博和發布者這三者中的兩兩之間的隱性因子度量用戶的興趣度,不僅全面地考慮了多種隱性因子豐富了模型,而且一定程度上緩解了數據稀疏的問題。
(4)參數估計
本文使用線性加權的方法來預測用戶對微博的興趣度,其中α為發布者對微博影響因子的權重,β為發布者對微博主題影響因子的權重。2.1節中給出的目標函數(6)是求解的對象,本文中使用梯度下降的方法得到最優解即對目標函數求導。首先對矩陣進行初始化,這里我們使用隨機數,然后通過對構造的數據集D中的每一組元素計算梯度來不斷更新矩陣中的值直到循環終止得到最優解。其中,梯度更新系數詳見公式(12)到公式(17):
算法中不停循環使得模型中的權重值不斷更新,向著梯度下降的方向直到循環終止得到最優解。
3 實驗(Experiment)
3.1 數據來源
本文根據特定的需求在新浪微博使用爬蟲系統[9]獲取相關數據,網絡爬蟲作為搜索引擎的核心技術是一種自動提取網頁信息的計算機程序或者自動化腳本[10]。本文的實驗數據通過隨機選取一個微博用戶,然后以發射狀不斷爬取該用戶的關注者的數據,以及關注者的關注者的數據,從爬取的數據中找出1024個關注者人數超過15的微博用戶的主頁信息作為實驗數據。
3.2 評價標準
考慮到推薦結果中成功率的問題,本文使用平均準確率來評價預測結果的準確度。模型的推薦結果是微博排序,同時還可以用準確度關聯成功推薦的微博的排序位置從而使得推薦模型得到更準確的評估,即成功推薦的微博排序越靠前,那么平均準確率越高。如果系統沒有成功推薦的微博,那么準確率記為0。評估公式詳見(19):
3.3 實驗結果
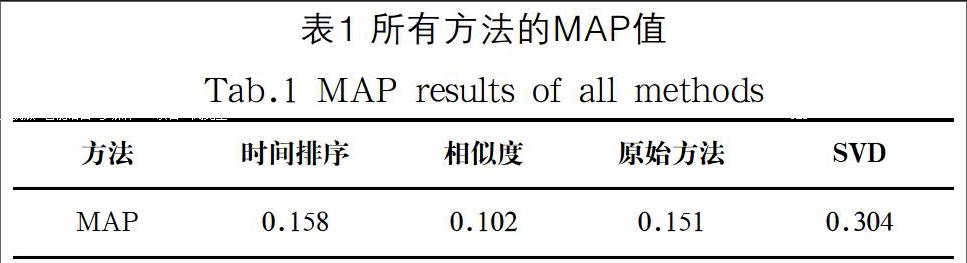
本文通過與其他幾種方法的對比實驗結果來驗證算法的有效性。按照時間排序的方法是指所有微博按照時間排序不通過其他算法重排序,這種方法表現微博最直接、最原始的狀態,但卻忽略了用戶興趣對微博排序的影響,與這種方法得到的結果相對比將有效地說明本文中算法研究的意義和必要性。按相似度排序的方法是按照微博與用戶標簽的相似性來排序的,這里使用余弦相似度來計算相似度,標簽是指用戶歷史微博和轉發微博歷史里面的關鍵詞的集合。原始[11]方法在隱性因素方面只考慮主題層次和社會關系層次。矩陣分解模型算法SVD在原始算法的基礎上添加影響用戶興趣度的微博權威性隱性因素預測用戶興趣度。該算法也使用隨機梯度算法來估計實驗參數,實驗中矩陣分解過程中使用到的K值取30準確率最高。
4 結論(Conclusion)
按照時間序列排序的推薦方法依賴于用戶的登錄時間,用戶對登錄時間前后的微博轉發概率大,因此預測準確度很低。按照相似度的排序只通過關鍵詞計算微博表面相似度,忽略了內在語義。原始方法沒有考慮微博與微博發布者之間的隱性因素而低于SVD方法。
參考文獻(References)
[1] Shi Y,Larson M,Hanjalic A.Collaborative Filtering Beyond the User-Item Matrix:A Survey of the State of the Art and Future Challenges[J].ACM Computing Surveys (CSUR),2014,47(1):3.
[2] Yang X,et al.A Survey of Collaborative Filtering Based Social Recommender Systems[J].Computer Communications, 2014,41:1-10.
[3] Levy O,Goldberg Y.Neural Word Embedding as Implicit Matrix Factorization[C].Advances in Neural Information Processing Systems,2014:2177-2185.
[4] Sarwar B.,et al.Item-Based Collaborative Filtering Recommendation Algorithms[A].Hypermedia Track of the 10th International World Wide Web Conference,2001:285-295.
[5] Shi Y.,Larson M.,Hanjalic A.Exploiting User Similarity Based on Rated-Item Pools for Improved User-Based Collaborative Filtering[A].Third ACM Conference on Recommender Systems,2009:125-132.
[6] Koren Y.Factorization Meets the Neighborhood:a Multifaceted Collaborative Filtering Model[A].The 14th ACM SIGKDD International Conference on Knowledge,2008:426-434.
[7] Rendle S.The IEEE International Conference on Data Mining[C].Factorization machines,2010:995-1000.
[8] Cao Y.,et al.Adapting Ranking SVM to Document Retrieval[C].The 29th Annual International SIGIR Conference,2006:186-193.
[9] 孫立偉,何國輝,吳禮發.網絡爬蟲技術的研究[J].電腦知識與技術,2010,6(15):4112-4115.
[10] 高建煌.個性化推薦系統技術與成用[D].中國科學技術大學,2010.
[11] Chen K.,et al.Collaborative Personalized Tweet Recommendation[A].The 35th International ACM SIGIR Conference on Research and Development in Information Retrieval,2012:661-670.
作者簡介:
秦曉暉(1987-),女,碩士,助教.研究領域:中文信息處理,人工智能.
