知識遷移的極大熵聚類算法及其在紋理圖像分割中的應(yīng)用
2017-05-16 07:00:05程旸蔣亦樟錢鵬江王士同
智能系統(tǒng)學(xué)報 2017年2期
程旸,蔣亦樟,錢鵬江,王士同
(江南大學(xué) 數(shù)字媒體學(xué)院,江蘇 無錫 214122)
知識遷移的極大熵聚類算法及其在紋理圖像分割中的應(yīng)用
程旸,蔣亦樟,錢鵬江,王士同
(江南大學(xué) 數(shù)字媒體學(xué)院,江蘇 無錫 214122)
本文研究了一種新型的基于知識遷移的極大熵聚類技術(shù)。擬解決兩大挑戰(zhàn)性問題: 1)如何從源域中選擇合適的知識對目標(biāo)域進行遷移學(xué)習(xí)以最終強化目標(biāo)域的聚類性能;2)若存在源域聚類數(shù)與目標(biāo)域聚類數(shù)不一致的情況時,該如何進行遷移聚類。為此提出一種全新的遷移聚類機制,即基于聚類中心的中心匹配遷移機制。進一步將該機制與經(jīng)典極大熵聚類算法相融合提出了基于知識遷移的極大熵聚類算法(KT-MEC)。實驗表明,在不同遷移場景下的紋理圖像分割應(yīng)用中,KT-MEC算法較很多現(xiàn)有聚類算法具有更高的精確度和抗噪性。
遷移學(xué)習(xí);中心遷移匹配;極大熵聚類;紋理圖像分割;抗噪性
在實際生產(chǎn)中,大部分機器學(xué)習(xí)方法處理的對象均為含噪數(shù)據(jù)集且存在數(shù)據(jù)量不足的問題。如對于圖像分割[1]任務(wù)而言,圖像數(shù)據(jù)往往含有很大的噪聲。圖像數(shù)據(jù)含噪程度越高,使用的機器學(xué)習(xí)方法對其進行分割的性能就變得越弱。一般來說,無監(jiān)督的聚類方法通常用來獲得圖像的分割結(jié)果[2-3],比較著名的算法有模糊C均值算法(FCM)[4]、可能性聚類算法(PCM)[5]、極大熵聚類算法[6]等。這些方法雖簡單實用,但其對于含噪圖像數(shù)據(jù)的分割效果并不理想。盡管已有學(xué)者致力于解決該問題,但效果并不明顯。
1 問題描述
遷移學(xué)習(xí)技術(shù)[7]的提出,為我們提供了一種新的解決問題的思路。傳統(tǒng)的機器學(xué)習(xí)假設(shè)訓(xùn)練數(shù)據(jù)與測試數(shù)據(jù)服從相同的數(shù)據(jù)分布。然而,大量實際情況中并不滿足這種同分布假設(shè)。從另外一個角度上看,如果我們已經(jīng)有了大量的、在不同分布下的訓(xùn)練數(shù)據(jù),完全丟棄這些數(shù)據(jù)是非常浪費的。如何合理地利用這些數(shù)據(jù)就是遷移學(xué)習(xí)要解決的問題。遷移學(xué)習(xí)可以從現(xiàn)有的數(shù)據(jù)中遷移知識,用來幫助將來的學(xué)習(xí)。遷移學(xué)習(xí)的目標(biāo)是將從一個環(huán)境中學(xué)到的知識用來幫助新環(huán)境中的學(xué)習(xí)任務(wù),其學(xué)習(xí)過程類似人類的學(xué)習(xí)和思維方式。我們面臨的問題如圖1所示。

圖1 問題描述Fig.1 The description of the problem
源域的數(shù)據(jù)中往往存在一部分數(shù)據(jù)為可用數(shù)據(jù),如源域優(yōu)質(zhì)圖像,目標(biāo)域的數(shù)據(jù)通常呈現(xiàn)數(shù)據(jù)不足或噪聲污染嚴(yán)重[8-9]等情況,如目標(biāo)域含噪圖像。如何才能得到最接近目標(biāo)域理想分割的效果圖,如果能夠?qū)⒃从虻闹R成功遷移到目標(biāo)域中進行學(xué)習(xí),是否能夠大幅提高圖像分割性能呢?
為了驗證本文的設(shè)想,實現(xiàn)提高圖像分割性能的目標(biāo),本文將遷移學(xué)習(xí)方法融入到經(jīng)典的極大熵聚類算法[10](maximum entropy clustering,MEC)中,以提高極大熵算法的聚類性能,進而提高該算法對圖像分割的性能。在將遷移學(xué)習(xí)策略融入到極大熵聚類算法的過程中,我們面臨的挑戰(zhàn)有:1)選擇源域的何種知識進行遷移學(xué)習(xí)以增強目標(biāo)域的聚類性能;2)當(dāng)源域和目標(biāo)域的聚類數(shù)不一致時如何遷移。
針對挑戰(zhàn)1),本文選用聚類中心作為遷移知識,因源域的聚類中心是各類所包含點的高度濃縮,亦是各類的代表點,將其作為聚類中的高級知識具有更強的指導(dǎo)性;針對挑戰(zhàn)2),本文提出了一個中心遷移匹配機制用于處理源域和目標(biāo)域聚類數(shù)不一致的情況。無論源域與目標(biāo)域的聚類數(shù)是否相同,該中心遷移匹配機制均可適用,且能夠找到源域與目標(biāo)域類中心的最佳匹配關(guān)系。將上述遷移知識與中心遷移匹配機制融入到經(jīng)典的極大熵聚類算法中,本文提出了一種全新的基于知識遷移的極大熵聚類算法,并將該算法成功應(yīng)用于紋理圖像分割中。實驗結(jié)果表明,本文所提出的基于知識遷移的極大熵聚類算法在不同的遷移場景下對于紋理圖像的分割性能均優(yōu)于其他遷移以及非遷移聚類算法。本文工作的創(chuàng)新主要涵蓋以下幾點:
1)確定了源域中哪種知識能夠進行有效遷移,即從源域數(shù)據(jù)中獲取的聚類中心知識可以用來指導(dǎo)并增強目標(biāo)域的聚類性能;
2)給出了一種解決源域與目標(biāo)域聚類數(shù)不同時,如何進行有效遷移的途徑,即提出了一種通用的中心遷移匹配機制,不僅能夠有效解決源域與目標(biāo)域聚類數(shù)不相同時的遷移問題,還能指導(dǎo)源域、目標(biāo)域聚類數(shù)相同時,各類中心如何一一對應(yīng)的問題。
3)將上述兩個問題的解決策略融入到極大熵聚類算法后,本文提出了一種新的基于知識遷移的極大熵聚類算法,實驗表明該算法的聚類性能較其他遷移聚類算法以及非遷移聚類算法在處理不同遷移場景下的紋理分割圖像時,具有更加優(yōu)良的性能。
本文所用的符號說明如表1所示。

表1 符號說明
2 相關(guān)工作
2.1 經(jīng)典MEC算法
MEC聚類算法是基于劃分的聚類算法中最具代表性的算法之一,該算法的數(shù)學(xué)表達式簡單明了、物理意義明確,是廣大學(xué)者較常使用的聚類算法,關(guān)于MEC算法的變形算法較經(jīng)典的如文獻[10]。特別是在針對含有噪聲的紋理圖像的分割中,MEC聚類算法相比經(jīng)典的模糊C均值聚類FCM以及可能性聚類PCM等聚類算法具有更好的抗噪性,進而能夠獲得更好的聚類性,使得分割結(jié)果更加逼近理想分割結(jié)果。綜上,本文選用了MEC算法。MEC算法的函數(shù)表達式為
(1)
式中:xj為第j個數(shù)據(jù)樣本,Vi為第i個聚類中心,uij為樣本xj屬于聚類中心Vi的隸屬度,C為聚類數(shù),N為樣本總數(shù),γ為熵的正則化參數(shù), ‖xj-Vi‖2代表樣本xj與聚類中心Vi之間的距離。
由拉格朗日乘子法則,求解式(1),解得聚類中心Vi和隸屬度Uij的表達式為
(2)
(3)
MEC算法步驟如下:
1)給定聚類數(shù)C,樣本總數(shù)N,正則化參數(shù)γ,聚類精度ε,最大迭代次數(shù)T,初始化隸屬度矩陣U和聚類中心V;
2)根據(jù)式(2)更新聚類中心矩陣V;
3)根據(jù)式(3)更新隸屬度矩陣U;

5)算法收斂后,輸出聚類中心V和隸屬度矩陣U。
2.2 相關(guān)遷移聚類算法
近年來,遷移聚類算法及其相關(guān)算法的研究已受到許多專家學(xué)者的關(guān)注,本文將研究中較有價值的文獻羅列如下:文獻[11]提出了一種自學(xué)聚類算法,該算法是第1個基于互信息的遷移聚類算法,但是由于該算法運行的前提是假定源域數(shù)據(jù)是可用的,這在實際生產(chǎn)應(yīng)用中并不切實際,所以該算法具有一定的局限性;文獻[12]提出了一種基于譜聚類的遷移聚類算法,該算法主要針對光譜聚類;文獻[13]提出了一種極大熵的遷移聚類算法,該算法提出了基于類中心和隸屬度的兩種知識遷移機制,但該算法并未解決當(dāng)源域目標(biāo)域聚類數(shù)不一致時,如何進行遷移的問題。除了直接提出的遷移聚類算法,還存在如協(xié)同聚類[14]、多任務(wù)聚類[15]、聯(lián)合聚類[16]、半監(jiān)督聚類[17]等具有相關(guān)性的聚類算法。其中,協(xié)同聚類算法的核心思想為結(jié)合樣本間不同的協(xié)作能力形成拉動效應(yīng),共同推動事物的發(fā)展,從而提高樣本的整體聚類精度。多任務(wù)聚類的核心思想為多個聚類任務(wù)同時進行,各個聚類任務(wù)之間相互協(xié)調(diào)配合,以提高聚類性能。聯(lián)合聚類顧名思義就是聯(lián)合多個聚類算法進行一定關(guān)系的聯(lián)合使用,聚類精度的提高對于具體聚類算法的選擇比較敏感。半監(jiān)督聚類算法需要已知一部分數(shù)據(jù)樣本的標(biāo)簽,根據(jù)這些標(biāo)簽來指導(dǎo)整個樣本數(shù)據(jù)的聚類過程,從而提高聚類性能。
現(xiàn)有的遷移聚類算法及其相關(guān)算法在處理含噪的圖像分割數(shù)據(jù)時,均存在各種問題。如文獻[13]提出的遷移聚類算法無法解決當(dāng)源域與目標(biāo)域的圖像分割數(shù)不一致時,如何實現(xiàn)遷移的問題。對于其他相關(guān)算法如聯(lián)合算法來說,圖像本身還有噪聲,經(jīng)過層層的聚類算法進行處理,誤差被層層放大,最終的聚類性能則被削弱。本文所做研究主要針對紋理圖像分割進行展開,我們將在下一節(jié)針對算法的抗噪性、源域目標(biāo)域聚類數(shù)是否一致等問題進行詳細描述。
3 基于知識遷移的MEC聚類算法
3.1 基于聚類中心的知識遷移機制
源域中存在許多知識可用于遷移到目標(biāo)域中進行學(xué)習(xí)。問題在于在具體選擇時,應(yīng)該選擇哪種或哪幾種知識的組合進行遷移。源域中存在可以遷移的知識主要有:聚類中心、隸屬度、數(shù)據(jù)樣本以及其他經(jīng)過二次或多次處理后獲得的知識。考慮到源域的聚類中心具有較高的數(shù)據(jù)集中特征,且該知識作為自然聚類知識的核心,本文最終選擇了聚類中心作為知識遷移的對象。基于中心遷移的表達式計算的是源域的聚類中心Vs與目標(biāo)域Vt之間距離和。
(4)
式中:λ為遷移平衡參數(shù),一般大于0,其值越大,表示源域知識在目標(biāo)域中所占分量越大;Ct為目標(biāo)域聚類數(shù);Vj,t為目標(biāo)域中第j個聚類中心;Vj,s為源域中第j個聚類中心。
3.2 基于聚類中心的遷移匹配機制
式(4)盡管實現(xiàn)了源域知識向目標(biāo)域遷移進行指導(dǎo)學(xué)習(xí)的目的,但其并未解決源域與目標(biāo)域的聚類數(shù)不相同時,如何進行遷移和中心間的匹配問題。本小節(jié),我們將致力于探討能否確定一個通用的準(zhǔn)則,無論源域與目標(biāo)域的聚類數(shù)是否一致均能自適應(yīng)地匹配。為了解決上述問題,本文引入了模糊聚類理論來解決該問題,從而提出了一種中心遷移匹配機制。中心遷移匹配機制的表達式為
(5)
式(5)解決了源域的聚類中心Vs與目標(biāo)域Vt之間的匹配問題。其中,參數(shù)Pt,s為知識遷移隸屬度,pjk表示目標(biāo)域的第j個類中心與源域的第k個類中心進行匹配的隸屬度。當(dāng)pjk→1,表示目標(biāo)域的第j個類中心完全匹配源域的第k個類中心;當(dāng)pjk→0,表示目標(biāo)域的第j個類中心不匹配源域的第k個類中心,若出現(xiàn)不匹配的情況,源域中未找到匹配聚類中心的那個聚類中心將會從源域的聚類中心中刪除掉。Nt為目標(biāo)域數(shù)據(jù)樣本的大小,Ct為目標(biāo)域聚類數(shù),Cs為源域聚類數(shù)。
3.3 基于知識遷移的極大熵聚類算法
將上述知識遷移機制與知識匹配機制融入到MEC聚類算法后,本文提出一種基于知識遷移的極大熵聚類算法。該算法的流程主要分為兩個階段,流程圖如圖2所示。

圖2 KT-MEC算法流程圖Fig.2 The flowchart of KT-MEC algorithm
1)知識提取
利用經(jīng)典的極大熵聚類算法對源域的數(shù)據(jù)集進行聚類,得到源域的聚類中心Vs。知識提取的表達式為
(6)
通過求解式(6),得到源域聚類中心Vs。
2)知識匹配與遷移
利用中心遷移匹配機制將階段1得到的聚類知識進行自適應(yīng)匹配,使源域中的聚類中心(知識)能夠與目標(biāo)域中的聚類中心進行完美匹配,以解決源域和目標(biāo)域不同類時的遷移問題。同時,將匹配后的源域知識遷移到目標(biāo)域中加以利用。結(jié)合極大熵聚類算法,基于知識遷移的極大熵聚類算法(KT-MEC),該算法的函數(shù)表達式為
(7)
1≤j≤Nt,1≤i≤Ct,1≤k≤Cs
式中:uij,t為目標(biāo)域隸屬度,xj,t為目標(biāo)域第j個樣本數(shù)據(jù),Vi,t為目標(biāo)域第i個聚類中心,γ為熵的正則化參數(shù),Ct為目標(biāo)域聚類數(shù),Nt為目標(biāo)域樣本總數(shù),λ為知識遷移的平衡系數(shù),pik表示目標(biāo)域的第i個類中心遷移到源域的第k個類中心的知識遷移隸屬度,Vk,s為源域的第k個類中心,η為遷移項的正則化參數(shù)。通過拉格朗日乘子法最小化式(7),各參數(shù)表達式如下:
目標(biāo)域隸屬度uij,t:
目標(biāo)域聚類中心vi,t:
知識遷移隸屬度pik:
通過上述兩個階段的流程,將各源域與目標(biāo)域的相關(guān)數(shù)據(jù)帶入到各表達式中,得到最終的聚類結(jié)果。KT-MEC聚類算法的詳細步驟如下:
輸入 源域數(shù)據(jù)集xs,目標(biāo)域數(shù)據(jù)集xt,源域聚類數(shù)Cs,目標(biāo)域聚類數(shù)Ct,熵的正則化參數(shù)γ,收斂精度ε,最大迭代次數(shù)T;
輸出 目標(biāo)域隸屬度Ut,目標(biāo)域聚類中心Vt。
知識提取階段:
1)隨機初始化源域的隸屬度矩陣Us;
2)利用式(2)求得源域的聚類中心Vs;
3)利用式(3)求得源域的隸屬度Us;
4)滿足迭代終止條件則輸出源域聚類中心Vs并終止算法,否則返回 2)。
知識匹配與遷移階段:
1)隨機初始化目標(biāo)域的隸屬度矩陣Ut以及聚類中心Vt;
2)利用式(8)求得目標(biāo)域的隸屬度矩陣Ut;
3)利用式(9)求得目標(biāo)域聚類中心矩陣Vt;
4)利用式(10)求得目標(biāo)域的知識遷移隸屬度矩陣Pts;
5)如滿足迭代終止條件則輸出目標(biāo)域隸屬度矩陣Ut,聚類中心Vt,并終止算法,否則返回2)。
4 實驗與分析
為了評估本文所提KT-MEC聚類算法的性能,實驗所使用的對比算法有:非遷移MEC聚類算法、自學(xué)聚類算法(STC)[11]、遷移譜聚類算法(TSC)[12]、DRCC協(xié)同聚類算法[15]、CombKM多任務(wù)聚類算法[15]。本文實驗所用數(shù)據(jù)集為Brodatz紋理圖像分割[17]數(shù)據(jù)集。
Brodatz紋理圖像由7個基本紋理圖像(D3、D6、D21、D49、D53、D56、D93)合成,具體見圖3。合成紋理圖像的大小被重新調(diào)整為100像素×100像素。為了模擬真實數(shù)據(jù)集環(huán)境,本文將不同標(biāo)準(zhǔn)偏差的高斯噪聲添加到各個紋理圖像中。實驗中,圖3(a)為源域的圖像數(shù)據(jù),圖3(b)~(i)為在不同的目標(biāo)域中的圖像數(shù)據(jù)。為了模擬不同的遷移場景,我們設(shè)計了兩種不同遷紋理圖像分割任務(wù),目標(biāo)域圖像T1~T4與源域圖像的類別數(shù)均為7,σ=0.1,0.2,0.0,0.1;目標(biāo)域圖像T5~T8與源域圖像的類別數(shù)分別為3、4、5、6,σ=0.1。


圖3 源域及不同情況下目標(biāo)域的紋理圖像數(shù)據(jù)Fig.3 Texture image datasets of one source domain and some different target domains
理想分割圖可用來為各算法的分割性能優(yōu)劣作參考,理想的紋理分割結(jié)果如圖4所示。


圖4 不同紋理圖像的理想分割結(jié)果Fig.4 Ideal segmentation result of different texture images
紋理圖像分割的過程概括如下。文獻[19]先采用Gabor濾波器在6個方向提取紋理圖像特征的濾波器組。每個紋理圖像的數(shù)據(jù)集包含30維特征,數(shù)據(jù)集大小為10 000。不同算法得到的類被認為分割圖像的一個區(qū)域。
4.1 實驗參數(shù)設(shè)置
通常用來衡量聚類算法性能的指標(biāo)有:NMI、RI、Entropy、F-measure等,本文主要采用以下兩種評估指標(biāo):
式中:Ni,j表示第i個聚類與類j的契合程度,Ni表示第i個聚類所包含的數(shù)據(jù)樣本量,Nj表示類j所包含的數(shù)據(jù)樣本量,而N表示整個數(shù)據(jù)樣本的總量大小。RI表達式中的f00表示數(shù)據(jù)點具有不同的類標(biāo)簽并且屬于不同類的配對點數(shù)目,f11則表示數(shù)據(jù)點具有相同的類標(biāo)簽并且屬于同一類的配對點數(shù)目,而N表示整個數(shù)據(jù)樣本的總量大小。NMI、RI兩種評價指標(biāo)的取值范圍均為[0,1],取值越大表明算法的性能越好。
在本文所使用的遷移算法中,KT-MEC算法的熵正則化參數(shù)γ∈{0∶0.05∶1},遷移平衡因子λ∈{0.1,0.5,1,5,10,50,100,500,1 000},遷移隸屬度的正則化參數(shù)η∈{0∶0.05∶1}。TSC算法和STC算法的參數(shù)設(shè)置詳見文獻[11]和文獻[12]。
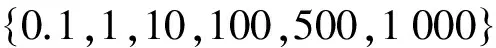
上述所有參數(shù)均由網(wǎng)格搜索[18]得到最優(yōu)值,實驗結(jié)果均為運行算法15次的結(jié)果取均值及方差所得。實驗均在MARTLAB8.1.0.604(R2013a)平臺下完成,操作系統(tǒng)為64位Windows7,CPU為Intel(R)Core(TM)i3-3240 3.40GHz,內(nèi)存為4GB。
4.2 聚類數(shù)相同的紋理圖像分割
表2與圖5分別為源域與目標(biāo)域聚類數(shù)相同時,各算法對紋理圖像進行分割時的聚類性能對比與圖像分割結(jié)果對比。

表2 源域與目標(biāo)域的聚類數(shù)相同時的各算法聚類性能對比

(a) 6種算法分別在數(shù)據(jù)集T1上的圖像分割結(jié)果

(b) 6種算法分別在數(shù)據(jù)集T2上的圖像分割結(jié)果

(c) 6種算法分別在數(shù)據(jù)集T3上的圖像分割結(jié)果

(d) 6種算法分別在數(shù)據(jù)集T4上的圖像分割結(jié)果 圖5 源域與目標(biāo)域聚類數(shù)相同的含噪紋理圖像分割結(jié)果Fig.5 Segmentation results of clustering algorithms for noisy texture images with the same number of clusters between source domain and target domain
從表2和圖5的聚類結(jié)果可以觀察到,遷移聚類算法(STC、TSC、KT-MEC)在T1~T4數(shù)據(jù)集上取得了比傳統(tǒng)的非遷移聚類算法更高的聚類精度。表2中NMI和RI值以及圖5中可視化的分割結(jié)果,均表明本文所提出的KT-MEC聚類算法優(yōu)于經(jīng)典的MEC算法。以上結(jié)果進一步表明,在含噪的數(shù)據(jù)環(huán)境中,本文KT-MEC算法具有比MEC更好的魯棒性,也進一步表明遷移學(xué)習(xí)技術(shù)是提高算法魯棒性的有效途徑。
如表2和圖5的聚類結(jié)果所示,本文提出的KT-MEC算法與協(xié)同算法DRCC以及多任務(wù)聚類算法CombKM相比,本文算法仍然較優(yōu),這是因為多任務(wù)聚類與遷移聚類的原理明顯不同。協(xié)同聚類與多任務(wù)聚類在集中完成多個聚類任務(wù)的同時,通過使用每個聚類任務(wù)的獨立信息和多個聚類任務(wù)間的潛在相關(guān)信息,以獲得良好的聚類性能。然而,在遷移聚類場景中,目標(biāo)域的數(shù)據(jù)不能提供正確的聚類信息,這就會使得協(xié)同聚類和多任務(wù)聚類算法的聚類性能變?nèi)酢?/p>
此外,由于本文提出的KT-MEC算法較其他遷移聚類算法、協(xié)同聚類算法、多任務(wù)聚類算法具有更好的聚類性能,這進一步表明先進的集群知識(如聚類中心)可以被看作是一種有效的遷移知識,以提高目標(biāo)域的聚類性能。這也表明本文提出的聚類中心自適應(yīng)匹配機制能使源域的類中心與目標(biāo)域的類中心進行成功匹配,達到知識遷移的目的。
4.3 聚類數(shù)不同的紋理圖像分割
表3與圖6分別為源域與目標(biāo)域聚類數(shù)不同時,各算法對紋理圖像進行分割時的聚類性能對比與圖像分割結(jié)果對比。
由于協(xié)同聚類算法DRCC、遷移聚類算法STC和TSC的聚類機制需要源域與目標(biāo)域有相同的聚類數(shù),所以這3種聚類算法不能在源域與目標(biāo)域聚類數(shù)不同的遷移場景下運行。
表3和圖6的實驗結(jié)果表明本文提出KT-MEC聚類算法在圖像分割性能上較經(jīng)典的非遷移MEC算法以及CombKM算法具有更優(yōu)的聚類性能。此外,得益于本文提出的基于知識的中心遷移機制,源域與目標(biāo)域聚類數(shù)不同的遷移場景中的聚類結(jié)果表明了本文提出的基于知識的中心匹配機制可挖掘出源域和目標(biāo)域之間完美的聚類中心的配對關(guān)系,進而確保知識遷移的質(zhì)量。

表3 源域與目標(biāo)域的聚類數(shù)不同時的各算法聚類性能對比
續(xù)表3
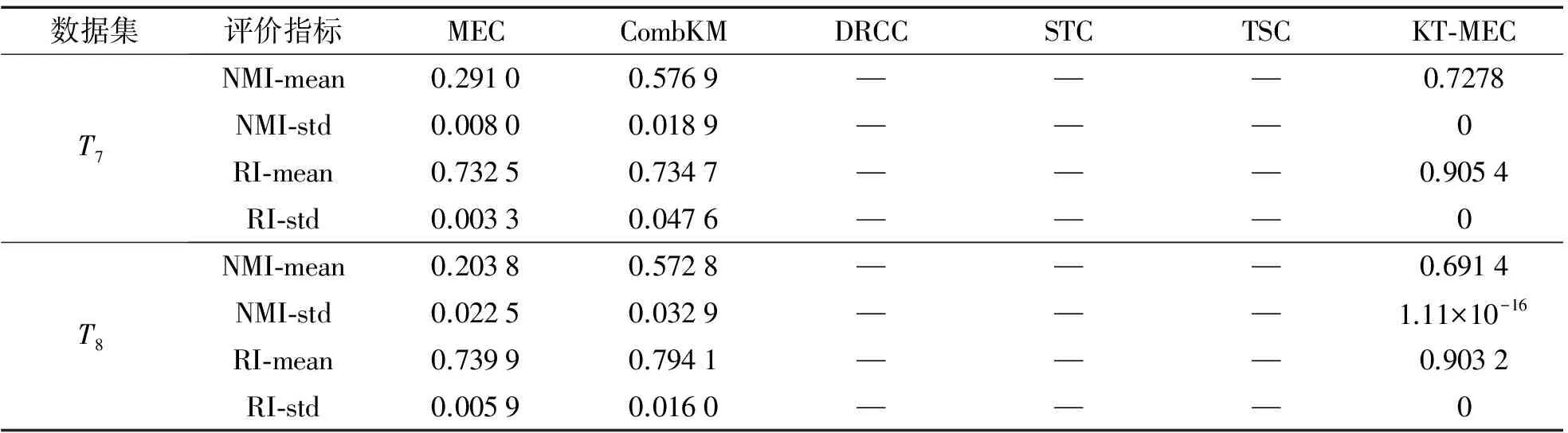
數(shù)據(jù)集評價指標(biāo)MECCombKMDRCCSTCTSCKT?MECT7NMI?mean0.29100.5769———0.7278NMI?std0.00800.0189———0RI?mean0.73250.7347———0.9054RI?std0.00330.0476———0T8NMI?mean0.20380.5728———0.6914NMI?std0.02250.0329———1.11×10-16RI?mean0.73990.7941———0.9032RI?std0.00590.0160———0

(a) 6種算法分別在數(shù)據(jù)集T5上的圖像分割結(jié)果

(b) 6種算法分別在數(shù)據(jù)集T6上的圖像分割結(jié)果

(c) 6種算法分別在數(shù)據(jù)集T7上的圖像分割結(jié)果

(d) 6種算法分別在數(shù)據(jù)集T8上的圖像分割結(jié)果 圖6 源域與目標(biāo)域聚類數(shù)不同的含噪紋理圖像分割結(jié)果Fig.6 Segmentation results of clustering algorithms for noisy texture images with the different number of clusters between source domain and target domain
上述實驗結(jié)果表明本文提出的KT-MEC聚類算法在不同的遷移場景中的聚類性能均優(yōu)于現(xiàn)有的相關(guān)聚類算法。特別是,KT-MEC聚類算法適用于一般的遷移場景,即無論是源域和目標(biāo)域的聚類的數(shù)目是相同或不同時,本文KT-MEC算法均能適用且能獲得比其他聚類算法更好的聚類結(jié)果。
5 結(jié)束語
本文研究是基于遷移學(xué)習(xí)的聚類算法,實驗部分主要針對紋理圖像的分割。本文算法對遷移聚類算法的貢獻主要有兩方面:1)確定了聚類中心作為遷移知識,實驗證明了將聚類中心作為遷移知識能夠更好地增強目標(biāo)域的聚類性能;2)找到了一個解決無論源域與目標(biāo)域的聚類數(shù)是否一致,都能夠成功進行遷移的通用策略。基于上述工作,結(jié)合傳統(tǒng)的非遷移極大熵聚類算法,本文提出了基于知識遷移的極大熵聚類算法,并將該算法與其他遷移算法、非遷移算法、協(xié)同聚類算法、多任務(wù)聚類算法等一系列相關(guān)算法進行了性能對比,實驗表明本文KT-MEC聚類算法的性能在紋理圖像分割上較其他算法具有更加優(yōu)良的性能。KT-MEC聚類算法不僅能夠提高算法的聚類精度,增強圖像的分割效果,還能適應(yīng)不同遷移場景下的聚類任務(wù),具有較強的魯棒性。
雖然本文KT-MEC聚類算法在紋理圖像的分割上具有較好的性能,但該算法的適應(yīng)性上還需進行進一步的研究。隨著數(shù)據(jù)的爆炸式增長,數(shù)據(jù)復(fù)雜性的迅速增加,KT-MEC聚類算法是否能夠適用于高維復(fù)雜數(shù)據(jù)還有待研究。
[1]ZHU Lin, CHUNG F L, WANG Shitong. Generalized fuzzy c-means clustering algorithm with improved fuzzy partitions[J]. IEEE transactions on systems, man, and cybernetics, part B (cybernetics), 2009, 39(3): 578-591.
[2]KIM S, YOO C D, NOWOZIN S, et al. Image segmentation usinghigher-order correlation clustering[J]. IEEE transactions on pattern analysis and machine intelligence, 2014, 36(9): 1761-1774.
[3]JIANG Yizhang, CHUNG F L, WANG Shitong, et al. Collaborative fuzzy clustering from multiple weighted views[J]. IEEE transactions on cybernetics, 2015, 45(4): 688-701.
[4]BEZDEK J C. Pattern recognition with fuzzy objective function algorithms[M]. USA: Springer Science & Business Media, 2013: 155-201.
[5]KRISHNAPURAM R, KELLER J M. A possibilistic approach to clustering[J]. IEEE transactions on fuzzy systems, 1993, 1(2): 98-110.
[6]KARAYIANNIS N B. MECA: maximum entropy clustering algorithm[C]//Proceedings of the Third IEEE Fuzzy Systems Conference. Orlando, USA: IEEE, 1994: 630-635.
[7]PAN S J, YANG Qiang. A survey on transfer learning[J]. IEEE transactions on knowledge and data engineering, 2010, 22(10): 1345-1359.
[8]DENG Zhaohong, CHOI K S, JIANG Yizhang, et al. Generalized hidden-mapping ridge regression, knowledge-leveraged inductive transfer learning for neural networks, fuzzy systems and kernel methods[J]. IEEE transactions on cybernetics, 2014, 44(12): 2585-2599.
[9]DENG Zhaohong, JIANG Yizhang, CHOI K S, et al. Knowledge-leverage-based TSK fuzzy system modeling[J]. IEEE transactions on neural networks and learning systems, 2013, 24(8): 1200-1212.
[10]ZHI Xiaobin, FAN Jiulun, ZHAO Feng. Fuzzy linear discriminant analysis-guided maximum entropy fuzzy clustering algorithm[J]. Pattern recognition, 2013, 46(6): 1604-1615.
[11]DAI Wenyuan, YANG Qiang, XUE Guirong, et al. Self-taught clustering[C]//Proceedings of the 25th International Conference on Machine Learning. New York, USA: ACM, 2008: 200-207.
[12]JIANG Wenhao, CHUNG F L. Transfer spectral clustering[M]//FLACH P A, DE BIE T, CRISTIANINI N. Machine Learning and Knowledge Discovery in Databases. Berlin Heidelberg: Springer, 2012: 789-803.
[13]錢鵬江, 孫壽偉, 蔣亦樟, 等. 知識遷移極大熵聚類算法[J]. 控制與決策, 2015, 30(6): 1000-1006. QIAN Pengjiang, SUN Shouwei, JIANG Yizhang, et al. Knowledge transfer based maximum entropy clustering[J]. Control and decision, 2015, 30(6): 1000-1006.
[14]PEDRYCZ W, RAI P. Collaborative clustering with the use of Fuzzy C-Means and its quantification[J]. Fuzzy sets and systems, 2008, 159(18): 2399-2427.
[15]GU Quanquan, ZHOU Jie. Learning the shared subspace for multi-task clustering and transductive transfer classification[C]//Proceedings of the Ninth IEEE International Conference on Data Mining. Miami, USA: IEEE, 2009: 159-168.
[16]GU Quanquan, ZHOU Jie. Co-clustering on manifolds[C]//Proceedings of the 15th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. New York, USA: ACM, 2009: 359-368.
[17] RANDEN T. Brodatz texture[EB/OL]. [2015-12-14]. http://www.ux.uis.no/~tranden/brodatz.html.
[18]DENG Zhaohong, CHOI K S, CHUNG F L, et al. Enhanced soft subspace clustering integrating within-cluster and between-cluster information[J]. Pattern recognition, 2010, 43(3): 767-781.
[19]KYRKI V, KAMARAINEN J K, KLVIINEN H. Simple Gabor feature space for invariant object recognition[J]. Pattern recognition letters, 2004, 25(3): 311-318.

程旸,男,1991年生,碩士研究生,主要研究方向為人工智能、模式識別、數(shù)據(jù)挖掘。

蔣亦樟,男,1988年生,博士,講師,主要研究方向為人工智能、模式識別、模糊系統(tǒng)。

錢鵬江,男,1979年生,副教授,博士,主要研究方向為模式識別、醫(yī)學(xué)圖像處理、大數(shù)據(jù)。
A maximum entropy clustering algorithm based onknowledge transfer and its application to texture image segmentation
CHENG Yang, JIANG Yizhang, QIAN Pengjiang, WANG Shitong
(School of Digital Media, Jiangnan University, Wuxi 214122, China)
In this paper, we propose a novel technique for maximum entropy clustering (MEC) based on knowledge transfer. More specifically, we aim to solve the following two challenging questions. First, how can knowledge be appropriately selected from a source domain to enhance clustering performance in the target domain via transfer learning? Second, how best do we conduct transfer clustering if the number of clusters in the source domain and the target domain are inconsistent? To address these questions, we designed a new transfer clustering mechanism called the central matching transfer mechanism, which we based on clustering centers. Further, we developed a knowledge-transfer-based maximum entropy clustering (KT-MEC) algorithm by incorporating our mechanism into the classic MEC approach. Our experimental results reveal that our proposed KT-MEC algorithm achieves a higher level of accuracy and better noise immunity than many existing methods when applied to texture image segmentation in different transfer scenarios.
transfer learning; center transfer matching; maximum entropy clustering; texture image segmentation; robustness
2016-03-04.
日期:2016-08-24.
國家自然科學(xué)基金項目(61572236);江蘇省自然科學(xué)基金項目(BK20160187);江蘇省產(chǎn)學(xué)研前瞻性聯(lián)合研究項目(BY2013015-02).
蔣亦樟. E-mail:jyz0512@163.com.
10.11992/tis.201603005
http://www.cnki.net/kcms/detail/23.1538.tp.20160824.0928.004.html
TP181
A
1673-4785(2017)02-0179-09
程旸,蔣亦樟,錢鵬江,等. 知識遷移的極大熵聚類算法及其在紋理圖像分割中的應(yīng)用[J]. 智能系統(tǒng)學(xué)報, 2017, 12(2): 179-187.
英文引用格式:CHENG Yang, JIANG Yizhang, QIAN Pengjiang, et al. A maximum entropy clustering algorithm based on knowledge transfer and its application to texture image segmentation[J]. CAAI transactions on intelligent systems, 2017, 12(2): 178-187.
