數據科學家參加競賽,開發癌癥檢測算法
2017-06-16 18:54:25ThorOlavsrud
計算機世界 2017年23期
Thor+Olavsrud
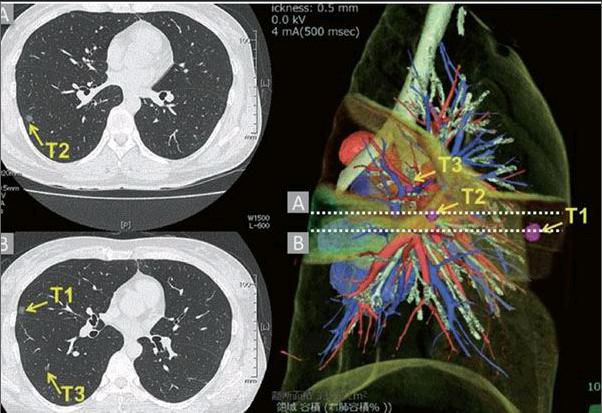
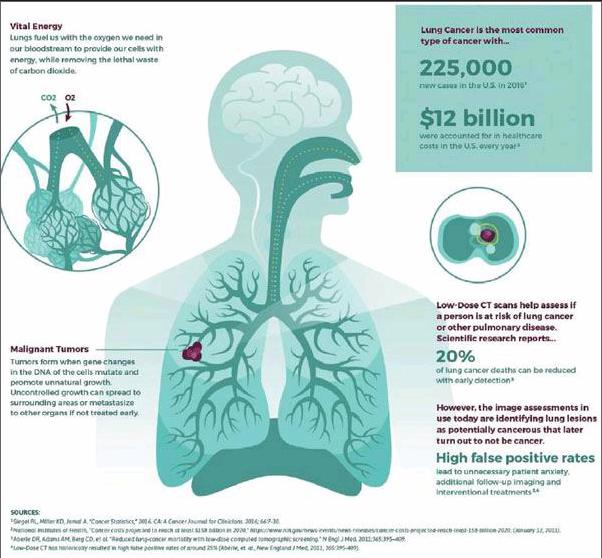
數據科學家正在使用機器學習來解決肺癌的檢測問題。從1月份開始,世界各地近1萬名數據科學家參加了數據科學碗競賽,開發最有效的算法,以幫助醫療專業人員更早、更準確地檢測肺癌。
2010年,美國國家肺癌篩查試驗顯示,使用低劑量計算機斷層掃描(CT)進行年度篩查能夠將肺癌死亡率減少20%,這種掃描設備使用計算機處理來自不同角度的大量X射線圖像,對這些圖像進行組合產生高對比度的3D圖像。雖然這一技術在早期檢測上實現了突破,但與更傳統的X射線相比,其誤報率也相對較高。
機器學習公司Kaggle與合作伙伴Booz Allen Hamilton出席了年度數據科學碗活動,Kaggle首席執行官Anthony Goldbloom說:“這真的是一種非常強大的方法,可以將癌癥死亡率降低20%,但是誤報率非常高。有很多人被告知他們得了癌癥,但后來才發現實際沒有。這是人為的代價。會讓人非常緊張。”
所以對于今年的數據科學碗,Booz Allen和Kaggle決定對數據科學和機器學習進行適當的引導,以解決誤報問題。在Laura和John Arnold基金會資助下,這兩名合作伙伴將為名列前十的參賽選手提供100萬美元獎金。
數據科學為社會公益做出貢獻
Booz Allen高級副總裁兼首席數據科學家Josh Sullivan說,Booz Allen和Kaggle在2015年創建了數據科學碗,目的是讓數據科學為社會公益做出貢獻。
他說:“我們想做一些讓人們聚在一起為社會公益做出貢獻的事情,能超越自我的事情。我們怎樣為社會公益切實做一些事情?我們希望所做的事情能夠導致科學發現。對公眾開放的事情;不是為了我們的利益或者客戶的利益,而是開放來源,為了世界各地的人們。”
Sullivan說,第三屆年度數據科學碗收到了300多個建議(前兩屆數據科學碗的主題是確定海洋健康和檢測心臟病的算法)。他說,最終,合作伙伴決定幫助美國國家癌癥研究所(NCI)及其《Beau Biden癌癥月刊》,努力加速癌癥研究,為更多的患者提供更多的治療方案,提高癌癥預防和早期檢測能力。
NCI為數據科學碗提供了2000張匿名的高分辨率CT掃描圖像,每張圖像包含千兆字節的數據。Sullivan說,1500張圖像是訓練集,有最終的診斷。剩下的500張圖像是問題集。使用訓練集后,參賽選手的機器學習算法必須學會怎樣正確地確定其余500張圖像中的肺部病變是否是癌變。根據正確診斷的百分比對算法進行評分。
數據已在Kaggle平臺上打包。谷歌在3月份收購的Kaggle是由Goldbloom于2010年創建的,專業舉辦預測模型和分析競賽。公司和研究人員發布數據,數據科學家在競賽中使用這些數據,產生最好的模型。該公司在近200個國家注冊了成百上千個“Kagglers”。
在這場競賽中,Kagglers是卷積神經網絡(CNN)方面的專家,這是一類由生物體內視覺機制啟發產生的深度學習神經網絡。CNN能夠解決很多不同類型的問題,但尤其擅長計算機視覺問題。在以前的Kaggle比賽中,Kaggler參賽人員競爭創建基于CNN的算法,這一算法可以在社交媒體上區分狗和貓的圖片。
Goldbloom對NCI提供的CT圖像發表了看法:“這一數據源很新奇,它真的把卷積神經網絡推向了從未涉足的方向。由于數據集的規模很大,醫學數據集始終是一個難題。互聯網上有多少貓和狗的圖片?可能是數百萬。但收集醫學圖像的成本非常高。人們會給自己的狗和貓照相,但很少去做CT掃描。”
Goldbloom解釋說,CNN非常容易出現名為“過度擬合”的效應,統計模型傾向于描述噪聲而不是基本關系,因為相對于觀測次數而言參數太多了。
Goldbloom說:“很難構建不過度擬合的卷積神經網絡,數據集越小就越難。這真的需要技巧。必須能夠從數量相對較少的圖像中得出抽象的結果。”
近10,000名Kagglers選手參加了數據科學碗。他們總共花了1萬5千多小時,提交了近18,000個算法。許多放射科醫師在Kaggle論壇上自愿為競賽選手提供專業知識,幫助他們完善工作。
數據科學碗獲勝者
最終,中國清華大學的兩位研究人員Liao Fangzhou和Zhe Li獲得了第一名。荷蘭的軟件和機器學習工程師Julian de Wit和Daniel Hammack獲得了第二名。為一家荷蘭公司工作的Aidence團隊獲得了第三名,該公司把機器學習技術應用于醫療圖像解釋。
Sullivan說:“NIH(美國國家衛生研究所)將最終與美國食品和藥物管理局合作,提供這些分析技術,以便應用于實際閱讀這些CT掃描圖像的軟件。這就是我們正在努力爭取的巨大利益。”
他說,他希望NIH和FDA能夠關注一些非常優秀的算法。優秀團隊的得分相差不到百分之幾,有的可能會很快轉化為產品,也有的非常適合擴展。
猜你喜歡
保健醫苑(2023年2期)2023-03-15 09:03:04
中國臨床醫學影像雜志(2022年2期)2022-05-25 13:24:34
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
小小藝術家(2019年6期)2019-06-24 17:39:44
今古傳奇·故事版(2016年15期)2016-09-07 06:57:32
海峽科技與產業(2016年3期)2016-05-17 04:32:12
醫學研究雜志(2015年12期)2015-06-10 06:57:46
小雪花·成長指南(2015年3期)2015-05-04 00:04:37
