面向標記分布學習的標記增強
2017-06-23 12:47:19邵瑞楓
計算機研究與發展 2017年6期
關鍵詞:方法
耿 新 徐 寧 邵瑞楓
(東南大學計算機科學與工程學院 南京 211189) (計算機網絡和信息集成教育部重點實驗室(東南大學) 南京 211189) (軟件新技術與產業化協同創新中心(南京大學) 南京 210093) (無線通信技術協同創新中心(東南大學) 南京 211189)
面向標記分布學習的標記增強
耿 新 徐 寧 邵瑞楓
(東南大學計算機科學與工程學院 南京 211189) (計算機網絡和信息集成教育部重點實驗室(東南大學) 南京 211189) (軟件新技術與產業化協同創新中心(南京大學) 南京 210093) (無線通信技術協同創新中心(東南大學) 南京 211189)
(xgeng@seu.edu.cn)
(CollaborativeInnovationCenterofWirelessCommunicationsTechnology(SoutheastUniversity),Nanjing211189)
多標記學習(multi-label learning, MLL)任務處理一個示例對應多個標記的情況,其目標是學習一個從示例到相關標記集合的映射.在MLL中,現有方法一般都是采用均勻標記分布假設,也就是各個相關標記(正標記)對于示例的重要程度都被當作是相等的.然而,對于許多真實世界中的學習問題,不同相關標記的重要程度往往是不同的.為此,標記分布學習將不同標記的重要程度用標記分布來刻畫,已經取得很好的效果.但是很多數據中卻僅包含簡單的邏輯標記而非標記分布.為解決這一問題,可以通過挖掘訓練樣本中蘊含的標記重要性差異信息,將邏輯標記轉化為標記分布,進而通過標記分布學習有效地提升預測精度.上述將原始邏輯標記提升為標記分布的過程,定義為面向標記分布學習的標記增強.首次提出了標記增強這一概念,給出了標記增強的形式化定義,總結了現有的可以用于標記增強的算法,并進行了對比實驗.實驗結果表明:使用標記增強能夠挖掘出數據中隱含的標記重要性差異信息,并有效地提升MLL的效果.
多標記學習;標記分布學習;標記增強;邏輯標記;標記分布
多標記學習(multi-label learning, MLL)可以處理一個示例對應多個標記的情況,其目標是學習一個多標記的分類器,將示例映射到與之相關的標記集合上[1-3].在過去的十余年間,MLL技術已經被廣泛地應用于許多領域,例如文本[4]、圖像[5]、語音[6]、視頻[7]等的分類、識別和檢索等,這些領域中的數據往往都含有豐富的語義,適合于用MLL來進行建模.
標記分布學習的出現使得從數據中學習比多標記更為豐富的語義成為可能,比如可以更精確地刻畫與同一示例相關的多個標記的相對重要性差異等.事實上,Geng[8]曾經指出,單標記學習和MLL都可以看作標記分布學習的特例,這也就意味著標記分布學習是一個更為泛化的機器學習框架,在此框架內研究機器學習方法具有重要的理論和應用價值.然而,標記分布學習應用的基礎是假設每個示例由一個涵蓋所有標記重要程度的標記分布來標注,這一點在很多實際應用中往往無法滿足.這些實際應用中的數據多數情況下由單標記或者多標記(均勻標記分布)標注,缺乏完整的標記分布信息.盡管如此,這些數據中的監督信息本質上卻是遵循某種標記分布的.這種標記分布雖然沒有顯式給出,卻常常隱式地蘊含于訓練樣本中.如果能夠通過合適的方法將其恢復出來,則可以真正發揮標記分布學習挖掘更多語義信息的優勢.
基于上述考慮,本文提出的面向標記分布學習的標記增強是指將訓練樣本中的原始邏輯標記轉化為標記分布的過程,這一過程依賴于對隱藏在訓練樣本中的標記相關信息的挖掘.假設Y表示樣本的原始邏輯標記空間,D表示經過標記增強后的標記分布空間,那么,標記增強方法將原始的標記空間Y={0,1}c拓展為D=[0,1]c,其中c表示標記的個數.事實上,D構成c維歐氏空間中的一個超立方體,而Y僅位于該超立方體的頂點.標記增強利用隱含于數據中的標記間相關性,可以有效加強示例的監督信息,進而通過標記分布學習獲得更好的預測效果.
盡管現有文獻中并未明確提出過標記增強的概念,但是許多工作中實際上已經涉及了一些與之相關的方法.例如:在頭部姿態估計問題中,文獻[9-10]依靠對數據的先驗知識,直接假設每個示例的標記分布為高斯分布;文獻[11-12]用圖模型表示示例間的拓撲結構,通過加入一些模型假設,建立示例間相關性與標記間相關性之間的關系,進而將示例的邏輯標記增強為標記分布;文獻[13-16]從訓練樣本中生成示例對每個標記的模糊隸屬度,從而可以將原有的邏輯標記增強為標記分布.上述工作有些是直接為標記分布學習而提出的,有些則是在其他領域提出但可以用來生成標記分布.不管哪種情況,它們都可以統一到同一個概念下,即本文提出的面向標記分布學習的標記增強.
1 符號及形式化定義
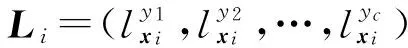
給定訓練集S={(xi,Li)|1≤i≤n},標記增強即根據S中蘊含的標記間相關性,將每個示例xi的邏輯標記Li轉化為相應的標記分布Di,從而得到標記分布訓練集E={(xi,Di)|1≤i≤n}的過程.
2 標記增強方法
在標記分布學習這一概念提出之后,陸續有文獻提出了一些面向標記分布學習的標記增強方法.這些研究有的利用了具體應用中的先驗知識,如頭部姿態和人臉年齡的先驗分布[9-10];有的使用了半監督學習[17]中常用的標記傳播方法[11];也有的引入了流形學習[12],均取得了不錯的結果.而事實上,在標記分布學習概念提出之前,其他領域也已經出現了一些方法,盡管它們的應用背景和具體目標不盡相同,但是放到標記分布學習的框架之中,卻可以用于實現標記增強,經典的如模糊聚類[13]、核隸屬度[14]等.
本文將現有的標記增強算法分為3種類型,分別是基于先驗知識的標記增強、基于模糊方法的標記增強和基于圖模型的標記增強.下面分別闡述這3種類型中典型的標記增強算法.
2.1 基于先驗知識的標記增強
基于先驗知識的標記增強算法建立在對數據本身特點有較為深入理解的基礎之上,完全依靠先驗知識直接將邏輯標記增強為標記分布,或者部分引入先驗知識,在此基礎上通過挖掘隱含的標記間相關性將邏輯標記增強為標記分布.本節介紹2種基于先驗知識的標記增強算法,分別是基于先驗分布的標記增強算法和基于自適應先驗分布的標記增強算法.
2.1.1 基于先驗分布的標記增強
在某些特定的應用中,人們根據對數據的了解,可以預先知道每個示例應滿足的標記分布的參數模型,這種含參標記分布模型就稱為先驗分布.一旦利用邏輯標記以及一些啟發式方法確定了這種模型中的參數,就可以為每個示例生成相應的標記分布.

(1)

基于先驗分布的標記增強算法一般在假設一個先驗分布的前提下,利用邏輯標記以及一些啟發式方法確定先驗分布的參數,直接將示例xi的邏輯標記Li轉化為相應的標記分布Di,從而得到標記分布訓練集E={(xi,Di)|1≤i≤n}.這類方法依賴于算法設計者對數據本身的深入理解.如果這種理解與事實相符則可能獲得不錯的效果,并且實現起來方便高效.然而,一旦對數據的理解有所偏差,則標記增強后的結果往往并不理想.
2.1.2 基于自適應先驗分布的標記增強
如前所述,2.1.1節中的標記增強算法完全依靠先驗知識直接將邏輯標記增強為標記分布.這一做法過于依賴先驗知識,在許多對數據的了解不夠充分的情況下,其生成的標記分布不一定能夠真實反映數據本身的特點.為了解決上述問題,Geng等人[10]以人臉年齡估計為應用背景,在引入先驗分布的前提下,通過自適應方法確定先驗分布中的參數,從而將每個示例xi的邏輯標記Li轉化為相應的標記分布Di.

(2)

基于自適應先驗分布的標記增強算法部分引入先驗知識,通過自適應的方法,從訓練樣本中學習得到先驗分布的參數,進而將每個示例xi的邏輯標記Li轉化為相應的標記分布Di.這類方法部分依賴先驗知識,部分依賴從樣例中學習,因此相較2.1.1節中完全依賴先驗知識的方法更能有效利用隱藏在訓練數據中的標記間相關性.正如文獻[10]中的實驗所報告的結果,一般情況下,基于自適應先驗分布的標記增強算法效果要優于完全依賴先驗分布的標記增強算法.
2.2 基于模糊方法的標記增強
基于模糊方法的標記增強[13-16]利用模糊數學的思想,通過模糊聚類、模糊運算和核隸屬度等方法,挖掘出標記間相關信息,將邏輯標記轉化為標記分布.值得注意的是,這類方法提出的目的一般是為了將模糊性引入原本剛性的邏輯標記,而并未明確其可以將邏輯標記增強為標記分布.但是,很多模糊標記增強方法實際上可以基于模糊隸屬度輕松生成標記分布.
本節介紹2種基于模糊方法的標記增強算法,分別是基于模糊聚類的標記增強算法和基于核隸屬度的標記增強算法.
2.2.1 基于模糊聚類的標記增強
基于模糊聚類的標記增強[13]通過模糊C-均值聚類(fuzzy c-means algorithm, FCM)[18]和模糊運算,將訓練集S中每個示例xi的邏輯標記Li轉化為相應的標記分布Di,從而得到標記分布訓練集E={(xi,Di)|1≤i≤n}.
模糊C-均值聚類(FCM)是用隸屬度確定每個數據點屬于某個聚類程度的一種聚類算法.FCM把n個樣本分為p個模糊聚類,并求每個聚類的中心,使得所有訓練樣本到聚類中心的加權(權值由樣本點對相應聚類的隸屬度決定)距離之和最小.假設FCM將訓練集S分成p個聚類,μk表示第k個聚類的中心,則可用:
(3)

(4)
即Aj為所有屬于第j個類的樣本的隸屬度向量之和.經過行歸一化后得到的矩陣A可以被當作一個“模糊關系”矩陣,A中的元素Ajk表示了第j個類別(標記)與第k個聚類的關聯強度.

Vi=A°mxi,
(5)
其中,°表示模糊數學中的合成算子.最后,對隸屬度向量Vi進行歸一化,使向量中元素的和為1,即得到標記分布Di.
基于模糊聚類的標記增強算法利用模糊聚類過程中產生的示例對每個聚類的隸屬度,通過類別和聚類的關聯矩陣,將示例對聚類的隸屬度轉化為對類別的隸屬度,從而生成標記分布.在這一過程中,模糊聚類反映了示例空間的拓撲關系,而通過關聯矩陣將這種關系轉化到標記空間,從而有可能使得簡單的邏輯標記產生更豐富的語義,轉變為標記分布.
2.2.2 基于核隸屬度的標記增強
該標記增強方法源于一種模糊支持向量機中核隸屬度的生成過程[14],通過一個非線性映射函數將示例xi映射到高維空間,利用核函數計算該高維空間中正負類的中心、半徑和各示例xi到類別中心的距離,進而通過隸屬度函數計算示例xi的標記分布.

φ(xi),
(6)

(7)
其中,φ(xi)是一個非線性映射函數,由核函數K(xi,xj)=φ(xi)×φ(xj)確定.正類和負類的半徑分別計算為
(8)
(9)
樣本xi到正類和負類中心的平方距離分別是:
(10)
(11)
則示例xi對于標記yj的隸屬度為

基于核隸屬度的標記增強算法利用核技巧在高維空間中計算示例對每個類別的隸屬度,從而能夠挖掘訓練數據中類別標記間較為復雜的非線性系.
2.3 基于圖模型的標記增強
基于圖模型的標記增強算法用圖模型表示示例間的拓撲結構,通過引入一些模型假設,建立示例間相關性與標記間相關性之間的關系,進而將示例的邏輯標記增強為標記分布.本節介紹2種基于圖模型的標記增強算法,分別是基于標記傳播的標記增強算法和基于流形的標記增強算法.
2.3.1 基于標記傳播的標記增強
文獻[11]將半監督學習[17]中的標記傳播技術應用于標記增強中.該方法首先根據示例間相似度構建一個圖,然后根據圖中的拓撲關系在示例間傳播標記,由于標記的傳播會受到路徑上權值的影響,會自然形成不同標記的描述度差異,當標記傳播收斂時,每個示例的原有邏輯標記即可增強為標記分布.
具體地,假設多標記訓練集S={(xi,Li)|1≤i≤n},G=(V,E,W)表示以S中的示例為頂點的全連通圖,其中V={xi|1≤i≤n}表示頂點,E表示頂點兩兩之間的邊,xi與xj之間的邊上的權值為它們之間的相似度:
(13)

F(t)=αPF(t-1)+(1-α)Φ,
(14)
其中,α是平衡參數,控制了初始的邏輯標記和標記傳播對最終描述度的影響程度.經過迭代,最終F收斂到:F*=(1-α)(I-αP)-1Φ,對F*做歸一化處理:
(15)

基于標記傳播的標記增強算法通過圖模型表示示例間的拓撲結構,構造了基于示例間相關性的標記傳播矩陣,利用傳播過程中路徑權值的不同使得不同標記的描述度自然產生差異,從而反映出蘊含在訓練數據中的標記間關系.
2.3.2 基于流形的標記增強
基于流形的標記增強算法[12]假設數據在特征空間和標記空間均分布在某種流形上,并利用平滑假設將2個空間的流形聯系起來,從而可以利用特征空間流形的拓撲關系指導標記空間流形的構建,在此基礎上將示例的邏輯標記增強為標記分布.
具體地,該算法用圖G=(V,E,W)表示多標記訓練集S的特征空間的拓撲結構,其中V是由示例構成的頂點集合,E是邊的集合,W=(wij)n×n是圖的邊權重矩陣.首先,在特征空間中,假設示例分布的流形滿足局部線性,即任意示例xi可以由它的K-近鄰的線性組合重構,重構權值矩陣W可通過最小化得到:
s.t.wij=0,xj不是xi的K-近鄰,
(16)
其中,Wi表示W的第i行,1T表示全部由1構成的向量.通過平滑假設[19],即特征相似的示例的標記也很可能相似,可將特征空間的拓撲結構遷移到標記空間中,即共享同樣的局部線性重構權值矩陣W.這樣,標記空間的標記分布可由最小化得到:
(17)
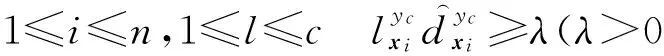
(18)
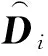
基于流形的方法通過重構特征空間和標記空間的流形,利用平滑假設將特征空間的拓撲關系遷移到標記空間中,建立示例間相關性與標記間相關性之間的關系,從而將邏輯標記增強為標記分布.
2.4 小結與比較
本節簡要介紹了現存的3類可用于實現標記增強的方法,分別是基于先驗知識的標記增強、基于模糊方法的標記增強和基于圖模型的標記增強,每一類方法分別介紹了幾種典型的實現算法.這些算法有些是專門為了將邏輯標記增強為標記分布而提出的,如基于先驗知識的標記增強方法和基于圖模型的標記增強方法;有些則是源于其他領域的工作,但可以借用到本文語境中實現標記增強,如基于模糊方法的標記增強.這些不同的增強方法,或者通過先驗知識,或者通過從樣本中學習來獲得額外的監督信息,從而將訓練樣本原有的簡單邏輯標記轉化為信息量更為豐富的標記分布.綜合來看,對于不同類型的標記增強算法,其優點和缺點總結如下:
1) 基于先驗知識的標記增強.優點:在對數據有比較深入理解的前提下,可以充分利用先驗知識,快速高效地實現標記增強;缺點:過于依賴先驗知識,在缺乏關于數據的領域知識的情況下無法應用此類方法.
2) 基于模糊方法的標記增強.優點:利用模糊隸屬度,將標記間相關信息與邏輯標記融合,不需要建立精確的數學模型,有較強的魯棒性,數據和參數等對算法影響較小;缺點:缺乏深度挖掘標記空間和特征空間信息的明確模型,往往難以生成符合特定數據特點的標記分布.
3) 基于圖模型的標記增強.優點:充分利用特征空間的拓撲關系來指導標記空間相關性信息挖掘,有良好的數學基礎,有利于形成適合數據本身特點的標記增強算法;缺點:模型較為復雜,數據和參數對算法的影響較大.
3 實 驗
本節實驗在不同數據集上測試了第2節提到的3種代表性的標記增強算法.由于基于先驗知識的標記增強方法依賴于對數據本身的深入理解,只有在特定數據集上才能應用,因此這類算法這里不作比較.
實驗主要分為2個部分:
1) 在一個人造數據集上測試所有對比算法由邏輯標記增強為標記分布的精度;
2) 在11個多標記數據集上,將基于標記增強的標記分布學習算法與主流的MLL算法進行對比.
3.1 實驗設置
3.1.1 數據集
實驗中共使用了12個數據集,包括1個人造數據集和11個真實世界的多標記數據集.
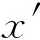

(19)
(20)
(21)
(22)
(23)
(24)
這樣共生成2 601個分布于三維特征空間流形上的示例,每個示例對應的真實標記分布D由式(19)~(23)產生.



Table 1 Attributes of the Benchmark Multi-label Data Sets表1 基準多標記數據集屬性
實驗第2部分使用11個基準多標記數據集*http://meka.sourceforge.net/#datasets和http://mulan.sourceforge.net/datasets.html,這些數據集均來自真實應用場景,在本實驗中用于比較基于標記增強的MLL與傳統MLL算法.表1總結了這些數據集的各種屬性.其中,|S|,dim(S),L(S)和F(S)分別表示數據集的樣本數目、特征維度、類別標記數目和特征類型.另外還有一些關于多標記數據的統計指標[20],包括標記基數LCard(S)、標記密度LDen(S)、獨特標記集合DL(S)和獨特標記集合占比PDL(S).
3.1.2 對比算法

實驗的第1部分在人造數據集上直接對比4種標記增強算法生成的標記分布與真實標記分布相比的相似程度.第2部分在11個多標記數據集上對比基于標記增強的MLL和傳統的MLL算法.所謂基于標記增強的MLL是指先分別用4種標記增強算法將數據集中原有的邏輯標記增強為標記分布;然后用標記分布學習算法SA-BFGS[8]為從示例到標記分布的映射建模;最后在測試時,用3.1.1節介紹的二值化方法將預測出的標記分布轉化為邏輯標記.
用于對比的傳統MLL算法包括4種MLL領域的主流算法,分別為binary relevance(BR)[21],calibrated label ranking(CLR)[22],ensemble of classifier chains (ECC)[20]和RAndom K-labELsets (RAKEL)[23].這4種算法都在MULAN MLL包[24]上運行,基分類器為logistic regression模型,ECC全體尺度設置為30,RAKEL的全體尺度設置為2c且K=3.
3.1.3 評價指標
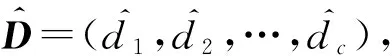

Table 2 Evaluation Measures for Label Enhancement Algorithms
Notes: “↓” indicates the smaller the better, and “↑” indicates the larger the better.
將標記增強算法與傳統的MLL方法比較時,我們使用了在MLL中常用的5種評價指標,分別是Hamming-loss,One-error,Coverage,Ranking-loss和Average-precision[25].
3.2 實驗結果
3.2.1 標記分布比較實驗
為了直觀可視化標記增強的效果,假設人造數據集中標記分布的3個分量分別對應RGB顏色空間的3個顏色通道.這樣,每個示例的標記分布就可以用示例空間中點的顏色來直觀表示.根據3.1.1節描述的人造數據采樣方法可知,2 601個樣本點分布在三維示例空間的一個流形上.因此,通過比較這個流形上的顏色模式即可直觀判斷不同算法標記增強的效果.圖1顯示了人造數據集上的真實標記分布(圖1(a))以及4種標記增強算法得到的標記分布(圖1(b)~1(e)).為了方便觀察,圖1中對流形上的顏色應用了去相關拉伸(decorrelation stretch)技術來增強顏色對比度.由圖1可以看出,LP算法標記增強后的顏色模式非常接近真實標記分布,KM算法和ML算法記增強后的顏色模式也與真實標記分布相似,FCM算法的顏色模式和真實值差距較大.
進一步,我們對4種標記增強算法在人造數據集上的表現進行了定量分析.表3給出了4種標記增強算法在表2所示的6種評價指標上的比較結果,每個結果后的括號中給出了相應算法的排序,并且統計了每種算法在所有指標上的平均排序.表3中的結果與圖1的可視化比較結果一致,即根據平均排序:LP?KM?ML?FCM.LP算法的表現最好,因為該算法在保留了原始的邏輯標記的前提下,使用示例間相關信息對邏輯標記進行了增強;KM算法使用了模糊方法,不會對增強后的標記分布引入過多的誤差,因此該算法也能夠得到較為不錯的結果;ML算法使用了流形模型,將示例間的相關信息與標記相關信息建立了聯系,但使用的約束項不能夠保留較多的原始邏輯信息,因此標記增強效果與KM算法接近;FCM算法的標記分布生成中使用了簡單的模糊合成運算,不能有效地挖掘標記相關信息,因此標記增強的效果較差.

Fig. Visual comparison between the tabel distributions generated by the label anhancement algorithms and the groun-truth label distributions
圖1 標記增強算法生成的標記分布與真實標記分布的可視化對比
Table3 Quantitative Comparison Between the Label Distributions Generated by the Label Enhancement Algorithms and the Ground-truth Label Distributions

表3 標記增強算法生成的標記分布與真實標記分布的定量對比
Notes:“↓” indicates the smaller the better, and “↑” indicates the larger the better.
3.2.2 MLL比較實驗
實驗的第2部分在11個真實世界的多標記數據集上比較基于標記增強的MLL與傳統MLL算法.在每個數據集上采用10倍交叉驗證,記錄每個算法分別在5個MLL評價指標上的平均值,結果如表4~8所示.其中,評價指標后的“↓”表示“越低越好”,“↑”表示“越高越好”.在每種指標和每個數據集上表現最好的算法的結果用黑體表示.算法在每種指標和每個數據集上的排序顯示在其結果后的括號中,并統計了每種算法在所有數據集上的平均排序.
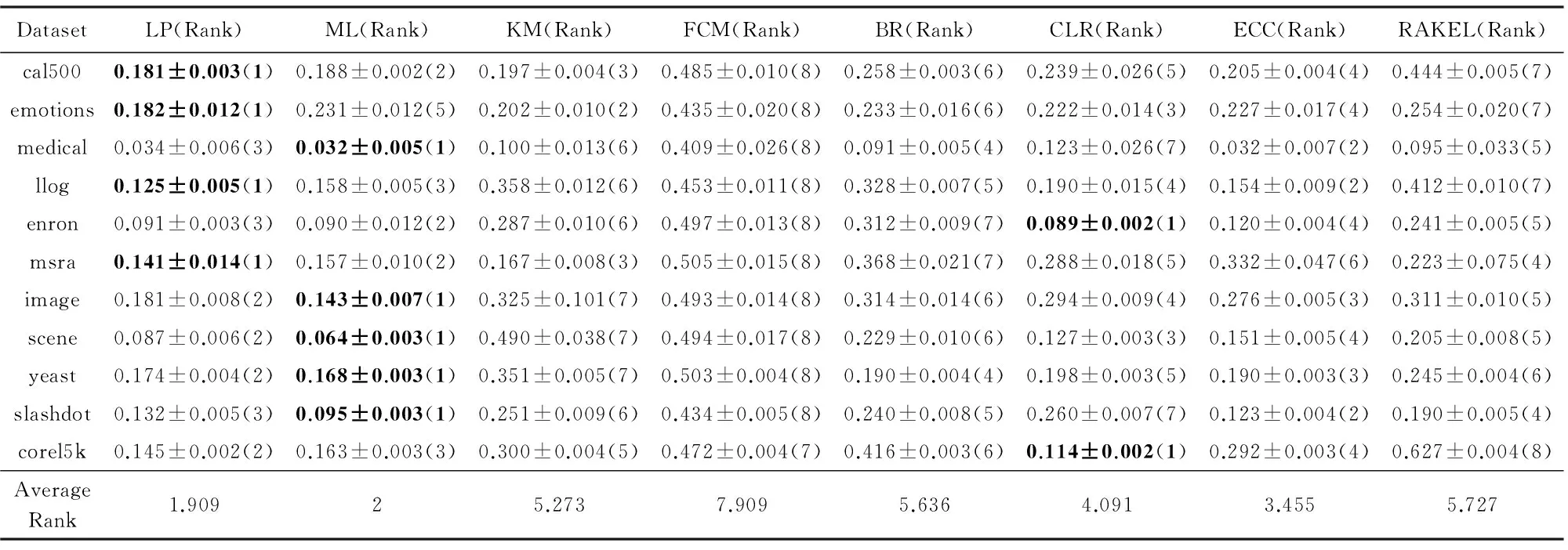
Table 4 Comparison of Multi-label Learning Algorithms on Ranking-loss↓ (mean±std)表4 MLL算法在Ranking-loss↓指標(均值±標準差)上的比較

Table 5 Comparison of Multi-label Learning Algorithms on One-error↓ (mean±std)表5 MLL算法在One-error↓指標(均值±標準差)上的比較

Table 6 Comparison of Multi-label Learning Algorithms on Hamming-loss↓ (mean±std)表6 MLL算法在Hamming-loss↓指標(均值±標準差)上的比較

Table 7 Comparison of Multi-label Learning Algorithms on Coverage↓ (mean±std)表7 MLL算法在Coverage↓指標(均值±標準差)上的比較

Table 8 Comparison of Multi-label Learning Algorithms on Average-precision↑ (mean±std)表8 MLL算法在Average-precision↑指標(均值±標準差)上的比較
為了從統計意義上比較8種算法在11個數據集上的表現,這里采用一種由Dem?ar[26]提出的兩步統計假設檢驗法.該方法首先對原假設“所有算法的平均排序是一樣的”應用Friedman檢驗.表9給出了在顯著水平為0.05、對比算法數為8、數據集數為11時,各個評價指標上的Friedman統計值FF及關鍵值(critical value).可以看出,所有指標上的FF值均大于關鍵值,因此在所有指標上都可以拒絕原假設,即在每個指標上所有算法的平均排序不是都一樣的.在此基礎上,該方法第2步用Nemenyi檢驗來檢驗算法兩兩之間的平均排序比較,結果可用如圖2所示的CD(critical difference)圖來表示.Nemenyi檢驗在顯著水平為0.05、對比算法數為8、數據集數為11時,CD=2.809 6.在CD圖中,每個算法的平均排序被標注在同一條坐標軸上.如果2個算法的平均排序之差小于CD值,則說明兩者沒有顯著差異,在CD圖中即將這2個算法用一條線段連起來.

Table 9 Friedman Statistics on Each Evaluation Measure表9 各種評價指標上的Friedman統計值

Fig. 2 CD diagrams (CD=2.809 6) of the Nemenyi tests on the eight algorithms for the five evaluation measures圖2 在5個不同評價指標上對8種算法對比應用Nemenyi檢驗的CD圖
基于表4~8和圖2中的實驗結果,我們可以得出以下8條結論:
1) 總體上,4種標記增強算法排名大致為LP?ML?KM?FCM.
2) 在Ranking-loss(圖2(a))和Coverage(圖2(d))指標上,LP的平均排序是最小的(最優的).
3) 在One-error(圖2(b))、Hamming-loss(圖2(c))和Average precision(圖2(e))指標上,ML的平均排序是最小的(最優的).
4) 在5種評價指標中,ML和LP并沒有顯著差異,而且這2種標記增強算法都顯著地優于MLL算法BR.
5) 在One-error和Average precision指標上,ML顯著地優于MLL算法BR,CLR和RAKEL.
6) 在Ranking-loss,Coverage和Average precision指標上,LP顯著優于MLL算法BR和RAKEL.
7) 在5種指標上,KM優于BR,且KM與ECC,CLR,RAKEL沒有顯著的差異.
8) 4種標記增強方法中,FCM平均排序是最差的,但與BR沒有顯著差異.
對比3.2.1節中的實驗結果,ML在第2部分實驗的表現好于KM主要是因為這里采用的數據集的標記空間維度(標記個數)明顯高于3.2.1節中所采用的人造數據集.這時,KM中對標記逐個處理的手法自然使得其在標記個數較多時表現不佳.另外,總體來看,基于圖模型的標記增強(LP和ML)平均性能要優于基于模糊方法的標記增強(KM和FCM),這主要是因為KM和FCM都并非為了面向標記分布的標記增強而專門設計,因此一些非針對性的做法,如模糊操作的簡單運用或者對不同標記的逐個處理使得這類方法直接用于標記增強效果并不理想.當然,在一些特殊情況下,如標記個數比較少時,模糊方法也可能取得不錯的表現.例如,在人造數據集上KM的表現就要優于ML.
綜上,可以認為,一方面,有效的標記增強(如LP和ML算法)能夠顯著提升傳統MLL的效果.這說明標記增強確實有助于挖掘蘊含在訓練樣本中的標記間相關信息;另一方面,由于KM和FCM算法并非為標記分布專門設計,所以標記增強的效果并不理想,這也說明了針對面向標記分布的標記增強進行專門研究的必要性.
4 結 論
本文提出了面向標記分布的標記增強這一新概念.這類方法可以從訓練樣本中挖掘隱藏的標記間相關性信息,將樣本中原有的簡單邏輯標記增強為包含更多監督信息的標記分布,從而為后續的機器學習過程提供了更多可用信息.
本文綜述了可用于面向標記分布的標記增強方法.它們有些是專門為標記分布學習提出的增強方法,有些則是在其他領域(如模糊分類)提出,但可以用于實現標記增強.本文進一步通過在1個人造數據集和11個真實世界的多標記數據集上的實驗,比較了已有標記增強算法的表現,顯示了標記增強方法的優勢.實驗結果表明,建立在良好標記增強基礎上的MLL算法能夠取得比建立在邏輯標記基礎上的傳統MLL算法更好的表現,這也說明了對標記增強方法進一步深入研究的必要性.未來在標記增強方面的研究至少包括3點重要內容:
1) 建立可用于標記增強實驗的標準數據集.目前適合于標記增強算法實驗的數據集還非常少,本文不得不借助人造數據或者多標記數據集來進行初步實驗.而適合于標記增強的專門數據集中應包括真實的標記分布以及對應的邏輯標記.
2) 建立標記增強算法的性能評價體系.該評價體系應能全面反映算法從簡單邏輯標記恢復真實標記分布的能力.
3) 提出能夠充分利用標記間相關性的標記增強算法.標記間相關性既可以體現在標記空間,也可能從示例空間遷移而來,這方面不論是理論層面還是應用層面都還有很大的研究空間.
[1]Gibaja E, Ventura S. A tutorial on multilabel larning[J]. ACM Computing Surveys, 2015, 47(3): 1-38
[2]Tsoumakas G, Katakis I, Vlahavas I. Mining multi-label data[G]//Data Mining and Knowledge Discovery Handbook. Berlin: Springer, 2009: 667-685
[3]Zhang Minling, Zhou Zhihua. A review on multi-Label learning algorithms[J]. IEEE Trans on Knowledge & Data Engineering, 2014, 26(8): 1819-1837
[4]Rubin N T, Chambers A, Smyth P, et al. Statistical topic models for multi-label document classification[J]. Machine Learning, 2012, 88(1): 157-208
[5]Cabral S R, Torre F D, Costeira P J, et al. Matrix completion for multi-label image classification[C] //Proc of NIPS 2011. Cambridge, MA: MIT Press, 2011: 190-198
[6]Lo H Y, Wang J C, Wang H M, et al. Cost-sensitive multi-Label learning for audio tag annotation and retrieval[J]. IEEE Trans on Multimedia, 2011, 13(3): 518-529
[7]Wang Jingdong, Zhao Yinghai, Wu Xiuqing, et al. A transductive multi-label learning approach for video concept detection[J]. Pattern Recognition, 2011, 44(10/11): 2274-2286
[8]Geng Xin. Label distribution learning[J]. IEEE Trans on Knowledge and Data Engineering, 2016, 28(7): 1734-1748
[9]Geng Xin, Xia Yu. Head pose estimation based on multivariate label distribution[C] //Proc of IEEE Conf on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE, 2014: 3742-3747
[10]Geng Xin, Wang Qin, Xia Yu. Facial age estimation by adaptive label distribution learning[C] //Proc of the 22nd Int Conf on Pattern Recognition. Piscataway, NJ: IEEE, 2014: 4465-4470
[11]Li Yukun, Zhang Minling, Geng Xin. Leveraging implicit relative labeling-importance information for effective multi-label learning[C] //Proc of IEEE Int Conf on Data Mining. Piscataway, NJ, IEEE, 2015: 251-260
[12]Hou Peng, Geng Xin, Zhang Minling. Multi-label manifold learning[C] //Proc of the 30th AAAI Conf on Artificial Intelligence. Menlo Park, CA: AAAI, 2016: 1680-1686
[13]Gayar N E, Schwenker F, Palm G. A study of the robustness of KNN classifiers trained using soft labels[C] //Proc of the 2nd Conf Artificial Neural Networks in Pattern Recognition. Berlin: Springer, 2006: 67-80
[14]Jiang Xiufeng, Yi Zhang, Lv Jiancheng. Fuzzy SVM with a new fuzzy membership function[J]. Neural Computing & Applications, 2006, 15(3/4): 268-276
[15]Lin Xiaotong, Chen Xuewen. Mr. KNN: Soft relevance for multi-label classification[C] //Proc of the 19th ACM Int Conf on Information and Knowledge Management. New York: ACM, 2010: 349-358
[16]Jiang J Y, Tsai C C, Lee S J. FSKNN: Multi-label text categorization based on fuzzy similarity and k nearest neighbors[J]. Expert Systems with Applications, 2012, 39(3): 2813-2821
[17]Zhu Xiaojin, Goldberg A B. Introduction to Semi-Supervised Learning[M]. Williston, VT: Morgan & Claypool, 2009[18]Klir J G, Yuan B. Fuzzy sets and fuzzy logic[G] //Theory and Applications. Upper Saddle River, NJ: Prentice Hall, 1995
[19]Zhu Xiaojin, Lafferty J, Rosenfeld R. Semi-supervised learning with graphs[D]. Pittsburgh, PA: Language Technologies Institute, School of Computer Science, Carnegie Mellon University, 2005
[20]Read J, Pfahringer B, Holmes G, et al. Classifier chains for multi-label classification[J]. Machine Learning, 2011, 85(3): 333-359
[21]Boutell R M, Luo Jiebo, Shen Xipeng, et al. Learning multi-label scene classification[J]. Pattern Recognition, 2004, 37(9): 1757-1771
[22]Fürnkranz J, Hüllermeier E, Mencía E L, et al. Multi-label classification via calibrated label ranking[J]. Machine Learning, 2008, 73(2): 133-153
[23]Tsoumakas G, Katakis I, Vlahavas I. Randomk-labelsets for multilabel classification[J]. IEEE Trans on Knowledge and Data Engineering, 2011, 23(7): 1079-1089
[24]Tsoumakas G, Eleftherios S, Vilcek J, et al. MULAN: A Java library for multi-label learning[J]. Journal of Machine Learning Research, 2011, 12(7): 2411-2414
[25]Zhang Minling, Zhou Zhihua. A review on multi-label learning algorithms[J]. IEEE Trans on Knowledge and Data Engineering, 2014, 26(8): 1819-1837
[26]Dem?ar J. Statistical comparisons of classifiers over multiple data sets[J]. Journal of Machine Learning Research, 2006, 7(1): 1-30

Geng Xin, born in 1978. PhD, professor. His main research interests include machine learning, pattern recognition, and computer vision.

Xu Ning, born in 1988. PhD candidate. His main research interests include pattern recognition and machine learning.

Shao Ruifeng, born in 1994. Master candidate. His main research interests include pattern recognition and machine learning.
Label Enhancement for Label Distribution Learning
Geng Xin, Xu Ning, and Shao Ruifeng
(SchoolofComputerScienceandEngineering,SoutheastUniversity,Nanjing211189) (KeyLaboratoryofComputerNetworkandInformationIntegration(SoutheastUniversity),MinistryofEducation,Nanjing211189) (CollaborativeInnovationCenterofNovelSoftwareTechnologyandIndustrialization(NanjingUniversity),Nanjing210093)
Multi-label learning (MLL) deals with the case where each instance is associated with multiple labels. Its target is to learn the mapping from instance to relevant label set. Most existing MLL methods adopt the uniform label distribution assumption, i.e., the importance of all relevant (positive) labels is the same for the instance. However, for many real-world learning problems, the importance of different relevant labels is often different. For this issue, label distribution learning (LDL) has achieved good results by modeling the different importance of labels with a label distribution. Unfortunately, many datasets only contain simple logical labels rather than label distributions. To solve the problem, one way is to transform the logical labels into label distributions by mining the hidden label importance from the training examples, and then promote prediction precision via label distribution learning. Such process of transforming logical labels into label distributions is defined as label enhancement for label distribution learning. This paper first proposes the concept of label enhancement with a formal definition. Then, existing algorithms that can be used for label enhancement have been surveyed, and compared in the experiments. Results of the experiments reveal that label enhancement can effectively discover the difference of the label importance hidden in the data, and improve the performance of multi-label learning.
multi-label learning (MLL); label distribution learning (LDL); label enhancement; logical label; label distribution
2017-01-03;
2017-03-09
國家自然科學基金優秀青年科學基金項目(61622203);江蘇省自然科學基金杰出青年基金項目(BK20140022) This work was supported by the National Natural Science Fundation of China for Excellent Young Scientists (61622203) and Jiangsu Natural Science Funds for Distinguished Young Scholar (BK20140022).
TP391
猜你喜歡
中老年保健(2021年9期)2021-08-24 03:52:04
河北畫報(2021年2期)2021-05-25 02:07:46
中學生數理化(高中版.高考理化)(2020年2期)2020-04-21 05:33:04
兒童繪本(2020年5期)2020-04-07 17:46:30
兒童故事畫報(2019年5期)2019-05-26 14:26:14
Coco薇(2016年2期)2016-03-22 02:42:52
山東青年(2016年1期)2016-02-28 14:25:23
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
