大型計算機網絡中的非正常數據挖掘技術研究
2017-06-23 07:41:26王曉靜李琦
現代電子技術 2017年12期
王曉靜++李琦
摘 要: 大型計算機網絡中的各種軟件和設備均存在安全漏洞,導致以往提出的大型計算機網絡中非正常數據挖掘方法無法進行合理挖掘。針對該問題,提出一種新型的大型計算機網絡中非正常數據挖掘方法。所提方法通過數據洗滌、格式變換和模式挖掘等操作,挖掘出大型計算機網絡中的非正常數據。使用所提方法設計的數據挖掘系統由數據挖掘器、分析模塊和數據庫組成,數據庫為數據挖掘器和分析模塊提供處理和挖掘方案。數據挖掘器實時監控著大型計算機網絡中的非正常情況,并進行數據處理。分析模塊使用“二次激活”方式對處理過的數據進行分析,挖掘出其中的非正常數據。實驗結果表明,所提方法具有較好的收斂性,所設計的系統具有較強的可擴展性。
關鍵詞: 大型計算機網絡; 非正常數據; 數據挖掘技術; 合理挖掘
中圖分類號: TN711?34; TP393.08 文獻標識碼: A 文章編號: 1004?373X(2017)12?0059?04
Abstract: Various softwares and equipments in large?scale computer networks have security holes, which lead to the previously?proposed abnormal data mining methods in large?scale computer networks can′t make reasonable mining. Therefore, a new abnormal data mining method in large?scale computer network is put forward. The method can mine the abnormal data in large?scale computer network by data washing, data format conversion and pattern mining operation. The data mining system designed with the proposed method is composed of data mining processor, analysis module and database. The database provides the processing and mining schemes for data mining processor and analysis module. The data mining processor is used to monitor the abnormal situation in large?scale computer network in real time, and carry out data processing. The analysis module is used to analyze the processed data by means of "secondary activation" mode, and dig up the abnormal data. The experimental results show that the proposed method has good convergence, and the system designed with the method has strong scalability.
Keywords: large?scale computer network; abnormal data; data mining technology; reasonable mining
0 引 言
隨著電子信息技術的普及和不斷發展,大型計算機網絡隨之產生,越來越多的網民能夠更為便捷地享受各種信息資源,現如今,網絡已成為人們生活中不可缺少的一部分。大型計算機網絡在為人們提供便利的同時,也造成了一定的困擾,網絡入侵事件時有發生[1]。若想有效維護大型計算機網絡安全,需要將其中的非正常數據準確、高效地挖掘出來,相關組織已開始著手進行大型計算機網絡中非正常數據挖掘技術的研究工作[2]。
1 非正常數據挖掘技術
數據挖掘技術是指依據特定任務,將重要的隱含知識從具有一定干擾存在下的隨機數據集群中提煉出來[3]。數據挖掘技術是一項交匯科目,經其挖掘出來的數據具有一定的輔助決策作用。將這種技術用于進行大型計算機網絡非正常數據的挖掘工作中,能夠自動控制大量初始數據,為用戶提供更多的便利[4]。
所提大型計算機網絡中非正常數據挖掘方法的挖掘流程如圖1所示。
由圖1可知,所提方法先對大型計算機網絡中的初始數據集群進行統一處理,處理過程包括數據洗滌和格式變換。數據洗滌的目的是將初始數據集群中的噪音、重疊參數和缺失重要特征的數據除去,再經由格式變換,使洗滌后的數據集群特征更加明顯,提高對非正常數據的挖掘準確性。
當數據處理完畢,所提方法隨即開始進行模式挖掘。所謂模式挖掘,是指通過對比分析方式獲取大型計算機網絡中數據之間共有特征的過程,所獲取到的共有特征即為數據挖掘技術中的“知識”[5]。
將模式挖掘定義成向的映射,和均是大型計算機網絡中初始數據集群的一部分,并且,。在中隨機定義一個數據集群,此時可以將和在中出現的幾率設為向映射的知識,用表示,則有:
設置和的取值范圍可使所提大型計算機網絡中非正常數據挖掘方法具有收斂性。若無特殊規定,可將二者的取值范圍均設置在0~100%之間。如果用戶需要對某一特定的非正常數據進行精準挖掘,也可隨時變更取值范圍。
取值范圍設定成功后,本文將式(1)和式(2)中的重疊部分輸出,用來表示大型計算機網絡中非正常數據的挖掘結果。
2 非正常數據挖掘系統設計
2.1 系統總體設計
現使用所提大型計算機網絡中非正常數據挖掘方法設計數據挖掘系統,以實現對大型計算機網絡安全的有效維護。
所設計的系統由數據挖掘器、分析模塊和數據庫組成,如圖2所示。數據挖掘器被安放在大型計算機網絡的特定節點上,用來實時監控網絡工作的非正常情況,并進行數據處理。分析模塊負責對數據挖掘器處理過的數據進行分析,進而挖掘出大型計算機網絡中的非正常數據。數據庫為數據挖掘器和分析模塊提供數據的處理和挖掘方案。
2.2 系統具體設計
在所設計的大型計算機網絡非正常數據挖掘系統中,數據挖掘器可看作是大型計算機網絡初始數據集群的接收端,用于獲取數據挖掘技術中的“知識”,其工作流程如圖3所示。
由圖3可知,在數據挖掘器開始工作前,數據庫會事先根據大型計算機網絡初始數據集群的特征制定數據挖掘器的具體挖掘方案,并對其實施驅動。數據挖掘器根據挖掘方案對數據進行洗滌和格式轉換等處理。處理結果將被存儲。
值得一提的是,數據挖掘器具有自檢功能,如果處理結果不符合用戶所設定的置信度,那么該結果將會被保留到數據挖掘器的緩存器中。一旦緩存器中有新鮮數據進入,數據庫便會重新驅動數據挖掘器,直至處理結果成功通過自檢。隨后,所設計大型計算機網絡中非正常數據挖掘系統的分析模塊將對數據挖掘器的處理結果進行分析。為了增強系統的可擴展性,應充分利用系統計算節點的性能,并縮減節點失效率,為此,給分析模塊設計出一種“二次激活”方式[6],以延長系統計算節點的使用壽命,如圖4所示。二次激活是指當系統計算節點出現疲勞狀態時,分析模塊將自動放出替補節點,使疲勞節點擁有足夠的時間去休整。休整后的計算節點將替換下替補節點,繼續進行數據挖掘工作。
在分析模塊中,每個計算節點均有多個替補節點,如果節點即將失效并且未能尋找到下一個合適的計算節點,將采取替補節點與性能相似節點同時工作的分析方式,以保證所設計大型計算機網絡中非正常數據挖掘系統的可擴展性,并使挖掘結果更加準確。
3 實驗驗證
3.1 方法收斂性驗證
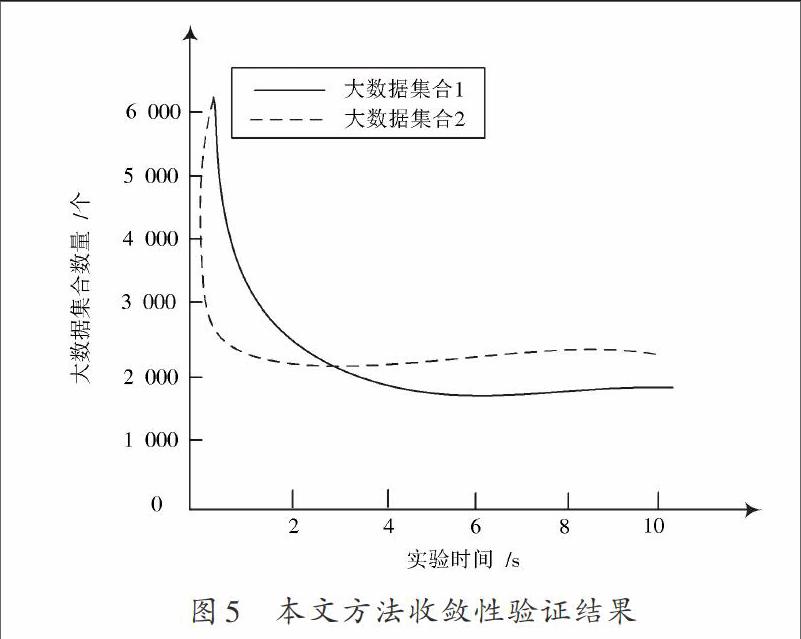
在大型計算機網絡中,只有具有較好收斂性的非正常數據挖掘方法才能有效保證挖掘結果的準確性。為了驗證本文所提方法收斂性的優劣,需要進行一次實驗。本次實驗在某大型計算機網絡實驗室中進行。用于進行數據挖掘的主機配置為:3 GB內存、四核i7處理器、500 GB硬盤。實驗中,于主機寫入本文方法,并向大型計算機網絡中加入兩種類型的大數據集群,兩集群中的數據節點[7?8]分別為4萬個和80萬個。當數據節點中的數據不出現波動時,表示本文方法已進入收斂狀態,此時主機便不會再向下一節點傳遞數據。實驗結果如圖5所示。
從圖5可明確看出,本文方法具有收斂性,并且大數據集群中的數據節點越多,方法的收斂時間就越短。在兩種大數據集群中,本文方法的收斂時間分別為1.2 s和4.3 s。據統計,其他方法的收斂時間大多在10.8 s左右,這顯示出本文方法具有較好的收斂性。
3.2 系統可擴展性驗證
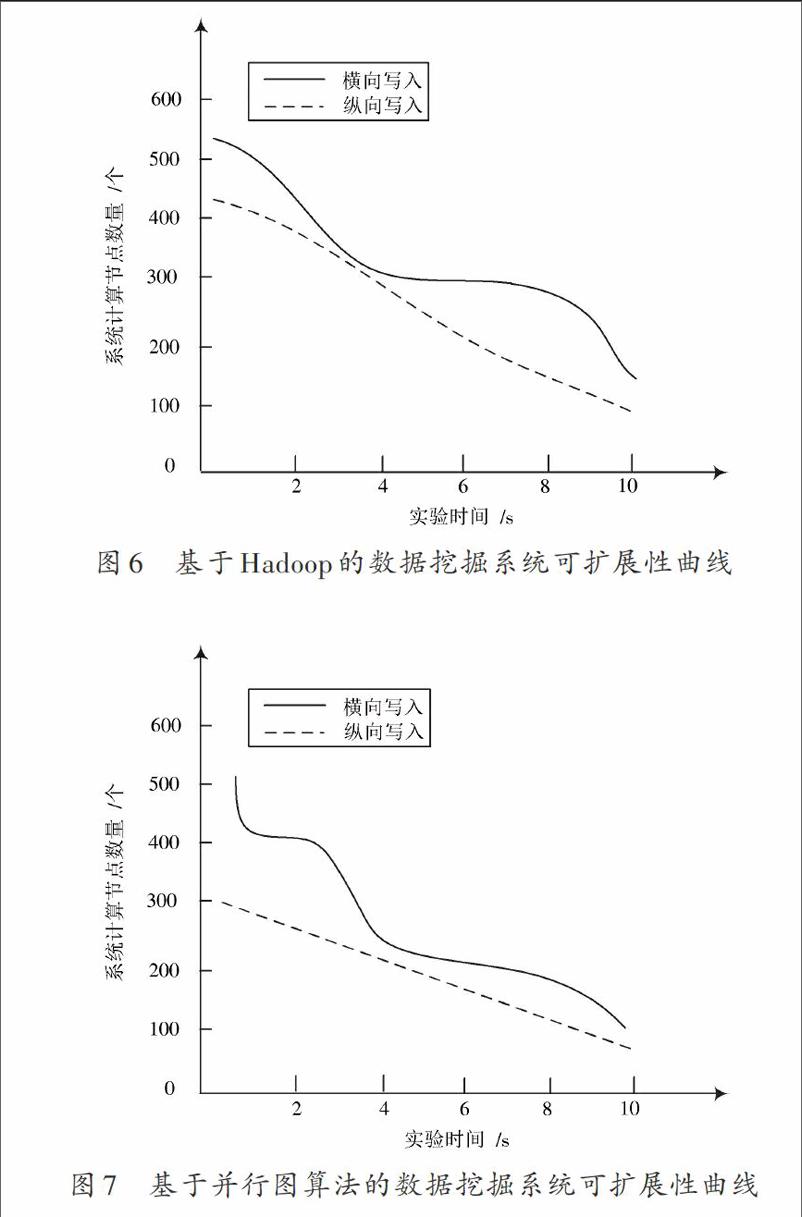
為了驗證經本文方法設計出的數據挖掘系統是否能夠合理應對大型計算機網絡中非正常數據的更新,需要對本文系統的可擴展性進行驗證。實驗選出的對比系統有基于Hadoop的數據挖掘系統和基于并行圖算法的數據挖掘系統。
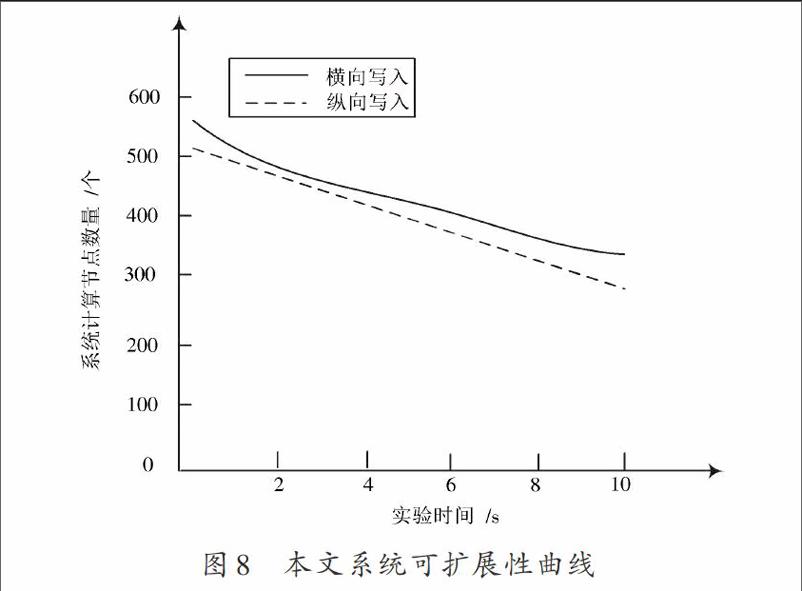
在第3.1節實驗的基礎上,只保留大數據集群2,并分別以橫向和縱向方式向集群的數據節點中隨機寫入30 000個非正常數據。使用三種系統對大型計算機網絡中的非正常數據進行挖掘,所得實驗結果如圖6~圖8所示。
由圖6~圖8可知,三個系統在縱向寫入下的可擴展性均低于橫向寫入。與其他兩個系統相比,本文系統參與進行非正常數據挖掘的節點數量更多,并且節點失效率最少,證明使用本文方法設計出的數據挖掘系統具有較強的可擴展性。
4 結 論
本文提出一種新型的大型計算機網絡中非正常數據挖掘方法,并使用該方法設計數據挖掘系統。數據挖掘技術是指依據特定任務,將重要的隱含知識從具有一定干擾存在下的隨機數據集群中挖掘出來。將數據挖掘技術用于進行大型計算機網絡非正常數據挖掘工作中,能夠對大量數據進行自動控制,為用戶提供更多便利。實驗結果表明,本文方法具有較好的收斂性,使用本文方法設計出的數據挖掘系統也具有較強的可擴展性,可將大型計算機網絡中的非正常數據準確、高效地挖掘出來。
參考文獻
[1] 吳嘉瑞,唐仕歡,郭位先,等.基于數據挖掘的名老中醫經驗傳承研究述評[J].中國中藥雜志,2014,39(4):614?617.
[2] 李善青,趙輝,宋立榮.基于大數據挖掘的科技項目查重模型研究[J].圖書館論壇,2014,34(2):78?83.
[3] 丁騁騁,邱瑾.性別與信用:非法集資主角的微觀個體特征—基于網絡數據挖掘的分析[J].財貿經濟,2016,37(3):78?94.
[4] 楊丹丹.搜索引擎及網絡數據挖掘相關技術研究[J].數字化用戶,2014,20(11):126.
[5] 王元卓,賈巖濤,劉大偉,等.基于開放網絡知識的信息檢索與數據挖掘[J].計算機研究與發展,2015,52(2):456?474.
[6] 唐曉東.基于關聯規則映射的生物信息網絡多維數據挖掘算法[J].計算機應用研究,2015,32(6):1614?1616.
[7] 陳震.對于以數據挖掘為基礎的網絡學習系統的設計與研究[J].山東農業工程學院學報,2014,31(6):38?39.
[8] 周立軍,張杰,呂海燕.基于數據挖掘技術的網絡入侵檢測技術研究[J].現代電子技術,2016,39(6):10?13.
