基于未登錄詞識別的微博評價短語抽取方法
2017-07-10 10:27:27汪龍慶劉振宇
計算機應用與軟件 2017年6期
汪龍慶 張 超 宋 暉* 劉振宇
1(東華大學計算機科學與技術學院 上海 201600)2(上海計算機軟件技術開發中心上海市計算機軟件評測重點實驗室 上海 201112)
基于未登錄詞識別的微博評價短語抽取方法
汪龍慶1張 超1宋 暉1*劉振宇2
1(東華大學計算機科學與技術學院 上海 201600)2(上海計算機軟件技術開發中心上海市計算機軟件評測重點實驗室 上海 201112)
由于微博內容話題分散,識別博文評論對象是微博情感分析研究的熱點和難點。研究表明未登錄詞識別是導致評價短語識別率低的重要原因之一。針對這種情況,提出一種基于文本詞序列的詞頻、凝聚度、左右自由度等統計特征學習未登錄詞識別模型的方法。實驗結果表明,將自動識別的微博文本中的未登錄詞加入基于CRFs的評價短語識別算法后,顯著地提高了評價短語識別的準確率和召回率。未登錄詞的學習算法直接利用評價短語識別的標注樣本,具有較強的可行性。
微博 評價短語 未登錄詞 統計特征 CRFs
ComputerSoftwareTechnology,Shanghai201112,China)
0 引 言
近年來微博作為一種新的分享和社交平臺越來越受到人們的關注,微博平臺以其時效性和靈活性經常成為新事件和熱點話題的前沿陣地。
人們在微博上發表對政治、經濟、文化和社會等各個方面的觀點和看法,充分利用海量微博數據進行用戶情感傾向性分析,對政府輿情監控、企業廣告投放、用戶行為預測和信息決策提供了重要參考。微博不同于電商和新聞等專業領域網站,用戶發布的博文目標分散、用語隨意,要對微博進行情感傾向性分析,評價短語的識別變得尤為重要。
評價短語的識別是從文本中自動抽取出情感表達所針對的對象,是情感要素傾向性分析的基礎,也是情感傾向性研究的重要任務之一[1-2]。針對評價短語的識別,目前大部分學者的研究主要是基于句法分析和關聯規則等方法。如倪茂樹等[3]提出一種基于關聯規則和極性分析的商品評論挖掘算法,利用詞與詞之間的關聯關系準確定位每一個評價短語的具體位置。劉鴻宇等[4]則是采用網絡挖掘的PMI算法和名詞剪枝算法對候選評價短語進行篩選。以上方法評價短語識別的準確性都不高,其中影響抽取評價短語的重要原因之一是未登錄詞識別。在大規模中文文本的自動分詞處理中,未登錄詞也是造成分詞錯誤的一個重要原因。因此,提高未登錄詞識別的準確性對于評價短語識別具有重要作用。
漢語未登錄詞識別, 現有研究大多采用基于詞語結構信息和基于規則的方法,也有利用未登錄詞上下文信息, 通過計算與已知詞類詞語上下文的相似度來進行預測。依據模型和算法的不同, 歸納為以下3種方法:
1) 基于統計的方法
基于統計的方法,又稱為基于語料庫的方法,其主要思想是通過對大規模語料庫中的語言信息進行獲取、學習和歸納,再使用統計方法進行建模,最后使用建好的模型進行詞性標注。 Wang、Chen等通過尋找詞語的詞頻、剛性、“二元語法“統計模型等統計特征來進行未登錄詞識別[5-7]。
2) 基于規則的方法
基于規則的方法主要是利用語言學家根據語言學原理和知識人工制定的一系列規則,在進行文本標注時通過匹配規則庫中的規則對文本進行詞性標注。賈自艷等通過單字、多字組合規則進行未登錄詞識別[7]。王立希等提出了一種基于主題式搜索引擎的專業詞典庫發現新專業詞匯的方法,詳述了如何通過關聯規則挖掘來實現專業詞典庫的擴展[8]。
3) 基于統計和規則相結合的方法
這類方法即是將以上兩種方法進行結合,從而可以充分利用基于統計方法和基于規則方法的優勢,使得在詞性標注任務中既充分地發揮基于統計方法的優勢,又能夠有效地利用語言學家編撰的語言規則。周蕾等介紹了一種基于知識和規則的混合模型[9],該方法分為兩個步驟:首先,對文本進行分詞,對分詞結果中的碎片進行全切分生成臨時詞典,并利用規則和頻度信息給臨時詞典中的每個字串賦權值,利用貪心算法獲得每個碎片的最長路徑,從而提取未登錄詞;然后,在上一步驟的基礎上,建立二元模型來提取由若干個詞組合而成的未登錄詞。
基于規則的方法具有準確率高的特點,但規則的編寫和維護卻比較復雜。規則一般都是與領域相關的,通用性較差,這就導致基于規則的方法不易維護和移植。 基于統計的方法則具有領域關聯性小、使用規則少、可移植性好、應用靈活等特點,但需要大規模的語料進行訓練,同時也存在準確率不高的問題。正因為基于規則和基于統計兩種方法各有缺點,現在多采用二者相結合的方法,以達到更好的識別效果。上述方法都依賴于不易得到的輔助工具,而且規則復雜,系統實現困難。針對以上存在的不足,本文提出了一種基于詞頻、凝聚度和左右自由度等統計特征學習未登錄詞識別模型的算法,然后在基于條件隨機場的評價短語識別算法中引入識別的新詞來提高微博中各種新出現的評價短語的識別性能,最后通過實驗驗證了算法的有效性。
1 未登錄詞特征分析
1.1 未登錄詞定義
對于待確定的詞語,在和已有詞庫進行比較后,如果已有詞庫不包含該待確定的詞,那么它就被認為是未登錄詞UW。
1.2 未登錄詞特征
針對未登錄詞判別問題,本文提出了通過詞頻、停用字、凝聚度和自由度這四個維度進行未登錄詞識別。
凝聚度標示著詞語的成詞能力,假設詞A出現的概率為P(A),詞B出現的概率為P(B),詞A與B同時出現的概率為P(AB)。若詞A和詞B獨立,則P(AB)=P(A)P(B);若P(AB)?P(A)P(B),這說明詞A與詞B并不是完全獨立,可能存在某種內在的聯系。借助于這種思想,將詞A和B的內部結合的緊密程度表示為 P(AB)/P(A)P(B),值越大說明詞A和B組成新詞或者成為新詞一部分的概率越大。
錯誤的切分方法會過高地估計片段的凝合程度。假設一個文本片段由ABC三個字依次組合而成。可能的組合方式就有A+BC和AB+C兩種,故將ABC的凝聚程度表示為P(ABC)/P(A)P(BC)和P(ABC)/P(A B)P(C)中的較小者。
如果一個文本片段是一個單獨的詞,它應該能夠反復地出現在各種不同的上下文中,具有非常豐富的左鄰字集合和右鄰字集合。本文把一個文本片段的自由運用程度定義為它的左自由度和右自由度中的較小值。
“自由度”是指一個字符串的鄰接集合中鄰接字種類的數量,自由度越大,表明字符串的邊界集合中字符的種類越多,即與該字符串相鄰的字符越復雜,那么該字符串成為邊界的可能性就越大,反之亦然。通常用信息熵來衡量邊界自由度大小。信息熵反映了一個事件的發生帶來的信息量。
對于已有詞庫不包含的詞語,如果被判定為未登錄詞,首先,該詞語應該不包括停用字;其次,詞語間的凝聚度能夠達到一定數值;最后,如果詞語能夠被判定為未登錄詞,則其自由度應該足夠高,也就是結合能力較強。
2 未登錄詞識別模型
2.1 成詞維度定義
一個文本片段要想成為一個詞,必須滿足多個條件。首先,漢語中沒有以“我、你、他”等這樣的代字開頭和結尾的詞語,在進行未登錄詞判別時可以根據這樣的規則進行過濾;其次,漢字詞語有一定的統計規律,可以結合這樣的規律進行未登錄詞識別。最后,再綜合各種特征進行未登錄詞的篩選。為了方便理解,定義1-定義4請參見文獻[8]。
1) 停用字過濾
漢語中某些詞性的詞本身并無具體的意義(見表1),其主要功能是用來幫助造句的,這些詞很少能夠用來組成新詞、新概念,在未登錄詞識別過程中可以借助這些常見停用字進行過濾,減少計算的復雜度。

表1 常見停用字列表
2) 詞頻特征
定義1 一個詞語w在上下文中出現的頻數被稱為詞頻,記作TF(w),其定義為:
(1)
3) 自由度
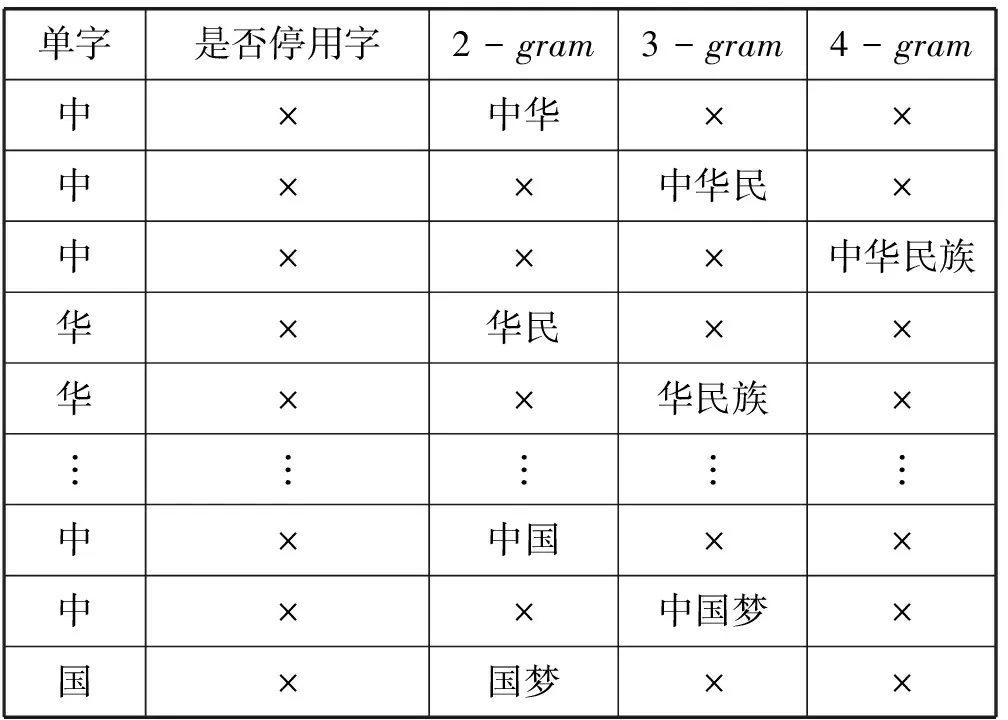
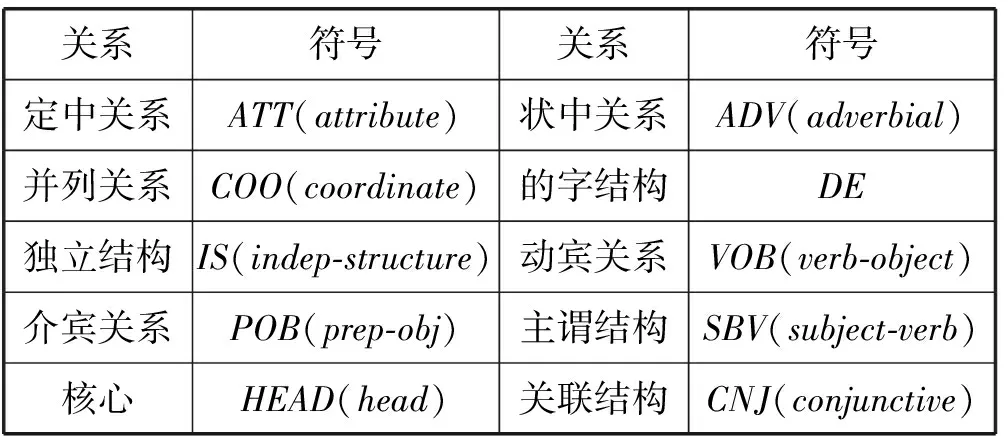
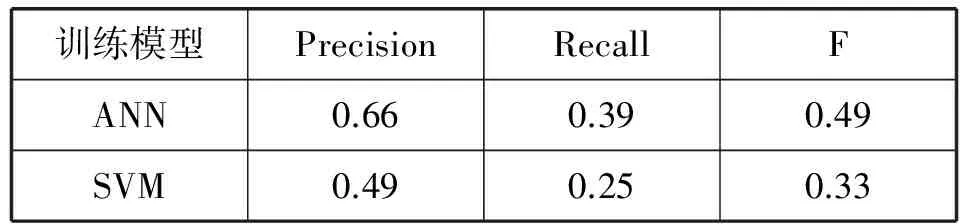
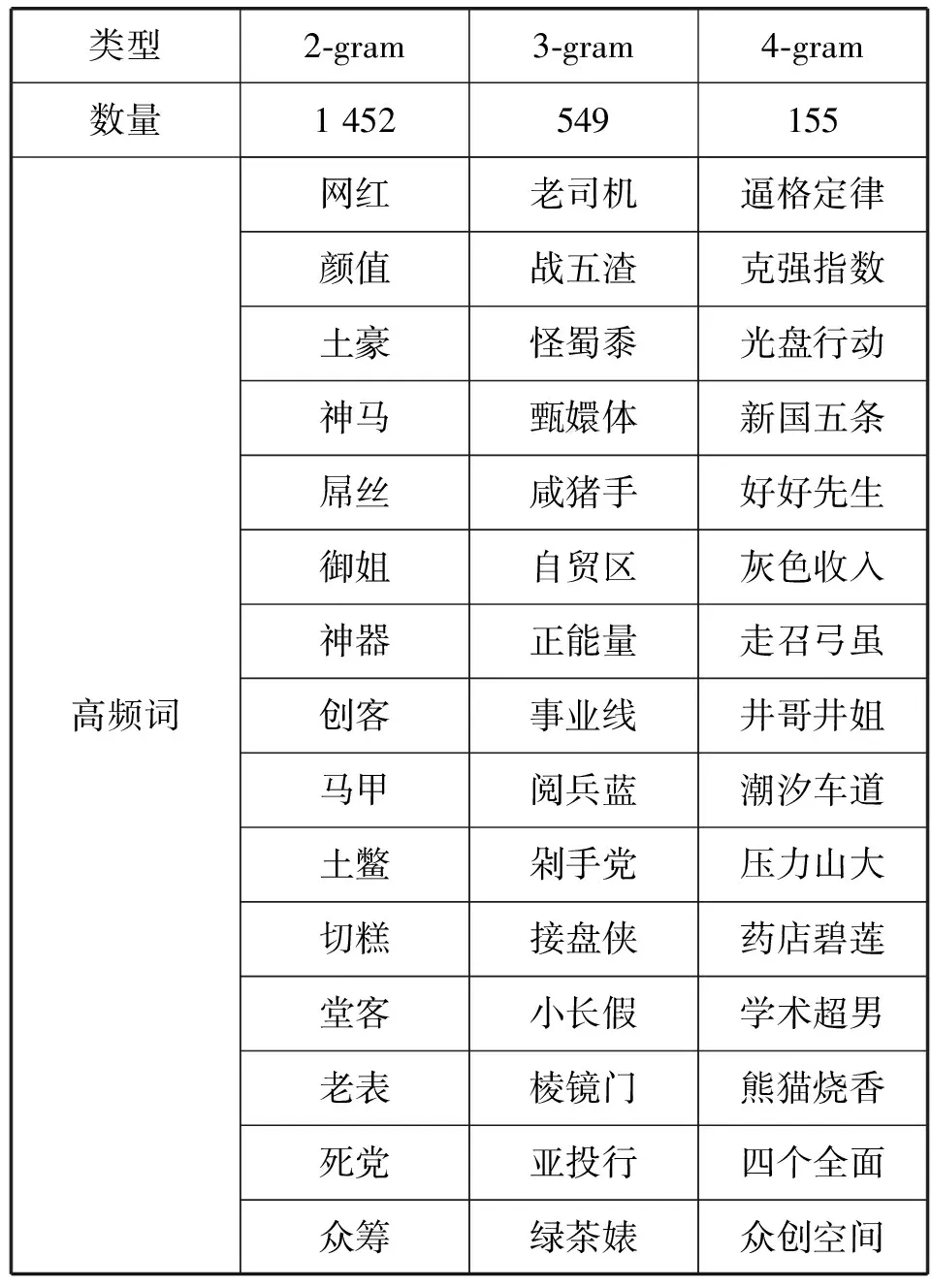
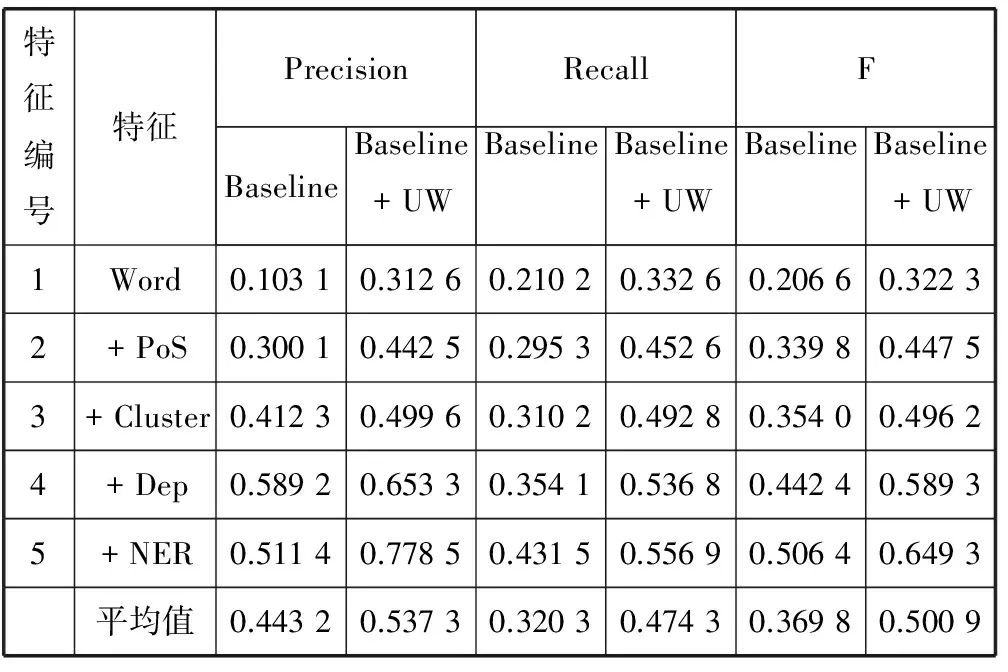
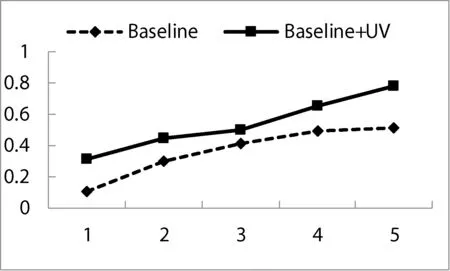
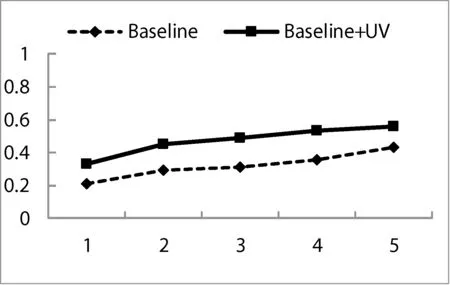
記一個文本片段seg(i)={wi,…,wj},i 定義2 文本片段seg(i)與左邊字符wi-1自由運用程度為該文本片段的左自由度,記為LE(w),其定義為: (2) 其中,w表示當前文本片段,A為語料庫中位于w左邊的詞的集合,C(a,w)表示語料庫中詞語a與w同時出現的次數。 定義3 文本片段seg(i)與右邊字符wj+1自由運用程度為該文本片段的右自由度,記為RE(w),其定義為: (3) 其中,w表示當前詞,B為語料庫中位于w右邊的詞的集合,C(a,w)表示語料庫中詞語a與w同時出現的次數。 定義4 記當前文本片段seg(i)自由度為R(w),則其可定義為: R(w)=min{LE(w),RE(w)} (4) 從左、右自由度的定義可以看出,如果一個詞的左右自由度都很大,則說明與該詞項左右相鄰的不同詞項個數比較多,并且相鄰頻率比較均勻,那么這個詞與左右相鄰的詞項構成新詞的概率就比較低;反之,如果一個詞項的左右側上下文自由度中有一個較小(假設左側自由度較小),則說明該詞左側相鄰的不同詞項的頻率分布并不均勻,它與左側頻率相鄰較高的詞搭配成新詞的頻率就較高,因此可以得到當前詞自由度的定義。 4) 凝聚度 一個詞語的內部凝聚程度標志著這個詞語的成詞能力,本文將這種內部凝聚程度稱為詞語的凝聚度。 定義5 記凝聚度為MI,其定義為: (5) 歸一化處理: (6) (7) (8) 其中,p(w1,w2)表示w1、w2同時出現的概率,p(w1)表示w1單獨出現的概率,p(w2)表示w2單獨出現的概率。則MI越大表示內部凝固程度越高,w1、w2一起成詞的概率越高,構詞能力越強。 2.2 模型框架設計 首先給出本文圖1所示未登錄詞識別的主要框架,其主要包括統計特征提取、標注樣本集、模型訓練和未登錄詞判別四個步驟。 圖1 未登錄詞識別步驟 由于微博數據的無規則性,所以首先需要經過數據預處理得到預處理文本,主要包括無關字符的濾除和根據標點進行短句的切分,經過數據預處理后,再進行語料的標注工作。具體的xml格式標注示例如下: 為了得到未登錄詞,首先需要提取出微博所有的n(n=2,3,4)元組,再結合規則過濾形成詞列表。具體過程為:對于每一個子句{w1,w2,…,wi,…,wn},其中wi表示一個漢字字符,n表示該子句包含的漢字的個數;生成該子句的所有n元組(n=2,3,4),需要過濾停用字,過濾方法如下:如果待定片段首尾字符均不包含停用字,且不在待選詞列表中,則加入待選詞列表。給定漢字字符wi,首先判斷wi是不是停用字,如果是則直接進行下一個字符wi+1的迭代,否則依次判斷二元組{wiwi+1}、三元組{wiwi+1wi+2}、四元組{wiwi+1wi+2wi+3}的尾字符wi+1、wi+2、wi+3是否是停用字,如果是非停用字且不被包含在待選詞列表則作為待選詞加入。關于句子“中華名族一定能夠實現中國夢”,其n元組篩選過程如表2所示。 表2 詞列表生成示例 經過基于單字的候選未登錄詞識別之后,中華、中國、中國夢被初步篩選為待選未登錄詞,算法1給出了基于單字的候選未登錄詞識別算法主要過程。 算法1 基于單字的候選未登錄詞識別算法 輸入:doc、pos、curLen、stopwords 輸出:dic//候選未登錄詞詞典 BEGIN 01 //初始化抽取器,開始位置pos=0 02 selecor = initSelector(doc, 0) 03 //初始化最小、最大字符個數 04 minChar=2, maxChar=4 05 //初始化判別器,計算每一個字出現的位置 06 judger = initJudger() 07 WHILE(!selector.end()) 08 pos++ 09 curLen=minChar 10 letter=selector.next() 11 WHILE(curLen <=maxChar) 12 letter=selector.next() 13 //首尾字符是否包含停用字 14 IF(letter∈stopwords || 15 doc.charAt(pos+count) ∈ 16 stopwords) 17 THEN 18 curLen ++ 19 continue 20 END IF 21 candidate=subString(doc,pos,count) 22 IF(candidate∈dic) THEN 23 curLen ++ 24 continue 25 END IF 26 dic.add(candidate) 27 END WHILE 28 END WHILE 29 //依據單字上下文依次計算候選詞4個統計特征 30 FOR each C∈dic 31 TF=frequence(judger,C) 32 MI=cohesievness(judger,C) 33 LE=leftEntropy(judger,C) 34 RE=rightEntropy(judger,C) 35 END FOR 2.3 判定算法 經過算法1的初步篩選可以得到待選詞列表,本部分通過SVM分類器和神經網絡兩種模型對待選詞列表進行訓練,選擇準確率高的一類模型作為未登錄詞判定模型,最后將未登錄詞識別算法應用于所有的微博得到未登錄詞詞典。 1) SVM分類判別 輸入數據格式:{ 其中, 0 1∶0.22 2∶0.33 3∶0.15 4∶0.19 1 1∶0.61 2∶0.41 3∶0.74 4∶0.54 0 1∶0.11 2∶0.21 3∶0.15 4∶0.23 …… 輸出數據格式為:{ 其中,label1表示標注結果,label2表示預測結果 使用SparkMLlib庫,本文實驗流程如以下步驟所示: Step1 構建Spark對象 Step2 讀取樣本數據,為LIBSVM格式 Step3 樣本數據劃分訓練樣本與測試樣本 Step4 新建邏輯回歸模型,并訓練 Step5 對測試樣本進行測試 Step6 誤差計算 Step7 保存模型 Step8 加載模型,讀取輸入數據預測未登錄詞 2) ANN判別 同SVM算法,本文也是使用Spark MLlib庫作為ANN(人工神經網絡)的基本類庫進行訓練得到分類模型,再對測試樣本進行未登錄詞識別工作。 輸入數據格式:{ 輸出數據格式為:{ 輸出數據label1表示標注的標簽,label2表示神經網絡預測的標簽,right表示label2與label1相同,wrong表示label2與label1不同。 條件隨機場是在2001年由JohnLafferty和AndrewMcCallum提出的一種無向圖模型,在中文分詞、命名實體識別(NER)、歧義消解等漢語自然語言處理任務中都有應用,并有著良好的表現。 本文利用條件隨機場(CRFSuite)可對序列輸入標注的特點[12],將未登錄詞識別問題轉化為轉化為待選詞邊界是否為未登錄詞邊界的問題。 3.1 特征描述 1)Word 詞特征,即n-gram特征,本文采取當前文本片段及其前后各兩個漢字分別作為特征,使用StanfordCoreNLP工具進行n-gram特征的提取。 2)PoS 詞性標注,POS標簽提供這個詞有關詞性的標簽信息,使用FudanNLP工具處理。 3)WordCluster 詞串聚類特征,本文采用word2vec工具分別對當前詞及其前后各一個詞進行聚類分析。 4)WordDependency 本文使用FudanNLP進行中文依存關系分析,在依存關系分析中,有一些關鍵的關系可以確定很多的問題,比如主謂關系,可以比較容易地找到句子的結構。當然“的”字結構也會表征很多歸屬信息,這些信息都可能在接下來的規則中用到。表3列出了一些關鍵的依存關系。 表3 常見依存關系列表 5)NER 使用FudanNLP中文自然語言處理工具包進行命名實體特征的識別。 3.2 特征提取算法 本文選取了n-gram、詞性、依存關系、聚類、命名實體五類特征,采用了FudanNLP、word2vec等工具包進行了特征提取,算法2給出了具體的提取方法。 算法2 評價短語識別特征提取算法 輸入:doc//輸入微博文檔集 輸出:featureList Begin 01 //循環文檔集中的每一個句子C 02 FOR each C∈doc 03 //分詞,提取n-gram特征 04 I = segment(C) 05 words = ngram(I) 06 //詞性特征 07 posTags = POSTagger(I, "seg.m","pos.m" ) 08 //依存關系特征 09 stree = JointParser(I, “models/dep.m”) 10 //命名實體特征 11 ners = NERTagger(I, "seg.m","pos.m") 12 featurelist.add(I,words, posTags, stree, ners) 13 END FOR 14 //學習聚類特征 15 learn = word2vec(doc) 16 //保存模型 17 vec = learn.saveModel() 18 //加載模型 19 vec.loadJavaModel() 20 //聚類分析 21 vector = vec.getWordVector() 22 featureList.add(vector) 23 Return featureList 上述算法步驟03-05提取n-gram特征,06-07提取PoS詞性特征,08-09提取句子依存關系特征,10-11提取命名實體特征,14-21使用word2vec提取聚類特征,并將所有特征加入特征集,最后一步返回所有的特征列表。 3.3 自定義特征模板 使用評價短語識別特征提取算法提取特征,圖2列出了各種特征模板的組合。 圖2 自定義特征模板組合 圖2中,數字代表每個詞語的相對位置,w代表對應位置詞語的n-gram特征,p代表對應位置詞語的詞性特征,c代表對應位置詞語的類別特征。不同特征的各種組合就形成了自定義特征模版。 3.4CRFSuite模型數據規范化 在文本標注過程中,引入BIO三個符號,將評價短語識別問題轉化為序列標注問題。再將自定義特征模板和人工標注標簽規范化成CRFSuite的標準輸入格式,進行n次迭代得到一個預測模型,其數據規范化之后輸入格式為: 給定一個句子{W1,W2,…,Wi,…,Wn},Wi表示第i個詞語: B-TERMw[0]= W1w[1]= W2w[2]= W3w[0]|w[1]= W1| W2pos[0]=NNpos[1]=INpos[2]=DTpos[0]|pos[1]=NN|INpos[1]|pos[2]=IN|DTpos[0]|pos[1]|pos[2]=NN|IN|DT… 本實驗搭建了一個微博情感要素分析平臺,主要由未登錄詞識別和評價短語識別兩個模塊組成。 4.1 實驗數據集 本實驗采取的數據集是采用網絡爬蟲爬取的新浪微博一天的數據,總工包括約800萬條微博,本文選取了其中3 000條微博,人工標注了每條微博的評價短語,產生了3 000條數據的樣本集,用于未登錄詞識別算法和評價短語識別算法的有監督學習數據集。其中,70%用來訓練,其余作為測試。 標準結果集有兩個,分別是評測用的3 000條標注結果和用于測試的微博數據。 4.2 未登錄詞識別結果及分析 未登錄詞識別中首先自動對微博生語料進行,再依次篩選出所有的n元組(其中n=2,3,4)。然后對每一個n元組計算它的詞頻TF、凝聚度MI、左自由度LE和右自由度RE這4個統計特征。最后使用人工神經網絡和SVM在測試數據上進行測試之后選擇性能較好的模型,并使用該模型用于所有的微博進行未登錄詞識別,形成未登錄詞詞典。 表4給出了使用ANN人工神經網絡和SVM支持向量機進行未登錄詞識別的準確率、召回率和F值得具體數值。 表4 未登錄詞識別效果比較ANN vs SVM 從表4給出的未登錄詞識別效果對比圖可以直觀地看出不管是準確率、召回率還是F值,人工神經網絡的分類性能都要優于SVM,因此本文選擇人工神經網絡產生的未登錄詞識別模型。 選定人工神經網絡模型后,在800萬條微博中發現了2 156個未登錄詞,2-gram的二字詞1 452個,占比67%;3-gram的三字詞549個,占比25%;4-gram的四字詞155個,占比8%。表5給出了部分高頻未登錄詞識別結果。 表5 高頻未登錄詞識別結果示例 4.3 評價短語識別結果及分析 評價短語識別在中文分詞過程中,加入未登錄詞識別實驗形成的未登錄詞詞典,接下來再依次進行word、pos、word cluster、word dependency和ner特征的提取,將既有特征按照一定的規則組裝成特征模板,再運用CRFSuite工具訓練得到評價短語分類模型,最后對測試文檔進行測試,得到評價短語。 評價短語識別實驗,本文分成不加入未登錄詞和加入未登錄詞2大組,每一大組再分別依據word、 word + pos、 word + pos + cluster、word + pos + cluster + dep和word + pos + cluster + dep + ner的特征模板分成5小組對比進行,準確率、召回率和F值如表6所示。從表6可以看出,在逐步加入word、pos、cluster、dep和ner特征后,Baseline和在Baseline基礎上加入未登錄詞的評價短語識別實驗的效果都有顯著提高。但總體性能加入未登錄詞處理之后要優于Baseline實驗。本文最終選定效果較好的word+pos+cluster+dep+ner最為系統的特征模板。 表6 未加入未登錄詞處理的評價短語識別 在加入未登錄詞前后的評價短語識別的準確率和召回率分別如圖3和圖4所示。從圖3和圖4可以看出,加入詞性特征之后,無論是準確率還是召回率都提升顯著,說明詞性特征對于評價短語識別的影響較大。相反,聚類特征對于準確率的提升卻很小,基本上與Baseline實驗處于同等水平。圖3和圖4都能看出加入未登錄詞之后的實驗準確率和召回率相對于Baseline實驗都有明顯提高,本文方法的優勢在于文本處理階段增加了分詞的準確率,使得在評價短語識別階段能夠準確有效地識別更多的評價對象。 圖3 加入未登錄詞前后評價短語識別的準確率 圖4 加入未登錄詞前后評價短語識別的召回率 從圖3和圖4均可以看出加入未登錄詞之后的評價短語識別準確率和召回率均明顯高于加入之前的方法。由于本文采用了基于大規模語料的學習且考慮到每一個詞語的凝聚度、自由度等互信息,使得在第一階段未登錄詞識別部分效果顯著,在第二階段使用CRFSuite分類器預測目標評價短語的準確率和召回率大大提升,改進后的性能提升明顯。 本文研究了情感分析領域的評價短語識別問題,發現未登錄詞的識別對評價短語識別的性能有較大影響。本文根據中文文法性實現了未登錄詞的四種特征:詞頻、凝聚度、左自由度、右自由度,通過學習訓練樣本的這些統計特征自動建立未登錄詞識別模型,然后將自動識別的未登錄詞加入基于CRFs的評價短語識別算法。實驗結果說明加入未登錄詞后對評價短語的抽取性能提升顯著。尤其對于用戶行文自由的微博數據,未登錄詞出現頻繁,相對傳統的評價短語抽取方法,本文提出的模型能夠有較好的應用前景。 [1] 葉成緒,楊萍,劉少鵬.基于主題詞的微博熱點話題發現[J].計算機應用與軟件,2016,33(2):46-50. [2] 曹勇剛,曹羽中,金茂忠,等.面向信息檢索的自適應中文分詞系統[J].軟件學報,2006,17(3):356-363. [3] 倪茂樹,林鴻飛.基于關聯規則和極性分析的商品評論挖掘[C]//全國信息檢索與內容安全學術會議,2007. [4] Liu H,Zhao Y,Qin B,et al.Comment Target Extraction and Sentiment Classification[J].Journal of Chinese Information Processing,2010,24(1):84-88. [5] Wang M C,Huang C R,Chen K J.The identification and classification of unknown words in Chinese:an n-grams-based approach[J].Festschrift for Professor Akira Ikeya,1995:113-123. [6] Chen A.Chinese word segmentation using minimal linguistic knowledge[C]//Proceedings of the second SIGHAN workshop on Chinese language processing-Volume 17.Association for Computational Linguistics,2003:148-151. [7] 賈自艷,史忠植.基于概率統計技術和規則方法的新詞發現[J].計算機工程,2004,30(20):19-21. [8] 王立希,王建東,汪靜.基于數據挖掘的新詞發現[J].計算機應用研究,2006,2(12):195-197. [9] 周蕾,朱巧明.基于統計和規則的未登錄詞識別方法研究[J].計算機工程,2007,33(8):196-198. [10] 李文坤,張仰森,陳若愚.基于詞內部結合度和邊界自由度的新詞發現[J].計算機應用研究,2015,32(8):51. [11] 林江豪,陽愛民,周詠梅,等.一種基于樸素貝葉斯的微博情感分類[J].計算機工程與科學,2012,34(9):160-165. [12] 陳飛,劉奕群,魏超,等.基于條件隨機場方法的開放領域新詞發現[J].Journal of Software,2013,24(5). [13] 霍帥,張敏,劉奕群,等.基于微博內容的新詞發現方法[J].模式識別與人工智能,2014,27(2):141-145. [14] Zou G,Liu Y,Liu Q,et al.Internet-oriented Chinese New Words Detection[J].Journal of Chinese Information Processing,2004,18(6):1-9. [15] Kong L,Ren F,Sun X,et al.Word Frequency Statistics Model for Chinese Base Noun Phrase Identification[M]//Intelligent Computing Methodologies,2014:635-644. [16] 謝麗星,周明,孫茂松.基于層次結構的多策略中文微博情感分析和特征抽取[J].中文信息學報,2012,26(1):73-83. A METHOD OF TARGET PHRASE EXTRACTION FROM MICROBLOG BASED ON UNKNOWN WORDS RECOGNITION Wang Longqing1Zhang Chao1Song Hui1*Liu Zhenyu2 1(SchoolofComputerScienceandTechnology,DonghuaUniversity,Shanghai201600,China)2(ShanghaiKeyLaboratoryofComputerSoftwareTestingandEvaluating,ShanghaiDevelopmentCenterof As the topic of microblog content is scattered, the identification of microblog comment object is the hot and difficult point of microblog emotion analysis. The research shows that unknown words recognition is one of the important reasons leading to the low recognition rate of target phrase. To solve this problem, this paper proposes a method of learning unknown words recognition model based on statistical features such as word frequency, cohesion, left and right degrees of freedom. The experimental results show that the unknown words in the microblog text are automatically added to the target phrase recognition algorithm based on CRFs, and the accuracy and recall of the phrase recognition are improved remarkably. The learning algorithm of unknown words has strong feasibility by directly using annotated samples of target phrase recognition. Microblog Target phrase Unknown words Statistical feature CRFs 2016-07-10。汪龍慶,碩士生,主研領域:文本挖掘。張超,碩士生。宋暉,教授。劉振宇,副研究員。 TP3 A 10.3969/j.issn.1000-386x.2017.06.051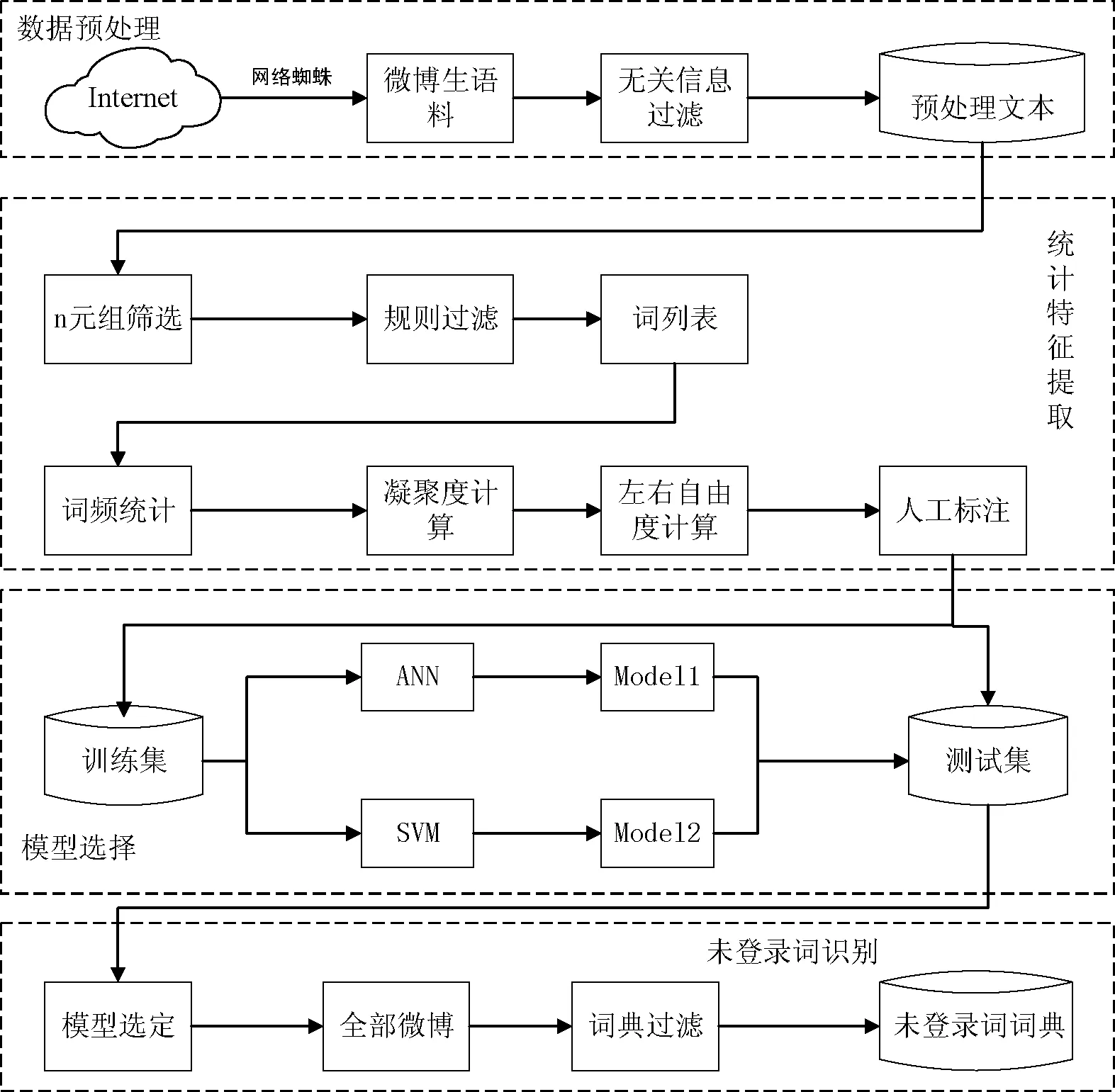
3 評價短語識別

4 實驗結果及分析
5 結 語
猜你喜歡
小獼猴智力畫刊(2022年3期)2022-03-29 01:09:42
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:26:14
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
制造技術與機床(2019年10期)2019-10-26 02:48:08
當代陜西(2019年10期)2019-06-03 10:12:04
電子制作(2018年18期)2018-11-14 01:48:06
Coco薇(2017年11期)2018-01-03 20:59:57
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
暨南學報(哲學社會科學版)(2016年9期)2017-01-15 13:52:02
小學教學參考(2015年20期)2016-01-15 08:44:38
