
基于K-均值聚類分析的風力機功率曲線統計應用
2017-07-10 09:13:00宋聚眾蘭杰林淑莫爾兵
東方汽輪機 2017年2期
關鍵詞:可視化
宋聚眾,蘭杰,林淑,莫爾兵
(東方電氣風電有限公司,四川德陽,618000)
基于K-均值聚類分析的風力機功率曲線統計應用
宋聚眾,蘭杰,林淑,莫爾兵
(東方電氣風電有限公司,四川德陽,618000)
風力機相關數據的處理對風力機能否正常發電無影響,但對風力機性能的分析卻至關重要。文章以風力機的功率曲線為研究對象,把SCADA數據記錄分為兩類,采用模式識別的K-均值聚類分析方法排除掉無效數據點,能夠以統一的算法處理不同類型的散點圖,通過.NET平臺有效地結合EXCEL的數據統計功能和VB語言的邏輯和流程控制功能,準確、快速地開發出可視化軟件,繪制好的功率曲線有助于用戶直觀地分析風力機的發電性能,為用戶在風電場發電性能改進方面提供重要依據。
功率曲線,聚類分析,K-均值,數據處理,.NET平臺,VB
0 引言
隨著化石能源日益稀缺,全球環境的惡化,風能作為一種儲量大、分布廣、綠色環保的新能源和可再生能源,目前被世界各國大力利用。我國疆域遼闊,多數地區的風能資源豐富,陸上和海上能開發利用的風能儲量近似為10億千瓦。近年來,風力發電技術迅速發展,風電機組的功率曲線,對風電場的運行經濟效益有著至關重要的影響。
風力發電機組在運行過程中的數據會通過SCADA系統記錄到遠程數據庫中,以便進行相應統計分析,其中功率曲線是常用到的統計結果,它是風力機發電性能的直接表征。因此需要通過原始記錄數據提取有效數據,以便進行功率曲線繪制。但是在SCADA系統中記錄的數據,往往包含受風力機起停機過程、風湍流過大、限功率運行等影響的數據點,使風力機實際發電功率與風速不匹配,造成對應該條數據記錄無效,從而導致SCADA系統在統計功率曲線時,常使統計結果有偏差,難以準確評價風力機發電性能。若對單臺風力機進行人工處理,手動剔除無效統計數據點,理論上是可行的,但不同風力機無效數據記錄情況不盡相同,難以采用統一的定量方法進行處理,因此在面臨多臺風力機、大量數據的情況下,人工處理的辦法是不可取的。故針對風電場,研究功率曲線處理辦法,實現快速、準確、有效地繪制風力機功率曲線是十分必要的。
本文以風電場實測數據為基礎,把SCADA功率曲線數據記錄分為兩類,采用模式識別的K-means聚類分析方法,通過.NET平臺有效地結合EXCEL的數據統計功能和VB語言的邏輯和流程控制功能,快速開發出可視化軟件,準確、快速地繪制出風力機功率曲線。
1 風力機功率曲線意義
根據IEC61400-12-1標準的定義,風力發電機組的功率曲線是機組輸出功率隨10 min平均風速變化的關系曲線,表示風力機在不同的風速下有多大的功率輸出[1-2]。
功率曲線確定了風力發電機組的發電性能,是風力發電設備整機廠商(廠家)進行機組研發設計時的重要性能指標,也是設備運行商(業主)招標、計算經濟性和投資回報率的重要參考指標。機組進行型式認證時,其也是認證的主要內容之一。在風電場投運以后,功率曲線是廠家進行評估和后期優化的依據,也是業主進行產品考核、質保交機驗收的重要內容。因此,如何準確、快速統計風力機功率曲線是十分重要的。
2 K-means聚類分析
聚類分析常用于模式識別、數據挖掘等人工智能領域,其基本思想是把數據對象按照一定的標準劃分為幾類,使同類數據具有相同的特性,不同類數據特性不同。目前常用的聚類分析算法有:K-means聚類算法、凝聚型層次聚類算法、神經網絡聚類算法[3-4]。
本文采用的K-means算法是比較經典的聚類算法,只要數據對象具有比較明顯的區域特征,均可采用此方法。該算法具有效率高、實現簡單、運行速度快的特點,在大規模樣本分析方面,具有廣泛的應用[5]。
K-means算法的主要思想是:首先選定分類數目K,指定對應的K個初始中心,再將其余的數據對象按照一定的優化準則劃分到某一類中,其劃分原則以減小目標函數為依據。其目標函數常采用樣本對象到聚類中心的歐幾里得距離,則可定義為:
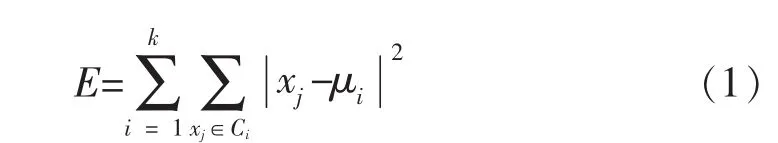
其中:k為聚類類數;Ci為第i個聚類;xj為類Ci中的數據對象;μi為類Ci的質心。
K-means的算法可以分為兩個階段:
第一階段為批量計算階段,基本流程如下:
(1)指定初始K個聚類中心;
(2)把每個數據歸到距離中心最近的一類;
(3)重新計算該類的中心;
(4)重復步驟2、3一定次數,獲得較合理的初始聚類中心;
第二階段為單獨計算階段,基本流程如下:
(1)選取上一階段計算的結果,將其作為初始聚類中心;
(2)循環計算每個點所屬分類,以減小優化準則函數為標準,重新確定該點分類,并更新該類中心;
(3)重復第2步,直至每一類不再發生改變或優化函數值趨于收斂。
3 數據處理應用
本文以國內某個風電場實測數據為基礎進行分析,得到如圖1、圖2所示的結果。
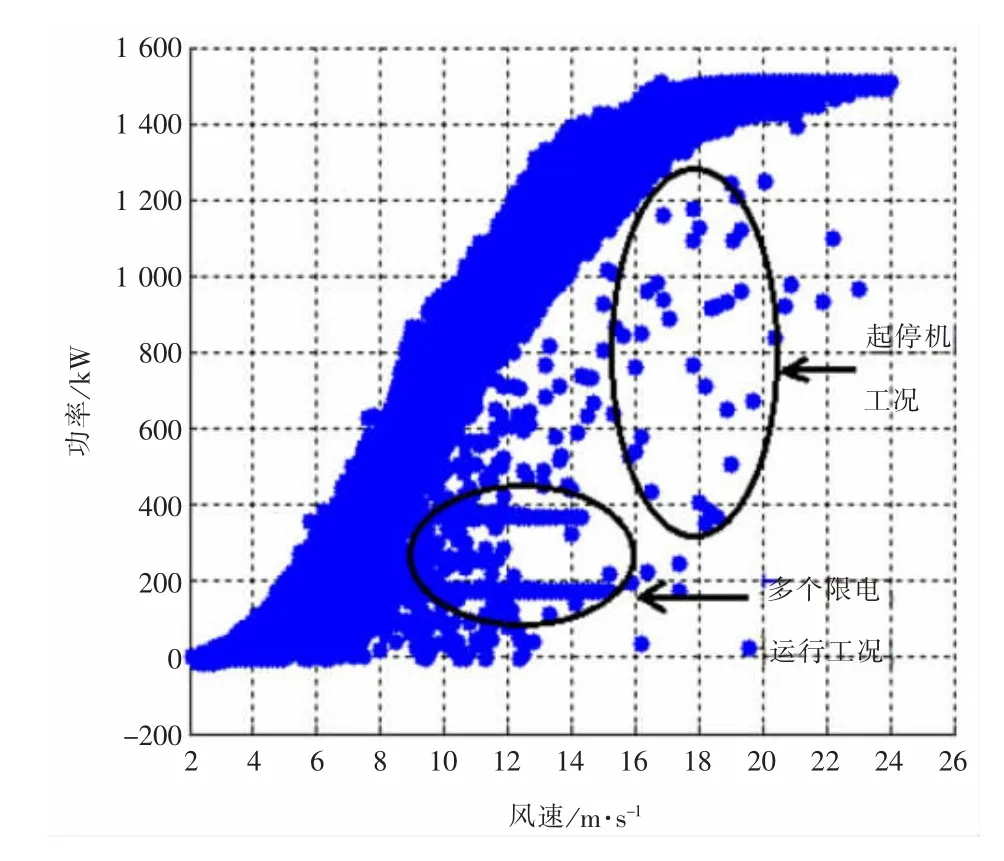
圖1 含有起停機、不同限功率運行狀態(1#機組)
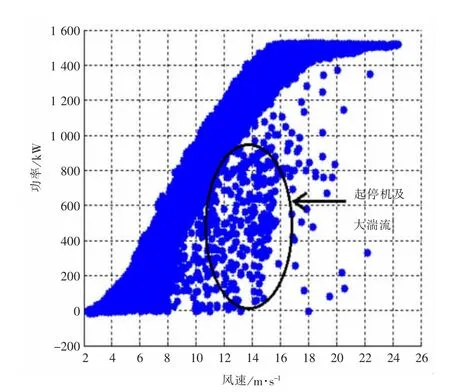
圖2 含有起停機過程及湍流強度過大(2#機組)
從圖1、圖2可以看出,同一風電場兩臺風力機一年的功率散點圖卻含有不同類型的無效數據點組合,從而很難進行統一定量分析。用戶很難根據圖形直觀地評價風力機發電狀況的好壞。
本文通過分析功率曲線散點圖可以發現具有如下特點:
(1)有效數據點具有聚合性,即都在一定范圍內分布;
(2)有效數據點遠遠多于無效數據點。
從(1)可以得出具有聚類分析所定義的特點,數據具有聚合性,相同特性聚集在一定范圍內;從(2)可以看出無效數據點的存在對有效數據點的聚合性影響不大,因此可以把整個數據分為兩個集合{有效數據點集合}、{無效數據點集合}。集合劃分依據采用有效數據點集合均值一定半徑內的點為有效數據點集合,半徑之外為無效集合。而初始集合的選取,由于有效數據點遠遠多于無效數據點,因此可以簡單設置初始有效數據點集合為全部數據點、無效數據點集合為空集,當迭代到兩個集合數據點穩定以后即可得到結果,而有效半徑可以通過風電場選址數據的湍流強度,通過仿真計算得出合理值。因此采用K-means聚類分析方法可以獲得具體程序流程圖(見圖3)。
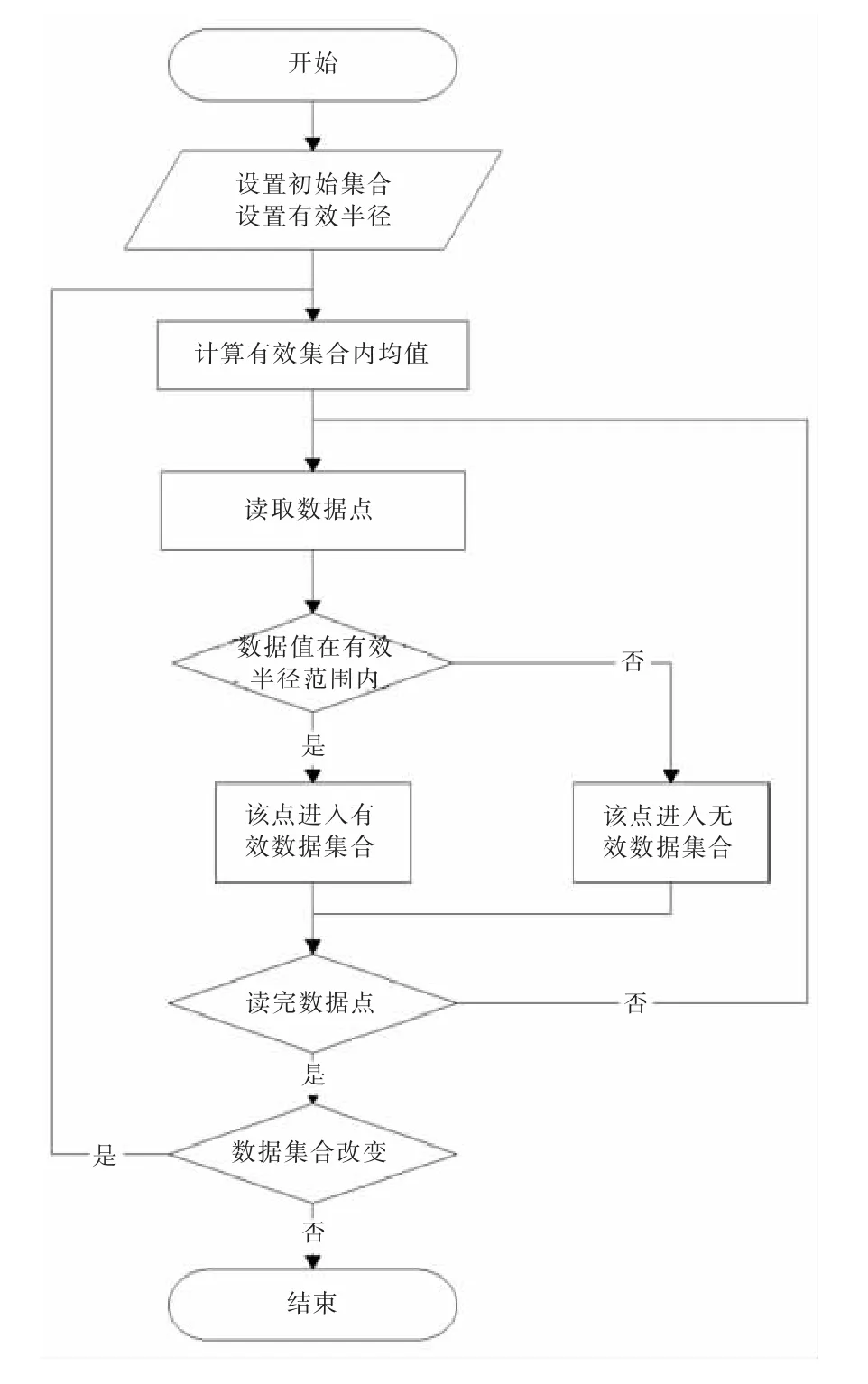
圖3 K-means程序流程圖
按照圖3所示的方法,考慮到常見的數據庫系統可以導出EXCEL格式的數據記錄,雖然EXCEL具有良好的數據統計能力和廣泛的應用基礎,但卻沒有很好的邏輯和流程控制能力,因此,采用.NET平臺[6-7],編譯了相應程序。.NET平臺是微軟公司推出的新一代軟件開發平臺,其主要特點是運行于.NET框架下,各種編程語言只要支持.NET編譯器,就可以和其他類型.NET編程語言之間相互調用,其內建提供了良好的EXCEL操作方法,能夠集EXCEL的數據統計功能和VB的邏輯和流程控制功能于一體,快速開發出所需軟件,且很容易編寫出可視化圖形界面,便于操作,開發完成的軟件界面如圖4所示。

圖4 功率曲線可視化圖形界面
4 數據處理結果
通過已得的可視化圖形界面很容易得到圖5~圖8所示的結果。

圖5 1#機組處理后散點圖
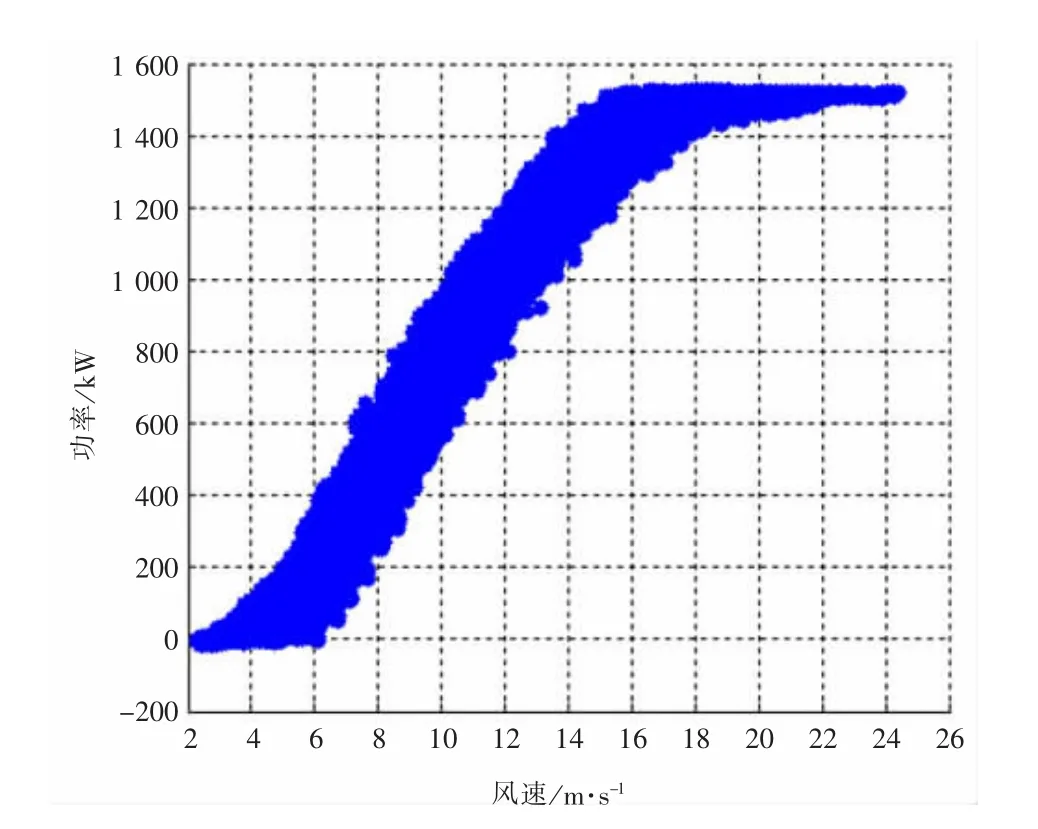
圖7 2#機組處理后散點圖
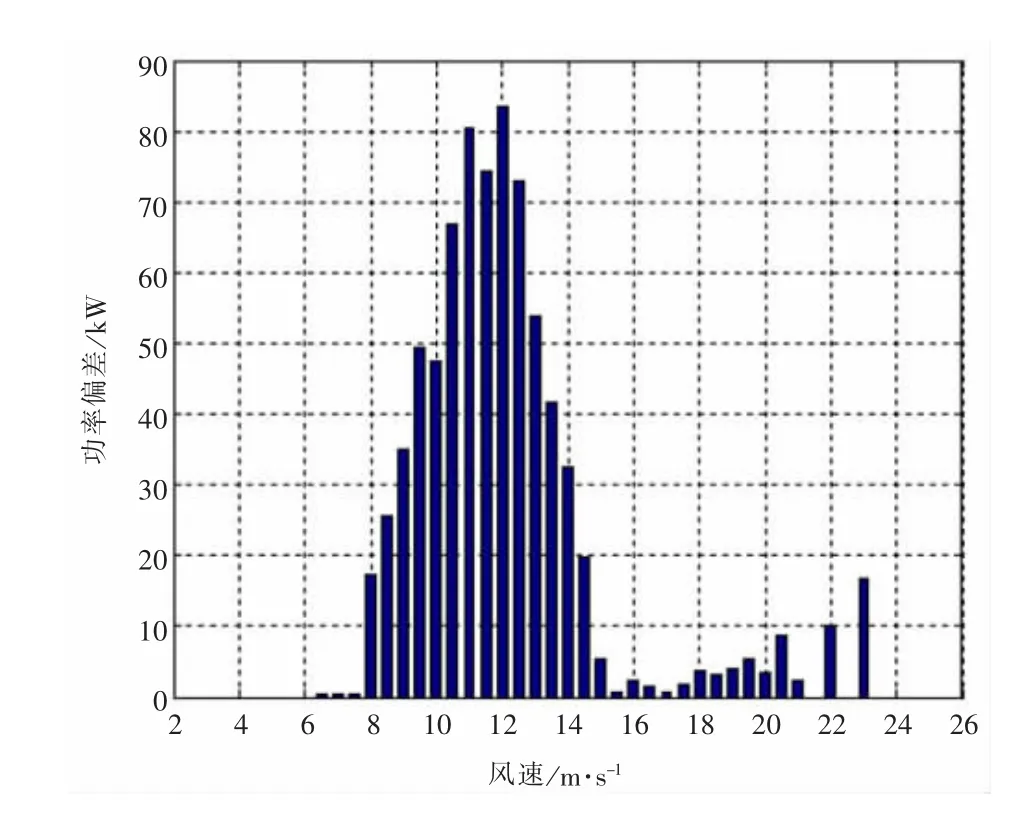
圖6 1#機組處理前后功率曲線偏差
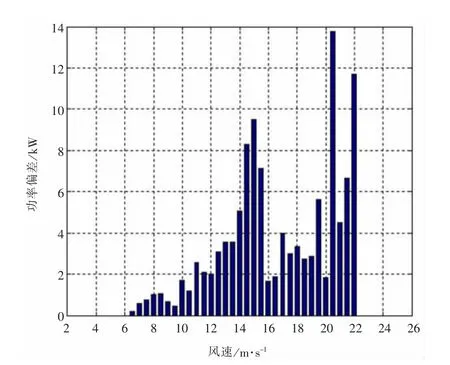
圖8 2#機組處理前后功率曲線偏差
通過對以上圖形的分析,可知采用本文所提出的方法進行處理后的功率曲線散點圖能夠有效剔除掉無效數據點,有助于用戶直觀、快速地分析風力機的發電狀況,有效地提高工作效率。
5 結論
本文采用K-means聚類分析方法對風電場SCADA記錄的功率曲線數據進行處理,通過可視化圖形界面,可以快速、準確、有效地繪制出風力機功率曲線,用戶可以很直觀地分析風力機的發電狀況,也為用戶在風電場發電性能改進方面提供了重要的依據。
[1]郎斌斌,穆剛,嚴干貴.聯網風電機組風速-功率特性曲線的研究[J].電網技術,2008,32(12):70-74.
[2]Wind turbine generator systems-Part 12:Wind turbine power performance testing[S].International Electro Technical Commission,2005.
[3]J F Manwell,J G McGowan,A L Rogers.Wind energy explained[M].British:John Wiley&sons,Ltd.,2002.
[4]李楠.基于強化學習算法的多智能體學習問題的研究[D].無錫:江南大學,2006.
[5]李永森,楊善林,馬溪駿.空間聚類算法中的K值優化問題研究[J].系統仿真學報,2006,18(3):573-576.
[6]周羽明,劉元婷..NET平臺與C#面向對象程序設計[M].北京:電子工業出版社,2010.
[7]嚴月浩.基于.NET平臺的web開發[M].北京:北京大學出版社,2011.
Application of Wind Turbine Power Curve Based on K-means Clustering Analysis
Song Juzhong,Lan Jie,Lin Shu,Mo Erbing
(Dongfang Electric Wind Power Co.,Ltd.,Deyang Sichuan,618000)
Data processing of wind turbine has no effect on wind turbine normal power generation,but it is critical to wind turbine performance analysis.This paper takes the power curve of wind turbine as the study object,the SCADA data records are divided into two categories,the pattern recognition of K-means clustering analysis method is used to exclude invalid data points,and the different types of scatter plots can be handled by the unified algorithm.Through.NET platform which effectively combines with the statistic function of EXCEL and the logic and flow control function of VB language,the visual software is developed accurately and rapidly,the power curve is plotted to help users analyse the power generation performance of wind turbine,and provide an important basis for users to improve the performance of wind farm.
power curve,clustering analysis,K-means,data processing,.NET platform,VB
TP311
A
1674-9987(2017)02-0046-05
10.13808/j.cnki.issn1674-9987.2017.02.011
基金編號:四川省科技支撐計劃項目資助項目(2014GZ0084)
宋聚眾(1978-),男,工學碩士,工程師,2007年畢業于汕頭大學機械設計專業,現從事風電電控設計工作。
猜你喜歡
江蘇安全生產(2022年7期)2022-08-24 02:11:52
世界科學技術-中醫藥現代化(2022年3期)2022-08-22 00:32:50
北京測繪(2022年6期)2022-08-01 09:19:06
選煤技術(2022年2期)2022-06-06 09:13:12
師道·教研(2022年1期)2022-03-12 05:46:47
云南化工(2021年8期)2021-12-21 06:37:54
北京測繪(2021年7期)2021-07-28 07:01:18
海洋信息技術與應用(2020年1期)2020-06-11 12:43:56
山東農業工程學院學報(2019年11期)2020-01-19 02:49:22
傳媒評論(2019年4期)2019-07-13 05:49:14
