關聯規則在急性心肌梗死病案分析中的應用
2017-07-31 21:20:31張彪
移動信息 2017年3期
張 彪
河北大學附屬醫院,河北 保定 071000
關聯規則在急性心肌梗死病案分析中的應用
張 彪
河北大學附屬醫院,河北 保定 071000
目的:對急性心肌梗死的相關因素進行研究,通過運用數據挖掘算法形成關聯規則。方法:收集某醫院近三年的急性心肌梗死病案首頁信息,包括性別、年齡、化驗信息、心電信息、個人史、既往史等。運用 Java語言實現數據挖掘算法(FP-growth),得出281條關聯規則,通過比較支持度、置信度、提升度三個指標獲得有價值的關聯規則。結論:有利于從病案大數據中挖掘出有價值的信息,為醫院的病案信息的管理提供了信息思路。
急性心肌梗死;合并癥;關聯規則;FP-growth
1 研究背景
急性心肌梗死屬于急性冠脈綜合征。除心肌梗死外缺血性心臟病還包括,穩定型心絞痛、不穩定型心絞痛,心肌梗死是其中最嚴重的一種。其發病機理為:在冠狀動粥樣脈硬化的基礎上,發生突然性的冠狀動脈血驟減甚至中斷,使相應的心肌持久性的極度供血不足從而導致心肌壞死。急性心肌梗死的一般臨床表現為持久性胸痛,其位置大多在胸骨后或胸骨中上段,并伴隨發熱、白細胞計數和血清心肌壞死標記物增高等癥狀。心電圖結果多顯示心臟進行性改變,可發生心律失常、休克或心力衰竭等。
2 材料準備
(1)材料來源。本文采用的研究數據源來自河北大學附屬醫院近三年的急性心肌梗死患者的病案首頁信息,內容包括住院號、年齡、性別、住院天數、主要診斷信息、其他診斷信息、既往史等信息。
(2)數據處理。在進行數據挖掘之前,要對原始數據進行預處理,主要包括數據清洗和數據規約兩個步驟。數據清洗是指對原始數據中的錯誤數據、空值數據進行處理,保證結論的準確性;數據規約的目的是對數據源進行精簡,并對數據按照一定規則進行分類,使之具有一定的特征性[1]。
3 研究方法
(1)關聯規則定義。關聯規則分析的目是從數據集中發現各個屬性之間關聯性。在現實世界中事物的發生是存在關聯的,這些聯系或是顯而易見的常識,或是已經被科學證實了的規律,但還有很多關聯性影響是隱藏的。關聯規則分析的作用正是為了隱藏的關聯。關聯規則分析的核心就是計算不同事物同時發生的頻度,得到頻繁項集,再通過計算得到事物相互作用的置信度。即事物A發生時B也發生的概率。
在臨床上,如果要研究疾病X是否是疾病Y的誘因,可以使用關聯規則進行分析,通過在大量數據集中檢索頻繁項,計算當X發生時,Y也出現的概率,若概率值很大說明二者具有強關聯,而且關聯規則具有單向性的特點,容易發現哪個是因,哪個是果。若XY互推概率都很高,說明二者互為因果,也稱共生共存。本文以急性心肌梗死為例,一組患者的數量為2770例,其合并癥(如高血壓,糖尿病等)約有上千種,而具體到個人,有人的合并癥多,有人合并癥少,本文將利用關聯規則算法去發現蘊含在這些合并癥信息中的一些規律。
(2)關聯規則的判斷指標。關聯規則含兩個重要的興趣度度量:支持度(support)和置信度(confidence),它們分別反映所發現規則的有用性和確定性。
支持度s是指事務集D中包含A∪B的百分比,即
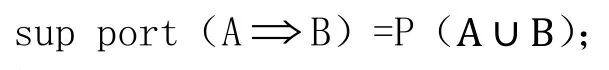
置信度c是指D中包含A的事務同時也包含B的百分比,即:
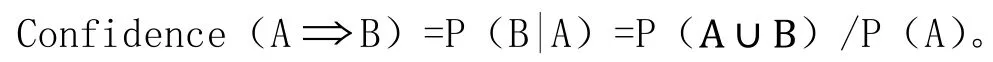
同時滿足最小支持度閾值和最小置信度閾值的規則稱作強規則。在某種情況下,即使支持度和置信的兩個指標都非常高,但是其產生的關聯規則是明顯的無用的。所以,本文有引入了一個新指標——提升度(lift)。Lift也是一種相關性度量,其定義為:項集A的出現獨立于項集B的出現,若P(A∪B)= P(A)P(B)則項集A和B是依賴的和相關的,其公式為:
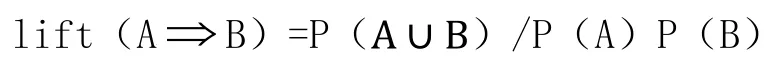
(3)關聯規則算法的核心內容是尋找所有支持度不小于最小支持度的項集。在這里,所有支持度大于最小支持度的項集稱為頻繁項集,簡稱頻集。FP-growth具有深度優先搜索的功能,這種搜索法利用到了項集的反單調性,即:若一個項集是非頻繁的,那么它的超集也是頻繁的。本文將最小支持度設定為3,即只選出至少出現 3次的項集,得出結果后篩選出提升度大于1的模式。
4 結果顯示

36[高血壓 3級,冠狀動脈支架植入后狀態,陳舊性下壁心肌梗死]->2型糖尿病0.0849 0.6149 1.0621[2型糖尿病,高血壓病,冠狀動脈粥樣硬化型心臟病]->高脂血癥0.0849 0.6148 1.06221[高血壓病,冠狀動脈粥樣硬化型心臟病,胃炎]->高脂血癥0.0624 0.1211 1.0799 [室性早搏,陣發性室性心動過速]->高血壓2級 0.0597 0.8906 1.727 22[高脂血癥,冠狀動脈粥樣硬化,高血壓2級]->心功能Ⅰ級0.0671 0.5981 1.09211 [冠狀動脈粥樣硬化,2型糖尿病性腎病]->2型糖尿病 0.0671 0.5981 1.066
5 討論
從編號 8的結果可以看出,患有急性心肌梗死的患者,在出現 2型糖尿病的情況下,發生冠狀動脈粥樣硬化型心臟的概率非常高,由id36可看出,有心肌梗死病史的患者,若同時患有 2型糖尿病,急性心肌梗死的復發概率也是非常高的,結論與文獻描述一致。
綜上所述,關聯規則挖掘能夠從海量數據中發現有價值的信息,而這些信息通過傳統的統計方法往往難以發現,隨著我國醫療技術的不斷發展,醫院信息化建設不斷加強,每天都會產生大量的數據,構建醫療大數據平臺有著廣闊的發展前景。今后我們要更好的利用海量的電子病歷信息,高效、準確地發掘出有價值的信息,更好地服務于臨床。
[1]李春慧,云虹渝,何森,等.心臟增強MRI在冠狀動脈造影基本正常急性心肌梗死一例中的應用及文獻分析[J].華西醫學,2014(10):1891-1894.
Association Rules in the Application of the Medical Record Analysis of Acute Myocardial Infarction
Zhang Biao
Hebei University Affiliated Hospital, Hebei Baoding 071000
Objective:To study the correlative factors of acute myocardial infarction (AMI), and to form association rule by using data mining algorithm. Methods:The first page of acute myocardial infarction(AMI) in a hospital was collected, including sex, age, laboratory information, ECG information, personal history and past history.By using the data mining algorithm (FP-growth) in Java language, 281association rules are obtained, and valuable association rules are obtained by comparing the three indexes of support, confidence and promotion.Conclusion This method is useful for mining valuable information from medical record data and providing information for hospital management of medical record information.
AMI; complication; association rules; FP-growth
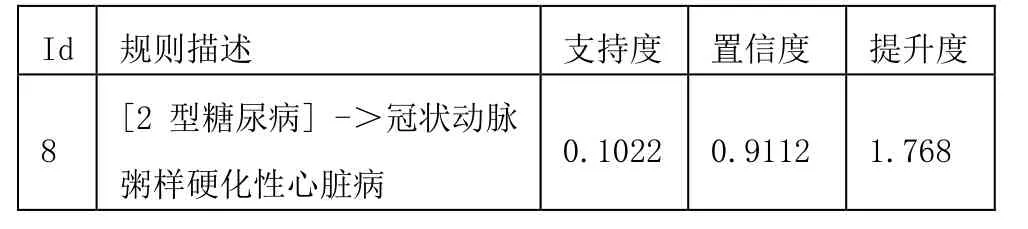
表1
R445.2;R542.22
A
1009-6434(2017)3-0107-02
猜你喜歡
小獼猴智力畫刊(2022年3期)2022-03-29 01:09:42
當代陜西(2021年17期)2021-11-06 03:21:36
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:26:14
學苑創造·A版(2018年11期)2018-02-01 06:29:20
Coco薇(2017年11期)2018-01-03 20:59:57
中華手工(2017年2期)2017-06-06 23:00:31
讀者(2017年5期)2017-02-15 18:04:18
暨南學報(哲學社會科學版)(2016年9期)2017-01-15 13:52:02
中外會展(2014年4期)2014-11-27 07:46:46
當代修辭學(2011年2期)2011-01-23 06:39:12
