KECVS:一個面向專業文獻知識實體的類型標注及可視化系統
2017-08-12 12:22:05伍思杰蔡瑞初郝志峰王麗娟
計算機應用與軟件 2017年8期
溫 雯 伍思杰 蔡瑞初 郝志峰,2 王麗娟
1(廣東工業大學計算機學院 廣東 廣州 510006) 2(佛山科學技術學院數學與大數據學院 廣東 佛山 528000)
?
KECVS:一個面向專業文獻知識實體的類型標注及可視化系統
溫 雯1伍思杰1蔡瑞初1郝志峰1,2王麗娟1
1(廣東工業大學計算機學院 廣東 廣州 510006)2(佛山科學技術學院數學與大數據學院 廣東 佛山 528000)
知識實體的類型標注是專業文獻結構化管理和知識脈絡挖掘中的一個重要任務。由于專業文獻的知識實體具有專業性強、類型多樣、隨時間變化的特點,如何在無監督的情況下對其進行類型標簽抽取、實體類型標注及知識關系挖掘具有重要的意義。設計并實現了一個面向專業文獻知識實體的類型標注及可視化系統,提供文獻數據的實體識別、實體類型標注、知識實體關系圖構建及其可視化等功能,幫助科研工作者更加便捷、直觀、準確地把握知識關系和研究熱點。
信息抽取 實體類型標注 知識關系挖掘 數據可視化 專業文獻
0 引 言
近年來,隨著互聯網的快速普及和硬件存儲技術的高速發展,人們可以輕松地通過眾多的學術數據庫或學術搜索引擎獲取到所需的專業文獻,如Google Scholar、百度學術、CNKI、萬方數據等。由此看來,從互聯網上獲取海量的電子文獻資源的確成為了一件輕松簡單的事情。但是隨之出現的問題是,現有的知識服務已經無法滿足人們對信息“快速、簡單、準確”的需求。面對這樣的知識服務需求,我們有必要針對這類專業文獻進行更深層次的信息抽取與文本挖掘,建立結構化的專業知識體系,以輔助用戶進行文獻檢索。其中,實體類型標注是信息抽取任務中一個重要的子任務,準確的實體類型信息可以實現對知識點的有效分層和分類,還可以基于實體類型進一步挖掘其中的知識關系,從而構造知識脈絡圖。已有的研究大多針對互聯網上常見的新聞文本[1]、微博[2]、Tweets[3]、Facebook等文本進行實體抽取,而針對專業文獻這類特殊文本的研究還比較少,因此有必要對這類文本進行更深入的研究。此外,實體類型標注是實體識別的一個重要組成部分,對后續實體關系的抽取也具有重要的意義[4]。
專業領域的信息抽取已經有一些相關的研究,如Yoshida等針對生物醫學領域實體的研究[5],毛存禮等對有色金屬領域實體的研究[6],還有針對商務領域產品領域實體的研究[7]等。這些研究都是針對不同領域的專業實體進行實體識別,但是卻缺少更深一層的實體類型分析與挖掘,也沒有設計和實現一個真實可用的實體類型標注及可視化系統。還有一部分工作,主要是通過分析網絡上的大量命名實體,實現了上位詞/類別挖掘系統[8]。但是,這些工作缺少對專業文獻這類蘊含復雜且豐富知識點的數據的針對性研究,并不能切實解決專業領域知識服務的迫切需求。
針對以上問題,本文設計并實現了一個面向專業文獻知識實體的類型標注及可視化系統KECVS(Knowledge-Entity Categorization and Visualization System)。該系統能夠根據用戶查詢的實體關鍵詞進行實體類型標注,然后可視化地呈現出知識實體之間的類型關系、層次關系和時序演變模式。系統實施簡單,標注準確率高,具有很強的實際價值和現實意義。另外,提出的一種面向專業文獻知識實體的類型標簽抽取及標注方法可以有效地對專業領域的知識實體進行類型標注。同時也得到比較全面的類型標簽集合,解決了人工預定義實體類型的局限性和主觀性問題,有助于專業知識網絡的結構化實現。
1 系統架構
如圖1所示,KECVS系統分為4層邏輯結構,自底向上分別是:數據獲取層、數據處理層、存儲層和應用層。各層的功能依次遞進,緊密相扣: 1) 最底層為數據獲取層,它的功能是數據源的獲取和存儲,主要包括在線爬蟲及其管理模塊、頁面解析模塊和本地文獻存儲模塊。2) 數據處理層,主要為上面兩層提供核心處理算法,包括有知識實體邊界識別、類型標簽抽取方法及基于多標簽加權標簽傳播的類型標注方法等關鍵技術的實現。3) 中間的存儲層主要是把處理后的數據進行數據庫存儲并建立索引,然后對數據進行知識實體關系圖建模,并轉換成JSON格式數據供應用層實現可視化。4) 最上面的應用層主要是與用戶進行可視化交互,功能是根據用戶的輸入反饋出不同的可視化關系圖,包括有層次圖、關系圖、熱點圖等。以下對部分重要模塊進行介紹。
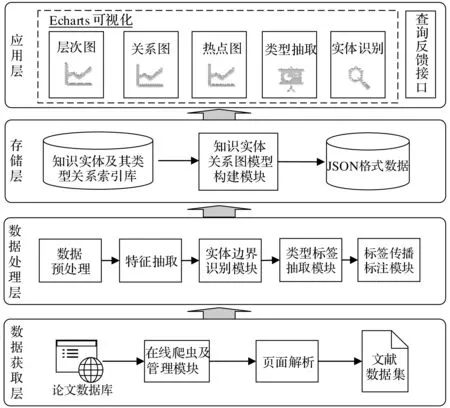
圖1 KECVS系統架構圖
1.1 在線爬蟲及其管理模塊
管理員可以通過后臺指定爬取頁面的地址和范圍,在線爬蟲模塊在后臺自動化地對文獻數據進行爬取并存儲在本地,從而實現定向的文獻爬取及分析。這樣可以簡便地把實體類型抽取擴展到其他專業領域或者其他論文數據庫,為上面三層提供了充足的數據來源。
1.2 類型標簽抽取及類型標注模塊
知識實體的類型標簽抽取模塊主要是對識別到的知識實體進行類型標簽抽取,得到類型標簽集合和部分標注數據。然后,通過基于多標簽加權的標簽傳播算法對未標知識實體實現進一步的標注,得到的類型標注數據傳遞給存儲層進行本地存儲,并建立知識實體及其類型關系索引庫,提高檢索效率。
1.3 知識實體關系圖模型構建及可視化模塊
為了更好地將挖掘到的知識脈絡實現可視化,我們需要對知識實體及其類型數據進行圖模型的構建。根據用戶輸入的關鍵詞對索引庫進行檢索,構建出不同的知識實體關系圖模型,包括有基于同一類型的實體層次關系樹模型(層次圖)、基于不同類型分組的知識關系圖模型(關系圖)和基于時序的知識熱點跟蹤圖模型(熱點圖)。然后,把得到的關系圖模型轉換成JSON格式的數據,傳遞到應用層利用Echarts進行Web可視化實現。
2 關鍵技術
2.1 基于啟發式規則的類型標簽抽取方法
通過對專業文獻的知識實體內部進行統計分析實驗,發現大部分類型詞本就存在于實體內部,我們只需要利用啟發式規則的方法就可以抽取到大部分的類型標簽數據。基于啟發式規則的類型標簽抽取方法具體步驟如下:
1) 首先,我們需要結合文獻摘要信息中知識實體的相關上下文以輔助類型標簽抽取。以識別到的知識實體為匹配詞,對文獻的摘要進行知識實體匹配,再把在摘要中匹配到的知識實體及其后相鄰的名詞提取出來,添加到知識實體集合中。
2) 利用基于啟發式規則的方法對步驟1)得到知識實體集合進行類型標簽抽取,得到候選類型標簽集合,類型抽取的同時獲得部分已標注實體,其中啟發式規則如下:
啟發式規則1:設知識實體ei=(w1,w2,w3,…,wn-1,wn),n≥1,組成詞wi的詞性為ci。如果ci為名詞,則進入規則2。
啟發式規則2:設知識實體ei=(w1,w2,w3,…,wn-1,wn),n≥1,wn是實體ei的最后一個詞,且規則1中的wi=wn,那么把wn加入類型詞候選集Ti。
3) 篩選掉不可靠的類型標簽,通過統計類型標簽與其所屬知識實體共現的頻次,然后根據頻次特征篩選掉共現頻次低且對應知識實體出現頻次少的類型標簽,篩選后的類型標簽集合作為最終輸出。
2.2 基于多標簽加權的標簽傳播標注方法
由于基于啟發式規則的類型標簽抽取方法可以得到絕大部分類型標簽集合和一部分的已標注實體,因此我們考慮可以將其轉換為一個多標簽標注問題,提出一種基于多標簽加權的標簽傳播算法,用于實現剩余未標知識實體的類型標注。
標簽傳播算法[9](LPA)是由Zhu等于2002年提出,它是一種基于圖的半監督學習方法,其基本思路是用已標記節點的標簽信息去預測未標記節點的標簽信息。節點之間邊的權重越大,標簽信息越容易在節點間傳遞。因而,樣本節點越相似,它們擁有同樣的標簽的可能性就越大[10]。我們給出如下定義:
定義1轉換概率矩陣T:
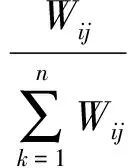
(1)
式中,Tij表示從節點xj轉移到節點xi的概率,也就是知識實體ej轉移到知識實體ei的概率。這里轉移概率Wij可由式(2)計算得到:
(2)
其中,Sij是知識實體ei和ej的相似度度量,本系統使用編輯距離作為度量方法,?參數用于調整Sij的比例,設?為Sij的均值。
定義2類型標簽矩陣Y設第一層抽取中成功抽出類型詞的知識實體個數為l,未能抽出類型詞的知識實體個數為u,則定義類型標簽矩陣Y是一個(l+u)×R矩陣,R為已抽取類型標簽的去重個數。設知識實體ei在第一層類型標注后有K個類型標簽,Cik是第i個實體的k標簽的出現頻次。
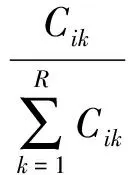
(3)
(4)
其中,Wik是知識實體ei擁有類型標簽k的權重,以標簽k在ei中出現的頻率來度量。當知識實體ei擁有類型標簽k時,則Yij=Wik,否則Yij=0。
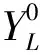
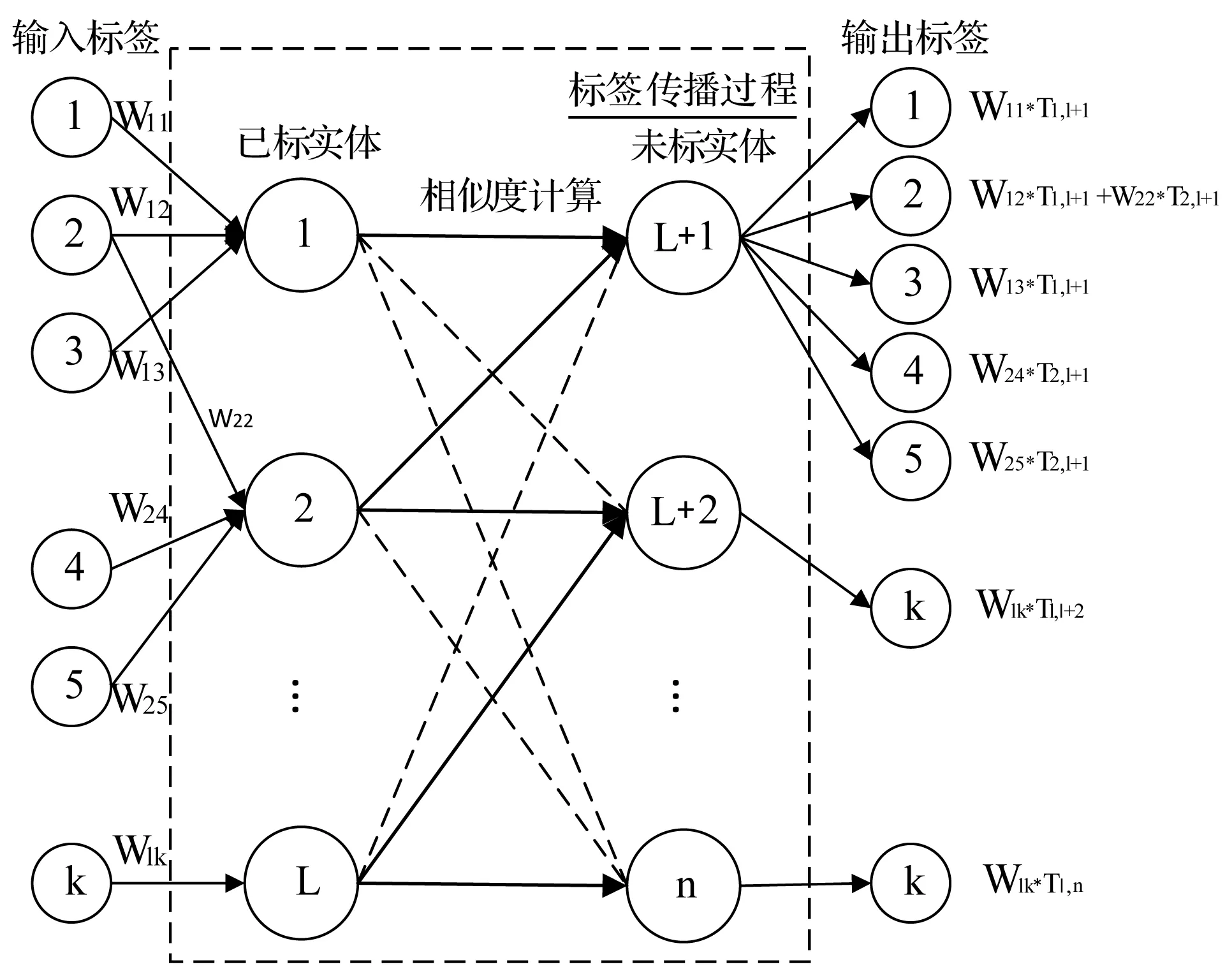
圖2 基于多標簽加權的標簽傳播
2.3 基于知識實體類型關系圖模型構建方法
基于知識實體類型關系圖模型的構建方法主要包括以下5個步驟:
1) 根據用戶輸入的關鍵詞從知識實體索引庫中提取出與該關鍵詞相關的知識實體集合,相關關系包括標題中和摘要中的共現關系、包含關系,以及擴展關系。
2) 構建基于同一類型的實體層次關系樹模型,驗證知識實體集合中兩兩個實體之間的擴展或包含關系,如果實體ei包含實體ej,則建立樹圖模型中父子關系,表示ei是ej的父節點,依次類推,建立層次關系模型。
3) 構建基于類型分組的知識關系圖模型,對知識實體集合中的知識實體按類型進行分組,統計每個類型分組的權值,分組內的知識實體也按照實體權重降序排序;篩選出權值最高的N個分組,每個分組篩選出排在前M個的知識實體(N和M可由用戶選擇指定),按照關鍵詞—類型分組—實體的次序構造三層的圖模型。
4) 構建基于時序的知識熱點跟蹤圖模型,根據知識實體的時間進行排序,構建按照半年為周期的時間段分組,分別統計每個時間段出現的相關的知識實體數量,各個時間段分組內的知識實體按照實體權重進行排序,最后以時間分組和對應實體列表構建熱點跟蹤圖模型。
5) 把步驟2)~4)所述的模型轉換成JSON形式的數據并輸出到數據可視化模塊。
3 實驗及結果分析
3.1 數據使用情況
本文設計實現網絡爬蟲對CNKI中國知網(http://www.cnki.net/)的計算機類專業論文進行爬取,并以爬取到的論文題目、論文關鍵詞,以及論文摘要作為實驗數據,共包含56 462篇計算機類核心期刊論文。我們以論文關鍵詞為分詞用戶詞典,對論文標題進行中文分詞及知識實體抽取,共抽出77 364個知識實體。其中,隨機抽取出500個知識實體并進行人工類型標注,以標注后的知識實體作為測試集。
3.2 實驗結果及分析
為了方便統計和實驗,我們對500個知識實體進行類型分組,我們把類型樣本個數占比最高的前5個類型獨自作為類型分組,剩下的其他類型由于樣本占比較少,合并作為一個類型分組,并統一標注為其他。因此,測試集中共標注6種類型,分別是方法、算法、系統、模型、技術和其他。以準確率(Precision)、召回率(Recall)和F1系數(F1-Measure)作為評價指標,F1系數計算方法見式(5)。
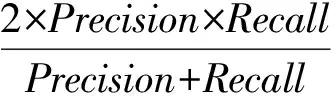
(5)
圖3是系統分別對這6種類型進行知識實體類型標注實驗的結果。可以看出,各個分組的準確率都較高,最高的“技術”分組準確率達到94.11%,說明系統判斷的正確率較高,能較好地對知識實體進行類型標注。而召回率相對低一點,原因是有較多知識實體專業性較強,出現頻次過少而無法根據實體相似性傳播類型標簽所導致的,因此這類出現頻次較少的知識實體大多會被判定為其他。改進的方法是擴大爬蟲爬取范圍,增加訓練數據,解決部分知識實體訓練樣本不足的問題。總體而言,實驗中的各個類型分組結果都表現較好,F1值最低的“其他”分組也達到72.29%,各組平均F1值約77%,說明系統可以有效地對專業知識實體進行類型標注,并具有較高的指導意義。
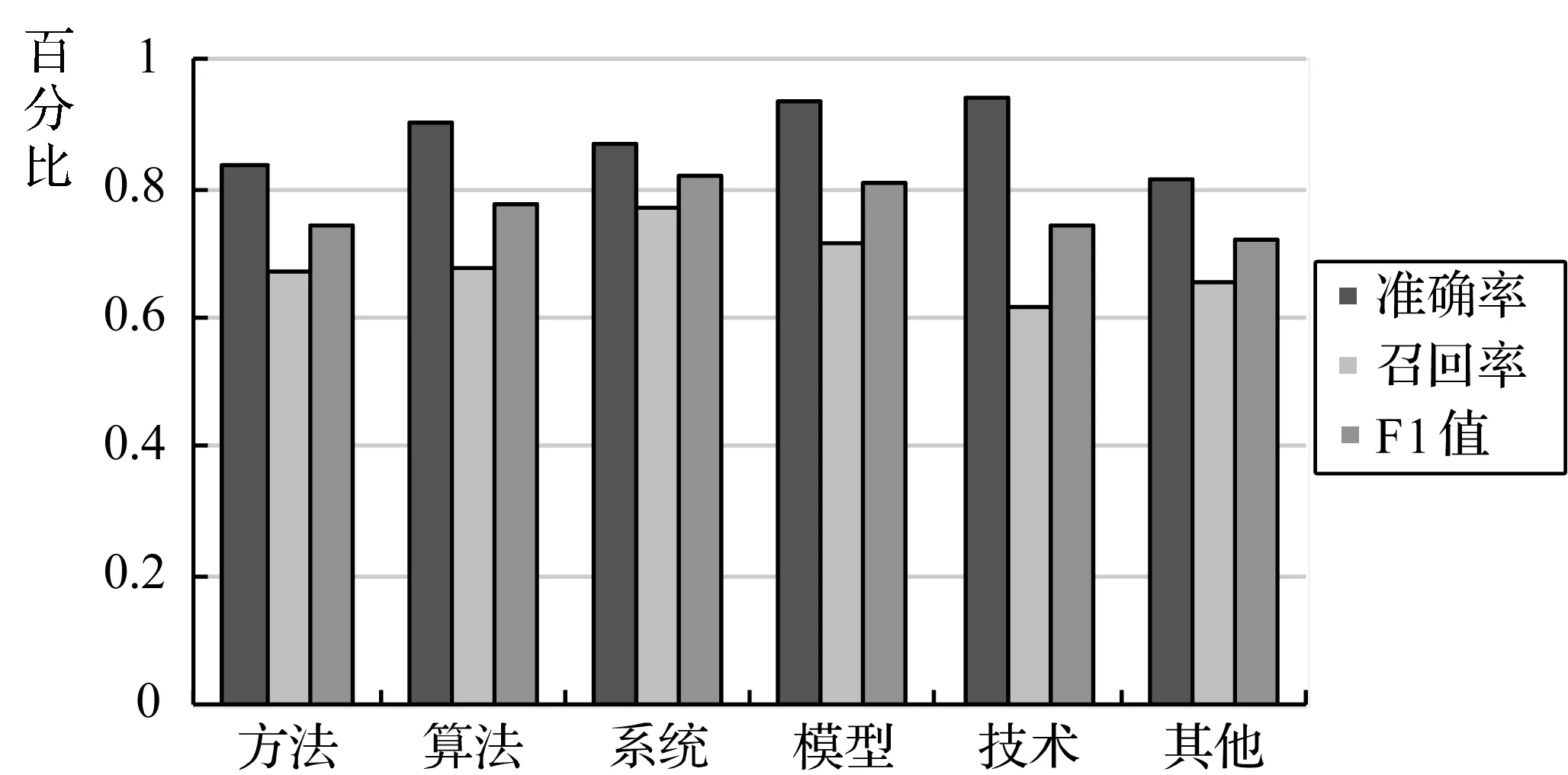
圖3 不同分組的結果對比
在另外一組實驗中,將本文的標注方法與傳統的CRF標注方法進行了實驗對比。從圖4以看出,本文提出的基于多標簽加權的標簽傳播方法效果較好,在各個分組的測試結果中F1系數值均比CRF方法要高,各分組平均F1值提升了7.61%。其中在“方法”分組中,本文方法的F1值相對CRF方法提升了19.66%。由此,我們可以看出CRF這類方法并不適合于這類專業文獻知識實體的類型標注,可能的原因是這類知識實體長度較短,上下文信息特征不足,導致無法準確判斷標注。另外,由于知識實體類型種類較多,類型特征高達3 000多維,導致CRF模型在訓練的過程中十分緩慢,性能較差。由此可以看出,本文提出的方法能更加有效地解決專業文獻知識實體的類型標注問題,無論是準確率還是性能都比傳統CRF方法有較大的提升。
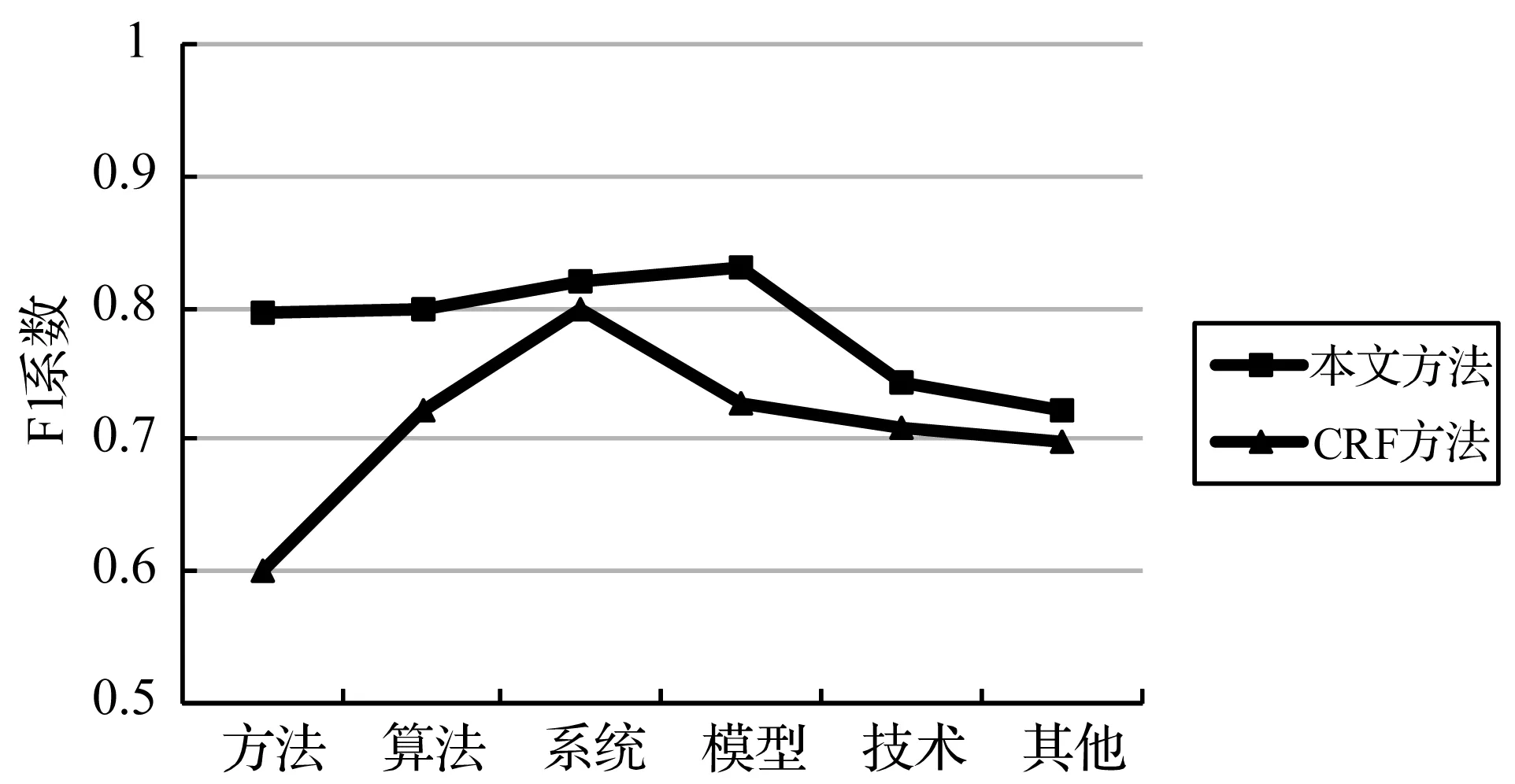
圖4 不同方法的結果對比
4 應 用
4.1 系統環境需求
KECVS系統的服務器硬件配置要求為:CPU:Intel Core i3以上,內存1 GB以上,操作系統:Windows 7;環境配置要求:JDK1.7.0及以上版本,PHP5.5.12,Apache2.4.9,MySQL5.6.17;用戶瀏覽器要求:IE10.X及以上版本IE內核瀏覽器、Firefox、Chrome瀏覽器。
4.2 系統功能及應用
KECVS系統(http://kecvs.dmirlab.com/)首頁如圖5所示,左側主菜單包括5部分內容:類型抽取、層次圖、關系圖、熱點圖和實體識別。首頁同時也是類型抽取頁面,在右上角檢索框輸入實體關鍵詞(或者直接點擊檢索框下的快捷提示詞)后,類型抽取頁面會生成類型結果說明,同時在說明下方生成該檢索關鍵詞的類型分布餅狀圖。例如我們輸入“條件隨機場”進行類型抽取,可以看到“條件隨機場”的最符合類型標簽是“模型”。
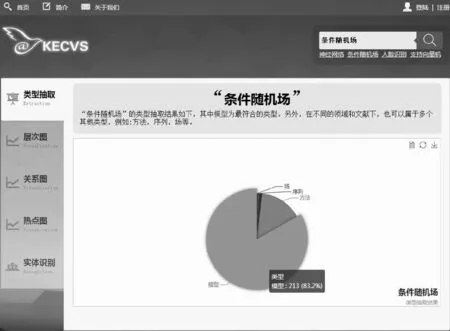
圖5 KECVS系統首頁
知識實體關系圖分別包括層次樹圖、知識關系圖及時序熱點圖三部分。其中,圖6展示的是基于類型分組的知識關系圖的可視化界面,用戶輸入關鍵詞“條件隨機場”檢索后,獲得以“條件隨機場”為中心的不同類型分組下的知識關系圖,包括有模型、方法、算法、協議、系統等多個類型下的知識點。例如,從圖中可以看到,與“條件隨機場”相關的“方法”有:“視頻分割方法”、“中文詞性標注方法”、“機器學習方法”等。
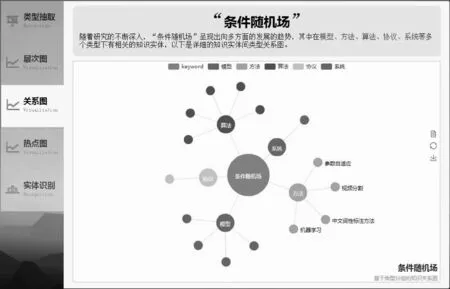
圖6 基于類型分組的知識關系圖可視化界面
知識實體識別及類型標注的界面如圖7所示。用戶可以在上方輸入框輸入想要進行識別的文本或者點擊“隨機獲取摘要”按鈕獲取文獻摘要文本進行識別測試。點擊“開始識別”按鈕后,可以在下方得到知識實體的類型標注結果,結果中不同的顏色背景代表不同的類型,在最下方有對應顏色的類型圖示。例如,從圖7中可以看到,“條件隨機場”、“LDA”、“CRF”等知識實體都能識別出來,并將類型標注為“模型”,而“目標檢測”、“機器學習”等則標注為“方法”。

圖7 知識實體識別及類型標注界面
目前,KECVS系統所有圖表采用Echarts3實現可視化,均提供數據視圖及圖表下載功能。
5 結 語
本文設計實現了面向專業文獻知識實體的類型標注及可視化系統KECVS,提供對文獻數據的數據爬取、數據清理、實體識別、類型標簽抽取、類型標注及知識實體關系圖構建等功能,并通過Web數據可視化技術呈現給用戶。同時,本文通過對比實驗驗證了本文的方法比傳統的標注方法更加適用于專業文獻知識實體的類型標注問題,最終實驗結果也表明本文的方法擁有更高的準確率和更佳的性能。因此,通過KECVS系統可以簡單便捷地獲取到所關注知識點的層次樹圖、知識關系圖及熱點跟蹤圖等,從而為科研工作者在科研方向上提供有價值的參考和啟發。未來進一步的工作包括繼續完善系統功能,提高系統后臺處理性能,為用戶提供更便捷、準確和高效的知識服務系統。
[1] 吳共慶,胡駿,李莉,等.基于標簽路徑特征融合的在線 Web 新聞內容抽取[J].軟件學報,2016,27(3):714-735.
[2] 鄭影,李大輝.面向微博內容的信息抽取模型研究[J].計算機科學,2014,41(2):270-275.
[3] Liu X, Li K, Zhou M, et al. Collective semantic role labeling for tweets with clustering[C]// International Joint Conference on Artificial Intelligence. AAAI Press, 2011:1832-1837.
[4] 陳宇,鄭德權,趙鐵軍.基于Deep Belief Nets的中文名實體關系抽取[J].軟件學報,2012,23(10):2572-2585.
[5] Yoshida K, Tsujii J. Reranking for biomedical named-entity recognition[C]//Proceedings of the Workshop on BioNLP 2007: Biological, Translational, and Clinical Language Processing. Association for Computational Linguistics, 2007: 209-216.
[6] 毛存禮,余正濤,沈韜,等.基于深度神經網絡的有色金屬領域實體識別[J].計算機研究與發展,2015,52(11):2451-2459.
[7] 劉非凡,趙軍,呂碧波,等.面向商務信息抽取的產品命名實體識別研究[J].中文信息學報,2006,20(1):7-13.
[8] 付瑞吉.開放域命名實體識別及其層次化類別獲取[D]. 哈爾濱工業大學計算機科學與技術學院,2014.
[9] Zhu X, Ghahramani Z. Learning from labeled and unlabeled data with label propagation[R]. Technical Report CMU-CALD-02-107, Carnegie Mellon University, 2002.
[10] Chen J, Ji D, Tan C L, et al. Relation extraction using label propagation based semi-supervised learning[C]//Proceedings of the 21st International Conference on Computational Linguistics and the 44th Annual Meeting of the Association for Computational Linguistics. Association for Computational Linguistics, 2006: 129-136.
KECVS:AKNOWLEDGE-ENTITYCATEGORIZATIONANDVISUALIZATIONSYSTEMFORACADEMICLITERATURE
Wen Wen1Wu Sijie1Cai Ruichu1Hao Zhifeng1,2Wang Lijuan1
1(SchoolofComputerScienceandTechnology,GuangdongUniversityofTechnology,Guangzhou510006,Guangdong,China)2(CollegeofMathematicsandBigData,FoshanUniversity,Foshan528000,Guangdong,China)
Knowledge-entity categorization is an important task for the structural management of academic literature and knowledge-graph mining. Since knowledge entities are highly specialized, diverse and evolve with time, how to categorize, annotate and analyze the knowledge-entity on unlabeled data is of great significance. In this paper, a knowledge-entity categorization and visualization system are designed and developed for academic literature, which provides knowledge-entity recognition and categorization, as well as generation and visualization of the knowledge-graph. Hence it is able to help researchers effectively analyze the knowledge relations and research hotspots.
Information extraction Entity categorization Knowledge relationship mining Data visualization Academic literature
2016-06-21。國家自然科學基金項目(61202269,61472089,61502108);NSFC-廣東聯合基金項目(U1501254);廣東省科技計劃項目(2015B010108006,2015B010131015);廣州市科技計劃項目(2014Y2-00027)。溫雯,副教授,主研領域:機器學習,模式識別,信息檢索。伍思杰,碩士生。蔡瑞初,教授。郝志峰,教授。王麗娟,講師。
TP391
A
10.3969/j.issn.1000-386x.2017.08.016
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
世界科學技術-中醫藥現代化(2022年3期)2022-08-22 00:32:50
云南化工(2021年8期)2021-12-21 06:37:54
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
海洋信息技術與應用(2020年1期)2020-06-11 12:43:56
數學物理學報(2020年2期)2020-06-02 11:29:24
傳媒評論(2019年4期)2019-07-13 05:49:14
光學精密工程(2016年6期)2016-11-07 09:07:19
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
