基于主題模型的改進隨機森林算法在文本分類中的應用
2017-08-12 12:22:06張曦煌
計算機應用與軟件 2017年8期
姚 立 張曦煌
(江南大學物聯網工程學院 江蘇 無錫 214122)
?
基于主題模型的改進隨機森林算法在文本分類中的應用
姚 立 張曦煌
(江南大學物聯網工程學院 江蘇 無錫 214122)
針對傳統隨機森林算法在維度高、噪聲大的文本分類上出現計算復雜度高和分類效果較差的問題,提出一種基于隱狄利克雷分配(LDA)主題模型的改進隨機森林算法。該算法利用LDA主題模型對原始文本建立模型,將原始文本映射到主題空間上,保證了文本主旨與原始文本的一致性,同時也大大降低了文本噪聲對分類的影響;并且針對隨機森林中決策樹特征的隨機選擇方法,提出在決策樹生成過程中,利用對稱不確定計算各個特征之間的相關性,從而可以降低不同決策樹之間的關聯度。最終在主題空間上利用改進的隨機森林算法對文本進行分類。經過實驗證明,該算法在文本分類上具有良好的優越性。
隱狄利克雷模型 主題模型 隨機森林 特征評估 文本分類
0 引 言
目前超過80%的信息都是以文本的形式存儲的[1],因此對于機器學習和數據挖掘來說,如何有效地組織大量的文本信息已經成為當前一個重要的課題。文本分類是鑒別文檔類別的一種預測算法。傳統的文本分類技術主要有決策樹、樸素貝葉斯、支持向量機、k-鄰近、神經網絡等算法。
在文本分類的應用研究上,許多學者提出了自己的算法。周慶平等[2]提出基于聚類的改進 KNN 算法。算法開始之前采用改進χ2統計量方法進行文本特征提取,再依據聚類方法將文本集聚類成幾個簇,最后利用改進的 KNN 方法對簇類進行文本分類。Yang[3]提出了一種組合特征選擇函數,將常用的特征選擇函數通過準確度系數連接起來構成一個新的特征選擇函數,最后在SVM 分類器進行文本分類。Zhou[4]提出了一種基于k-means聚類特征選擇的文本分類算法。該算法使用k-means算法獲取每個類別的聚類中心,然后選擇高頻詞作為文本特征的中心來進行文本分類。張翔等[5]提出了一種Bagging中文文本分類器的改進算法。其算法針對弱分類器的分類結果進行可信度計算從而得到每個弱分類器的權重,最后將權重應用于Attribute Bagging算法。
在文獻[6]中,作者將LDA模型應用到文本分類中,并且通過實驗表明采用基于LDA的SVM算法比用VSM結合SVM和LSI結合SVM相比具有較好的分類效果。而在文獻[7]中提出在其測試的179種分類器中,并行化的隨機森林算法在眾多的分類器中的綜合表現最優。因此本文提出了基于LDA的主題模型的改進隨機森林文本分類算法(LDA-iRF),通過使用LDA主題模型的主題分布表示原始文本,使用LDA在降維后的低維特征空間可以有效減少隨機森林的計算時間;并且在主題選擇上進行改進,淘汰掉低權重的主題;最后在隨機森林的決策樹生成過程中考慮不同特征之間的相關性,從而降低各個決策樹之間的關聯度。最終,通過實驗證明了該分類方法的優越性。
1 相關說明
1.1 LDA模型
傳統的文檔表示方法有向量空間模型[8](VSM)、概率潛語義分析[9](PLSA)等。其中VSM方法將文章抽象成一個向量,以關鍵字為基本單位,其文章間相似度取決于兩篇文章的共同的詞匯量,所以無法避免一詞多義給文章帶來語義模糊性;而PLSA又會由于訓練數據存在噪聲,會出現過擬合現象,為了解決此問題,PLSA采用最大似然估計的方法。但是PLSA可以生成原始文檔集的模型,卻無法生成新的文檔模型。
LDA模型是Blei等[10]提出的一種處理像文本文檔的這類離散數據的生成概率模型。LDA是三層生成式的貝葉斯網絡結構,其有向概率圖模型,如圖1所示。
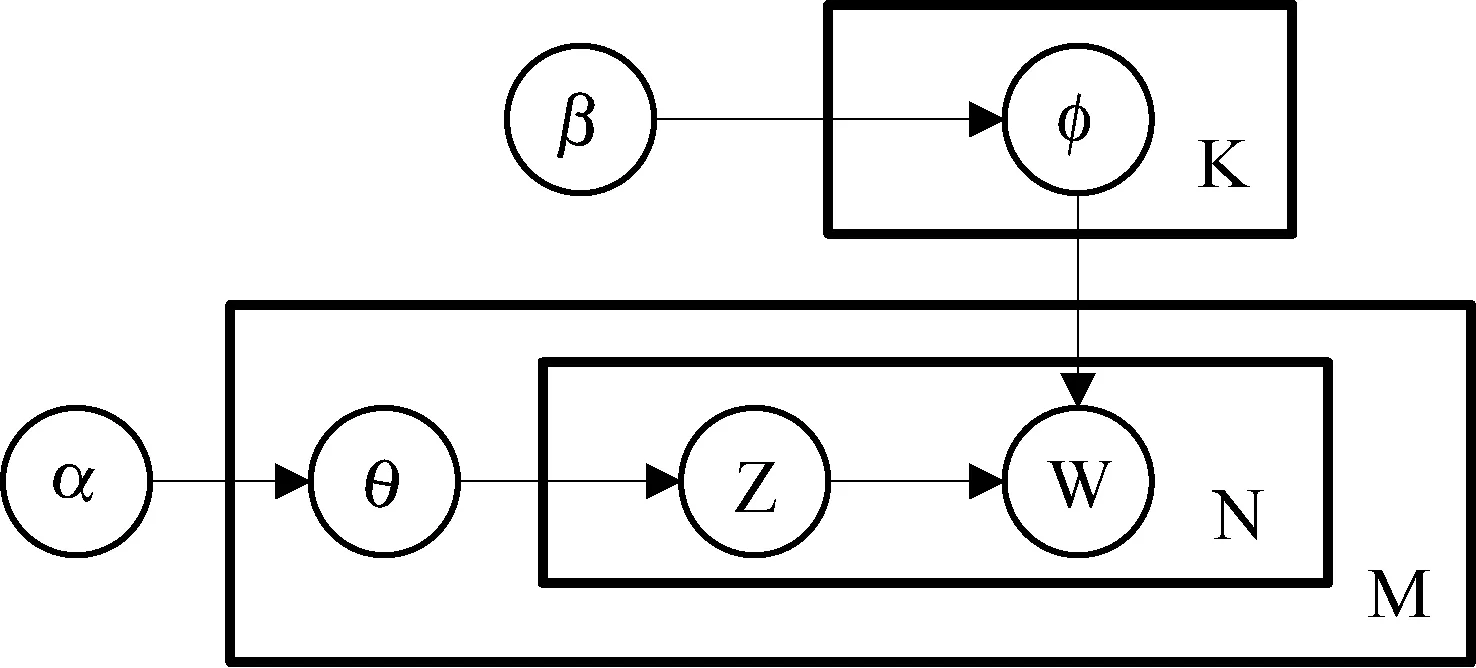
圖1 LDA模型有向概率圖
根據LDA的圖模型,可以寫出所有變量的聯合分布如公式中所示:
(1)
其等價于公式如下:
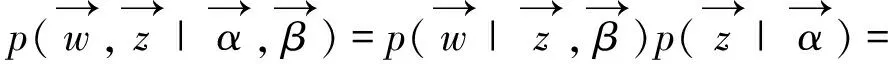
(2)
LDA概率主題模型的一篇文檔生成方式如下:
1) 按照先驗概率P(di)選擇一篇文檔di。
2) 從Dirichlet分布中取樣生成文檔di的主題分布θ。
3) 從主題的多項式分布θi中取樣生成文檔di第j個詞的主題zi,j。
4) 從Dirichlet分布β中取樣生成主題zi,j對應的詞語分布。
5) 從詞語的多項式分布φi,j中采樣最終生成詞語wi,j。
LDA模型參數的估計方法有多種,Blei在其論文中使用的是變分-最大期望算法,后來Griffiths發現使用吉布斯采樣方法效果更好[11]。吉布斯采樣是馬爾科夫鏈蒙特卡羅理論(MCMC)中用來獲取一系列近似等于指定多維概率分布觀察樣本的算法。
對于吉布斯采樣,其核心思想是,先排除當前主題分配,然后利用其它主題分配和詞匯來計算當前主題分配的概率。其算法見式(3):
(3)
式中,zi代表第i個詞匯所設置對應的主題;i代表排除第i個詞匯;表示主題k中出現了多少次詞匯t;βt是詞匯t的Dirichlet先驗超參數;表示在文檔m中出現主題k的次數;αk是主題k的Dirichlet先驗超參數。
在獲得每個單詞的主題標號后,需要的參數可以由以下公式推導得:
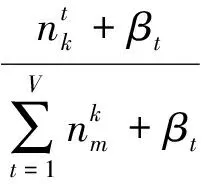
(4)
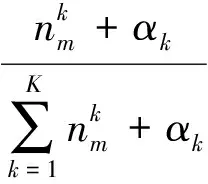
(5)
式(4)和式(5)中,φk,t表示主題k中詞項t的概率;θm,k表示文本m中主題k的概率。
1.2 隨機森林
隨機森林[12](RF)構建在多棵決策樹基礎上,采用Bagging的集成學習思想,在決策樹的訓練過程中采用了隨機特征選擇。其算法步驟是,首先使用Bootstrap方法從原始的數據集合中隨機選擇N個樣本,然后對這N個樣本進行決策樹算法訓練,從而得到N棵決策樹。因為本文使用隨機森林是用來處理分類問題,故將測試集記錄使用這N棵決策樹進行預測,針對最后的每棵決策樹的預測結果進行投票決定最終分類。最終的分類決策如公式所示:
(6)
其中,H(x)表示分類器的模型,hi是單個決策樹,Y表示輸出變量(或稱目標變量),I(·)為指示函數[13]。
2 基于LDA的改進隨機森林算法
2.1 主題選取策略
由于LDA是一個非監督的機器學習方法,文檔-主題矩陣是建立的所有的文檔之上,許多跟文檔無關的主題也會被分配到較低的權重,所以如果直接使用訓練后的文檔-主題矩陣將會降低分類效果。針對此問題,采用設定文檔-主題矩陣閾值的方法將低權重的主題淘汰。每篇文章的主題選取的閾值采用式(7)計算,其中Td表示文章d的主題閾值,∑Wd表示文章d所設定的所有主題的權重之和,K表示主題的數目。
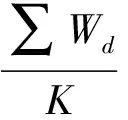
(7)
最終,改進的隨機森林算法將會建立在經以上步驟處理后的文檔-主題矩陣之上。
2.2 改進的隨機森林算法
傳統隨機森林的決策樹特征選擇是隨機選取的,而沒有考慮到相關特征之間的關系,而在文獻[14]中提出:如果不同的決策樹之間關聯程度越小,那么隨機森林的分類效果越好。因此本文提出了基于特征評估的改進隨機森林算法。
2.2.1 改進方法1:基于熵的改進連續屬性離散化方法
經過LDA算法對原始文檔進行處理后得到的文檔-主題矩陣的值為連續值,所以必須對其進行離散化處理。
定義1設閾值T將集合S分成兩個集合S1和S2,并設有k個類別C1,C2,…,Ck,使用P(Ci,S)表示S中有類別Ck的比例,那么定義集合S的熵為:
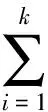
(8)
定義2對于集合S,如果有特征A和閾值T,現在閾值T按特征A的值小于等于T或者大于T將集合分成兩個子集合S1和S2,那么定義特征A對集合S的條件熵為:
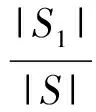
(9)
傳統的基于熵的連續屬性離散化方法是按二元劃分,計算每個可能的數據劃分點,即如果有N條數據,那么需要進行N-1次計算,最后選取最小的那個劃分點,因此這種算法開銷較高。而文獻[15]提出并證明:不管數據集合有多少類別,而且不管這些數據是如何分布的,那么數據劃分點總是在兩個類別的邊界點上。基于以上思想,改進的連續屬性離散化算法步驟如下:
步驟一將文檔-主題的特征列按從低到高排序。并按照式(8)計算Entropy(S)。
步驟二按照式(9)計算兩個不同類別相鄰邊界點上的條件熵。
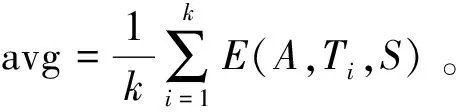
步驟四對步驟二上求出的各個邊界點上的條件熵與步驟三的條件熵的平均值作比較,保留低于平均熵的邊界點,即將這些點作為屬性劃分點。
2.2.2 改進方法2:基于對稱不確定的特征評估方法
定義3信息增益的計算公式為:
gain=Entropy(S)-E(A,T,S)
(10)
因為基于信息增益的特征評估方法對于數據不多的特征效果欠缺,所以采用對稱不確定來計算兩個特征A與B之間的關系:
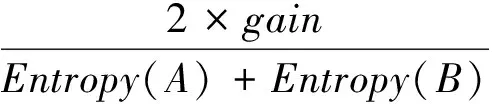
(11)
式(11)表明,如果SU(A,B)值越大,那么表明兩個特征之間越相關,反之表明兩個特征之間關聯越小。
綜上所述改進的隨機森林具體步驟如下所述:
算法1改進的隨機森林算法
輸入:設S={x1,y1},{x2,y2},…,{xm,ym},其中|x1,x2,…,xm|T表示經過改進方法1離散化后的文檔-主題矩陣φm,k,|y1,y2,…,ym|T表示文檔的類別。
輸出:隨機森林RF
1. 設N為隨機森林中決策樹的數量
2. 設k=log2n[16]為決策樹中節點的個數
3. 設builded_trees為構建好的隨機森林決策樹集合,初始為空
4. 設矩陣mat[i,j]用于存儲不同特征之間的SU值
5. For 特征i In 特征集合:
6. For 特征j In 特征集合:
7. 根據式(11)計算特征i和特征j之間的對稱不確定的值,并將值存入mat[i,j]
8. End For
9. End For
10.
11. For i In N:
12. 為正在構建的決策樹i隨機選擇n/3個特征
13. 設sumSU=+∞
14. For j In builded_trees:
15. For node_i In j:
16. 在矩陣中獲取與node_i對應的n/3個特征的SU值
17. 選擇k個最小SU值對應的特征,選擇規則如下:
18. 如果node_i有多個對應的SU相同,則在這些特征中隨機選擇
19. 如果某個特征已經被之前的節點選中,則選擇下一個特征
20. End For //以上會獲取k個SU值
21. 設tempSumSU為k個SU值的和
22. 如果tempSumSU小于sumSu,則sumSu=tempSumSU,并記錄這k個特征
23. End For
24. 根據選擇的k個特征構造CART決策樹
25. 將該決策樹添加到builded_trees中
26. End For
27. return builded_trees;
2.3 基于LDA的改進隨機森林算法步驟描述
LDA-iRF算法主要包括文本預處理、使用LDA建立模型、主題選取處理、隨機森林訓練分類器、對測試集預測和對分類效果進行對比。具體步驟如下:
步驟一文本的預處理。將訓練文本集和測試文本集使用中科院的ICTCLAS分詞系統進行分詞,并采用哈工大停用詞表以去除沒有對分類效果沒有意義的停用詞、數字和標點符號。
步驟二利用LDA建模。先利用Perplexiy選擇出合適的主題數量。再使用LDA對訓練集文本建模,獲得訓練集的文檔-主題矩陣θm,k和主題-詞匯矩陣φk,t。接著對測試集使用在訓練集上建立的LDA模型進行推斷,得到測試集的文檔-主題矩陣。最后,采用主題選擇策略以淘汰低權重的主題。
步驟三構造改進的隨機森林分類器。對訓練集的文檔-主題矩陣和每篇文章對應的分類別進行建模,先使用改進方法1對文檔-主題矩陣進行離散化,再使用算法1構造文本分類器。
步驟四對預測結果進行分類。采用簡單投票法對隨機森林中的每棵決策樹預測的的結果進行表決獲得最后結果。
步驟五對分類的結果進行對比評估。在不同的數據集上進行比較。利用分類指標對分類器的結果進行評估。
2.4 時間復雜度分析
設文本的數量是N,第n篇文章的單詞數目為Mn,主題數目為K。在算法初始化階段的時間復雜度為O(N·Mn)。在LDA算法對數據進行訓練階段的時間復雜度是O(N·Mn·K)。文檔-主題矩陣離散化時間復雜度為O(N·K)。而利用對稱不確定性評估不同特征之間的時間復雜度為O(K·K)。
在建立決策樹階段,設Ntrees為隨機森林中決策樹的數量,設V是決策樹中節點的個數,則構建一顆決策樹的時間復雜度是O(V·Ntrees+V·Nlog(N)),那么構建隨機森林的時間復雜度是O(Ntree·(V·Ntrees+V·Nlog(N)))。
綜上述,本文算法的時間復雜度是:O(N·Mn·K)+O(N·K)+O(K2)+O(Ntrees·(V·Ntrees+V·Nlog(N)))。
3 實驗設計和結果分析
3.1 實驗環境
本文的實驗計算機使用的是Intel i5-2500 CPU,主頻為3.3 GHz,操作系統是Windows 8.1,16 GB內存。所有的實驗代碼均采用Java語言實現。
3.2 數據集介紹以及評價方法
本文采用了搜狗新聞公開語料庫與復旦大學語料庫兩種不同的數據集進行實驗。其中搜狗新聞語料庫的隨機選擇了商業、旅行、健康和房產四個類目各400篇訓練文本和100篇測試文本。另外,復旦語料庫隨機選擇了計算機、環境、農業、經濟和體育五個類目各400篇訓練文本和100篇測試文本。
文本分類通常采用的評價方式是精確率(P=TP/(TP+FP))和召回率(R=TP/(TP+FN)),其中TP、FN和FP分別表示真正例、假反例和假正例的數量。為了綜合考慮精確率和召回率,將實驗進行了很多次,每次實驗產生的精確率和召回率記為(P1,R1),(P2,R2),…,(Pn,Rn),則可以采用宏F1(macro-F1)和微F1(micro-F1)來綜合評價分類性能,其計算公式如下。
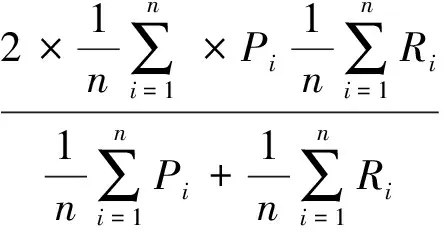
(12)
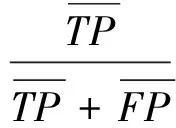
(13)
3.3 實驗結果與分析
3.3.1 LDA主題模型參數選取實驗
LDA模型的參數有超參數α、β和主題數目K。本文中α根據主題的數目設定,即采用α=50/K;β取常數0.01[17]。實驗中的迭代次數為1 000次。
LDA主題的數目K能直接影響到后續的分類精確程度,如果主題數目過多,會導致各個主題之間的詞匯相互重合;而如果主題過少,就會導致不能完全表達原始文本的主旨,從而導致分類效果差。本文采用的是基于Perplexity的主題個數選取方法。該方法通過式(14)計算不同主題個數下的Perplexity值。
(14)
將兩個語料庫進行詞匯預處理之后,搜狗語料庫共有58 897個詞匯,復旦語料庫共有148 021個詞匯。實驗中主題的個數選取從10到100以5遞增,實驗數據如圖2所示。
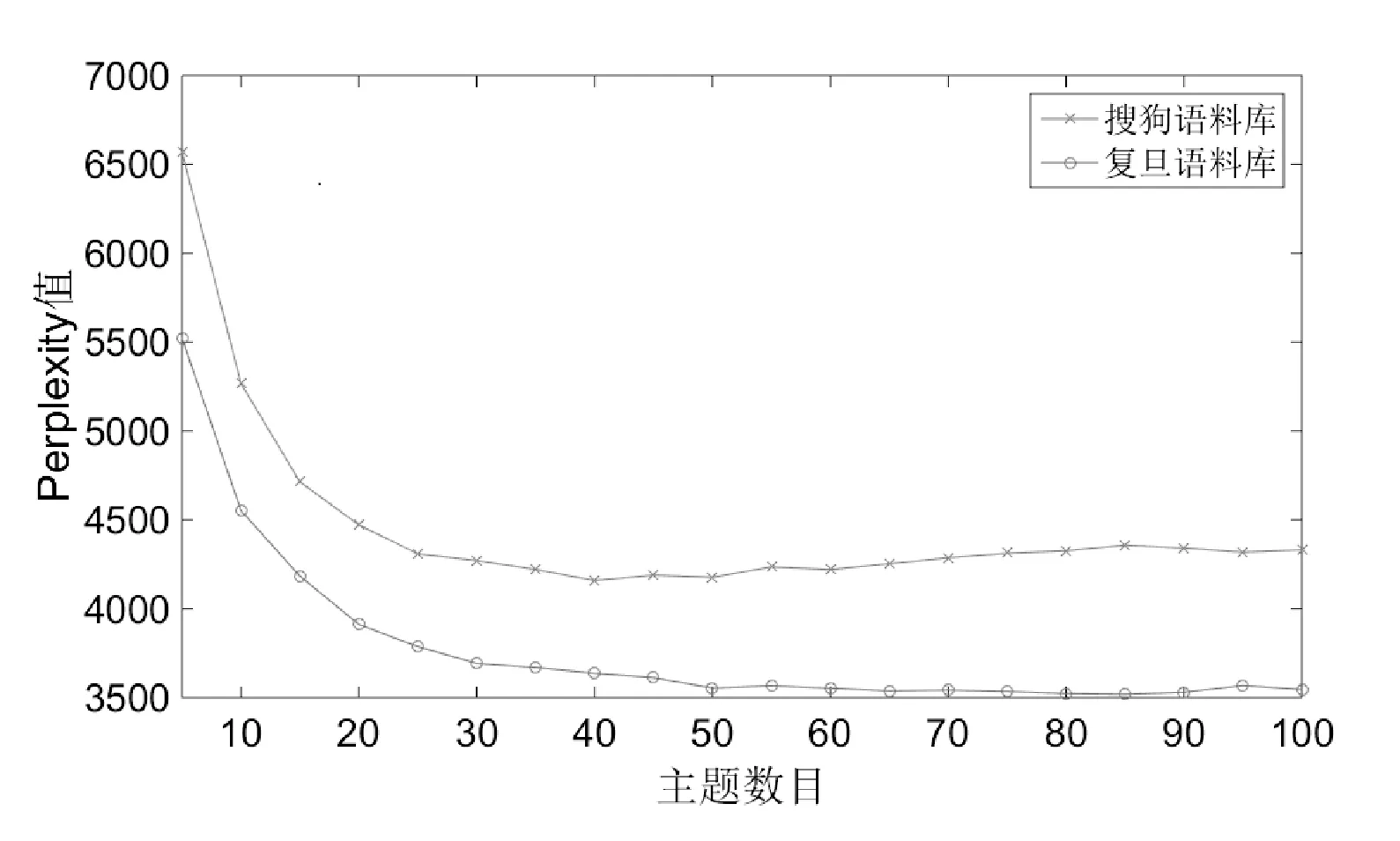
圖2 Perplexity與主題數目的關系
根據Perplexity曲線圖可以看出,對于復旦語料庫與搜狗語料庫,其主題數目分別取50和40后,Perplexity值趨于平穩。
3.3.2 文本分類實驗
本文的實驗設計采用以下四種算法模型進行比較實驗,它們分別是基于LDA的改進隨機森林算法(LDA_iRF)、基于LDA的隨機森林算法(LDA_RF)、基于LDA的SVM算法(LDA_SVM)和隨機森林算法(RF)。隨機森林中決策樹的數量為100棵;LDA_SVM算法采用的LIBSVM[18]所作為SVM分類器,其使用的是徑向基RBF核函數。將以上四個算法對訓練文本和測試文本分別運行10次并按分類評價方法計算得到實驗結果,如圖3-圖6所示。

圖3 復旦語料庫下四種算法的macro_F1值比較
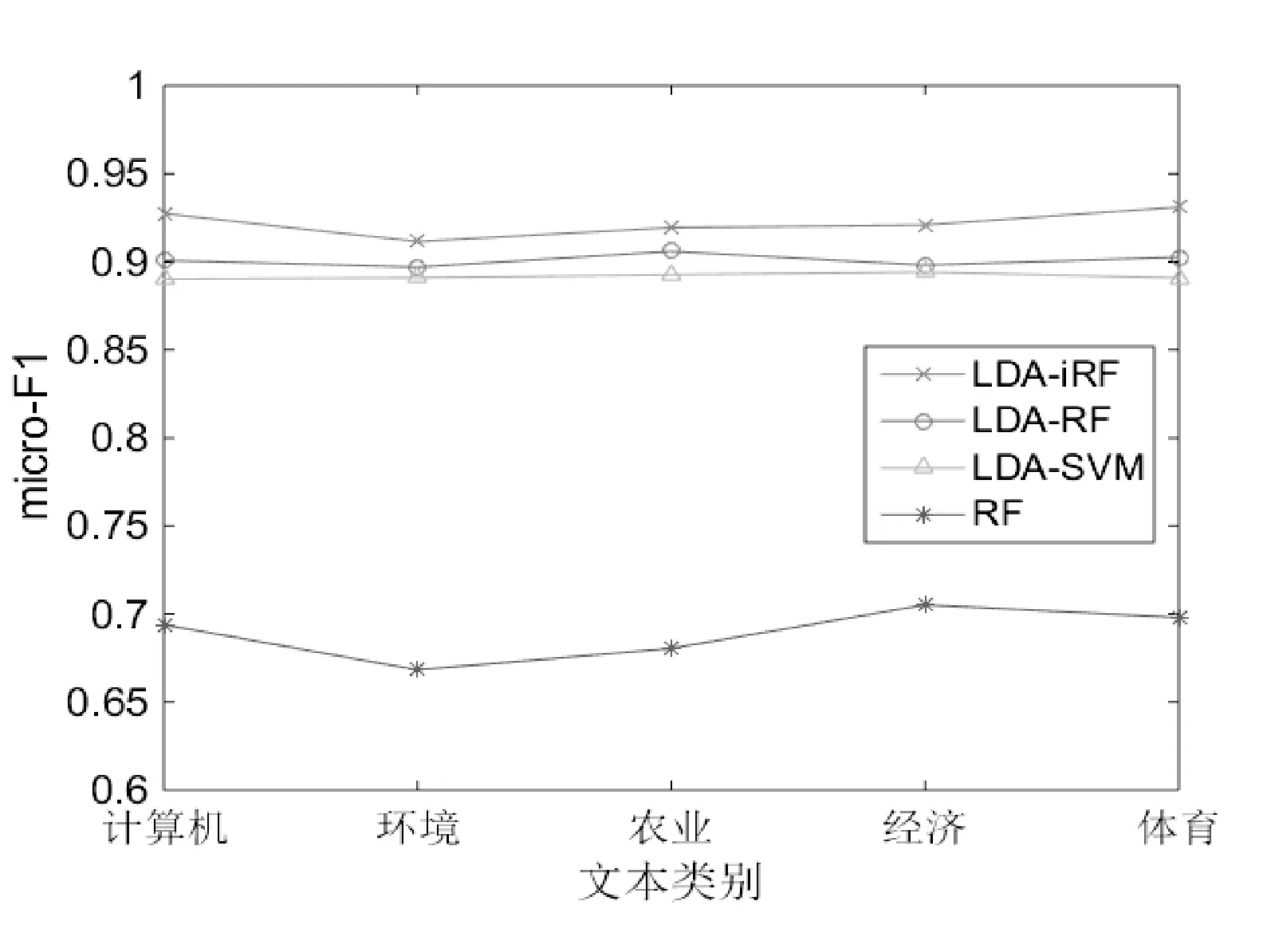
圖4 復旦語料庫下四種算法的micro_F1值比較
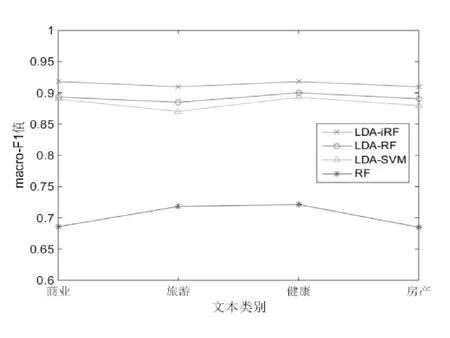
圖5 搜狗語料庫下四種算法的macro_F1值比較
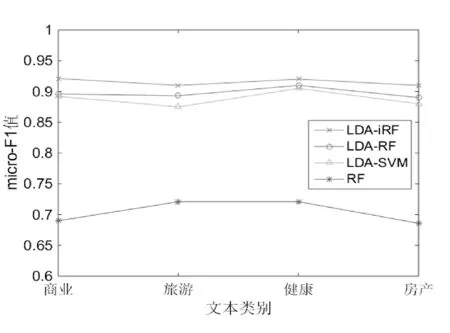
圖6 搜狗語料庫下四種算法的micro_F1值比較
由圖3-圖6可以看出,由于實驗數據是采用的均衡數據,macro_F1和micro_F1兩種指標在不同的語料庫下表現基本一致。而且不管是在復旦語料庫還是搜狗語料庫,LDA_iRF的macro_F1值和macro_F1值均高于其他三種算法,且比LDA_RF算法的macro_F1和micro_F1在兩個語料庫上分別平均高出2.192%和2.144%。另外,LDA_RF和LDA_SVM算法相比,前者比后者的分類指標略有提升但相差不大。而傳統的RF算法在高維度的文本處理上確實存在不足。通過以上實驗可以得出,基于LDA的改進隨機森林算法在文本分類上macro_F1值和micro_F1值較之前的文本分類算法相比有一定的提高,從而驗證了該算法的有效性。
4 結 語
本文提出了基于LDA主題模型的改進隨機森林文本分類算法,通過在實驗部分與當前主流的文本分類算法進行對比,其預測分類的效果得到明顯提升。然而在對比過程中發現,隨著文檔的數量增多,LDA模型中字典中的詞也越來越多,這樣就會導致吉布斯采樣運算迭代次數的增多,以致運算時間大大增加。所以在下一步工作中,將研究如何將吉布斯算法并行化,以減少模型的訓練時間。
[1] Korde V,Mahender C N.Text classification and classifiers:A survey[J].International Journal of Artificial Intelligence & Applications,2012,3(2):85.
[2] 周慶平,譚長庚,王宏君,等.基于聚類改進的KNN文本分類算法[J].計算機應用研究,2016,33(11):3374-3377.
[3] Yang Y.Are-examination of text categorization methods[C]//International ACM SIGIR Conference on Research and Development in Information Retrieval.ACM,1999:42-49.
[4] Zhou X,Hu Y,Guo L.Text categorization based on clustering feature selection[J].Procedia Computer Science,2014,31:398-405.
[5] 張翔,周明全,耿國華.Bagging中文文本分類器的改進方法研究[J].小型微型計算機系統,2010,31(2):281-284.
[6] 姚全珠,宋志理,彭程.基于LDA模型的文本分類研究[J].計算機工程與應用,2011,47(13):150-153.
[7] Fernández-Delgado M,Cernadas E,Barro S,et al.Do we need hundreds of classifiers to solve real world classification problems[J].Journal of Machine Learning Research,2014,15(1):3133-3181.
[8] Salton G,Wong A,Yang C S.A vector space model for automatic indexing[J].Communications of the ACM,1975,18(11):613-620.
[9] Hofmann T.Probabilistic latent semantic indexing[C]//Proceedings of the 22nd annual international ACM SIGIR conference on Research and development in information retrieval.ACM,1999:50-57.
[10] Blei D M,Ng A Y,Jordan M I.Latent dirichlet allocation[J].Journal of Machine Learning Research,2003,3:993-1022.
[11] Griffiths T L,Steyvers M.Finding scientific topics[J].Proceedings of the National Academy of Sciences of the United States of America,2004,101(S1):5228-5235.
[12] Breiman L.Random Forests[J].Machine Learning,2001,45(1):5-32.
[13] 方匡南,吳見彬,朱建平,等.信貸信息不對稱下的信用卡信用風險研究[J].經濟研究,2010(S1):97-107.
[14] Xu B,Huang J Z,Williams G,et al.Classifying very high-dimensional data with random forests built from small subspaces[J].International Journal of Data Warehousing and Mining (IJDWM),2012,8(2):44-63.
[15] Fayyad U M.Multi-Interval Discretization of Continuous-Valued Attributes for Classification Learning[C]//International Joint Conference on Artificial Intelligence,1993:1022-1027.
[16] 周志華.機器學習[M].清華大學出版社,2016:180.
[17] Steyvers M,Griffiths T.Probabilistic topic models[J].Handbook of latent semantic analysis,2007,427(7):424-440.
[18] Chang C C,Lin C J.LIBSVM:a library for support vector machines[J].ACM Transactions on Intelligent Systems and Technology (TIST),2011,2(3):27.
IMPROVEDRANDOMFORESTSALGORITHMBASEDONTOPICMODELANDITSAPPLICATIONINTEXTCLASSIFICATION
Yao Li Zhang Xihuang
(SchoolofIOTEngineering,JiangnanUniversity,Wuxi214122,Jiangsu,China)
In view of some problem emerged in text classification which has high dimension and big noise, the traditional random forest algorithm has exposed the defect of the computational complexity and the poor classification performance. We present an improved random forest algorithm based on LDA. This algorithm uses the LDA to model the original text, maps the original text to the topic space, ensures the consistency of the purport between text and the original text, and greatly reduces the impact of text noise on the classification. Moreover, to solve the problem of the random selection method for the features of decision tree in random forests, a method which utilizes the symmetrical uncertainty to calculate the correlation between all features is presented during the generation process of decision trees and reduces the correlation between different decision trees. Finally, we used the improved random forests algorithm in topic space for text classification. The experiment shows that the algorithm has good superiority classification ability in text.
Latent Diriehlet Allocation (LDA) Topic model Random forest Feature evaluation Text categorization
2016-11-15。江蘇省產學研合作項目(BY2015019-30)。姚立,碩士,主研領域:數據挖掘,文本分類。張曦煌,教授。
TP391.1
A
10.3969/j.issn.1000-386x.2017.08.031
猜你喜歡
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
制造技術與機床(2019年10期)2019-10-26 02:48:08
當代陜西(2019年10期)2019-06-03 10:12:04
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
電子制作(2018年18期)2018-11-14 01:48:06
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
小學教學參考(2015年20期)2016-01-15 08:44:38
